Você também pode gostar
- Business @ the Speed of Thought (Review and Analysis of Gates' Book)No EverandBusiness @ the Speed of Thought (Review and Analysis of Gates' Book)Nota: 5 de 5 estrelas5/5 (2)
- Ebook Supercharge Incident Response Runbook AutomationDocumento9 páginasEbook Supercharge Incident Response Runbook AutomationShiva KumarAinda não há avaliações
- Link.: More Secure? More Authentic? Even Nostalgic?Documento6 páginasLink.: More Secure? More Authentic? Even Nostalgic?Akpknuako1Ainda não há avaliações
- Digital Transformation ChallengesDocumento2 páginasDigital Transformation ChallengessujadilipAinda não há avaliações
- FlowForma - 6 Step Digital Process Automation EGuideDocumento20 páginasFlowForma - 6 Step Digital Process Automation EGuideOnur UyarAinda não há avaliações
- Empower Citizen Developers With 3 Data-Driven StepsDocumento12 páginasEmpower Citizen Developers With 3 Data-Driven StepsArijit BrahmaAinda não há avaliações
- A Roadmap For Scaling Self-Service Analytics 1.0Documento13 páginasA Roadmap For Scaling Self-Service Analytics 1.0Deepak GuptaAinda não há avaliações
- INFO661-Final Individual AssignmentDocumento6 páginasINFO661-Final Individual AssignmentReetu RahmanAinda não há avaliações
- Fast-Track To Enterprise Cloud: Integrated Platforms As A Route To Digital ReadinessDocumento11 páginasFast-Track To Enterprise Cloud: Integrated Platforms As A Route To Digital ReadinessjasonyapAinda não há avaliações
- Empower Citizen Developers With 3 Data-Driven StepsDocumento12 páginasEmpower Citizen Developers With 3 Data-Driven StepsJuan David Gómez ZapataAinda não há avaliações
- T4YVZVgETuOwpYkcZ98C - Complete Guide To Modern IT Operations EbookDocumento11 páginasT4YVZVgETuOwpYkcZ98C - Complete Guide To Modern IT Operations EbookSAmpleAinda não há avaliações
- BPM8 - The Future of BPMDocumento4 páginasBPM8 - The Future of BPMSuhas UdaykumarAinda não há avaliações
- Vendor Invoice Management With SAPDocumento434 páginasVendor Invoice Management With SAPRangabashyamAinda não há avaliações
- Demystifying Digital Transformation Non Technical Toolsets For Business Professionals Thriving in The Digital Age Attul Sehgal Full ChapterDocumento51 páginasDemystifying Digital Transformation Non Technical Toolsets For Business Professionals Thriving in The Digital Age Attul Sehgal Full Chapterlouise.butler839100% (16)
- Omniverse Enterprise 5 Steps Digital Twins EbookDocumento11 páginasOmniverse Enterprise 5 Steps Digital Twins EbookDávid AnnamAinda não há avaliações
- Gartner SDLCDocumento12 páginasGartner SDLCRubanBalu B BAinda não há avaliações
- Guide To Edge Management SolutionsDocumento13 páginasGuide To Edge Management Solutionssaba0707Ainda não há avaliações
- 5 Steps Process Centric It OrganizationDocumento12 páginas5 Steps Process Centric It OrganizationNelton MucivaneAinda não há avaliações
- Emerging Technologies Workbook: DigitalDocumento11 páginasEmerging Technologies Workbook: DigitalFazli SameerAinda não há avaliações
- Information Technology in The Digital EconomyDocumento40 páginasInformation Technology in The Digital EconomyAhsan NaeemAinda não há avaliações
- Ultimate Guide To ObservabilityDocumento16 páginasUltimate Guide To ObservabilityShruthiAinda não há avaliações
- What Are The Key Barriers in Digitising Organisations' Procurement Function and How To Overcome ThemDocumento6 páginasWhat Are The Key Barriers in Digitising Organisations' Procurement Function and How To Overcome ThemAy KAinda não há avaliações
- Module I - Becoming Data-DrivenDocumento20 páginasModule I - Becoming Data-DrivenKoko LaineAinda não há avaliações
- Agile Ops Ebook Digital TransformationDocumento31 páginasAgile Ops Ebook Digital TransformationMarkAinda não há avaliações
- Arquitectura de DatosDocumento9 páginasArquitectura de DatosjorgecifAinda não há avaliações
- Dynamics365 en Replacing Accounting SoftwareDocumento10 páginasDynamics365 en Replacing Accounting SoftwareDavid BriggsAinda não há avaliações
- COVID 19 ArticleDocumento5 páginasCOVID 19 Articlegirma tsegayeAinda não há avaliações
- Why Digital Transformation Cant Wait Whitepaper PDFDocumento12 páginasWhy Digital Transformation Cant Wait Whitepaper PDFRipneet SinghAinda não há avaliações
- Why Automation Is Critical To Delivering Scalable and Reliable Big Data SolutionsDocumento8 páginasWhy Automation Is Critical To Delivering Scalable and Reliable Big Data SolutionsSteep BesoinAinda não há avaliações
