Escolar Documentos
Profissional Documentos
Cultura Documentos
NIC BR - Curso de IPv6 Básico
Enviado por
luluzinha08Título original
Direitos autorais
Formatos disponíveis
Compartilhar este documento
Compartilhar ou incorporar documento
Você considera este documento útil?
Este conteúdo é inapropriado?
Denunciar este documentoDireitos autorais:
Formatos disponíveis
NIC BR - Curso de IPv6 Básico
Enviado por
luluzinha08Direitos autorais:
Formatos disponíveis
2
CURSO IPv6 BSICO
Rodrigo Regis dos Santos
Antnio M. Moreiras
Ailton Soares da Rocha
Ncleo de Informao e Coordenao do ponto BR
So Paulo
2010
3
Santos, Rodrigo Regis dos
Curso de IPv6 bsico / Rodrigo Regis dos
Santos, Antonio Marcos Moreiras, Ailton Soares
da Rocha. -- 1. ed. -- So Paulo : Comit Gestor
da Internet no Brasil, 2009.
1. Sistemas de comunicao sem fio - Inovaes
tecnolgicas 2. Telecomunicao 3. Telefones
I. Moreiras, Antonio Marcos. II. Rocha, Ailton
Soares da. III. Ttulo.
09-06849 CDD-621
NcIeo de Informao e Coordenao do Ponto BR
Diretor Presidente
Demi Getschko
Diretor Administrativo
Hartmut Richard Glaser
Diretor de Servios
Frederico Neves
Diretor de Projetos Especiais e de DesenvoIvimento
Milton Kaoru Kashowakura
Centro de Estudos e Pesquisas em TecnoIogia de Redes e Operaes - CEPTRO.br
Antnio Marcos Moreiras
Coordenao Executiva e EditoriaI: Antnio Marcos Moreiras
Autores / Design / Diagramao
Rodrigo Regis dos Santos
Antnio Marcos Moreiras
Ailton Soares da Rocha
Dados Internacionais de Catalogao na Publicao (CIP)
(Cmara Brasileira do Livro, SP, Brasil)
ndices para catlogo sistemtico:
1. Telefonia e Protocolo IPv6 : Telecomunicaes
621
4
Sobre o Projeto IPv6.br
O Pv6 a nova gerao do Protocolo nternet.
Ele j vem sendo utilizado h algum tempo. Mas agora sua implantao deve ser
acelerada. Ela imprescindvel para a continuidade do crescimento e da evoluo da
nternet!
O objetivo do projeto Pv6.br do NC.br estimular a utilizao do novo protocolo na
nternet e nas redes brasileiras. Para saber mais acesse o stio nternet www.ipv6.br ou
entre em contato pelo e-mail ipv6@nic.br.
O CEPTRO.br- Centro de Estudos e Pesquisas em Tecnologia de Redes e Operaes
do NC.br responsvel por projetos que visam melhorar a qualidade da nternet no
Brasil e disseminar seu uso, com especial ateno para seus aspectos tcnicos e de
infraestrutura. Mais informaes podem ser obtidas no stio nternet www.ceptro.br.
Sobre os autores
Rodrigo Regis dos Santos formado em Cincia da Computao pela Universidade
Presbiteriana Mackenzie e atualmente Analista de Projetos no NC.br. Rodrigo
especialista em Pv6 e um dos responsveis pelo projeto Pv6.br, que tem por objetivo
incentivar o uso do protocolo no pas.
Antnio M. Moreiras atua no NC.br na coordenao de projetos relacionados
infraestrutura da nternet e a seu desenvolvimento no Brasil. Est envolvido atualmente
com a disseminao do Pv6 no Brasil, distribuio da Hora Legal via NTP, medies da
qualidade da nternet no Brasil e estudos da Web brasileira. Engenheiro eletricista e
mestre em engenharia pela POL/USP, com MBA em Gesto Empresarial pela
FACC/UFRJ e atualmente est especializando-se em Governana da nternet na Diplo
Foundation.
AiIton Soares da Rocha Analista de Projetos no NC.br, onde est envolvido com
pesquisas e projetos relacionados infraestrutura da nternet no pas, com importante
atuao nos projetos Pv6.br e NTP.br. Engenheiro eletricista e de telecomunicaes
graduado pelo NATEL, atuou por mais de 10 anos na coordenao da rea de redes e
nternet da instituio.
5
Sobre a Iicena
Para cada novo uso ou distribuio, voc deve deixar claro para outros os termos da licena desta obra.
No caso de criao de obras derivadas, os logotipos do CG.br, NC.br, Pv6.br e CEPTRO.br no devem ser utilizados.
Na atribuio de autoria, essa obra deve ser citada da seguinte forma:
Apostila Curso Pv6 bsico do NC.br, disponvel no stio http://curso.ipv6.br ou atravs do e-mail ipv6@nic.br.
Qualquer uma destas condies podem ser renunciadas, desde que voc obtenha permisso do autor.
Se necessrio, o NC.br pode ser consultado atravs do email ipv6@nic.br.
Nada nesta licena prejudica ou restringe os direitos morais do autor.
6
6
7
Neste modulo de introduo, iniciaremos conhecendo um pouco da historia da Internet e do
desenvolvimento do protocolo IP.
Entenderemos quais os problemas causados pela Iorma adotada inicialmente para
distribuio dos endereos IP e pelo rapido crescimento da Internet, e quais as solues adotadas
para resolver esses problemas. Seguindo este historico, veremos como algumas dessas solues
evoluiram at se chegar a deIinio da verso 6 do protocolo IP, o IPv6.
Tambm veremos neste modulo, atravs de dados estatisticos, a real necessidade da
implantao do IPv6 nas redes de computadores, conIrontando dados sobre o ritmo de crescimento
da Internet e sobre a adoo e utilizao do IPv6. Tambm sero discutidas as consequncias da
no implantao do novo protocolo IP e da larga utilizao de tcnicas tidas como paliativas,
como por exemplo as NATs.
7
Introduo
MduIo 1
8
O Departamento de DeIesa (DoD - Department of Defense) do governo estadunidense
iniciou em 1966, atravs de sua Agencia de Pesquisas e de Projetos Avanados (ARPA - Aavancea
Research Profects Agency), um projeto para a interligao de computadores em centros militares e
de pesquisa. Este sistema de comunicao e controle distribuido com Iins militares recebeu o
nome de ARPANET, tendo como principal objetivo teorico Iormar uma arquitetura de rede solida
e robusta que pudesse, mesmo com a queda de alguma estao, trabalhar com os computadores e
ligaes de comunicao restantes. Em 1969, so instalados os primeiros quatro nos da rede, na
Universidade de Los Angeles (UCLA), na Universidade da CaliIornia em Santa Barbara (UCSB),
no Instituto de Pesquisas de StandIord (SRI) e na Universidade de Utah.
No inicio, a ARPANET trabalhava com diversos protocolos de comunicao, sendo o
principal o NCP (Network Control Protocol). No entanto, em 1/1/1983, quando a rede ja possuia
562 hosts, todas as maquinas da ARPANET passaram a adotar como padro os protocolos TCP/IP,
permitindo o crescimento ordenado da rede e eliminando restries dos protocolos anteriores.
DeIinido na RFC 791, o protocolo IP possui duas Iunes basicas: a Iragmentao, que
permite o envio de pacotes maiores que o limite de traIego estabelecido de um enlace, dividindo-
os em partes menores; e o endereamento, que permite identiIicar o destino e a origem dos pacotes
a partir do endereo armazenado no cabealho do protocolo. A verso do protocolo IP utilizada na
poca e atualmente a verso 4 ou IPv4. Ela mostrou-se muito robusta, e de Iacil implantao e
interoperabilidade, entretanto, seu projeto original no previu alguns aspectos como:
O crescimento das redes e um possivel esgotamento dos endereos IP;
O aumento da tabela de roteamento;
Problemas relacionados a segurana dos dados transmitidos;
Prioridade na entrega de determinados tipos de pacotes.
8
1969 ncio da ARPANET
1981 Definio do Pv4 na RFC 791
1983 ARPANET adota o TCP/P
1990 Primeiros estudos sobre o esgotamento
dos endereos
1993 nternet passa a ser explorada
comercialmente
ntensifica-se a discusso sobre o possvel
esgotamento dos endereos livres e do aumento da
tabela de roteamento.
A Internet e o TCP/IP
9
As especiIicaes do IPv4 reservam 32 bits para endereamento, possibilitando gerar mais
de 4 bilhes de endereos distintos. Inicialmente, estes endereos Ioram divididos em trs classes
de tamanhos Iixos da seguinte Iorma:
Classe A: deIinia o bit mais signiIicativo como 0, utilizava os 7 bits restantes do
primeiro octeto para identiIicar a rede, e os 24 bits restantes para identiIicar o host.
Esses endereos utilizavam a Iaixa de 1.0.0.0 at 126.0.0.0;
Classe B: deIinia os 2 bits mais signiIicativo como 10, utilizava os 14 bits seguintes
para identiIicar a rede, e os 16 bits restantes para identiIicar o host. Esses endereos
utilizavam a Iaixa de 128.1.0.0 at 191.254.0.0;
Classe C: deIinia os 3 bits mais signiIicativo como 110, utilizava os 21 bits seguintes
para identiIicar a rede, e os 8 bits restantes para identiIicar o host. Esses endereos
utilizavam a Iaixa de 192.0.1.0 at 223.255.254.0;
Embora o intuito dessa diviso tenha sido tornar a distribuio de endereos mais
Ilexivel, abrangendo redes de tamanhos variados, esse tipo de classiIicao mostrou-se
ineIiciente. Desta Iorma, a classe A atenderia um numero muito pequeno de redes, mas
ocupava metade de todos os endereos disponiveis; para enderear 300 dispositivos em
uma rede, seria necessario obter um bloco de endereos da classe B, desperdiando
assim quase o total dos 65 mil endereos; e os 256 endereos da classe C no supriam
as necessidades da grande maioria das redes.
CIasse Formato Redes Hosts
A 7 Bits Rede, 24 Bits Host 128 16.777.216
B 14 Bits Rede, 16 Bits Host 16.384 65.536
C 21 Bits Rede, 8 Bits Host 2.562.097.152 256
9
Esgotamento dos endereos
IPv4
Pv4 = 4.294.967.296 endereos.
Poltica inicial de distribuio de endereos.
Classe A
BM
HP
AT&T
MT
Classe B
Classe C
Endereos reservados
DoD
US Army
USPS
........
10
Outro Iator que colaborava com o desperdicio de endereos, era o Iato de que dezenas de
Iaixas classe A Ioram atribuidas integralmente a grandes instituies como IBM, AT&T, Xerox,
HP, Apple, MIT, Ford, Departamento de DeIesa Americano, entre muitas outras, disponibilizando
para cada uma 16.777.216 milhes de endereos. Alm disso, 35 Iaixas de endereos classe A
Ioram reservadas para usos especiIicos como multicast, loopback e uso Iuturo.
Em 1990, ja existiam 313.000 hosts conectados a rede e estudos ja apontavam para um
colapso devido a Ialta de endereos. Outros problemas tambm tornavam-se mais eIetivos
conIorme a Internet evoluia, como o aumento da tabela de roteamento.
Devido ao ritmo de crescimento da Internet e da politica de distribuio de endereos, em
maio de 1992, 38 das Iaixas de endereos classe A, 43 da classe B e 2 da classe C, ja
estavam alocados. Nesta poca, a rede ja possuia 1.136.000 hosts conectados.
Em 1993, com a criao do protocolo HTTP e a liberao por parte do Governo
estadunidense para a utilizao comercial da Internet, houve um salto ainda maior na taxa de
crescimento da rede, que passou de 2.056.000 de hosts em 1993 para mais de 26.000.000 de hosts
em 1997.
Mais inIormaes:
RFC 1287 - Towaras the Future Internet Architecture.
RFC 1296 - Internet Growth (1981-1991)
Solensky F., Continuea Internet Growth`, Proceeaings of the 18th Internet Engineering Task
Force, Agosto 1990, http://www.ietI.org/proceedings/prior29/IETF18.pdI
IANA IPv4 Aaaress Space Registry -
http://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xml
RFC 3330 - Special-Use IPv4 Aaaresses.
Data Hosts Domnios
1981 213 -
1982 235 -
1983 562 -
1984 1.024 -
1985 1.961 -
1986 5.089 -
1987 28.174 -
1988 56.000 1.280
1989 159.000 4.800
1990 313.000 9.300
1991 617.000 18.000
1992 1.136.000 17.000
1993 2.056.000 26.000
1994 3.212.000 46.000
1995 8.200.000 120.000
1996 16.729.000 488.000
1997 26.053.000 1.301.000
Tabela de crescimento da nternet.
11
11
Esgotamento dos endereos
IPv4
Esta imagem mostra uma visualizao das inIormaes da tabela de roteamento BGP
extraida do projeto Routeviews. Nela, o espao de endereo IPv4 unidimensional mapeado em
uma imagem de bidimensional, onde blocos CIDR sempre aparecem como quadrados ou
retngulos.
Mais inIormaes:
http://maps.measurement-Iactory.com/
12
Diante desse cenario, a IETF (Internet Engineering Task Force) passa a discutir estratgias
para solucionar a questo do esgotamento dos endereos IP e o problema do aumento da tabela de
roteamento. Para isso, em novembro de 1991, Iormado o grupo de trabalho ROAD (ROuting ana
Aaaressing), que apresenta como soluo a estes problemas a utilizao do CIDR (Classless Inter-
aomain Routing).
DeIinido na RFC 4632 (tornou obsoleta a RFC 1519), o CIDR tem como idia basica o Iim
do uso de classes de endereos, permitindo a alocao de blocos de tamanho apropriado a real
necessidade de cada rede; e a agregao de rotas, reduzindo o tamanho da tabela de roteamento.
Com o CIDR os blocos so reIerenciados como preIixo de redes. Por exemplo, no endereo
a.b.c.d/x, os x bits mais signiIicativos indicam o preIixo da rede. Outra Iorma de indicar o preIixo
atravs de mascaras, onde a mascara 255.0.0.0 indica um preIixo /8, 255.255.0.0 indica um /16, e
assim sucessivamente.
Outra soluo, apresentada na RFC 2131 (tornou obsoleta a RFC 1541), Ioi o protocolo
DHCP (Dynamic Host Configuration Protocol). Atravs do DHCP um host capaz de obter um
endereo IP automaticamente e adquirir inIormaes adicionais como mascara de sub-rede,
endereo do roteador padro e o endereo do servidor DNS local.
O DHCP tem sido muito utilizado por parte dos ISPs por permitir a atribuio de endereos
IP temporarios a seus clientes conectados. Desta Iorma, torna-se desnecessario obter um endereo
para cada cliente, devendo-se apenas designar endereos dinamicamente, atravs de seu servidor
DHCP. Este servidor tera uma lista de endereos IP disponiveis, e toda vez que um novo cliente se
conectar a rede, lhe sera designado um desses endereo de Iorma arbitraria, e no momento que o
cliente se desconecta, o endereo devolvido.
12
SoIues paIiativas:
1992 - ETF cria o grupo ROAD (ROuting and ADdressing).
CDR (RFC 4632)
Fim do uso de classes = blocos de tamanho apropriado.
Endereo de rede = prefixo/comprimento.
Agregao das rotas = reduz o tamanho da tabela de rotas.
DHCP
Alocaes dinmicas de endereos.
NAT + RFC 1918
Permite conectar toda uma rede de computadores usando
apenas um endereo vlido na nternet, porm com vrias
restries.
SoIues
13
A NAT (Network Aaaress Translation), Ioi outra tcnica paliativa desenvolvida para
resolver o problema do esgotamento dos endereos IPv4. DeIinida na RFC 3022 (tornou obsoleta
a RFC 1631), tem como idia basica permitir que, com um unico endereo IP, ou um pequeno
numero deles, varios hosts possam traIegar na Internet. Dentro de uma rede, cada computador
recebe um endereo IP privado unico, que utilizado para o roteamento do traIego interno. No
entanto, quando um pacote precisa ser roteado para Iora da rede, uma traduo de endereo
realizada, convertendo endereos IP privados em endereos IP publicos globalmente unicos.
Para tornar possivel este esquema, utiliza-se os trs intervalos de endereos IP declarados
como privados na RFC 1918, sendo que a unica regra de utilizao, que nenhum pacote
contendo estes endereos pode traIegar na Internet publica. As trs Iaixas reservadas so:
A utilizao da NAT mostrou-se eIiciente no que diz respeito a economia de endereos IP,
alm de apresentar alguns outros aspectos positivos, como Iacilitar a numerao interna das redes,
ocultar a topologia das redes e so permitir a entrada de pacotes gerados em resposta a um pedido
da rede. No entanto, o uso da NAT apresenta inconvenientes que no compensam as vantagens
oIerecidas.
A NAT quebra o modelo Iim-a-Iim da Internet, no permitindo conexes diretas entre dois
hosts, o que diIiculta o Iuncionamento de uma srie de aplicaes, como P2P, VoIP e VPNs.
Outro problema a baixa escalabilidade, pois o numero de conexes simultneas limitado, alm
de exigir um grande poder de processamento do dispositivo tradutor. O uso da NAT tambm
impossibilita rastrear o caminho de pacote, atravs de Ierramentas como traceroute, por exemplo,
e diIiculta a utilizao de algumas tcnicas de segurana como IPSec. Alm disso, seu uso passa
uma Ialsa sensao de segurana, pois, apesar de no permitir a entrada de pacotes no
autorizados, a NAT no realiza nenhum tipo de Iiltragem ou veriIicao nos pacotes que passa por
ela.
13
NAT
Vantagens:
Reduz a necessidade de endereos pblicos;
Facilita a numerao interna das redes;
Oculta a topologia das redes;
S permite a entrada de pacotes gerado em resposta a um pedido
da rede.
Desvantagens:
Quebra o modelo fim-a-fim da nternet;
Dificulta o funcionamento de uma srie de aplicaes;
No escalvel;
Aumento do processamento no dispositivo tradutor;
Falsa sensao de segurana;
mpossibilidade de se rastrear o caminho do pacote;
mpossibilita a utilizao de algumas tcnicas de segurana como
PSec.
SoIues
10.0.0.0 a 10.255.255.255 /8 (16.777.216 hosts)
172.16.0.0 a 172.31.255.255 /12 (1.048.576 hosts)
192.168.0.0 a 192.168.255.255 /16 (65.536 hosts)
14
Embora estas solues tenham diminuido a demanda por IPs, elas no Ioram suIicientes
para resolver os problemas decorrentes do crescimento da Internet. A adoo dessas tcnicas
reduziu em apenas 14 a quantidade de blocos de endereos solicitados a IANA e a curva de
crescimento da Internet continuava apresentando um aumento exponencial.
Essas medidas, na verdade, serviram para que houvesse mais tempo para se desenvolver
uma nova verso do IP, que Iosse baseada nos principios que Iizeram o sucesso do IPv4, porm,
que Iosse capaz de suprir as Ialhas apresentadas por ele.
Mais inIormaes:
RFC 1380 - IESG Deliberations on Routing ana Aaaressing
RFC 1918 - Aaaress Allocation for Private Internets
RFC 2131 - Dynamic Host Configuration Protocol
RFC 2775 - Internet Transparency
RFC 2993 - Architectural Implications of NAT
RFC 3022 - Traaitional IP Network Aaaress Translator (Traaitional NAT)
RFC 3027 - Protocol Complications with the IP Network Aaaress Translator
RFC 4632 - Classless Inter-aomain Routing (CIDR). The Internet Aaaress Assignment ana
Aggregation Plan.
14
SoIues paIiativas: Queda de apenas 14%
SoIues
15
Deste modo, em dezembro de 1993 a IETF Iormalizou, atravs da RFC 1550, as pesquisas a
respeito da nova verso do protocolo IP, solicitando o envio de projetos e propostas para o novo
protocolo. Esta Ioi umas das primeiras aes do grupo de trabalho da IETF denominado Internet
Protocol next generation (IPng). As principais questes que deveriam ser abordadas na elaborao
da proxima verso do protocolo IP Ioram:
Escalabilidade;
Segurana;
ConIigurao e administrao de rede;
Suporte a QoS;
Mobilidade;
Politicas de roteamento;
Transio.
15
Estas medidas geraram mais tempo para desenvolver uma nova
verso do P.
1992 - ETF cria o grupo Png (P Next Generation)
Principais questes:
Escalabilidade;
Segurana;
Configurao e administrao de rede;
Suporte a QoS;
Mobilidade;
Polticas de roteamento;
Transio.
SoIues
16
Diversos projetos comearam a estudar os eIeitos do crescimento da Internet, sendo os
principais o CNAT, o IP Encaps, o Nimroa e o Simple CLNP. Destas propostas surgiram o TCP
and UDP with Bigger Aaaresses (TUBA), que Ioi uma evoluo do Simple CLNP, e o IP Aaaress
Encapsulation (IPAE), uma evoluo do IP Encaps. Alguns meses depois Ioram apresentados os
projetos Pauls Internet Protocol (PIP), o Simple Internet Protocol (SIP) e o TP/IX. Uma nova
verso do SIP, que englobava algumas Iuncionalidades do IPAE, Ioi apresentada pouco antes de
agregar-se ao PIP, resultando no Simple Internet Protocol Plus (SIPP). No mesmo periodo, o
TP/IX mudou seu nome para Common Architecture for the Internet (CATNIP).
Em janeiro de 1995, na RFC 1752 o IPng apresentou um resumo das avaliaes das trs
principais propostas:
CANTIP - Ioi concebido como um protocolo de convergncia, para permitir a
qualquer protocolo da camada de transporte ser executado sobre qualquer protocolo de
camada de rede, criando um ambiente comum entre os protocolos da Internet, OSI e
Novell;
TUBA - sua proposta era de aumentar o espao para endereamento do IPv4 e torna-lo
mais hierarquico, buscando evitar a necessidade de se alterar os protocolos da camada
de transporte e aplicao. Pretendia uma migrao simples e em longo prazo, baseada
na atualizao dos host e servidores DNS, entretanto, sem a necessidade de
encapsulamento ou traduo de pacotes, ou mapeamento de endereos;
SIPP - concebido para ser uma etapa evolutiva do IPv4, sem mudanas radicais e
mantendo a interoperabilidade com a verso 4 do protocolo IP, Iornecia uma
plataIorma para novas Iuncionalidades da Internet, aumentava o espao para
endereamento de 32 bits para 64 bits, apresentava um nivel maior de hierarquia e era
composto por um mecanismo que permitia 'alargar o endereo chamado cluster
aaaresses. Ja possuia cabealhos de extenso e um campo flow para identiIicar o tipo
de Iluxo de cada pacote.
16
SoIuo definitiva:
SoIues
17
Entretanto, conIorme relatado tambm na RFC 1752, todas as trs propostas apresentavam
problemas signiIicativos. Deste modo, a recomendao Iinal para o novo Protocolo Internet
baseou-se em uma verso revisada do SIPP, que passou a incorporar endereos de 128 bits,
juntamente com os elementos de transio e autoconIigurao do TUBA, o endereamento
baseado no CIDR e os cabealhos de extenso. O CATNIP, por ser considerado muito
incompleto, Ioi descartado.
Apos esta deIinio, a nova verso do Protocolo Internet passou a ser chamado
oIicialmente de IPv6.
Mais inIormaes:
RFC 1550 - IP. Next Generation (IPng) White Paper Solicitation
RFC 1752 - The Recommenaation for the IP Next Generation Protocol
18
As especiIicaes da IPv6 Ioram apresentadas inicialmente na RFC 1883 de dezembro de
1995, no entanto, em em dezembro de 1998, esta RFC Ioi substituida pela RFC 2460. Como
principais mudanas em relao ao IPv4 destacam-se:
Maior capacidade para endereamento: no IPv6 o espao para endereamento aumentou
de 32 bits para 128 bits, permitindo: niveis mais especiIicos de agregao de endereos;
identiIicar uma quantidade muito maior de dispositivos na rede; e implementar mecanismos
de autoconIigurao. A escalabilidade do roteamento multicast tambm Ioi melhorada
atravs da adio do campo "escopo" no endereo multicast. E um novo tipo de endereo, o
anycast, Ioi deIinido;
Simplificao do formato do cabealho: alguns campos do cabealho IPv4 Ioram
removidos ou tornaram-se opcionais, com o intuito de reduzir o custo do processamento dos
pacotes nos roteadores;
Suporte a cabealhos de extenso: as opes no Iazem mais parte do cabealho base,
permitindo um roteamento mais eIicaz, limites menos rigorosos em relao ao tamanho e a
quantidade de opes, e uma maior Ilexibilidade para a introduo de novas opes no
Iuturo;
Capacidade de identificar fluxos de dados: Ioi adicionado um novo recurso que permite
identiIicar de pacotes que pertenam a determinados traIegos de Iluxos, para os quais podem
ser requeridos tratamentos especiais;
Suporte a autenticao e privacidade: Ioram especiIicados cabealhos de extenso
capazes de Iornecer mecanismos de autenticao e garantir a integridade e a
conIidencialidade dos dados transmitidos.
18
1998 - Definido pela RFC 2460
128 bits para endereamento.
Cabealho base simplificado.
Cabealhos de extenso.
dentificao de fluxo de dados (QoS).
Mecanismos de PSec incorporados ao protocolo.
Realiza a fragmentao e remontagem dos pacotes apenas na
origem e no destino.
No requer o uso de NAT, permitindo conexes fim-a-fim.
Mecanismos que facilitam a configurao de redes.
....
IPv6
19
Alm disso, o IPv6 tambm apresentou mudanas no tratamento da Iragmentao dos
pacotes, que passou a ser realizada apenas na origem; permite o uso de conexes Iim-a-Iim,
principio que havia sido quebrado com o IPv4 devido a grande utilizao de NAT; trouxe recursos
que Iacilitam a conIigurao de redes, alm de outros aspectos que Ioram melhorados em relao
ao IPv4.
Mais inIormaes:
RFC 2460 - Internet Protocol, Jersion 6 (IPv6) Specification
20
Durante os ultimos dez anos, durante o desenvolvimento do IPv6, a Internet continuou
apresentando um ritmo de crescimento cada vez mais acelerado. O numero de hosts conectados a
Internet saltou de 30.000.000 para aproximadamente 732.000.000 nos dias de hoje, com um
numero cada vez maior de usuarios e dispositivos conectados a Rede.
20
Por que utiIizar IPv6 hoje?
A nternet continua crescendo
Quantidade de hosts na Internet
21
Esta expanso da Internet pode ser medida por diversos Iatores, e inumeras pesquisas tm
mostrado que este crescimento no ocorre de Iorma isolada.
Estima-se que existam no mundo 1.733.993.741 usuarios de Internet, ou 25,6 da
populao da Terra, o que representa, considerando os ultimos nove anos, um crescimento de
380,3. Mantendo este ritmo de crescimento, dentro de dois anos sero dois bilhes de usuarios,
superando a previso de que este numero so seria alcanado em 2015. A tabela a seguir detalha
esses numeros, apresentando a penetrao e o crescimento da Internet em cada regio do mundo.
Segundo dados da ABI Research a quantidade de equipamentos moveis capazes de
acessarem a Internet, como celulares, smartphones, netbooks e modens 3G, deve chegar a 2,25
bilhes de aparelhos.
Regies
Populao
(em 29)
Usurios de
Internet
(em 2)
Usurios de
Internet
(atualmente)
" por
Regio
" no
mundo
Crescimento
2-29
Africa 991.002.342 4.514.400 67.371.700 6,8 3,9 1.392,4
Asia 3.808.070.503 114.304.000 728.257.230 19,4 42,6 545,9
Europa 803.850.858 105.096.093 418.029.796 52,0 24,1 297,8
Oriente
Meaio
202.687.005 3.284.800 57.425.046 28,3 3,3 1.648,2
America
Norte
340.831.831 108.096.800 252.908.000 74,2 14,6 134,0
America
Latina
/Caribe
586.662.468 18.068.919 179.031.479 30,5 10,3 890,8
Oceania 34.700.201 7.620.480 20.970.419 60,4 1,2 175,2
TOTAL 6.767.805.208 360.985.492 1.733.993.741 25,6 100 380,3
21
Por que utiIizar IPv6 hoje?
A nternet continua crescendo
Mundo
1.733.993.741 usurios de nternet;
25,6% da populao;
Crescimento de 380,3% nos ltimos 9 anos.
Em 2014, soma de celulares, smartphones, netbooks e modens
3G deve chegar a 2,25 bilhes de aparelhos.
Brasil
21% de domiclios com acesso nternet;
2,6 milhes de conexes em banda larga mvel;
11 milhes de conexes em banda larga fixa.
Dados de 15/01/2010.
22
Seguindo esta tendncia, no Brasil o percentual de domicilios com acesso a Internet,
via computadores domsticos, aumentou de 11, no segundo semestre de 2005, para os atuais
21. O Brasil tambm alcanou, em Junho de 2009, a marca de 2,6 milhes de conexes em
banda larga movel, crescendo 34,2 em um semestre. Ja o numero de conexes atravs de banda
larga Iixa alcanam o total de 11 milhes.
23
Como conseqncia deste crescimento, a demanda por endereos IP tambm cresce
consideravelmente. Em 2010, 6 blocos /8 ja Ioram atribuidos pela IANA aos RIRs, restando, no
momento, 20 blocos no-alocados dos 256 /8 possiveis, ou seja, 7,81 do total. Este indice,
reIora a projeo para 2011 como data para o esgotamento de seus blocos de endereos IPv4,
principalmente porque o numero de solicitaes de blocos de endereos aumenta a cada ano.
Em setembro de 2008, os RIRs chegaram a um acordo quanto a politica que sera adotada
pela IANA quando sua reserva de endereos atingir o limite de 5 blocos /8. Estes ultimos /8 sero
imediatamente atribuidos a cada RIR, que os atribuiro entre os ISPs e Registros Nacionais. Caso
o estoque da IANA ocorra em 2011 como previsto, o numero de endereos IPv4 disponiveis so se
esgotara quando as reservas regionais terminarem, o que podera ocorrer dois ou trs anos apos o
Iim das reservas da IANA.
23
Por que utiIizar IPv6 hoje?
Com isso, a demanda por endereos Pv4 tambm cresce:
Em 2010 j foram atribudos 6 blocos /8 aos RRs;
Restam apenas 20 blocos /8 livres na ANA, equivalente a 7,81% do total;
Previses atuais apontam para um esgotamento desses blocos em 2011;
O estoque dos RRs deve durar 2 ou 3 anos a mais.
Embora a nternet seja conhecida por ser uma rede mundial livre de uma coordenao central, existem rgos
responsveis por administrar os principais aspectos tcnicos necessrios ao seu funcionamento. As atribuies desses
rgos so distribudas em nvel mundial, respeitando uma estrutura hierrquica:
A Internet Assigned Numbers Authority (IANA) a responsvel pela coordenao e alocao global do espao de
endereos P e dos ASNs. Desde 1998, a ANA passou a operar atravs da Internet Corporation for Assigned Names and
Numbers (ICANN), uma organizao internacional dirigida por um conselho de diretores, provenientes de diversos
pases, que supervisiona a CANN e as polticas elaboradas por ela, trabalhando em parceria com governos, empresas e
organizaes criadas por tratados internacionais, envolvidos na construo e manuteno da nternet.
A responsabilidade pela distribuio local dos endereos P dos Registros de nternet (Internet Registry - IR),
que so classificados de acordo com sua funo principal e alcance territorial dentro da estrutura hierrquica da nternet.
Os Registros Regionais de nternet (Regional Internet Registries - RIR) so rgos, reconhecidos pela ANA, que
atuam e representam grandes regies geogrficas. A funo primordial de um RR gerenciar e distribuir endereos P
pblicos dentro de suas respectivas regies. Existem cinco RRs: o African Network Information Centre (AfriNIC), que
atua na regio da frica; o Asia-Pacific Network Information Centre (APINIC), atuando na sia e na regio do Pacfico; o
American Registry for Internet Numbers (ARIN), responsvel pela Amrica do Norte; o Latin American and Caribbean
Internet Addresses Registry (LACNIC), que atua na Amrica Latina e em algumas ilhas do Caribe; e o Rseaux IP
Europens Network Coordination Centre (RIPE NCC), que serve a Europa e pases da sia Central.
Um Registro Nacional de nternet (National Internet Registry - NIR) o responsvel pela alocao dos endereos
P em nvel nacional, distribuindo-os aos Registros Locais de nternet (Local Internet Registry - LIR). Os LRs so
geralmente SPs, que por sua vez podem oferecer estes endereos aos usurios finais ou outros SPs.
No Brasil, o NR responsvel pela distribuio de endereos P e do registro de nomes de domnios usando .br
o Ncleo de nformao e Coordenao do ponto br (NIC.br).
24
24
Por que utiIizar IPv6 hoje?
Evoluo do estoque de blocos P na ANA.
Projeo
Este graIico apresenta a evoluo do estoque de blocos IP na IANA ao longo dos ultimos
anos, alm de uma projeo dos proximos dois anos.
25
Este graIico apresenta a quantidade de blocos /8 IPv4 alocados anualmente pelos RIRs.
Mais inIormaes:
http://www.internetworldstats.com/stats.htm
http://cetic.br/usuarios/ibope/tab02-04.htm
http://www.cisco.com/web/BR/barometro/barometro.html
https://www.isc.org/solutions/survey
http://www.nro.net/statistics
http://www.abiresearch.com
25
Por que utiIizar IPv6 hoje?
Quantidade de blocos (/8) Pv4 alocados anualmente pelos RRs.
26
Embora todos os numeros conIirmem a necessidade mais endereos IP, questo essa que
prontamente resolvida com a adoo do IPv6, o ritmo de implantao da nova verso do protocolo
IP no esta ocorrendo da Iorma que Ioi prevista no inicio de seu desenvolvimento, que apontava o
IPv6 como protocolo padro da Internet aproximadamente dez anos apos sua deIinio, ou seja, se
isso realmente tivesse ocorrido, o objetivo desse curso provavelmente seria outro.
26
Como est a impIantao do
IPv6?
A previso inicial era que fosse assim:
27
Ainda ha muitos debates em torno da implantao do IPv6 e alguns Iatores tm atrasado a
implantao do novo protocolo.
Tcnicas como NAT e o DHCP, apesar de dar-nos tempo para desenvolver o IPv6,
colaboraram para a demora em sua adoo. Aliado a isso, ha o Iato de o IPv4 no apresentar
graves problemas de Iuncionamento.
Tambm preciso destacar que at o momento, a utilizao do IPv6 esta ligada
principalmente a area acadmica, e para que a Internet passe a utilizar IPv6 em grande escala,
necessario que a inIraestrutura dos principais ISPs seja capaz de transmitir traIego IPv6 de Iorma
nativa. No entanto, sua implantao em redes maiores tem encontrado diIiculdades devido, entre
outras coisas, ao receio de grandes mudanas na Iorma de se gerencia-las, na existncia de gastos
devido a necessidade de troca de equipamentos como roteadores e switches, e gastos com o
aprendizado e treinamento para a area tcnica.
27
Mas a previso agora est assim:
Como est a impIantao do
IPv6?
28
Diversos estudos esto sendo realizados buscando mensurar a quantidade de inIormao
que traIega na Internet sobre o protocolo IPv6. Analises sobre o numero de ASs anunciando IPv6,
analise de consultas a servidores DNS e a quantidade de paginas na Internet usando IPv6, so
alguns exemplos de como tem se tentado medir a evoluo da implantao da verso 6 do
Protocolo Internet.
O Google tem realizado uma avaliao do estado atual do uso de IPv6 por usuarios
comuns, coletando inIormaes Iornecidas pelos navegadores de uma parcela de usuarios de seus
servios. Com isso, Ioi possivel determinar que aproximadamente 0,2 de seus clientes IPv6
ativado, e que a quantidade de acessos utilizando IPv6 subiu de 0,189 em agosto de 2008, para
0,261 em janeiro de 2009.
Outros dados interessantes apontam que apenas 6,2 dos ASs trabalham sobre IPv6.
Destaca-se tambm que 7 dos 13 root DNS servers so acessiveis via IPv6 (A, F, H, J, K, L e M).
28
6,2% dos ASs trabalham sobre Pv6
7 dos 13 root DNS servers so acessveis via Pv6
0,261% de clientes do Google possuem Pv6 ativado
Como est a impIantao do
IPv6?
29
Ponto Iundamental da inIraestrutura da Internet, 23 dos PTTs (Pontos de Troca de
TraIego, ou em ingls, IXP - Internet eXchange Point) no mundo trocam traIego IPv6, e em um
dos maiores IXPs, o AM-IX (Amsterdam Internet Exchange), o traIego IPv6 trocado de
aproximadamente 1Gbps, o que corresponde a 0,3 do traIego total.
No Brasil, desde Ievereiro de 2010 o NIC.br oIerece para os participantes do PTTMetro
So Paulo o servio de trnsito IPv6 experimental gratuitamente. Com a iniciativa, o NIC.br tem o
objetivo de promover o uso do protocolo, reduzindo o tempo entre a atribuio dos blocos para as
entidades e seu eIetivo uso, permitindo experimentao e Iacilitando sua implantao.
29
Pelo menos 23% dos PTTs no mundo trocam trfego Pv6
No AM-X o trfego Pv6 trocado de aproximadamente 1Gbps
O PTTMetro-SP oferece trnsito
Pv6 experimental gratuito a seus
participantes
Como est a impIantao do
IPv6?
30
Blocos de endereos IPv6 vm sendo alocados pelos RIRs ha aproximadamente dez anos.
No entanto, o Iato dos RIRs alocarem endereos aos Registros Nacionais ou aos ISPs, no
signiIica que estes endereos estejam sendo utilizados. Ao cruzar os dados sobre a quantidade de
blocos /32 IPv6 ja alocados com o numero de rotas anunciadas na tabela de roteamento, nota-se
que apenas 3 desses recursos esto sendo eIetivamente utilizados, isto , dos 73.000 blocos ja
alocados, apenas pouco mais 2.500 esto presentes na tabela global de roteamento.
30
Como est a impIantao do
IPv6?
Dos ~73.000 blocos /32 j alocados pelos RR, apenas 3% so
efetivamente utilizados.
AIocaes feitas peIos RIRs
Entradas IPv6 na tabeIa de rotas gIobaI
Dados de 15/01/2010
31
No Brasil, e em toda a Amrica Latina, a situao similar.
O LACNIC, RIR que atua na Amrica Latina e Caribe, ja alocou aproximadamente 230
blocos /32 IPv6, o que corresponde a aproximadamente 0,4 do total de blocos ja alocados
mundialmente. Destes, 35,3 esto alocados no Brasil, porm, apenas 30 esto sendo
eIetivamente utilizado.
Mais inIormaes:
http://www.arbornetworks.com/IPv6research
https://sites.google.com/site/ipv6implementors/conference2009/agenda/10_Lees_Google_IPv6_User_Measurement.pdf
http://www.oecd.org/dataoecd/48/51/44953210.pdI
http://www.ipv6.br/IPV6/MenuIPv6Transito
http://www.ams-ix.net/sIlow-stats/ipv6/
http://bgp.he.net/ipv6-progress-report.cgi
http://portalipv6.lacnic.net/pt-br/ipv6/estat-sticas
http://bgp.potaroo.net/v6/as2.0/index.html
Itp://Itp.registro.br/pub/stats/delegated-ipv6-nicbr-latest
31
Como est a impIantao do
IPv6 no BrasiI?
Os blocos atribudos para o
LACNC correspondem a apenas
0,4% dos j atribudos
mundialmente;
Destes 0,4%, 35,3% esto
alocados para o Brasil;
Porm, dos blocos alocados
para o Brasil, apenas 30% esto
sendo efetivamente utilizados.
BIocos aIocados para o BrasiI versus bIocos roteados
Dados de 15/01/2010
32
E importante observar que, embora a utilizao do IPv6 ainda no tenha tanta
representatividade, todos os dados apresentados mostram que sua penetrao nas redes tem
aumentado gradativamente. No entanto, preciso avanar ainda mais. Adiar por mais tempo a
implantao do IPv6 pode trazer diversos prejuizos para o desenvolvimento de toda a Internet.
Como vimos, existe hoje uma demanda muito grande por mais endereos IP, e mesmo que
a Internet continue Iuncionando sem novos endereos, ela tera muita diIiculdade para crescer. A
cada dia surgem novas redes, graas a expanso das empresas e ao surgimento de novos negocios;
iniciativas de incluso digital tem trazido muitos novos usuarios para a Internet; e o crescimento
das redes 3G, e a utilizao da Internet em dispositivos eletrnicos e eletrodomsticos so
exemplos de novas aplicaes que colaboram com seu crescimento.
A no implantao do IPv6 provavelmente impedira o desenvolvimento de todas essas
areas, e alm disso, com o IPv6 elimina-se a necessidade da utilizao de NATs, Iavorecendo o
Iuncionamento de varias aplicaes. Deste modo, o custo de no se utilizar, ou adiar ainda mais a
implantao do protocolo IPv6, sera muito maior do que o de utiliza-lo.
Para os Provedores Internet, importante que estes oIeream novos servios a seus
clientes, e principalmente, porque inovar a chave para competir e manter-se a Irente da
concorrncia.
32
Quais os riscos da no
impIantao do IPv6?
Embora ainda seja pequena, a utilizao do Pv6 tem aumentado
gradativamente;
Porm precisa avanar ainda mais;
A no implementao do Pv6 ir:
mpedir o surgimento de novas redes;
Diminuir o processo de incluso digital o reduzindo o nmero de novos
usurios;
Dificultar o surgimento de novas aplicaes;
Aumentar a utilizao de tcnicas como a NAT.
O custo de no implementar o Pv6 poder ser maior que o custo de
implement-lo;
Provedores nternet precisam inovar e oferecer novos servios a seus
clientes.
33
33
34
A partir desse ponto, iniciaremos o estudo das principais caracteristicas do IPv6,
comeando pela analise das mudanas ocorridas na estrutura de seu cabealho, apresentando as
diIerenas entre os cabealhos IPv4 e IPv6, e de que Iorma essas mudanas aprimoraram o
Iuncionamento do protocolo. Tambm sera detalhado o Iuncionamento dos cabealhos de
extenso, mostrando porque sua utilizao pode melhorar o desempenho dos roteadores.
34
CabeaIho IPv6
MduIo 2
35
O cabealho IPv4 composto por 12 campos Iixos, podendo conter ou no opes,
Iazendo com que seu tamanho possa variar entre 20 e 60 Bytes. Estes campos so destinados
transmitir inIormaes sobre:
a verso do protocolo;
o tamanho do cabealho e dos dados;
a Iragmentao;
o tipo de dados;
o tempo de vida do pacote;
o protocolo da camada seguinte (TCP, UDP, ICMP);
a integridade dos dados;
a origem e o destino do pacote.
35
CabeaIho IPv4
O cabealho Pv4 composto por 12 campos fixos, podendo conter ou no
opes, fazendo com que seu tamanho possa variar entre 20 e 60 Bytes.
36
Algumas mudanas Ioram realizadas no Iormato do cabealho base do IPv6 de modo a
torna-lo mais simples, com apenas oito campos e com tamanho Iixo de 40 Bytes, alm de mais
Ilexivel e eIiciente, prevendo sua extenso por meio de cabealhos adicionais que no precisam
ser processados por todos os roteadores intermediarios. Estas alteraes permitiram que, mesmo
com um espao para endereamento de 128 bits, quatro vezes maior que os 32 bits do IPv4, o
tamanho total do cabealho IPv6 seja apenas duas vezes maior que o da verso anterior.
36
CabeaIho IPv6
Mais simples
40 Bytes (tamanho fixo).
Apenas duas vezes maior que o da verso anterior.
Mais flexvel
Extenso por meio de cabealhos adicionais.
Mais eficiente
Minimiza o overhead nos cabealhos.
Reduz o custo do processamento dos pacotes.
37
Entre essas mudanas, destaca-se a remoo de seis campos do cabealho IPv4, visto que
suas Iunes no so mais necessarias ou so implementadas pelos cabealhos de extenso.
No IPv6, as opes adicionais agora Iazem parte dos cabealhos de extenso do IPv6.
Deste modo, os campos Opes e Complementos puderam ser removidos.
O campo Tamanho do Cabealho tambm Ioi removido, porque o tamanho do cabealho
IPv6 Iixo.
Os campos IdentiIicao, Flags e Deslocamento do Fragmento, Ioram removidos porque
as inIormaes reIerentes a Iragmentao so indicadas agora em um cabealho de extenso
apropriado.
Com o intuito de aumentar a velocidade do processamento dos roteadores, o campo Soma
de VeriIicao Ioi retirado, pois esse calculo ja realizado pelos protocolos das camadas
superiores.
37
CabeaIho IPv6
Seis campos do cabealho Pv4 foram removidos.
38
Outra mudana reIere-se a alterao do nome e do posicionamento de outros quatro
campos.
Esses reposicionamentos Ioram deIinidos para Iacilitar o processamento dessas
inIormaes pelos roteadores.
IPv4 IPv6
Tipo de Servio Classe de TraIego
Tamanho Total Tamanho dos Dados
Tempo de Vida (TTL) Limite de Encaminhamento
Protocolo Proximo Cabealho
38
CabeaIho IPv6
Seis campos do cabealho Pv4 foram removidos.
Quatro campos tiveram seus nomes alterados e seus posicionamentos modificados.
1 1 2
2
3
3 4
4
39
Tambm Ioi adicionado um novo campo, o IdentiIicador de Fluxo, acrescentado um
mecanismo extra de suporte a QoS ao protocolo IP. Mais detalhes sobre este campo e de como o
protocolo IPv6 trata a questo do QoS sero apresentados nos proximos modulos deste curso.
39
CabeaIho IPv6
Seis campos do cabealho Pv4 foram removidos.
Quatro campos tiveram seus nomes alterados e seus posicionamentos modificados.
O campo dentificador de Fluxo foi acrescentado.
40
Os campo Verso, Endereo de Origem e Endereo de Destino Ioram mantidos, alterando
apenas o tamanho do espao reservado para o endereamento que passa a ter 128 bits.
40
CabeaIho IPv6
Seis campos do cabealho Pv4 foram removidos.
Quatro campos tiveram seus nomes alterados e seus posicionamentos modificados.
O campo dentificador de Fluxo foi acrescentado.
Trs campos foram mantidos.
41
Vamos conhecer um pouco sobre cada campo do cabealho base do IPv6:
Verso (4 bits) - IdentiIica a verso do protocolo IP utilizado. No caso do IPv6 o valor desse
campo 6.
Classe de Trfego (8 bits) - IdentiIica e diIerencia os pacotes por classes de servios ou
prioridade. Ele continua provendo as mesmas Iuncionalidades e deIinies do campo Tipo de
Servio do IPv4.
Identificador de Fluxo (20 bits) - IdentiIica e diIerencia pacotes do mesmo Iluxo na camada de
rede. Esse campo permite ao roteador identiIicar o tipo de Iluxo de cada pacote, sem a necessidade
de veriIicar sua aplicao.
Tamanho do Dados (16 bits) - Indica o tamanho, em Bytes, apenas dos dados enviados junto ao
cabealho IPv6. Substituiu o campo Tamanho Total do IPv4, que indica o tamanho do cabealho
mais o tamanho dos dados transmitidos. Os cabealhos de extenso tambm so incluidos no
calculo do tamanho.
Prximo Cabealho (8 bits) - IdentiIica cabealho que se segue ao cabealho IPv6. Este campo
Ioi renomeado (no IPv4 chamava-se Protocolo) reIletindo a nova organizao dos pacotes IPv6,
pois agora este campo no contm apenas valores reIerentes a outros protocolos, mas tambm
indica os valores dos cabealhos de extenso.
Limite de Encaminhamento (8 bits) - Indica o numero maximo de roteadores que o pacote IPv6
pode passar antes de ser descartado, sendo decrementado a cada salto. Padronizou o modo como o
campo Tempo de Vida (TTL) do IPv4 tem sido utilizado, apesar da deIinio original do campo
TTL, dizer que este deveria indicar, em segundos, quanto tempo o pacote levaria para ser
descartado caso no chegasse ao seu destino.
Endereo de origem (128 bits) - Indica o endereo de origem do pacote.
Endereo de Destino (128 bits) - Indica o endereo de destino do pacote.
41
CabeaIho IPv6
42
DiIerente do IPv4, que inclui no cabealho base todas as inIormaes opcionais, o IPv6
trata essas inIormaes atravs de cabealhos de extenso. Estes cabealhos localizam-se entre o
cabealho base e o cabealho da camada imediatamente acima, no havendo nem quantidade, nem
tamanho Iixo para eles. Caso existam multiplos cabealhos de extenso no mesmo pacote, eles
sero adicionados em srie Iormando uma 'cadeia de cabealhos.
As especiIicaes do IPv6 deIinem seis cabealhos de extenso: Hop-by-Hop Options,
Destination Options, Routing, Fragmentation, Authentication Heaaer e Encapsulating Security
Payloaa.
A utilizao cabealhos de extenso do IPv6, visa aumentar a velocidade de processamento
nos roteadores, visto que, o unico cabealho de extenso processado em cada roteador o Hop-by-
Hop, os demais so tratados apenas pelo no identiIicado no campo Endereo de Destino do
cabealho base. Alm disso, novos cabealhos de extenso podem ser deIinidos e usados sem a
necessidade de se alterar o cabealho base.
42
CabeaIhos de Extenso
No Pv6, opes adicionais so tratadas por meio de cabealhos de
extenso.
Localizam-se entre o cabealho base e o cabealho da camada de
transporte.
No h nem quantidade, nem tamanho fixo para estes cabealhos.
CabeaIho IPv6
Prximo
Cabealho = 6
CabeaIho TCP Dados
CabeaIho Routing
Prximo
Cabealho = 6
CabeaIho TCP Dados
CabeaIho TCP Dados
CabeaIho Routing
Prximo
Cabealho = 44
CabeaIho
Fragmentation
Prximo
Cabealho = 6
CabeaIho IPv6
Prximo
Cabealho = 6
CabeaIho IPv6
Prximo
Cabealho = 43
43
IdentiIicado pelo valor 0 no campo Proximo Cabealho, o cabealho de extenso Hop-by-
Hop deve ser colocado imediatamente apos o cabealho base IPv6. As inIormaes carregadas por
ele devem ser examinadas por todos os nos intermediarios ao longo do caminho do pacote at o
destino. Na sua ausncia, o roteador sabe que no precisa processar nenhuma inIormao
adicional e assim pode encaminha o pacote para o destino Iinal imediatamente.
As deIinies de cada campo do cabealho so as seguintes:
Prximo Cabealho (1 Byte): IdentiIica o tipo de cabealho que segue ao Hop-by-
Hop.
Tamanho do Cabealho (1 Byte): Indica o tamanho do cabealho Hop-by-Hop em
unidades de 8 Bytes, excluido o oito primeiros.
Opes: Contem uma ou mais opes e seu tamanho variavel. Neste campo, o
primeiro Byte contem inIormaes sobre como estas opes devem ser tratadas no
caso o no que esteja processando a inIormao no a reconhea. O valor dos primeiros
dois bits especiIica as aes a serem tomadas:
00: ignorar e continuar o processamento.
