Escolar Documentos
Profissional Documentos
Cultura Documentos
Dr. Wheeler's SPC Toolkit
Enviado por
Gaurav NarulaDescrição original:
Título original
Direitos autorais
Formatos disponíveis
Compartilhar este documento
Compartilhar ou incorporar documento
Você considera este documento útil?
Este conteúdo é inapropriado?
Denunciar este documentoDireitos autorais:
Formatos disponíveis
Dr. Wheeler's SPC Toolkit
Enviado por
Gaurav NarulaDireitos autorais:
Formatos disponíveis
Dr.
Wheeler’s SPC Toolkit
Articles from Quality Digest columns 1996-97
What Are Shewhart's Charts?
One day my friend David Chambers found a graph summarizing the " daily percentage of
defective pairs" on the office wall of the president of a shoe company. Intrigued, David asked
the president why he had this graph on the wall. The president condescendingly replied that he
had the chart on the wall so he could tell how the plant was doing. David immediately
responded with, "Tell me how you're doing." He paused, looked at the chart on the wall, and
then said, "Well, some days are better than others!"
Even though the president displayed his data in a suitable graphic format, and even though he
felt that these data were important enough to require their posting each day, he did not have a
formal way to analyze these values and interpret them.
Data must be filtered in some manner to make them intelligible. This filtration may be based
upon a person's experience plus presuppositions and assumptions, or it may be more
formalized and less subjective, but there will always be some method of analysis. Of course,
inadequate experience, flawed assumptions or inappropriate presuppositions can result in
incorrect interpretations. However, in the absence of a formal and standardized approach to
interpreting data, most managers use the seat-of-the-pants approach.
Walter Shewhart developed a simple and effective way to define the voice of the process- he
called it a control chart. A control chart begins with a time-series graph. A central line is added
as a visual reference for detecting shifts or trends, and control limits (computed from the data)
are placed equidistant on either side of the central line. Thus, a control chart is simply a time
series with three horizontal lines added. The key to the effectiveness of the control chart is the
way in which these limits are computed from the data.
The control chart shown below consists of a sequence of single values. In other situations, the
control chart may be based upon a time series of average values, ranges or some other
function of the raw data. While there are several different types of control charts, they are all
interpreted in the same way, and they all reveal different aspects of the voice of the process.
Control charts also characterize the behavior of the time series. Occasionally you will encounter
a time series that is well-behaved; such time series are predictable, consistent and stable over
time. More commonly, time series are not well-behaved; they are unpredictable, inconsistent
and change over time. The lines on a control chart provide reference points for use in deciding
which type of behavior is displayed by any given time series.
Shewhart wrote that a process "will be said to be in control when, through the use of past
experience, we can predict, at least within limits, how the process will behave in the future."
Thus, the essence of statistical control is predictability, and the opposite is also true. A process
that does not display a reasonable degree of statistical control is unpredictable.
This distinction between predictability and unpredictability is important because prediction is
the essence of doing business. Predictability is a great asset for any process because it makes
the manager's job that much easier. When the process is unpredictable, the time series will be
unpredictable, and this unpredictability will repeatedly undermine all of our best efforts.
Shewhart's terminology of "controlled variation" and "uncontrolled variation" must be
understood in the context of predictable and unpredictable, rather than in the sense of being
Wheeler’s SPC Toolkit 1996-97 Pag 1 di 36
able to exert control. The user does not get to "set the limits." We should talk about "
predictable processes" and "unpredictable processes."
The control chart shows a time series that remains within the computed limits, with no obvious
trend nor any long sequences of points above or below the central line. Thus, this process
appears to be predictable. Unless the process is changed in some fundamental way, the plant
will continue to produce anywhere from 7-percent defectives to 30-percent defectives, with a
daily average of about 19-percent defective.
Predictable performance is not necessarily the same as desirable performance. Notice how the
control chart has helped interpret the data. First, the chart is used to characterize the behavior
of the data- are they predictable or not? Second, the control chart allows the manager to
predict what to expect in the future- the voice of the process!
Finally, notice the difference between the shoe company president's interpretation of these
data and the interpretation based on the control chart. Some days only appeared to be better
than others! In truth, both the "good" days and the "bad" days came from the same process.
