Você também pode gostar
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (119)
- SQL for Tivoli Storage Manager DatabaseDocumento32 páginasSQL for Tivoli Storage Manager Databasemajumder_subhrajitAinda não há avaliações
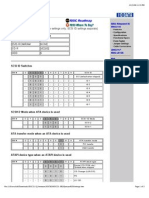
- IDSC21-E Jumper SettingsDocumento2 páginasIDSC21-E Jumper Settingsa4000tAinda não há avaliações
- Z8F4822AR020SCDocumento299 páginasZ8F4822AR020SCrdc02271Ainda não há avaliações
- 467 Experiment3Documento10 páginas467 Experiment3mid_cyclone100% (1)
- MBTCP DAServer User's Guide PDFDocumento112 páginasMBTCP DAServer User's Guide PDFKléber Chávez CifuentesAinda não há avaliações
- Lab 5Documento5 páginasLab 5viswanathrd45Ainda não há avaliações
- Siebel Open UI Interview QuestionsDocumento2 páginasSiebel Open UI Interview QuestionsSourav Chatterjee67% (3)
- Nokia Live PresentationDocumento27 páginasNokia Live PresentationwasiffarooquiAinda não há avaliações
- Syllabus: R708 Network Programming LabDocumento64 páginasSyllabus: R708 Network Programming LabbaazilpthampyAinda não há avaliações
- ReadmeDocumento4 páginasReadmeSerghei PlamadealaAinda não há avaliações
- 5Documento149 páginas5api-3709715Ainda não há avaliações
- 50 SAP ABAP ALE IDOC Interview QuestionsDocumento6 páginas50 SAP ABAP ALE IDOC Interview QuestionsAjit Keshari Pradhan100% (1)
- Network Engineer With CCNA CCNP ResumeDocumento4 páginasNetwork Engineer With CCNA CCNP ResumeSi ValAinda não há avaliações
- Itec55 - Operating System StructureDocumento4 páginasItec55 - Operating System StructureaescarlannAinda não há avaliações
- Final SRS DocumentDocumento25 páginasFinal SRS Documentsanjeev_18017% (6)
- Script ESupervision SystemDocumento4 páginasScript ESupervision SystemGracy BabsyAinda não há avaliações
- Cisco PPPoE Over L2TP Sample Configuration - Rejohn Cuares PDFDocumento9 páginasCisco PPPoE Over L2TP Sample Configuration - Rejohn Cuares PDFCAinda não há avaliações
- Learning Node - Js For Mobile Application Development - Sample ChapterDocumento27 páginasLearning Node - Js For Mobile Application Development - Sample ChapterPackt PublishingAinda não há avaliações
- Chapter 2: Database Environment TransparenciesDocumento38 páginasChapter 2: Database Environment TransparenciesRifat_mmuAinda não há avaliações
- CISCO PIX506-E - IPSec VPN Configuration GuideDocumento15 páginasCISCO PIX506-E - IPSec VPN Configuration Guidegreenbow100% (4)
- Veeam On Nutanix With Hyper-V BPDocumento24 páginasVeeam On Nutanix With Hyper-V BPqabbasAinda não há avaliações
- Sample PDFDocumento1 páginaSample PDFlucasloudAinda não há avaliações
- Loan Management System Project PresentationDocumento92 páginasLoan Management System Project PresentationJilly Arasu33% (24)
- MSJ 1986 10Documento34 páginasMSJ 1986 10lolo12345Ainda não há avaliações
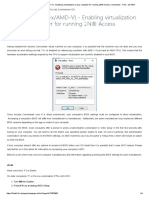
- Virtualization (VT-X - AMD-V) - Enabling Virtualization On Your Computer For Running 2N® Access Commander - FAQ - 2N WIKIDocumento4 páginasVirtualization (VT-X - AMD-V) - Enabling Virtualization On Your Computer For Running 2N® Access Commander - FAQ - 2N WIKIErick Luna RojasAinda não há avaliações
- m160 PDFDocumento836 páginasm160 PDFMery Helen Barraza Delgado100% (1)
- 3GPP TS 29.274: Technical SpecificationDocumento152 páginas3GPP TS 29.274: Technical SpecificationAlan WillAinda não há avaliações
- ETW-REST API v1.01 Scope and SequenceDocumento2 páginasETW-REST API v1.01 Scope and SequencePepito CortizonaAinda não há avaliações
- Pre Emphasis de EmphasisDocumento2 páginasPre Emphasis de EmphasisgodierobertAinda não há avaliações
- Atmega 8 Connection To 74HC595: Circuit DiagramDocumento3 páginasAtmega 8 Connection To 74HC595: Circuit DiagramRuhollah PurbafraniAinda não há avaliações