- The Definitive Guide To Bizops PDFDocumento11 páginasThe Definitive Guide To Bizops PDFEduardo PignalberiAinda não há avaliações
- Chapter 13 Emerging TechnologiesDocumento6 páginasChapter 13 Emerging Technologiesqwira analyticsAinda não há avaliações
- Itil® 4 and Devops: A Cultural Perspective Mark SmalleyDocumento10 páginasItil® 4 and Devops: A Cultural Perspective Mark SmalleyAvneeshÜbermenschBalyanAinda não há avaliações
- How Automation Powers Business InnovationDocumento13 páginasHow Automation Powers Business InnovationShiva KumarAinda não há avaliações
- Frontline Workers in The Digital Age: A Manager's Guide: Resco InspectionsDocumento14 páginasFrontline Workers in The Digital Age: A Manager's Guide: Resco Inspectionszafar.ccna1178Ainda não há avaliações
- Digital Procurement For Lasting Value Go Broad and Deep PDFDocumento9 páginasDigital Procurement For Lasting Value Go Broad and Deep PDFbilalsununu1097Ainda não há avaliações
- 1st PaperDocumento8 páginas1st PaperShirisha N RajAinda não há avaliações
- Why You Need Operational IntelligenceDocumento15 páginasWhy You Need Operational IntelligenceMutia DiarAinda não há avaliações
- Business Continuity RoadmapDocumento38 páginasBusiness Continuity RoadmapCatherine Gardner-GaskinAinda não há avaliações
- Smarter IT: Optimize IT Delivery, Accelerate Innovation: InsideDocumento15 páginasSmarter IT: Optimize IT Delivery, Accelerate Innovation: InsidedachronicmasterAinda não há avaliações
- What's Next After Lean? Nothing Well, Maybe Lean LogisticsDocumento4 páginasWhat's Next After Lean? Nothing Well, Maybe Lean Logisticscp3y2000-scribdAinda não há avaliações
- 4 Steps To Building A Low Code CompanyDocumento18 páginas4 Steps To Building A Low Code CompanyEmmerson da Silva MartinsAinda não há avaliações
- How To Develop A Cloud Strategy and Technology Roadmap User Guide From Bluefin SolutionsDocumento16 páginasHow To Develop A Cloud Strategy and Technology Roadmap User Guide From Bluefin Solutionssantoshkodihalli100% (2)
- Tired of "Winging It":: 6 Suggestions To Get Data Working For YouDocumento4 páginasTired of "Winging It":: 6 Suggestions To Get Data Working For YouAnonymous yjLUF9gDTSAinda não há avaliações
- LeanIX Whitepaper-Metrics enDocumento10 páginasLeanIX Whitepaper-Metrics enPratyusha MaddaliAinda não há avaliações
- 4.introduction - The Enterprise Capabilities That Turndigital and AI Into A Source of Ongoing Competitive Advantage - RewiredDocumento13 páginas4.introduction - The Enterprise Capabilities That Turndigital and AI Into A Source of Ongoing Competitive Advantage - RewiredZaghim GhafoorAinda não há avaliações
- Cio Guide Align Business Tech StrategyDocumento22 páginasCio Guide Align Business Tech Strategyprakash113779Ainda não há avaliações
- Keynote Presentation Executive Visions: Agenda KeyDocumento7 páginasKeynote Presentation Executive Visions: Agenda KeyShobha ShettyAinda não há avaliações
- AI and Due DiligenceDocumento10 páginasAI and Due DiligenceDhananjai ranaAinda não há avaliações
- Emerging Trends in Information TechnologyDocumento13 páginasEmerging Trends in Information Technologylolmingani saipanyuAinda não há avaliações
- 1 - Composable DevOps Automated Ontology Based DevOps Maturity AnalysisDocumento8 páginas1 - Composable DevOps Automated Ontology Based DevOps Maturity AnalysisSohaib RehmanAinda não há avaliações
- The Cloud Native Journey PivotalDocumento30 páginasThe Cloud Native Journey Pivotaltmrajghat_247145222Ainda não há avaliações
- Selecting, Implementing, and Using EHS Software SolutionsDocumento15 páginasSelecting, Implementing, and Using EHS Software SolutionsMohamed AlyAinda não há avaliações
- The Definition of Big DataDocumento7 páginasThe Definition of Big DataLinh NguyenAinda não há avaliações
- Reprints Forrester Com Assets 2 437 RES137037 ReportsDocumento11 páginasReprints Forrester Com Assets 2 437 RES137037 ReportsMario Ruiz100% (1)
- 1-11271 WP CioDocumento6 páginas1-11271 WP CioJennie SansomAinda não há avaliações
- 7 Essentials Ebook US FINALDocumento10 páginas7 Essentials Ebook US FINALfrancisAinda não há avaliações
- A Framework For Incident ResponseDocumento65 páginasA Framework For Incident ResponseVicente OrtizAinda não há avaliações