Looking for differences between the "good" days and the "bad" days will simply be a waste of
time.
Myths About Shewhart's Charts
The control charts described in many current technical articles bear little, if any, resemblance
to the control chart technique described in Walter Shewhart's writings. Part of this problem can
be attributed to novices teaching neophytes, while part is due to the failure to read Shewhart's
writings carefully. Therefore, to help the reader differentiate control chart myths from
foundations, this column will focus on both. This month, I will discuss four myths about
Shewhart's charts. Next month, I will discuss four foundations of Shewhart's charts.
Myth One: Data must be normally distributed before they can be placed on a control chart.
While the control chart constants were created under the assumption of normally distributed
data, the control chart technique is essentially insensitive to this assumption. This insensitivity
is what makes the control chart robust enough to work in the real world as a procedure for
inductive inference. In August, this column showed the robustness of three-sigma limits with a
graphic showing some very nonnormal curves.
The data don't have to be normally distributed before you can place them on a control chart.
The computations are essentially unaffected by the degree of normality of the data. Just
because the data display a reasonable degree of statistical control, doesn't mean that they will
follow a normal distribution. The normality of the data is neither a prerequisite nor a
consequence of statistical control.
Myth Two: Control charts work because of the central limit theorem.
The central limit theorem applies to subgroup averages (e.g., as the subgroup size increases,
the histogram of the subgroup averages will, in the limit, become more "normal," regardless of
how the individual measurements are distributed). Because many statistical techniques utilize
the central limit theorem, it's only natural to assume that it's the basis of the control chart.
However, this isn't the case. The central limit theorem describes the behavior of subgroup
averages, but it doesn't describe the behavior of the measures of dispersion. Moreover, there
isn't a need for the finesse of the central limit theorem when working with Shewhart's charts,
where three-sigma limits filter out 99 percent to 100 percent of the probable noise, leaving only
the potential signals outside the limits. Because of the conservative nature of the three-sigma
limits, the central limit theorem is irrelevant to Shewhart's charts.
Undoubtedly, this myth has been one of the greatest barriers to the effective use of control
charts with management and process-industry data. When data are obtained one-value-per-
Wheeler’s SPC Toolkit 1996-97 Pag 2 di 36
time-period, it's logical to use subgroups with a size of one. However, if you believe this myth
to be true, you'll feel compelled to average something to make use of the central limit theorem.
But the rationality of the data analysis will be sacrificed to superstition.
Myth Three: Observations must be independent-data with autocorrelation are inappropriate for
control charts.
Again, we have an artificial barrier based on theoretical assumptions, which ignores the nature
of real data and the robustness of the control chart. All data derived from production processes
will display some level of autocorrelation. Shewhart uses autocorrelated data in the control
chart as early as page 20 of his first book. He writes that assignable causes of variation are
found and removed, then new data is collected. The new data shows they improved the
process.
Remember, the purpose of analysis is insight rather than numbers. The control chart isn't
concerned with probability models. Rather, it's concerned with using data for making decisions
in the real world. Control charts have worked with autocorrelated data for more than 60 years.
Myth Four: Data must be in control before you can plot them on a control chart.
This myth could have only come from computing limits incorrectly. Among the blunders that
have been made in the name of this myth are: censoring data prior to charting them and using
limits that aren't three-sigma limits. Needless to say, these and other manipulations are
unnecessary. The purpose of Shewhart's charts is to detect lack of control. If a control chart
can't detect lack of control, why use it?
Foundations of Shewhart's Charts
Last month, I described four myths relating to Shewhart's charts. This month I will discuss four
foundations of the charts.
Foundation One: Shewhart's charts always use three-sigma limits. Regardless of the type of
chart you're using, the limits depend on the same principle. The data will be used to determine
the amount of variation that is likely to be background noise, and the limits will be placed three
estimated standard deviations on either side of the central line.
Three-sigma limits are action limits-they dictate when action can be taken on a process. They
are not probability limits. While they have a basis in probability theory, three-sigma limits were
chosen because they provided reasonable action limits. They strike an economical balance
between the two possible errors you can make in interpreting data from a continuing process.
Three-sigma limits neither result in too many false alarms nor do they miss too many signals. In
addition, they are unaffected by data nonnormality, even when the subgroup size is one.
