Você também pode gostar
- Bigdata HadoopDocumento49 páginasBigdata Hadoopjagadeeswara71Ainda não há avaliações
- Ieee Inter SVM DT 07857480Documento5 páginasIeee Inter SVM DT 07857480jagadeeswara71Ainda não há avaliações
- Reference: Apache Hadoop: Hadoop: The Definitive Guide, by Tom White, 2 Edition, Oreilly's, 2010Documento57 páginasReference: Apache Hadoop: Hadoop: The Definitive Guide, by Tom White, 2 Edition, Oreilly's, 2010jagadeeswara71100% (1)
- HIVEDocumento56 páginasHIVEjagadeeswara71Ainda não há avaliações
- Blast FastaDocumento59 páginasBlast FastaSegun FatumoAinda não há avaliações
- ICIT Paper 349ELMtimeseriesClust2016Documento4 páginasICIT Paper 349ELMtimeseriesClust2016jagadeeswara71Ainda não há avaliações
- AJR ECG Mixture Bare Conf 14aug11Documento3 páginasAJR ECG Mixture Bare Conf 14aug11jagadeeswara71Ainda não há avaliações
- Big Data Analytics in Heart Attack Prediction 2167 1168 1000393Documento9 páginasBig Data Analytics in Heart Attack Prediction 2167 1168 1000393jagadeeswara71Ainda não há avaliações
- Dynamic programming solves edit distance efficientlyDocumento30 páginasDynamic programming solves edit distance efficientlyjagadeeswara71Ainda não há avaliações
- LATEX Forloop PDFDocumento2 páginasLATEX Forloop PDFjagadeeswara71Ainda não há avaliações
- Ieee Inter SVM DT 07857480Documento5 páginasIeee Inter SVM DT 07857480jagadeeswara71Ainda não há avaliações
- III B.Tech I Semester Regular Examinations, November 2008Documento7 páginasIII B.Tech I Semester Regular Examinations, November 2008jagadeeswara71Ainda não há avaliações
- Testing Object-Oriented Systems:: Dr. Magdy S. HannaDocumento42 páginasTesting Object-Oriented Systems:: Dr. Magdy S. Hannajagadeeswara71Ainda não há avaliações
- FIT JunitDocumento7 páginasFIT Junitjagadeeswara71Ainda não há avaliações
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (399)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (119)
- B767 WikipediaDocumento18 páginasB767 WikipediaxXxJaspiexXx100% (1)
- Glowing Stones in Ancient LoreDocumento16 páginasGlowing Stones in Ancient LorerippvannAinda não há avaliações
- Westbourne Baptist Church NW CalgaryDocumento4 páginasWestbourne Baptist Church NW CalgaryBonnie BaldwinAinda não há avaliações
- The Apostolic Church, Ghana English Assembly - Koforidua District Topic: Equipping The Saints For The MinistryDocumento2 páginasThe Apostolic Church, Ghana English Assembly - Koforidua District Topic: Equipping The Saints For The MinistryOfosu AnimAinda não há avaliações
- 5E Lesson PlanDocumento3 páginas5E Lesson PlanSangteablacky 09100% (8)
- Instafin LogbookDocumento4 páginasInstafin LogbookAnonymous gV9BmXXHAinda não há avaliações
- Mobile Services Tax Invoice for Dr Reddys LaboratoriesDocumento3 páginasMobile Services Tax Invoice for Dr Reddys LaboratoriesK Sree RamAinda não há avaliações
- 04 - JTC Template On Project ProposalDocumento10 páginas04 - JTC Template On Project Proposalbakelm alqamisAinda não há avaliações
- TAFJ-H2 InstallDocumento11 páginasTAFJ-H2 InstallMrCHANTHAAinda não há avaliações
- Polystylism in The Context of Postmodern Music. Alfred Schnittke's Concerti GrossiDocumento17 páginasPolystylism in The Context of Postmodern Music. Alfred Schnittke's Concerti Grossiwei wuAinda não há avaliações
- Analysis of Cocoyam Utilisation by Rural Households in Owerri West Local Government Area of Imo StateDocumento11 páginasAnalysis of Cocoyam Utilisation by Rural Households in Owerri West Local Government Area of Imo StatePORI ENTERPRISESAinda não há avaliações
- Anschutz Nautopilot 5000Documento4 páginasAnschutz Nautopilot 5000Văn Phú PhạmAinda não há avaliações
- GEA 1000 Tutorial 1 SolutionDocumento12 páginasGEA 1000 Tutorial 1 SolutionAudryn LeeAinda não há avaliações
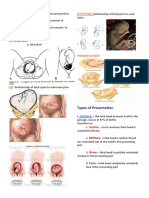
- The 4Ps of Labor: Passenger, Passageway, Powers, and PlacentaDocumento4 páginasThe 4Ps of Labor: Passenger, Passageway, Powers, and PlacentaMENDIETA, JACQUELINE V.Ainda não há avaliações
- All EscortsDocumento8 páginasAll Escortsvicky19937Ainda não há avaliações
- I CEV20052 Structureofthe Food Service IndustryDocumento98 páginasI CEV20052 Structureofthe Food Service IndustryJowee TigasAinda não há avaliações
- The Avengers (2012 Film)Documento4 páginasThe Avengers (2012 Film)Matthew SusetioAinda não há avaliações
- Financial Management-Capital BudgetingDocumento39 páginasFinancial Management-Capital BudgetingParamjit Sharma100% (53)
- Strategies in Various Speech SituationsDocumento6 páginasStrategies in Various Speech SituationsSky NayytAinda não há avaliações
- Eng 188 Change in Ap, Ae, and ErrorsDocumento5 páginasEng 188 Change in Ap, Ae, and Errorsmkrisnaharq99Ainda não há avaliações
- Bullish EngulfingDocumento2 páginasBullish EngulfingHammad SaeediAinda não há avaliações
- 2020 Non Student Candidates For PCL BoardDocumento13 páginas2020 Non Student Candidates For PCL BoardPeoples College of LawAinda não há avaliações
- Script - TEST 5 (1st Mid-Term)Documento2 páginasScript - TEST 5 (1st Mid-Term)Thu PhạmAinda não há avaliações
- Rebekah Hoeger ResumeDocumento1 páginaRebekah Hoeger ResumerebekahhoegerAinda não há avaliações
- Visual AnalysisDocumento4 páginasVisual Analysisapi-35602981850% (2)
- Lumafusion Shortcuts LandscapeDocumento2 páginasLumafusion Shortcuts Landscapepocho clashAinda não há avaliações
- Training Plan JDVP 2020 - BPP (40days)Documento36 páginasTraining Plan JDVP 2020 - BPP (40days)Shallimar Alcarion100% (1)
- Segmenting, Targeting, and Positioning (STP)Documento16 páginasSegmenting, Targeting, and Positioning (STP)Rachmat PutraAinda não há avaliações
- Chippernac: Vacuum Snout Attachment (Part Number 1901113)Documento2 páginasChippernac: Vacuum Snout Attachment (Part Number 1901113)GeorgeAinda não há avaliações
- Foundations of Public Policy AnalysisDocumento20 páginasFoundations of Public Policy AnalysisSimran100% (1)