01: descartar o pacote.
10: descartar o pacote e enviar uma mensagem ICMP Parameter Problem para
o endereo de origem do pacote.
11: descartar o pacote e enviar uma mensagem ICMP Parameter Problem para
o endereo de origem do pacote, apenas se o destino no Ior um endereo de
multicast.
O terceiro bit deste campo especiIica se a inIormao opcional pode mudar de rota (valor
01) ou no (valor 00).
43
CabeaIhos de Extenso
Hop-by-Hop Options
dentificado pelo valor 0 no campo Prximo Cabealho.
Carrega informaes que devem ser processadas por todos os
ns ao longo do caminho do pacote.
Opes
Tam. cab. de
extenso
Prximo
Cabealho
44
At o momento existem dois tipos deIinidos para o cabealho Hop-by-Hop: a Router Alert
e a Jumbogram.
Router Alert: Utilizado para inIormar aos nos intermediarios que a mensagem a ser
encaminhada exige tratamento especial. Esta opo utilizada pelos protocols MLD
(Multicast Listener Discovery) e RSVP (Resource Reservation Protocol).
1umbogram: Utilizado para inIorma que o tamanho do pacote IPv6 maior do que
64KB.
Mais inIormaes:
RFC 2711 - IPv6 Router Alert Option
45
IdentiIicado pelo valor 60 no campo Proximo Cabealho, o cabealho de extenso
Destination Options carrega inIormaes que devem ser processadas pelo no de destino do pacote,
indicado no campo Endereo de Destino do cabealho base. A deIinio de seus campos igual as
do cabealho Hop-by-Hop e um exemplo de usa utilizao.
Este cabealho utilizado no suporte a mobilidade do IPv6 atravs da opo Home
Aaaress, que contem o Endereo de Origem do No Movel quando este esta em transito.
45
CabeaIhos de Extenso
Destination Options
dentificado pelo valor 60 no campo Prximo Cabealho.
Carrega informaes que devem ser processadas pelo n de
destino do pacote.
Opes
Tam. cab. de
extenso
Prximo
Cabealho
46
IdentiIicado pelo valor 43 no campo Proximo Cabealho, o cabealho de extenso Routing
Ioi desenvolvido inicialmente para listar um ou mais nos intermediarios que deveriam ser
visitados at o pacote chegar ao destino, semelhante as opes Loose Source e Recora Route do
IPv4. Esta Iuno, realizada pelo cabealho Routing Type 0, tornou-se obsoleta pela RFC5095
devido a problemas de segurana.
Um novo cabealho Routing, o Type 2, Ioi deIinido para ser utilizado como parte do
mecanismo de suporte a mobilidade do IPv6, carregando o Endereo de Origem do No Movel em
pacotes enviados pelo No Correspondente.
As deIinies de cada campo do cabealho so as seguintes:
Prximo Cabealho (1 Byte): IdentiIica o tipo de cabealho que segue ao cabealho
Routing.
Tamanho do Cabealho (1 Byte): Indica o tamanho do cabealho Routing em unidades
de 8 Bytes, excluido o oito primeiros.
Routing 1ype (1 Byte): IdentiIica o tipo de cabealho Routing. Atualmente apenas o Type
2 esta deIinido.
Saltos restantes: DeIinido para ser utilizado com o Routing Type 0, indica o numero de
saltos a serem visitados antes do pacote atingir seu destino Iinal.
Endereo de Origem: Carrega o Endereo de Origem de um No Movel.
Mais inIormaes:
RFC 3775 - Mobility Support in IPv6 - 6.4. Type 2 Routing Heaaer
RFC 5095 - Deprecation of Type 0 Routing Heaaers in IPv6
46
CabeaIhos de Extenso
Routing
dentificado pelo valor 43 no campo Prximo Cabealho.
Desenvolvido inicialmente para listar um ou mais ns
intermedirios que deveriam ser visitados at o pacote chegar
ao destino.
Atualmente utilizado como parte do mecanismo de suporte a
mobilidade do Pv6.
Endereo de Origem
Tam. cab. de
extenso
Prximo
Cabealho
Saltos restantes
Tipo de
Routing
Reservado
47
IdentiIicado pelo valor 44 no campo Proximo Cabealho, o cabealho de extenso
Fragmentation utilizado quando o pacote IPv6 a ser enviado maior que o Path MTU.
As deIinies de cada campo do cabealho so as seguintes:
Prximo Cabealho (1 Byte): IdentiIica o tipo de cabealho que segue ao cabealho
Fragmentation.
Deslocamento do Fragmento (13 bits): Indica, em unidades de oito Bytes, a posio
dos dados transportados pelo Iragmento atual em relao ao inicio do pacote original.
Flag M (1 bit): Se marcado com o valor 1, indica que ha mais Iragmentos. Se marcado
com o valor 0, indica que o Iragmento Iinal.
Identificao (4 Bytes): Valor unico, gerado pelo no de origem, para cada identiIicar o
pacote original original. E utilizado para detectar os Iragmentos de um mesmo pacote.
O processo de Iragmentao de pacotes do IPv6 sera detalhado nos proximos modulos.
47
CabeaIhos de Extenso
Fragmentation
dentificado pelo valor 44 no campo Prximo Cabealho.
Carrega informaes sobre os fragmentos dos pacotes Pv6.
Reservado
Prximo
Cabealho
Res
Deslocamento do
Fragmento
dentificao
M
48
Os cabealhos de extenso Authentication Heaaer e Encapsulating Security Payloaa,
indicados respectivamente pelos valores 51 e 52 no campo Proximo Cabealho, Iazem parte do
cabealho IPSec.
Embora as Iuncionalidades do IPSec sejam idnticas tanto no IPv4 quanto no IPv6, sua
utilizao com IPv6 Iacilitada pelo Iato de seu principais elementos serem parte integrante da
nova verso do protocolo IP. Outros aspectos tambm Iacilitam essa utilizao, como o Iato de no
se utilizar NAT com IPv6, no entanto essa questo sera detalhada nos proximos modulos,
juntamente com o detalhamento dos cabealhos de extenso AH e ESP.
48
CabeaIhos de Extenso
Authentication Header
dentificado pelo valor 51 no campo Prximo Cabealho.
Utilizado pelo PSec para prover autenticao e garantia de
integridade aos pacotes Pv6.
Encapsulating Security Payload
dentificado pelo valor 52 no campo Prximo Cabealho.
Tambm utilizado pelo PSec, garante a integridade e
confidencialidade dos pacotes.
49
Alguns aspectos sobre os cabealhos de extenso devem ser observados.
Primeiramente importante destacar que, para evitar que os nos existentes ao longo do
caminho do pacote tenham que percorrer toda a cadeia de cabealhos de extenso para
conhecer quais inIormaes devero tratar, estes cabealhos devem ser enviados respeitando
um determinada ordem. Geralmente, os cabealhos importantes para todos os nos envolvidos
no roteamento devem ser colocados em primeiro lugar, cabealhos importantes apenas para o
destinatario Iinal so colocados no Iinal da cadeia. A vantagem desta seqncia que o no
pode parar de processar os cabealhos assim que encontrar algum cabealho de extenso
dedicado ao destino Iinal, tendo certeza de que no ha mais cabealhos importantes a seguir.
Com isso, possivel melhorar signiIicativamente o processamento dos pacotes, porque, em
muitos casos, apenas o processamento do cabealho base sera suIiciente para encaminhar o
pacote. Deste modo, a sequncia a ser seguida :
Hop-by-Hop Options
Routing
Fragmentation
Authentication Heaaer
Encapsulating Security Payloaa
Destination Options
Tambm vale observar, que se um pacote Ior enviado para um endereo multicast, os
cabealhos de extenso sero examinados por todos os nos do grupo.
Em relao a Ilexibilidade oIerecida pelos cabealhos de extenso, merece destaque o
desenvolvido o cabealho Mobility, utilizado pelos nos que possuem suporte a mobilidade
IPv6.
49
CabeaIhos de Extenso
Quando houver mais de um cabealho de extenso, recomenda-se
que eles apaream na seguinte ordem:
Hop-by-Hop Options
Routing
Fragmentation
Authentication Header
Encapsulating Security Payload
Destination Options
Se o campo Endereo de Destino tiver um endereo multicast, os
cabealhos de extenso sero examinados por todos os ns do
grupo.
Pode ser utilizado o cabealho de extenso Mobility pelos ns que
possurem suporte a mobilidade Pv6.
50
50
51
O protocolo IPv6 apresenta como principal caracteristica e justiIicativa maior para o seu
desenvolvimento, o aumento no espao para endereamento. Por isso, importante conhecermos
as diIerenas entre os endereos IPv4 e IPv6, saber reconhecer a sintaxe dos endereos IPv6 e
conhecer os tipos de endereos IPv6 existentes e suas principais caracteristicas.
51
Endereamento IPv6
MduIo 3
52
No IPv4, o campo do cabealho reservado para o endereamento possui 32 bits. Este
tamanho possibilita um maximo de 4.294.967.296 (2
32
) endereos distintos. A poca de seu
desenvolvimento, esta quantidade era considerada suIiciente para identiIicar todos os
computadores na rede e suportar o surgimento de novas sub-redes. No entanto, com o rapido
crescimento da Internet, surgiu o problema da escassez dos endereos IPv4, motivando a a criao
de uma nova gerao do protocolo IP.
O IPv6 possui um espao para endereamento de 128 bits, sendo possivel obter
340.282.366.920.938.463.463.374.607.431.768.211.456 endereos (2
128
). Este valor representa
aproximadamente 79 octilhes (7,9x10
28
) de endereos a mais do que no IPv4 e representa,
tambm, mais de 56 octilhes (5,6x10
28
) de endereos por ser humano na Terra, considerando-se a
populao estimada em 6 bilhes de habitantes.
52
Endereamento
Um endereo Pv4 formado por 32 bits.
2
32
= 4.294.967.296
Um endereo Pv6 formado por 128 bits.
2
128
= 340.282.366.920.938.463.463.374.607.431.768.211.456 340.282.366.920.938.463.463.374.607.431.768.211.456
~ 56 octilhes (5,6x10
28
) de endereos P por ser humano.
~ 79 octilhes (7,9x10
28
) de endereos a mais do que no Pv4.
53
Os 32 bits dos endereos IPv4 so divididos em quatro grupos de 8 bits cada, separados
por '., escritos com digitos decimais. Por exemplo: 192.168.0.10.
A representao dos endereos IPv6, divide o endereo em oito grupos de 16 bits,
separando-os por ':, escritos com digitos hexadecimais (0-F). Por exemplo:
2001:0DB8:AD1F:25E2:CADE:CAFE:F0CA:84C1
Na representao de um endereo IPv6, permitido utilizar tanto caracteres maiusculos
quanto minusculos.
Alm disso, regras de abreviao podem ser aplicadas para Iacilitar a escrita de alguns
endereos muito extensos. E permitido omitir os zeros a esquerda de cada bloco de 16 bits, alm
de substituir uma sequncia longa de zeros por '::. Por exemplo, o endereo
2001:0DB8:0000:0000:130F:0000:0000:140B pode ser escrito como 2001:DB8:0:0:130F::140B
ou 2001:DB8::130F:0:0:140B. Neste exemplo possivel observar que a abreviao do grupo de
zeros so pode ser realizada uma unica vez, caso contrario podera haver ambigidades na
representao do endereo. Se o endereo acima Iosse escrito como 2001:DB8::130F::140B, no
seria possivel determinar se ele corresponde a 2001:DB8:0:0:130F:0:0:140B, a
2001:DB8:0:0:0:130F:0:140B ou 2001:DB8:0:130F:0:0:0:140B.
Esta abreviao pode ser Ieita tambm no Iim ou no inicio do endereo, como ocorre em
2001:DB8:0:54:0:0:0:0 que pode ser escrito da Iorma 2001:DB8:0:54::.
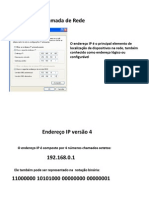
53
Endereamento
A representao dos endereos Pv6, divide o endereo em oito
grupos de 16 bits, separando-os por :, escritos com dgitos
hexadecimais.
2001:0DB8:AD1F:25E2:CADE:CAFE:F0CA:84C1
Na representao de um endereo Pv6 permitido:
Utilizar caracteres maisculos ou minsculos;
Omitir os zeros esquerda; e
Representar os zeros contnuos por "::".
Exemplo:
2001:0DB8:0000:0000:130F:0000:0000:140B
2001:db8:0:0:130f::140b
Formato invlido: 2001:db8::130f::140b (gera ambiguidade)
2 Bytes
54
Outra representao importante a dos preIixos de rede. Em endereos IPv6 ela continua
sendo escrita do mesmo modo que no IPv4, utilizando a notao CIDR. Esta notao
representada da Iorma 'endereo-IPv6/tamanho do preIixo, onde 'tamanho do preIixo um
valor decimal que especiIica a quantidade de bits contiguos a esquerda do endereo que
compreendem o preIixo. O exemplo de preIixo de sub-rede apresentado a seguir indica que dos
128 bits do endereo, 64 bits so utilizados para identiIicar a sub-rede.
Esta representao tambm possibilita a agregao dos endereos de Iorma hierarquica,
identiIicando a topologia da rede atravs de parmetros como posio geograIica, provedor de
acesso, identiIicao da rede, diviso da sub-rede, etc. Com isso, possivel diminuir o tamanho da
tabela de roteamento e agilizar o encaminhamento dos pacotes.
Com relao a representao dos endereos IPv6 em URLs (Uniform Resource Locators),
estes agora passam a ser representados entre colchetes. Deste modo, no havera ambiguidades
caso seja necessario indicar o numero de uma porta juntamente com a URL. Observe os exemplos
a seguir:
http://|2001:12ff:0:4::22|/index.html
http://|2001:12ff:0:4::22|:8080
54
Endereamento
Representao dos Prefixos
Como o CDR (Pv4)
endereo-Pv6/tamanho do prefixo
Exemplo:
Prefixo 2001:db8:3003:2::/64
Prefixo global 2001:db8::/32
D da sub-rede 3003:2
URL
http://[2001:12ff:0:4::22]/index.html
http://[2001:12ff:0:4::22]:8080
PreIixo 2001:db8:3003:2::/64
PreIixo global 2001:db8::/32
ID da sub-rede 3003:2
55
Existem no IPv6 trs tipos de endereos deIinidos:
Unicast este tipo de endereo identiIica uma unica interIace, de modo que um pacote
enviado a um endereo unicast entregue a uma unica interIace;
Anycast identiIica um conjunto de interIaces. Um pacote encaminhado a um endereo
anycast entregue a interIace pertencente a este conjunto mais proxima da origem (de
acordo com distncia medida pelos protocolos de roteamento). Um endereo anycast
utilizado em comunicaes de um-para-um-de-muitos.
Multicast tambm identiIica um conjunto de interIaces, entretanto, um pacote enviado
a um endereo multicast entregue a todas as interIaces associadas a esse endereo. Um
endereo multicast utilizado em comunicaes de um-para-muitos.
DiIerente do IPv4, no IPv6 no existe endereo broaacast, responsavel por
direcionar um pacote para todos os nos de um mesmo dominio. No IPv6, essa Iuno Ioi
atribuida a tipos especiIicos de endereos multicast.
55
Endereamento
Existem no Pv6 trs tipos de endereos definidos:
Unicast dentificao ndividual
Anycast dentificao Seletiva
Multicast dentificao em Grupo
No existe mais Broadcast.
56
Os endereos unicast so utilizados para comunicao entre dois nos, por exemplo,
teleIones VoIPv6, computadores em uma rede privada, etc., e sua estrutura Ioi deIinida para
permitir agregaes com preIixos de tamanho Ilexivel, similar ao CIDR do IPv4.
Existem alguns tipos de endereos unicast IPv6: Global Unicast; Unique-Local; e Link-
Local por exemplo. Existem tambm alguns tipos para usos especiais, como endereos IPv4
mapeados em IPv6, endereo de loopback e o endereo no-especiIicado, entre outros.
Clobal Unicast - equivalente aos endereos publicos IPv4, o endereo global unicast
globalmente roteavel e acessivel na Internet IPv6. Ele constituido por trs partes: o
preIixo de roteamento global, utilizado para identiIicar o tamanho do bloco atribuido a
uma rede; a identiIicao da sub-rede, utilizada para identiIicar um enlace em uma
rede; e a identiIicao da interIace, que deve identiIicar de Iorma unica uma interIace
dentro de um enlace.
Sua estrutura Ioi projetada para utilizar os 64 bits mais a esquerda para identiIicao
da rede e os 64 bits mais a direita para identiIicao da interIace. Portanto, exceto
casos especiIicos, todas as sub-redes em IPv6 tem o mesmo tamanho de preIixo, 64
bits (/64), o que possibilita 2
64
18.446.744.073.709.551.616 dispositivos por sub-
rede.
Atualmente, esta reservada para atribuio de endereos a Iaixa 2000::/3 (001), que
corresponde aos endereos de 2000:: a 3fff:ffff:ffff:ffff:ffff:ffff:ffff:ffff. Isto
representa 13 do total de endereos possiveis com IPv6, o que nos permite criar
2
(643)
2.305.843.009.213.693.952 (2,3x10
18
) sub-redes (/64) diIerentes ou 2
(483)
35.184.372.088.832 (3,5x10
13
) redes /48.
56
Endereamento
Unicast
Global Unicast
2000::/3
Globalmente rotevel (similar aos endereos pblicos Pv4);
13% do total de endereos possveis;
2
(45)
= 35.184.372.088.832 redes /48 distintas.
PreIixo de roteamento global
ID da
sub-rede
n 64 - n 64
IdentiIicador da interIace
57
Link Local podendo ser usado apenas no enlace especiIico onde a interIace esta
conectada, o endereo link local atribuido automaticamente utilizando o preIixo
FE80::/64. Os 64 bits reservados para a identiIicao da interIace so conIigurados
utilizando o Iormato IEEE EUI-64. Vale ressaltar que os roteadores no devem
encaminhar para outros enlaces, pacotes que possuam como origem ou destino um
endereo link-local;
57
Endereamento
Unicast
Link local
FE80::/64
Deve ser utilizado apenas localmente;
Atribudo automaticamente (autoconfigurao stateless);
IdentiIicador da interIace
FE80 0
58
Unique Local Address (ULA) endereo com grande probabilidade de ser
globalmente unico, utilizado apenas para comunicaes locais, geralmente dentro de
um mesmo enlace ou conjunto de enlaces. Um endereo ULA no deve ser roteavel na
Internet global.
Um endereo ULA, criado utilizado um ID globa alocado pseudo-randomicamente,
composto das seguintes partes:
Prefixo: FC00::/7.
Flag Local (L): se o valor Ior 1 (FD) o preIixo atribuido localmente. Se o
valor Ior 0 (FC), o preIixo deve ser atribuido por uma organizao central
(ainda a deIinir).
Identificador global: identiIicador de 40 bits usado para criar um preIixo
globalmente unico.
Identificador da Interface: identiIicador da interIace de 64 bits.
Deste modo, a estrutura de um endereo ULA FDUU:UUUU:UUUU:<ID da sub-
rede>:<Id da interface> onde U so os bits do identiIicador unico, gerado
aleatoriamente por um algoritmo especiIico.
Sua utilizao permite que qualquer enlace possua um preIixo /48 privado e unico
globalmente. Deste modo, caso duas redes, de empresas distintas por exemplo, sejam
interconectadas, provavelmente no havera conIlito de endereos ou necessidade de
renumerar a interIace que o esteja usando. Alm disso, o endereo ULA
independente de provedor, podendo ser utilizado na comunicao dentro do enlace
mesmo que no haja uma conexo com a Internet. Outra vantagem, que seu preIixo
pode ser Iacilmente bloqueado, e caso um endereo ULA seja anunciado
acidentalmente para Iora do enlace, atravs de um roteador ou via DNS, no havera
conIlito com outros endereos.
58
Endereamento
Unicast
Unique local
FC00::/7
Prefixo globalmente nico (com alta probabilidade de ser nico);
Utilizado apenas na comunicao dentro de um enlace ou entre
um conjunto limitado de enlaces;
No esperado que seja roteado na nternet.
IdentiIicador global
ID da
sub-rede
IdentiIicador da interIace PreI. L
7
59
Os identiIicadores de interIace (IID), utilizados para distinguir as interIaces dentro de um
enlace, devem ser unicos dentro do mesmo preIixo de sub-rede. O mesmo IID pode ser usado em
multiplas interIaces em um unico no, porm, elas dever estar associadas a deIerentes sub-redes.
Normalmente utiliza-se um IID de 64 bits, que pode ser obtido de diversas Iormas. Ele
pode ser conIigurado manualmente, a partir do mecanismo de autoconIigurao stateless do IPv6,
a partir de servidores DHCPv6 (stateful), ou Iormados a partir de uma chave publica (CGA). Estes
mtodos sero detalhados no decorrer deste curso.
Embora eles possam ser gerados randomicamente e de Iorma temporaria, recomenda-se
que o IID seja construido baseado no endereo MAC da interIace, no Iormato EUI-64.
Mais inIormaes:
RFC 3986 - Uniform Resource Iaentifier (URI). Generic Syntax
RFC 4291 - IP Jersion 6 Aaaressing Architecture
RFC 4193 - Unique Local IPv6 Unicast Aaaresses
RFC 5156 - Special-Use IPv6 Aaaresses
RFC 3587 - IPv6 Global Unicast Aaaress Format
Internet Protocol Jersion 6 Aaaress Space - http://www.iana.org/assignments/ipv6-address-
space
59
Endereamento
Unicast
dentificador da nterface (D)
Devem ser nicos dentro do mesmo prefixo de sub-rede.
O mesmo D pode ser usado em mltiplas interfaces de um
nico n, desde que estejam associadas a sub-redes diferentes.
Normalmente utiliza-se um D de 64 bits, que pode ser obtido:
Manualmente
Autoconfigurao stateless
DHCPv6 (stateful)
A partir de uma chave pblica (CGA)
D pode ser temporrio e gerado randomicamente.
Normalmente basado no endereo MAC (Formato EU-64).
60
Um IID baseado no Iormato EUI-64 criado da seguinte Iorma:
Caso a interIace possua um endereo MAC de 64 bits (padro EUI-64), basta
complementar o stimo bit mais a esquerda (chamado de bit U/L Universal/Local)
do endereo MAC, isto , se Ior 1, sera alterado para 0; se Ior 0, sera alterado para 1.
Caso a interIace utilize um endereo MAC de 48 bits (padro IEEE 802), primeiro
adiciona-se os digitos hexadecimais FF-FE entre o terceiro e quarto Byte do endereo
MAC (transIormando no padro EUI-64), e em seguida, o bit U/L complementado.
Por exemplo:
Se endereo MAC da interIace Ior:
48-1E-C9-21-85-0C
adiciona-se os digitos FF-FE na metade do endereo:
48-1E-C9-FF-FE-21-85-0C
complementa-se o bit U/L:
48 01001000
01001000 01001010
01001010 4A
IID 4A-1E-C9-FF-FE-21-85-0C
Um endereo link local atribuido a essa interIace seria FE80::4A1E:C9FF:FE21:850C.
Mais inIormaes:
Guiaelines for 64-bit Global Iaentifier (EUI-64) Registration Authority -
http://standards.ieee.org/regauth/oui/tutorials/EUI64.html
60
Endereamento
Unicast
EU-64
Endereo MAC
Endereo EUI-64
IdentiIicador da InterIace
Bit U/L
48 1E C9 21 85 0C
0C
0C
85
85
21
21
C9
C9
1E
1E
48
0 1 0 0 1 0 0 0
0 1 0 0 1 0 1 0
4A
FF FE
FF FE
61
Existem alguns endereos IPv6 especiais utilizados para Iins especiIicos:
Endereo No-Especificado (Unspecified): representado pelo endereo
0:0:0:0:0:0:0:0 ou ::0 (equivalente ao endereo IPv4 unspecifiea 0.0.0.0). Ele nunca
deve ser atribuido a nenhum no, indicando apenas a ausncia de um endereo. Ele
pode, por exemplo, ser utilizado no campo Endereo de Origem de um pacote IPv6
enviado por um host durante o processo de inicializao, antes que este tenha seu
endereo exclusivo determinado. O endereo unspecifiea no deve ser utilizado como
endereo de destino de pacotes IPv6;
Endereo Loopback: representado pelo endereo unicast 0:0:0:0:0:0:0:1 ou ::1
(equivalente ao endereo IPv4 loopback 127.0.0.1). Este endereo utilizado para
reIerenciar a propria maquina, sendo muito utilizado para teste internos. Este tipo de
endereo no deve ser atribuido a nenhuma interIace Iisica, nem usado como endereo
de origem em pacotes IPv6 enviados para outros nos. Alm disso, um pacote IPv6
com um endereo loopback como destino no pode ser enviado por um roteador IPv6,
e caso um pacote recebido em uma interIace possua um endereo loopback como
destino, este deve ser descartado;
Endereos IPv4-mapeado: representado por 0:0:0:0:0:FFFF:wxyz ou
::FFFF:wxyz, usado para mapear um endereo IPv4 em um endereo IPv6 de 128-
bit, onde wxyz representa os 32 bits do endereo IPv4, utilizando digitos decimais. E
aplicado em tcnicas de transio para que nos IPv6 e IPv4 se comuniquem. Ex.
::FFFF:192.168.100.1.
61
Endereamento
Unicast
Endereos especiais
Localhost - ::1/128 (0:0:0:0:0:0:0:1)
No especificado - ::/128 (0:0:0:0:0:0:0:0)
Pv4-mapeado - ::FFFF:wxyz
Faixas Especiais
6to4 - 2002::/16
Documentao - 2001:db8::/32
Teredo - 2001:0000::/32
Obsoletos
Site local - FEC0::/10
Pv4-compatvel - ::wxyz
6Bone 3FFE::/16 (rede de testes desativada em 06/06/06)
62
Algumas Iaixas de endereos tambm so reservadas para uso especiIicos:
2002::/16: preIixo utilizado no mecanismo de transio 6to4;
2001:0000::/32: preIixo utilizado no mecanismo de transio TEREDO;
2001:db8::/32: preIixo utilizado para representar endereos IPv6 em textos e
documentaes.
Outros endereos, utilizados no inicio do desenvolvimento do IPv6 tornaram-se obsoletos e
no devem mais ser utilizados:
FEC0::/10: preIixo utilizado pelos endereos do tipo site local, desenvolvidos para
serem utilizados dentro de uma rede especiIica sem a necessidade de um preIixo global,
equivalente aos endereos privados do IPv4. Sua utilizao Ioi substituida pelos
endereos ULA;
::wxyz: utilizado para representar o endereo IPv4-compativel. Sua Iuno a mesma
do endereo IPv4-mapeado, tornando-se obsoleto por desuso;
3FFE::/16: preIixo utilizado para representar os endereos da rede de teste 6Bone.
Criada para ajudar na implantao do IPv6, esta rede Ioi desativada em 6 de junho de
2006 (06/06/06).
Mais inIormaes:
RFC 3849 - IPv6 Aaaress Prefix Reservea for Documentation
RFC 3879 - Deprecating Site Local Aaaresses
63
Um endereo IPv6 anycast utilizado para identiIicar um grupo de interIaces, porm, com
a propriedade de que um pacote enviado a um endereo anycast encaminhado apenas a interIace
do grupo mais proxima da origem do pacote.
Os endereos anycast so atribuidos a partir da Iaixa de endereos unicast e no ha
diIerenas sintaticas entre eles. Portanto, um endereo unicast atribuido a mais de uma interIace
transIorma-se em um endereo anycast, devendo-se neste caso, conIigurar explicitamente os nos
para que saibam que lhes Ioi atribuido um endereo anycast. Alm disso, este endereo deve ser
conIigurado nos roteadores como uma entrada separada (preIixo /128 host route).
Este esquema de endereamento pode ser utilizado para descobrir servios na rede, como
servidores DNS e proxies HTTP, garantindo a redundncia desses servios. Tambm pode-se
utilizar para Iazer balanceamento de carga em situaes onde multiplos hosts ou roteadores
provem o mesmo servio, para localizar roteadores que Iorneam acesso a uma determinada sub-
rede ou para localizar os Agentes de Origem em redes com suporte a mobilidade IPv6.
Todos os roteadores devem ter suporte ao endereo anycast Subnet-Router. Este tipo de
endereo Iormado pelo preIixo da sub-rede e pelo IID preenchido com zeros (ex.:
2001:db8:cafe:dad0::/64). Um pacote enviado para o endereo Subnet-Router sera entregue para
o roteador mais proximo da origem dentro da mesma sub-rede.
Tambm Ioi deIinido um endereo anycast para ser utilizado no suporte a mobilidade
IPv6. Este tipo de endereo Iormado pelo preIixo da sub-rede seguido pelo IID dfff:ffff:ffff:fffe
(ex.: 2001:db8::dfff:ffff:ffff:fffe). Ele utilizado pelo No Movel, quando este precisar localizar
um Agente Origem em sua Rede Original.
Mais inIormaes:
Internet Protocol Jersion 6 Anycast Aaaresses - http://www.iana.org/assignments/ipv6-anycast-
addresses
63
Endereamento
Anycast
dentifica um grupo de interfaces
Entrega o pacote apenas para a interface mais perto da origem.
Atribudos a partir de endereos unicast (so sintaticamente iguais).
Possveis utilizaes:
Descobrir servios na rede (DNS, proxy HTTP, etc.);
Balanceamento de carga;
Localizar roteadores que forneam acesso a uma determinada sub-rede;
Utilizado em redes com suporte a mobilidade Pv6, para localizar os
Agentes de Origem...
Subnet-Router
64
Endereos multicast so utilizados para identiIicar grupos de interIaces, sendo que cada
interIace pode pertencer a mais de um grupo. Os pacotes enviados para esses endereo so
entregues a todos as interIaces que compe o grupo.
No IPv4, o suporte a multicast opcional, ja que Ioi introduzido apenas como uma
extenso ao protocolo. Entretanto, no IPv6 requerido que todos os nos suportem multicast, visto
que muitas Iuncionalidades da nova verso do protocolo IP utilizam esse tipo de endereo.
Seu Iuncionamento similar ao do broaacast, dado que um unico pacote enviado a
varios hosts, diIerenciando-se apenas pelo Iato de que no broaacast o pacote enviado a todos os
hosts da rede, sem exceo, enquanto que no multicast apenas um grupo de hosts recebera esse
pacote. Deste modo, a possibilidade de transportar apenas uma copia dos dados a todos os
elementos do grupo, a partir de uma arvore de distribuio, pode reduzir a utilizao de recurso de
uma rede, bem como otimizar a entrega de dados aos hosts receptores. Aplicaes como
videoconIerncia, distribuio de video sob demanda, atualizaes de softwares e jogos on-line,
so exemplos de servios que vm ganhando notoriedade e podem utilizar as vantagens
apresentadas pelo multicast.
Os endereos multicast no devem ser utilizados como endereo de origem de um pacote.
Esses endereos derivam do bloco FF00::/8, onde o preIixo FF, que identiIica um endereo
multicast, precedido por quatro bits, que representam quatro flags, e um valor de quatro bits que
deIine o escopo do grupo multicast. Os 112 bits restantes so utilizados para identiIicar o grupo
multicast.
64
Endereamento
Multicast
dentifica um grupo de interfaces.
O suporte a multicast obrigatrio em todos os ns Pv6.
O endereo multicast deriva do bloco FF00::/8.
O prefixo FF seguido de quatro bits utilizados como flags e mais
quatro bits que definem o escopo do endereo multicast. Os 112
bits restantes so utilizados para identificar o grupo multicast.
IdentiIicador do grupo multicast FF
Flags
0RPT
Escopo
8 4 4 112
65
As flags so deIinidas da seguinte Iorma:
O primeiro bit mais a esquerda reservado e deve ser marcado com 0;
Flag R: Se o valor Ior 1, indica que o endereo multicast 'carrega o endereo de um
Ponto de Encontro (Renae:vous Point). Se o valor Ior 0, indica que no ha um
endereo de Ponto de Encontro embutido;
Flag P: Se o valor Ior 1, indica que o endereo multicast baseado em um preIixo de
rede. Se o valor Ior 0, indica que o endereo no baseado em um preIixo de rede;
Flag T: Se o valor Ior 0, indica que o endereo multicast permanente, ou seja,
atribuido pela IANA. Se o valor Ior 1, indica que o endereo multicast no
permanente, ou seja, atribuido dinamicamente.
Os quatro bits que representam o escopo do endereo multicast, so utilizados para
delimitar a area de abrangncia de um grupo multicast. Os valores atribuidos a esse
campo so o seguinte:
1 - abrange apenas a interIace local;
2 - abrange os nos de um enlace;
3 - abrange os nos de uma sub-rede
4 - abrange a menor area que pode ser conIigurada manualmente;
5 - abrange os nos de um site;
8 - abrange varios sites de uma mesma organizao;
E - abrange toda a Internet;
0, F - reservados;
6, 7, 9, A, B, C, D - no esto alocados.
Deste modo, um roteador ligado ao backbone da Internet no encaminhara pacotes
com escopo menor do que 14 (E em hexa), por exemplo. No IPv4, o escopo de um
grupo multicast especiIicado atravs do campo TTL do cabealho.
65
Endereamento
Multicast
Flags
Escopo
VaIor (4 bits hex) Descrio
1 nterface
2 Enlace
3 Sub-rede
4 Admin
5 Site
8 Organizao
E Global
(0, F) Reservados
(6, 7, 9, A, B, C, D) No-alocados
Flag VaIor (binrio) Descrio
Primeiro bit 0 Marcado como 0 (Reservado para uso futuro)
R 1 Endereo de um Ponto de Encontro (Rendezvous Point)
R 0 No representa um endereo de Ponto de Encontro
P 1 Endereo multicast baseado no prefixo da rede
P 0 Endereo multicast no baseado no prefixo da rede
T 1 Endereo multicast temporrio (no alocado pela ANA)
T 0 Endereo multicast permanente (alocado pela ANA)
66
A lista abaixo apresenta alguns endereos multicast permanentes:
Endereo Escopo Descrio
FF01::1 nterface Todas as interfaces em um n (all-nodes)
FF01::2 nterface Todos os roteadores em um n (all-routers)
FF02::1 Enlace Todos os ns do enlace (all-nodes)
FF02::2 Enlace Todos os roteadores do enlace (all-routers)
FF02::5 Enlace Roteadores OSFP
FF02::6 Enlace Roteadores OSPF designados
FF02::9 Enlace Roteadores RP
FF02::D Enlace Roteadores PM
FF02::1:2 Enlace Agentes DHCP
FF02::FFXX:XXXX Enlace Solicited-node
FF05::2 Site Todos os roteadores em um site
FF05::1:3 Site Servidores DHCP em um site
FF05::1:4 Site Agentes DHCPem um site
FF0X::101 Variado NTP (Network Time Protocol)
66
Endereamento
Multicast
Endereo Escopo Descrio
FF01::1 nterface Todas as interfaces (all-nodes)
FF01::2 nterface Todos os roteadores (all-routers)
FF02::1 Enlace Todos os ns (all-nodes)
FF02::2 Enlace Todos os roteadores (all-routers)
FF02::5 Enlace Roteadores OSFP
FF02::6 Enlace Roteadores OSPF designados
FF02::9 Enlace Roteadores RP
FF02::D Enlace Roteadores PM
FF02::1:2 Enlace Agentes DHCP
FF02::FFXX:XXXX Enlace Solicited-node
FF05::2 Site Todos os roteadores (all-routers)
FF05::1:3 Site Servidores DHCP em um site
FF05::1:4 Site Agentes DHCP em um site
FF0X::101 Variado NTP (Network Time Protocol)
67
O endereo multicast solicitea-noae identiIica um grupo multicast que todos os nos
passam a Iazer parte assim que um endereo unicast ou anycast lhes atribuido. Um endereo
solicitea-noae Iormado agregando-se ao preIixo FF02::1:FF00:0000/104 os 24 bits mais a
direita do identiIicador da interIace, e para cada endereo unicast ou anycast do no, existe um
endereo multicast solicitea-noae correspondente.
Em redes IPv6, o endereo solicitea-noae utilizado pelo protocolo de Descoberta de
Vizinhana para resolver o endereo MAC de uma interIace. Para isso, envia-se uma mensagem
Neighbor Solicitation para o endereo solicitea-noae. Com isso, apenas as interIaces registradas
neste grupo examinam o pacote. Em uma rede IPv4, para se determinar o endereo MAC de uma
interIace, envia-se uma mensagem ARP Request para o endereo broaacast da camada de enlace,
de modo que todas as interIaces do enlace examinam a mensagem.
67
Endereamento
Multicast
Endereo Solicited-Node
Todos os ns devem fazer parte deste grupo;
Formado pelo prefixo FF02::1:FF00:0000/104 agregado aos 24
bits mais a direita do D;
Utilizado pelo protocolo de Descoberta de Vizinhana (Neighbor
Discovery).
68
Com o intuito de reduzir o numero de protocolos necessarios para a alocao de endereos
multicast, Ioi deIinido um Iormato estendido de endereo multicast, que permite a alocao de
endereos baseados em preIixos unicast e de endereos SSM (source-specific multicast).
Em endereos baseados no preIixo da rede, a flag P marcada com o valor 1. Neste caso, o
uso do campo escopo no altera, porm, o escopo deste endereo multicast no deve exceder o
escopo do preIixo unicast 'carregado junto a ele. Os 8 bits apos o campo escopo, so reservados
e devem ser marcados com zeros. Na sequncia, ha 8 bits que especiIicam o tamanho do preIixo
da rede indicado nos 64 bits que os seguem. Caso o preIixo da rede seja menor que 64 bits, os bits
no utilizados no campo tamanho do preIixo, devem ser marcados com zeros. O campo
identiIicador do grupo utiliza os 32 bits restantes. Note que, em um endereo onde a flag P
marcada com o valor 1, a flag T tambm deve ser marcada com o valor 1, pois este no representa
um endereo deIinido pela IANA.
68
Endereamento
Multicast
Endereo multicast derivado de um prefixo unicast
Flag P = 1
Flag T = 1
Prefixo FF30::/12
Exemplo:
prefixo da rede = 2001:DB8::/32
endereo = FF3E:20:2001:DB8:0:0:CADE:CAFE
Reservado FF
Flags
0RPT
Escopo
8 4 4
Tamanho do
PreIixo
ID do
Grupo
8 64 32
PreIixo da
Rede
8
69
No modelo tradicional de multicast, chamado de any-source multicast (ASN), o
participante de um grupo multicast no controla de que Ionte deseja receber os dados. Com o
SSM, uma interIace pode registrar-se em um grupo multicast e especiIicar as Iontes de dados. O
SSM pode ser implementado utilizando o protocolo MLDv2 (Multicast Listener Discovery
version 2).
Para um endereo SSM, as flags P e T so marcadas com o valor 1. Os campos tamanho
do preIixo e o preIixo da rede so marcados com zeros, chegando ao preIixo FF3X::/32, onde X
o valor do escopo. O campo Endereo de Origem do cabealho IPv6 identiIica o dono do
endereo multicast. Todo endereo SSM tem o Iormato FF3X::/96.
Os mtodos de gerenciamento dos grupos multicast sero abordados no proximo modulo
deste curso.
69
Endereamento
Multicast
Endereos Multicast SSM
Prefixo: FF3X::/32
Formato do endereo: FF3X::/96
Tamanho do prefixo = 0
Prefixo = 0
Exemplo: FF3X::CADE:CAFE/96
onde X o escopo e CADE:CAFE o identificador do
grupo.
70
Tambm importante destacar algumas caracteristicas relacionadas ao endereo
apresentadas pela nova arquitetura do protocolo IPv6. Assim como no IPv4, os endereos IPv6
so atribuidos as interIaces Iisicas, e no aos nos, de modo que cada interIace precisa de pelo
menos um endereo unicast. No entanto, possivel atribuir a uma unica interIace multiplos
endereos IPv6, independentemente do tipo (unicast, multicast ou anycast) ou sub-tipo (loopback,
link local, 6to4, etc.). Deste modo um no pode ser identiIicado atravs de qualquer endereo das
suas interIaces, e com isso, torna-se necessario escolher entre seus multiplos endereos qual
utilizara como endereo de origem e destino ao estabelecer uma conexo.
Para resolver esta questo, Ioram deIinidos dois algoritmos, um para selecionar o endereo
de origem e outro para o de destino. Esses algoritmos, que devem ser implementados por todos os
nos IPv6, especiIicam o comportamento padro desse nos, porm no substituem as escolhas
Ieitas por aplicativos ou protocolos da camada superior.
Entre as regras mais importantes destacam-se:
Pares de endereos do mesmo escopo ou tipo tm preIerncia;
O menor escopo para endereo de destino tem preIerncia (utiliza-se o menor escopo
possivel);
Endereos cujo tempo de vida no expirou tem preIerncia sobre endereos com
tempo de vida expirado;
Endereos de tcnicas de transio (ISATAP, 6to4, etc.) no podem ser utilizados se
um endereo IPv6 nativo estiver disponivel;
Se todos os critrios Iorem similares, pares de endereos com o maior preIixo comum
tero preIerncia;
Para endereos de origem, endereos globais tero preIerncia sobre endereos
temporarios;
Em um No Movel, o Endereo de Origem tem preIerncia sobre um Endereo
Remoto.
70
Endereamento
Do mesmo modo que no Pv4, os endereos Pv6 so atribudos a
interfaces fsicas e no aos ns.
Com o Pv6 possvel atribuir a uma nica interface mltiplos
endereos, independentemente do seu tipo.
Com isso, um n pode ser identificado atravs de qualquer
endereo de sua interfaces.
Loopback ::1
Link Local FE80:....
Unique local FD07:...
Global 2001:....
A RFC 3484 determina o algoritmo para seleo dos endereos de
origem e destino.
71
Estas regras devem ser utilizadas quando no houver nenhuma outra especiIicao. As
especiIicaes tambm permitem a conIigurao de politicas que possam substituir esses padres
de preIerncias com combinaes entre endereos de origem e destino.
Mais inIormaes:
RFC 2375 - IPv6 Multicast Aaaress Assignments
RFC 3306 - Unicast-Prefix-basea IPv6 Multicast
RFC 3307 - Allocation Guiaelines for IPv6 Multicast Aaaresses
RFC 3484 - Default Aaaress Selection for Internet Protocol version 6 (IPv6)
RFC 3569 - An Overview of Source-Specific Multicast (SSM)
RFC 3956 - Embeaaing the Renae:vous Point (RP) Aaaress in an IPv6 Multicast Aaaress
RFC 4007 - IPv6 Scopea Aaaress Architecture
RFC 4489 - A Methoa for Generating Link-Scopea IPv6 Multicast Aaaresses
Internet Protocol Jersion 6 Multicast Aaaresses - http://www.iana.org/assignments/ipv6-
multicast-addresses/
72
72
PoIticas de aIocao e
designao
Cada RR recebe da ANA um bloco /12
O bloco 2800::/12 corresponde ao espao reservado para o
LACNC o NC.br trabalha com um /16 que faz parte deste /12
A alocao mnima para SPs um bloco /32
Alocaes maiores podem ser feitas mediante apresentao de
justificativa de utilizao
ATENO! Diferente do Pv4, com Pv6 a utilizao medida em
relao ao nmero de designaes de blocos de endereos para
usurios finais, e no em relao ao nmero de endereos
designados aos usurios finais
Na hierarquia das politicas de atribuio, alocao e designao de endereos, cada RIR
recebe da IANA um bloco /12 IPv6.
O bloco 2800::/12 corresponde ao espao reservado para o LACNIC alocar na Amrica
Latina. O NIC.br por sua vez, trabalha com um /16 que Iaz parte deste /12.
A alocao minima para ISPs um bloco /32, no entanto, alocaes maiores podem ser
Ieitas mediante apresentao de justiIicativa de utilizao. Um aspecto importante que merece
destaque que diIerente do IPv4, com IPv6 a utilizao medida em relao ao numero de
designaes de blocos de endereos para usuarios Iinais, e no em relao ao numero de
endereos designados aos usuarios Iinais.
73
73
Abordagem: one size fits all
Recomendaes para designao de endereos (RFC3177):
De um modo geral, redes /48 so recomendadas para todos os
tipos de usurios, sejam usurios domsticos, pequenos ou
grandes empresas;
Empresas muito grandes podem receber um /47, prefixos um
pouco menores, ou mltiplos /48;
Redes /64 so recomendadas quando houver certeza que uma
e apenas uma sub-rede necessria, para usurios 3G, por
exemplo;
Uma rede /128 pode ser utilizado quando houver absoluta
certeza que uma e apenas uma interface ser conectada.
Em relao a alocao e designao de endereos a usuarios Iinais, a RFC 3177 recomenda
que seja seguida uma abordagem conhecida como one si:e fits all, que apresenta as seguintes
caracteristicas:
De um modo geral, redes /48 so recomendadas para todos os tipos de usuarios, sejam
usuarios domsticos, pequenos ou grandes empresas;
Empresas muito grandes podem receber um /47, preIixos um pouco menores, ou
multiplos /48;
Redes /64 so recomendadas quando houver certeza que uma e apenas uma sub-rede
necessaria, para usuarios 3G, por exemplo;
Uma rede /128 pode ser utilizado quando houver absoluta certeza que uma e apenas
uma interIace sera conectada. Ex.: conexes PPoE.
74
74
Abordagem: one size fits all
Facilita a renumerao da rede em caso de troca de provedor
(troca de prefixo);
Permite a expanso da rede sem a necessidade de solicitar mais
endereos ao provedor;
Facilita o mapeamento entre o endereo global e o endereo
Unique Local (ULA fc00:xyzw:kImn::/48);
H redes que j utilizam prefixos /48 6to4;
Permite que se mantenha regras nicas para zonas reversas de
diversos prefixos;
Facilita a administrao;
H quem acredita que desperdia demasiados endereos e que
pode gerar problemas em algumas dcadas.
A abordagem one si:e fits all apresenta algumas vantagens:
Facilita a renumerao da rede em caso de troca de provedor (troca de preIixo);
Permite a expanso da rede sem a necessidade de solicitar mais endereos ao
provedor;
Facilita o mapeamento entre o endereo global e o endereo Unique Local (ULA
fc00:xyzw:klmn::/48);
Ha redes que ja utilizam preIixos /48 6to4;
Permite que se mantenha regras unicas para zonas reversas de diversos preIixos;
Facilita a administrao;
Ha quem acredita que desperdia demasiados endereos e que pode gerar problemas
em algumas dcadas.
75
75
Abordagem conservadora
Se usarmos one size fits all...
um /32 possibilita 65.536 /48.
No delegar /48 a todos, atribuindo um /56 para usurios
domsticos - SOHOs.
Reduz o consumo total de endereos de 6 a 7 bits.
Uma abordagem mais conservadora, oposta a one si:e fits all, recomenda que no sejam
delegados /48 a todo tipo de usuario, atribuindo /56 para usuarios domsticos e SOHO. Deste
modo, se reduz o consumo total de endereos de 6 a 7 bits.
Alm disso, um /32 possibilita 'apenas 65,536 /48, que no caso de grandes provedores,
no seria suIiciente para atender toda a sua demanda.
76
76
O que os RIRs e ISPs tm
praticado?
LACNC e AFRNC
Avaliam a requisio de blocos adicionais por parte dos SPs
baseando-se na quantidade de blocos /48 designados.
Threshold HD-Ratio = 0.94.
APNC, ARN e RPE
Avaliam a requisio de blocos adicionais por parte dos SPs
baseando-se na quantidade de blocos /56 designados.
Threshold HD-Ratio = 0.94.
HD = -------------------------------------------------
log(nmero de objetos alocados)
log(nmero de objetos alocveis)
Entre os RIRs, temos duas politicas distintas sendo praticadas em relao a recomendao
de uso aos ISPs e ao critrio para alocao de blocos de endereos adicionais.
Os RIRs LACNIC e AFRINIC, seguem a recomendao one si:e fits all, sugerindo que os
provedores de suas regies tambm o sigam. A avaliao das requisies de blocos adicionais por
parte dos ISPs tambm segue essa abordagem, baseando-se na quantidade de blocos /48
designados por eles.
Ja os RIRs APNIC, ARIN e RIPE, seguem uma abordagem mais conservadora, utilizando
a quantidade de blocos /56 designados pelos provedores como base para avaliao das requisies
de blocos adicionais.
Em todos os casos, utilizada como medida para avaliao o valor do HD-Ratio (Host-
Density ratio). O HD-Ratio um modo de medir o uso do espao de endereamento, onde seu
valor relacionado a porcentagem de uso. A Iormula para se calcular o HD-Ratio a seguinte:
HD log(numero de objetos alocados)
log(numero de objetos alocaveis)
Todos os RIRs utilizam como valor de Threshola (limite) o HD-Ratio 0,94, mas o
LACNIC e o AFRINIC sobre o a utilizao de blocos /48, e o APNIC, ARIN e o RIPE sobre a
utilizao de blocos /56.
77
77
O que os RIRs e ISPs tm
praticado?
Bloco Qtd. /48 Threshold (HD=0,94) % de
Utilizao
/32 65.536 33.689 51,41%
/31 131.072 64.634 49,31%
/30 262.144 124.002 47,30%
/29 524.288 237.901 45,38%
/28 1.048.576 456.419 43,53%
/27 2.097.152 875.653 41,75%
/26 4.194.304 1.679.965 40,05%
/25 8.388.608 3.223.061 38,42%
/24 16.777.216 6.183.533 36,86%
/23 33.554.432 11.863.283 35,36%
/22 67.108.864 22.760.044 33,92%
/21 134.217.728 43.665.787 32,53%
/20 268.435.456 83.774.045 31,21%
Esta tabela apresenta a porcentagem de utilizao de blocos /48 baseando-se no calculo do
HD-Ratio igual a 0,94.
78
78
O que os RIRs e ISPs tm
praticado?
Bloco Qtd. /56 Threshold (HD=0,94) % de
Utilizao
/32 16.777.216 6.183.533 36,86%
/31 33.554.432 11.863.283 35,36%
/30 67.108.864 22.760.044 33,92%
/29 134.217.728 43.665.787 32,53%
/28 268.435.456 83.774.045 31,21%
/27 536.870.912 160.722.871 29,94%
/26 1.073.741.824 308.351.367 28,72%
/25 2.147.483.648 591.580.804 27,55%
/24 4.294.967.296 1.134.964.479 26,43%
/23 8.589.934.592 2.177.461.403 25,35%
/22 17.179.869.184 4.177.521.189 24,32%
/21 34.359.738.368 8.014.692.369 23,33%
/20 68.719.476.736 15.376.413.635 22,38%
Esta tabela apresenta a porcentagem de utilizao de blocos /56 baseando-se no calculo do
HD-Ratio igual a 0,94.