Foundation Two: Computing three-sigma control limits requires the use of an average
dispersion statistic. By computing several dispersion statistics, using either an average or a
median dispersion statistic, computation stability increases. This use of the subgroup variation
will provide measures of dispersion that are much less sensitive to a lack of control than most
other approaches.
The choice of dispersion statistic is unimportant-ranges, standard deviations or root mean
square deviations may be used. If the proper approach is used, different statistics will yield
similar results. If the wrong approach is used, different statistics will yield similar incorrect
results.
Foundation Three: The conceptual foundation of Shewhart's control charts is the notion of
rational sampling and rational subgrouping. How the data are collected, how they are arranged
into subgroups and how these subgroups are charted must be based on the context of the
Wheeler’s SPC Toolkit 1996-97 Pag 3 di 36
data, the sources of data variation, the questions to be answered by the charts and how the
knowledge gained will be used.
Failure to consider these factors when placing data on a control chart can result in nonsensical
control charts. The effective use of Shewhart's charts requires an understanding of rational
sampling and rational subgrouping.
Foundation Four: Control charts are effective only to the extent that the organization can use
the knowledge. Knowledge gathering is in vain without an organization that can disseminate
and use this knowledge. As long as there are internal obstacles that prevent an organization
from utilizing SPC charts, nothing will happen.
This is why so many of W. Edwards Deming's 14 points bear directly upon this one foundation
and why SPC alone isn't enough. On the other hand, any program designed to increase
organizational effectiveness and efficiency that does not use SPC is doomed to fail.
This fourth foundation of Shewhart's charts is only implicit in Shewhart's work-there was always
the assumption that organizations behave in a rational manner. However, Deming came to see
that this wasn't the case. Simply giving people effective methods for collecting, organizing and
analyzing data wasn't enough. In the absence of such methods, businesses had come to be run
by the emotional interpretation of the visible figures-a universal "My mind is made up, don't
bother me with the facts" syndrome.
While Deming's 14 points do not constitute the whole of his philosophy, they are a profound
starting point. They are not a set of techniques, a list of instructions nor a checklist. They are a
vision of just what can be involved in using SPC. And they ultimately lead to radically different
and improved ways of organizing businesses and working with people. However, a deep
understanding is required before these 14 points can be used to accomplish the total
transformation. The need is not to adopt the 14 points individually or collectively, but rather to
create a new environment conducive to their principles.
The New Definition of Trouble
Product 1411 was in trouble. After batches 1 through 29 ran without a problem, Batch 30 failed
in the customer's plant. Batch 31 worked, but the next three batches failed. When the
preliminary investigation exonerated the customer's process as the problem source, the
pressure shifted to the supplier.
The supplier had a five-step process spanning three plants. Product 1411 started as a fluid
produced by Step A in Plant One. The fluid was then shipped 400 miles to Plant Two, where
Step B was performed. From there, it was shipped to Plant Three, where steps C, D and E were
completed.
The supplier knew that, at no time, had any marginal material been passed on to the next step-
all of the material supplied to Step E had been within specification. Therefore, the investigation
focused on Step E as the likely problem source. While they investigated Step E, batches 35
through 52 were produced. Of these 18 batches, 10 worked, seven failed in the customer's
plant and one was recycled because it did not meet internal specifications.
After much effort, the investigators became convinced that the problem did not originate in
Step E. They then widened the investigation to include Step D. While Step D was scrutinized,
batches 53 through 65 were produced and shipped to the customer. Of these 13 batches, only
two worked.
After Batch 65, they decided to look at Step C. Finally, seven months after the problem arose,
steps C and D were also eliminated as the problem source. By this time, they had produced 75
batches. However, only one of the last 10 batches had worked in the customer's plant.
Wheeler’s SPC Toolkit 1996-97 Pag 4 di 36
Extending the investigation to Step B required the involvement of personnel from Plant Two.
Even with the expanding number of people and the mounting number of man-hours, nothing
was found at Step B. By now, eight months had passed, and only 18 of the last 54 batches had
worked. So the team returned to Plant One and Step A.
As the investigators looked over the records for Step A, they found that the levels of
"Compound M" had increased, beginning with Batch 30. The specification for Compound M was
"not more than 1,500 ppm." This value was based upon the safe-handling requirements.