- Innovation Governance Innovate Yourself-Using Innovation To Overcome Auditing ChallengesDocumento4 páginasInnovation Governance Innovate Yourself-Using Innovation To Overcome Auditing ChallengesSucreAinda não há avaliações
- What Is Big DataDocumento8 páginasWhat Is Big Databheng avilaAinda não há avaliações
- Pe 03 - Course ModuleDocumento42 páginasPe 03 - Course ModuleMARIEL ASIAinda não há avaliações
- Solved Simplex Problems PDFDocumento5 páginasSolved Simplex Problems PDFTejasa MishraAinda não há avaliações
- Computing of Test Statistic On Population MeanDocumento36 páginasComputing of Test Statistic On Population MeanKristoffer RañolaAinda não há avaliações
- Rule 113 114Documento7 páginasRule 113 114Shaila GonzalesAinda não há avaliações
- SHCDocumento81 páginasSHCEng Mostafa ElsayedAinda não há avaliações
- LTE Networks Engineering Track Syllabus Overview - 23 - 24Documento4 páginasLTE Networks Engineering Track Syllabus Overview - 23 - 24Mohamed SamiAinda não há avaliações
- Organization and Management Module 3: Quarter 1 - Week 3Documento15 páginasOrganization and Management Module 3: Quarter 1 - Week 3juvelyn luegoAinda não há avaliações
- Project - New Restuarant Management System The Grill HouseDocumento24 páginasProject - New Restuarant Management System The Grill HouseMayank Mahajan100% (3)
- Homework 1 W13 SolutionDocumento5 páginasHomework 1 W13 SolutionSuzuhara EmiriAinda não há avaliações
- Assignment#10 Global Strategy and The Multinational CorporationDocumento1 páginaAssignment#10 Global Strategy and The Multinational CorporationAnjaneth A. VillegasAinda não há avaliações
- Modulo EminicDocumento13 páginasModulo EminicAndreaAinda não há avaliações
- Thermally Curable Polystyrene Via Click ChemistryDocumento4 páginasThermally Curable Polystyrene Via Click ChemistryDanesh AzAinda não há avaliações
- BMOM5203 Full Version Study GuideDocumento57 páginasBMOM5203 Full Version Study GuideZaid ChelseaAinda não há avaliações
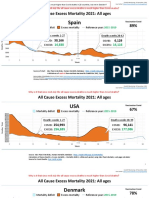
- Countries EXCESS DEATHS All Ages - 15nov2021Documento21 páginasCountries EXCESS DEATHS All Ages - 15nov2021robaksAinda não há avaliações
- History of The Sikhs by Major Henry Cour PDFDocumento338 páginasHistory of The Sikhs by Major Henry Cour PDFDr. Kamalroop SinghAinda não há avaliações
- in Strategic Management What Are The Problems With Maintaining A High Inventory As Experienced Previously With Apple?Documento5 páginasin Strategic Management What Are The Problems With Maintaining A High Inventory As Experienced Previously With Apple?Priyanka MurthyAinda não há avaliações
- Technical Bulletin LXL: No. Subject Release DateDocumento8 páginasTechnical Bulletin LXL: No. Subject Release DateTrunggana AbdulAinda não há avaliações
- The Indonesia National Clean Development Mechanism Strategy StudyDocumento223 páginasThe Indonesia National Clean Development Mechanism Strategy StudyGedeBudiSuprayogaAinda não há avaliações
- RSA - Brand - Guidelines - 2019 2Documento79 páginasRSA - Brand - Guidelines - 2019 2Gigi's DelightAinda não há avaliações
- Space Hulk - WDDocumento262 páginasSpace Hulk - WDIgor Baranenko100% (1)
- Corrosion Fatigue Phenomena Learned From Failure AnalysisDocumento10 páginasCorrosion Fatigue Phenomena Learned From Failure AnalysisDavid Jose Velandia MunozAinda não há avaliações
- FM 2030Documento18 páginasFM 2030renaissancesamAinda não há avaliações
- Ron Kangas - IoanDocumento11 páginasRon Kangas - IoanBogdan SoptereanAinda não há avaliações
- GPS Spoofing (2002-2003)Documento8 páginasGPS Spoofing (2002-2003)Roger JohnstonAinda não há avaliações
- Presentation 11Documento14 páginasPresentation 11stellabrown535Ainda não há avaliações
- Washing Machine: Service ManualDocumento66 páginasWashing Machine: Service ManualFernando AlmeidaAinda não há avaliações
- Stress-Strain Modelfor Grade275 Reinforcingsteel With Cyclic LoadingDocumento9 páginasStress-Strain Modelfor Grade275 Reinforcingsteel With Cyclic LoadingRory Cristian Cordero RojoAinda não há avaliações
- ISO 9001 2015 AwarenessDocumento23 páginasISO 9001 2015 AwarenessSeni Oke0% (1)
- Roleplayer: The Accused Enchanted ItemsDocumento68 páginasRoleplayer: The Accused Enchanted ItemsBarbie Turic100% (1)
- Oracle Forms & Reports 12.2.1.2.0 - Create and Configure On The OEL 7Documento50 páginasOracle Forms & Reports 12.2.1.2.0 - Create and Configure On The OEL 7Mario Vilchis Esquivel100% (1)