79
79
Provedores
NTT Communications
Japo
Pv6 nativo (ADSL)
/48 a usurios finais
http://www.ntt.com/business_e/service/category/nw_ipv6.html
nternode
Australia
Pv6 nativo (ADSL)
/64 dinmico para sesses PPP
Delega /60 fixos
http://ipv6.internode.on.net/configuration/adsl-faq-guide/
Em relao a politica seguida por alguns provedores no mundo que ja Iornecem a seus
clientes endereos IPv6, temos algumas vises diIerentes. Analise os seguinte exemplos:
NTT Communications
Japo
IPv6 nativo (ADSL)
/48 a usuarios Iinais
http://www.ntt.com/businesse/service/category/nwipv6.html
Internode
Australia
IPv6 nativo (ADSL)
/64 dinmico para sesses PPP
Delega /60 Iixos
http://ipv6.internode.on.net/conIiguration/adsl-Iaq-guide/
IIJ
Japo
Tuneis
/48 a usuarios Iinais
http://www.iij.ad.jp/en/service/IPv6/index.html
Arcnet6
Malasia
IPv6 nativo (ADSL) ou Tuneis
/48 a usuarios Iinais
/40 e /44 podem ser alocados (depende de aprovao)
http://arcnet6.net.my/how.html
80
80
Provedores
Japo
Tneis
/48 a usurios finais
http://www.iij.ad.jp/en/service/Pv6/index.html
Arcnet6
Malsia
Pv6 nativo (ADSL) ou Tneis
/48 a usurios finais
/40 e /44 podem ser alocados (depende de aprovao)
http://arcnet6.net.my/how.html
81
81
Consideraes
/32 =
65 mil redes /48 (33 mil, se considerarmos desperdcio)
16 milhes de redes /56 (6 milhes, se cons. hd ratio)
suficiente para seu provedor?
Reservar um bloco (/48 ?) para infraestrutura.
Links ponto a ponto:
/64? /112? /120? /126? /127?
RFC 3531
|--|--|--|--|--|--|--|--
1 | | | 2 | | |
| 3 | | 4 |
5 7 6 8
Antes de solicitar um bloco de endereos IPv6 preciso elaborar cuidadosamente o plano
de endereamento da rede. Neste momento, alguns aspectos importantes precisam ser
considerados:
Um bloco /32 permite 65 mil redes /48, ou 33 mil, se considerarmos desperdicio; 16
milhes de redes /56, ou 6 milhes, se considerarmos o HD-ratio. Cada provedor devera analisar
se esses valores atendem as suas necessidades, ou se sera necessario solicitar ao Registro de
Internet um bloco de endereos maior.
Tambm preciso considerar os endereos que sero utilizados para inIraestrutura, qual
tamanho de bloco sera reservado para as redes internas, para links ponto-a-ponto, etc.
A RFC 3531 prope um mtodo para gerenciar a atribuio dos bits de um bloco de
endereos IPv6 ou de um preIixo, de modo que estes sejam alocados reservando um espao maior
entre eles. Com isso, caso seja necessario alocar novos blocos a um usuario, a probabilidade de se
alocar blocos contiguos ao que ele ja possui sera maior.
|--|--|--|--|--|--|--|--
1 | | | 2 | | |
| 3 | | 4 |
5 7 6 8
82
82
Exerccio de endereamento
IPv6
Voc um provedor e recebeu o bloco 2001:0db8::/32
Voc est presente em vrias localidades (5 estados diferentes) e
tem planos de expanso.
Voc atende a usurios domsticos, a pequenas, mdias e grandes
empresas.
Sera proposto agora um exercicio rapido de planejamento de endereamento:
Voc um provedor e recebeu o bloco 2001:0db8::/32
Voc esta presente em varias localidades (5 estados diIerentes) e tem planos de
expanso.
Voc atende a usuarios domsticos, a pequenas, mdias e grandes empresas.
Trabalhe com os seguintes pontos:
(1) Voc decidiu que a melhor Iorma de dividir os endereos hierarquicamente... Qual o
tamanho do bloco de cada estado?
(2) Qual o tamanho do bloco a ser designado para cada tipo de usuario?
(3) Quantos usuarios de cada tipo podero ser atendidos dessa Iorma?
(4) Indique o bloco correspondente a cada localidade.
(5) Escolha uma localidade e indique os blocos correspondentes a cada tipo de usuario
(6) Nessa mesma localidade, indique o primeiro e o segundo blocos designados para cada
tipo de usuario (os 2 primeiros usuarios de cada tipo)
(7) Para o segundo bloco/usuario de cada tipo, indique o primeiro e o ultimo endereos.
83
83
Exerccio de endereamento
IPv6
(1) Voc decidiu que a melhor forma de dividir os endereos
hierarquicamente... Qual o tamanho do bloco de cada estado?
(2) Qual o tamanho do bloco a ser designado para cada tipo de
usurio?
(3) Quantos usurios de cada tipo podero ser atendidos dessa
forma?
(4) ndique o bloco correspondente a cada localidade.
(5) Escolha uma localidade e indique os blocos correspondentes a
cada tipo de usurio
(6) Nessa mesma localidade, indique o primeiro e o segundo
blocos designados para cada tipo de usurio (os 2 primeiros
usurios de cada tipo)
(7) Para o segundo bloco/usurio de cada tipo, indique o primeiro e
o ltimo endereos.
84
Mais InIormaes:
RFC 5375 - IPv6 Unicast Aaaress Assignment Consiaerations
RFC 3177 - IAB/IESG Recommendations on IPv6 Address Allocations to Sites
RFC 3531 - A Flexible Methoa for Managing the Assignment of Bits of an IPv6 Aaaress Block
RFC 3627 - Use of /127 Prefix Length Between Routers Consiaerea Harmful
RFC 3194 - The Host-Density Ratio for Aaaress Assignment Efficiency. An upaate on the HD ratio
RFC 4692 - Consiaerations on the IPv6 Host Density Metric
http://www.potaroo.net/ispcol/2005-07/ipv6size.html
http://www.lacnic.net/en/politicas/manual12.html
http://tools.ietI.org/html/draIt-narten-ipv6-3177bis-48boundary-04
https://www.arin.net/policy/proposals/20058.html
http://www.apnic.net/policy/ipv6-address-policy#2.7
http://www.ripe.net/ripe/docs/ipv6-sparse.html
http://www.ipv6book.ca/allocation.html
http://tools.ietI.org/html/draIt-kohno-ipv6-preIixlen-p2p-00
http://www.swinog.ch/meetings/swinog18/swissixswinog18.pdI
https://www.arin.net/participate/meetings/reports/ARINXXIV/PDF/wednesday/ipv6implementationIundamentals.pdI
http://www.6deploy.org/workshops/20090921bogotacolombia/ConsulintelIPv63-DireccionamientoIPv6.pdI
85
85
86
O protocolo IPv6 apresenta uma srie de novas Iuncionalidades e outras aprimoradas em
relao ao IPv4.
Na primeira parte deste modulo, conheceremos um pouco mais sobre essas
Iuncionalidades, comeando pelo estudo do protocolo ICMPv6 (Internet Control Message
Protocol version 6), pea Iundamental para a execuo de Ierramentas como o protocolo de
Descoberta de Vizinhana (Neighbor Discovery) e o mecanismos de autoconIigurao stateless,
tambm tratados aqui. Por analisaremos o Iuncionamento do protocolo DHCPv6 e como estas
Iuncionalidades podem auxiliar no trabalho de renumerao de redes.
86
FuncionaIidades do
IPv6 #1
MduIo 4
87
DeIinido na RFC 4443 para ser utilizado com o IPv6, o ICMPv6 uma verso atualizada
do ICMP (Internet Control Message Protocol) utilizado com IPv4.
Esta nova verso do ICMP, embora apresente as mesma Iunes que o ICMPv4, como
reportar erros no processamento de pacotes e enviar mensagens sobre o status a as caracteristicas
da rede, ela no compativel com seu antecessor, apresentando agora um numero maior de
mensagens e Iuncionalidades.
O ICMPv6, agora o responsavel por realizar as Iunes dos protocolos ARP (Aaaress
Resolution Protocol), que mapeia os endereos da camada dois para IPs e vice-versa no IPv4, e do
IGMP (Internet Group Management Protocol), que gerencia os membros dos grupos multicast no
IPv4.
O valor no campo Proximo Cabealho, que indica a presena do protocolo ICMPv6, 58,
e o suporte a este protocolo deve ser implementado em todos os nos.
87
Definido na RFC 4443.
Mesmas funes do CMPv4 (mas no so compatveis):
nformar caractersticas da rede;
Realizar diagnsticos;
Relatar erros no processamento de pacotes.
Assume as funcionalidades de outros protocolos:
ARP/RARP
GMP
dentificado pelo valor 58 no campo Prximo Cabealho.
Deve ser implementado em todos os ns.
ICMPv6
88
Em um pacote IPv6, o ICMPv6 posiciona-se logo apos o cabealho base do IPv6, e dos
cabealhos de extenso, se houver.
O ICMPv6, um protocolo chave na arquitetura IPv6, visto que, alm do gerenciamento
dos grupos multicast, atravs do protocolo MLD (Multicast Listener Discovery), e da resoluo de
endereos da camada dois, suas mensagens so essenciais para o Iuncionamento do protocolo de
Descoberta de Vizinhana (Neighbor Discovery), responsavel por localizar roteadores vizinhos na
rede, detectar mudanas de endereo no enlace, detectar endereos duplicados, etc.; no suporte a
mobilidade, gerenciando Endereos de Origem dos hosts dinamicamente; e no processo de
descoberta do menor MTU (Maximum Transmit Unit) no caminho de uma pacote at o destino.
88
precedido pelos cabealhos de extenso, se houver, e pelo
cabealho base do Pv6.
Protocolo chave da arquitetura Pv6.
Essencial em funcionalidades do Pv6:
Gerenciamento de grupos multicast;
Descoberta de Vizinhana (Neighbor Discovery);
Mobilidade Pv6;
Descoberta do Path MTU.
ICMPv6
Pv6
cadeia de
cab. de extenso
CMPv6
89
O cabealho de todas as mensagens ICMPv6 tem a mesma estrutura simples, sendo
composto por quatro campos:
Tipo: especiIica o tipo da mensagem, o que determinara o Iormato do corpo da
mensagem. Seu tamanho de oito bits;
Cdigo: oIerece algumas inIormaes adicionais para determinados tipos de
mensagens. Tambm possui oito bits de tamanho;
Soma de Verificao: utilizado para detectar dados corrompidos no cabealho
ICMPv6 e em parte do cabealho IPv6. Seu tamanho de 16 bits;
Dados: apresenta as inIormaes de diagnostico e erro de acordo com o tipo de
mensagem. Para ajudar na soluo de problemas, as mensagens de erro traro neste
campo, o pacote que invocou a mensagem, desde que o tamanho total do pacote
ICMPv6 no exceda o MTU minimo do IPv6, que 1280 Bytes.
89
Cabealho simples
Tipo (8 bits): especifica o tipo da mensagem.
Cdigo (8 bits): oferece algumas informaes adicionais para
determinados tipos de mensagens.
Soma de Verificao (16 bits): utilizado para detectar dados
corrompidos no cabealho CMPv6 e em parte do cabealho
Pv6.
Dados: apresenta as informaes de diagnstico e erro de
acordo com o tipo de mensagem. Seu tamanho pode variar de
acordo com a mensagem.
ICMPv6
90
As mensagens ICMPv6 so divididas em duas classes, cada uma composta por diversos
tipos de mensagens, conIorme as tabelas a seguir:
Mensagens de Erro:
Tipo Nome Descrio
1 Destnaton Unreachabe
2 Packet Too Bg
3 Tme Exceeded
4 Parameter Probem
100-101
102-126
127 Reservado para expanso das mensagens de
erro ICMPv6
No utzado
Uso expermenta
Indca fahas na entrega do pacote como
endereo ou porta desconhecda ou probemas
na comuncao.
Indca que o tamanho do pacote maor que a
Undade Mxma de Transto (MTU) de um
enace.
Indca que o Lmte de Encamnhamento ou o
tempo de remontagem do pacote fo exceddo.
Indca erro em agum campo do cabeaho IPv6
ou que o tpo ndcado no campo Prxmo
Cabeaho no fo reconhecdo.
90
Possui duas classes de mensagens:
Mensagens de Erro
Destination Unreachable
Packet Too Big
Time Exceeded
Parameter Problem
Mensagens de nformao
Echo Request e Echo Reply
Multicast Listener Query
Multicast Listener Report
Multicast Listener Done
Router Solicitation e Router Advertisement
Neighbor Solicitation e Neighbor Advertisement
Redirect...
ICMPv6
91
Mensagens de InIormao
Tipo Nome Descrio
128 Echo Request
129 Echo Repy
130 Mutcast Lstener Ouery
131 Mutcast Lstener Report
132 Mutcast Lstener Done
133 Router Soctaton
134 Router Advertsement
135 Neghbor Soctaton
136 Neghbor Advertsement
137 Redrect Message
138 Router Renumberng
139 ICMP Node Informaton Ouery
140 ICMP Node Informaton Response
Utzadas peo comando png.
Utzadas no gerencamento de grupos
multicast.
Utzadas com o protocoo Descoberta
de Vznhana.
Utzada no mecansmo de Re-
endereamento (Renumbering) de
roteadores.
Utzadas para descobrr nformaes
sobre nomes e endereos, so atuamente
mtadas a ferramentas de dagnstco,
depurao e gesto de redes.
141 Inverse ND Soctaton Message
142 Inverse ND Advertsement Message
143 Verson 2 Mutcast Lstener Report
144 HA Address Dscovery Req. Message
145 HA Address Dscovery Repy Message
146 Mobe Prefx Soctaton
147 Mobe Prefx Advertsement
148 Certfcaton Path Soctaton Message
149 Cert. Path Advertsement Message
150
151 Mutcast Router Advertsement
152 Mutcast Router Soctaton
153 Mutcast Router Termnaton
154 FMIPv6 Messages
200-201
255
Utzadas em uma extenso do protocoo
de Descoberta de Vznhana.
Utzada no gerencamento de grupos
multicast.
Utzadas no mecansmo de Mobdade
IPv6.
Utzadas peo protocoo SEND.
Reservado para expanso das
mensagens de erro ICMPv6
Uso Expermenta
Utzada expermentamente com
protocoos de mobdade como o
5eamoby.
Utzadas peo mecansmo Multicast
Router Discovery
Utzada peo protocoo de mobdade
Fast Handovers
92
DeIinido pela RFC4861, o protocolo de Descoberta de Vizinhana torna mais dinmicos
alguns processos de conIigurao de rede em relao ao IPv4, combinando as Iunes de
protocolos como ARP, ICMP Router Discovery e ICMP Reairect, alm de adicionar novos
mtodos no existentes na verso anterior do protocolo IP.
O protocolo de Descoberta de Vizinhana do IPv6 utilizado por hosts e roteadores para
os seguintes propositos:
determinar o endereo MAC dos nos da rede;
encontrar roteadores vizinhos;
determinar preIixos e outras inIormaes de conIigurao da rede;
detectar endereos duplicados;
determinar a acessibilidades dos roteadores;
redirecionamento de pacotes;
autoconIigurao de endereos.
92
Neighbor Discovery definido na RFC 4861.
Assume as funes de protocolos ARP, ICMP Router Discovery e
ICMP Redirect, do Pv4.
Adiciona novos mtodos no existentes na verso anterior do
protocolo P.
Torna mais dinmico alguns processos de configurao de rede:
determinar o endereo MAC dos ns da rede;
encontrar roteadores vizinhos;
determinar prefixos e outras informaes de configurao da rede;
detectar endereos duplicados;
determinar a acessibilidades dos roteadores;
redirecionamento de pacotes;
autoconfigurao de endereos.
Descoberta de Vizinhana
93
As mensagens Neighbor Discovery so conIiguradas com um Limite de Encaminhamento
de 255 para assegurar que as mensagens recebidas so originadas de um no do mesmo enlace,
descartando as mensagens com valores diIerentes.
O Neighbor Discovery utiliza cinco mensagens ICMPv6:
Router Solicitation (ICMPv6 tipo 133): utilizada por hosts para requisitar aos
roteadores mensagens Router Aavertisements imediatamente. Normalmente
enviada para o endereo multicast FF02::2 (all-routers on link);
Router Advertisement (ICMPv6 tipo 134): enviada periodicamente, ou em resposta
a uma Router Solicitation, utilizada pelos roteadores para anunciar sua presena
em um enlace. As mensagens periodicas so enviadas para o endereo multicast
FF02::1 (all-noaes on link) e as solicitadas so enviadas diretamente para o
endereo do solicitante. Uma RA carrega diversas inIormaes reIerentes a
conIiguraes da rede como:
O valor padro do enlace para o campo Limite de Encaminhamento;
Uma flag especiIicando se deve ser utilizado autoconIigurao stateless ou
stateful,
Outra flag que especiIica se os nos devem utilizar conIiguraes stateful para
obter outras inIormaes sobre a rede;
Uma terceira flag utilizada em redes com suporte a mobilidade IPv6, para
indicar se o roteador um Agente de Origem;
93
Utiliza 5 tipos de mensagens CMPv6:
Router Solicitation (RS) CMPv6 Tipo 133;
Router Advertisement (RA) CMPv6 Tipo 134;
Neighbor Solicitation (NS) CMPv6 Tipo 135;
Neighbor Advertisement (NA) CMPv6 Tipo 136;
Redirect CMPv6 Tipo 137.
So configuradas com o valor 255 no campo Limite de Encaminhamento.
Podem conter, ou no, opes:
Source link-layer address.
Target link-layer address.
Prefix information.
Redirected header.
MTU.
Descoberta de Vizinhana
94
Por quanto tempo, em segundos, o roteador sera considerado o roteador padro
do enlace. Caso no seja o roteador padro o valor sera zero;
O tempo que um host pressupe que os vizinhos so alcanaveis apos ter
recebido uma conIirmao de acessibilidade;
O intervalo entre o envio de mensagens Neighbor Solicitation.
Aeighbor Solicitation (ICMPv6 tipo 135): mensagem multicast enviada por um no
para determinar o endereo MAC e a acessibilidade de um vizinho, alm de detectar
a existncia de endereos duplicados. Esta mensagem possui um campo para indicar
o endereo de origem da mensagem;
Aeighbor Advertisement (ICMPv6 tipo 136): enviada como resposta a uma
Neighbor Solicitation, pode tambm ser enviada para anunciar a mudana de algum
endereo dentro do enlace. Esta mensagem possui trs flags.
A primeira indica se quem esta enviando a mensagem um roteador;
A segunda indica se a mensagem uma resposta a uma NS;
A terceira indica se a inIormao carregada na mensagem uma atualizao de
endereo de algum no da rede.
Redirect (ICMPv6 tipo 137): utilizada por roteadores para inIormar ao host o
melhor roteador para encaminhar o pacote ao destino. Esta mensagem traz como
inIormao, o endereo do roteador considerado o melhor salto, o endereo do no
que esta sendo redirecionado.
Estas mensagens podem trazer zero ou mais opes, deIinidas na RFC 4861:
Source link-layer address. contm o endereo MAC do remetente do pacote. E
utilizada nas mensagens NS, RS, e RA;
1arget link-layer address: contm o endereo MAC de destino do pacote. E
utilizada nas mensagens NA e Reairect;
Prefix information: Iornea a hosts os preIixos do enlace e os preIixos para
autoconIigurao do endereo. E utilizada nas mensagens RA;
Redirected header: contm todo ou parte do pacote que esta sendo redirecionado. E
utilizada nas mensagens Reairect; e
MTU: indica o valor do MTU do enlace. E utilizada nas mensagens RA.
Novas opes Ioram deIinidas para novas Iuncionalidades do protocolo de Descoberta
de Vizinhana. Estas opes sero detalhadas conIorme essas novas Iunes Iorem apresentadas.
95
Esta Iuncionalidade utilizada para determinar o endereo MAC dos vizinhos do mesmo
enlace, onde um host envia uma mensagem NS para o endereo multicast solicitea noae do
vizinho, inIormando seu endereo MAC.
95
Descoberta de Vizinhana
Descoberta de Endereos da Camada de Enlace
Determina o endereo MAC dos vizinhos do mesmo enlace.
Substitui o protocolo ARP.
Utiliza o endereo multicast solicited-node em vez de broadcast.
O host envia uma mensagem NS informando seu endereo MAC e
solicita o endereo MAC do vizinho.
96
Ao receber a mensagem, o vizinho a responde enviando uma mensagem NA inIormando
seu endereo MAC.
Esta caracteristica do protocolo Descoberta de Vizinhana substitui, no IPv6, o protocolo
ARP do IPv4, utilizando no lugar de um endereo broaacast, o endereo multicast solicitea-noae
como endereo de destino.
96
Descoberta de Endereos da Camada de Enlace
Determina o endereo MAC dos vizinhos do mesmo enlace.
Substitui o protocolo ARP.
Utiliza o endereo multicast solicited-node em vez de broadcast.
O host envia uma mensagem NS informando seu endereo MAC e
solicita o endereo MAC do vizinho.
O vizinho responde enviando uma mensagem NA informando seu
endereo MAC.
Descoberta de Vizinhana
97
Esta Iuncionalidade do protocolo de Descoberta de Vizinhana utilizada para localizar
roteadores vizinhos dentro do mesmo enlace, bem como aprender preIixos e parmetros
relacionados a autoconIigurao de endereo.
Estas inIormaes so enviadas a partir de um roteador local, atravs de mensagens RA
encaminhadas para o endereo multicast all-noaes.
No IPv4, o mapeamento dos endereos da rede local so realizados atravs de mensagens
ARP Request.
97
Descoberta de Roteadores e Prefixos
Localizar roteadores vizinhos dentro do mesmo enlace.
Determina prefixos e parmetros relacionados autoconfigurao de
endereo.
No Pv4, est funo realizada pelas mensagens ARP Request.
Roteadores enviam mensagens RA para o endereo multicast all-
nodes.
Descoberta de Vizinhana
98
A Deteco de Endereos Duplicados o procedimento utilizado pelos nos para veriIicar a
unicidade dos endereos em um enlace, devendo ser realizado antes de se atribuir qualquer
endereo unicast a uma interIace, independentemente de este ter sido obtido atravs de
autoconIigurao stateless, DHCPv6, ou conIigurao manual.
Este mecanismo consiste no envio de uma mensagem NS pelo host, com o campo target
aaaress preenchido com seu proprio endereo. Caso alguma mensagem NA seja recebida em
resposta, isso indicara que o endereo ja esta sendo utilizado e o processo de conIigurao deve
ser interrompido.
No IPv4, os nos utilizam mensagens ARP Request e o mtodo chamado gratuitous ARP
para detectar endereos unicast duplicados dentro do mesmo enlace, deIinindo os campos Source
Protocol Aaaress e Target Protocol Aaaress, do cabealho da mensagem ARP Request, com o
endereo IPv4 que esta sendo veriIicado.
98
Deteco de Endereos Duplicados
Verifica a unicidade dos endereos de um n dentro do enlace.
Deve ser realizado antes de se atribuir qualquer endereo
unicast a uma interface.
Consiste no envio de uma mensagem NS pelo host, com o
campo target address preenchido com seu prprio endereo.
Caso alguma mensagem NA seja recebida como resposta, isso
indicar que o endereo j est sendo utilizado.
Descoberta de Vizinhana
99
Este mecanismo utilizado na comunicao host-a-host, host-a-roteaaor, e roteaaor-a-
host para rastrear a acessibilidade dos nos ao longo do caminho.
Um no considera um vizinho acessivel se ele recebeu recentemente a conIirmao de
entrega de algum pacote a esse vizinho. Essa conIirmao pode ocorrer de dois modos: ser uma
resposta a uma mensagem do protocolo de Descoberta de Vizinhana; ou algum processo da
camada de transporte que indique que uma conexo Ioi estabelecida.
Esse processo apenas executado quando os pacotes so enviados a um endereo unicast,
no sendo utilizado no envio para endereos multicast.
Para acompanhar os estados de um vizinho, o no IPv6 utiliza duas importantes tabelas:
Aeighbor Cache mantem uma lista de vizinhos locais para os quais Ioi enviado
traIego recentemente, armazenado seus endereos IP, inIormaes sobre o
endereo MAC e um flag indicando se o vizinho um roteador ou um host.
Tambm inIorma se ainda ha pacotes na Iila para serem enviados, a acessibilidade
dos vizinhos e a proxima vez que um evento de deteco de vizinhos inacessiveis
esta agendado. Esta tabela pode ser comparada a tabela ARP do IPv4.
Destination Cache mantem inIormaes sobre destinos para os quais Ioi
enviado traIego recentemente, incluindo tanto destinos locais quanto remotos,
sendo atualizado com inIormaes recebidas por mensagens Reairect. O Neighbor
Cache pode ser considerado um subconjunto das inIormaes do Destination
Cache.
99
Deteco de Vizinhos Inacessveis
Utilizado para rastrear a acessibilidade dos ns ao longo do
caminho.
Um n considera um vizinho acessvel se ele recebeu
recentemente a confirmao de entrega de algum pacote a esse
vizinho.
Pode ser uma resposta a mensagens do protocolo de
Descoberta de Vizinhana ou algum processo da camada de
transporte que indique que uma conexo foi estabelecida.
Executado apenas para endereos unicast.
Neighbor Cache (similar a tabela ARP).
Destination Cache.
Descoberta de Vizinhana
100
Mensagens Reairect so enviadas por roteadores para redirecionar um host
automaticamente a um roteador mais apropriado ou para inIormar ao host que destino encontra-se
no mesmo enlace. Este mecanismo igual ao que existe no IPv4.
100
Redirecionamento
Envia mensagens Redirect
Redireciona um host para um roteador mais apropriado para o primeiro
salto.
nformar ao host que destino encontra-se no mesmo enlace.
Este mecanismo igual ao existente no Pv4.
Descoberta de Vizinhana
Pacote Pv6
101
101
Redirecionamento
Envia mensagens Redirect
Redireciona um host para um roteador mais apropriado para o primeiro
salto.
nformar ao host que destino encontra-se no mesmo enlace.
Este mecanismo igual ao existente no Pv4.
Descoberta de Vizinhana
102
102
Redirecionamento
Envia mensagens Redirect
Redireciona um host para um roteador mais apropriado para o primeiro
salto.
nformar ao host que destino encontra-se no mesmo enlace.
Este mecanismo igual ao existente no Pv4.
Descoberta de Vizinhana
Pacotes Pv6
subsequentes
103
O mecanismo de autoconIigurao stateless, deIinido na RFC 4862, permite que endereos
IPv6 sejam atribuidos as interIaces sem a necessidade de conIiguraes manuais, sem a utilizao
de servidores adicionais (DHCP), apenas com conIiguraes minimas de roteadores.
Para gerar o endereo IP, um host utiliza uma combinao entre dados locais, como o
endereo MAC da interIace ou um valor randmico para gerar o ID, e inIormaes recebidas dos
roteadores, como multiplos preIixos. Se no houver roteadores presentes, o host gera apenas o
endereo link local com o preIixo FE80::.
Roteadores so utilizam este mecanismo para gerar endereos link-local. Seus endereos
globais devem ser conIigurados de outra Iorma.
103
Autoconfigurao de Endereos Stateless
Mecanismo que permite a atribuio de endereos unicast aos
ns...
sem a necessidade de configuraes manuais.
sem servidores adicionais.
apenas com configuraes mnimas dos roteadores.
Gera endereos P a partir de informaes enviadas pelos
roteadores e de dados locais como o endereo MAC.
Gera um endereo para cada prefixo informado nas
mensagens RA
Se no houver roteadores presentes na rede, gerado apenas
um endereo link local.
Roteadores utilizam apenas para gerar endereos link-local.
Descoberta de Vizinhana
104
O mecanismo de autoconIigurao de endereos executado respeitando os seguintes
passo:
Um endereo link-local gerado anexando ao preIixo FE80::/64 o identiIicador da
interIace;
Esse endereo passa a Iazer parte dos grupos multicast solicitea-noae e all-noae,
E Ieita a veriIicao da unicidade do endereo de link-local gerado,
Caso outro no no enlace esteja utilizando o mesmo endereo, o processo de
autoconIigurao interrompido, exigindo uma conIigurao manual;
Se o endereo Ior considerado unico e valido, ele sera automaticamente inicializado
para a interIace;
O host envia uma mensagem Router Solicitation para o grupo multicast all-routers,
Todos os roteadores do enlace respondem com uma mensagem Router Aavertisement
inIormando: os roteadores padro; um valor predeIinido para o campo Limite de
Encaminhamento; o MTU do enlace; a lista de preIixos da rede, para os quais tambm
sero gerados endereos automaticamente.
104
Autoconfigurao de Endereos Stateless
Um endereo link-local gerado.
Prefixo FE80::/64 + identificador da interface.
Endereo adicionado aos grupos multicast solicited-node e all-node.
Verifica-se a unicidade do endereo.
Se j estiver sendo utilizado, o processo interrompido, exigindo uma
configurao manual.
Se for considerado nico e vlido, ele ser atribudo interface.
Host envia uma mensagem RS para o grupo multicast all-routers.
Todos os roteadores do enlace respondem com mensagem RA.
Estados dos endereos:
Endereo de Tentativa;
Endereo Preferencial;
Endereo Depreciado;
Endereo Vlido;
Endereo nvlido.
Descoberta de Vizinhana
105
Um endereo IPv6 pode assumir diIerentes estados:
Endereo de Tentativa endereo qua ainda no Ioi atribuido. E o estado anterior a
atribuio, enquanto o processo de DAD realizado. No pode ser utilizado na
comunicao do no, apenas por mensagens relativas a Descoberta de Vizinhana;
Endereo PreIerencial endereo atribuido a interIace e pode ser utilizado sem
restries, at expirar seu tempo de vida;
Endereo Depreciado endereo cujo tempo de vida expirou. Pode ser utilizado para
continuar as comunicaes abertas por ele, mas no para iniciar novas comunicaes;
Endereo Valido termo utilizado para designar tanto os endereos preIerenciais quanto
os depreciados;
Endereo Invalido endereo que no pode ser atribuido a uma interIace. Um endereo
se torna invalido quando seu tempo de vida expira.
106
O Dynamic Host Configuration Protocol (DHCP) um protocolo de autoconIigurao
stateful utilizado na distribuio de endereos IP dinamicamente em uma rede, a partir de um
servidor DHCP, Iornecendo um controle maior na atribuio de endereos aos host.
DeIinido na RFC 3315 o DHCPv6 uma opo ao mecanismo de autoconIigurao
stateless do IPv6, podendo ser utilizado quando no ha roteadores na rede, ou quando seu uso Ior
indicado nas mensagens RA, sendo capaz de Iornecer endereos IPv6 e diversos parmetros de
rede, como endereos de servidores DNS, NTP, SIP, etc.
No DHCPv6, a troca de mensagens entre cliente e servidor realizada utilizando-se o
protocolo UDP. Os clientes utilizam um endereo link-local para transmitir ou receber mensagens
DHCP, enquanto que os servidores utilizam um endereo multicast reservado (FF02::1:2 ou
FF05::1:3) para receber mensagens dos clientes. Caso o cliente necessite enviar uma mensagem a
um servidor que esteja Iora de sua sub-rede, utilizado um Relay DHCP.
106
Autoconfigurao de Endereos Stateful
Usado pelo sistema quando nenhum roteador encontrado.
Usado pelo sistema quando indicado nas mensagens RA.
Fornece:
Endereos Pv6
Outros parmetros (servidores DNS, NTP...)
Clientes utilizam um endereo link-local para transmitir ou receber
mensagens DHCP.
Servidores utilizam endereos multicast para receber mensagens
dos clientes (FF02::1:2 ou FF05::1:3).
Clientes enviam mensagens a servidores fora de seu enlace
utilizando um Relay DHCP.
DHCPv6
107
A utilizao de DHCPv6 oIerece um controle maior na atribuio de endereos, visto que,
alm de Iornecer opes de conIigurao de rede, possivel deIinir politicas de alocao de
endereos e atribuir endereos aos hosts que no sejam derivados do endereo MAC.
Em uma rede IPv6, possivel combinar o uso de autoconIigurao stateless com
servidores DHCP. Neste cenario, possivel por exemplo, utilizar autoconIigurao stateless na
atribuio de endereos aos hosts e servidores DHCPv6 para Iornecer inIormaes adicionais de
conIigurao, como o endereo de servidores DNS.
Os protocolos DHCPv6 e DHCPv4 so independentes, de modo que, em uma rede com
Pilha Dupla, sera necessario rodar um servio para cada protocolo. Com DHCPv4, preciso
conIigurar no cliente se este usara DHCP, enquanto que com o DHCPv6, sua utilizao indicada
atravs das opes das mensagens RA.
107
Autoconfigurao de Endereos Stateful
Permite um controle maior na atribuio de endereos aos host.
Os mecanismos de autoconfigurao de endereos stateful e
stateless podem ser utilizados simultaneamente.
Por exemplo: utilizar autoconfigurao stateless para atribuir
os endereos e DHCPv6 para informar o endereo do
servidor DNS.
DHCPv6 e DHCPv4 so independentes. Redes com Pilha Dupla
precisam de servios DHCP separados.
DHCPv6
108
O endereamento de uma rede muitas vezes baseado nos preIixos atribuidos por ISPs.
No caso de uma mudana de provedor, necessario renumerar todos os endereos da rede.
No IPv6, o processo de reendereamento dos hosts pode ser Ieito de Iorma relativamente
simples. Atravs dos mecanismos do protocolo de Descoberta de Vizinhana, um novo preIixo
pode ser anunciado pelo roteador a todos os hosts do enlace. E possivel tambm, a utilizao de
servidores DHCPv6. Para tratar a conIigurao e reconIigurao dos preIixos nos roteadores to
Iacilmente quanto nos hosts, Ioi deIinido na RFC 2894, o protocolo Router Renumbering.
O mecanismo Router Renumbering utiliza mensagens ICMPv6 do tipo 138, enviadas aos
roteadores, atravs do endereo multicast all-routers, contendo as instrues de como atualizar
seus preIixos.
As mensagens Router Renumbering so Iormadas pelos seguintes campos:
Tipo - 138 (decimal);
Codigo - 0 para mensagens de Comando;
1 para mensagens de Resultado;
255 para Zerar Numero Sequencial;
108
Hosts Autoconfigurao stateless ou DHCPv6
Roteadores Router Renumbering
Mensagens CMPv6 Tipo 138
Formato da Mensagem
Cabealho RR + Corpo da Mensagem
Renumerao da Rede
Nmero de
Segmento
Cdigo Tipo Soma de Verificao
Nmero Sequencial
Flags Atraso Mximo
Reservado
Corpo da Mensagem
Mensagem de Comando / Mensagem de Resultado
109
Soma de VeriIicao veriIica a integridade da mensagem ICMPv6 e de parte do
cabealho IPv6;
Numero Sequencial identiIica as operaes;
Numero de Segmento enumera diIerentes mensagens RR validas que tenham o mesmo
Numero Sequencial.
Flags T: indica se a conIigurao do roteador deve ser modiIicada, ou se um
teste;
R: indica se uma mensagem de Resultado deve ser enviada;
A: indica se o comando deve ser aplicado a todas as interIaces, independente do
seu estado;
S: indica que o comando deve ser aplicado a todas as interIaces, independente de
qual sub-rede pertenam;
P: indica que a mensagem de Resultado contm o relatorio completo do
processamento da mensagem de Comando, ou que a mensagem de Comando Ioi
previamente tratada (e no um teste) e que o roteador no esta processando-a
novamente.
Atraso Maximo - especiIica o tempo maximo, em milisegundos, que um roteador deve
atrasar o envio de qualquer resposta a mensagem de Comando.
As mensagens de Comando so Iormadas por sequencias de operaes, Match-Prefix e
Use-Prefix. O Match-Prefix indica qual preIixo deve ser modiIicado, e o Use-Prefix indica o novo
preIixo. As operaes podem ser ADD, CHANGE, ou SET-GLOBAL, que instruem,
respectivamente, o roteador a adicionar os preIixos indicados em Use-Prefix ao conjunto de
preIixos conIigurados; a remover o preIixo indicado em Match-Prefix, se existirem, e troca-los
pelos contidos em Use-Prefix; ou substituir todos os preIixos de escopo global, pelos preIixos do
Use-Prefix. Se o conjunto de Use-Prefix Ior vazio, a operao no ADD no Iaz nenhuma adio e
as outras duas operaes apenas apagam o conteudo indicado.
Os roteadores tambm enviam mensagens de Resultados contendo um Match Report para
cada preIixo igual aos enviados na mensagem de Comando.
Mais inIormaes:
RFC 3315 - Dynamic Host Configuration Protocol for IPv6 (DHCPv6)
RFC 4443 - Internet Control Message Protocol (ICMPv6) for the Internet Protocol Jersion 6
(IPv6) Specification
RFC 4861 - Neighbor Discovery for IP version 6 (IPv6)
RFC 5006 - IPv6 Router Aavertisement Option for DNS Configuration
110
Dando continuidade ao estudo das Iuncionalidades do protocolo IPv6, veremos a seguir
como o novo protocolo trata a questo da Iragmentao de pacotes e o gerenciamento de grupos
multicast. Veremos tambm, as alteraes Ieitas no protocolo DNS e as melhorias apresentadas
pelo protocolo IPv6 reIerentes a aplicao de QoS e ao suporte a mobilidade.
110
FuncionaIidades do
IPv6 #2
MduIo 4
111
Determinado pelos protocolos de roteamento, cada enlace na rede pode possuir um valor
diIerente de MTU, ou seja, uma limitao distinta em relao ao tamanho maximo do pacote que
pode traIegar atravs dele. Para que pacotes maiores que o MTU de enlace seja encaminhado, ele
deve ser Iragmentado em pacotes menores, que sero remontados ao chegarem em seu destino.
Na transmisso de um pacote IPv4, cada roteador ao longo do caminho pode Iragmentar os
pacotes, caso estes sejam maiores do que o MTU do proximo enlace. Dependendo do desenho da
rede, um pacote IPv4 pode ser Iragmentado mais de uma vez durante seu trajeto atravs da rede,
sendo reagrupado no destino Iinal.
No IPv6, a Iragmentao dos pacotes realizada apenas na origem, no sendo permitida em
roteadores intermediarios. Este processo tem o intuito de reduzir o overheaa do calculo dos
cabealhos alterados nos roteadores intermediarios.
Para isso, utilizado, no inicio do processo de Iragmentao, o protocolo Path MTU
Discovery, descrito na RFC 1981, que descobre de Iorma dinmica qual o tamanho maximo
permitido ao pacote, identiIicando previamente os MTUs de cada enlace no caminho at o
destino. O protocolo PMTUD deve ser suportado por todos os nos IPv6. No entanto,
Implementaes minimas de IPv6 podem omitir esse suporte, utilizando 1280 Bytes como
tamanho maximo de pacote.
111
MTU - Maximum Transmit Unit - tamanho mximo do pacote que
pode trafegar atravs do enlace.
Fragmentao - permite o envio de pacotes maiores que o MTU de
um enlace.
Pv4 - todos os roteadores podem fragmentar os pacotes que sejam
maiores que o MTU do prximo enlace.
Dependendo do desenho da rede, um pacote Pv4 pode ser fragmentado
mais de uma vez durante seu trajeto.
Pv6 - fragmentao realizada apenas na origem.
Path MTU Discovery busca garantir que o pacote ser
encaminhado no maior tamanho possvel.
Todos os ns Pv6 devem suportar PMTUD.
mplementaes mnimas de Pv6 podem omitir esse suporte, utilizando
1280 Bytes como tamanho mximo de pacote.
Path MTU Discovery
112
O processo de Path MTU Discovery se inicia assumindo que o MTU de todo o caminho
igual ao MTU do primeiro salto. Se o tamanho dos pacotes enviados Ior maior do que o suportado
por algum roteador ao longo do caminho, este ira descarta-lo e retornara uma mensagem ICMPv6
packet too big, que devolve juntamente com a mensagem de erro, o valor do MTU do enlace
seguinte. Apos o recebimento dessa mensagem, o no de origem reduzira o tamanho dos pacotes de
acordo com o MTU indicado na mensagem packet too big.
Esse procedimento termina quando o tamanho do pacote Ior igual ou inIerior ao menor
MTU do caminho, sendo que estas iteraes, de troca de mensagens e reduo do tamanho dos
pacotes, podem ocorrer diversas vezes at se encontrar o menor MTU. Caso o pacote seja enviado
a um grupo multicast, o tamanho utilizado sera o menor PMTU de todo o conjunto de destinos.
De um ponto de vista teorico, o PMTUD pode parecer imperIeito, dado que o roteamento
dos pacotes dinmico, e cada pacote pode ser entregue atravs de uma rota diIerente. No
entanto, essas mudanas no so to Irequentes, e caso o valor do MTU diminua devido a uma
mudana de rota, a origem recebera a mensagem de erro e reduzira o valor do Path MTU.
Mais inIormaes:
RFC 1981 - Path MTU Discovery for IP version 6
112
Assume que o MTU mximo do caminho igual ao MTU do
primeiro salto.
Pacote maiores do que o suportado por algum roteador ao longo do
caminho, so descartados
Uma mensagem CMPv6 packet too big retornada.
Aps o recebimento dessa mensagem, o n de origem reduz o
tamanho dos pacotes de acordo com o MTU indicado na mensagem
packet too big.
O procedimento termina quando o tamanho do pacote for igual ou
inferior ao menor MTU do caminho.
Essas interaes podem ocorrer diversas vezes at se encontrar o
menor MTU.
Pacotes enviados a um grupo multicast utilizam tamanho igual ao
menor PMTU de todo o conjunto de destinos.
Path MTU Discovery
113
A RFC 2675 deIine uma opo do cabealho de extenso Hop-By-Hop chamada Jumbo
Payload. Esta opo permitir envio de pacotes IPv6 com cargas uteis entre 65.536 e
4.294.967.295 Bytes de comprimento, conhecidos como fumbograms.
Ao enviar fumbograms, o cabealho IPv6 trara os campos Tamanho dos Dados e Proximo
Cabealho com o valor zero. Este ultimo indicara que as opes do cabealho de extenso Hop-
By-Hop devem ser processadas pelos nos, onde so indicados os tamanhos dos pacotes
fumbograms.
O cabealho UDP possui um campo de 16 bits chamado Tamanho, que indica o tamanho
do cabealho UDP mais o tamanho dos dados, no permitindo o envio de pacotes com mais
65.536 Bytes. Entretanto, possivel o envio de fumbograms deIinindo o campo Tamanho como
zero, deixando que o receptor extraia o tamanho real do pacote UDP a partir do tamanho do
pacote IPv6.
Nos pacotes TCP, as opes Maximum Segment Si:e (MSS), que negocia no inicio da
conexo o tamanho maximo do pacote TCP a ser enviado, e Urgent Pointer, que indica um
deslocamento de Bytes a partir do numero de seqncia em que dados com alta prioridade devem
ser encontrados, tambm no podem reIerenciar pacotes maiores que 65.535 Bytes. Deste modo,
para se enviar fumbograms preciso no caso do MSS, determinar seu valor como 65.535, que sera
tratado como inIinito pelo receptor do pacote. Em relao ao Urgent Pointer, a soluo
semelhante, visto que se pode determinar o valor do Urgent Pointer como 65.535, indicando que
este esta alm do Iinal deste pacote.
Mais inIormaes:
RFC 2675 - IPv6 Jumbograms
113
Pv6 permite o envio de pacotes que possuam entre 65.536 e
4.294.967.295 Bytes de comprimento.
Um jumbograms identificado utilizando:
O campo Tamanho dos Dados com valor 0 (zero).
O campo Prximo Cabealho indicando o cabealho Hop-by-Hop.
O cabealho de extenso Hop-by-Hop trar o tamanho do pacote.
Devem ser realizadas alteraes tambm nos cabealhos TCP e
UDP, ambos limitados a 16 bits para indicar o tamanho mximo dos
pacotes.
Jumbograms
114
Recapitulando o que Ioi dito no modulo anterior, multicast uma tcnica que permite
enderear multiplos nos como um grupo, possibilitando o envio de pacotes a todos os nos que o
compe a partir de um endereo unico que o identiIica.
Os membros de um grupo multicast so dinmicos, sendo que os nos podem entrar e sair de
um grupo a qualquer momento, no existindo limitaes para o tamanho de um grupo multicast.
O gerenciamento dos grupos multicast no IPv6 realizado pelo Multicast Listener
Discovery (MLD), deIinido na RFC 2710. Este protocolo o responsavel por inIormar aos
roteadores multicast locais o interesse de nos em Iazer parte ou sair de um determinado grupo
multicast. No IPv4, este trabalho realizado pelo protocolo Internet Group Management Protocol
(IGMPv2).
O MLD utiliza trs tipos de mensagens ICMPv6:
Multicast Listener Query (Tipo 130) - as mensagens Query possuem dois subtipos. A
General Query utilizada por roteadores veriIicar periodicamente os membros do
grupo, solicitando a todos os nos multicast reportem todos os grupos de que Iazem
parte. A Multicast-Aaaress-Specific Query utilizada por roteadores para descobrir se
existem nos Iazendo parte de um determinado grupo;
Multicast Listener Report (Tipo 131) - mensagens Report no solicitadas so enviadas
por um no quando este comea a Iazer parte de grupo multicast. Elas tambm so
geradas em resposta a mensagens Query;
Multicast Listener Done (Tipo 132) enviada pelos nos quando estes esto deixando
um determinado grupo.
Estas mensagens so enviadas com um endereo de origem link-local e com o valor 1 no
campo Limite de Encaminhamento, garantindo que elas permaneam na rede local. Caso o pacote
possua um cabealho Hop-by-Hop, a flag Router Alert sera marcada, deste modo, os roteadores
no descartaro o pacote, ainda que o endereo do grupo multicast em questo, no esteja sendo
ouvido por eles.
114
Gerenciamento de Grupos
MuIticast
MLD (Multicast Listener Discovery).
Equivalente ao GMPv2 do Pv4.
Utiliza mensagens CMPv6.
Utiliza endereos link local como endereo de origem.
Utiliza a opo Router Alert do cabealho de extenso Hop-by-
Hop.
Nova verso
MLDv2 (equivalente ao GMPv3).
MRD (Multicast Router Discovery).
Mecanismo utilizado para descobrir roteadores multicast.
Utiliza 3 novas mensagens CMPv6.
115
Uma nova verso do protocolo MLD, chamada de MLDv2, Ioi deIinida na RFC3810.
Equivalente ao IGMPv3, alm de incorporar as Iuncionalidades de gerenciamento de grupos do
MLD, esta nova verso introduziu o suporte a Iiltragem de origem, que permite a um no
especiIicar se no deseja receber pacotes de uma determinada origem, ou inIormar o interesse em
receber pacotes somente de endereos especiIicos. Por padro, os membros de um grupo recebem
pacotes de todos os membros deste grupo.
Outro mecanismo importante para o Iuncionamento dos grupos multicast, o Multicast
Router Discovery (MRD). DeIinido na RFC 4286, ele utilizado na descoberta de roteadores
multicast na rede. Ele utiliza trs mensagens ICMPv6:
Multicast Router Aavertisement (Tipo 151)- esta mensagem enviada por roteadores
para anunciar que o roteamento IP multicast esta habilitado. Ela enviada a partir do
endereo link-local do roteador para o endereo multicast all-snoopers (FF02::6A);
Multicast Router Solicitation (Tipo 152) esta mensagem enviada pelos
dispositivos para solicitar mensagens Multicast Router Aavertisement aos roteadores
multicast. Ela enviada a partir do endereo link-local do dispositivo para o endereo
multicast all-routers (FF02::2);
Multicast Router Termination (Tipo 153) Esta mensagem enviada por roteadores
para anunciar que suas interIaces no esto mais encaminhando pacotes IP multicast.
Ela enviada a partir do endereo link-local do roteador para o endereo multicast
all-snoopers (FF02::6A).
Todas as mensagens MRD tambm so enviadas com um Limite de Encaminhamento igual
a 1 e com contendo a opo Router Alert.
Mais inIormaes:
RFC 2710 - Multicast Listener Discovery (MLD) for IPv6
RFC 4286 - Multicast Router Discovery
116
O protocolo Domain Name System (DNS) uma imensa base de dados distribuida
utilizada para a resoluo de nomes de dominios em endereos IP e vice-versa. Possui uma
arquitetura hierarquica, com dados dispostos em uma arvore invertida, distribuida eIicientemente
em um sistema descentralizado e com cache.
Para que o DNS trabalhe com a verso 6 do protocolo IP, algumas mudanas Ioram
deIinidas na RFC 3596.
Um novo registro Ioi criado para armazenar os endereos IPv6 de 128 bits, o AAAA ou
quad-A. Sua Iuno traduzir nomes para endereos IPv6, equivalente ao registro A utilizado
com o IPv4. Caso um host possua mais de um endereo IPv6, ele tera um registro quad-A para
cada endereo. Os registros so representados como se segue:
Exemplo: www.ipv6.br. IN A 200.160.4.22
IN AAAA 2001:12ff:0:4::22
116
mensa base de dados distribuda utilizada para a resoluo de
nomes de domnios em endereos P e vice-versa.
Arquitetura hierrquica, com dados dispostos em uma rvore
invertida, distribuda eficientemente em um sistema descentralizado e
com cache.
Registros
Pv4 = A - Traduz nomes para endereos Pv4.
Pv6 = AAAA (quad-A) - Traduz nomes para endereos Pv6.
Exemplo: www.ipv6.br. N A 200.160.4.22
N AAAA 2001:12ff:0:4::22
DNS
117
Para resoluo de reverso, Ioi adicionado o registro PTR ip6.arpa, responsavel por traduzir
endereos IPv6 em nomes. Em sua representao, omitir sequncia de zeros no permitido e o
bit menos signiIicativo colocado mais a esquerda, como possivel observar no exemplo a
seguir:
Exemplo:
22.4.160.200.in-addr.arpa PTR www.ipv6.br.
2.2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.4.0.0.0.0.0.0.0.I.I.2.1.1.0.0.2.ip6.arpa
PTR www.ipv6.br.
Os outros tipos de registro DNS no soIreram alteraes, apenas Ioram adaptados para
suportar o novo tamanho dos endereos.
A RFC 2874 introduziu os registros A6 e DNAME, com o intuito de Iacilitar renumerao
de redes, onde cada nameserver detm apenas uma parte do endereo IPv6. Inicialmente o
dominio para resoluo de reverso, deIinido na RFC 1886, era o ip6.int, no entanto, houve
maniIestaes contrarias a sua utilizao, pois, o .int signiIica "internacional", e no deve servir
para Iins administrativos na Internet. Os registros A6 e DNAME tornaram-se obsoletos pelo
desuso, e o dominio .int Ioi substituido pelo .arpa, respectivamente nas RFCs 3363 e 3152,
117
Registro PTR Resoluo de Reverso.
Pv4 = in-addr.arpa - Traduz endereos Pv4 em nomes.
Pv6 = ip6.arpa - Traduz endereos Pv6 em nomes.
Exemplo:
22.4.160.200.in-addr.arpa PTR www.ipv6.br.
2.2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.4.0.0.0.0.0.0.0.f.f.2.1.1.0.0.2.ip6.arpa
PTR www.ipv6.br.