Because the level of Compound M was fixed at Step A, and because safety requirements
prohibited shipping any liquid that was out-of-spec, Compound M was not even measured at
the subsequent steps.
Batches 1 through 29 averaged 78 ppm of Compound M, with levels ranging from 0 to 167
ppm. All of these batches worked.
Batches 30 through 51 averaged 191 ppm of Compound M, with levels ranging from 0 to 346
ppm. Of these 22 batches, only the 10 with less than 200 ppm worked.
Batches 53 through 85 averaged 412 ppm of Compound M, with levels ranging from 0 to 969
ppm. Of these 32 batches, only the eight with less than 200 ppm worked.
Dozens of people had worked for eight months to discover something that a simple control
chart at the first production step could have revealed immediately-Plant One had ceased to
produce a consistent product with Batch 30. This deterioration was not noticed because the
specification was so much greater than the actual levels.
They are still trying to assess the damage done to the customer of Step E because of the
performance degradation at Step A.
Conformance to specifications is no longer the definition of world-class quality. Specifications
seldom take into account customer needs
Shewhart's charts, on the other hand, are the voice of the process. They define when a process
is in trouble, and they will warn you so that you can take action to avoid even greater trouble.
Statistical control is an achievement attainable only by the persistent and effective use of
Shewhart's charts. And those who can't use Shewhart's charts are doomed.
Charts for Rare Events
Counts of rare events are inherently insensitive and weak.
Your imagination is the only limitation on the use of Shewhart's charts. They are such a basic
tool for analyzing and understanding data that they can be used in all kinds of situations-the
key is to see how best to apply them. This column will illustrate how to use Shewhart's charts
to track rare events.
Department 16 has occasional spills. The most recent spill was on July 13. Spills are not
desirable, and everything possible is done to prevent them; yet they have historically averaged
about one spill every seven months. Of course, with this average, whenever they have a spill,
they are 690 percent above average for that month. When dealing with very small numbers,
such as the counts of rare events, a one-unit change can result in a huge percentage
difference.
Counts of rare events would commonly be placed on a c-chart. (While the c-chart is a chart for
individual values, and while most count data may be charted using an XmR chart, the XmR
chart requires an average count that exceeds 1.0. The c-chart does not suffer this restriction.)
The average count is found by dividing the total number of spills in a given time period by the
Wheeler’s SPC Toolkit 1996-97 Pag 5 di 36
length of that time period. During the past 55 months, a total of eight spills occurred, which
gives an average count of:
c bar = 8 spills/55 months = 0.145 spills per month
This average will be the central line for the c-chart, and the upper control limit will be
computed according to the formula:
UCLc = c bar + 3 (square root of c bar ) = 0.145 + 3 (square root of 0.145 ) = 1.289
The c-chart is shown in Figure 1. In spite of the fact that a single spill is 690 percent above the
average, the c-chart does not show any out-of-control points. This is not a problem with the
charts but rather a problem with the data. Counts of rare events are inherently insensitive and
weak. No matter how these counts are analyzed, there is nothing to discover here.
Yet there are other ways to characterize the spills. Instead of counting the number of spills each
year, they could measure the number of days between the spills. The first spill was on Feb. 23,
Year One. The second spill was on Jan. 11, Year Two. The elapsed time between these two spills
was 322 days. One spill in 322 days is equivalent to a spill rate of 1.13 spills per year.
The third spill was on Sept. 15, Year Two. This is 247 days after the second spill. One spill in 247
days is equivalent to a spill rate of 1.48 spills per year. Continuing in this manner, the
remaining five spills are converted into instantaneous spill rates of 1.24, 1.61, 1.64, 2.12 and
3.17 spills per year. These seven spill rates are used to compute six moving ranges and are
placed on an XmR chart in Figure 2.
The average spill rate is 1.77 spills per year, and the average moving range is 0.42. These two
values result in an upper natural process limit of:
UNPL = 1.77 + 2.66 x 0.42 = 2.89
the lower natural process limit will be:
LNPL = 1.77 - 2.66 x 0.42 = 0.65
and the upper control limit for the moving ranges will be:
UCL = 3.268 x 0.42 = 1.37
This XmR chart for the spill rates is shown in Figure 2.
