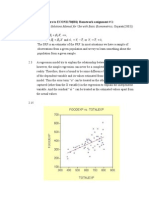
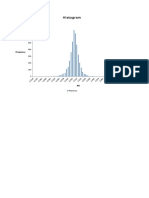
Você também pode gostar
- Econ 251 PS4 SolutionsDocumento11 páginasEcon 251 PS4 SolutionsPeter ShangAinda não há avaliações
- The Better Sine Wave IndicatorDocumento10 páginasThe Better Sine Wave IndicatorcoachbiznesuAinda não há avaliações
- AsistDocumento18 páginasAsistdeviAinda não há avaliações
- Solutions To Problem Set 1Documento6 páginasSolutions To Problem Set 1Harry KwongAinda não há avaliações
- Example For NumericalDocumento9 páginasExample For Numericaltekalign yerangoAinda não há avaliações
- Solutions Manual to accompany Introduction to Linear Regression AnalysisNo EverandSolutions Manual to accompany Introduction to Linear Regression AnalysisNota: 1 de 5 estrelas1/5 (1)
- Canal OutletsDocumento32 páginasCanal OutletsAhmed Hassan83% (6)
- Econ107 Assignment 1 PrepDocumento9 páginasEcon107 Assignment 1 Prepjusleen.sarai03Ainda não há avaliações
- Answered Sheets CombinedDocumento52 páginasAnswered Sheets CombinedrayanmaazsiddigAinda não há avaliações
- Econometrics FinalDocumento16 páginasEconometrics FinalDanikaLiAinda não há avaliações
- ECON 301 - Midterm - F2023 - Answer KeyDocumento4 páginasECON 301 - Midterm - F2023 - Answer KeyAidanaAinda não há avaliações
- Introductory Econometrics A Modern ApproDocumento202 páginasIntroductory Econometrics A Modern ApproMinnie JungAinda não há avaliações
- HW3Documento19 páginasHW3rogervalen5049Ainda não há avaliações
- Econ 113 Probset3 SolDocumento7 páginasEcon 113 Probset3 SolPrebble Q RamswellAinda não há avaliações
- Exercise 1:: Chapter 3: Describing Data: Numerical MeasuresDocumento11 páginasExercise 1:: Chapter 3: Describing Data: Numerical MeasuresPW Nicholas100% (1)
- Assignment R New 1Documento26 páginasAssignment R New 1Sohel RanaAinda não há avaliações
- Ans To The Question Number 5: From Output of MinitabDocumento4 páginasAns To The Question Number 5: From Output of MinitabAlizay NishatAinda não há avaliações
- Lecture 5. Part 1 - Regression AnalysisDocumento28 páginasLecture 5. Part 1 - Regression AnalysisRichelle PausangAinda não há avaliações
- Number of Children Over 5 Number of Households Relative Frequency 0 1 2 3 4Documento19 páginasNumber of Children Over 5 Number of Households Relative Frequency 0 1 2 3 4hello helloAinda não há avaliações
- Assignment 1Documento8 páginasAssignment 1kowletAinda não há avaliações
- Midterm Exam SolutionsDocumento4 páginasMidterm Exam SolutionsDaniel GagnonAinda não há avaliações
- Homework 1 Math Problem AnalysisDocumento8 páginasHomework 1 Math Problem AnalysisSaravana SomasundaramAinda não há avaliações
- Nur Syuhada Binti Safaruddin - Rba2403a - 2020819322Documento6 páginasNur Syuhada Binti Safaruddin - Rba2403a - 2020819322syuhadasafar000Ainda não há avaliações
- Assignment 2 Business Statistics (BBA) Aleem Hasan & Mohib SheikhDocumento8 páginasAssignment 2 Business Statistics (BBA) Aleem Hasan & Mohib SheikhAleem HasanAinda não há avaliações
- Comprehensive Assignment 2 Question OneDocumento11 páginasComprehensive Assignment 2 Question OneJasiz Philipe OmbuguAinda não há avaliações
- Statistics - AssignmentDocumento14 páginasStatistics - AssignmentRavinderpal S Wasu100% (1)
- CH 2Documento17 páginasCH 2Daniiar KamalovAinda não há avaliações
- HW5 For Financial MathameticsDocumento9 páginasHW5 For Financial MathameticsshihuiAinda não há avaliações
- 15.S24 Fundamentals of Financial Mathematics Problem Set 5 Shihui Chen ID: 913599770Documento12 páginas15.S24 Fundamentals of Financial Mathematics Problem Set 5 Shihui Chen ID: 913599770shihuiAinda não há avaliações
- Project 2: Technical University of DenmarkDocumento11 páginasProject 2: Technical University of DenmarkRiyaz AlamAinda não há avaliações