Obsoletos
Registros
A6
DNAME
Domnio para a resoluo de reverso
ip6.int
DNS
118
O suporte a IPv6 do DNS deve ser observado por dois aspectos. O primeiro, que um
servidor DNS deve ser capaz de armazenar registros quad-A para endereos IPv6. O segundo
aspecto, se um servidor DNS capaz de transportar consultas e respostas atravs de conexes
IPv6. Isto , a base de dados de um servidor DNS pode armazenar tanto registros IPv6 quanto
IPv4, independente verso de IP em que este servidor opera.
Com isso, um servidor com conexo apenas IPv4 pode responder tanto consultas AAAA
quanto A. No entanto, as inIormaes obtidas na consulta via IPv6 devem ser iguais as obtidas na
consulta IPv4.
Mais inIormaes:
RFC 3596 - DNS Extensions to Support IP Jersion 6
RFC 3363 - Representing Internet Protocol version 6 (IPv6) Aaaresses in the Domain Name
System (DNS)
RFC 3364 - Traaeoffs in Domain Name System (DNS) Support for Internet Protocol version 6
(IPv6)
118
A base de dados de um servidor DNS pode armazenar tanto
registros Pv6 quanto Pv4.
Esses dados so independentes da verso de P em que o
servidor DNS opera.
Um servidor com conexo apenas Pv4 pode responder
consultas AAAA ou A.
As informaes obtidas na consulta Pv6 devem ser iguais
s obtidas na consulta Pv4.
DNS
119
A principio, o protocolo IP trata todos os pacotes da mesma Iorma, sem nenhuma
preIerncia no momento de encaminha-los. Isto pode acarretar diversas implicaes no
desempenho de uma aplicao, visto que, atualmente muitas dessas aplicaes, como voz e video
sobre IP, requerem transmisso e reproduo praticamente em tempo real, podendo ter sua
qualidade diminuida devido a ocorrncia de perda de pacotes, entrega Iora de ordem, atraso ou
variao de sinal. Estes problemas podem acontecer devido a Iorma como o traIego chega e
manipulado pelos roteadores, dado que, vindo de diIerentes interIaces e diversas redes, o roteador
processa os pacotes na ordem em que so recebidos.
O conceito de QoS (Quality of Service), ou em portugus, Qualidade de Servio,
empregado para em protocolos cuja a tareIa prover a transmisso de determinados traIegos de
dados com prioridade e garantia de qualidade. Existem atualmente, duas arquiteturas principais: a
Differentiatea Services (DiIIServ) e a Integratea Services (IntServ). Ambas utilizam politicas de
traIego e podem ser combinadas para permitir QoS em LANs ou WANs.
119
O protocolo P trata todos os pacotes da mesma forma, sem
nenhuma preferncia.
Algumas aplicaes necessitam que seus pacotes sejam
transportados com a garantia de que haja o mnimo de atraso,
latncia ou perda de pacotes.
VoP
Videoconferncia
Jogos online
Entre outros...
Utiliza-se o conceito de QoS (Quality of Service), ou em portugus,
Qualidade de Servio.
Arquiteturas principais: Differentiated Services (DiffServ) e
Integrated Services (ntServ).
Ambas utilizam polticas de trfego e podem ser combinadas para
permitir QoS em LANs ou WANs.
QoS
120
O DiffServ trabalha por meio de classes, agregando e priorizando pacotes com requisitos
QoS similares.
Pacotes DiffServ so identiIicados pelos oito bits dos campos Tipo de Servio do IPv4 e
Classe de TraIego do IPv6, com o intuito de identiIicar e distinguir as diIerentes classes ou
prioridades de pacotes que necessitem de QoS.
Ambos os campos possuem as mesmas deIinies e as prioridades atribuidas a cada tipo de
pacote podem ser deIinidos tanto na origem quanto nos roteadores, podendo tambm, serem
redeIinidas ao longo do caminho por roteadores intermediarios. Pacotes que no necessitem de
QoS o campo Classe de TraIego apresenta o valor zero.
Comparado com o IntServ, o DiffServ no exige qualquer identiIicao ou gerencia dos
Iluxos, alm de ser geralmente mais utilizado nas redes, devido a sua Iacilidade de implantao.
120
DiffServ: trabalha por meio de classes, agregando e priorizando
pacotes com requisitos QoS similares.
Pv4 campo Tipo de Servio (ToS).
Pv6 campo Classe de Trfego:
Mesma definio do campo ToS do Pv4.
Pode ser definido na origem ou por roteadores.
Pode ser redefinido por roteadores ao longo do caminho.
Em pacotes que no necessitam de QoS o campo Classe de
Trfego apresenta o valor 0 (zero).
DiffServ no exige identificao ou gerencia dos fluxos.
Muito utilizado devido a sua facilidade de implantao.
QoS
121
O modelo IntServ baseia-se na reserva de recursos por Iluxo e sua utilizao esta
normalmente associada ao protocolo RSVP. O RSVP utilizado para reservar o recurso ao longo
do caminho da Ionte at o destino de um Iluxo que requer QoS.
No IPv6, para identiIicar os Iluxos que necessitam de QoS so utilizados os 20 bits do
campo IdentiIicador de Fluxo, que so preenchidos com valores aleatorios entre 00001 e FFFFF.
Pacotes que no pertencem a um Iluxo devem marcar o campo IdentiIicador de Fluxo com zeros.
Os hosts e roteadores que no tm suporte as Iunes deste campo devem preencher este campo
com os zeros quando enviarem um pacote, no altera-lo ao encaminharem um pacote, ou ignora-lo
quando receberem um pacote. Pacotes de um mesmo Iluxo devem possuir o mesmo endereo de
origem e destino, e o mesmo valor no campo IdentiIicador de Fluxo.
O RSVP utiliza alguns elementos do protocolo IPv6, como o campo IdentiIicador de Fluxo
e o cabealho de extenso Hop-by-Hop. Pacotes RSVP so enviados com o mesmo valor no
campo IdentiIicador de Fluxo, junto com o cabealho de Extenso Hop-By-Hop, usado para
transportar uma mensagem Router Alert, indicando para cada roteador no caminho do traIego
QoS, que o pacote IP devera ser processado.
Mais inIormaes:
RFC 1633 - Integratea Services in the Internet Architecture. an Overview
RFC 2205 - Resource ReSerJation Protocol (RSVP)
RFC 2475 - An Architecture for Differentiatea Services
RFC 3260 - New Terminology ana Clarifications for Diffserv
121
ntServ: baseia-se na reserva de recursos por fluxo. Normalmente
associado ao protocolo RSVP (Resource ReSerVation Protocol).
Pv6 - campo dentificador de Fluxo preenchido pela origem com
valores aleatrios entre 00001 e FFFFF para identificar o fluxo que
necessita de QoS.
Pacotes que no pertencem a um fluxo devem marc-lo com zeros.
Os hosts e roteadores que no tm suporte s funes do campo
dentificador de Fluxo devem preencher este campo com zeros
quando enviarem um pacote, no alter-lo ao encaminharem um
pacote, ou ignor-lo quando receberem um pacote.
Pacotes de um mesmo fluxo devem possuir o mesmo endereo de
origem e destino, e o mesmo valor no campo dentificador de Fluxo.
RSVP utiliza alguns elementos do protocolo Pv6, como o campo
dentificador de Fluxo e o cabealho de extenso Hop-by-Hop.
QoS
122
O suporte a mobilidade permite que um dispositivo movel se desloque de uma rede
para outra sem necessidade de alterar seu endereo IP de origem, tornando a movimentao
entre redes invisivel para os protocolos das camadas superiores. Com isso, todos os pacotes
enviados para este no movel, continuaro sendo encaminhados a ele usando o endereo de
origem.
No suporte a mobilidade IPv6 existem alguns componentes chave para o seu
Iuncionamento:
N Mvel - dispositivo que pode mudar de uma rede para outra enquanto continua
recebendo pacotes atravs de seu Endereo de Origem;
Rede de Origem - rede que atribui o Endereo de Origem ao No Movel;
Agente de Origem - roteador localizado na Rede de Origem, que mantem a
associao entre o Endereo de Origem e o Endereo Remoto do No Movel.
Endereo de Origem - endereo global unicast atribuido pela Rede de Origem ao
No Movel. E utilizado como endereo permanente, para o qual os pacotes so
encaminhados.
Rede Remota - qualquer rede, diIerente da origem, onde o No Movel se encontra;
Endereo Remoto - endereo global unicast atribuido ao No Movel pela Rede
Remota;
N Correspondente - no que se comunica com o No Movel. Este pode ser movel ou
estacionario.
122
Permite que um dispositivo mvel se desloque de uma rede para
outra sem necessidade de alterar seu endereo P de origem,
tornando a movimentao entre redes invisvel para os protocolos das
camadas superiores.
MobiIidade IPv6
123
O No Movel possui um Endereo de Origem Iixo, que lhe atribuido pela sua Rede de
Origem. Mesmo quando o no se desloca de sua Rede de Origem, este endereo mantido.
Ao ingressar em uma Rede Remota, o No Movel recebe um ou mais Endereos Remotos
atravs dos mecanismos de autoconIigurao, constituidos de um preIixo valido na Rede Remota.
Para assegurar que os pacotes IPv6 destinados ao seu Endereo de Origem sejam recebidos, o no
realiza uma associao entre o Endereo de Origem e o Endereo Remoto, registrando seu novo
endereo no Agente de Origem, atravs do envio de uma mensagem Binaing Upaates. Como
resposta a essa mensagem, o roteador da Rede de Origem envia uma mensagem Binaing
Acknowleagement.
Essa associao de endereos tambm pode ser Ieita diretamente com o No
Correspondente, com o intuito de otimizar a comunicao.
Para o No Movel detectar que retornou a sua rede, ele utiliza o processo de Descoberta de
Vizinhos Inacessiveis, para detectar se o seu roteador padro esta ativo. Caso ele localize um novo
roteador padro, ele ira gerar um novo endereo baseado no preIixo anunciado na mensagem RA.
No entanto, encontrar um novo roteador padro no signiIica necessariamente que ele esteja em
uma nova rede, pode ser apenas uma renumerao em sua rede ou a adio de um novo roteador.
Com isso, antes de realizar a associao de endereos com o Agente de Origem e com os Nos
Correspondentes, o No Movel tenta localizar novamente seu roteador padro e ira comparar se o
intervalo entre o envio de mensagens RA no solicitadas o mesmo que o conIigurado em sua
Rede Original.
Quando o No Movel retorna a sua Rede de Origem, ele envia uma mensagem Binaing
Upaates inIormando ao Agente de Origem o seu retorno e que este no precisa mais lhe
encaminhar os pacotes.
123
MobiIidade IPv6
Funcionamento
O N Mvel utiliza Endereo de Origem para receber pacotes na Rede
de Origem.
Deslocamento
Adquire Endereo Remoto via autoconfigurao stateless ou stateful.
O N Mvel tambm pode se registrar diretamente com o N
Correspondente.
Agente de Origem realiza
a associao entre o
Endereo Remoto e o
Endereo de Origem.
124
As comunicaes entre nos moveis e nos correspondentes podem acontecer de dois modos,
tunelamento bidirecional e otimizao de rota.
No Tunelamento Bidirecional, os pacotes enviados pelo No Correspondente para o
Endereo Original do No Movel, so interceptados pelo Agente de Origem, que os encaminhara,
atravs de um tunel, para o No Movel utilizando o Endereo Remoto. Em seguida, o No Movel
responde ao Agente de Origem, atravs do tunel, que reenvia o pacote ao No Correspondente.
Neste caso, o No Correspondente no necessita ter suporte a mobilidade IPv6 e o No Movel no
precisa se registrar no No Correspondente.
124
MobiIidade IPv6
O encaminhamento de pacotes para o N Mvel pode acontecer de
dois modos:
TuneIamento bidirecionaI
125
No modo Otimizao de Rota, a comunicao entre o No Movel e o No Correspondente
ocorre diretamente, sem a necessidade da utilizao do Agente de Origem. Para que esta
comunicao ocorra, o No Movel registra seu Endereo Remoto no No Correspondente, que
associa os Endereos de Origem e Remoto do No Movel.
A troca de mensagens entre os dois nos Iunciona do seguinte modo:
O No Correspondente envia pacotes com o campo Endereo de Destino do cabealho
base preenchido com o Endereo Remoto do No Movel. O cabealho base seguido
pelo cabealho de extenso Routing Tipo 2, que carrega o Endereo de Origem do No
Movel;
Ao receber o pacote, o No Movel processa o cabealho Routing e insere o Endereo
de Origem do cabealho Routing no campo Endereo de Destino do cabealho base.
As camadas superiores continuam o processamento do pacote normalmente;
Os pacotes enviados pelo No Movel, tm o campo Endereo de Origem do cabealho
base preenchido com o Endereo Remoto. O cabealho base seguido pelo cabealho
de extenso Destination Options, que carrega na opo Home Aaaress o Endereo de
Origem do No Movel;
Ao receber o pacote , o No Correspondente insere o Endereo de Origem do
cabealho Destination Options no campo Endereo de Origem do cabealho base. As
camadas superiores continuam o processamento do pacote normalmente.
125
MobiIidade IPv6
O encaminhamento de pacotes para o N Mvel pode acontecer de
dois modos:
Otimizao de rota
126
Para otimizar o Iuncionamento deste servio Ioi adicionado a especiIicao do IPv6 um
novo cabealho de extenso, o Mobility.
O cabealho de extenso Mobility indicado no campo Proximo Cabealho pelo valor
135. Ele utilizado pelo No Movel, pelo Agente Remoto e pelo No Correspondente, nas trocas de
mensagens relacionadas a criao e gerenciamento das associaes de endereos.
Este cabealho possui os seguintes campos:
Protocolo de dados Corresponde ao campo Proximo Cabealho. Atualmente apenas
o valor 59, em decimal, utilizado, indicando que no ha proximo cabealho;
Tamanho do cabealho de extenso contem o tamanho do cabealho Mobility em
unidades de 8 Bytes. O tamanho desse cabealho deve ser sempre multiplo de 8;
Tipo de Mensagem Mobility indica o tipo da mensagem enviada;
Soma de VeriIicao veriIica a integridade do cabealho Mobility;
Dados o seu Iormato e tamanho dependem do tipo de mensagem Mobility que esta
sendo enviada.
Principais tipos de mensagem Mobility utilizadas so:
Binaing Refresh Request (Tipo 0) enviada pelo No Correspondente, solicitando ao
No Movel a atualizao da associao de endereos;
Binaing Upaate (Tipo 5) enviada pelo No Movel notiIicando ao Agente de Origem
ou ao No Correspondente sobre um novo Endereo Remoto;
Binaing Ack (Tipo 6) enviada como conIirmao de recebimento de uma mensagem
Binaing Upaate,
Binaing Error (Tipo 7) enviada pelo No Correspondente para relatar erros.
126
MobiIidade IPv6
dentificado no campo Prximo Cabealho pelo valor 135.
Utilizado nas trocas de mensagens relacionadas criao e
gerenciamento das associaes de endereos.
Cabealho de extenso Mobility
Principais tipos de mensagem Mobility:
Binding Refresh Request (Tipo 0)
Binding Update (Tipo 5)
Binding Ack (Tipo 6)
Binding Error (Tipo 7)
Dados
Tam. cab. de
extenso
Protocolo
dos dados
Reservado
Tipo de Mensagem
Mobility
Soma de Verificao
127
Tambm Ioram criadas quatro novas mensagens ICMPv6 utilizadas na conIigurao de
preIixos na Rede de Origem e na descoberta de Agentes de Origem.
O par de mensagens Home Agent Aaaress Discovery Request e Home Agent Aaaress
Discovery Reply so utilizadas para descobrir dinamicamente um Agente de Origem em sua rede.
Isto evita a necessidade de conIiguraes manuais e problemas no caso da renumerao do Agente
de Origem.
O No Movel envia uma mensagem Discovery Request para o endereo anycast do Agente
de Origem em sua rede. O campo Endereo de origem do cabealho base carrega o Endereo
remoto do No Movel. O Agente de Origem responde enviando uma mensagem Discovery Reply.
As mensagens Discovery Request e Reply so identiIicadas, respectivamente, pelos valores 150 e
151 no campo Proximo Cabealho.
Ja a mensagem Mobile Prefix Solicitation enviada pelo No Movel ao Agente de origem,
para determinar mudanas nas conIiguraes de preIixo em sua rede. O Agente Remoto responde
enviando uma mensagem Mobile Prefix Aavertisement. Baseado nessa resposta, o No Movel pode
ajustar seu Endereo de Origem. As mensagens Mobile Prefix Solicitation e Aavertisement, so
identiIicadas, respectivamente, no campo Proximo Cabealho pelo valor 152 e 153.
127
MobiIidade IPv6
Novas mensagens CMPv6
Home Agent Address Discovery Request;
Home Agent Address Discovery Reply;
Mobile Prefix Solicitation;
Mobile Prefix Advertisement.
128
Algumas modiIicaes tambm Ioram Ieitas no protocolo de Descoberta de Vizinhana.
Foi adicionada a mensagem RA a flag H, que permite a um roteador anunciar se este atua
como um Agente de Origem na rede. A partir desse anuncio, um No Movel Iorma uma lista de
Agentes de Origem da sua rede.
No entanto, para manter essa lista atualizada, o No Movel precisa saber os endereos
global unicast dos roteadores, porm, as mensagens RA trazem apenas o endereo link-local. Para
resolver este problema, Ioi adicionada uma nova flag a opo Prefix Information, a flag R.
Quando esta flag marcada, ela indica que a opo Prefix Information no contm um preIixo,
mas sim o endereo global unicast do roteador.
Tambm Ioram criadas duas novas opes ao protocolo, a Aavertisement Interval e a
Home Agent Information. A primeira indica o intervalo entre mensagens RA no solicitadas,
inIormao esta, que utilizada no algoritmo de deteco de mudana de rede. Nas especiIicaes
do protocolo de Descoberta de Vizinhana, o intervalo minimo entre o envio dessas mensagens
deve ser de trs segundos. No entanto, para garantir que o No Movel detecte a mudana de rede e
aprenda as inIormaes sobre a nova rede o mais rapido possivel, roteadores com suporte a
mobilidade IPv6 podem ser conIigurados com um intervalo de tempo menor para o anuncio de
mensagens RA.
A opo Home Agent Information utilizada para indicar o nivel de preIerencia de
associao de cada Agente de Origem.
128
MobiIidade IPv6
Mudanas no protocolo Descoberta de Vizinhana:
Modificao no formato das mensagens RA;
Modificao no formato do Prefix Information;
Adicionada a opo Advertisement Interval;
Adicionada a opo Home Agent Information.
129
129
MobiIidade IPv6
Mobilidade Pv4 x Mobilidade Pv6:
No necessita da implantao de Agentes Remotos;
A otimizao da rota passou a incorporada ao protocolo;
A autoconfigurao stateless facilita a atribuio de Endereos
Remotos;
Aproveita os benefcios do protocolo Pv6:
Descoberta de Vizinhana, CMPv6, cabealhos de extenso...
Utiliza o protocolo de Descoberta de Vizinhana, em vez de ARP;
Utiliza anycast para localizar Agentes de Origem em vez de
broadcast.
As principais diIerenas entre o suporte a mobilidade do IPv6 e do IPv4 podem ser
resumidas nos seguintes topicos:
No ha mais a necessidade de se implantar roteadores especiais atuando como agentes
remotos;
A otimizao da rota passou a incorporada ao protocolo, em vez de Iazer parte de um
conjunto de extenses opcionais;
A autoconIigurao stateless Iacilita a atribuio de Endereos Remotos;
Aproveita os beneIicios do protocolo IPv6 como o protocolo de Descoberta de Vizinhana,
as mensagens ICMPv6, e os cabealhos de extenso;
O uso do protocolo de Descoberta de Vizinhana, em vez de ARP, permite que o processo
de interceptao dos pacotes destinados ao no movel no dependa da camada de enlace,
simpliIicando o protocolo e aumentando sua eIicincia;
A busca por agentes de origem realizada pelo no movel passou a ser Ieita utilizando
anycast. Desta Iorma, o no movel recebera apenas a reposta de um unico agente de origem.
Com o IPv4, utiliza-se broaacast, o que implica em uma resposta separada para cada
agente de origem existente.
Mais inIormaes:
RFC 3775 - Mobility Support in IPv6
130
130
131
A utilizao de protocolos e Ierramentas de gerenciamento e monitoramento de redes
muito importante para a manuteno da qualidade e obteno do maximo desempenho desta rede.
Com a adoo do novo Protocolo Internet, preciso conhecer quais dessas Ierramentas so
capazes de coletar inIormaes sobre IPv6 e se esto aptas a obt-las atravs da rede IPv6.
Neste modulo estes aspectos sero abordados em relao a alguns protocolos utilizados
para estes Iins como SSH, FTP, SNMP, entre outros, e alguns aplicativos como Argus, Nagios,
MRTG, Rancid, Wireshark e Looking Glass.
131
Gerenciamento e
Monitoramento de
Redes IPv6
MduIo 5
132
Necessaria para manter a qualidade e garantir o maximo de eIicincia de seu
Iuncionamento, o gerenciamento e o monitoramento de redes de computadores uma parte
importante na operao, independente do tamanho dessa rede.
Atualmente existem inumeras Ierramentas e protocolos que realizam essas Iunes, que
podem diIerenciar-se de acordo com o segmento de rede que atuam, sejam LANs ou WANs, e
Iuncionalidades como garantir acesso remoto e seguro a nos da rede, coletar inIormaes sobre o
Iluxo dos dados, autenticao de usuarios, testes e manutenes e acesso as inIormaes.
Portanto, neste momento de transio entre o IPv4 e o IPv6, importante que essas
Ierramentas sejam capazes de suportar as duas verses do protocolo IP, estando aptas a coletar
inIormaes sobre IPv6 e transmiti-las via conexes IPv6.
132
Gerenciamento e
Monitoramento
Necessrio para manter a qualidade da rede.
Realizado atravs de vrias ferramentas e protocolos.
Devem cobrir diversos segmentos:
LAN
WAN
Abranger diversos aspectos:
Acesso Remoto
nformao sobre o fluxo dos dados
Segurana
Manuteno
Acesso s informaes
Devem coletar informaes sobre Pv6 e transmiti-las via conexes
Pv6.
133
Umas das Iunes mais basicas de gesto de redes, o acesso remoto a outros dispositivos.
Neste aspecto, os principais protocolos existentes ja so capazes de operar sobre IPv6.
Os protocolos Telnet e SSH (Secure Shell), utilizados para estabelecer conexes remotas a
outros dispositivos da rede, ja permitem o acesso via conexes IPv6. Aplicativos como OpenSSH
e PuTTy, por exemplo, ja oIerecem essa Iuncionalidade.
Do mesmo modo, realizar a transIerncia de arquivos entre dispositivos remotos via IPv6,
ja possivel atravs de protocolos como SCP, TFTP e FTP. O FTP inclusive, Ioi um dos
primeiros protocolos a serem adaptados para trabalhar sobre IPv6.
133
Funes bsicas
Funes bsicas de gesto de redes
Acesso Remoto:
SSH;
TELNET.
Transferncia de Arquivos
SCP;
FTP;
TFTP.
134
Em redes IPv4, o protocolo SNMP (Simple Network Management Protocol), deIinido na
RFC 1157, uma das Ierramentas de gerenciamento mais utilizadas, devido a sua Ilexibilidade e
Iacilidade de implantao.
O Iuncionamento do SNMP baseia-se na utilizao de dois dispositivos, um agente e um
gerente. Cada dispositivo gerenciado deve possuir um agente e uma base de dados reIerente ao
seu estado atual, que pode ser consultada e alterada pelo gerente. O conjunto desses dados, ou
objetos gerenciados, conhecido como MIB (Management Information Base), uma estrutura de
dados que modela todas as inIormaes necessarias para a gerncia da rede.
O agente o responsavel pela manuteno das inIormaes gerenciadas. Ele quem deve
responder as requisies Ieitas pelo gerente, lhe enviando as inIormaes necessarias para que este
possa realizar o monitoramento do sistema.
O envio dessas inIormaes, armazenadas nas MIBs, pode ser realizado tanto via conexes
IPv4 ou IPv6, visto que, o tipo de inIormao transportada independente do protocolo de rede
utilizado. No entanto, ja existe desde de 2002, implementaes de SNMPs capazes de monitorar
redes que possuam somente conexes IPv6.
134
SNMP e MIBs
SNMP: protocolo mais utilizado no gerenciamento de redes Pv4.
Seu funcionamento baseia-se na utilizao de dois dispositivos, os
agentes e os gerentes.
O gerente obtm as informaes realizando requisies a um ou
mais agentes.
As informaes podem ser transportadas tanto via conexes Pv4
quanto conexes Pv6.
O tipo de informao transportada (Pv4 ou Pv6)
independente do protocolo de rede utilizado na conexo.
mplementao sobre Pv6 j existem desde 2002.
MB: estrutura de dados que modela todas as informaes
necessrias para a gerncia da rede.
135
Embora o tipo de protocolo de rede utilizado na transmisso dos dados no interIira no
envio das mensagens SNMP, necessario que as MIBs sejam capazes de armazenar inIormaes
sobre a rede IPv6.
Em vista disso, em 1998, na RFC 2465 (tornou-se obsoleta pela RFC 4292), Ioi deIinida
uma abordagem apenas para endereos IPv6. No entanto, era necessario implantar uma MIB para
cada protocolo. Em 2002, a RFC 2851 (tornou-se obsoleta pelas RFCs 3291 e 4001 ), estabeleceu
uma MIB uniIicada, criando um unico conjunto de objetos capaz de descrever e gerenciar
modulos IP de Iorma independente do protocolo.
Esta nova conveno deIine um endereo IP como uma estrutura inetAaaressType,
inetAaaress}, onde o primeiro, um valor inteiro que determina a Iorma como o segundo sera
codiIicado.
Mais inIormaes:
RFC 1157 - A Simple Network Management Protocol (SNMP)
RFC 4001 - Textual Conventions for Internet Network Aaaresses
RFC 4292 - IP Forwaraing Table MIB
135
SNMP e MIBs
necessrio que as MBs sejam capazes de recolher informao
sobre a rede Pv6.
1998: definida uma abordagem apenas para endereos Pv6. No
entanto, era necessrio implantar uma MB para cada protocolo.
2006: elaborou-se uma MB unificada, criando um nico conjunto de
objetos capaz de descrever e gerenciar mdulos P de forma
independente do protocolo.
InetAddressType
InetAddress
136
Para analises mais detalhadas de uma rede, podemos aplicar uma abordagem alternativa
que consiste em recolher inIormaes sobre cada pacote. Neste mtodo, equipamentos de rede,
por exemplo, um roteador, enviam periodicamente inIormaes sobre um determinado Iluxo de
dados para um dispositivo chamado coletor, que armazena e interpreta esses dados.
Um Iluxo de dados pode ser deIinido como um conjunto de pacotes pertencentes a mesma
aplicao que possuem o mesmo endereo de origem e destino. Os principais protocolos
utilizados para a transmisso de inIormaes sobre um Iluxo IP de uma rede, tambm ja esto
preparados para coletar dados sobre o traIego IPv6.
O NetFlow, protocolo desenvolvido pela Cisco Systems deIinido na RFC 3954, uma
eIiciente Ierramenta utilizada, entre outras coisas, para contabilizao e caracterizao de traIego
de redes, planejamento de redes e deteco de ataques DoS e DDoS. O protocolo NetFlow com
suporte IPv6 encontra-se implementado a partir do Cisco IOS 12.3(7)T, no entanto, esta
implementao ainda utiliza o protocolo IPv4 para a exportao de dados.
Do mesmo modo, o protocolo IPFIX (IP Flow Information Export), proposto pela IETF na
RFC 3917, tambm capaz de exportar e coletar dados sobre o traIego IPv6.
Mais inIormaes:
RFC 3917 - Requirements for IP Flow Information Export (IPFIX)
RFC 3954 - Cisco Systems NetFlow Services Export V9
136
Monitoramento de FIuxo
Fluxo - conjunto de pacotes pertencentes mesma aplicao que
possuam o mesmo endereo de origem e de destino.
Equipamentos de rede enviam informaes sobre um determinado
fluxo de dados para o coletor, que armazena e interpreta esses dados.
NetFlow - protocolo desenvolvido pela Cisco Systems, j apresenta
suporte a Pv6.
PFX - baseado no NetFlow, tambm capaz de exportar e coletar
dados sobre o trfego Pv6.
137
Um quesito muito importante no gerenciamento de redes, a sincronizao dos relogios dos
computadores pode reIletir de Iorma signiIicativa no Iuncionamento de diversos softwares e
sistemas, alm da segurana dos computadores, redes e da propria Internet. Com a utilizao do
protocolo NTP (Network Time Protocol) possivel manter o relogio do computador sempre com
a hora certa, com exatido de alguns milsimos de segundo. Isto pode ser Ieito sincronizando o
relogio do computador com um servidor NTP publico.
A sincronizao dos relogios de uma rede IPv6 possivel conectando-se a servidores que
possuam suporte ao novo protocolo IP. A lista a seguir apresenta o endereo de uma srie de
servidores NTP publicos no Brasil que ja trabalham com conexo IPv6:
a.ntp.br
ntp.pop-sc.rnp.br
ntp.pop-rs.rnp.br
ntp.cert-rs.tche.br
ntp.pop-mg.rnp.br
Mais inIormaes:
RFC 1305 - Network Time Protocol (Jersion 3) Specification, Implementation ana Analysis
137
NTP
A sincronizao dos relgios dos computadores pode refletir de forma
significativa no funcionamento das redes.
O protocolo NTP manter o relgio do computador sempre com a hora
certa, com exatido de alguns milsimos de segundo.
sto pode ser feito sincronizando o relgio do computador com um
servidor NTP pblico.
Servidores NTP pblicos no Brasil com suporte Pv6
a.ntp.br
ntp.pop-sc.rnp.br
ntp.pop-rs.rnp.br
ntp.cert-rs.tche.br
ntp.pop-mg.rnp.br
138
Existem diversas Ierramentas que auxiliam no monitoramento de uma rede. Utilitarios para
gerenciamento de traIego, elaborao de graIicos e relatorios sobre o status de equipamentos e
links, analise de traIego e diversas outras tareIas, so utilizados Irequentemente por
administradores de redes, sendo que muitas dessas Ierramentas ja possuem suporte o IPv6. Entre
essas Ierramentas podemos destacar:
ARGUS aplicativo de monitoramento de redes e sistemas, que permite acompanhar
e avaliar dados reIerentes a conectividade na rede, portas TCP/UDP e de aplicaes
como HTTP, SMTP, RADIUS, etc.. Apresenta suporte a IPv6 desde a verso 3.2;
NAGIOS - Ierramenta versatil e Ilexivel que apresenta inumeras Iuncionalidades
como monitoramento de servios de rede; de recursos dos hosts; notiIicao de erros;
etc.. Possui a vantagem da possibilidade de adio de novas Iuncionalidades atravs
de plugins. O suporte IPv6 Ioi incluido nas verses de plugins 1.4.x;
138
Ferramentas de Monitoramento
ARGUS
Suporte a Pv6 desde a verso 3.2;
Aplicativo de monitoramento de redes e sistemas
Permite acompanhar e avaliar dados sobre:
Conectividade na rede;
Portas TCP/UDP;
Aplicaes - HTTP, SMTP, RADUS, etc.
NAGOS
Ferramenta verstil e flexvel;
Principais funcionalidades:
Monitoramento de servios de rede;
Monitoramento de recursos dos hosts;
Notificao de erros;
Adio de novas funcionalidades atravs de plugins;
Suporte a Pv6 includo nas verses de plugins 1.4.x.
139
NTOP (Network Traffic Probe) - capaz de detalhar a utilizao da rede por host,
protocolo, etc., permitindo a visualizao de estatisticas do traIego, analise do traIego
IP, deteco de violaes de segurana na rede, entre outras Iunes. Possui suporte a
traIego IPv6;
MRTG (Multi Router Traffic Grapher) - Desenvolvido em C e Perl, utiliza o SNMP
para obter inIormaes de traIego dos dispositivos gerenciados. Todos os dados
obtidos atravs do protocolo SNMP podem ser monitorados por esta Ierramenta e
analisados atravs de graIicos visualizados em Iormato HTML. Suporte a IPv6 desde
a verso 2.10.0.
139
Ferramentas de Monitoramento
NTOP
Detalhar a utilizao da rede;
Visualizao de estatsticas do trfego;
Anlise do trfego P;
Deteco de violaes de segurana;
Possui suporte a trfego Pv6.
MRTG
Desenvolvido em C e Perl;
Utiliza SNMP para obter informaes dos dispositivos gerenciados;
Anlisde dos dados atravs de grficos visualizados em formato HTML;
Suporte a Pv6 desde a verso 2.10.0.
140
Pchar Ierramenta de avaliao de perIormance da rede. Analisa aspectos como
largura de banda, latncia e perda de conexes. Permite a analise de redes IPv6.
Rancid permite o monitoramento de conIiguraes de equipamentos (software e
haraware), utilizando CVS. Desenvolvida nas linguagens Perl, Shell e C,
disponibiliza alm das Iuncionalidades tradicionais de uma Ierramenta de
monitoramento de rede, possui um looking glass. E capaz de caracterizar o caminho
entre dois hosts em redes IPv6.
140
Ferramentas de Monitoramento
Pchar
Ferramenta de avaliao de performance;
Anlise de largura de banda;
Anlise de latncia
Anlise de perda de conexes;
Permite a anlise de redes Pv6.
Rancid
Monitora configuraes de equipamentos;
Desenvolvida nas linguagens Perl, Shell e C;
Disponibiliza um looking glass;
capaz de caracterizar o caminho entre dois hosts em redes Pv6.
141
Wireshark - analisador de traIego de rede (sniffer) atravs da captura de pacotes.
Possui interIace graIica e apresenta inIormao sobre a arvore de protocolos do pacote
e o seu conteudo. Permite a captura de pacotes IPv6;
Looking Glass permite a obteno de inIormaes sobre um roteador sem necessidade
de acesso direto ao equipamento. Pode ser acessado atravs de uma interIace Web,
Iacilitando o diagnostico de problemas na rede. Permite o acesso via conexes IPv6.
141
Ferramentas de Monitoramento
Wireshark
Analisador de trfego de rede (sniffer);
Possui interface grfica
Apresenta informao sobre:
rvore de protocolos do pacote
Contedo dos pacotes;
Permite a captura de pacotes Pv6.
Looking Glass
Permite a obteno de informaes sobre roteadores sem necessidade
de acesso direto ao equipamento;
Pode ser acessado atravs de uma interface Web, facilitando o
diagnostico de problemas na rede;
Permite o acesso via conexes Pv6.
142
142
143
143
Segurana
MduIo 6
No projeto do IPv6 a questo da segurana Ioi pensada desde o inicio. Mecanismos de
autenticao e encriptao passaram a Iazer parte do protocolo IPv6, disponibilizando para
qualquer par de dispositivos de uma conexo Iim-a-Iim, mtodos que visam garantir a segurana
dos dados que traIegam pela rede. No entanto, inumeros problemas ainda existem e novas Ialhas
de segurana tambm surgiram.
Neste modulo abordaremos cada um desses novos cenarios, analisando as novas
Ierramentas de segurana do IPv6 e traando um paralelo entre as ameaas existentes no IPv4 e
em seu sucessor.
144
144
Segurana
Pv4
Projetado para interligar rede acadmicas sem muita
preocupao com segurana.
Uso comercial operaes bancrias, comrcio eletrnico,
troca de informao confidenciais.....
Ameaas
Varredura de endereos (Scanning)
Falsificao de endereos (Spoofing)
Manipulao de cabealho e fragmentao
Vrus, Cavalos de Tria e Worms
...
NAT + PSec so incompatveis
Destinado principalmente a interligar redes de pesquisa acadmicas, o projeto original do
IPv4 no apresentava nenhuma grande preocupao com a questo da segurana das inIormaes
transmitidas. No entanto, o aumento da importncia da Internet para a realizao de transaes
entre empresas e consumidores, por exemplo, Iez com que um nivel maior de segurana passasse
a ser exigido, como identiIicao de usuarios e criptograIia de dados, tornando necessario anexar
novos mecanismos ao protocolo original, que garantissem tais servios. Contudo, as solues
adotadas normalmente so especiIicas para cada aplicao.
Este Iato bastante claro na Internet atual. Ha quem deIenda que deveria haver uma nova
Internet, projetada do zero (abordagem clean slate) para resolver esse problema.
145
145
Pv6 mais seguro?
Apresenta novos problemas:
Tcnicas de transio;
Descoberta de vizinhana e Autoconfigurao;
Modelo fim-a-fim;
Mobilidade Pv6;
Falta de Best Practices, polticas, treinamento,
ferramentas....
Segurana no IPv6
Alguns aspectos de segurana Ioram abordados no projeto do IPv6, mas suas
implementaes ainda esto imaturas. Apesar de ter mais de dez anos, no ha boa experincia de
uso. As melhores praticas ainda so adaptadas do IPv4, e isso nem sempre Iunciona bem.
146
146
Segurana no IPv6
Pv6 mais seguro?
Ferramentas de Segurana
PSec
Secure Neighbor Discovery (SEND)
Estrutura dos Endereos
Cryptographically Generated Address (CGA)
Extenses de Privacidade
Unique Local Addresses (ULA)
No IPv6 a segurana Ioi uma preocupao desde o inicio, varias Ierramentas de segurana
Ioram implementadas no protocolo.
Mais inIormaes:
RFC 4864 - Local Network Protection for IPv6
147
147
Segurana no IPv6
Estratgia de mplantao
Sem planejamento... Ex:
Roteadores wireless
Sistemas sem firewall
Projetos de ltima hora / demonstraes
Projetos sem o envolvimento de especialistas em segurana
Ou...
Planejamento (Plan)
Implantao (Do)
Verificao (Check)
Ao (Act)
Antes de entrar em detalhes sobre as Ierramentas, vamos pensar um pouco sobre a
estratgia de implantao do IPv6.
Podemos pensar em varios exemplos historicos de implantaes de tecnologias novas em
que no houve uma preocupao com aspectos de segurana desde o inicio, como quando
surgiram os roteadores wireless. Podemos pensar, certamente, em varios exemplos do dia a dia, de
projetos de ultima hora, demonstraes para clientes, que acabam tornando-se sistemas em
produo e apresentando varias vulnerabilidades.
O ideal que a implantao do IPv6 seja Ieita de uma Iorma planejada e organizada, com a
preocupao com a segurana presente desde o inicio.
Este e os slides seguintes Ioram retirados da apresentao de Joe Klein, na Google IPv6
Implementors Conference 2009. O original pode ser encontrado em:
https://sites.google.com/site/ipv6implementors/conIerence2009/agenda/03KleinIPv6Security.pdI?attredirects0
148
148
DesenvoIvimento de Sistemas com IPv6
HabiIitado
Data Produtos Suporte ao IPv6 IPv6 HabiIitado
1996 OpenBSD / NetBSD / FreeBSD Sim Sim
Linux KerneI 2.1.6 Sim No
1997 AIX 4.2 Sim No
2000 Windows 95/98/ME/NT 3.5/NT 4.0 Sim (pacotes adicionais) No
Windows 2000 Sim No
SoIaris 2.8 Sim Sim
2001 Cisco IOS (12.x e superior) Sim No
2002 Juniper (5.1 e superior) Sim A maioria
IBM z/OS Sim Sim
AppIe OS/10.3 Sim Sim
Windows XP Sim No
Linux KerneI 2.4 Sim No
AIX 6 Sim Sim
IBM AS/400 Sim Sim
2006 Roteadores Linksys (Mindspring) Sim No
TeIefones CeIuIares (Vrios) Sim Sim
SoIaris 2.10 Sim Sim
Linux KerneI 2.6 Sim Sim
2007 AppIe Airport Extreme Sim Sim
BIackBerry (TeIefone CeIuIar) Sim No
Windows Vista Sim Sim
HP-UX 11iv2 Sim Sim
Open VMS Sim Sim
Mac OS/X Leopard Sim Sim
2009 CIoud Computing e Sistemas embarcados Sim Sim
E interessante notar quantos sistemas so capazes de executar o IPv6, e que muitos deles
vm com o protocolo habilitado por padro. A lista inclui Sistemas Operacionais, teleIones
celulares, equipamentos de redes, entre outros.
149
149
Incidentes de segurana no IPv6
2001 Reviso de logs, aps anuncio do Projeto Honeynet
2002 Projeto Honeynet: Lance Spitzner: Solaris
Snort: Martin Roesch: Pv6 adicionado, depois removido
2003 Worm: W32.HLLW.Raleka: Download de arquivos de um local pr-
definido e conecta em um RC server
2005 Trojam: Troj/LegMir-AT: Conecta em um RC server
CERT: Backdoors usando Teredo Pv6
Mike Lynn: Blackhat: captura de pacotes Pv6
2006 CAMSECWest: THC Pv6 Hacking Tools
RP Murphy: DefCon: Backdoors Pv6
2007 Rootkit: W32/Agent.EZM!tr.dldr: TCP HTTp SMTP
James Hoagland: Blackhat: falha relatada no Teredo Pv6 do Vista
2008 HOPE: Vulnerabilidade em telefones mveis com Pv6
Novembro: Atacantes esto tentando ou usando-o como
mecanismo de transporte para botnets. Pv6 tornou-se um problema
do lado operacional.Arbor Networks
Incidentes de Segurana envolvendo IPv6 vm sendo reportados ha tempos.
Ex:
From: Lance Spitzner <lance_at_honeynet.org>
Date: Tue, 17 Dec 2002 20:34:33 -0600 (CST)
Recently one of the Honeynet Project's Solaris Honeynets was
compromised.
What made this attack unique was after breaking into the system,
the attackers enabled IPv6 tunneling on the system, with communications
being forwarded to another country. The attack and communications were
captured using Snort, however the data could not be decoded due to the
IPv6 tunneling. Also, once tunneled, this could potentialy disable/bypass the
capabilities of some IDS systems.
Marty is addressing this issue and has added IPv6 decode support to Snort.
Its not part of Snort current (2.0) yet, its still in the process of testing. If you
would like to test this new capability, you can find it online at
http://www.snort.org/~roesch/
Marty's looking for feedback. As IPv6 usage spreads, especially in Asia, you
will want to be prepared for it. Keep in mind, even in IPv4 environments (as
was our Solaris Honeynet) attackers can encode their data in IPv6 and then
tunnel it through IPv4. We will most likely being seeing more of this type of
behavior.
Just a friendly heads-up :)
-- Lance Spitzner http://www.tracking-hackers.com
150
150
MaIwares
Data Infeco Nome
2001 10/1/2001 DOS bot pv4.ipv6.tcp.connection
2003 9/26//2003 Worm W32/Raleka!worm
2004 7/6/2004 Worm W32/Sbdbot-JW
2005 2/18/2005 Worm W32/Sdbot-VJ
8/24/2005 Trojan Troj/LegMir-AT
9/5/2005 Trojan Troj/LegMir-AX
2006 4/28/2006 Trojan W32/Agent.ABU!tr.dldr
2007 1/2/2007 Trojan Cimuz.CS
4/10/2007 Trojan Cimuz.EL
5/4/2007 Trojan Cimuz.FH
11/5/2007 Worm W32/Nofupat
11/15/2007 Trojan Trojan.Astry
12/1/2007 Rootkit W32/Agent.EZM!tr.dldr
12/16/2007 Trojan W32/Agent.GBU!tr.dldr
12/29/2007 Worm W32/VB-DYF
2008 4/22/2008 Trojan Troj/PWS-ARA
5/29/2008 Trojan Generic.dx!DAEE3B9
Da mesma Iorma, malwares que Iazem uso do IPv6 ou atacam sistemas IPv6 vm sendo
reportados pelo menos desde 2001.
151
151
VuInerabiIidades IPv6
2000 2001 2002 2003 2004 2005 2006 2007 2008
70
60
50
40
30
20
10
0
Vulnerabilidades Pv6 publicadas ao longo do tempo
TotaI
No
corrigidas
O numero de vulnerabilidades (encontradas) deve crescer, com o aumento do uso do IPv6.
152
152
Impactos das VuInerabiIidades
Obteno de
PriviIgio
Execuo de Cdigo
OverfIow
DivuIgao de Informaes
Outros
DoS
VuInerabiIidades IPv6 pubIicadas por cIassificao
A maior parte das vulnerabilidades torna os sistemas sujeitos a ataques DoS.
153
153
NcIeo dos ProbIemas
VuInerabiIidades IPv6 pubIicadas por tecnoIogia
A maior parte das vulnerabilidades publicadas aIeta equipamentos de rede
154
154
reas de Ataque
Durante a transio de IPv4 para IPv6 ha o uso de ambas as tecnologias nativamente, e de
tuneis. Observando a Iigura v-se 7 superIicies de ataque possiveis, nesse contexto.
155
155
AIvos nas 7 Camadas
nterface de usurio
Bibliotecas de programao
Tratamento de erros
Problemas de codificao
Problemas de Logs
AP's
mplementaes imprprias
ncompatibilidade L2/L3, MTU, etc
Camada de ApIicao
Camada de Apresentao
Camada de Sesso
Camada de Transporte
Camada de Rede
Camada de EnIace
Camada Fsica
Apesar do IP tratar da camada de rede, implicaes nas outras camadas podem levar
tambm a vulnerabilidades ou problemas.
156
156
Segurana no IPv6
O IPv6 oIerece varias Ierramentas tanto para deIesa, quanto para o ataque:
DeIesa:
IPsec
SEND
Crypto-generatea Aaaress
Unique Local Aaaresses
Privacy Aaaresses
Ataque:
Tunel automatico
Neighbor Discovery e autoconIigurao
Modelo Iim a Iim
Novidade / Complexidade
Falta de politicas, treinamentos e Ierramentas.
Deve-se:
Ter preocupao com segurana e envolver a equipe de segurana desde o inicio
Obter equipamentos certiIicados
Educao / Treinamento
Fazer upgrade das Ierramentas e processos de segurana
Desenvolver praticas de programao adequadas (e seguras) para IPv6
Procurar auditorias / equipes de teste que conheam IPv6
157
157
IPSec
mplementa criptografia e autenticao de pacotes na camada de
rede.
Fornecendo soluo de segurana fim-a-fim.
Associaes de segurana.
Garante a integridade, confidencialidade e autenticidade dos
dados.
Desenvolvido como parte integrante do Pv6.
Suporte obrigatrio.
Adaptado para funcionar com o Pv4.
Suporte opcional.
O IPSec Ioi desenvolvido para o IPv4 e pouca coisa muda com o IPv6. Contudo o suporte
passa a ser mandatorio, e no ha a NAT para atrapalhar o Iuncionamento.
158
158
IPSec - Modos de Operao
O PSec pode operar em dois modos:
Modo de Transporte
Modo TneI (VPN de Camada 3)
O IPSec pode ser utilizado de duas Iormas distintas, em modo de transporte, ou em modo
de tunel. No modo de transporte, ambos os extremos da comunicao necessitam de suporte
IPSec, entre os quais se realiza a comunicao segura.
Ao contrario do modo de transporte, no modo de tunel (tambm conhecido por VPN) o
IPSec implementado em dispositivos proprios (ex: concentradores VPN), entre os quais sera
eIetuada a comunicao IPSec encapsulando todos os pacotes IP dos respectivos extremos.
E de salientar, que no caso de uma comunicao em modo de transporte, o cabealho do
pacote IP original mantm-se. No modo de tunel, este codiIicado e criado um novo cabealho
tornando possivel a ligao entre o dispositivo emissor, com o dispositivo receptor (do tunel).
Transporte - protege apenas os protocolos das camadas superiores, pois o cabealho
de segurana aparece imediatamente apos o cabealho IP e antes dos cabealhos dos
protocolos das camadas superiores;
Tnel - protege todo o pacote IP, encapsulando-o dentro de outro pacote IP, deixando
visivel apenas o cabealho IP externo.
159
159
IPSec
Framework de segurana - utiliza recursos independentes para
realizar suas funes.
Authentication Header (AH)
ntegridade de todo o pacote;
Autenticao da origem;
Proteo contra o reenvio do pacote.
Encapsulating Security Payload (ESP)
Confidencialidade;
ntegridade do interior do pacote;
Autenticao da origem;
Proteo contra o reenvio do pacote.
Internet Key Exchange (KE)
Gerar e gerenciar chaves de segurana.
160
160
IPSec - AH
Authentication Header (AH)
adicionado aps os cabealhos Hop-by-Hop, Routing e
Fragmentation (se houver);
Pode ser utilizado em ambos os modos de operao.
Nmero de Sequncia
Tam. cab. de
extenso
Prximo
Cabealho
Reservado
ndice de Parmetros de Segurana
Autenticao dos Dados
161
161
IPSec - ESP
Encapsulating Security Payload (ESP)
Responsvel pela criptografia dos dados (opcional);
Pode ser utilizado em ambos os modos de operao;
Pode ser combinado com o AH.
Autenticao dos Dados
Nmero de Sequncia
ndice de Parmetros de Segurana
Tamanho do
complemento
Prximo
Cabealho
Dados + Complemento
162
162
IPSec -
Gerenciamento de Chaves
Manual
Chaves configuradas em cada sistema.
Automtica
Internet Key Exchange (KE)
Baseado em trs protocolos
SAKMP
OAKLEY
SKEME
Funciona em duas fases
Possui duas verses
KEv1
KEv2
O Gerenciamento de Chaves uma das diIiculdades operacionais para implantar-se o
IPSec no IPv4, e continua tendo o mesmo nivel de complexidade no IPv6.
Mais inIormaes:
RFC 4301 - Security Architecture for the Internet Protocol
163
163
SEcure Neighbor Discovery -
SEND
Pv4 - ataques ao ARP e DHCP (Spoofing).
No h mecanismos de proteo.
Pv6 - utiliza o protocolo de Descoberta de Vizinhana.
Mensagens CMPv6 - no depende da camada de enlace;
Possui as mesmas vulnerabilidades que o ARP e o DHCP;
H dificuldades na implementao de PSec.
Problemas na gerao automtica de chaves.
Mais inIormaes:
RFC 3756 - IPv6 Neighbor Discovery (ND) Trust Moaels ana Threats
RFC 3971 - SEcure Neighbor Discovery (SEND)
164
164
SEND
Cadeia de certificados.
Utilizados para certificar a autoridade dos roteadores.
Utilizar endereos CGA.
Gerados criptograficamente.
Nova opo do protocolo de Descoberta de Vizinhana.
RSA signature - protege as mensagens relativas ao Neighbor Discovery
e ao Router Discovery.
Duas novas opes do protocolo de Descoberta de Vizinhana.
Timestamp e nonce - preveni ataques de reenvio de mensagens.
165
165
Estrutura dos Endereos
Os 128 bits de espao para endereamento podem dificultar alguns
tipos de ataques.
Novas formas de gerar D.
A filtragem dos endereos tambm muda.
Endereos bogons.
Novos tipos de ataques.
166
166
Varredura de endereos (Scanning)
Tornou-se mais complexo, mas no impossvel.
Com uma mascara padro /64, so possveis 2
64
endereos por
sub-rede.
