Você também pode gostar
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5795)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- Mathematics V Kas 304Documento2 páginasMathematics V Kas 304Digvijoy RanjanAinda não há avaliações
- Santosh S. Venkatesh - The Theory of Probability - Explorations and Applications (2012, Cambridge University Press) PDFDocumento832 páginasSantosh S. Venkatesh - The Theory of Probability - Explorations and Applications (2012, Cambridge University Press) PDFomertave100% (3)
- Lesson 7Documento19 páginasLesson 7History RoseAinda não há avaliações
- Econometrics Notes - University of Utah (370 Pages)Documento370 páginasEconometrics Notes - University of Utah (370 Pages)Justin_C_RAinda não há avaliações
- 07 Queuing ModelsDocumento59 páginas07 Queuing Modelsshofi maharaniAinda não há avaliações
- In Statistics, How Do T and Z - Normal Distributions Differ - QuoraDocumento3 páginasIn Statistics, How Do T and Z - Normal Distributions Differ - QuoraBruno SaturnAinda não há avaliações
- Bessel's CorrectionDocumento8 páginasBessel's CorrectionCarlos Cuevas LópezAinda não há avaliações
- Pricing of Zero-Coupon BondsDocumento15 páginasPricing of Zero-Coupon BondsKofi Appiah-DanquahAinda não há avaliações
- Chapter 5 - Uncertain Knowledge and ReasoningDocumento29 páginasChapter 5 - Uncertain Knowledge and ReasoningsomsonengdaAinda não há avaliações
- Probability-Assignment 1Documento4 páginasProbability-Assignment 1ibtihaj aliAinda não há avaliações
- 9ABS401 Probability & StatisticsDocumento1 página9ABS401 Probability & StatisticssivabharathamurthyAinda não há avaliações
- Assignment 1 PDFDocumento6 páginasAssignment 1 PDFlaxmi mahtoAinda não há avaliações
- Exam P Review SheetDocumento12 páginasExam P Review SheetHarry HallerAinda não há avaliações
- Module 4 Measures of VariabilityDocumento9 páginasModule 4 Measures of VariabilityNiema Tejano FloroAinda não há avaliações
- Fundamental Probability: A Computational ApproachDocumento19 páginasFundamental Probability: A Computational Approachquant3Ainda não há avaliações
- ECON1203 HW Solution Week07Documento5 páginasECON1203 HW Solution Week07Bad Boy0% (1)
- Markov Random Topic Fields: Hal Daum e III School of Computing University of Utah Salt Lake City, UT 84112 Me@hal3.nameDocumento4 páginasMarkov Random Topic Fields: Hal Daum e III School of Computing University of Utah Salt Lake City, UT 84112 Me@hal3.nameRagó DominikAinda não há avaliações
- Using Skellam's Distribution To Assess Soccer Team PerformanceDocumento9 páginasUsing Skellam's Distribution To Assess Soccer Team PerformanceBartoszSowulAinda não há avaliações
- Mca4020 SLM Unit 07Documento22 páginasMca4020 SLM Unit 07AppTest PIAinda não há avaliações
- 410Hw03 PDFDocumento3 páginas410Hw03 PDFdAinda não há avaliações
- Monte Carlo EssayDocumento2 páginasMonte Carlo EssaydonAinda não há avaliações
- STA301 Assignment 2 Solution 2022Documento3 páginasSTA301 Assignment 2 Solution 2022Entertainment StatusAinda não há avaliações
- Stochastic Signals and Systems Problem Set 10 Solution: N N N 1 1 2 N N M 1 2Documento4 páginasStochastic Signals and Systems Problem Set 10 Solution: N N N 1 1 2 N N M 1 2AnupKumarJaiswalAinda não há avaliações
- GATE Statistics SyllabusDocumento3 páginasGATE Statistics Syllabuskumar HarshAinda não há avaliações
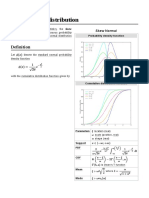
- Skew Normal DistributionDocumento4 páginasSkew Normal Distributionanthony777Ainda não há avaliações
- SHS Statistics and Probability Q3 Mod1 Random Variables and v4Documento43 páginasSHS Statistics and Probability Q3 Mod1 Random Variables and v4Charmian100% (3)
- UW MATH-STAT394 HW6-solDocumento3 páginasUW MATH-STAT394 HW6-solRachmat HidayatAinda não há avaliações
- A New Extended Weibull Distribution With ApplicatiDocumento17 páginasA New Extended Weibull Distribution With Applicatiluis gabrielAinda não há avaliações
- STAT 552 Probability and Statistics Ii: Short Review of S551Documento51 páginasSTAT 552 Probability and Statistics Ii: Short Review of S551Arthur LegaspinaAinda não há avaliações
- Sample ExamDocumento5 páginasSample ExamNoha El-sheweikhAinda não há avaliações