The last spill results in a point that is above the upper natural process limit, which suggests
that there has been an increase in the spill rate. This signal should be investigated, yet it is
missed by the c-chart.
In general, counts are weaker than measurements. Counts of rare events are no exception.
When possible, it will always be more satisfactory to measure the activity than to merely count
events. And, as shown in this example, the times between undesirable rare events are best
charted as rates.
Why Three-Sigma Limits?
Three-sigma limits filter out nearly all probable noise and isolate the potential signals.
The key to Walter Shewhart's choice of three-sigma limits lies in the title of his first book,
Economic Control of Quality of Manufactured Product, where he emphasizes the economics of
decisions. For example, Shewhart writes: "As indicated the method of attack is to establish
Wheeler’s SPC Toolkit 1996-97 Pag 6 di 36
limits of variability such that, when [a value] is found outside these limits, looking for an
assignable cause is worthwhile."
Here Shewhart makes a fundamental distinction-some processes are predictable while others
are not. He shows that by examining the data produced by a process, we can determine the
predictability of a process. If the data show that a process has been predictable in the past, it's
reasonable to expect that it will remain predictable in the future. When a process is predictable,
it's said to display common-cause, or chance-cause variation. When a process is unpredictable,
it's said to display assignable-cause variation. Therefore, the ability to distinguish between a
predictable process and an unpredictable one depends upon your ability to distinguish between
common-cause and assignable-cause variation.
What's the difference? Shewhart writes that a predictable process can be thought of as the
outcome of "a large number of chance causes in which no cause produces a predominating
effect." When a cause does produce a predominating effect, it becomes an "assignable" cause.
Thus, if we denote the predominating effect of any assignable cause as a signal, then the
collective effects of the many common causes can be likened to background noise, and the job
of separating the two types of variations is similar to separating signals from noise.
In separating signals from noise, you can make two mistakes. The first mistake occurs when
you interpret noise as a signal (i.e., attribute common-cause variation to an assignable cause).
The second mistake occurs when you miss a signal (i.e., when we attribute assignable-cause
variation to common causes).
Both mistakes are costly. The trick is to avoid the losses caused by these mistakes. You can
avoid making the first mistake if you consider variation to be noise. But, in doing this, your
losses from the second mistake will increase. In a similar manner, you can avoid making the
second mistake if you consider each value a signal indicator. But, in doing this, your losses from
the first mistake will increase.
In our world, when using historical data, it's impossible to avoid both mistakes completely. So,
given that both mistakes will be made occasionally, what can we do? Shewhart realized it's
possible to regulate the frequencies of both mistakes to minimize economic loss. Subsequently,
he developed a control chart with three-sigma limits. Three-sigma limits filter out nearly all
probable noise (the common-cause variation) and isolate the potential signals (the assignable-
cause variation).
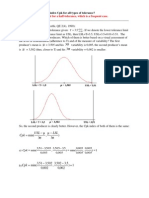
How is it possible that three-sigma limits filter out virtually all probable noise? While there are
certain mathematical inequalities that guarantee most data sets will require at least 95 percent
of the values within three standard deviations of the average, a better rule of practice is the
Empirical Rule, which states that about 99 percent to 100 percent of the data will be located
within three standard deviations, either above or below the average.
Figure 1 displays six theoretical distributions to illustrate the Empirical Rule's appropriateness.
It shows the area within three standard deviations of the mean. No matter how skewed or
"heavy tailed" the distribution may be, virtually all of the area under the distribution curve will
fall within three standard deviation units of the mean. When applied to homogeneous data
sets, the Empirical Rule suggests that no matter how the data "behave," virtually all of the data
will fall within three standard deviation units of the average. Because data that display
statistical control are, by definition, reasonably homogeneous, the Empirical Rule explains why
the control chart will yield very few instances of noise interpreted as a signal.
Figure 1 also shows that three-sigma limits will indeed filter out nearly all common-cause
variation displayed by predictable processes.
Three-sigma limits allow you to detect the process changes that are large enough to be
economically important, while filtering out almost all common-cause variation. These limits
allow you to strike a balance between the losses associated with interpreting noise as a signal
and attributing assignable-cause variation to common causes.
Wheeler’s SPC Toolkit 1996-97 Pag 7 di 36
What About Charts for Count Data?
