Você também pode gostar
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- TW Ycm01265958803Documento62 páginasTW Ycm0126595880313239563Ainda não há avaliações
- Insulation Resistance TestDocumento7 páginasInsulation Resistance Testcarlos vidalAinda não há avaliações
- 7 ReferencesDocumento6 páginas7 Referencessuneerav17100% (1)
- 12 New Trends in ManagementDocumento18 páginas12 New Trends in ManagementSaqib IqbalAinda não há avaliações
- Implementing Product ManagementDocumento156 páginasImplementing Product ManagementJyoti MohantyAinda não há avaliações
- Jet RevisedDocumento8 páginasJet RevisedDharavGosaliaAinda não há avaliações
- Standards List July2019Documento8 páginasStandards List July2019Richard PAinda não há avaliações
- ResearchDocumento48 páginasResearchCai De JesusAinda não há avaliações
- Philadelphia University Faculty of Engineering and Technology Department of Mechanical EngineeringDocumento8 páginasPhiladelphia University Faculty of Engineering and Technology Department of Mechanical EngineeringTamer JafarAinda não há avaliações
- M & E Eyerusalem TesfayeDocumento12 páginasM & E Eyerusalem Tesfayeeyerusalem tesfayeAinda não há avaliações
- Update CV KhanDocumento2 páginasUpdate CV KhanqayyukhanAinda não há avaliações
- t-030f Spanish p35-48Documento4 páginast-030f Spanish p35-48Juan ContrerasAinda não há avaliações
- JURNALfidyaDocumento20 páginasJURNALfidyaIrma NasridaAinda não há avaliações
- Future Time ClausesDocumento7 páginasFuture Time ClausesAmanda RidhaAinda não há avaliações
- Final AnswersDocumento4 páginasFinal AnswersAnshul SinghAinda não há avaliações
- UN 9252-06 Part 1-UD-AU-000-EB-00020 PDFDocumento7 páginasUN 9252-06 Part 1-UD-AU-000-EB-00020 PDFManjeet SainiAinda não há avaliações
- Accountability Report Ba CharityDocumento24 páginasAccountability Report Ba CharityBintang sonda sitorus PaneAinda não há avaliações
- Jakob's Ten Usability Heuristics: Nielsen Norman GroupDocumento11 páginasJakob's Ten Usability Heuristics: Nielsen Norman GroupPiyush ChauhanAinda não há avaliações
- Katalog - Bengkel Print Indonesia PDFDocumento32 páginasKatalog - Bengkel Print Indonesia PDFJoko WaringinAinda não há avaliações
- Alenar R.J (Stem 11 - Heliotrope)Documento3 páginasAlenar R.J (Stem 11 - Heliotrope)REN ALEÑARAinda não há avaliações
- Control Charts For Lognormal DataDocumento7 páginasControl Charts For Lognormal Dataanjo0225Ainda não há avaliações
- Present Environment and Sustainable Development - Annual Review Report 2015Documento7 páginasPresent Environment and Sustainable Development - Annual Review Report 2015catalinlungeanu758Ainda não há avaliações
- NASA: 2202main COL Debris Boeing 030121Documento9 páginasNASA: 2202main COL Debris Boeing 030121NASAdocumentsAinda não há avaliações
- Adolescent InterviewDocumento9 páginasAdolescent Interviewapi-532448305Ainda não há avaliações
- Disaster Readiness Exam SpecificationsDocumento2 páginasDisaster Readiness Exam SpecificationsRICHARD CORTEZAinda não há avaliações
- 574-Article Text-1139-1-10-20170930Documento12 páginas574-Article Text-1139-1-10-20170930Jhufry GhanterAinda não há avaliações
- Boyut AnaliziDocumento65 páginasBoyut AnaliziHasan Kayhan KayadelenAinda não há avaliações
- Valve Type Trim Type CF XTDocumento1 páginaValve Type Trim Type CF XTAye KyweAinda não há avaliações
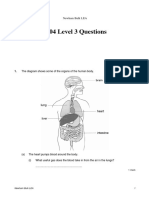
- 2004 Level 3 Questions: Newham Bulk LEADocumento18 páginas2004 Level 3 Questions: Newham Bulk LEAPatience NgundeAinda não há avaliações