Percorrendo 1 milho de endereos por segundo, seria preciso
mais de 500.000 anos para percorrer toda a sub-rede.
NMAP s tem suporte para escanear um nico host de
cada vez.
Worms que utilizam essa tcnica para infectar outros
dispositivos, tambm tero dificuldades para continuar se
propagando.
Estrutura dos Endereos
167
167
Varredura de endereos (Scanning)
Devem surgir novas tcnicas:
Explorar endereos de servidores pblicos divulgados no
DNS.
Procura por endereos fceis de memorizar utilizados por
administradores de redes.
::10, ::20, ::DAD0, ::CAFE.
ltimo Byte do endereo Pv4.
Explorar endereos atribudos automaticamente com base no
MAC, fixando a parte do nmero correspondente ao
fabricante da placa de rede.
Estrutura dos Endereos
168
168
Endereos - CGA
Endereos Pv6 cujas Ds so geradas criptograficamente
utilizando uma funo hash de chaves pblicas.
Prefixo /64 da sub-rede .
Chave pblica do proprietrio endereo.
Parmetro de segurana.
Utiliza certificados X.509.
Utiliza a funo hash SHA-1.
Mais inIormaes:
RFC 3972 - Cryptographically Generatea Aaaresses (CGA)
169
169
Endereos -
Extenses de Privacidade
Extenso do mecanismo de autoconfigurao stateless.
Gera endereos temporrios e/ou randmicos.
Dificulta o rastreamento de dispositivos ou usurios.
Os endereos mudam de acordo com a poltica local.
Para cada endereo gerado, deve-se executar a Deteco de
Endereos Duplicados.
Mais inIormaes:
RFC 4864 - Local Network Protection for IPv6
RFC 4941 - Privacy Extensions for Stateless Aaaress Autoconfiguration in IPv6
170
170
Segurana no IPv6
A segurana em redes Pv6 no difere substancialmente da
segurana em redes Pv4.
Muitas formas de ataque continuam idnticas e a forma de evit-
las tambm.
Sniffing
Ataques camada de aplicao
Man-in-the-Middle
Vrus
DoS
PSec no a soluo de todos os problemas.
Muitas implementaes da pilha IPv6 ainda no suportam IPSec integralmente. Assim, ele
vem sendo usado sem o suporte criptograIico. Mesmo quando este utilizado, varias questes de
segurana em redes IP ainda esto presentes. Mas o IPv6 pode potencialmente melhorar a
segurana na Internet.
DoS: No existem endereos broaacast em IPv6
Evita ataques atravs do envio de pacotes ICMP para o endereo de broaacast.
As especiIicaes do IPv6 proibem a gerao de pacotes ICMPv6 em resposta a mensagens
enviadas para endereos globais multicast (com a exceo da mensagem packet too big).
Muitos Sistemas Operacionais seguem a especiIicao;
Ainda ha alguma incerteza sobre o perigo que pode ser criado por pacotes ICMPv6 com
origem em endereos multicast globais.
171
171
Recomendaes
mplementar extenses de privacidade apenas em comunicaes
externas.
Cuidado com o uso indiscriminado. Pode dificultar auditorias
internas.
Endereos de uso interno devem ser filtrados nos roteadores de
borda.
Endereos multicast como FF02::1(all-nodes on link), FF05::2
(all-routers on link) e FF05::5 (all DHCPv6 servers) podem se
tornar novos vetores de ataque.
Filtrar trfego ingresso de pacotes com endereos de origem
multicast.
172
172
Recomendaes
No usar endereos bvios;
Filtrar servios desnecessrios no firewall.
Filtrar mensagens CMPv6 no essenciais.
Filtrar endereos bogon.
Essa filtragem no Pv6 diferente da feita no Pv4.
No Pv4, bloqueia-se as faixa no-alocadas (h poucas).
No Pv6 o inverso. mais fcil liberar apenas as faixas
alocadas.
Mais inIormaes:
RFC 3704 - Ingress Filtering for Multihomea Networks
RFC 4890 - Recommenaations for Filtering ICMPv6 Messages in Firewalls
173
173
Recomendaes
Bloquear fragmentos de pacotes Pv6 com destino a equipamentos
de rede.
Descartar pacotes com tamanho menor do que 1280 Bytes (exceto
o ltimo).
Os mecanismos de segurana do BGP e do S-S no mudam.
Com OSPFv3 e RPng deve-se utilizar PSec.
Limitar o nmero de saltos para proteger dispositivos de rede.
E utilizar PSec sempre que necessrio.
174
174
175
Para que a transio entre os dois Protocolo Internet ocorra de Iorma gradativa e sem
maiores impactos no Iuncionamento das redes, necessario que exista um periodo de coexistncia
entre os protocolos IPv4 e IPv6.
Neste modulo, aprenderemos as diIerentes tcnicas de transio utilizadas, analisando os
conceitos basicos do Iuncionamento da Pilha Dupla, dos Tuneis e das Tradues, de modo a
entender em qual situao cada tcnica melhor aplicada.
175
Coexistncia e
Transio
MduIo 7
176
Com o intuito de Iacilitar o processo de transio entre as duas verses do Protocolo
Internet, algumas tcnicas Ioram desenvolvidas para que toda a base das redes instaladas sobre
IPv4 mantenha-se compativel com o protocolo IPv6, sendo que nesse primeiro momento de
coexistncia entre os dois protocolo, essa compatibilidade torna-se essencial para o sucesso da
transio para o IPv6.
Cada uma dessa tcnicas apresenta uma caracteristica especiIica, podendo ser utilizada
individualmente ou em conjunto com outras tcnicas, de modo a atender as necessidades de cada
situao, seja a migrao para o IPv6 Ieita passo a passo, iniciando por um unico host ou sub-rede,
ou at de toda uma rede corporativa.
176
Toda a estrutura da nternet est baseada no Pv4.
Uma troca imediata de protocolo invivel devido o tamanho e a
proporo que esta rede possui.
A adoo do Pv6 deve ser realizada de forma gradual.
Haver inicialmente um perodo de transio e de coexistncia
entre os dois protocolos.
Redes Pv4 precisaro comunicar-se com redes Pv6 e vice-versa.
Para facilitar este processo, foram desenvolvidas algumas tcnicas
que visam manter a compatibilidade de toda a base das redes
instaladas sobre Pv4 com o novo protocolo Pv6.
Coexistncia e Transio
177
Estes mecanismos de transio podem ser classiIicados nas seguintes categorias:
Pilha Dupla: que prov o suporte a ambos os protocolos no mesmo dispositivo;
Tunelamento: que permite o traIego de pacotes IPv6 sobre estruturas de rede IPv4; e
Traduo: que permite a comunicao entre nos com suporte apenas a IPv6 com nos
que suportam apenas IPv4.
Como o periodo de coexistncia entre os dois protocolos pode durar indeIinidamente, a
implementao de mtodos que possibilitem a interoperabilidade entre o IPv4 e o IPv6, podera
garantir uma migrao segura para o novo protocolo, atravs da realizao de testes que permitam
conhecer as opes que estes mecanismos oIerecem, alm de evitar, no Iuturo, o surgimento de
'ilhas isoladas de comunicao.
177
Estas tcnicas de transio so divididas em 3 categorias:
PiIha DupIa
Prov o suporte a ambos os protocolos no mesmo
dispositivo.
TuneIamento
Permite o trfego de pacotes Pv6 sobre a estrutura da rede
Pv4 j existente.
Traduo
Permite a comunicao entre ns com suporte apenas a
Pv6 com ns que suportam apenas Pv4.
Coexistncia e Transio
178
Nesta Iase inicial de implementao do IPv6, ainda no aconselhavel ter nos com suporte
apenas a esta verso do protocolo IP, visto que muitos servios e dispositivos de rede ainda
trabalham somente sobre IPv4. Deste modo, uma possibilidade a de se introduzir o mtodo
conhecido como pilha dupla.
A utilizao deste mtodo permite que hosts e roteadores estejam equipados com pilhas
para ambos os protocolos, tendo a capacidade de enviar e receber os dois pacotes, IPv4 e IPv6.
Com isso, um no Pilha Dupla, ou no IPv6/IPv4, na comunicao com um no IPv6, se comportara
como um no apenas IPv6, e na comunicao com um no IPv4, se comportara como um no apenas
IPv4.
Cada no IPv6/IPv4 conIigurado com ambos endereos, utilizando mecanismos IPv4 (ex.
DHCP) para adquirir seu endereo IPv4, e mecanismos do protocolo IPv6 (ex. autoconIigurao
e/ou DHCPv6) para adquirir seu endereo IPv6.
Este mtodo de transio pode Iacilitar o gerenciamento da implantao do IPv6, por
permitir que este seja Ieito de Iorma gradual, conIigurando pequenas sees do ambiente de rede
de cada vez. Alm disso, caso no Iuturo o IPv4 no seja mais usado, basta simplesmente
desabilitar a pilha IPv4 de cada no.
178
Os ns tornam-se capazes de enviar e
receber pacotes tanto para o Pv4,
quanto para o Pv6.
Um n Pv6/Pv4, ao se comunicar com
um n Pv6, se comporta-se como um
n Pv6 e na comunicao com um n
Pv4, como n Pv4.
O precisa de pelo menos um endereo
para cada pilha.
Utiliza mecanismos Pv4, como por
exemplo DHCP, para adquirir endereos
Pv4, e mecanismos do Pv6 para
endereos Pv6.
PiIha DupIa
179
Alguns aspectos devem ser considerados ao se implementar a tcnica de pilha dupla. A
necessidade de mudanas na inIra-estrutura da rede deve ser analisada, como a estruturao do
servio de DNS e a conIigurao dos protocolos de roteamento e de firewalls.
Em relao ao DNS, preciso que este esteja habilitado para resolver nomes e endereos
de ambos os protocolos. No caso do IPv6, preciso responder a consultas de registros do tipo
AAAA (quad-A), que armazenam endereos no Iormato do IPv6, e para o dominio criado para a
resoluo de reverso, o ip6.arpa. Para mais detalhes sobre o suporte do DNS ao IPv6, consulte a
RFC 3596.
Em uma rede IPv6/IPv4, a conIigurao do roteamento IPv6 normalmente independente
da conIigurao do roteamento IPv4. Isto implica no Iato de que, se a rede antes de ser
implementada a pilha dupla utilizava apenas o protocolo de roteamento interno OSPFv2, com
suporte apenas ao IPv4, sera necessario migrar para um protocolo de roteamento que suporte tanto
IPv6 quanto IPv4, como IS-IS por exemplo, ou Iorar a execuo de um IS-IS ou OSPFv3
paralelamente com o OSPFv2.
A Iorma como Ieita a Iiltragem dos pacote que traIegam na rede, pode depender da
plataIorma que se estiver utilizando. Em um ambiente Linux, por exemplo, os Iiltros de pacotes
so totalmente independentes um dos outros, de modo que o iptables Iiltra apenas pacotes IPv4 e
o ip6tables apenas IPv6, no compartilhando nenhuma conIigurao. No FreeBSD, as regras so
aplicadas a ambos os protocolos, a menos que se restrinja explicitamente a qual Iamilia de
protocolo as regras devem ser aplicadas, usando inet ou inet6.
179
Uma Rede Pilha Dupla uma infraestrutura capaz de encaminhar
ambos os tipos de pacotes.
Exige a anlise de alguns aspectos:
Configurao dos servidores de DNS;
Configurao dos protocolos de roteamento;
Configurao dos firewalls;
Mudanas no gerenciamento das redes.
PiIha DupIa
180
A tcnica de criao de tuneis, ou tunelamento, permite transmitir pacotes IPv6 atravs da
inIra-estrutura IPv4 ja existente, sem a necessidade de realizar qualquer mudana nos mecanismos
de roteamento, encapsulando o conteudo do pacote IPv6 em um pacote IPv4.
Essas tcnicas, tratadas na RFC 4213, tm sido as mais utilizadas na Iase inicial de
implantao do IPv6, por serem Iacilmente aplicadas em teste, onde ha redes no estruturadas
para oIerecer traIego IPv6 nativo.
Mais inIormaes:
RFC 4213 - Basic Transition Mechanisms for IPv6 Hosts ana Routers
180
Tambm chamada de encapsulamento.
O contedo do pacote Pv6 encapsulado em um pacote Pv4.
Podem ser classificadas nos seguintes modos:
Roteador-a-Roteador
Host-a-Roteador
Roteador-a-Host
Host-a-Host
Tcnicas de TuneIamento
181
Existem diversas tcnicas de tunelamento disponiveis. Os cenarios onde podem ser
aplicados, as diIiculdades de implementao e a diIerena de perIormance variam
signiIicativamente entre os modelo, necessitando uma analise detalhada de cada um. As principais
tcnicas de tunelamento so:
Tunnel Broker
6to4
ISATAP
Teredo
GRE
Vamos agora, analisar detalhadamente cada uma dessas tcnicas.
181
Existem diferentes formas de encapsulamento:
Pacotes Pv6 encasulado em pacotes Pv4;
Protocolo 41.
6to4, SATAP e Tunnel Brokers.
Pacotes Pv6 encapsulado em pacotes GRE;
Protocolo GRE.
Pacotes Pv6 encapsulados em pacotes UDP;
TEREDO.
Tcnicas de TuneIamento
182
Descrita na RFC 3053, essa tcnica permite que hosts IPv6/IPv4 isolados em uma rede
IPv4 acessem redes IPv6. Seu Iuncionamento bastante simples, primeiramente necessario
cadastrar-se em um provedor de acesso Tunnel Broker e realizar o aownloaa de um software ou
script de conIigurao. A conexo do tunel estabelecida atravs da solicitao do servio ao
Servidor Web do provedor, que apos autenticao, veriIica qual tipo de conexo o cliente esta
utilizado (IPv4 publico ou NAT) e lhe atribui um endereo IPv6. A partir desse ponto, o cliente
pode acessar qualquer host na Internet.
Mais inIormaes:
RFC 3053 - IPv6 Tunnel Broker
182
Tunnel Broker
Consiste em um tnel Pv6 dentro da rede Pv4, criado do seu
computador ou rede at o provedor que ir fornecer a conectividade
Pv6.
Basta cadastrar-se em um provedor de acesso Tunnel Broker e
realizar o download de um software ou script de configurao.
A conexo do tnel feita atravs da solicitao do servio ao
Servidor Web do provedor.
ndicado para redes pequenas ou para um nico host isolado.
183
DeIinida na RFC 3056, a tcnica de tunelamento automatica 6to4 permite a interconexo
ponto-a-ponto entre roteadores, subredes ou computadores IPv6 atravs da rede IPv4, Iornecendo
um endereo IPv6 unico Iormado a partir de endereos IPv4 publicos. Este endereamento 6to4
utiliza o preIixo de endereo global 2002:wwxx:yyzz::/48, onde wwxx:yyzz o endereo IPv4
publico do cliente convertido para hexadecimal.
* Cliente/Roteador 6to4: cliente que possui um endereo IPv4 publico e conectividade direta
6to4, ou seja, ele tem uma interIace virtual 6to4 pela qual acessa diretamente a Internet IPv6 sem
necessidade de utilizao de roteador 6to4. Ele necessita apenas de um Relay 6to4;
* Roteador 6to4: roteador que suporta 6to4, possibilitando aos clientes que no suportam este
tipo de endereo, acessarem outros hosts 6to4 IPv6 atravs dele. No caso dos acessos a Internet
IPv6, ele direcionara o traIego at o Relay Router mais proximo, que encaminhara o pacote para a
rede IPv6;
* Relay 6to4: roteador com suporte ao 6to4 e que tambm possui conexo nativa a Internet
IPv6. Com isso, ele consegue rotear e se comunicar com a rede IPv6 nativa, com a rede IPv4 e
com a rede 6to4;
* Cliente 6to4: equipamento de rede ou computador que possui apenas endereo IPv6 no
Iormato 6to4, mas que no tem uma interIace virtual 6to4. Com isso, ha a necessidade de um
Roteador 6to4 que Iaa a comunicao com outras redes IPv6 e 6to4.
Mais inIormaes:
RFC 3056 - Connection of IPv6 Domains via IPv4 Clouas
183
Forma de tunelamento roteador-a-roteador.
Fornecendo um endereo Pv6 nico ao
host.
O endereo formado pelo prefixo de
endereo global 2002:wwxx:yyzz::/48,
onde wwxx:yyzz o endereo Pv4
pblico do host convertido para
hexadecimal.
O relay 6to4 pode ser identificado pelo
endereo anycast 192.88.99.1.
Encaminhamento Assimtrico.
Pode ser utilizada com Relays pblicos,
quando no h conectividade v6 nativa.
Quando h conectividade nativa e servios,
deve ser implementada para facilitar a
comunicao com clientes 6to4.
6to4
184
- O preIixo 6to4 sempre 2002, conIorme deIinio da IANA;
- O proximo campo, IPv4 publico do cliente, criado conIorme o seguinte exemplo:
Endereo IPv4: 200.192.180.002
Primeiro convertemos cada numero decimal para hexadecimal:
200C8
192C0
180B4
00202
Com isso, o endereo convertido C8C0:B402
- O ID da subrede utilizado apenas para segmentar a rede 6to4 associada ao IPv4 publico em
varias subredes(2
16
subredes com 2
64
endereos cada), pode se utilizar por exemplo 0, 1, 2, 3, 4...;
- O ID da interIace pode ser igual ao segundo campo(IPv4 convertido para hexadecimal) no caso
da conIigurao automatica do Windows Vista e Server 2008 ou ento 1, 2, 3, 4... no caso de
conIigurao manual ou do Linux e BSD. Como o comprimento deste campo de 64 bits,
podemos ter at 2
64
endereos por subrede.
184
6to4
O prefixo 6to4 sempre 2002.
O prximo campo, Pv4 pblico do cliente, criado convertendo-se
o endereo para hexadecimal.
O D da subrede pode ser usado para segmentar a rede Pv6 6to4
em at 2
16
subredes com 2
64
endereos cada, pode se utilizar por
exemplo 0, 1, 2, 3, 4...
O D da interface pode ser igual ao segundo campo (Windows faz
assim) ou qualquer outro nmero no caso de configurao manual
(no Linux, usa-se sequencial 1, 2, 3, 4...).
185
Equipamento Rota
C1 ::/0 atravs de R1
2002:0102:0304:1::/64 atravs da interIace LAN
R1 ::/0 atravs do Relay 6to4 utilizando a interIace virtual 6to4
2002::/16 atravs da interIace virtual 6to4
2002:0102:0304:1/64 para a rede local atravs da interIace LAN
R2 ::/0 atravs de R2
2002:0102:0305:1:/64 para a rede local atravs da interIace LAN
C2 ::/0 atravs do Relay 6to4 utilizando a interIace virtual 6to4
2002::/16 atravs da interIace Virtual 6to4
2002:0102:0305:1:/64 para a rede local atravs da interIace LAN
1- Analisando a tabela de roteamento, nota-se que o pacote enviado atravs da rede local IPv6
para o roteador R1 utilizando a rota ::/0;
2- O pacote IPv6 recebido por R1 atravs da interIace LAN. R1 veriIica sua tabela de
roteamento e descobre que deve enviar o pacote para a sua interIace virtual 6to4 (rota para rede
2002::/16). Nesta interIace o pacote IPv6 encapsulado em um pacote IPv4 (protocolo tipo 41)
que endereado ao roteador R2 (endereo extraido do endereo IPv6 do destinatario do pacote
original);
3- O pacote IPv6 encapsulado em IPv4 recebido por R2 atravs da sua interIace IPv4 ou WAN.
Como o pacote do tipo 41, ele encaminhado a interIace virtual 6to4, que o desencapsula.
Consultando a sua tabela de roteamento, R2 descobre que o pacote destinado a sua rede local
2002:0102:03:05:1::/64, sendo assim, ele encaminha atravs da sua rede local o pacote IPv6 ao
computador C2.
Nos passos seguintes o sistema de comunicao o mesmo, mudando apenas a direo de
encaminhamento do pacote.
185
6to4
Comunicao CIiente 6to4 com CIiente 6to4 em redes diferentes
Note-se que o trfego na rede local nativo Pv6, ele encapsulado
apenas entre os roteadores 6to4
186
Equipamento Rota
HR1 ::/0 atravs da interIace virtual 6to4
2002::/16 atravs da interIace virtual 6to4
RL1 ::/0 rede IPv6 atravs da interIace LAN
2002::/16 atravs da interIace virtual 6to4
S1 Rota padro atravs de R1
R1 2002::/16 atravs do Relay RL1 (rota descoberta atravs da divulgao via BGP)
1- HR1 envia um pacote IPv6 para S1, atravs da tabela de roteamento o pacote direcionado
para a interIace virtual 6to4. Esta encapsula o pacote IPv6 em um pacote IPv4 (protocolo 41) e
coloca como destino o endereo do Relay, que pode ser especiIicado manualmente ou ento
descoberto automaticamente atravs do encaminhamento do pacote para o endereo anycast
192.88.99.1;
2- O Relay RL1 recebe o pacote encapsulado atravs do seu IPv4 ou anycast, como o protocolo
do pacote 41, ele desencapsula o pacote IPv6, e atravs da sua tabela de roteamento, descobre
que o pacote deve ser enviado para S1 atravs da sua interIace LAN na rede IPv6;
3- Depois de recebido o pacote, S1 responde utilizando a sua rota padro atravs do roteador R1
da sua rede. O roteador R1 recebeu via BGP a rota para a rede 2002::/16, e encaminha o pacote
para o Relay RL1;
4- RL1 recebe o pacote e v que ele destinado a rede 6to4, sendo assim, ele encaminha o pacote
para a interIace virtual 6to4, que o encapsula em um pacote IPv4 (protocolo 41) e atravs do
endereo IPv4 implicito no endereo IPv6 do destinatario, o pacote encaminhado para HR1.
HR1 recebe o pacote na sua interIace IPv4, v que esta sendo utilizado o protocolo 41 e
desencapsula o pacote IPv6 atravs da interIace virtual 6to4.
186
6to4
Comunicao CIiente/Roteador 6to4 com servidor IPv6
187
Equipamento Rota
RL1 ::/0 rede IPv6 atravs da interIace LAN / 2002::/16 atravs da interIace virtual 6to4
RL2 ::/0 rede IPv6 atravs da interIace LAN / 2002::/16 atravs da interIace virtual 6to4
S1 Rota padro atravs de R2
R2 2002::/16 atravs do Relay RL1 (rota descoberta atravs da divulgao via BGP)
R1 ::/0 atravs do Relay 6to4 RL1 ou RL2 utilizando a interIace virtual 6to4
2002::/16 atravs da interIace virtual 6to4
2002:0102:0304:1/64 para a rede local atravs da interIace LAN
C1 ::/0 atravs de R1 / 2002:0102:0304:1::/64 atravs da interIace LAN
C2 ::/0 atravs de R1 / 2002:0102:0304:1::/64 atravs da interIace LAN
1- De acordo com a tabela de roteamento, o pacote enviado atravs da rede local IPv6 para o roteador R1 utilizando
a rota ::/0;
2- O pacote IPv6 recebido por R1 atravs da interIace LAN, que veriIica a sua tabela de roteamento e descobre que
o pacote deve ser encaminhado para a interIace virtual 6to4 (rota para rede 2002::/16). Nesta interIace o pacote IPv6
encapsulado em um pacote IPv4 (protocolo tipo 41) enviado ao Relay RL1 ou RL2 (O Relay 6to4 pode ser
deIinido manualmente no roteador 6to4 ou ento automaticamente atravs da utilizao do endereo anycast
192.88.99.1). Vamos supor que o pacote Ioi enviado para o Relay RL1;
3- RL1 recebe o pacote 6to4 atravs de sua interIace IPv4, e como o pacote utiliza o protocolo 41, ele o encaminha
para a interIace virtual, que desencapsula o pacote IPv6 e veriIica na tabela de roteamento que deve envia-lo pela
interIace LAN atravs do roteador R2, que simplesmente repassa o pacote IPv6 ao servidor S1;
4- S1 responde com o envio de outro pacote IPv6 com destino ao Cliente C1 utilizando a sua rota padro que aponta
para o roteador R2. R2 recebe o pacote e atravs da rota recebida via BGP, ele sabe que deve envia-lo para o relay
mais proximo, neste caso RL1;
5- RL1 recebe o pacote IPv6 e veriIica que o destino a rede 6to4 (2002::/16). Sendo assim, de acordo com sua
tabela de roteamento, o pacote encaminhado para a interIace virtual 6to4, que o empacota em um pacote IPv4
(protocolo 41) e o envia ao endereo IPv4 implicito no endereo IPv6 do destinatario do pacote;
6- O roteador R1 recebe o pacote atravs de seu endereo IPv4, como o pacote esta utilizando o protocolo 41, este
encaminhado a interIace virtual 6to4, que o desencapsula e veriIica o endereo de destino. De acordo com sua tabela
de roteamento ela envia o pacote IPv6 atravs da sua interIace LAN para o Cliente 6to4 C1.
187
6to4
Comunicao CIiente 6to4 com servidor IPv6 utiIizando
apenas um ReIay 6to4 (Rota de ida e voIta iguais):
188
Equipamento Rota
RL1 ::/0 rede IPv6 atravs da interIace LAN / 2002::/16 atravs da interIace virtual 6to4
RL2 ::/0 rede IPv6 atravs da interIace LAN / 2002::/16 atravs da interIace virtual 6to4
S2 Rota padro atravs de R3
R3 2002::/16 atravs do Relay RL2 (rota descoberta atravs da divulgao via BGP)
R1 ::/0 atravs do Relay 6to4 RL1 ou RL2 utilizando a interIace virtual 6to4
2002::/16 atravs da interIace virtual 6to4
2002:0102:0304:1/64 para a rede local atravs da interIace LAN
C1 ::/0 atravs de R1 / 2002:0102:0304:1::/64 atravs da interIace LAN
C2 ::/0 atravs de R1 / 2002:0102:0304:1::/64 atravs da interIace LAN
1- De acordo com a tabela de roteamento, o pacote enviado atravs da rede local IPv6 para o roteador R1 utilizando
a rota ::/0;
2- O pacote IPv6 recebido por R1 atravs da interIace LAN, que veriIica sua tabela de roteamento e descobre que
deve enviar o pacote para a interIace virtual 6to4 (rota para rede 2002::/16). Nesta interIace o pacote IPv6
encapsulado em um pacote IPv4 (protocolo tipo 41) e enviado ao Relay RL1 ou RL2 (O Relay 6to4 pode ser deIinido
manualmente no roteador 6to4 ou ento automaticamente atravs da utilizao do endereo anycast 192.88.99.1).
Vamos supor que o pacote Ioi enviado para o Relay RL1;
3- RL1 recebe o pacote 6to4 atravs de sua interIace IPv4, v que o pacote utiliza o protocolo 41 e o encaminha para
a interIace virtual. Esta desencapsula o pacote IPv6 e veriIica na sua tabela de roteamento que deve envia-lo pela
interIace LAN atravs do roteador R3, que simplesmente repassa o pacote IPv6 ao servidor S2;
4- S2 responde com o envio de outro pacote IPv6 com destino ao Cliente C2 utilizando a sua rota padro que aponta
para o roteador R3. R3 recebe o pacote e atravs da rota recebida via BGP, ele sabe que deve envia-lo para o relay
mais proximo que RL2;
5- RL2 recebe o pacote IPv6 e veriIica que o destino a rede 6to4 (2002::/16). Deste modo, de acordo com sua
tabela de roteamento, ele encaminha o pacote para a interIace virtual 6to4, que o empacota em um pacote IPv4
(protocolo 41) e o envia ao endereo IPv4 implicito no endereo IPv6 do destinatario do pacote;
6- O roteador R1 recebe o pacote atravs de seu endereo IPv4, veriIica que o pacote esta utilizando o protocolo 41 e
o encaminha a interIace virtual 6to4. Esta o desencapsula e veriIica o endereo de destino. De acordo com sua tabela
de roteamento e o endereo de destino, o pacote IPv6 enviado atravs da sua interIace LAN para o Cliente 6to4 C2.
188
6to4
Comunicao CIiente 6to4 com servidor Ipv6 utiIizando
dois reIays 6to4 diferentes(Rota de ida e voIta diferentes)
189
189
6to4
Segurana
Os Relay roteador no verifica os pacotes Pv6 que esto
encapsulados em Pv4, apesar dele os encapsular e desencapsular;
O spoofing de endereo um problema grave de tneis 6to4,
podendo ser facilmente explorado;
No h um sistema de autenticao entre o roteador e o Relay
roteador, facilitando assim a explorao de segurana atravs da
utilizao de Relays roteadores falsos.
190
A tcnica de transio Intra-Site Automatic Tunnel Aaaressing Protocol (ISATAP),
deIinida na RFC 5214, baseada em tuneis IPv6 criados automaticamente dentro da rede IPv4, e
em endereos IPv6 associados aos clientes de acordo com o preIixo especiIicado no roteador
ISATAP e no IPv4 do cliente. Para a criao destes tuneis so utilizadas as especiIicaes da
seo 3 da RFC 4213, que trata o tunelamento atravs do protocolo IPv4 tipo 41 ou 6in4.
Mais inIormaes:
RFC 5214 - Intra-Site Automatic Tunnel Aaaressing Protocol (ISATAP)
190
SATAP (Intra-Site Automatic Tunnel Addressing Protocol ) - tcnica
de tunelamento que liga hosts-a-roteadores.
No h um servio pblico de SATAP, uma tcnica utilizada
dentro das organizaes.
Faz sentido, por exemplo, quando a organizao j tem numerao
Pv6 vlida e conectada na borda, mas sua infraestrutura interna
no suporta Pv6.
ISATAP
191
Exemplos de endereos ISATAP:
Endereo IPv4 Endereo IPv6/ISATAP
250.140.80.1 2001:10fe:0:8003:200:5efe:250.140.80.1
fe80::200:5efe:250.140.80.1
192.168.50.1 2001:10fe:0:8003:0:5efe:192.168.50.1
fe80:0:5efe:250.140.80.1
191
Endereamento
Nesta tcnica, o endereo Pv4 dos clientes e roteadores so utilizados
como parte dos endereos SATAP. Com isso, um n SATAP pode
determinar facilmente os pontos de entrada e sada dos tneis Pv6, sem
utilizar nenhum protocolo ou recurso auxiliar.
O formato do endereo SATAP segue o seguinte formato:
Prefixo unicast : qualquer prefixo unicast vlido em Pv6, que pode ser
link-local (FE80::/64) ou global;
ID IPv4 pbIico ou privado: Se o endereo Pv4 for pblico, este campo
deve ter o valor "200" e se for privado (192.168.0.0/16, 172.16.0.0/12 e
10.0.0.0/8) o valor do campo zero;
ID ISATAP: Sempre tem o valor 5EFE;
Endereo IPv4: o Pv4 do cliente ou roteador em formato Pv4;
ISATAP
192
1- Neste passo o cliente tenta determinar o endereo IPv4 do roteador, se o endereo IPv4 ja no
estiver determinado na sua conIigurao. No caso do Windows ele tenta por padro resolver o
nome ISATAP e ISATAP.dominio-local via resoluo local ou servidor DNS;
2- O servidor DNS retorna o IPv4 do roteador ISATAP (se Ior o caso);
3- O cliente envia uma mensagem de solicitao de roteador (RS) encapsulada em IPv4 ao
roteador ISATAP;
4- O Roteador ISATAP responde com uma mensagem de Anuncio de Roteador (RA) encapsulada
em IPv4, com isso, o cliente ja pode conIigurar os seus endereos IPv6/ISATAP.
192
1- Consulta ao DNS (no caso do Windows, procura por
SATAP.domnio-local)
2- O servidor DNS retorna o Pv4 do roteador SATAP
3- Router Solicitation (encapsulada em v4)
4- Router Advertisement (encapsulada em Pv4)
ncio
ISATAP
193
1- C2 solicita a resoluo DNS do nome do roteador ISATAP (Se necessario);
2- C2 recebe o IPv4 do roteador ISATAP (Se necessario);
3- O cliente envia uma mensagem de solicitao de roteador (RS) encapsulada em IPv4 ao
roteador ISATAP;
4- O Roteador ISATAP responde com uma mensagem de Anuncio de Roteador (RA) encapsulada
em IPv4, com isso, o cliente ja pode conIigurar os seus endereos IPv6/ISATAP;
Os processos de 1 a 4 so executados tambm por C1;
5- O cliente ISATAP C2 envia um pacote IPv6 encapsulado em IPv4 utilizando o protocolo 41
atravs da rede IPv4 com destino ao endereo IPv4 de C1;
6- O cliente ISATAP C1 recebe o pacote IPv4 e desencapsula o pacote IPv6 dele, apos isto, ele
responde com um outro pacote IPv6 encapsulado em IPv4 utilizando o protocolo 41 atravs da
rede IPv4 com destino ao endereo IPv4 do cliente C2.
193
A comunicao entre os clientes SATAP numa mesma rede feita
diretamente, sem a interferncia do Roteador SATAP (aps
autoconfigurao inicial). O trfego na rede sempre Pv4, o Pv6
encapsulado ou desencapsulado localmente nos clientes.
Comunicao entre cIientes ISATAP na mesma rede
ISATAP
194
1.O cliente ISATAP C1 quer enviar um pacote IPv6 para o cliente C2. Atravs de sua tabela de
roteamento ele descobre que tem que envia-lo utilizando a interIace virtual ISATAP, com isso, o
pacote encapsulado em IPv4 (protocolo 41) e enviado ao endereo IPv4 do roteador R1;
2.O roteador R1 recebe o pacote atravs de sua interIace IPv4, mas, como o pacote IPv6 esta
encapsulado utilizando o protocolo 41, ele o desencapsula (utilizando a interIace virtual ISATAP)
e veriIica o endereo IPv6 do destino. Depois disso ele descobre que a rota para o destino
atravs da rede IPv6, sendo assim, o pacote desencapsulado (IPv6 nativo) encaminhado para o
roteador R2;
3.O roteador R2 recebe o pacote IPv6 em sua interIace IPv6, mas veriIicando o endereo de
destino, descobre que ele para o cliente C2 que esta na sua subrede ISATAP, sendo assim, ele
envia o pacote atravs desta interIace, que encapsula novamente o pacote IPv6 em um pacote IPv4
e o envia a C2 (baseado no IPv4 que esta implicito no IPv6). O cliente ISATAP C1 recebe o
pacote IPv4 e desencapsula o pacote IPv6 (atravs da interIace virtual ISATAP);
4.O cliente ISATAP C2 quer responder ao cliente C1, sendo assim, ele veriIica a sua tabela de
rotas e conclui que tem que enviar o pacote atravs da interIace virtual ISATAP, com isso, o
pacote IPv6 encapsulado em IPv4 e encaminhado ao roteador R2;
5.O roteador R2 recebe o pacote atravs de sua interIace IPv4, mas, como o pacote esta utilizando
o protocolo 41, ele desencapsula o pacote IPv6 dele e veriIicando na sua tabela de roteamento, o
encaminha atravs da sua interIace IPv6;
6.O roteador R1 recebe o pacote IPv6, mas, veriIicando em sua tabela de roteamento descobre que
o pacote tem que ser enviado atravs de sua interIace virtual ISATAP, a qual encapsula o pacote
IPv6 em IPv4 utilizando o protocolo 41 e o encaminha o IPv4 de C1;
C1 recebe o pacote, mas, como ele esta encapsulado utilizando o protocolo 41, ele extrai o pacote
IPv6 enviado por C2 e o recebe.
194
O trfego SATAP entre clientes de redes Pv4 diferentes, depende
dos roteadores SATAP.
Na rede Pv4, o trfego v6 est sempre encapsulado dentro de
pacotes v4.
Entre os roteadores SATAP diferentes, o trfego v6 nativo.
Comunicao entre cIientes ISATAP em redes diferentes
ISATAP
195
1- O cliente ISATAP quer enviar um pacote IPv6 para o servidor IPv6. Atravs de sua tabela de
roteamento ele descobre que tem que envia-lo utilizando a interIace virtual ISATAP, com isso, o
pacote encapsulado em IPv4(protocolo 41) e enviado ao endereo IPv4 do roteador ISATAP;
2- O roteador ISATAP recebe o pacote atravs de sua interIace IPv4, mas, como o pacote IPv6
esta encapsulado utilizando o protocolo 41, ele o desencapsula(utilizando a interIace virtual
ISATAP) e veriIica o endereo IPv6 do destino. Depois disso ele descobre que a rota para o
destino atravs da rede IPv6, sendo assim, o pacote desencapsulado(IPv6 nativo) encaminhado
para o servidor IPv6. O servidor recebe o pacote IPv6 destinado a ele;
3- O servidor IPv6 quer responder ao cliente ISATAP, sendo assim, veriIicando sua tabela de
roteamento ele descobre que tem que enviar atravs de sua rota padro, que atravs da rede
IPv6;
4- Como a rota para a rede do cliente ISATAP atravs do roteador ISATAP, o pacote
encaminhado a ele atravs de sua interIace IPv6. VeriIicando em sua tabela de roteamento o
roteador descobre que tem que enviar o pacote atravs de sua interIace virtual ISATAP, sendo
assim, o pacote encapsulado em IPv4 e encaminhado ao cliente ISATAP atravs da rede IPv4. O
cliente recebe o pacote IPv4, mas, como ele esta utilizando o protocolo 41, ele desencapsula e
recebe o pacote IPv6.
195
Comunicao entre cIientes ISATAP e computadores IPv6
ISATAP
196
A tcnica de tunelamento automatica Teredo, deIinida na RFC 4380, permite que nos
localizados atras de Network Aaaress Translations (NAT), obtenham conectividade IPv6 utilizando o
protocolo UDP.
A conexo realizada atravs de um Servidor Teredo que a inicializa, e determinar o tipo de
NAT usada pelo cliente. Em seguida, caso o host de destino possua IPv6 nativo, um Relay Teredo
utilizado para criar uma interIace entre o Cliente e o host de destino. O Relay utilizado sera sempre o
que estiver mais proximo host de destino, e no o mais proximo ao cliente.
Esta tcnica no muito eIiciente devido ao overheaa e a complexidade de seu
Iuncionamento, entretanto, quando o host esta atras de NAT, ela uma das unicas opes.
Por padro, o Windows Vista ja traz o Teredo instalado e ativado, enquanto que no Windows
XP, 2003 e 2008, ele vem apenas instalado. Quanto ao FreeBSD e ao Linux, ele no vem instalado.
Para Iacilitar a compreenso do Iuncionamento deste tipo de tunel, apresentaremos no quadro
a seguir um resumo dos quatro tipos de NAT existentes:
196
Encapsula o pacote Pv6 em pacotes UDP.
Funciona atravs de NAT tipo Cone e Cone Restrito.
Envia pacotes bubles periodicamente ao Servidor para manter as
configuraes iniciais da conexo UDP.
Seu funcionamento complexo e apresenta overhead.
Teredo
NAT Cone - todas as requisies originadas de um mesmo endereo e porta internos so mapeadas para uma mesma
porta do NAT. Com isso, preciso apenas conhecer o endereo pblico do NAT e a porta associada a um n interno
para que um n externo estabelea uma comunicao, no importando seu endereo ou porta, podendo assim, enviar
arbitrariamente pacotes para o n interno. tambm conhecido como NAT Esttico.
NAT Cone Restrito - todas as requisies originadas de um mesmo endereo e porta internos so mapeadas para
uma mesma porta do NAT. No entanto, o acesso externo permitido apenas em respostas a requisies feitas
previamente, sendo que o endereo do n externo, que est respondendo a requisio, deve ser o mesmo utilizado
como endereo de destino da requisio. tambm conhecido como NAT Dinmico.
NAT Cone Restrito por Porta - Tm as mesmas caractersticas de mapeamento do NAT Cone Restrito, porm, a
restrio para a comunicao considera tambm a porta do n externo. Com isso, um n externo s poder
estabelecer uma comunicao com um n interno se este ltimo houver lhe enviado previamente um pacote atravs
da mesma porta e endereo.
NAT Simtrico - Alm de possuir as mesmas restries do NAT tipo Cone Restrito por Porta, cada requisio realizada
a partir de um endereo e porta internos para um endereo e porta externos mapeada unicamente no NAT. Ou seja,
se o mesmo endereo interno envia uma requisio, com a mesma porta, porm para um endereo de destino
diferente, um mapeamento diferente ser criado no NAT. Este tipo de NAT tambm conhecido como NAT
Masquerade ou NAT Stateful.
197
Baseado nas mensagens RA recebidas dos Servidores, o cliente constroi seu endereo
IPv6, utilizando o seguinte padro:
* Os bits 0 a 31 so o preIixo do Teredo recebido do Servidor atravs das mensagens RA; o
padro 2001:0000;
* Os bits 32 a 63 so o endereo IPv4 primario do Servidor Teredo que enviou a primeira
mensagem RA;
* Os bits 64 a 79 so utilizados para deIinir alguns flags. Normalmente, somente o bit mais
signiIicativo utilizado, sendo que ele marcado como 1 se o Cliente esta atras de NAT do tipo
Cone, caso contrario ele marcado como 0. Apenas o Windows Vista e Windows Server 2008
utilizam todos os 16 bits, que seguem o Iormado "CRAAAAUG AAAAAAAA", onde "C"
continua sendo a flag Cone; o bit R reservado para uso Iuturo; o bit U deIine a flag
Universal/Local (o padro 0); o bit G deIine a flag Individual/Group (o padro 0); e os 12 bits
'A so randomicamente determinados pelo Cliente para introduzir uma proteo adicional ao no
contra ataques de scan;
* Os bits 80 a 95 so a porta UDP de saida do NAT, recebida nas mensagens RA e mascarada
atravs da inverso de todos os seus bits. Este mascaramento necessario porque alguns NATs
procuram portas locais dentro dos pacotes e os substituem pela porta publica ou vice-versa;
* Os bits 96 a 127 so o endereo IPv4 publico do Servidor NAT, mascarado atravs da
inverso de todos os seus bits. Este mascaramento necessario porque alguns NATs procuram
endereos IPs locais dentro dos pacotes e os substituem pelo endereo publico ou vice-versa.
197
Utiliza o prefixo 2001:0000::/32.
Os 32 bits seguintes contm o endereo Pv4 do Servidor Teredo.
Os 16 bits seguintes so utilizados para definir flags que indicam o
tipo de NAT utilizado e introduzem uma proteo adicional ao n
contra ataques de scan.
Os prximos 16 bits indicam a porta UDP de sada do NAT.
Os ltimos 32 bits representam o endereo Pv4 pblico do Servidor
NAT.
Teredo
198
1- Uma mensagem Router Solicitation (RS) enviada ao servidor Teredo 1 (servidor primario)
com o flag de NAT tipo Cone ativado, o servidor Teredo 1 ento responde com uma mensagem de
Router Aavertisement (RA). Como a mensagem RS estava com o Cone flag ativado, o servidor
Teredo 1 envia a mensagem RA utilizando um endereo IPv4 alternativo. Com isso o cliente
conseguira determinar se o NAT que ele esta utilizando do tipo Cone, se ele receber a
mensagem de RA;
2- Se a mensagem RA do passo anterior no Ior recebida, o cliente Teredo envia uma outra
mensagem RS, mas, agora com o Cone flag desativado. O servidor Teredo 1 responde novamente
com uma mensagem RA, mas, como o Cone flag da mensagem RS estava desativado, ele
responde utilizando o mesmo endereo IPv4 em que ele recebeu a mensagem RS. Se agora o
cliente receber a mensagem de RA, ento ele conclui que esta utilizando NAT do tipo restrita;
3- Para ter certeza que o cliente Teredo no esta utilizando um NAT do tipo simtrico, ele envia
mais uma mensagem RS, mas, agora para o servidor secundario Teredo 2, o qual responde com
uma mensagem do tipo RA. Quando o cliente recebe a mensagem RA do servidor Teredo 2, ele
compara o endereo e a porta UDP de origem contidos na mensagem RA recebidas dos dois
servidores, se Iorem diIerentes o cliente conclui que esta utilizando NAT do tipo simtrico, o qual
no compativel com o Teredo.
198
Teredo
199
1- Para iniciar a comunicao, primeiro o cliente Teredo tem que determinar o endereo IPv4 e a
porta UDP do Relay Teredo que estiver mais proximo do host IPv6, para isto, ele envia uma
mensagem ICMPv6 echo request para o host IPv6 via o seu servidor Teredo;
2- O servidor Teredo recebe a mensagem ICMPv6 echo request e a encaminha para o host IPv6
atravs da rede IPv6;
3- O host IPv6 responde ao cliente Teredo com uma mensagem ICMPv6 Echo Reply que
roteada atravs do Relay Teredo mais proximo dele;
4- O Relay Teredo ento encapsula a mensagem ICMPv6 Echo Reply e envia diretamente ao
cliente Teredo. Como o NAT utilizado pelo cliente do tipo Cone, o pacote enviado pelo Relay
Teredo encaminhado para o cliente Teredo;
5- Como o pacote retornado pelo Relay Teredo contm o endereo IPv4 e a porta UDP utilizada
por ele, o cliente Teredo extrai estas inIormaes do pacote. Depois disso um pacote inicial
encapsulado e enviado diretamente pelo cliente Teredo para o endereo IPv4 e porta UDP do
Relay Teredo;
6- O Relay Teredo recebe este pacote, remove o cabealho IPv4 e UDP e o encaminha para o host
IPv6. Depois disso toda a comunicao entre o cliente Teredo e o host IPv6 Ieita via o relay
Teredo atravs deste mesmo mtodo.
199
Comunicao atravs de NAT tipo CONE
Teredo
200
1- Para iniciar a comunicao, primeiro o cliente Teredo tem que determinar o endereo IPv4 e a
porta UDP do Relay Teredo que estiver mais proximo do host IPv6, para isto, ele envia uma
mensagem ICMPv6 echo request para o host IPv6 via o seu servidor Teredo;
2- O servidor Teredo recebe a mensagem ICMPv6 echo request e a encaminha para o host IPv6
atravs da rede IPv6;
3- O host IPv6 responde ao cliente Teredo com uma mensagem ICMPv6 Echo Reply que
roteada atravs do Relay Teredo mais proximo dele;
4- Atravs do pacote recebido, o Relay Teredo descobre que o cliente Teredo esta utilizando um
NAT do tipo restrito, sendo assim, se o Relay Teredo enviar o pacote ICMPv6 diretamente para o
cliente Teredo, ele sera descartado pelo NAT porque no ha mapeamento pr-deIinido para
traIego entre o cliente e o Relay Teredo, com isso, o Relay Teredo envia um pacote 'bubble para
o cliente Teredo atravs do Servidor Teredo utilizando a rede IPv4;
5- O servidor Teredo recebe o pacote 'Bubble do Relay Teredo e o encaminha para o cliente
Teredo, mas coloca no indicador de origem o IPv4 e a porta UDP do Relay Teredo. Como ja havia
um mapeamento de traIego entre o servidor Teredo e o Cliente Teredo, o pacote passa pelo NAT e
entregue ao Cliente Teredo;
6- O Cliente Teredo extrai do pacote 'Bubble recebido o IPv4 e a porta UDP do Relay Teredo
mais proximo do host IPv6, com isso, o Cliente Teredo envia um pacote 'Bubble para o Relay
Teredo, para que seja criado um mapeamento de conexo entre eles no NAT;
7- Baseado no conteudo do pacote 'Bubble recebido, o Relay Teredo consegue determinar que
ele corresponde ao pacote ICMPv6 Echo Reply que esta na Iila para a transmisso e tambm que a
passagem atravs do NAT restrito ja esta aberta, sendo assim, ele encaminha o pacote ICMPv6
Echo Reply para o cliente Teredo;
8- Depois de recebido o pacote ICMPv6, um pacote inicial ento enviado do Cliente Teredo para
o host IPv6 atravs do Relay Teredo mais proximo dele;
9- O relay Teredo remove os cabealhos IPv4 e UDP do pacote e o encaminha atravs da rede
IPv6 para o host IPv6. Apos isto os pacotes subseqentes so enviados atravs do Relay Teredo.
200
Comunicao atravs de NAT restrito
Teredo
201
Mais inIormaes:
RFC 4380 - Tereao. Tunneling IPv6 over UDP through Network Aaaress Translations (NATs)
201
O principal problema de segurana quando se utiliza o Teredo que seu
trfego pode passar desapercebido pelos filtros e firewalls se os mesmos
no estiverem preparados para interpret-lo, sendo assim, os computadores
e a rede interna ficam totalmente expostos ataques vindos da nternet Pv6.
Para resolver este problema, antes de implementar o Teredo, deve se fazer
uma reviso nos filtros e firewalls da rede ou pelo menos dos computadores
que utilizaro esta tcnica. Alm deste problema, ainda temos os seguintes:
O cliente Teredo divulga na rede a porta aberta por ele no NAT e o tipo de
NAT que ele est utilizando, possibilitando assim um ataque atravs dela;
A quantidade de endereos Teredo bem menor que os Pv6 nativos,
facilitando assim a localizao de computadores vulnerveis;
Um ataque por negao de servio fcil de ser aplicado tanto no cliente
quanto no relay;
Devido ao mtodo de escolha do Relay pelo host de destino, pode-se criar
um Relay falso e utiliz-lo para coletar a comunicao deste host com os
seus clientes.
Teredo
202
O GRE (Generic Routing Encapsulation) um tunel estatico entre dois hosts
originalmente desenvolvido pela Cisco com a Iinalidade de encapsular varios tipos diIerentes de
protocolos, como por exemplo IPv6 e IS-IS (veja a lista completa de protocolos suportados em
http://www.iana.org/assignments/ethernet-numbers). Este tipo de encapsulamento suportado na
maioria do sistemas operacionais e roteadores e consiste em um link ponto a ponto. A principal
desvantagem do tunel GRE a conIigurao manual, que de acordo com a quantidade de tuneis,
gerara um grande esIoro na sua manuteno e gerenciamento.
Mais inIormaes:
RFC 2784 - Generic Routing Encapsulation (GRE)
202
GRE (Generic Routing Encapsulation) - tnel esttico hosts-a-host
desenvolvido para encapsular vrios tipos diferentes de protocolos.
Suportado na maioria do sistemas operacionais e roteadores.
Seu funcionamento consiste em pegar os pacotes originas, adicionar
o cabealho GRE, e enviar ao P de destino.
Quando o pacote encapsulado chega na outra ponta do tnel,
remove-se o cabealho GRE, sobrando apenas o pacote original.