Deciding which probability model is appropriate requires judgment that most students of
statistics do not possess.
Some data consist of counts rather than measurements. With count data, it has been tradition
to use a theoretical approach for constructing control limits rather than an empirical approach
for making measurements. The charts obtained by this theoretical approach have traditionally
been known as "attribute charts." There are certain advantages and disadvantages of these
charts.
Count data differ from measurement data in two ways. First, count data possess a certain
irreducible discreteness that measurement data do not. Second, every count must have a
known "area of opportunity" to be well-defined.
With measurement data, the discreteness of the values is a matter of choice. This is not the
case with count data, which are based on the occurrence of discrete events (the so-called
attributes). Count data always consist of integral values. This inherent discreteness is,
therefore, a characteristic of the data and can be used in establishing control charts.
The area of opportunity for any given count defines the criteria by which the count must be
interpreted. Before two counts may be compared, they must have corresponding (i.e., equally
sized) areas of opportunity. If the areas of opportunity are not equally sized, then the counts
must be converted into rates before they can be compared effectively. The conversion from
counts to rates is accomplished by dividing each count by its own area of opportunity.
These two distinctive characteristics of count data have been used to justify different
approaches for calculating the control limits of attribute charts. Hence, four control charts are
commonly associated with count data-the np-chart, the p-chart, the c-chart and the u-chart.
However, all four charts are for individual values.
The only difference between an XmR chart and an np-chart, p-chart, c-chart or u-chart is the
way they measure dispersion. For any given set of count data, the X-chart and the four types of
charts mentioned previously will show the same running records and central lines. The only
difference between these charts will be the method used to compute the distance from the
central line to the control limits.
The np-, p-, c- and u-charts all assume that the dispersion is a function of the location. That is,
they assume that SD(X) is a function of MEAN(X). The application of the relationship between
the parameters of a theoretical probability distribution must be justified by establishing a set of
conditions. When the conditions are satisfied, the probability model is likely to approximate the
behavior of the counts when the process displays a reasonable degree of statistical control.
Yet, deciding which probability model is appropriate requires judgment that most students of
statistics do not possess. For example, the conditions for using a binomial probability model
may be stated as:
Binomial Condition 1: The area of opportunity for the count Y must consist of n distinct items.
Binomial Condition 2: Each of the n distinct items must be classified as possessing, or not
possessing, some attribute. This attribute is usually a type of nonconformance to specifications.
Binomial Condition 3: Let p denote the probability that an item has the attribute being
counted. The value of p must be the same for all n items in any one sample. While the chart
checks if p changes from sample to sample, the value of p must be constant within each
sample. Under the conditions, which are considered to be in a state of statistical control, it
must be reasonable to assume that the value of p is the same for every sample.
Binomial Condition 4: The likelihood that an item possessing the attribute will not be affected
if the preceding item possessed the attribute. (This implies, for example, that nonconforming
items do not naturally occur in clusters, and counts are independent of each other.)
If these four conditions apply to your data, then you may use the binomial model to compute
an estimate of SD(X) directly from your estimate of MEAN(X). Or, you could simply place the
counts (or proportions) on an XmR chart and estimate the dispersion from the moving range
Wheeler’s SPC Toolkit 1996-97 Pag 8 di 36
chart. You will obtain essentially the same chart either way.
Unlike attribute charts, XmR charts assume nothing about the relationship between the
location and dispersion. It measures the location directly with the average, and it measures the
dispersion directly with the moving ranges. Thus, while the np-, p-, c- and u-charts use
theoretical limits, the XmR chart uses empirical limits. The only advantage of theoretical limits
is that they include a larger number of degrees of freedom, which means that they stabilize
more quickly.
If the theory is correct, and you use an XmR chart, the empirical limits will be similar to the
theoretical limits. However, if the theory is wrong, the theoretical limits will be wrong, and the
empirical limits will still be correct.
You can't go far wrong using an XmR chart with count data, and it is generally easier to work
with empirical limits than to verify the conditions for a theoretical model.
Which Chart Should I Use?
In the previous columns, we saw examples of the basic control chart for individual values. This
chart is recommended whenever you obtain data one value per time period, or one value per
shipment.