- Bivariate Regression AnalysisDocumento15 páginasBivariate Regression AnalysisCarmichael MarlinAinda não há avaliações
- ECON2206 Assignment - Introductory EconometricsDocumento7 páginasECON2206 Assignment - Introductory EconometricsRichard HenryAinda não há avaliações
- Economics of Health and Health Care 7th Edition Folland Solutions ManualDocumento16 páginasEconomics of Health and Health Care 7th Edition Folland Solutions Manuallisafloydropyebigcf100% (9)
- Summative Assignment: ECOS1101 Undergraduate Programmes 2008/09 Quantitative MethodsDocumento23 páginasSummative Assignment: ECOS1101 Undergraduate Programmes 2008/09 Quantitative MethodsTanya MyrymskaAinda não há avaliações
- Lnq = Β + Β Lnli + Β Lnki + ƐDocumento12 páginasLnq = Β + Β Lnli + Β Lnki + ƐBiren PatelAinda não há avaliações
- The Next 5 Questions Are Based On The Following Information.Documento10 páginasThe Next 5 Questions Are Based On The Following Information.testttAinda não há avaliações
- Chapter 10 SolutionsDocumento22 páginasChapter 10 SolutionsGreg100% (1)
- FRM Quantitative Analysis Test 1 SolutionsDocumento4 páginasFRM Quantitative Analysis Test 1 SolutionsConradoCantoIIIAinda não há avaliações
- Department of Statistics: Course Stats 330Documento5 páginasDepartment of Statistics: Course Stats 330PETERAinda não há avaliações
- ASSIGNMENT ON STATISTICAL PROCESS CONTROL ProdDocumento4 páginasASSIGNMENT ON STATISTICAL PROCESS CONTROL ProdsamanthaAinda não há avaliações
- Logistic RegressionDocumento10 páginasLogistic RegressionParth MehtaAinda não há avaliações
- Chapter 1Documento7 páginasChapter 1phingoctuAinda não há avaliações
- Lahore School of EconomicsDocumento10 páginasLahore School of EconomicsMahnoorAinda não há avaliações
- S&W, Chapter 5 SolutionsDocumento13 páginasS&W, Chapter 5 SolutionsL'houssaine AlayoudAinda não há avaliações
- SW 2e Ex ch05Documento5 páginasSW 2e Ex ch05Nicole Dos AnjosAinda não há avaliações
- Solution Chapter 2 MandenhallDocumento29 páginasSolution Chapter 2 MandenhallUzair KhanAinda não há avaliações
- Interpretation and Statistical Inference With OLS RegressionsDocumento17 páginasInterpretation and Statistical Inference With OLS RegressionsXènia Bellet NavarroAinda não há avaliações
- Prop of UncertDocumento2 páginasProp of UncertKhondokar TarakkyAinda não há avaliações
- Stats For Data Science Assignment-2: NAME: Rakesh Choudhary ROLL NO.-167 BATCH-Big Data B3Documento9 páginasStats For Data Science Assignment-2: NAME: Rakesh Choudhary ROLL NO.-167 BATCH-Big Data B3Rakesh ChoudharyAinda não há avaliações
- Assignment 3Documento8 páginasAssignment 3vidula pandeAinda não há avaliações
- ECON2170 Homework: Regression models and hypothesis testingDocumento7 páginasECON2170 Homework: Regression models and hypothesis testingPilSeung HeoAinda não há avaliações
- BES220 Sick Nov2022Documento12 páginasBES220 Sick Nov2022Simphiwe BenyaAinda não há avaliações
- MAT 540 Statistical Concepts For ResearchDocumento42 páginasMAT 540 Statistical Concepts For Researchnequwan79Ainda não há avaliações
- A Review of Basic Statistical Concepts: Answers To Odd Numbered Problems 1Documento32 páginasA Review of Basic Statistical Concepts: Answers To Odd Numbered Problems 1Abbas RazaAinda não há avaliações
- Mean DeviationDocumento10 páginasMean DeviationJanarthanan YadavAinda não há avaliações
- Decision ScienceDocumento8 páginasDecision ScienceHimanshi YadavAinda não há avaliações
- Working Version 1Documento7 páginasWorking Version 1Bhaskkar SinhaAinda não há avaliações
- 1.3 Statistical ConceptDocumento12 páginas1.3 Statistical ConceptrollickingdeolAinda não há avaliações
- Final EM2 2021 Perm 1 VNov22Documento14 páginasFinal EM2 2021 Perm 1 VNov22Il MulinaioAinda não há avaliações
- Dummy Variable Regression Models 9.1:, Gujarati and PorterDocumento18 páginasDummy Variable Regression Models 9.1:, Gujarati and PorterTân DươngAinda não há avaliações