GRE
203
O Iuncionamento deste tipo de tunel muito simples, e consiste em pegar os pacotes
originas, adicionar o cabealho GRE, e enviar ao IP de destino (o endereo do destino
especiIicado no cabealho GRE), quando o pacote encapsulado chega na outra ponta do tunel (IP
de destino) removido dele o cabealho GRE, sobrando apenas o pacote original, o qual
encaminhado normalmente ao destinatario. Como estamos mais preocupados com os pacotes
IPv6, no desenho abaixo podemos ver a estrutura de um pacote IPv6 sendo transportado em um
tunel GRE:
Os campos mais importantes do cabealho GRE so os seguintes:
- C (Checksum): Se Ior 1, indica que existe o campo Checksum e que ha inIormaes validas nele
e no OIIset;
- R (Routing): Se Ior 1, indica que existe o campo Roteamento e que ha inIormaes de
roteamento validas nele e no Offset;
- K (Key): Se Ior 1, indica que o campo Chave existe e esta sendo utilizado;
- S (Sequence): Se Ior 1, indica que o campo Numero de seqncia existe e esta sendo utilizado;
- Verso: Geralmente preenchido com 0;
- Protocolo: E preenchido com o codigo do protocolo sendo transportado, de acordo com os tipos
de pacotes ethernet (http://www.iana.org/assignments/ethernet-numbers);
- Offset: Indica a posio onde inicia o campo de roteamento;
- Checksum: Contm o checksum IP (complemento de 1) do cabealho GRE e do pacote sendo
transportado;
- Chave (Key): Contm um numero de 32 bits que inserido pelo encapsulador. Ele utilizado
pelo destinatario para identiIicar o remetente do pacote;
- Numero de seqncia (Sequence number): Contm um numero inteiro de 32 bits que inserido
pelo remetente do pacote. Ele utilizado pelo destinatario para seqenciar os pacotes recebidos;
- Roteamento (Routing): Contm uma lista de entradas de roteamento, mas, geralmente no
utilizado.
203
GRE
204
As tcnicas de traduo possibilitam um roteamento transparente na comunicao entre
nos que apresentem suporte apenas a uma verso do protocolo IP, ou utilizem pilha dupla. Estes
mecanismos podem atuar de diversas Iormas e em camadas distintas, traduzindo cabealhos IPv4
em cabealhos IPv6 e vice-versa, realizando converses de endereos, de APIs de programao,
ou atuando na troca de traIego TCP ou UDP.
Mais inIormaes:
RFC 4966 - Reasons to Move the Network Aaaress Translator - Protocol Translator (NAT-PT)
to Historic Status
204
Possibilitam um roteamento transparente na comunicao entre ns
de uma rede Pv6 com ns em uma rede Pv4 e vice-versa.
Podem atuar de diversas formas e em camadas distintas:
Traduzindo cabealhos Pv4 em cabealhos Pv6 e vice-versa;
Realizando converses de endereos;
Converses de APs de programao;
Atuando na troca de trfego TCP ou UDP.
Tcnicas de Traduo
205
SIIT (Stateless IP/ICMP Translation Algorithm) - deIinido na RFC 2765, o SIIT um
mecanismo de traduo stateless de cabealhos IP/ICMP, permitindo a comunicao entre nos
com suporte apenas ao IPv6 com nos que apresentam suporte apenas ao IPv4. Ele utiliza um
tradutor localizado na camada de rede da pilha, que converte campos especiIicos dos cabealhos
de pacotes IPv6 em cabealhos de pacotes IPv4 e vice-versa. Para realizar este processo, o
tradutor necessita de um endereo IPv4-mapeado em IPv6, no Iormato 0::FFFF:a.b.c.d, que
identiIica o destino IPv4, e um endereo IPv4-traduzido, no Iormato 0::FFFF:0:a.b.c.d, para
identiIicar o no IPv6. Quando o pacote chega ao SIIT, o cabealho traduzido, convertendo o
endereo para IPv4 e encaminhado ao no de destino;
Mais inIormaes:
RFC 2765 - Stateless IP/ICMP Translation Algorithm (SIIT)
205
ST (Stateless IP/ICMP Translation) - permite a comunicao entre ns
com suporte apenas ao Pv6 com ns que apresentam suporte apenas ao
Pv4.
Utiliza um tradutor localizado na camada de rede da pilha, que converte
campos especficos dos cabealhos de pacotes Pv6 em cabealhos de
pacotes Pv4 e vice-versa.
Cabealhos TCP e UDP geralmente no so traduzidos.
Utiliza um endereo Pv4-mapeado em Pv6, no formato 0::FFFF:a.b.c.d,
que identifica o destino Pv4, e um endereo Pv4-traduzido, no formato
0::FFFF:0:a.b.c.d, para identificar o n Pv6.
Utiliza faixas de endereos Pv4 para identificar ns Pv6.
Traduz mensagens CMPv4 em CMPv6 e vice-versa.
SIIT
206
BIS (Bump in the Stack) - esse mtodo possibilita a comunicao de aplicaes IPv4 com
nos IPv6. DeIinida na RFC 2767, o BIS Iunciona entre a camada de aplicao e a de rede,
adicionando a pilha IPv4 trs modulos: translator, que traduz os cabealhos IPv4 enviados em
cabealhos IPv6 e os cabealhos IPv6 recebidos em cabealhos IPv4; extension name resolver,
que atua nas DNS queries realizadas pelo IPv4, de modo que, se o servidor DNS retorna um
registro AAAA, o resolver pede ao aaaress mapper para atribuir um endereo IPv4
correspondente ao endereo IPv6; e aaaress mapper, que possui uma certa quantidade de
endereos IPv4 para associar a endereos IPv6 quando o translator receber um pacote IPv6. Como
os endereos IPv4 no so transmitidos na rede, eles podem ser endereos endereos privados.
Esse mtodo permite apenas a comunicao de aplicaes IPv4 com hosts IPv6, e no o contrario,
alm de no Iuncionar em comunicaes multicast.
Como os endereos IPv4 no so transmitidos na rede, eles podem ser endereos privados.
Esse mtodo permite apenas a comunicao de aplicaes IPv4 com hosts IPv6, e no o contrario,
alm de no Iuncionar em comunicaes multicast.
Mais inIormaes:
RFC 2767 - Dual Stack Hosts using the "Bump-In-the-Stack" Technique (BIS)
206
BS (Bump-in-the-Stack) - funciona entre a
camada de aplicao e a de rede.
Utilizada para suportar aplicaes Pv4
em redes Pv6.
Adiciona a pilha Pv4 trs mdulos:
Translator - traduz cabealhos Pv4
em cabealhos Pv6 e vice-versa;
Address mapper - possui uma faixa de
endereos Pv4 que so associados a
endereos Pv6 quando o translator
receber um pacote Pv6;
Extension name resolver - atua nas
consultas DNS realizadas pela
aplicao Pv4.
No funciona em comunicaes
multicast.
BIS
207
BIA (Bump in the API) - similar ao BIS, esse mecanismo adiciona uma API de traduo
entre o socket API e os modulos TPC/IP dos hosts de pilha dupla, permitindo a comunicao de
aplicaes IPv4 com hosts IPv6, traduzindo as Iunes do socket IPv4 em Iunes do socket IPv6
e vice-versa. ConIorme descrito na RFC 3338, trs modulos so adicionados, extension name
resolver e aaaress mapper, que Iuncionam da mesma Iorma que no BIS, e o function mapper, que
detecta as chamadas das Iunes do socket IPv4 e invoca as Iunes correspondentes do socket
IPv6 e vice-versa. O BIA apresenta duas vantagens em relao ao BIS: no depender do ariver da
interIace de rede e no introduzir overheaa na traduo dos cabealhos dos pacotes. No entanto,
ele tambm no suporta comunicaes multicast.
Mais inIormaes:
RFC 3338 - Dual Stack Hosts Using "Bump-in-the-API (BIA)
207
BA (Bump in the API) - similar ao BS,
traduz funes da AP Pv4 em funes da
AP Pv6 e vice-versa.
Trs mdulos so adicionados, extension
name resolver e address mapper, que
funcionam da mesma forma que no BS, e
o function mapper, que detecta as
chamadas das funes do socket Pv4 e
invoca as funes correspondentes do
socket Pv6 e vice-versa.
Tambm utiliza faixas de endereos Pv4.
No suporta comunicaes multicast;
BIA
208
TRT (Transport Relay Translator) - atuando como um tradutor de camada de transporte,
esse mecanismo possibilita a comunicao entre hosts apenas IPv6 e hosts apenas IPv4 atravs de
traIego TCP/UDP. Sem a necessidade de se instalar qualquer tipo de software, o TRT roda em
maquinas com pilha dupla que devem ser inseridas em um ponto intermediario dentro da rede. Na
comunicao de um host IPv6 com um host IPv4, conIorme deIinio na RFC 3142, adicionado
um preIixo IPv6 Ialso ao endereo IPv4 do destino. Quando um pacote com esse preIixo Ialso
passa pelo TRT, esse pacote interceptado e enviado ao host IPv4 de destino em um pacote TCP
ou UDP. Na traduo TCP e UDP o checksum deve ser recalculado e apenas no caso das conexes
TCP, o estado do socket sobre o qual o host esta conectado deve ser mantido, removendo-o
quando a comunicao Ior Iinalizada. Para que o mecanismo Iuncione de Iorma bidirecional,
necessario a adio de um bloco de endereos IPv4 publicos e o uso de um servidor DNS-ALG
para mapear os endereos IPv4 para IPv6.
Mais inIormaes:
RFC 3142 - An IPv6-to-IPv4 Transport Relay Translator
208
TRT (Transport Relay Translator) - atua como tradutor de camada
de transporte, possibilitando a comunicao entre hosts Pv6 e
Pv4 atravs de trfego TCP/UDP.
Atua em mquinas com pilha dupla que devem ser inseridas em
um ponto intermedirio dentro da rede.
Na comunicao de um host Pv6 com um host Pv4, adiciona um
prefixo Pv6 falso ao endereo Pv4 do destino.
Quando um pacote com esse prefixo falso passa pelo TRT, o
pacote interceptado e enviado ao host Pv4 de destino em um
pacote TCP ou UDP.
Para funcionar de forma bidirecional, deve-se adicionar um bloco
de endereos Pv4 pblicos e o usar de um servidor DNS-ALG
para mapear os endereos Pv4 para Pv6.
TRT
209
209
ALG (Application Layer Gateway) - trabalha como um proxy HTTP.
O cliente inicia a conexo com o ALG, que estabelece uma
conexo com o servidor, retransmitindo as requisies de sada e
os dados de entrada.
Em redes apenas Pv6, o ALG habilita a comunicao dos hosts
com servios em redes apenas Pv4, configurando o ALG em ns
com pilha dupla.
normalmente utilizado quando o host que deseja acessar a
aplicao no servidor Pv4, est atrs de NAT ou de um firewall.
DNS-ALG traduz consultas DNS do tipo AAAA vindo de um host
Pv6, para uma consulta do tipo A, caso o servidor de nomes a ser
consultado se encontre no ambiente Pv4, e vice-versa.
ALG e DNS-ALG
210
210
ALG e DNS-ALG
Fonte: TOTD
211
211
Com a utilizao de Pilha Dupla as aplicaes ficam expostas aos
ataques a ambos os protocolos, Pv6 e Pv4, o que pode ser
resolvido configurando firewalls especficos para cada protocolo.
As tcnicas de Tneis e Traduo so as que causam maiores
impacto do ponto de vista de segurana.
Mecanismos de tunelamento so suscetveis a ataques de DoS,
falsificao de pacotes e de endereos de roteadores e relays
utilizados por essas tcnicas, como 6to4 e TEREDO.
As tcnicas de traduo implicam em problemas relacionados a
incompatibilidade dessas tcnicas com alguns mecanismos de
segurana existentes. Similar ao que ocorre com o NAT no Pv4.
Segurana
212
212
Como se proteger:
Utilizar pilha dupla na migrao, protegendo as duas pilhas
com firewall;
Dar preferncia aos tneis estticos, no lugar dos automticos;
Permitir a entrada de trfego apenas de tneis autorizados.
Segurana
213
214
Neste modulo apresentaremos algumas caracteristicas basicas sobre o Iuncionamento dos
mecanismos de roteamento, tanto interno (IGP) quanto externo (EGP), sempre destacando as
principais mudanas em relao ao IPv6. Sero abordados os protocolos de roteamento RIP,
OSPF, IS-IS e BGP.
Roteamento
IPv6
MduIo 8
O IPv4 e o IPv6 so protocolos da Camada de Rede, de modo que esta a unica camada
diretamente aIetada com a implantao do IPv6, sem a necessidade de alteraes no
Iuncionamento das demais.
Porm, preciso compreender que so duas Camadas de Rede distintas e independentes.
Isto implica em algumas consideraes importantes:
Como atuar no planejamento e estruturao das redes:
Migrar toda a estrutura para Pilha Dupla; migrar apenas areas criticas; manter duas
estruturas distintas, uma IPv4 e outra IPv6; etc.
Em redes com Pilha Dupla algumas conIiguraes devem ser duplicadas como DNS,
firewall e protocolos de roteamento.
No suporte e resoluo de problemas sera preciso detectar se ha Ialhas na conexo da rede
IPv4 ou da rede IPv6;
Novos equipamentos e aplicaes precisam ter suporte as Iuncionalidades dos dois
protocolos.
Consideraes Importantes
Pv4 e Pv6 Camada de Rede
Duas redes distintas
Planejamento
Suporte
Troubleshooting
Arquitetura dos equipamentos
...
Consideraes Importantes
Caractersticas Fundamentais do Endereo P
dentificao
Unvoca
Comandos: host, nslookup, dig...
Localizao
Roteamento e encaminhamento entre a origem e o destino
Comandos: mtr -4/-6, traceroute(6), tracert(6)...
Semntica Sobrecarregada
Dificulta a mobilidade
Desagregao de rotas
A Camada de Rede esta associada principalmente a duas caracteristicas:
Identificao deve garantir que cada dispositivo da rede seja identiIicado de
Iorma univoca, sem chance de erro. Isto , o endereo IP deve ser unico no
mundo. Utilizando o comando host, em plataIormas UNIX, ou nslookup, em
plataIormas Windows, pode-se ver a identiIicao de um servio, por exemplo.
Em redes com Pilha Dupla, um no sera identiIicado pelos dois endereos.
Localizao - indica como chegar ao destino, tomando as decises de
encaminhamento dos pacotes baseando-se no endereamento, ocorrendo da
mesma Iorma tanto em IPv4 quanto em IPv6. Podemos veriIicar esta
Iuncionalidade utilizando comandos como mtr -4 e -6, ou traceroute
(traceroute6), ou tracert (tracert6). Estes comandos mostram a identiIicao e a
localizao de um no.
A unio dessas duas caracteristicas na Camada de Rede torna a semntica do
endereo IP sobrecarregada. Isto implica em questes como a desagregao de rotas, agravando o
problema do crescimento da tabela de roteamento global. Uma Iorma de impedir isso separar as
Iunes de localizao e identiIicao.
217
Consideraes Importantes
Separar as funes de localizao e identificao.
LSP (Locator/Identifier Separation Protocol).
Permite uma implementao de forma gradual.
no exige nenhuma alteraes nas pilhas dos host e nem
grandes mudanas na infraestrutura existente.
ED (Endpoint Identifiers).
RLOC (Routing Locators).
TR (Ingress Tunnel Router) / ETR (Egress Tunnel Router).
Fazem o mapeamento entre ED e RLOC.
Utiliza tanto Pv4 quanto Pv6.
Existe um grupo de trabalho no IETF que discute uma Iorma de separar essas duas Iunes
(identiIicao e localizao). O LISP (Locator/Iaentifier Separation Protocol) um protocolo
simples que busca separar os endereos IP em Enapoint Iaentifiers (EIDs) e Routing Locators
(RLOCs). Ele no exige nenhuma alterao nas pilhas dos host e nem grandes mudanas na
inIraestrutura existente, podendo ser implementado em um numero relativamente pequeno de
roteadores.
Seus principais elementos so:
Enapoint ID (EID): um identiIicador de 32 bits (para IPv4) ou 128 bits (para IPv6)
usado nos campos de endereo de origem e destino do primeiro cabealho LISP (mais
interno) de um pacote. O host obtm um EID de destino da mesma Iorma que obtm
um endereo de destino hoje, por exemplo atravs de uma pesquisa de DNS. O EID
de origem tambm obtido atravs dos mecanismos ja existentes, usados para deIinir
o endereo local de um host,
Routing Locator (RLOC): endereo IPv4 ou IPv6 de um ETR (Egress Tunnel
Router). RLOCs so numerados a partir de um bloco topologicamente agregado, e
so atribuidos a uma rede em cada ponto em que haja conexo com a Internet global;
Ingress Tunnel Router (ITR): roteador de entrada do tunel que recebe um pacote IP
(mais precisamente, um pacote IP que no contm um cabealho LISP), trata o
endereo de destino desse pacote como um EID e executa um mapeamento entre o
EID e o RLOC. O ITR, em seguida, anexa um cabealho 'IP externo contendo um
de seus RLOCs globalmente roteaveis, no campo de endereo de origem, e um
RLOC, resultado do mapeamento, no campo de endereo de destino;
Egress Tunnel Router (ETR): roteador de saida do tunel que recebe um pacote IP
onde o endereo de destino do cabealho 'IP externo um de seus RLOCs. O
roteador retira o cabealho externo e encaminha o pacote com base no proximo
cabealho IP encontrado.
Mais inIormaes
Locator/ID Separation Protocol (LISP) - http://www.ietI.org/id/draIt-ietI-lisp-06.txt
LISP Networking. Topology, Tools, ana Documents - http://www.lisp4.net (apenas conexes IPv4)
LISP Networking. Topology, Tools, ana Documents - http://www.lisp6.net (apenas conexes IPv6)
218
Consideraes Importantes
Prefixo P
O recurso alocado pelo Registro.br ao AS um bloco P.
O bloco P no rotevel.
bloco um grupo de Ps.
O prefixo P rotevel.
nmero de bits que identifica a rede;
voc pode criar um prefixo /32 igual ao bloco /32 Pv6 recebido
do Registro.br;
pode criar um prefixo /33, /34,... /48.
Esta nomenclatura importante.
ativao de sesses de transito com outras operadoras;
troubleshooting.
Um deIinio importante a de preIixo IP.
O recurso alocado pelo Registro.br aos ASs um bloco IP, que representa um grupo de
endereos IP. O bloco no um elemento roteavel, o que roteavel o preIixo. O que possivel,
por exemplo, criar um preIixo IPv6 /32 igual ao bloco /32 recebido do Registro.br e anunciar
esse preIixo na tabela de rotas. Porm tambm possivel criar preIixos /33, /34, /48 etc a partir do
bloco recebido.
O preIixo representa o numero de bits de um endereo que identiIica a rede.
Apesar de ser apenas mais uma nomenclatura, essa deIinio importante na hora de
enviar inIormaes para ativar sesses de trnsito com outras operadoras e na deteco de
problemas de conectividade.
Tambm importante compreender o Iuncionamento basico de um roteador, de que Iorma
ele processa os pacotes recebidos e eIetua as decises de encaminhamento. Analise o seguinte
exemplo:
O roteador recebe um quadro Ethernet atravs de sua interIace de rede;
VeriIica a inIormao do Ethertype, que indica que o protocolo da camada superior
transportado IPv6;
O cabealho IPv6 processado e o endereo de destino analisado;
O roteador procura na tabela de roteamento unicast (RIB - Router Information Base)
se ha alguma entrada para a rede de destino;
Visualizando a RIB IPv6:
Cisco/Quagga show ipv6 route
Juniper show route table inet6
Visualizando a RIB IPv4:
Cisco/Quagga show ip route
Juniper show route
219
Como o roteador trabaIha?
Ex.:
1.O roteador recebe um quadro Ethernet;
2.Verifica a informao do Ethertype que indica que o protocolo da
camada superior transportado Pv6;
3.O cabealho Pv6 processado e o endereo de destino
analisado;
4.O roteador procura na tabela de roteamento unicast (RB - Router
Information Base) se h alguma entrada para a rede de destino;
Visualizando a RB:
show ip(v6) route Cisco/Quagga
show route (table inet6) Juniper
Longest Match - procura a entrada mais especiIica. Ex.:
O IP de destino 2001:0DB8:0010:0010::0010
O roteador possui as seguintes inIormaes em sua tabela de rotas:
2001:DB8::/32 via interIace A
2001:DB8::/40 via interIace B
2001:DB8:10::/48 via interIace C
Os trs preIixos englobam o endereo de destino, porm o roteador sempre ira preIerir
o mais especiIico, neste caso, o /48;
Uma vez identiIicado o preIixo mais especiIico, o roteador decrementa o TTL, monta
o quadro Ethernet de acordo a interIace, e envia o pacote.
220
5. Longest Match - procura a entrada mais especfica. Ex.:
O P de destino 2001:0DB8:0010:0010::0010
O roteador possui as seguintes informaes em sua tabela de rotas:
2001:DB8::/32 via interface A
2001:DB8::/40 via interface B
2001:DB8:10::/48 via interface C
Os trs prefixos englobam o endereo de destino, porm o roteador
sempre ir preferir o mais especfico, neste caso, o /48;
Qual a entrada mais especfica Pv4 e Pv6?
6. Uma vez identificado o prefixo mais especfico, o roteador decrementa
o TTL, monta o quadro Ethernet de acordo a interface, e envia o
pacote.
Como o roteador trabaIha?
Se o roteador localizar mais de uma caminho para o mesmo destino e com o mesmo valor
de longest match, ele utilizara uma tabela predeIinida de preIerncias (conceito de Distancia
Aaministrativa da Cisco).
Os valores desta tabela so numeros inteiros entre 0 e 255 associados a cada rota, sendo
que quanto menor o valor mais conIiavel a rota. Os valores so atribuidos avaliando se a rota
esta diretamente conectada, se Ioi aprendida atravs do protocolo de roteamento externo ou
interno, etc. Estes valores tm signiIicado apenas local, no podendo ser anunciados pelos
protocolos de roteamento, e caso seja necessario, podem ser alterados para priorizar um
determinado protocolo.
Caso tambm seja encontrado um mesmo valor na tabela de preIerncias, ha equipamentos
e implementaes que, por padro, realizam balanceamento de traIego.
Como o roteador trabaIha?
E se houver mais de um caminho para o mesmo prefixo?
Utiliza-se uma tabela predefinida de preferncias.
nmero inteiro entre 0 e 255 associado a cada rota, sendo que,
quanto menor o valor mais confivel a rota;
avalia se est diretamente conectado, se a rota foi aprendida
atravs do protocolo de roteamento externo ou interno;
tem significado local, no pode ser anunciado pelos protocolos
de roteamento;
seu valor pode ser alterado caso seja necessrio priorizar um
determinado protocolo.
E se o valor na tabela de preferncias tambm for o mesmo?
O processo de escolha das rotas idntico em IPv4 e IPv6, porm, as tabelas de rotas so
independentes. Por exemplo: ha uma RIB IPv4 e outra IPv6.
Para otimizar o envio dos pacotes, existem mecanismos que adicionam apenas as melhores
rotas a uma outra tabela, a tabela de encaminhamento (FIB - Forwaraing Information Base). Um
exemplo deste mecanismo o CEF (Cisco Express Forwaraing) da Cisco.
A FIB criada a partir da RIB, e assim como a RIB, ela tambm duplicada se a rede
estiver conIigurada com Pilha Dupla. Com isso, ha mais inIormaes para serem armazenadas e
processadas.
Em roteadores que possuem arquitetura distribuida, o processo de seleo das rotas e o
encaminhamento dos pacotes so Iunes distintas.
Ex.:
Roteadores 7600 da Cisco, a RIB reside no modulo central de roteamento e a
FIB nas placas das interIaces.
Roteadores Juniper da srie M, a Router Enginie a responsavel pela RIB, e a
FIB tambm reside nas placas das interIaces (Packet Forwaraing Engine -
PFE).
TabeIa de Roteamento
O processo de escolha das rotas idntico em Pv4 e Pv6, porm, as
tabelas de rotas so independentes.
H uma RB Pv4 e outra Pv6.
Atravs de mecanismos de otimizao as melhores rotas so
adicionadas tabela de encaminhamento
FB - Forwarding Information Base;
A FB criada a partir da RB;
Assim como a RB, a FB tambm duplicada.
Em roteadores que possuem arquitetura distribuda o processo de
seleo das rotas e o encaminhamento dos pacotes so funes
distintas.
223
TabeIa de Roteamento
So as informaes recebidas pelos protocolos de roteamento que
alimentam a RB que por sua vez alimenta a FB.
RIB v4
EGP
RIB v6
FIB v4 FIB v6
IGP Estticas
Os Protocolos de Roteamento se
dividem em dois grupos:
Interno (IGP) - protocolos que
distribuem as informaes dos
roteadores dentro de Sistemas
Autnomos. Ex.: OSPF; S-S;
RP.
Externo (EGP) - protocolos que
distribuem as informaes entre
Sistemas Autnomos. Ex.: BGP-4.
E o mecanismo de roteamento que possibilita o encaminhamento de pacotes de dados entre
quaisquer dois dispositivos conectados a Internet.
Para atualizar as inIormaes utilizadas pelos roteadores para encontrar o melhor caminho
disponivel no encaminhamento dos pacotes at o seu destino, utilizam-se os protocolos de
roteamento. So as inIormaes recebidas pelos protocolos de roteamento que 'alimentam a
RIB, que por sua vez 'alimenta a FIB.
Estes protocolos se dividem em dois grupos:
- Interno (IGP) - protocolos que distribuem as inIormaes dos roteadores dentro
de Sistemas Autnomos. Como exemplo desses protocolos podemos citar: OSPF; IS-IS; e RIP.
- Externo (EGP) - protocolos que distribuem as inIormaes entre Sistemas
Autnomos. Como exemplo podemos citar o BGP-4.
Caso o roteador receba um pacote cujo o endereo de destino no esteja explicitamente
listado na tabela de rotas, ele utilizara sua rota aefault.
Servidores e estaes de trabalho, naturalmente precisam de uma rota aefault. Eles no so
equipamentos de rede, eles so conhecem as redes diretamente conectadas em suas interIaces. Se
eles quiserem alcanar algum que no esteja diretamente conectado, eles tero que usar rota
aefault para um outro equipamento que conhea.
Ai surge a questo: todo mundo precisa ter rota aefault?
224
Rota DefauIt
Quando um roteador no encontra uma entrada na tabela de rotas
para um determinado endereo, ele utiliza uma rota default.
Servidores, estaes de trabalho, firewalls, etc., s conhecem as
redes diretamente conectadas em uma interface.
Para alcanar algum que no esteja diretamente conectado, eles
tero que usar rota default para um outro que conhea.
Todo mundo precisa ter rota default?
Existe um conceito entre as operadoras que delimita uma regio da Internet livre de rota
aefault, a DFZ (Default Free Zone).
Um AS que possua tabela completa no precisa ter rota aefault, pois a tabela completa,
mostra todas as entradas de rede do mundo.
Esse modelo bom e Iuncional, porm, isso pode acarretar alguns problemas. Os
roteadores tm que processar inIormaes do mundo inteiro em tempo real; e ha tambm
problemas de escalabilidade Iutura.
225
Rota DefauIt
DFZ (Default Free Zone) - conceito existente entre as operadoras.
uma regio da nternet livre de rota default.
Roteadores DFZ no possuem rota default, possuem tabela BGP
completa.
ASs que possuem tabela completa precisam ter rota default?
A tabela completa, mostra todas as entradas de rede do mundo.
roteadores tm que processar informaes do mundo inteiro em
tempo real;
problemas de escalabilidade futura.
A utilizao de rota aefault por roteadores que possuam tabela completa pode ocasionar
alguns problemas.
Imagine a seguinte situao como exemplo: uma rede Ioi comprometida pela inIeco de
um malware. A maquina contaminada ira 'varrer a Internet tentando contaminar outras
maquinas, inclusive IPs que no esto alocados, e no esto na tabela completa. Se houver rota
aefault, o seu roteador vai encaminhar esse traIego no valido para Irente. Essa uma das razes
de se utilizar DFZ. Uma sugesto para solucionar esse problema criar uma rota aefault e apontar
para Null0 ou DevNull. Alm disso, deve-se desabilitar o envio das mensagens 'ICMP
unreachable', porque quando um roteador descarta um pacote, ele envia uma mensagem 'ICMP
unreachable' avisando, porm, se o destino no valido, no ha necessidade de avisar a origem,
isso apenas consome CPU desnecessariamente.
A rota aefault em IPv4 0.0.0.0/0 e em IPv6 ::/0.
226
Rota DefauIt
Se houver tabela completa e rota default, neste caso, a rota default vai
ser usada?
Ex.:
magine uma rede comprometida pela infeco de um malware;
A mquina contaminada ir varrer a nternet tentando contaminar
outras mquinas, inclusive Ps que no esto alocados, e no
esto na tabela completa;
Se houver rota default, o seu roteador vai encaminhar esse trfego
no vlido para frente;
Essa uma das razes de se utilizar DFZ;
Sugesto: criar uma rota default e apontar para Null0 ou DevNull,
e desabilitar o envio das mensagens 'ICMP unreachable'.
A rota default em Pv4 0.0.0.0/0 e em Pv6 ::/0.
Os roteadores tomam decises de acordo com as inIormaes que eles conhecem. Essas
inIormaes so recebidas e passadas aos outros roteadores atravs dos protocolos de roteamento
interno e externo.
Ao enviar suas inIormaes, os roteadores so anunciam a melhor rota que eles conhecem
para um determinado destino. So essas inIormaes que sero utilizadas para inIluenciar o
traIego de entrada e o de saida do AS.
227
Deciso de Roteamento
Os roteadores tomam decises de acordo com as informaes que
eles conhecem.
Essas informaes so recebidas e passadas aos outros roteadores
atravs dos protocolos de roteamento interno e externo.
Os roteadores s anunciam a melhor rota que eles conhecem
para um determinado destino.
Essas informaes sero utilizadas para influenciar o trfego de
entrada e o de sada do AS.
Os preIixos anunciados interIerem na Iorma como os outros conhecem o AS, isso ,
interIerem no traIego de entrada. Do mesmo modo, os preIixos recebidos interIerem no traIego de
saida.
228
InfIuenciando o Trfego
Os prefixos que um AS anuncia, interferem no trfego de entrada ou
sada?
Os prefixos anunciados interferem na forma como os outros
conhecem o AS.
trfego de entrada.
Os prefixos recebidos de outras redes interferem no trfego de
sada.
O que mais Iacil em um AS, inIluenciar o traIego de entrada ou de saida?
Analise as inIormaes do exemplo a seguir:
Um AS possui um bloco IPv4 /20;
Este AS pode gerar para a Internet anuncios de preIixos at um /24, o preIixo IPv4
mais especiIico normalmente aceito pelas operadoras;
Com um /20 pode-se gerar 16 preIixos /24;
Se considerarmos a hipotese de se anunciar todos os preIixos possiveis entre o /20
at o /24, pode-se gerar um total de 31 preIixos;
E com um bloco de endereos IPv6, quantos preIixos podem ser gerados entre
um /32 e um /48?
229
InfIuenciando o Trfego
O que mais fcil, influenciar o trfego de entrada ou de sada?
Ex.:
Um AS possui um bloco Pv4 /20;
Este AS pode gerar para a nternet anncios de prefixos at um
/24, o prefixo Pv4 mais especfico normalmente aceito pelas
operadoras;
Quantos prefixos /24 podem ser gerados a partir de um /20?
E quantos prefixos podem ser gerados entre /20 e um /24?
E entre um /32 e um /48 Pv6?
230
InfIuenciando o Trfego
A nternet sabe chegar at um AS por at 31 prefixos Pv4.
E quantas entradas Pv4 um AS conhece da nternet?
Portanto h muito mais poder para trabalhar com o trfego de sada.
Maior quantidade de informaes;
Nos prefixos que so baseadas as decises de roteamento.
Balanceamento de trfego;
Contabilidade de trfego;
....
A influncia do trfego de entrada e de sada est associada poltica
de roteamento a ser implementada.
H duas frentes: a de entrada e a de sada, chamadas de AS-N e
AS-OUT.
Da mesma forma para Pv4 e Pv6.
Deste modo, a Internet sabe chegar at o AS por at 31 preIixos IPv4 e o AS tem a opo
de sair por aproximadamente 300.000 preIixos, que o tamanho da Tabela de Roteamento Global
IPv4 atualmente.
Portanto, se pensarmos na ideia de que 'inIormao poder, podemos aIirmar que mais
Iacil inIluenciar o traIego de saida, visto que ha uma maior quantidade de preIixos para se
trabalhar, e que so nos preIixos que so baseadas as decises de roteamento, atuando sobre o
balanceamento, contabilidade de traIego etc.
A inIluncia dos traIegos de entrada e de saida esta associada a politica de roteamento a ser
implementada, sendo que ha duas Irentes: a de entrada e a de saida, chamadas de AS-IN e AS-
OUT. Isto ocorre da mesma Iorma para IPv4 e IPv6.
Hoje ha duas principais opes para se trabalhar com roteamento interno, o OSPF e o IS-
IS. Esses dois protocolos so do tipo Link-State, isto consideram as inIormaes de estado do
enlace, e mandam atualizaes de Iorma otimizada, apenas quando ha mudana de estado. Eles
tambm permitem que se trabalhe com estrutura hierarquica, separando a rede por regies. Isso
um ponto Iundamental para IPv6.
Uma outra opo o protocolo RIP (Routing Information Protocol). E um protocolo do
tipo Vetor de Distncia (Bellman-Ford), de Iacil implementao e de Iuncionamento simples,
porm apresenta algumas limitaes como o Iato de enviar sua tabela de estados periodicamente,
independente de mudanas ou no na rede.
E importante que o protocolo de roteamento interno seja habilitado apenas nas interIaces
onde so necessarias. Embora parea obvio, ha quem conIigure de Iorma errada Iazendo com que
os roteadores Iiquem tentando estabelecer vizinhana com outros ASs.
231
ProtocoIos de Roteamento
Interno
H duas principais opes para se trabalhar com roteamento interno:
OSPF
S-S
protocolos do tipo Link-State;
consideram as informaes de estado e mandam atualizaes
de forma otimizada;
trabalham com estrutura hierrquica.
Terceira opo
RP
O protocolo de roteamento interno deve ser habilitado apenas nas
interfaces necessrias.
232
Para tratar o roteamento interno IPv6 Ioi deIinida uma nova verso do protocolo RIP, o
Routing Information Protocol next generation (RIPng). Esta verso Ioi baseada no RIPv2
utilizado em redes IPv4, porm, ela especiIica para redes IPv6.
Como mudanas principais destaca-se:
Suporte ao novo Iormato de endereo;
Utiliza o endereo multcast FF02::9 (All RIP Routers) como destino;
O endereo do proximo salto deve ser um endereo link local.
Em um ambiente com Pilha Dupla (IPv4IPv6) necessario usar uma instncia do RIP
para IPv4 e uma do RIPng para o roteamento IPv6.
Apesar de ser um protocolo novo, o RIPng ainda apresenta as mesma limitaes das
verses anteriores utilizadas com IPv4, como:
Dimetro maximo da rede de 15 saltos;
Utiliza apenas a distncia para determinar o melhor caminho;
Loops de roteamento e contagem at o inIinito.
Mais inIormaes:
RFC 2080 - RIPng for IPv6
RIPng
Routing Information Protocol next generation (RPng) - protocolo GP
simples e de fcil implantao e configurao.
Protocolo do tipo Vetor de Distncia (Bellman-Ford).
Baseado no RPv2 (Pv4).
Protocolo especfico para Pv6.
Suporte ao novo formato de endereo;
Utiliza o endereo multcast FF02::9 (All RIP Routers) como
destino;
O endereo do prximo salto deve ser um endereo link local;
Em um ambiente Pv4+Pv6 necessrio usar RP (Pv4) e RPng
(Pv6).
233
As inIormaes presentes na tabela de rotas so:
PreIixo do destino
Mtrica
Proximo salto
IdentiIicao da rota (route tag)
Mudana de rota
Tempo at a rota expirar (padro 180 segundos)
Tempo at a 'coleta de lixo (garbage collection) (padro 120 segundos)
A atualizao da tabelas de rotas pode ocorrer de trs Iormas: atravs do envio automatico
dos dados a cada 30 segundos; quando detectada alguma mudanas na topologia da rede,
enviando apenas a linha aIetada pela mudana; e quando recebida uma mensagem do tipo
Request.
RIPng
Limitaes:
Dimetro mximo da rede de 15 saltos;
Utiliza apenas a distncia para determinar o melhor caminho;
Loops de roteamento e contagem at o infinito.
Atualizao da tabelas de rotas:
Envio automtico a cada 30 segundos - independente de mudanas
ou no.
Quando detecta mudanas na topologia da rede - envia apenas a
linha afetada pela mudana)
Quando recebem uma mensagem do tipo Request
234
O cabealho das mensagens do RIPng bem simples, composto pelos seguintes campos:
Comando (commana) indica se a mensagem do tipo Requet ou Response;
Verso (version) indica a verso do protocolo que atualmente 1.
Esses campos so seguidos das entradas da tabela de rotas (Route Table Entry RTE):
PreIixo IPv6 (128 bits);
IdentiIicao da rota (16 bits);
Tamanho do preIixo (8 bits);
Mtrica (8 bits).
DiIerente do RIPv2, o endereo do proximo salto aparece apenas uma vez, seguido de
todas as entradas que devem utiliza-lo.
RIPng
Mensagens Request e Response
RTE
Prefixo Pv6 (128 bits)
dentificao da rota (16 bits)
Tamanho do prefixo (8 bits)
Mtrica (8 bits)
Diferente do RPv2, o endereo do prximo salto aparece apenas
uma vez, seguido de todas as entradas que devem utiliz-lo.
Comando Verso Reservado
Entrada 1 da tabela de rotas (RTE)
Entrada n da tabela de rotas
....
8 bits 8 bits 16 bits
233
O OSPF um protocolo do tipo link-state onde, atravs do processo de flooaing
(inundao), os roteadores enviam Link State Aavertisements (LSA) descrevendo seu estado atual
ao longo do AS. O flooaing consiste no envio de um LSA por todas as interIaces de saida do
roteador, de modo que todos os roteadores que receberem um LSA tambm o enviam por todas as
suas interIaces. Com isso, o conjunto dos LSAs de todos os roteadores Iorma um banco de dados
de estado do enlace, onde cada roteador participante do AS possui um banco de dados idntico.
Com as inIormaes desse banco, o roteador, atravs do protocolo OSPF, constroi um mapa da
rede que sera utilizado para determinar uma arvore de caminhos mais curtos dentro de toda a sub-
rede, tendo o proprio no como raiz. Ele utiliza o algoritimo de Dijkstra para a escolha do melhor
caminho e permite agrupar os roteadores em areas.
O OSPF pode ser conIigurado para trabalhar de Iorma hierarquica, dividindo os roteadores
de um AS em diversas areas. A cada uma dessas areas atribuido um identiIicador unico (Area-
ID) de 32 bits e todos os roteadores de uma mesma area mantm um banco de dados de estado
separado, de modo que a topologia de uma area desconhecida Iora dela, reduzindo a quantidade
de traIego de roteamento entre as partes do AS. A area de backbone a responsavel por distribuir
as inIormaes de roteamento entre as areas nonbackbone e identiIicada pelo ID 0 (ou 0.0.0.0).
Em ASs onde no ha essas divises a area de backbone geralmente a unica a ser conIigurada.
O OSPFv3 um protocolo especiIico para IPv6, apesar de ter sido baseado na verso do
OSPFv2, utilizada em redes IPv4. Deste modo, em uma rede com Pilha Dupla, necessario
utilizar OSPFv2 para o roteamento IPv4 e OSPFv3 para realizar o roteamento IPv6.
Mais inIormaes:
RFC 5340 - OSPF for IPv6
OSPFv3
Open Shortest Path First version 3 (OSPFv3) - protocolo GP do tipo
link-state
Roteadores descrevem seu estado atual ao longo do AS enviando
LSAs (flooding)
Utiliza o algoritmo de caminho mnimo de Dijkstra
Agrupa roteadores em reas
Baseado no OSPFv2
Protocolo especfico para Pv6
Em um ambiente Pv4+Pv6 necessrio usar OSPFv2 (Pv4) e
OSPFv3 (Pv6)
236
Roteadores OSPFv3
Os roteadores OSPF podem ser classiIicados como:
Internal Router (IR) roteadores que se relacionam apenas com vizinhos OSPF
de uma mesma area;
Area Boraer Router (ABR) roteadores que conectam uma ou mais areas ao
backbone. Eles possuem multiplas copias dos bancos de dados de estado, uma para
cada area, e so responsaveis por condensar as inIormaes destas areas e envia-las
ao backbone;
Backbone Router (BR) roteadores pertencentes a area backbone. Um ABR
sempre um BR, desde que todas suas areas estejam diretamente conectadas ao
backbone ou conectadas via virtual link - tunel que conecta uma area ao backbone
passando atravs de outra area; e
Autonomous System Boraer Router (ASBR) roteadores que trocam
inIormaes de roteamento com roteadores de outro AS e distribuem as rotas
recebidas ao longo do seu proprio AS.
237
Algumas caracteristicas do OSPFv2 ainda so encontradas no OSPFv3:
Tipos basicos de pacotes
Hello, DBD, LSR, LSU, LSA
Mecanismos para descoberta de vizinhos e Iormao de adjacncias
Tipos de interIaces
point-to-point, broaacast, NBMA, point-to-multipoint e links virtuais
A lista de estados e eventos das interIaces
O algoritmo de escolha do Designatea Router e do Backup Designatea Router
Envio e idade das LSAs
AREAID e ROUTERID continuam com 32 bits
OSPFv3
Semelhanas entre OSPFv2 e OSPFv3
Tipos bsicos de pacotes
Hello, DBD, LSR, LSU, LSA
Mecanismos para descoberta de vizinhos e formao de
adjacncias
Tipos de interfaces
point-to-point, broadcast, NBMA, point-to-multipoint e links
virtuais
A lista de estados e eventos das interfaces
O algoritmo de escolha do Designated Router e do Backup
Designated Router
Envio e idade das LSAs
AREA_D e ROUTER_D continuam com 32 bits
238
Entras as principais diIerenas entre o OSPFv2 e o OSPFv3 destacam-se:
OSPFv3 roda por enlace e no mais por sub-rede
Foram removidas as inIormaes de endereamento
Adio de escopo para flooaing
Suporte explicito a multipla instncias por enlace
Uso de endereos link-local
Mudanas na autenticao
Mudanas no Iormato do pacote
Mudanas no Iormato do cabealho LSA
Tratamento de tipos de LSA desconhecidos
Suporte a areas Stub/NSSA
IdentiIicao de vizinhos pelo Router IDs
Utiliza endereos multicast (AllSPFRouters FF02::5 e AllDRouters FF02::6)
OSPFv3
Diferenas entre OSPFv2 e OSPFv3
OSPFv3 roda por enlace e no mais por sub-rede
Foram removidas as informaes de endereamento
Adio de escopo para flooding
Suporte explcito a mltipla instncias por enlace
Uso de endereos link-local
Mudanas na autenticao
Mudanas no formato do pacote
Mudanas no formato do cabealho LSA
Tratamento de tipos de LSA desconhecidos
Suporte a reas Stub/NSSA
dentificao de vizinhos pelo Router Ds
Utiliza endereos multicast (AllSPFRouters FF02::5 e
AllDRouters FF02::6)
239
Assim como o OSFP, o Intermeaiate System to Intermeaiate System (IS-IS) um protocolo
IGP do tipo link-state, que utiliza o algoritimo de Dijkistra para calcular as rotas.
O IS-IS Ioi desenvolvido originalmente para Iuncionar sobre o protocolo CLNS, mas a
verso Integratea IS-IS permite rotear tanto pacotes de rede IP quanto OSI. Para isso, utiliza-se
um identiIicador de protocolo, o NLPID, para inIormar qual protocolo de rede esta sendo
utilizado.
Assim como o OSPF, o IS-IS tambm permite trabalhar a rede de Iorma hierarquica,
atuando com os roteadores em dois niveis, o L1 (Stub) e o L2 (Backbone), alm de roteadores que
integram essas areas, os L2/L1.
IS-IS
Intermediate System to Intermediate System (S-S) - protocolo GP do
tipo link-state
Desenvolvido originalmente para funcionar sobre o protocolo CLNS
Integrated IS-IS permite rotear tanto P quanto OS
Utiliza NLPD para identificar o protocolo de rede utilizado
Trabalha em dois nveis
L2 = Backbone
L1 = Stub
L2/L1= nterligao L2 e L1
240
Para tratar o roteamento IPv6, no Ioi deIinida uma nova verso do protocolo IS-IS, apenas
Ioram adicionadas novas Iuncionalidades a verso ja existente.
Duas novas TLVs (Type-Length-Jalues) Ioram adicionadas:
IPv6 Reachability (type 236) carrega as inIormaes das rede acessiveis;
IPv6 Interface Address (type 232) traz os endereos IP da interIace que esta
transmitindo o pacote.
Tambm Ioi adicionado um novo identiIicador da Camada de Rede
IPv6 NLPID seu valor 142.
O processo de estabelecimento de vizinhanas no muda.
Mais inIormaes:
RFC 1195 - Use of OSI IS-IS for Routing in TCP/IP ana Dual Environments
RFC 5308 - Routing IPv6 with IS-IS
IS-IS
No h uma nova verso desenvolvida para trabalhar com o Pv6.
Apenas adicionaram-se novas funcionalidades verso j existente
Dois novos TLVs para
Pv6 Reachability
Pv6 nterface Address
Novo identificador da camada de rede
Pv6 NLPD
Processo de estabelecimento de vizinhanas no muda
241
O protocolo de roteamento externo padro hoje, o Boraer Gateway Protocol verso 4
(BGP-4). E um protocolo do tipo path vector, onde roteadores BGP trocam inIormaes de
roteamento entre ASs vizinhos desenhando um graIo de conectividade entre os ASs.
O protocolo de roteamento externo padro hoje, o Border Gateway
Protocol verso 4 (BGP-4).
protocolo do tipo path vector.
Roteadores BGP trocam informaes de roteamento entre ASs
vizinhos.
com essas informaes, desenham um grafo de conectividade
entre os ASs.
ProtocoIo de Roteamento
Externo
242
Porta TCP 179
Quatro tipos de mensagem:
Open
Update
Keepalive
Notification
Dois tipos de conexo:
eBGP
BGP
Funcionamento representado
por uma Mquina de Estados.
BGP
O BGP um protocolo extremamente simples baseado em sesses TCP ouvindo na porta
179.
Quatro tipos de mensagens BGP so utilizadas para troca de inIormaes e manter o estado
da conexo TCP:
- Open - enviada pelos dois vizinhos logo apos o estabelecimento da conexo TCP,
ela carrega as inIormaes necessarias para o estabelecimento da sesso BGP, como ASN, verso do
BGP, etc;
- Upaate usada para transIerir as inIormaes de roteamento entre os vizinhos BGP,
que sero utilizadas para construir o graIo que descreve o relacionamento entre varios ASs;
- Keepalive so enviadas Irequentemente para evitar que a conexo TCP expire;
- Notification enviada quando um erro detectado, Iechando a conexo BGP
imediatamente apos o seu envio.
Voc pode estabelecer dois tipos de conexo BGP:
- externa (eBGP) conexo entre dois ASs vizinhos;
- interna (iBGP) conexo entre roteadores dentro de um mesmo AS. O
estabelecimento do iBGP muito importante para se manter uma viso consistente das rotas
externas em todos os roteadores de um AS.
O Iuncionamento do BGP pode ser representado por uma Maquina de Estados Finitos. Para
quem no esta Iamiliarizado com o BGP, ao veriIicar que o estado de uma conexo esta 'Active ou
'Established, pode ter a Ialsa impresso de que a conexo esta 'ativa ou 'estabelecida, mas em
geral, em BGP quando ha 'palavras representando o estado, signiIica que a sesso BGP ainda no
esta ok. A sesso so estara eIetivamente estabelecida quando Ior observada a quantidade de preIixos
que se esta recebendo do vizinho. Esse nomes representam estados intermediarios da sesso BGP.
IdentiIicar esses estados ajuda na analise e resoluo de problemas.
Mais inIormaes:
RFC 4271 - A Boraer Gateway Protocol 4 (BGP-4)
RFC 4760 - Multiprotocol Extensions for BGP-4
243
Apesar da RFC do BGP recomendar alguns pontos, o critrio de seleo entre diIerentes
atributos do BGP pode variar de implementao para implementao. No entanto, a maior parte
das implementaes segue os mesmos padres.
Os atributos BGP podem ser divididos em duas grandes categorias:
Bem-Conhecidos (Well-know) so atributos deIinidos na especiIicao
original do protocolo BGP. Eles se sub-dividem em outras duas categorias:
Mandatrios (Manaatory) - devem estar sempre presentes nas
mensagens do tipo UPDATE e devem ser obrigatoriamente
reconhecidos em todas as implementaes do protocolo;
Descricionrio (Discretionary) - no precisam estar obrigatoriamente
presente em todas as mensagens UPDATE.
Opcionais (Optional) - no so obrigatoriamente suportados por todas as
implementaes de BGP. Eles se sub-dividem em outras duas categorias:
Transitivos (Transitive) devem ser repassados nas mensagens
UPDATE;
No-Transitivo (Non-transitive) no deve ser repassado.
Atributos do BGP
ORIGIN Bem-conhecido Mandatrio
AS_PATH Bem-conhecido Mandatrio
NEXT_HOP Bem-conhecido Mandatrio
MULTI_EXIT_DISC Opcional No-transitivo
LOCAL_PREF Bem-conhecido Discricionrio
ATOMIC_AGGREGATE Bem-conhecido Discricionrio
AGGREGATOR Opcional Transitivo
O critrio de seleo entre diferentes atributos do BGP varia de
implementao para implementao.
Os atributos BGP so divididos em algumas categorias e sub-
categorias.
244
A RFC do BGP apresenta os seguintes atributos:
ORIGIN Bem-Conhecido e Mandatorio. Indica se o caminho Ioi aprendido
via IGP ou EGP;
ASPATH - Bem-Conhecido e Mandatorio. Indica o caminho para se chegar a
um destino, listando os ASN pelos quais se deve passar;
NEXTHOP Bem-Conhecido e Mandatorio. Indica o endereo IP da
interIace do proximo roteador;
MULTIEXITDISC Opcional e No-Transitivo. Indica para os vizinhos
BGP externos qual o melhor caminho para uma determinada rota do proprio
AS, inIluenciando-os, assim, em relao a qual caminho deve ser seguido no
caso do AS possuir diversos pontos de entrada;
LOCALPREF Bem-Conhecido e Discricionario. Indica um caminho
preIerencial de saida para uma determinada rota, destinada a uma rede externa
ao AS;
ATOMICAGGREGATE Bem-Conhecido e Discricionario. Indica se
caminhos mais especiIicos Ioram agregados em menos especiIicos.
AGGREGATOR - Opcional e Transitivo. Indica o ASN do ultimo roteador que
Iormou uma rota agregada, seguido de seu proprio ASN e endereo IP.
243
Na deciso pela melhor rota, os atributos so considerados se o caminho Ior conhecido, se
houver conectividade, se Ior acessivel e se o next hop estiver disponivel. Porm, a Iorma de
seleo pode variar de acordo com a implementao.
Um atributo que merece destaque o LOCALPREFERENCE. Ele um atributo
extremamente poderoso para inIluenciar o traIego de saida. Seu valor valido para todo o AS,
sendo repassado apenas nas sesses iBGP.