- Integer Optimization and its Computation in Emergency ManagementNo EverandInteger Optimization and its Computation in Emergency ManagementAinda não há avaliações
- Kakuro #1-4: 6X6 Kakuro Puzzles by Krazydad, Volume 1, Book 2Documento3 páginasKakuro #1-4: 6X6 Kakuro Puzzles by Krazydad, Volume 1, Book 2Aashirtha SAinda não há avaliações
- CISE-302-Linear-Control-Systems-Lab-Manual 1Documento22 páginasCISE-302-Linear-Control-Systems-Lab-Manual 1ffffffAinda não há avaliações
- Sensex 1Documento354 páginasSensex 1raghav4life8724Ainda não há avaliações
- Natural Frequency C ProgramDocumento18 páginasNatural Frequency C ProgramprateekAinda não há avaliações
- Aerodynamics MCQs on Low Speed AerodynamicsDocumento4 páginasAerodynamics MCQs on Low Speed AerodynamicsHarish MathiazhahanAinda não há avaliações
- Lecture 22Documento6 páginasLecture 22Rainesius DohlingAinda não há avaliações
- Risk Management Principles and Guidelines - IsO 31000 ReviewDocumento5 páginasRisk Management Principles and Guidelines - IsO 31000 ReviewMarcelo Coronel Castromonte100% (1)
- Optimizing Planetary Gear Design for Load DistributionDocumento17 páginasOptimizing Planetary Gear Design for Load DistributionANURAAG AAYUSHAinda não há avaliações
- 1-15-15 Kinematics AP1 - Review SetDocumento8 páginas1-15-15 Kinematics AP1 - Review SetLudwig Van Beethoven100% (1)
- 199307Documento87 páginas199307vtvuckovicAinda não há avaliações
- Irace Comex TutorialDocumento5 páginasIrace Comex TutorialOmarSerranoAinda não há avaliações
- Decimal and Fraction Concepts for Fourth GradersDocumento6 páginasDecimal and Fraction Concepts for Fourth GradersSharmaine VenturaAinda não há avaliações
- Javascript - Domain Fundamentals AssignmentsDocumento43 páginasJavascript - Domain Fundamentals AssignmentsSana Fathima SanaAinda não há avaliações
- Vectors and TensorsDocumento13 páginasVectors and TensorsNithinAinda não há avaliações
- Tabel Distribuzi Normal Z-Harus 0.5 Dikurangi PDFDocumento1 páginaTabel Distribuzi Normal Z-Harus 0.5 Dikurangi PDFLisna L. PaduaiAinda não há avaliações
- TrigonometryDocumento15 páginasTrigonometryJnanam100% (1)
- CH08 Wooldridge 7e PPT 2pp 20231128Documento3 páginasCH08 Wooldridge 7e PPT 2pp 20231128turtlefar1Ainda não há avaliações
- Wind Load On StructuesDocumento14 páginasWind Load On StructuesNasri Ahmed mohammedAinda não há avaliações
- Coding Area: Roman IterationDocumento3 páginasCoding Area: Roman IterationPratyush GoelAinda não há avaliações
- PCM PrincipleDocumento31 páginasPCM PrincipleSachin PatelAinda não há avaliações
- Math6338 hw1Documento5 páginasMath6338 hw1Ricardo E.Ainda não há avaliações
- Cross Drainage WorksDocumento71 páginasCross Drainage Worksjahid shohag100% (2)
- The Fast Continuous Wavelet Transformation (FCWT) For Real-Time, High-Quality, Noise-Resistant Time-Frequency AnalysisDocumento17 páginasThe Fast Continuous Wavelet Transformation (FCWT) For Real-Time, High-Quality, Noise-Resistant Time-Frequency AnalysisHARRYAinda não há avaliações
- Bitwise Operator StructuresDocumento6 páginasBitwise Operator StructuresrajuhdAinda não há avaliações
- FMEA Scope AnalysisDocumento14 páginasFMEA Scope AnalysisAnkurAinda não há avaliações
- Ansys Coupled Structural Thermal AnalysisDocumento12 páginasAnsys Coupled Structural Thermal AnalysisVaibhava Srivastava100% (1)
- Predicting Weather Forecaste Uncertainty With Machine LearningDocumento17 páginasPredicting Weather Forecaste Uncertainty With Machine LearningJUAN LOPEZAinda não há avaliações
- Gpelab A Matlab Toolbox For Computing Stationary Solutions and Dynamics of Gross-Pitaevskii Equations (Gpe)Documento122 páginasGpelab A Matlab Toolbox For Computing Stationary Solutions and Dynamics of Gross-Pitaevskii Equations (Gpe)Pol MestresAinda não há avaliações