Atributos do BGP
Os atributos so considerados se o
caminho for conhecido, se houver
conectividade, se for acessvel e se o
next hop estiver disponvel.
A forma de seleo pode variar de
acordo com a implementao.
O LOCAL_PREFERENCE um
atributo extremamente poderoso para
influenciar o trfego de sada.
O valor do LOCAL_PREFERENCE
valido para todo o AS.
Seleo do caminho no BGP (CSCO).
246
Foram deIinidas extenses para o BGP-4 com o intuito de habilita-lo a carregar
inIormaes de roteamento de multiplos protocolo da Camada de Rede (ex., IPv6, IPX, L3VPN,
etc.). Para se realizar o roteamento externo IPv6 essencial o suporte ao MP-BGP, visto que no
ha uma verso especiIica de BGP para tratar esta tareIa.
Para que o BGP possa trabalhar com inIormaes de roteamento de diversos protocolos,
dois novos atributos Ioram inseridos:
Multiprotocol Reachable NLRI (MPREACHNLRI): carrega o conjunto de
destinos alcanaveis junto com as inIormaes do next-hop,
Multiprotocol Unreachable NLRI (MPUNREACHNLRI): carrega o conjunto
de destinos inalcanaveis.
Estes atributos so Opcionais e No-Transitivos, e no caso de um roteador BGP no
suportar MBGP, este deve ignorar estas inIormaes, no passando-as para seus vizinhos.
Mais inIormaes:
RFC 2545 - Use of BGP-4 Multiprotocol Extensions for IPv6 Inter-Domain Routing
RFC 4760 - Multiprotocol Extensions for BGP-4
MuItiprotocoIo BGP
Multiprotocol BGP (MP-BGP) - extenso do BGP para suportar
mltiplos protocolos de rede ou famlias de endereos.
Para se realizar o roteamento externo Pv6 essencial o
suporte ao MP-BGP, visto que no h uma verso especfica de
BGP para tratar esta tarefa.
Dois novos atributos foram inseridos:
Multiprotocol Reachable NLRI (MP_REACH_NLR) - carrega o
conjunto de destinos alcanveis junto com as informaes do
next-hop;
Multiprotocol Unreachable NLRI (MP_UNREACH_NLR) -
carrega o conjunto de destinos inalcanveis;
Estes atributos so Opcionais e No-Transitivos.
247
As seguintes inIormaes so carregadas por esses atributos:
MPREACHNLRI
Aaaress Family Iaentifier (2 Bytes) - identiIica o protocolo de rede a ser
suportado;
Subsequent Aaaress Family Iaentifier (1 Byte) - identiIica o protocolo de rede a
ser suportado;
Length of Next Hop Network Aaaress (1 Byte) - valor que expressa o
comprimento do campo Network Aaaress of Next Hop, medida em Bytes;
Network Aaaress of Next Hop (variavel) - contem o endereo do proximo salto;
Reservea (1 Byte) - reservado;
Network Layer Reachability Information (variavel) - lista as inIormaes das
rotas acessiveis.
MPUNREACHNLRI
Aaaress Family Iaentifier (2 Bytes) - IdentiIica o protocolo de rede a ser
suportado;
Subsequent Aaaress Family Iaentifier (1 Byte) - IdentiIica o protocolo de rede a
ser suportado;
Witharawn Routes (variavel) - lista as inIormaes das rotas inacessiveis.
MuItiprotocoIo BGP
MP_REACH_NLR
Address Family Identifier (2 Bytes)
Subsequent Address Family Identifier (1 Byte)
Length of Next Hop Network Address (1 Byte)
Network Address of Next Hop (varivel)
Reserved (1 Byte)
Network Layer Reachability Information (varivel)
MP_UNREACH_NLR
Address Family Identifier (2 Bytes)
Subsequent Address Family Identifier (1 Byte)
Withdrawn Routes (varivel)
Cdigos mais comuns para AFI e Sub-AFI
Cdigo AFI Cdigo Sub-AFI Significado
1 1 IPv4 Unicast
1 2 IPv4 Multicast
1 3 IPv4 based VPN
2 1 IPv6 Unicast
2 2 IPv6 Unicast e IPv6 Multicast RPF
2 3 Multicast RPF
2 4 IPv6 Label
2 128 IPv6 VPN
..... .... ...
248
TabeIa BGP
As informaes sobre as rotas da nternet encontram-se na tabela
BGP.
Em roteadores de borda, essas informaes so replicadas para a
RB e para a FB, Pv4 e Pv6.
Tabela Global Pv4 ~300.000 entradas
Tabela Global Pv6 ~2.500 entradas
A duplicidade dessas informaes implica em mais espao, memria,
e processamento.
Agregao de rotas
Evitar anncio de rotas desnecessrios
Limitar a quantidade de rotas recebidas de outros ASs
mportante em Pv4
Fundamental em Pv6
As inIormaes sobre as rotas da Internet encontram-se na tabela BGP. Em roteadores de
borda, que tratam da comunicao entre ASs, essas inIormaes so replicadas para a RIB e para
a FIB, IPv4 e IPv6.
A tabela global IPv4 possuiu hoje aproximadamente 300.000 entradas. A tabela IPv6
possui aproximadamente 2.500 entradas. A duplicidade dessas inIormaes em arquiteturas
distribuidas, implica na necessidade de mais espao para armazenamento, mais memoria e mais
processamento, tanto no modulo central quanto nas placas das interIaces.
Este dados implicam em outro aspecto importante, a necessidade de se estabelecer um
plano hierarquico de endereamento para minimizar a tabela de rotas e otimizar o roteamento,
evitando o anuncio de rotas desnecessarias e desagregadas.
Os ASs tambm podem controlar os anuncios recebidos de seus vizinhos BGP. E possivel,
por exemplo, limitar o tamanho dos preIixos recebidos entre /20 e /24 IPv4, e entre /32 e /48
IPv6. Porm, lembre-se que podemos anunciar at 31 preIixos IPv4 (considerando anuncios entre
um /20 e um /24) e 131.071 preIixos IPv6 (considerando anuncios entre um /32 e um /48), com
isso, ha quem controle tambm a quantidade de preIixos recebidos de seus vizinhos BGP, atravs
de comandos como maximum-prefix (Cisco) e maximum-prefixes (Juniper). Tratar
esta quento em redes IPv4 muito importante, mas em redes IPv6 Iundamental.
249
230
Neste modulo veremos alguns conceitos basicos de como as sesses BGP so
estabelecidas; as vantagens na utilizao de interIaces loopbacks em sesses iBGP e eBGP;
alguns aspectos de segurana importantes que devem ser observados na comunicao entre ASs;
Iormas de se garantir redundncia e balanceamento de traIego; alm do detalhamento de uma
srie de comandos uteis para se veriIicar o estado das sesses BGP.
Todos esses topicos sero abordados utilizando como base as plataIormas Cisco, Quagga e
Juniper, e utilizando como exemplo a conIigurao IPv4 implementadas em nosso laboratorio.
Deste modo, Iacilitaremos a comparao entre as conIigurao e comandos utilizados com IPv6 e
IPv4.
Boas Prticas de
BGP
MduIo 9
231
Uma sesso BGP estabelecida entre dois roteadores baseado-se em uma conexo TCP,
utilizando como padro a porta TCP 179, necessitando para isso, de uma conexo IP, seja IPv4 ou
IPv6.
Uma das Iormas de se estabelecer essa comunicao, atravs de interIaces loopback.
Elas so interIaces logicas, como a 'null0, ou seja, ela 'no cai, a no ser que se desligue o
roteador, ou a interIace seja desconIigurada.
EstabeIecendo sesses BGP
Uma sesso BGP estabelecida entre dois roteadores
baseada numa conexo TCP.
porta TCP 179;
conexo Pv4 ou Pv6.
nterface de Loopback
interface lgica;
no caem.
232
Por suas caracteristicas, Iundamental que as sesses iBGP sejam estabelecidas utilizando
a interIace loopback. Caso a sesso seja estabelecida via IP da interIace Iisica, real, se o link Ior
interrompido, a sesso tambm sera. Se Ior estabelecida via interIace loopback, a sesso podera
ser re-estabelecida por outro caminho aprendido atravs dos protocolos IGP.
A utilizao de interIaces loopback no estabelecimento das sesses iBGP proporcionam
maior estabilidade aos AS.
EstabeIecendo sesses BGP
iBGP entre loopbacks
fundamental estabelecer sesses iBGP utilizando a interface de
loopback.
via P da interface real:
se o link for interrompido, a sesso tambm ser.
via P da interface de loopback:
mais estabilidade;
os Ps das interfaces de loopback sero aprendidos via
protocolo GP.
se o link for interrompido, a sesso pode ser estabelecida
por outro caminho.
233
Tambm recomendada a utilizao de interIaces loopback no estabelecimento de sesses
eBGP. Uma das Iinalidades de se estabelecer este tipo de conexo, garantir balanceamento.
Analise o seguinte exemplo:
Ha dois roteadores, cada um representando um AS, e eles esto conectados atravs de
dois links;
Se Ior utilizado nesta comunicao o IP das interIaces reais sera necessario estabelecer
duas sesses BGP e para cada sesso, eventualmente havera uma politica diIerente.
Isso pode ocasionar complicaes desnecessarias.
Utilizar as interIace loopback simpliIica esse processo. Nesse caso, so sera necessaria
uma sesso BGP, e a criao de rotas estaticas, apontando para o IP da loopback do
vizinho atravs de cada link.
EstabeIecendo sesses BGP
eBGP entre loopbacks
Balanceamento
Ex.:
H dois roteadores e cada roteador representa um AS;
Eles esto conectados por dois links;
Utilizando o P das interfaces reais:
Sero necessrias duas sesses BGP;
Eventualmente com polticas diferentes.
Utilizando o P das interfaces de loopbacks
estabelecida uma nica sesso BGP;
Cria-se uma rota esttica para o P da interface loopback do
vizinho atravs de cada link.
AS64511 AS64512
lo lo
234
No estabelecimento da sesso eBGP atravs da loopback, a rota estatica deve ser criada via
interIace ou via IP?
Se Ior uma interIace serial pode-se apontar a rota para a interIace. InterIaces seriais so um
'tubo, as inIormaes que traIegam por ela chegam diretamente do outro lado, portanto, pode-se
apontar a rota para a interIace.
Caso seja um meio compartilhado, uma interIace Ethernet por exemplo, deve-se apontar
para o IP.
Outro ponto importante o tamanho de rede utilizado nestes tipos de links. Em um link
serial, normalmente utiliza-se preIixos de redes /30 IPv4. Com isso, so possiveis quatro
endereos IP: o de rede; de broaacast; e os dois que vo identiIicar as interIaces. No entanto, em
um link serial no so necessarios os endereos de rede nem de broaacast, por isso, ha uma
abordagem que utiliza preIixos de rede /31 neste tipo de link. Este mtodo permite tambm a
econimia de uma grande quantidade de endereos IPv4, principalmente em operadora que
trabalham com milhares de links ponto-a-ponto. Porm, isto so recomendado para links seriais,
no em Ethernet.
Em redes IPv6, o equivalente ao /31 IPv4 seria um /127. A RFC 3627 no recomenda a
utilizao de /127, devido a possiveis problemas com o endereo anycast Subnet-Router, no
entanto, existe um araft que questiona esse argumento.
Existem diversas possibilidades para se trabalhar em IPv6. Em links ponto-a-ponto pode-se
utilizar um preIixo /64 ou /126, mas uma opo interessante utilizar /112, de modo a se trabalhar
apenas com o ultimo grupo de Bytes do endereo.
Mais inIormaes:
RFC 3021 - Using 31-Bit Prefixes on IPv4 Point-to-Point Links
RFC 3627 - Use of /127 Prefix Length Between Routers Consiaerea Harmful
draIt-kohno-ipv6-preIixlen-p2p-00.txt - Use of /127 IPv6 Prefix Length on P2P Links Not Consiaerea Harmful
EstabeIecendo sesses BGP
eBGP entre loopbacks
Essa rota esttica deve ser via interface ou via P?
Se for uma interface serial pode-se apontar a rota para a
interface;
Se for uma interface Ethernet deve-se apontar para o P.
Em link serial, o tamanho de rede Pv4 normalmente utilizado /30.
Um /30 possui 4 P; rede; broadcast; e os dois lados;
Em links seriais pode-se utilizar /31.
Qual o equivalente ao /31 em Pv6?
Em Pv6 pode-se trabalhar com redes /64 em links seriais.
Uma boa opo trabalhar com /112.
AS64511 AS64512
lo lo
233
Em relao ao endereamento das interIace loopback, normalmente utilizam-se preIixos /32 IPv4
e /128 IPv6. Isso desmistiIica a ideia de que so possivel utilizar preIixos /64. A utilizao de /64
so obrigatoria quando utiliza-se o protocolo de Descoberta de Vizinhana.
O endereo IP utilizado na loopback deve Iazer parte do bloco do proprio AS e deve ser um
endereo valido, no pode-se utilizar IPs privados. Os endereos IPs privados so para uso interno
na sua rede e a comunicao entre ASs uma conexo Internet, o que exige IPs validos.
O endereo da interIace real, conectada ao link de trnsito, deve ser do bloco da operadora
que Iornece o servio, do UpStream Proviaer. Alm disso, esse endereo IP deve ser roteavel.
Esta uma questo bastante polmica, pois ha quem deIenda que esse endereo no seja roteavel
devido a questes de segurana. Se houver uma relao IP interna com a operadora, por exemplo
uma conexo MPLS, interessante que se utilize um IP valido, da operadora, e no roteavel. No
entanto, se Ior um servio Internet, a operadora tem obrigao de Iornecer um endereo roteavel,
porque ter conectividade um ponto Iundamenta em um servio Internet.
Ex. 1 O traIego gerado por um roteador sai com IP da interIace de saida como IP de
origem. Com isso, se o seu roteador se conectar a um servidor NTP, seja IPv4 ou IPv6, o IP de
origem desse pacote sera o IP da interIace pela qual ele sabe chegar ao destino. Se Ior um IP no
roteavel, o pacote vai chegar ao servidor, mas o servidor no sabera como retornar a resposta.
Ex. 2 - Ha quem pea para a operadora no rotear esse IP por questes de segurana. Se os
IPs internos Iorem roteaveis, no ha proteo alguma, pois se houver apenas um IP roteavel, ele
sera conhecido pelo mundo e havera outro caminho para se chegar at ele, por exemplo, entrando
em outro elemento do AS que conhea o IP do roteador.
EstabeIecendo sesses BGP
eBGP entre loopbacks
Normalmente utilizam-se na interface de loopback prefixo /32 Pv4
ou /128 Pv6.
O P da loopback de responsabilidade do prprio AS.
No se deve utilizar P privado.
O P do link de trnsito da responsabilidade do Provedor de
Trnsito.
Esse P deve ou pode ser rotevel?
Se for uma relao P interna com a operadora, pode ser um
P vlido, da operadora e no rotevel, ex. conexo MPLS;
Se for um servio nternet, o P DEVE ser rotevel.
AS64511 AS64512
lo lo
236
Ha quem deIenda que a utilizao de interIace loopback so realmente necessaria apenas
para garantir o balanceamento do traIego. Essa pratica auxilia tambm em relao a questes de
segurana.
Estabelecer sesses eBGP utilizando o IP da interIace, pode Iacilitar ataques contra a
inIraestrutura de um AS. Por isso, recomendavel trabalhar sesses eBGP entre loopbacks
independente da existncia de apenas um link.
EstabeIecendo sesses BGP
eBGP entre loopbacks
Segurana
A utilizao de interfaces loopbacks em sesses eBGP no
necessria apenas para garantir balanceamento.
Estabelecer sesses eBGP utilizando o P da interface, facilita
muito ataques contra a infraestrutura.
recomendvel trabalhar eBGP entre loopbacks mesmo que s
haja um link.
AS64511 AS64512
lo lo
237
Esta questo pode ser exempliIicada com o cenario a seguir:
Uma sesso eBGP entre dois roteadores estabelecida atravs de uma conexo TCP;
Para isso, so necessarias quatro variaveis basicas: dois endereos IP e duas portas
TCP, uma padro, a 179, e da mesma Iorma que uma aplicao HTTP, o roteador que
iniciar a sesso BGP, vai sair por uma porta alta, maior que 1024, para Iechar com a
179;
Se a sesso eBGP Ior estabelecida utilizando o IP da interIace, possivel identiIicar
esse IP utilizando comandos como o traceroute. Como normalmente so utilizados
preIixo /30 IPv4, se Ior descoberto um IP, descobrir o segundo torna-se mais simples.
Com isso, das quatro variaveis, duas so Iaceis de descobrir;
A terceira uma porta padro, a 179;
Ou seja de quatro variaveis trs podem ser descobertas de Iorma relativamente Iacil, e
a unica variavel que Ialta, a porta alta, tambm no apresenta diIiculdade para sua
descoberta.
EstabeIecendo sesses BGP
eBGP entre loopbacks
Segurana
Ex.:
Para estabelecer uma sesso eBGP sobre TCP so necessrias
4 informaes bsicas:
2 Ps e 2 portas TCP (179 e >1024).
Se a sesso eBGP for estabelecida utilizando o P da interface:
normalmente identifica-se um dos P utilizando traceroute;
descobrindo o primeiro, descobre-se o segundo, visto que
normalmente utiliza-se /30;
a terceira informao uma porta padro, a 179.
Ou seja, de 4 variveis 3 podem ser descobertas de forma
relativamente fcil.
AS64511 AS64512
lo lo
238
Uma das Iormas de 'derrubar um AS ou um destino, 'derrubar o AS que prov
conectividade para ele e isso pode ser Ieito interrompendo as sesses eBGP.
Estabelecer a sesso eBGP utilizando a sesso loopback apresenta alguns pontos relativos a
segurana. Os IPs da loopback so IPs da rede interna, no sendo descobertos com traceroutes
Iacilmente, e o Iato dos dois IPs serem totalmente distintos, no tendo relaes entre eles,
diIiculta ainda mais.
EstabeIecendo sesses BGP
eBGP entre loopbacks
Segurana
Uma das formas de derrubar um As ou um destino, derrubar o
AS que prov conectividade para ele.
Estabelecendo uma sesso eBGP utilizando loopbacks:
os Ps so das redes internas, no tendo relaes entre eles;
dificulta a descoberta via traceroute.
AS64511 AS64512
o lo
239
Outro aspecto que se deve destacar em relao a utilizao da interIace loopback o de
trabalhar com uma loopback por Iuno e no uma unica loopback por roteador. Por exemplo,
pode-se conIigurar uma loopback para o Router ID, uma para o iBGP e uma para o eBGP.
Ex.:
Ha uma sesso eBGP estabelecida e preciso migrar essa sesso para um outro
roteador;
Se alm de ser a loopback usada para a sesso eBGP ela tambm Ior usada para n
outras Iunes. Se Ior assim, a migrao sera mais complicada;
Se Ior uma loopback por Iuno, a migrao podera ser realizada sem interIerir com
as outras Iunes. Pode-se mudar o iBGP, o Router ID, alterar a sesso eBGP de um
roteador para outro sem ter que avisar a operadora e no tem que mudar outros
servios internos.
Esta pratica apresenta uma maior Ilexibilidade, apesar de consumir mais endereos IP.
Entretanto, como normalmente so utilizados preIixos /32 ou /128, esta questo no to grave.
EstabeIecendo sesses BGP
Tambm recomenda-se trabalhar com uma loopback por funo e no
uma por roteador:
pode-se configurar uma loopback para o Router D, uma para o
iBGP e uma para o eBGP;
facilita a migrao de servios;
traz flexibilidade, porm, consome mais endereos P.
AS64511 AS64512
lo lo
Neste diagrama, podemos analisar as opes de conIigurao apresentadas at o momento.
260
EstabeIecendo sesses BGP
Uma importante tcnica de proteo a utilizao de MD5 para autenticao das sesses
BGP. Desta Iorma garante-se que apenas roteadores conIiaveis estabeleam sesses BGP com o
AS.
O algoritimo MD5 cria um chechsum codiIicado que incluido no pacote transmitido e o
roteador que recebe o pacote utiliza uma chave de autenticao para veriIicar o hash.
Utilize os seguintes comandos para habilitar essa Iuncionalidade:
neighbor 'ip-address ou peer-group-name password 'senha (Cisco)
authentication-key 'senha (Juniper)
Mais inIormaes:
RFC 1321 - The MD5 Message-Digest Algorithm
RFC 2385 - Protection of BGP Sessions via the TCP MD5 Signature Option
261
UtiIizando MD5
Uma importante tcnica de proteo a utilizao de MD5 para
autenticao das sesses BGP.
Garante que apenas roteadores confiveis estabeleam sesses
BGP com o AS.
O algortimo MD5 cria um chechsum codificado que includo no
pacote transmitido.
O roteador que recebe o pacote utiliza uma chave de autenticao
para verificar o checksum.
neighbor ip-address ou peer-group-name password senha
(Cisco)
authentication-key senha (Juniper)
Um ponto importante na conIigurao de roteadores IPv6 o Iuncionamento do protocolo
de Descoberta de Vizinhana. Ha roteadores que trazem o anuncio de mensagens RA (Router
Aavertisements) habilitado por padro. Caso seja utilizado na interIace do roteador um endereo /
64, vai haver descoberta de vizinhana, mesmo entre roteadores. Com isso o roteador pode
anunciar que ele o gateway padro para os outros roteadores da rede, podendo gerar loopings.
Esta Iuncionalidade so deve ser habilitada em interIaces que estejam conectadas a estaes
de trabalho ou em alguns casos, a servidores. Em links entre roteadores deve-se desabilitar o
envio das mensagens RA.
Esta Iuncionalidade pode ser desabilitada com a utilizao dos seguintes comandos:
ipv6 nd ra suppress (Cisco)
ipv6 nd suppres-ra (Cisco / Quagga / Juniper)
262
DesabiIitando a Descoberta de
Vizinhana
H roteadores que trazem o anncio de mensagens RA habilitado por
padro.
Se for utilizado na interface do roteador um endereo /64 vai haver
descoberta de vizinhana, mesmo entre roteadores.
Com isso o roteador pode anunciar que ele o gateway padro;
Pode gerar looping
No h problemas em links para estaes de trabalho.
Em links entre roteadores deve-se desabilitar o envio de RA.
ipv6 nd ra suppress (Cisco)
ipv6 nd suppres-ra (Cisco / Quagga / Juniper)
Ter conhecimento das Iuncionalidades e conIiguraes habilitas nos roteadores muito
importante principalmente quando se obtm um equipamento novo. Alguns comandos que podem
Iacilitar essa tareIa so:
Para veriIicar os protocolos conIigurados podemos utilizar:
show ip protocols (Cisco)
show ipv6 protocols (Cisco)
No Quagga existe um aaemon especiIico para cada protocolo de roteamento, tratado como
um processo separado.
Para veriIicar o status e os endereos das interIaces utilizamos:
show ip interface brief (Cisco)
show ipv6 interface brief (Cisco)
show interface terse (Juniper v4 e v6)
Note que, no caso de se trabalhar com sub-interIaces, o endereo link-local IPv6 sera o
mesmo. So interIaces logicas distintas, mas o endereo composto pelo MAC da Iisica.
Esses comandos so uteis porque mostram de Iorma resumida o esta conIigurado no
equipamento, que interIaces ja esto habilitadas com IPv6 por exemplo, etc.
263
Verificando Configuraes
Verificando os protocolos configurados:
show ip protocols (Cisco)
show ipv6 protocols (Cisco)
No Quagga existe um daemon especfico para cada protocolo de
roteamento, tratado como um processo separado.
Verificando o status e os endereos das interfaces:
show ip interface brief (Cisco)
show ipv6 interface brief (Cisco)
show interface terse (Juniper v4 e v6)
Note que, no caso de se trabalhar com sub-interfaces, o endereo
link-local Pv6 ser o mesmo. So interfaces lgicas distintas, mas
o endereo composto pelo MAC da fsica.
Os comandos a seguir listam uma srie de inIormaes de estado da tabela BGP:
Mostrando todos os vizinhos BGP IPv4:
show ip bgp summary (Cisco / Quagga)
show bgp summary (Juniper)
Mostrando todos os vizinhos BGP de ambas as Iamilias:
show bgp ipv4 unicast summary (Cisco / Quagga)
show bgp ipv6 unicast summary (Cisco / Quagga)
show bgp all summary (Cisco / Quagga)
A partir dessas inIormaes pode-se detectar uma srie de problemas da sesso BGP.
264
Verificando a Vizinhana BGP
Mostrando todos os vizinhos BGP Pv4:
show ip bgp summary (Cisco / Quagga)
show bgp summary (Juniper)
Mostrando todos os vizinhos BGP de ambas as famlias:
show bgp ipv4 unicast summary (Cisco / Quagga)
show bgp ipv6 unicast summary (Cisco / Quagga)
show bgp all summary (Cisco / Quagga)
Neste exemplo, podemos observar os seguintes dados sobre os vizinhos das sesses BGP
IPv6 em um roteador Cisco:
Neighbor IP do vizinho em que se estabeleceu a sesso BGP;
V verso do BGP;
AS ASN do vizinho;
MsgRcvd quantidade de mensagens recebidas do vizinho;
MsgSent quantidade de mensagens enviadas ao vizinho;
esses dois ultimos campos normalmente no so muito veriIicados, mas so
importantes. Muita variao desses campos pode identiIicar um problema.
Receber muitas mensagens, se a tabela esta sendo atualizada muitas vezes, pode
indicar uma Ilutuao grande com seu vizinho.
TblVer verso da tabela;
InQ Iila de entrada de pacotes;
OutQ Iila de saida de pacotes;
Up/Down - tempo da ultima mudana de estado;
State/PIxRcd indica o estado atual ou o numero de preIixo aprendidos. Lembre-se,
apesar de existirem estados como Active e Established, que aparentemente indicam
que a sesso esta ok, eles apenas representam estados intermediarios da conexo. A
sesso so estara plenamente estabelecida quando houver a indicao de quantos
preIixos Ioram aprendidos.
265
Verificando a Vizinhana BGP
router-R13#show bgp ipv6 unicast summary
BGP router identifier 172.21.15.253, local AS number 64501
BGP table version is 45, main routing table version 45
28 network entries using 4368 bytes of memory
54 path entries using 4104 bytes of memory
45/17 BGP path/bestpath attribute entries using 7560 bytes of memory
34 BGP AS-PATH entries using 848 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
Bitfield cache entries: current 2 (at peak 3) using 64 bytes of memory
BGP using 16944 total bytes of memory
26 received paths for inbound soft reconfiguration
BGP activity 49/1 prefixes, 96/21 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
2001:DB8:21::254 4 64501 1867 1856 45 0 0 1w0d Active
2001:DB8:21::255 4 64501 4136 3642 45 0 0 1d07h 26
2001:DB8:20::255 4 64512 1896 1876 45 0 0 1d07h 0
Cisco
Observe a saida do mesmo comando, mas agora para visualizar as inIormaes sobre a
vizinhana BGP IPv4 em um roteador Cisco:
router-R13#show bgp ipv4 unicast summary
BGP router identifier 172.21.15.253, local AS number 64501
BGP table version is 80, main routing table version 80
31 network entries using 4092 bytes of memory
52 path entries using 2704 bytes of memory
33/22 BGP path/bestpath attribute entries using 5544 bytes of memory
28 BGP AS-PATH entries using 672 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
Bitfield cache entries: current 3 (at peak 4) using 96 bytes of memory
BGP using 13108 total bytes of memory
21 received paths for inbound soft reconfiguration
BGP activity 99/40 prefixes, 185/84 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.2.255.255 4 64512 10578 10474 80 0 0 1w0d Active
172.21.15.254 4 64501 10544 10490 80 0 0 1w0d 0
172.21.15.255 4 64501 10572 10490 80 0 0 1w0d 21
Neste exemplo, podemos observar os seguintes dados sobre os vizinhos das sesses BGP
em um roteador Juniper:
Groups - numero de grupos BGP;
Peers numeros de vizinhos BGP;
Down peers numero de vizinhos BGP desconectados;
Table nome da tabela de rotas;
Tot Paths numero total de caminhos;
Act Paths numero de rotas ativas;
Suppressed - numero de rotas atualmente inativas. Estas rotas no aparecem na
tabela de encaminhamento e no so exportadas pelos protocolos de roteamento;
History - numero de rotas retiradas armazenadas localmente para manter o controle
historico de instabilidade;
Damp State numero de rotas com uma Iigura de mrito maior que zero, mas que
continuam ativas porque o valor no atingiu o limite em que a retirada ocorre;
Pending rotas em processamento pela politica de importao do BGP;
Peer endereo de cada vizinho BGP;
AS ASN do vizinho;
InPkt numero de pacotes recebidos do vizinho;
OutPkt numrero de pacotes enviados ao vizinho;
OutQ - Iila de saida de pacotes;
Flaps numero de vezes que a sesso BGP Ioi interrompida e se re-estabeleceu;
Last Up/Down ultima vez em que ocorreu uma mudana de estado;
State,#Active/Received/Accepted/Damped - indica o estado atual ou o numero de
preIixo aprendidos. Se a sesso no Ioi estabelecida, este campo mostra o estado atual
da sesso: Active, Connect, ou Idle. Se a sesso Ioi estabelecida, o campo indica o
numero de rotas ativas, recebidas, aceitas ou instaveis.
Observe que o Juniper apresenta na saida do mesmo comando as inIormaes sobre as sesses
IPv4 e IPv6.
267
Verificando a Vizinhana BGP
juniper@R11> show bgp summary
Groups: 4 Peers: 5 Down peers: 1
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0 19 17 0 0 0 0
inet6.0 56 27 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped
10.1.8.1 64511 3785 4127 0 0 1d 7:26:53 17/17/17/0
172.28.15.252 64508 3776 4135 0 0 1d 7:26:38 0/2/2/0
172.28.15.254 64508 3775 4136 0 0 1d 7:26:46 Connect
2001:db8:28::252 64508 3794 4147 0 0 1d 7:26:40 Establ inet6.0: 0/29/29/0
2001:db8:28::254 64508 3775 4149 0 0 1d 7:26:46 Establ inet6.0: 0/0/0/0
2001:db8:10::1 64511 3810 4128 0 0 1d 7:26:57 Establ inet6.0: 27/27/27/0
Juniper
Um ponto importante no plano de endereamento IP, tanto IPv4 quanto IPv6, a
distribuio dos servios, servidores, etc., entre partes distintas do bloco IP, de modo a Iacilitar a
inIluncia do traIego de entrada e saida do AS.
No recomendavel posicionar todos os servidores, clientes importantes que geram a
maior parte do traIego, no mesmo /24 IPv4 ou /48 IPv6. Esta ma distribuio restringira a
inIluencia do traIego de entrada. Porque o traIego de entrada inIluenciado pelos anuncios
gerados. Ou seja, Iundamental no plano de endereamento ver como sero posicionados os
consumidores de traIego de entrada e de saida.
Consumidor de traIego de entrada, que so os usuarios de acesso a Internet, tem que se
distribuir bem entre os preIixos anunciados.
268
PIano de Endereamento
Distribuio dos servios, servidores, etc., entre partes distintas do
bloco P.
facilita a influncia do trfego de entrada e sada de seu AS;
no adianta concentrar todo o trfego principal atrs do mesmo
prefixo /24 ou /48 anunciado na nternet.
Esta m distribuio ir restringir a influncia do trfego de entrada ou
de sada?
269
PIano de Endereamento
AS-OUT
o que ser anunciado para a nternet;
nterfere com o trfego de entrada.
Ex.:
O AS54501 possui um /48 Pv6;
para fazer o balanceamento do trfego, influenciaremos para
que metade deste trfego entre por um link e a outra metade
entre por outro;
divide-se o /48 em dois /49, anunciando o primeiro /49 em um
link e o segundo /49 em outro link.
AS-OUT a politica que trata do que sera anunciado para a Internet. E o que vai interIerir
com o traIego de entrada.
Por exemplo, o AS64501 possui um bloco /48 IPv6 e, para dividir e Iazer o balanceamento
do traIego de entrada por dois links de acesso a Internet, deve-se inIluencia-lo para que uma
metade entre por um link e a outra metade entre por outro link. Para isso, divide-se o /48 em dois
preIixos /49, anunciando o primeiro /49 em um link e o segundo /49 em outro link. Isto utilizado
para possibilitar um balanceamento do traIego.
270
PIano de Endereamento
AS-N
Depende dos anncios recebidos da nternet
normalmente a tabela completa.
nterfere com o trfego de sada.
Pode-se influenciar o trfego de sada alterando o valor do
LOCAL_PREFERENCE de acordo com determinadas condies.
LOCAL_PREFERENCE o atributo com maior fora para
influenciar o trfego de sada.
Ex.: O AS54501 precisa influenciar seu trfego de sada, de
modo que o trfego com destino ao primeiro /49 do AS64513
saia preferencialmente pelo link com o AS64511 e o trfego
com destino ao segundo /49 do AS64513 saia
preferencialmente pelo link com o AS64512.
Preferencialmente uma palavra chave para o BGP.
AS-IN a politica que ira interIerir no traIego de saida. Ela depende dos anuncios que so
recebidos da Internet, normalmente a tabela de roteamento completa.
Para inIluenciar o traIego de saida, pode-se alterar o valor do atributo
LOCALPREFERENCE dos anuncios recebidos, de acordo com determinadas condies. Ele o
atributo com maior Iora para inIluenciar este tipo de traIego.
Ex.: O AS 54501 precisa inIluenciar seu traIego de saida, de modo que o traIego com
destino ao primeiro /49 do AS64513 saia preIerencialmente pelo link com o AS64511
e o traIego com destino ao segundo /49 do AS64513 saia preIerencialmente pelo link
com o AS64512.
PreIerencialmente uma palavra chave para o BGP. E Iundamental, com BGP, trabalhar
com preIerncia e no com Iiltro. Existem varias Iormas de se Iazer isso, mas, para que seja
realmente eIetiva uma conIigurao, especialmente quando ocorre uma queda de link,
importante no se descartar nada, deve-se preIerenciar um caminho em relao ao outro, mas no
descartar. O descarte tem um eIeito imediato, mas quando no houver redundncia, ele deixa de
ser eIetivo.
Para que haja redundncia deve-se atuar da seguinte Iorma:
Apos dividir o bloco /48 IPv6 em dois preIixos /49, cada um deles anunciado em um
link, isso , cada /49 conhecido pelo mundo por apenas um link, um caminho;
Se um desses links cair, o /49 anunciado por ele Iicara inacessivel;
Para termos redundncia, deve-se anunciar tambm o preIixo /48 nos dois links,
Com isso, a Internet conhecera o /48 pelos dois caminhos;
Como a preIerncia pelo preIixo mais especiIico, se os dois links estiverem ativos, a
Internet vai preIerir os /49 sempre, ou seja o balanceamento estara em operao;
Quando um desses links cair, um dos preIixos /49 deixara de ser anunciado. No
entanto, esse /49 esta contido no /48, ou seja, mesmo com um dos links desativado, a
Internet ainda tera a opo do /48 anunciado no outro link. Garantindo a redundncia.
Para realmente distribuir o traIego entre os dois, deve-se colocar metade dos consumidores
de traIego de entrada em um /49 e metade no outro. Isso Iaz parte do planejamento.
271
PIano de Endereamento
Redundncia
Cada /49 Pv6 conhecido pelo mundo por apenas um link
Se um desses links cair, o /49 anunciado por ele ficar inacessvel.
Para termos redundncia, deve-se anunciar tambm o /48 nos dois
links.
Como a preferncia pelo prefixo mais especfico, se os dois links
estiverem ativos, a nternet vai preferir os /49.
Quando um dos links cair e um dos /49 deixar ser anunciado, porm a
nternet ainda ter a opo do /48 anunciado no outro link, garantindo a
redundncia.
Deve-se distribuir o trfego entre os dois, colocando metade dos
consumidores de trfego de entrada em um /49 e metade no outro.
Neste diagrama podemos analisar exemplos das politicas de roteamento apresentadas at o
momento.
AS-OUT Utiliza os anuncios enviados para interIerir o traIego de entrada;
AS-IN Utiliza os anuncios recebidos para inIluenciar o traIego de saida.
272
PIano de Endereamento
AS-OUT
AS-IN
Existem alguns comando que podem Iacilitar a analisar e conIerncia das politicas de
entrada e saida de um roteador.
Para visualiza a conIigurao corrente a partir do BGP em um roteador Cisco ou Quagga:
show running-config | begin bgp
Em nosso exemplo, a primeira linha da conIigurao BGP indica o ASN do proprio AS:
router bgp 64501
Por padro, os roteadores cisco e quagga so conhecem uma Iamilia de endereos, a ipv4-
unicast. Para utilizar outras Iamilias de endereos, utiliza-se o conceito de aaaress-family, e para
habilita-lo utiliza-se o comando:
no bgp default ipv4-unicast
Para habilitar IPv6 em roteadores Cisco e Quagga recomenda-se que seja marcada uma
janela de manuteno, para deste modo, poder interromper o traIego, aplicando o comando
no router bgp 64501
e reIazer toda a conIigurao com aaaress-family.
Mesmo utilizando aaaress-family, no inicio da conIigurao sempre so apresentadas as
inIormaes gerais que independem da Iamilia. Por exemplo:
neighbor 2001:DB8:200:FFFF::255 remote-as 64512 indica o IP e
o ASN do vizinho. Se indicar o ASN do proprio AS, porque trata-se de uma sesso
iBGP;
neighbor 2001:DB8:200:FFFF::255 description R03 apresenta
um nome de identiIicao;
273
Conferindo as configuraes do
eBGP e do iBGP
Visualizando a configurao corrente a partir do BGP (Cisco):
router-R13#show running-config | begin bgp
router bgp 64501
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 2001:DB8:21:FFFF::254 remote-as 64501
neighbor 2001:DB8:21:FFFF::254 description R12
neighbor 2001:DB8:21:FFFF::254 update-source Loopback20
neighbor 2001:DB8:21:FFFF::254 version 4
neighbor 2001:DB8:21:FFFF::255 remote-as 64501
neighbor 2001:DB8:21:FFFF::255 description R11
neighbor 2001:DB8:21:FFFF::255 update-source Loopback20
neighbor 2001:DB8:21:FFFF::255 version 4
neighbor 2001:DB8:200:FFFF::255 remote-as 64512
neighbor 2001:DB8:200:FFFF::255 description R03
neighbor 2001:DB8:200:FFFF::255 ebgp-multihop 2
neighbor 2001:DB8:200:FFFF::255 update-source Loopback30
neighbor 2001:DB8:200:FFFF::255 version 4
...
- neighbor 2001:DB8:200:FFFF::255 ebgp-multihop 2 especiIica o
numero de saltos at se alcanar o vizinho. Uma diIerena importante entre o iBGP e o eBGP,
que o quando o roteador gera uma mensagem eBGP, o pacote IP que carrega essa mensagem
enviado com o valor do TTL, se Ior IPv4, ou do HopLimit, se Ior IPv6, igual a 1, e com isso, ele
so podera alcanar um salto. Se um pacote tiver que ser roteado para uma interIace loopback, e a
mensagem sair como o TTL igual a 1, o roteador de destino ao abri-lo, ira decrementar o valor do
TTL e no podera realizar o roteamento interno para loopback. Por tanto, para levantar a sesso
eBGP entre loopbacks, deve-se especiIicar qual o numero de saltos;
- neighbor 2001:DB8:200:FFFF::255 update-source Loopback30 -
conIigura o roteador para que o IP de origem dos pacotes seja o da loopback, porque ao enviar
uma mensagem, o roteador adota por padro, como endereo IP de origem o IP da interIace por
onde ela enviada.
- neighbor 2001:DB8:200:FFFF::255 version 4 indica a verso de
protocolo BGP utilizada. Essa inIormao agiliza o estabelecimento da sesso BGP, visto que, na
primeira mensagem trocada entre os vizinhos, so passadas algumas inIormaes, entre elas, ha a
negociao da verso. Se ja Ior inIormado desde o inicio qual a verso utilizada, essa negociao
no necessita ser Ieita.
Em relao a conIigurao do iBGP, as unicas diIerenas so que o ASN o do proprio
AS e que diIerente do eBGP, no precisa alterar o TTL. Por padro, no iBGP o TTL no
alterado, presumindo que a sesso possa Iazer um caminho longo, saindo com TTL igual a 255 ou
outro valor intermediario dependendo da implementao.
Observe a seguir um exemplo das conIiguraes de uma sesso BGP IPv4:
router-R13#show running-config | begin bgp
router bgp 64501
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.2.255.255 remote-as 64512
neighbor 10.2.255.255 description R03
neighbor 10.2.255.255 ebgp-multihop 2
neighbor 10.2.255.255 update-source Loopback30
neighbor 10.2.255.255 version 4
neighbor 172.21.15.254 remote-as 64501
neighbor 172.21.15.254 description R12
neighbor 172.21.15.254 update-source Loopback20
neighbor 172.21.15.254 version 4
neighbor 172.21.15.255 remote-as 64501
neighbor 172.21.15.255 description R11
neighbor 172.21.15.255 update-source Loopback20
neighbor 172.21.15.255 version 4
...
Roteadores Juniper ja trabalham com o conceito de aaaress-family por padro. (inet,
inet6).
Para visualiza a conIigurao corrente a partir do BGP em um roteador Juniper:
show configuration protocols bgp
No primeiro grupo so apresentadas as conIiguraes do iBGP inIormando os seguintes
dados:
group iBGPv6 nome do grupo;
type internal indica que iBGP;
local-address 2001:DB8:21:FFFF::255 endereo da interIace de
saida;
export next-hop-self propaga aos roteadores internos que o proximo
salto para qualquer rota o roteador de borda do proprio AS;
neighbor 2001:DB8:21:FFFF::252 indica o IP do vizinho iBGP;
neighbor 2001:DB8:21:FFFF::254 - indica o IP do vizinho iBGP.
O segundo grupo traz as inIormaes do eBGP:
group eBGP-AS64511 nome do grupo;
type external indica que eBGP;
neighbor 2001:db8:100:1::1 indica o endereo do vizinho eBGP;
import nh-BGPin-IPv6-AS64511 politica de entrada aplicada;
export nh-BGPout-IPv6-AS64511 politica de saida aplicada;
peer-as 64511 ASN do vizinho.
DiIerente da conIigurao do roteador Cisco apresentada anteriormente, no exemplo acima
Ioi utilizado o endereo IP da interIace real para se estabelecer as sesses BGP.
275
juniper@R11> show configuration protocols bgp
protocols {
bgp {
group iBGPv6 {
type internal;
local-address 2001:DB8:21:FFFF::255;
export next-hop-self;
neighbor 2001:DB8:21:FFFF::252;
neighbor 2001:DB8:21:FFFF::254;
}
group eBGP-AS64511v6 {
type external;
neighbor 2001:db8:100:1::1 {
import nh-BGPin-IPv6-AS64511;
export nh-BGPout-IPv6-AS64511;
peer-as 64511;
}
}
}
Conferindo as configuraes do
eBGP e do iBGP
Visualizando a configurao corrente a partir do BGP (Juniper):
Observe a seguir um exemplo das conIiguraes de uma sesso BGP IPv4 no Juniper:
juniper@R11> show configuration protocols bgp
protocols {
bgp {
group iBGP {
type internal;
local-address 172.21.15.255;
export next-hop-self;
neighbor 172.21.15.252;
neighbor 172.21.15.254;
}
group eBGP-AS64511 {
type external;
neighbor 10.1.1.1 {
import nh-BGPin-IPv4-AS64511;
export nh-BGPout-IPv4-AS64511;
peer-as 64511;
}
}
}
Trabalhar com TTL ou Hop-Limit igual a 1 auxilia na segurana das sesses BGP, pois
permite que apenas se receba mensagens eBGP de quem estiver diretamente conectado. Porm
isso Iacilmente burlado, basta utilizar comandos como traceroute para identiIicar quantos
saltos so necessarios para chegar ao roteador de destino e gerar um pacote como valor do TTL
necessario para alcana-lo.
A RFC 5082 recomenda que se trabalhe com TTL igual a 255 em vez de 1. Deste modo,
em uma sesso eBGP diretamente conectada utilizando o IP da interIace, possivel garantir que o
vizinho BGP esta a no maximo um salto de distncia atravs da leitura do valor do TTL, que tera
sido decrementado a cada hop.
Para utilizar essa Iuncionalidade preciso conIigurar os dois vizinhos participantes da
sesso eBGP. Quem envia a mensagem deve montar o pacote com TTL igual a 255 e quem recebe
deve habilitar a veriIicao desse campo. Em roteadores Cisco possivel Iazer a veriIicao da
seguinte Iorma:
router-R13(config-router)#neighbor 2001:DB8:200:FFFF::255
ttl-security hops 1
Deste modo, deIine-se o valor minimo esperado para o TTL de entrada para pelo menos
254 (255 1). Com isso, o roteador aceitara a sesso a partir de 2001:DB8:200:FFFF::255
se este estiver a 1 salto de distncia.
Com um vizinho BGP IPv4 essa linha seria:
router-R13(config-router)#neighbor 10.2.255.255 ttl-security
hops 1
Mais inIormaes:
RFC 5082 - The Generalized TTL Security Mechanism (GTSM)
http://www.cisco.com/en/US/docs/ios/123t/123t7/Ieature/guide/gtbtsh.html
http://www.juniper.net/us/en/community/junos/script-automation/library/conIiguration/ttl-security/
277
TTL-Security Check
Trabalhar com TTL ou Hop-Limit igual a 1 auxilia na segurana
Permite que apenas se receba mensagens eBGP de quem estiver
diretamente conectado;
Porm isto facilmente burlado.
RFC5082 recomenda o uso de TTL igual a 255.
Ex.:
router-R13(config-router)# neighbor 2001:DB8:200:FFFF::255
ttl-security hops 1
Define o valor mnimo esperado para o TTL de entrada para pelo
menos 254 (255 - 1).
O roteador aceitar a sesso a partir de 2001:DB8:200:FFFF::255 se
este estiver a 1 salto de distncia.
Esse o terceiro mecanismo de proteo do eBGP apresentado at o momento:
1 estabelecer a sesso entre loopbacks;
2 Usar MD5;
3 Usar TTL-Security Check.
O TTL-Security Check pouco utilizado, mas extremamente util. No entanto, apenas
enviar o pacote com TTL 255 no suIiciente, tambm preciso conIigurar o vizinho. Caso isso
no ocorra, a sesso eBGP podera ser estabelecida por um link diIerente do correto, o que
diIicultara a deteco da origem de problemas.
Outro ponto importante, que em sesses entre loopbacks deve-se usar ttl-security
hops 2.
278
TTL-Security Check
Esse o terceiro mecanismo de proteo do eBGP apresentado at o
momento:
1 estabelecer a sesso entre loopbacks;
2 Usar MD5;
3 Usar TTL-Security Check.
O TTL-Security Check pouco utilizado, mas extremamente til.
Apenas enviar o pacote com TTL 255 no suficiente. Tambm
preciso configurar o vizinho.
a sesso eBGP poder ser estabelecida por um link diferente do
correto;
dificultar a deteco da origem de problemas.
Sesses entre loopbacks use ttl-security hops 2.
Em roteadores Cisco e Quagga, para utilizar IPv6 preciso especiIicar a Iamilia de
endereos com a qual se esta trabalhando. DiIerente dos roteadores Juniper, as conIiguraes do
BGP so apresentadas dividas em conIiguraes geais e nas conIiguraes especiIicas de cada
Iamilia para cada vizinho.
Para analisar as conIiguraes do aaaress-family IPv6 utiliza-se:
show running-config | begin address-family ipv6
address-family ipv6 indica a qual Iamilia pertence as conIiguraes;
neighbor 2001:DB8:200:FFFF::255 activate ativa a sesso,
necessario quando se trabalha com aaaress-family. Uma pratica boa a se aplicar
quando se conIigura uma sesso iBGP ou eBGP, levanta-la em shutaown. Isso evita
que se estabelea a sesso sem que as politicas estejam conIiguradas, no permitindo
que se envie inIormaes indevidas;
neighbor 2001:DB8:200:FFFF::255 soft-reconfiguration
inbound indica a Iorma que a tabela de rotas sera atualizada;
neighbor 2001:DB8:200:FFFF::255 prefix-list BGPout-IPv6-
AS64512 out indica a politica de saida aplicada;
neighbor 2001:DB8:200:FFFF::255 route-map BGPin-IPv6-
AS64512 in indica a politica de saida aplicada.
279
Configuraes do address-
family
Em roteadores Cisco e Quagga, para utilizar Pv6 preciso
especificar a famlia de endereos com a qual se est trabalhando.
Aplicar as configuraes especficas de cada famlia para cada
vizinho.
router-cisco# show running-config | begin address-family ipv6
address-family ipv6
neighbor 2001:DB8:21:FFFF::254 activate
neighbor 2001:DB8:21:FFFF::254 next-hop-self
neighbor 2001:DB8:21:FFFF::254 soft-reconfiguration inbound
neighbor 2001:DB8:21:FFFF::255 activate
neighbor 2001:DB8:21:FFFF::255 next-hop-self
neighbor 2001:DB8:21:FFFF::255 soft-reconfiguration inbound
neighbor 2001:DB8:200:FFFF::255 activate
neighbor 2001:DB8:200:FFFF::255 soft-reconfiguration inbound
neighbor 2001:DB8:200:FFFF::255 route-map BGPin-IPv6-AS64512 in
neighbor 2001:DB8:200:FFFF::255 route-map BGPout-IPv6-AS64512 out
network 2001:DB8:21::/48
network 2001:DB8:21:8000::/49
exit-address-family
Em relao as conIiguraes do iBGP destaca-se a seguinte inIormao:
neighbor 2001:DB8:21:FFFF::254 next-hop-self indica quem o
proximo salto. Esta conIigurao ajuda a trazer mais estabilidade e Iacilita na
operao dos ASs. Um roteador de borda pode repassar para os demais roteadores de
seu AS, via iBGP, todos os preIixos que ele aprender de seus ASs vizinhos. Quando
ele repassa para os demais roteadores, mantido o atributo next-hop. No entanto, o
next-hop desses preIixos sempre sera o roteador de borda dos ASs vizinhos, aos quais
os roteadores internos no possuem conectividade direta. Para solucionar esse
problema, o roteador de borda do AS repassa os anuncios inIormando que o next-hop
para os ASs vizinhos ele mesmo atravs do comando next-hop-self. Com
isso, os roteadores internos so precisam saber chegar no roteador de borda de seu AS,
que quem tem conectividade para a Internet.
Um exemplo de conIigurao do aaares-family IPv4 pode ser observado a seguir:
router-cisco# show running-config | begin address-family ipv4
address-family ipv4
neighbor 10.2.255.255 activate
neighbor 10.2.255.255 soft-reconfiguration inbound
neighbor 10.2.255.255 prefix-list BGPout-IPv4-AS64512 out
neighbor 10.2.255.255 route-map BGPin-IPv4-AS64512 in
neighbor 172.21.15.254 activate
neighbor 172.21.15.254 next-hop-self
neighbor 172.21.15.254 soft-reconfiguration inbound
neighbor 172.21.15.255 activate
neighbor 172.21.15.255 next-hop-self
neighbor 172.21.15.255 soft-reconfiguration inbound
network 172.21.0.0 mask 255.255.240.0
network 172.21.8.0 mask 255.255.248.0
exit-address-family
281
Configuraes do address-
family
Soft-Reconfiguration Inbound
Um comando interessante o soft-reconfiguration inbound. Analise o
seguinte exemplo:
O roteador R1 levanta uma sesso BGP com o roteador R2;
Quando a sesso estabelecida, o roteador envia todas as inIormaes que ele
conhece;
Novas inIormaes so sero enviadas quando houver a necessidade de se adicionar ou
retirar entradas da tabela;
Se Ior criada uma politica de entrada no R2, a mensagem original, trocada no
estabelecimento da sesso, sera alterada;
Caso seja necessario criar uma nova politica em R2, no se tera mais as inIormaes
iniciais para poder aplica-las;
282
Configuraes do address-
family
Soft-Reconfiguration Inbound
router-R13# clear bgp ipv6 unicast 2001:DB8:200:FFFF::255 soft in
Uma Iorma de se recuperar essas inIormaes seria 'derrubar a sesso, para que assim o
roteador mande novamente todos os seus preIixos. Essa pratica era Iuncional quando no havia
tantas entradas na tabela global de rotas. Hoje em dia ela no mais eIetiva.
Outra opo utilizar o comando soft-reconfiguration inbound. Com isso,
antes de se aplicar as politicas criada uma outra tabela de entrada por vizinho, exatamente igual
a recebida. Deste modo, tudo o que o R1 enviar, sera gravado nesta pr-tabela, salvando os
preIixos originais. Se Ior necessario alterar alguma conIigurao, basta utilizar, por exemplo, o
comando:
router-R13# clear bgp ipv6 unicast 2001:DB8:200:FFFF::255 soft in
Este comando Iaz com que o roteador re-leia a pr-tabela sem interromper a sesso. Porm,
isso tambm no Iuncional nos dias de hoje, porque a tabela BGP possui entorno de 300 mil
preIixos, e com esse comando duplica-se a tabela BGP para cada vizinho, consumindo muito mais
memoria do seu modulo de roteamento, na parte de controle.
Um exemplo de sua utilizao com IPv4 seria:
router-R13# clear bgp ipv4 unicast 10.2.255.255 soft in
Quando os roteadores iniciam uma sesso BGP, cada roteador passa uma srie de
inIormaes sobre os recursos que ele conhece, como: quais capabilities ele suporta. Uma delas
o route-refresh.
Este recurso permite recuperar as inIormaes originais da tabela de rotas sem 'derrubar a
sesso BGP e sem criar tabelas adicionais, apenas solicitando ao vizinho o reenvio da tabela de
rotas.
Para saber se o roteador suporta route-refresh um exemplo seria:
show ipv6 bgp neighbor 2001:DB8:200:FFFF::255
show ip bgp neighbor 10.2.255.255
Com este comando tambm possivel ver o suporta a outras capabilities como o suporte a
ASN de 32 bits (New ASN Capability).
283
Configuraes do address-
family
Route Refresh
Quando os roteadores iniciam uma sesso BGP, cada roteador
passa uma srie de informaes sobre os recursos que ele conhece,
como: quais capabilities ele suporta.
Uma delas o route-refresh.
Permite recuperar as informaes originais da tabela de rotas sem
derrubar a sesso BGP e sem criar tabelas adicionais.
Solicita ao vizinho o reenvio da tabela de rotas.
Para saber se o roteador suporta route-refresh use o comando:
show ipv6 bgp neighbor 2001:DB8:200:FFFF::255
Uma Iuno importante do BGP reside na manipulao dos atributos e nos testes
condicionais. Para tratar esses aspectos temos as seguintes Iuncionalidades:
route-map (Cisco e Quagga) deIine as condies para a redistribuio de rotas e
permite controlar e modiIicar inIormaes de politicas de roteamento;
prefix-list (Cisco e Quagga) mecanismo de Iiltragem de preIixos com muitos
recursos. Permite trabalhar com notao de preIixo, adicionar descrio e trabalhar
com sequencia, apresentando deste modo, uma vantagem em relao a utilizao da
Iuno aistribute-list, que por ser baseada em ACLs Iacilita a Iiltragem de pacotes,
porm, torna-se de diIicil gerenciamento;
route-filter (Juniper) utilizado para comparar rotas individualmente ou em grupos.
284
PoIticas de Roteamento
Uma funo importante do BGP est associada manipulao dos
atributos e os testes condicionais:
Cisco
route-map define as condies para a redistribuio de
rotas e permite controlar e modificar informaes de polticas
de roteamento;
prefix-list mecanismo de filtragem de prefixos muito
poderoso. Permite trabalhar com notao de prefixo,
adicionar descrio e trabalhar com sequencia;
Juniper
route-filter utilizado para comparar rotas individualmente ou
em grupos.
O BGP um protocolo usado na comunicao entre os ASs. Por isso, o AS-PATH torna-se
um atributo Iundamental do BGP. Ele consiste no ASN das redes pelas quais o pacote passara at
chegar ao destino.
Os roteadores Cisco, Quaga e Juniper oIerecem comandos que permitem a analise do AS-
PATH com expresses regulares. Em nosso exemplo, temos os seguintes termos nas expresses
regulares:
O caractere 'ponto signiIica 'qualquer elemento'
O caractere 'asterisco signiIica 'zero ou varias ocorrncias'
O caractere '$ signiIica 'Iim de linha'
O caractere ' signiIica 'uma ou mais ocorrncias'
ip as-path access-list 32 permit .* (Cisco / Quagga)
as-path ALL .*; (Juniper)
As linhas acima indicam que qualquer AS-PATH sera permitido.
ip as-path access-list 69 deny .* (Cisco / Quagga)
Esta linha indica que qualquer bloco sera negado.
ip as-path access-list 300 permit (_64513)+$ (Cisco / Quagga)
as-path AS64513 ".*( 64513)+$"; (Juniper)
Essas linhas indicam que todos os preIixos originados no AS 64513 sero
permitidos. A permisso de uma ou mais ocorrncias para garantir AS Path
prepenas, ou seja, repeties de um mesmo ASN em sequencia ao longo do AS-
PATH (no caso, o ASN 64513).
AnIise do AS-PATH
AS-PATH - Atributo fundamental do BGP. Consiste no ASN das redes
pelas quais o pacote passar at chegar ao destino.
Anlise do AS-PATH com expresses regulares:
Cisco / Quagga
Juniper
as-path ALL .*;
as-path AS64513 ".*( 64513)+$";
ip as-path access-list 32 permit .*
ip as-path access-list 69 deny .*
ip as-path access-list 300 permit (_64513)+$
286
EstabeIecendo FiItros
Poltica de entrada
Cisco
Juniper
ipv6 prefix-list BGPin-IPv6-AS64513 description Prefixos Preferidos do AS64513
ipv6 prefix-list BGPin-IPv6-AS64513 seq 10 permit 2001:DB8:300:8000::/49
policy-statement BGPin-IPv6-AS64513 {
term term-1 {
from {
route-filter 2001:db8:300::/49 exact;
}
then accept;
}
term implicit-deny {
then reject;
}
}
Este exemplo mostra atravs de um prefix-list em um roteador Cisco e um route-filter em
um roteador Juniper, o estabelecimento de uma politica de entrada.
No exemplo do roteador Cisco, o prefix-list identiIica o segunda /49 do AS 64513 que sera
recebido.
ipv6 prefix-list BGPin-IPv6-AS64513 seq 10 permit
2001:DB8:300:8000::/49
No exemplo do roteador Juniper, o route-filter identiIica o primeiro /49 do AS 64513 que
sera recebido.
route-filter 2001:db8:300::/49 exact;
Um exemplo da implantao dessas politicas em uma conIigurao IPv4 seria:
Cisco: ip prefix-list BGPin-IPv6-AS64513 seq 10 permit
10.3.128.0/17
Juniper: route-filter 10.3.0.0/17 exact;
287
EstabeIecendo FiItros
Poltica de sada
Cisco
Juniper
ipv6 prefix-list BGPout-IPv6-AS64512 description Prefixos para AS64512
ipv6 prefix-list BGPout-IPv6-AS64512 seq 10 permit 2001:DB8:21::/48
ipv6 prefix-list BGPout-IPv6-AS64512 seq 20 permit 2001:DB8:21:8000::/49
policy-statement BGPout-IPv6-AS64511 {
term term-1 {
from {
route-filter 2001:db8:21::/48 exact;
route-filter 2001:db8:21::/49 exact;
}
then accept;
}
term implicit-deny {
then reject;
}
}
Este exemplo mostra atravs de prefix-list em um roteador Cisco e de route-filter em um
roteador Juniper, o estabelecimento de uma politica de saida.
No exemplo do roteador Cisco, os prefix-list indicam os preIixos que sero anunciados
para o AS64512. Neste caso sero enviados o preIixo /48 IPv6 e segundo /49.
No exemplo do roteador Juniper, os route-filter indicam que sero anunciados para o AS
64511 o preIixo /48 IPv6 e o primeiro /49.
Um exemplo dessa politica de saida em uma conIigurao IPv4 poderia ser:
Cisco
ip prefix-list BGPout-IPv4-AS64512 seq 10 permit 172.21.0.0/20
ip prefix-list BGPout-IPv4-AS64512 seq 20 permit 172.21.8.0/21
Juniper
route-filter 172.21.0.0/20 exact;
route-filter 172.21.0.0/21 exact;
288
EstabeIecendo FiItros
Filtros de proteo
Cisco
ipv6 prefix-list IPv6-block-deny description Prefixos Gerais Bloqueados
ipv6 prefix-list IPv6-block-deny seq 10 permit 0::/0 le 128
ipv6 prefix-list IPv6-block-deny seq 20 permit 0000::/8 le 128
ipv6 prefix-list IPv6-block-deny seq 30 permit 3ffe::/16 le 128
ipv6 prefix-list IPv6-block-deny seq 40 permit 2001:db8::/32 le 128
ipv6 prefix-list IPv6-block-deny seq 50 permit 2001::/32 le 128
ipv6 prefix-list IPv6-block-deny seq 60 permit 2002::/16 le 128
ipv6 prefix-list IPv6-block-deny seq 70 permit fe00::/9 le 128
ipv6 prefix-list IPv6-block-deny seq 80 permit ff00::/8 le 128
Tambm possivel adicionar prefix-list de proteo. Observe o seguinte exemplo em um
roteador Cisco:
ipv6 prefix-list IPv6-block-deny seq 10 permit 0::/0 le 128
ipv6 prefix-list IPv6-block-deny seq 20 permit 0000::/8 le 128
ipv6 prefix-list IPv6-block-deny seq 30 permit 3ffe::/16 le 128
ipv6 prefix-list IPv6-block-deny seq 40 permit 2001:db8::/32 le 128
ipv6 prefix-list IPv6-block-deny seq 50 permit 2001::/32 le 128
ipv6 prefix-list IPv6-block-deny seq 60 permit 2002::/16 le 128
ipv6 prefix-list IPv6-block-deny seq 70 permit fe00::/9 le 128
ipv6 prefix-list IPv6-block-deny seq 80 permit ff00::/8 le 128
Estes prefix-list veriIicam respectivamente:
- A rota aefault,
- O primeiro preIixo /8;
- Endereox da rede de testes 6bone;
- Endereos para documentao;
- Endereos dos tuneis Teredo;
- Endereos dos tuneis 6to4;
- Endereos Link-local (RFC 5735);
- Endereos Multicast.
289
Um exemplo da aplicao de um prefix-list de proteo para IPv4 poderia ser:
ip prefix-list IPv4-block-deny seq 10 permit 0.0.0.0/0
ip prefix-list IPv4-block-deny seq 20 permit 0.0.0.0/8
ip prefix-list IPv4-block-deny seq 30 permit 127.0.0.0/8
ip prefix-list IPv4-block-deny seq 40 permit 169.254.0.0/16
ip prefix-list IPv4-block-deny seq 50 permit 192.0.2.0/24
ip prefix-list IPv4-block-deny seq 60 permit 10.0.0.0/8
ip prefix-list IPv4-block-deny seq 60 permit 172.16.0.0/12
ip prefix-list IPv4-block-deny seq 80 permit 192.168.0.0/16
Estas prefix-list veriIicam respectivamente:
- A rota aefault,
- O primeiro preIixo /8;
- O endereo de loopback;
- Endereos Link-local (RFC 5735);
- Endereos da TEST-NET-1 (RFC 5737);
- Endereos privados (RFC 1918).
290
EstabeIecendo FiItros
Filtros de proteo
Juniper
policy-statement IPv6-block-deny {
term term-1 {
from {
route-filter 0::/0 orlonger;
route-filter 0000::/8 orlonger;
route-filter 3ffe::/16 orlonger;
route-filter 2001:db8::/32 orlonger;
route-filter 2001::/32 longer;
route-filter 2002::/16 longer;
route-filter fe00::/9 orlonger;
route-filter ff00::/8 orlonger;
}
then accept;
}
term implicit-deny {
then reject;
}
}
Tambm possivel adicionar route-fiter de proteo. Observe o seguinte exemplo em um
roteador Juniper:
route-filter 0::/0 orlonger;
route-filter 0000::/8 orlonger;
route-filter 3ffe::/16 orlonger;
route-filter 2001:db8::/32 orlonger;
route-filter 2001::/32 longer;
route-filter 2002::/16 longer;
route-filter fe00::/9 orlonger;
route-filter ff00::/8 orlonger;
Estes route-fiters realizam as mesmas veriIicaes apresentadas no exemplo anterior de
roteadores Cisco.
Um exemplo da aplicao de um prefix-list de proteo para IPv4 poderia ser:
route-filter 0.0.0.0/0 exact;
route-filter 0.0.0.0/8 exact;
route-filter 127.0.0.0/8 exact;
route-filter 169.254.0.0/16 exact;
route-filter 192.0.2.0/24 exact;
route-filter 10.0.0.0/8 exact;
route-filter 172.16.0.0/12 exact;
route-filter 192.168.0.0/16 exact;
Mias inIormaes:
http://www.space.net/~gert/RIPE/ipv6-Iilters.html
291
291
EstabeIecendo FiItros
Filtros de proteo
Cisco
Juniper
ipv6 prefix-list IPv6-IPv6-AS64501-all description Todos Blocos IPv6
ipv6 prefix-list IPv6-IPv6-AS64501-all seq 10 permit 2001:DB8:21::/48 le 128
policy-statement IPv6-IPv6-AS64501-all {
term term-1 {
from {
route-filter 2001:db8:21::/48 orlonger;
}
then accept;
}
term implicit-deny {
then reject;
}
}
Outra politica de proteo importante a que impede que o AS receba anuncios de seus proprios
preIixos.
Para IPv6 poderiamos ter algo similar a:
- Cisco/Quagga
ipv6 prefix-list IPv6-IPv6-AS64501-all seq 10 permit 2001:DB8:21::/48 le 128
- Juniper
route-filter 2001:db8:21::/48 orlonger;
Para IPv4 poderiamos ter algo similar a:
Cisco / Quagga
ip prefix-list IPv4-AS64501-all seq 10 permit 172.21.0.0/20 le 32
Juniper
route-filter 172.21.0.0/20 orlonger;
As regras exempliIicadas acima indicam todos os preIixos possiveis dentro de um bloco /48 IPv6
ou /20 IPv4. Elas sero utilizadas na politica de entrada, para dizer: 'no aceito nenhum preIixo que seja
meu. Isso ajuda a evitar problemas como sequestro de preIixos.
Por padro, o roteador rejeita todos os preIixos que tenha o seu ASN, para evitar looping. Porm,
nada impede que outro AS na Internet, por intenso ou erro, gere anuncios do outro preIixo, at um mais
especiIico. Se no houver proteo, o roteador vai aceitar e encaminhar todo o traIego interno para Iora.
292
Um exemplo deste tipo de ocorrncia Ioio sequestro do preIixo do YouTube. Por
determinao do Governo Paquistans, o traIego do YouTube deveria ser bloqueado para evitar o
acesso ao trailer de um Iilme anti-Islamico. Para cumprir essa ordem, a operadora Pakistan
Telecom gerou o anuncio de um preIixo mais especiIico do que o utilizado pelo YouTube, com o
intuito de direcionar todos os acessos a ele para uma pagina que dizia 'YouTube was blocked.
No entanto, a operadora anunciou essa nova rota a seu upstream proviaer (primeiro erro),
que, alm de no veriIicar a nova rota (segundo erro) a propagou por toda a Internet (terceiro
erro). Com isso, todo o traIego do YouTube passou a ser direcionado para o Paquisto e ser
descartado.
Esse Ioi apenas o caso mais Iamoso, mas sequestros de blocos IP ocorrem diariamente,
intencionalmente ou no. Isso ocorre porque toda a estrutura da Internet e o Iuncionamento do
BGP Ioram deIinidos baseados em uma relao de conIiana. Essa 'inocncia ainda presente e
o que mantem toda a estrutura atual.
Existem discusses sobre modos de veriIicar se o AS que esta anunciando um determinado
preIixo tem autoridade para Iaze-lo, similar ao ao que o DNSSec Iaz.
Mais inIormaes:
http://www.ietI.org/dyn/wg/charter/idr-charter.html
http://www.ietI.org/dyn/wg/charter/sidr-charter.html
http://www.youtube.com/watch?vIzLPKuAOe50
http://www.wired.com/threatlevel/2008/02/pakistans-accid/
293
293
ApIicando FiItros
Poltica de entrada
Cisco
route-map BGPin-IPv6-AS64512 deny 10
match ipv6 address prefix-list IPv6-AS64501-all
!
route-map BGPin-IPv6-AS64512 deny 20
match ipv6 address prefix-list IPv6-block-deny
!
route-map BGPin-IPv6-AS64512 permit 30
match ipv6 address prefix-list BGPin-IPv6-AS64513
match as-path 300
set local-preference 150
!
route-map BGPin-IPv6-AS64512 permit 40
match as-path 32
Apos serem estabelecidas as condies dos Iiltros via prefix-list nos roteadores Cisco,
deve-se aplica-las atravs de route-maps.
Ex.:
route-map BGPin-IPv6-AS64512 deny 10
match ip address prefix-list IPv6-AS64501-all
!
route-map BGPin-IPv6-AS64512 deny 20
match ip address prefix-list IPv6-block-deny
!
route-map BGPin-IPv6-AS64512 permit 30
match ip address prefix-list BGPin-IPv6-AS64513
match as-path 300
set local-preference 150
!
route-map BGPin-IPv6-AS64512 permit 40
match as-path 32
Esse o route-map de entrada. Ele possui um nome para identiIicao de sua Iuno, pois
possivel ter varios route-maps. Neste exemplo, ele indica como tratar o que sera recebido do AS
64512. Ha 4 regras, a 10, 20, 30 e a 40.
Os route-maps trabalham com testes logicos de 'e e 'ou, onde cada preIixo passa pelo
route-map, e se a comparao entre a regra estabelecida e o preIixo coincidirem, ele processado
e a comparao encerrada. Se a comparao no coincidir, a regra seguinte sera analisada. Ou
seja, cada regra um teste 'ou.
A terceira regra possui dois testes de comparao. Quando ha dois ou mais teste na mesma
regra, equivalente a condio 'e. Com isso, a terceira regra diz que tem que coincidir na
primeira e na segunda linha.
O modo de Iuncionamento dos route-map independente se a conIigurao de uma
sesso IPv4 ou IPv6.
294
A primeira regra descarta todos os preIixos que coincidirem com o que Ioi estabelecido no
prefix-list IPv6-AS64501-all, que representa todos os preIixos do proprio AS. E a
regra que protege do sequestro de blocos.
A segunda regra descarta os blocos de uso privado especiIicados no prefix-list
IPv6-block-deny.
A terceira regra onde sera alterado o LOCALPREFERENCE. Ela veriIica de qual AS
vem o preIixo (as-path 300) e se o preIixo esperado (prefix-list BGPin-IPv6-
AS64513). Se coincidir com as duas condies, o valor do LOCALPREFERENCE aumentado
para 150. O valor padro do LOCALPREFERENCE 100 e, quanto maior seu valor, maior a
preIerncia.
A ultima regra permite tudo, o as-path 32 cuja regra permit .*, ou seja, sero
permitidos todos os outros preIixos que no Ioram tratados, o que representa a tabela completa.
Essa ultima regra necessaria porque normalmente ha um 'aeny implicito para todo preIixo que
no tiver Ieito match com nenhuma regra anterior.
295
295
ApIicando FiItros
Poltica de entrada
Juniper
policy-statement nh-BGPin-IPv6-AS64511 {
term term-1 {
from policy IPv6-AS64501-all;
then reject;
}
term term-2 {
from policy IPv6-block-deny;
then reject;
}
term term-3 {
from {
as-path AS64513;
policy BGPin-IPv6-AS64513;
}
then {
local-preference 150;
next term;
}
}
term accept {
then accept;
}
}
A politica implementada no roteador Juniper similar a do roteador Cisco apresentada
anteriormente. A principal diIerena que as politicas so aplicadas aos anuncios recebidos do AS
64511.
Ex.:
policy-statement nh-BGPin-IPv6-AS64511 {
term term-1 {
from policy IPv6-AS64501-all;
then reject;
}
term term-2 {
from policy IPv6-block-deny;
then reject;
}
term term-3 {
from {
as-path AS64513-IPv4;
policy BGPin-IPv6-AS64513;
}
then {
local-preference 150;
next term;
}
}
term accept {
then accept;
}
}
296
296
ApIicando FiItros
Poltica de sada
Cisco
Juniper
route-map BGPout-IPv6-AS64512 permit 10
match ipv6 address prefix-list BGPout-IPv6-AS64512
policy-statement nh-BGPout-IPv6-AS64511 {
term term-1 {
from policy BGPout-IPv6-AS64511;
then accept;
}
term implicit-deny {
then reject;
}
}
Do mesmo modo como Ioram aplicadas as politicas de entrada, podemos aplicar as
politicas de saida atravs de um route-map e de um policy-statement no Juniper. Os
prefixes-list e os route-filters aplicados nas politicas de saida podem ser analisadas
no slide 287.
297
297
Looking GIass
importante verificar atravs de Looking Glasses remotos como as
operadoras e toda a nternet recebem os anncios do AS.
Cisco
bgpd-R01> show bgp regexp _64501$
BGP table version is 0, local router ID is 10.3.255.255
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, R Removed
Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path
* 2001:db8:21::/48 2001:db8:300:11::2 0 64511 64501 i
*> 2001:db8:300:12::2 0 64512 64501 i
* 2001:db8:21::/49 2001:db8:300:11::2 0 64511 64512 64501 i
*> 2001:db8:300:12::2 0 64512 64501 i
* 2001:db8:21:8000::/49
2001:db8:300:12::2 0 64512 64511 64501 i
*> 2001:db8:300:11::2 0 64511 64501 i
Total number of prefixes 3
E importante veriIicar atravs de Looking Glasses remotos como as operadoras e toda a
Internet recebem os anuncios do AS. Deste modo, possivel veriIicar tambm, se suas politicas de
roteamento Ioram bem aplicadas.
Com o Looking Glass, possivel consultar como os preIixos de um AS, IPv4 e IPv6, esto
sendo aprendidos pela Internet, ou seja, como os ASs conseguem chegar at a sua rede.
Ex.:
show bgp regexp _64501$ (Cisco / Quagga)
Neste exemplo, em um roteador Cisco, podemos observar como cada preIixo anunciado
pelo AS 64501 Ioi aprendido. Nesta expresso regular, o '$ signiIica que a origem (inicio de
linha), e o ' signiIica espao, ou seja, o comando aplicado para todo preIixo que tem o AS
64501 como origem no AS-PATH.
Na resposta a consulta podemos observar o balanceamento do traIego, pois o bloco /48 Ioi
dividido em dois preIixos /49 permitindo que metade do traIego saia por um link e a outra metade
saia por outro link, e tambm a redundncia das rotas, pois alm dos preIixos /49 o preIixo /48
tambm esta sendo anunciado pelos dois links.
298
298
Looking GIass
Juniper
juniper@R11> show route table inet6.0 aspath-regex .64513$
inet6.0: 59 destinations, 84 routes (59 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
2001:db8:300::/48 *[BGP/170] 01:44:51, localpref 100
AS path: 64511 64513 I
> to 2001:db8:100:1::1 via ge-0/0/0.2105
[BGP/170] 01:44:13, MED 0, localpref 100, from 2001:db8:21:ffff::252
AS path: 64512 64513 I
> to fe80::224:97ff:fec1:c8bd via ge-0/0/0.2101
2001:db8:300::/49 *[BGP/170] 01:44:13, MED 0, localpref 150, from 2001:db8:21:ffff::252
AS path: 64512 64513 I
> to fe80::224:97ff:fec1:c8bd via ge-0/0/0.2101
[BGP/170] 01:44:51, localpref 100
AS path: 64511 64513 I
> to 2001:db8:100:1::1 via ge-0/0/0.2105
2001:db8:300:8000::/49
*[BGP/170] 01:44:51, localpref 150
AS path: 64511 64513 I
> to 2001:db8:100:1::1 via ge-0/0/0.2105
Neste exemplo podemos observar, em um roteador Juniper, como os preIixo anunciado
pelo AS64513 Ioram aprendidos pelo AS64501. A expresso regular utilizada similar a vista no
exemplo anterior utilizando roteadores Cisco.
Na resposta a consulta podemos observar o balanceamento do traIego e tambm a
redundncia das rotas, assim como no exemplo anterior, alm de inIormaes como: melhor rota,
indicado pelo asterisco; caminho at o destino (AS path); proximo salto; e interIace de saida do
pacote.
299
299
300
Apos conhecermos um pouco sobre o Iuncionamento e os novos recursos do protocolo
IPv6, discutiremos neste modulo alguns conceitos importantes que precisam ser estudados na hora
de implantar IPv6 nas grandes redes de computadores. Devemos compreender todos os aspectos
que envolvem a implantao do IPv6 principalmente em redes corporativas, como analise de
custos, troca de material e treinamento.
300
PIanejamento
MduIo 10
301
301
A deciso pela adoo do protocolo Pv6 gera muitas questes
Pv6 realmente necessrio?
Quando o Pv6 ser necessrio?
H alternativas viveis ao Pv6?
A transio deve ser feita de uma nica vez ou gradualmente?
Como tornar as aplicaes e servios compatveis com o novo
protocolo?
Como tirar vantagem das novas funcionalidades do Pv6?
Com quais aspectos devem ser avaliados alm da segurana?
Como se planejar para essa transio?
Qual ser o custo da implantao?
PIanejamento
Conceitos Importantes:
A troca de protocolo tem um carater estrutural;
Esta mudana no ocorrera apenas porque o protocolo IPv6 apresenta melhorias em
relao ao seu antecessor;
A implantao do IPv6 necessaria e inevitavel;
O esgotamento dos endereos IPv4 no Iara a Internet acabar, nem mesmo que ela
deixe de Iuncionar;
Mas deve haver uma diminuio na taxa de crescimento da rede e diIiculdades no
desenvolvimento de novas aplicaes;
Todos esses problemas podem ser evitados com a adoo do IPv6 antes do trmino do
IPv4;
A implantao do IPv6 no sera algo rapido;
No havera uma 'data da virada para a troca de protocolo;
A migrao do IPv4 para IPv6 acontecera de Iorma gradual, com o IPv4 ainda em
Iuncionamento;
E importante que as redes estejam preparadas para o novo protocolo desde ja. Quanto
mais cedo a questo Ior entendida, e a implantao planejada, menores sero os gastos
no processo.
302
302
importante que tcnicos e administradores de redes busquem
adquirir conhecimento sobre a nova tecnologia;
Cursos;
Livros;
Stios nternet;
Documentos tcnicos;
Fruns;
Eventos.
Este primeiro passo ser essencial para a elaborao das
prximas fases.
Primeiro Passo: Treinamento
O RIPE NCC disponibiliza alguns videos sobre 'cases IPv6 que podem servir como Ionte
de conhecimento muito interessante. Esses videos esto no canal ripencc do youtube:
www.youtube.com/ripencc, e alguns tm legendas em portugus:
Randy Bush (Internet Initiative Japan Inc.) - http://www.youtube.com/watch?vQh3i6lDqWBM
Lorenzo Colitti (Google) - http://www.youtube.com/watch?vvFwStbTpr6E
Marco Hogewoning (Dutch ISP XS4ALL) - http://www.youtube.com/watch?vI3WcWBIQ11A
Andy Davidson (NetSumo ISP Consultancy) - http://www.youtube.com/watch?vQCcigLJJbvU
David Freedman (Claranet) - http://www.youtube.com/watch?vHQtbz1ahRxE
303
303
Como o Pv6 pode afetar os negcios:
Novas aplicaes;
Novas oportunidades;
Novos servios.
Como obter conexo;
Que tipo de conexo oferecer aos clientes;
Pv6 nativo;
Tneis.
Quais servios internos sero migrados inicialmente;
Entender esses aspectos essencial para otimizar o retorno dos
investimentos.
O impacto do IPv6
304
304
Minimizar os custos da implantao.
Custo Relativo em um SP*:
Com equipamentos (15%)
Roteadores - Mdio;
Firewalls - Mdio.
Com softwares (15%)
Softwares de gerenciamento e monitoramento de redes - Alto;
SOs - Mdio.
Mo-de-obra (70%)
Pesquisa e desenvolvimento - Baixo;
Treinamento - Alto;
mplementao - Alto;
Manuteno Mdio/Alto;
Problemas de interoperabilidade - Mdio/Alto.
O impacto do IPv6
*Fonte: U.S. DEPARTMENT OF COMMERCE
305
305
Gerentes/Gestores/Diretores
X
Tcnicos/Engenheiros
Voc pode convencer os gestores de sua empresa?
Vamos trabalhar em grupos...
10 min preparao
10 min apresentao e discusso
Exerccio
Engenheiros x Gerentes
306
306
Gerentes:
No querem investir agora em Pv6
Tcnicos:
Querem convencer os gerentes a agir agora
Pontos para pensar:
Capacidade do hardware
Prioridades de negcio
Conhecimento existente / Treinamento
Clientes
Legislao
Custo
Timing
Troca de Trfego
Exerccio
Engenheiros x Gerentes
Este exercicio Ioi aplicado no treinamento IPv6 oIerecido pelo RIPE a provedores
europeus. Algumas respostas apresentadas Ioram:
Tcnicos:
Um cliente pediu!
Dispositivos moveis
Nosso equipamento ja suporta
Se Iizermos agora, podemos investir gradualmente
Obter a alocao agora um investimento, muito espao, nenhum custo
Ha varias oportunidades de treinamento
V6 a unica opo para crescermos
V6 Iacil, no so necessarios muitos recursos
Compare o preo de Iazer agora, com o de deixar pra depois
Gerentes:
Vai custar muito, vamos precisar de 20 a mais no oramento
No teremos clientes para isso
Antes precisamos auditar o equipamento
Precisamos de um plano, em Iases
Os equipamentos podem ter v6 mas no tem paridade nas Iuncionalidades
Temos equipamentos e soItwares obsoletos
Empresas que se preocupam com segurana no querem v6 agora, porque hardware e
soItware no esto maduros
Por que temos que mudar?
Como voc pode garantir que o v4 vai acabar mesmo?
307
307
Nenhum problema nos prximos anos
Com o passar do tempo, algumas pessoas no podero fazer uso
de seus servios
Nenhum custo extra
At batermos no muro!
Custos altos para uma implantao rpida
Tempos de planejamento curtos, implicam em mais erros...
Cenrio: Fazer nada!
308
308
Talvez o hardware tenha de ser trocado
nvestimento alto em tempo e outros recursos
Sem retorno imediato
Altos custos para uma implantao rpida
Planejamento rpido significa mais possibilidade de erros...
Cenrio: Fazer tudo agora!
309
309
Defina metas e prazos a serem cumpridos.
dentifique quais reas e servios sero afetados.
Procedimento de compra
Paridade de funcionalidades
Verifique seu hardware e software
Aplicaes ou sistemas que no sero atualizados;
Servios crticos.
Faa testes
Um servio de cada vez:
Face primeiro
Core
Clientes
Prepare-se para desligar o Pv4
Cenrio: Comece agora,
faa em etapas
310
310
Desenvolva um plano de endereamento
Obtenha os endereos
Anuncie-os
Web
DNS autoritativo
Servidores de email
etc.
Face primeiro
311
311
Todos os RRs j distribuem endereos Pv6 em suas regies.
Preencha o formulrio em:
http://registro.br/info/pedido-form.txt
Enviar por email: numeracao-pedido@registro.br
Receber um ticket, ou uma mensagem indicando erros de
preenchimento
Quem tem Pv4 certamente justifica Pv6
Gratuito, por hora
2 semanas entre anlise e aprovao
Dvidas: numeracao@registro.br
Obtendo um prefixo IPv6
312
312
No separe as funcionalidades v6 do v4
No faa tudo de uma vez
No indique um guru Pv6 para sua organizao
Voc tem um especialista v4?
No veja o Pv6 como um produto
O produto a nternet, ou o acesso/contedos nternet.
Nos
313
313
O Pv4 no mais igual a nternet
Evitar o problema no far ele desaparecer
Quanto voc est disposto a gastar agora, para economizar dinheiro
depois?
Somente o Pv6 permitir o crescimento contnuo da rede
Comece agora!
Consideraes
314
BIBLIOGRAFIA
Migrating to IPv6 : A Practical Guide to Implementing IPv6 in Mobile and Fixed Networks .
Autor: Marc Blanchet.
6 Net: An IPv6 Deployment Guide.
Autor: Martin Dunmore.
IPv6 Essentials.
Autor: Silvia Hagem.
Global IPv6 Strategies.
Autores: Patric Grossetete; Ciprian popovicius; Fred Wetting.
Planning and Accomplishing the IPv6 Integration: Lessons Learned Irom a Global Construction
and Project-Management Company .
Autor: Cisco Public InIormation.
Technical and Economic Assessment oI Internet Protocol Version 6.
Autor: U.S. DEPARTMENT OF COMMERCE.
Introduccion a IPv6.
Autor: Roque Gagliano.
PlaniIicando IPv6.
Autor: Roque Gagliano.
Deliverable D 6.2.4: Final report on IPv6 management tools, developments and tests.
Autor: 6 Net.
IPv6 Security: Are You Ready? You Better Be!
Autor: Joe Klein.
IPv6 and IPv4 Threat Comparison and Best- Practice Evaluation (v1.0)
Autores: Sean Convery; Darrin Miller.
BGP Routing Table Analysis Reports - http://bgp.potaroo.net/
Autores: Tony Bates; Philip Smith; GeoII Huston.
Measuring IPv6 Deployment
Autores: GeoII Huston; George Michaelson.
IPv6 at Google.
Autores: Angus Lees; Steinar H. Gunderson.
Resumo do Barmetro Cisco Banda Larga Brasil 2005-2010
Autores: Mauro Peres; Joo Paulo Bruder.
Tracking the IPv6 Migration. Global Insights From the Largest Study to Date on IPv6 TraIIic on
the Internet.
Autor: Craig Labovitz.
ICE: Uma soluo geral para a travessia de NAT
Autor: Jos Henrique de Oliveira Varanda
315
BIBLIOGRAFIA
TIC Domicilios e Usuarios Total Brasil - http://cetic.br/usuarios/tic/2008-total-brasil/index.htm
Autor: CETIC.br.
IPv6.br - http://ipv6.br
Autor: CEPTRO.br.
IPv6 Deployment and Support - http://www.6deploy.org
Autor: 6Deploy.
World Internet Usage Statistics News and World Population Stats -
http://www.internetworldstats.com/stats.htm
Autor: Internet World Stats.
Barmetro BRASIL - http://www.cisco.com/web/BR/barometro/barometro.html
Autor: Cisco Systems.
The ISC Domain Survey - https://www.isc.org/solutions/survey
Autor: Internet Systems Consortium.
Number Resource Organization Statistics - http://www.nro.net/statistics
Autor: Number Resource Organization (NRO).
Trick Or Treat Daemon (TOTD) - DNS-proxy Ior IPv4/IPv6 translation -
http://mucc.mahidol.ac.th/~ccvvs/totd-setup.html
Autor: Vasaka Visoottiviseth
Routing TCP/IP
Autor: JeII Doyle,JenniIer DeHaven Carroll
O Protocolo BGP4 - Parte 3 (Final) - http://www.rnp.br/newsgen/9907/pgbp4p3.html
Autor: RNP Rede Nacional de Ensino e Pesquisa
Você também pode gostar
- Curso IPv6 Básico: Introdução à nova geração do Protocolo InternetDocumento231 páginasCurso IPv6 Básico: Introdução à nova geração do Protocolo InternetmaxAinda não há avaliações
- Ipv4 - Ipv6Documento26 páginasIpv4 - Ipv6frances1967Ainda não há avaliações
- CCNA 640-801 PT/BR Simulado e RecomendaçõesDocumento150 páginasCCNA 640-801 PT/BR Simulado e RecomendaçõesBaroni AtlantisAinda não há avaliações
- IPv6 endereços tiposDocumento2 páginasIPv6 endereços tiposLuis Daniel MalundoAinda não há avaliações
- The DudeDocumento26 páginasThe DudeIsaac Costa0% (1)
- Apostila de Simbologia de Cabeamento Estruturado - AnhangueraDocumento43 páginasApostila de Simbologia de Cabeamento Estruturado - AnhangueraRafael SalvagniAinda não há avaliações
- JoiroNet - Lab - MPLS Básica Com GNS3 PDFDocumento6 páginasJoiroNet - Lab - MPLS Básica Com GNS3 PDFfilipecnAinda não há avaliações
- MPLS II: Aplicações e benefícios da tecnologiaDocumento17 páginasMPLS II: Aplicações e benefícios da tecnologiaEber SantanaAinda não há avaliações
- Modelo Memorial Descritivo - RedesDocumento7 páginasModelo Memorial Descritivo - RedesDaniel LauerAinda não há avaliações
- Config UbiquitiDocumento10 páginasConfig UbiquitiFelipe Brito SilvaAinda não há avaliações
- Intro IPv6Documento50 páginasIntro IPv6Cairo GonçalvesAinda não há avaliações
- IEEE 802 É Um Conjunto de Padrões Desenvolvidos Pelo IEEEDocumento5 páginasIEEE 802 É Um Conjunto de Padrões Desenvolvidos Pelo IEEEHenrique FerreiraAinda não há avaliações
- Tipos de RoteamentoDocumento4 páginasTipos de RoteamentoDaniella CostaAinda não há avaliações
- Instalação de Patch PanelDocumento14 páginasInstalação de Patch PanelJeferson PresottoAinda não há avaliações
- Apostila Ipv6 OnlineDocumento67 páginasApostila Ipv6 OnlineRodrigo AguilarAinda não há avaliações
- Entendendo o BackboneDocumento16 páginasEntendendo o BackboneElisangela Valeriano LucasAinda não há avaliações
- O Que É Uma WANDocumento9 páginasO Que É Uma WANMauro LucioAinda não há avaliações
- Protocolos de Roteamento Dinâmico OSPFDocumento5 páginasProtocolos de Roteamento Dinâmico OSPFPaulo CardosoAinda não há avaliações
- Configuração de Rede IPv6Documento51 páginasConfiguração de Rede IPv6Jobson100% (1)
- (AULA 05) VoIP e MPLSDocumento65 páginas(AULA 05) VoIP e MPLSPaulo Dembi100% (1)
- Prova6 RespDocumento11 páginasProva6 ResptguazzelliAinda não há avaliações
- Cablagem estruturada e normas de redeDocumento15 páginasCablagem estruturada e normas de redefsemineloAinda não há avaliações
- MF 102 PDFDocumento75 páginasMF 102 PDFSidneyAinda não há avaliações
- 4.1.4.6 - Laboratorio TRADUÇÃODocumento11 páginas4.1.4.6 - Laboratorio TRADUÇÃOUgs nguAinda não há avaliações
- Uma Rápida Explicação Do Modelo OSI - Redes, Guia Prático 2 EdDocumento4 páginasUma Rápida Explicação Do Modelo OSI - Redes, Guia Prático 2 EdFabio RodriguesAinda não há avaliações
- 3.3.2.7 Packet Tracer - WEP WPA2 PSK WPA2 RADIUSDocumento4 páginas3.3.2.7 Packet Tracer - WEP WPA2 PSK WPA2 RADIUSKelson AlmeidaAinda não há avaliações
- Guia oficial de capacitação em MPLSDocumento118 páginasGuia oficial de capacitação em MPLSPedro MarangaoAinda não há avaliações
- Atividade CiscoDocumento10 páginasAtividade CiscocentauroAinda não há avaliações
- Teste Pratico RedesDocumento6 páginasTeste Pratico RedesAnderson MonteiroAinda não há avaliações
- Enderecamento IPDocumento23 páginasEnderecamento IPHenrique Vital Leme100% (1)
- Fundamentos de Redes: Sistemas de ComunicaçãoDocumento15 páginasFundamentos de Redes: Sistemas de ComunicaçãoCarlos Davi PessoaAinda não há avaliações
- Modelos de referência para redes de computadoresDocumento69 páginasModelos de referência para redes de computadoresAngelo RoncalliAinda não há avaliações
- OSPF EssentialsDocumento50 páginasOSPF EssentialsMarden ViníciusAinda não há avaliações
- Lista 1 Protocolos Ate Camada TransporteDocumento2 páginasLista 1 Protocolos Ate Camada TransporteInformaAinda não há avaliações
- IP - Exercicios ResolvidosDocumento5 páginasIP - Exercicios ResolvidosGirazzAinda não há avaliações
- Classificação Das Redes Segundo Arquitetura Da RedeDocumento2 páginasClassificação Das Redes Segundo Arquitetura Da RedeAlexandru BurcăAinda não há avaliações
- ITN Module 9 101830Documento27 páginasITN Module 9 101830Ricardo PasseioAinda não há avaliações
- Curso de Configuração de Roteadores e Switches - Nível BásicoDocumento3 páginasCurso de Configuração de Roteadores e Switches - Nível Básicospyderlinuxrgm100% (1)
- Introdução ao cabeamento estruturadoDocumento9 páginasIntrodução ao cabeamento estruturadoEdson Ahlert100% (1)
- Como EIGRP estabelece e mantém relações de vizinhançaDocumento11 páginasComo EIGRP estabelece e mantém relações de vizinhançaLampz OsmyuhAinda não há avaliações
- Cablagem Estruturada - LaboratórioDocumento10 páginasCablagem Estruturada - LaboratórioHumberto Costa100% (4)
- História e evolução das redes de computadoresDocumento32 páginasHistória e evolução das redes de computadoresxequemate88068547Ainda não há avaliações
- Resumo Conceitos Protocolos WANDocumento1 páginaResumo Conceitos Protocolos WANIgor CoutinhoAinda não há avaliações
- CCNA - Modulo 4 - Tecnologias WANDocumento257 páginasCCNA - Modulo 4 - Tecnologias WANGilson Ramos Dos SantosAinda não há avaliações
- Lista Enderecamento IPDocumento4 páginasLista Enderecamento IPpaulopadiilhaAinda não há avaliações
- Ebook Do Curso Acesso A Rede Cabeada e Sem Fio-167Documento156 páginasEbook Do Curso Acesso A Rede Cabeada e Sem Fio-167Jonathan SouzaAinda não há avaliações
- Qos CompressDocumento144 páginasQos CompressNick Martins gaspar100% (1)
- Topologia rede lab R2 R1 R6 R4 R5 R3Documento21 páginasTopologia rede lab R2 R1 R6 R4 R5 R3Alex Machado100% (2)
- Lab-1 Rota Estática PDFDocumento20 páginasLab-1 Rota Estática PDFEndson SantosAinda não há avaliações
- Troubleshooting Redes CiscoDocumento45 páginasTroubleshooting Redes CiscoOrnato NogueiraAinda não há avaliações
- Gerenciamento de RedesDocumento52 páginasGerenciamento de RedesfellipewollyAinda não há avaliações
- Huawei MT800 ManualDocumento69 páginasHuawei MT800 ManualMarceloPeresAinda não há avaliações
- GUIA CONFIG ROTEADORDocumento18 páginasGUIA CONFIG ROTEADORCharles ParadedaAinda não há avaliações
- Calculando de Sub-RedesIPv4Documento7 páginasCalculando de Sub-RedesIPv4Mario Julio de Oliveira SilvaAinda não há avaliações
- Sistemas de numeração Decimal, Binário, Octal e HexadecimalDocumento15 páginasSistemas de numeração Decimal, Binário, Octal e HexadecimalEduarda DudaAinda não há avaliações
- Desenvolvendo Um Acesso Ao Cofre Eletrônico Com Rfid Usando O ArduinoNo EverandDesenvolvendo Um Acesso Ao Cofre Eletrônico Com Rfid Usando O ArduinoAinda não há avaliações
- Sistemas operacionais de tempo real e sua aplicação em sistemas embarcadosNo EverandSistemas operacionais de tempo real e sua aplicação em sistemas embarcadosAinda não há avaliações
- Escrita FiscalDocumento78 páginasEscrita FiscalJuliana da SilvaAinda não há avaliações
- Inicio em LinuxDocumento11 páginasInicio em Linuxldvieira83Ainda não há avaliações
- Dominando SedDocumento113 páginasDominando Sedinfms3383Ainda não há avaliações
- Nagios PortugueseDocumento83 páginasNagios PortugueseromieriAinda não há avaliações
- Exercicio de Contabilidade TributáriaDocumento1 páginaExercicio de Contabilidade Tributárialuluzinha08Ainda não há avaliações
- Ebook Combinacoes Diamantes Da LotofacilDocumento26 páginasEbook Combinacoes Diamantes Da LotofacilJosé FranciscoAinda não há avaliações
- TJ-MG - Oficial de Apoio Judicial Completa - Edital Oficial 2017 PDFDocumento488 páginasTJ-MG - Oficial de Apoio Judicial Completa - Edital Oficial 2017 PDFHérica GarciaAinda não há avaliações
- 30 Dias Postagens paraDocumento8 páginas30 Dias Postagens paraandreiacambezAinda não há avaliações
- Apostilas Do Curso PHP CSS MySQLDocumento57 páginasApostilas Do Curso PHP CSS MySQLMarcelo Lopes de OliveiraAinda não há avaliações
- Pedido de Contestação de Compra No Cartão Nubank - Sanrcm@gmail - Com - GmailDocumento1 páginaPedido de Contestação de Compra No Cartão Nubank - Sanrcm@gmail - Com - GmailSandro MoraesAinda não há avaliações
- InstalaçãoAtivação Windows 11 ProDocumento1 páginaInstalaçãoAtivação Windows 11 ProrodrigodmtbnAinda não há avaliações
- 1.simulado I InternetDocumento2 páginas1.simulado I InternetAna Paula CondorAinda não há avaliações
- Anexo I - RFP 02 - Inventário Firewall - Sizing Revisao - Usbee - SomeDocumento17 páginasAnexo I - RFP 02 - Inventário Firewall - Sizing Revisao - Usbee - SomedeovanirAinda não há avaliações
- Ferramenta I MacrosDocumento12 páginasFerramenta I MacrosMari NanaAinda não há avaliações
- Tutorial de keylogger, joiner e proteção com ThemidaDocumento25 páginasTutorial de keylogger, joiner e proteção com ThemidaReginaldo LimaAinda não há avaliações
- Datasheet VAULT SCAIIP CF - Versão PortuguêsDocumento6 páginasDatasheet VAULT SCAIIP CF - Versão PortuguêsnoporksAinda não há avaliações
- Apostila Digital Concurso Banpara Banco Do para Técnico Bancário 2012 Download Prova Anterior Público Banpara - Banco Do para 2012 Tecnico Bancario Baixar GabaritoDocumento4 páginasApostila Digital Concurso Banpara Banco Do para Técnico Bancário 2012 Download Prova Anterior Público Banpara - Banco Do para 2012 Tecnico Bancario Baixar GabaritoGarraApostilasAinda não há avaliações
- ModelosSDDocumento20 páginasModelosSDJoel Sambora MugileAinda não há avaliações
- Vídeo Aulas WEBMASTER e WEBDESIGNDocumento2 páginasVídeo Aulas WEBMASTER e WEBDESIGNcarlosmktAinda não há avaliações
- Pozzoli Com Áudios - Prof. Silvio RibeiroDocumento87 páginasPozzoli Com Áudios - Prof. Silvio RibeiromonimiuxaAinda não há avaliações
- Comunicação IndusoftDocumento25 páginasComunicação IndusoftMarcos Vinicius100% (1)
- Apresentação de Brainstorm Doodle Escrita A Mão Divertida AmarelaDocumento6 páginasApresentação de Brainstorm Doodle Escrita A Mão Divertida AmarelaDORILUS ESTHERAinda não há avaliações
- Focus-Concursos-NOÇÕES de INFORMÁTICA - Aula 05 - Linux e Windows 10 - Parte IDocumento7 páginasFocus-Concursos-NOÇÕES de INFORMÁTICA - Aula 05 - Linux e Windows 10 - Parte IWilson JúniorAinda não há avaliações
- Conhecimentos de Informática: Internet, Intranet e FerramentasDocumento279 páginasConhecimentos de Informática: Internet, Intranet e FerramentasMonsieur Welch100% (1)
- CV - Edilucia Fonseca PereiraDocumento1 páginaCV - Edilucia Fonseca PereiraAnderson Haaru (XF8)Ainda não há avaliações
- Catalogo Janela Maxim Ar 02 1Documento17 páginasCatalogo Janela Maxim Ar 02 1Monica de AlmeidaAinda não há avaliações
- Homem Ao Maximo - Pesquisa GoogleDocumento1 páginaHomem Ao Maximo - Pesquisa GoogleCristina Conceição FernandesAinda não há avaliações
- Educação e CiberespaçoDocumento354 páginasEducação e CiberespaçoHélder Filipe100% (2)
- Cartilha de Boas Vindas Da TI-IndiceDocumento2 páginasCartilha de Boas Vindas Da TI-IndiceDebora FalcaoAinda não há avaliações
- Dogecoin, A Moeda MemeDocumento1 páginaDogecoin, A Moeda Memejoão gabrielAinda não há avaliações
- Apostila Prefeitura de Ibipor - PR - 2019 - Auxiliar Administrativo PDFDocumento181 páginasApostila Prefeitura de Ibipor - PR - 2019 - Auxiliar Administrativo PDFGisele ItiyamaAinda não há avaliações
- Manual MultiSyncDocumento33 páginasManual MultiSyncArthur ReisAinda não há avaliações
- Como Aplicar Um Desconto Financeiro Num Documento - Moloni - Softw..Documento4 páginasComo Aplicar Um Desconto Financeiro Num Documento - Moloni - Softw..Sergio Daúde PortucalenseAinda não há avaliações
- Script DoDirectaoAgendamentoDocumento3 páginasScript DoDirectaoAgendamentorayanegommezssAinda não há avaliações
- Integração RM Reports e ProtheusDocumento20 páginasIntegração RM Reports e ProtheusWeverton Cesar PaulinoAinda não há avaliações