The second major type of control chart is used when the data have been arranged into
subgroups. Here we are typically concerned with data where several values are obtained in a
short period of time. For example, an auto plant in Portugal received shipments from a supplier
in Germany. The part was a piece of wire for connecting the horn buttons to steering wheels.
These wires were supposed to be 100 mm long. Every time they received a shipment, the
Portuguese selected five wires and measured the lengths. The data for the first four shipments
and a table of control chart constants are shown below:
A "subgroup" should consist of a set of measurements which, in the user's judgment, represent
essentially the same set of conditions. The concept here is that while each subgroup should be
more or less homogeneous, the control chart will examine the data to see if there are
differences from one subgroup to another. In this example, each set of five measurements
came from one shipment. The pieces of wire in each shipment were made in the same short
production run and under essentially the same conditions. Therefore it is logical to make each
shipment a subgroup.
With subgrouped data, we plot the subgroup averages and subgroup ranges. Therefore, we
must begin by computing averages and ranges for each subgroup. For each shipment, the
average of the five values will be the subgroup average. The range of a subgroup will be the
difference between the maximum value and the minimum value in that subgroup. For the first
shipment, the maximum value is 115.2, while the minimum value is 112. Thus the subgroup
range is: 115.2 ­p; 112.0 = 3.2 units.
After the average and range have been computed for each subgroup, these values are plotted
in two running records. Conventionally, the averages are plotted on the upper running record
and the ranges are plotted on the lower running record.
The limits for this average and range chart are computed from the data according to the
following steps:
Wheeler’s SPC Toolkit 1996-97 Pag 9 di 36
The average of the subgroup averages is obtained. This value is called the grand average. Here
the grand average is 112.45. This value will be the central line for the upper portion of the
chart.
The average of the subgroup ranges, called the average range, is also obtained. Here the
average range is 4.725. This value will be the central line for the lower portion of the chart.
The control limits for the average and range chart are computed using the grand average and
the average range. The upper control limit for the average chart will be:
Grand Average + (A2 times Average Range)
= 112.45 + (0.577 x 4.725) = 115.2
The lower control limit for the average chart is:
Grand Average - (A2 times Average Range)
= 112.45 - (0.577 x 4.725) = 109.7
The upper control limit for the range chart is:
D4 times Average Range = 2.114 x 4.725 = 10.0
where A2 and D4 are the appropriate control chart constants for a given subgroup size. They
are those values which allow us to convert the grand average and the average range into
control limits.
As may be seen on the average and range chart, one average and one range fall outside their
limits. Shipment Two has a lower average and a greater range than the other shipments. Due
to the way the data were arranged into subgroups, the average chart characterizes each
shipment's location-the average length of the wires in that shipment, while the range chart
characterizes each shipment's consistency-the dispersion of the lengths of the wires in each
shipment.
Clearly, the four shipments have different locations and dispersion. Moreover, since the target
is 100 mm, all shipments were far above the target. Based on this record of inconsistency, both
within and between the shipments, the German supplier was dropped. The other suppliers were
much more consistent in the product they delivered.
This example serves to introduce the second of the two major types of control charts-charts for
subgrouped data. When several values are collected under essentially the same conditions, it is
logical to place these values in subgroups and use an average and range chart. The key to
effective average and range charts is to have subgroups that are internally homogeneous. This
is, of course, a judgment made by the user. It is the means by which users get to bring their
process knowledge to bear upon the chart.
When the data are collected in such a way that each value may differ from the others, it is
logical to place the data on a chart for individual values. This commonly occurs when the
values are obtained individually.
Wheeler’s SPC Toolkit 1996-97 Pag 10 di 36
While there are other types of control charts, they are all special cases of the two charts above.
They are either charts for subgrouped data, or charts for individual values. Once you have
learned how to use an average and range chart and a chart for individual values, you can work
with virtually any type of data, in any type of situation.
When Do I Recalculate My Limits?
Correct limits allow the user to separate probable noise from potential signals.
Of all the questions about Shewhart's charts, this is perhaps the most frequently asked
question. While there is no simple answer, there are some useful guidelines.
The first guideline for computing limits for Shewhart's charts is: You get no credit for computing
the right number-only for taking the right action.
Without the follow-through of taking the right action, the computation of the right number is
meaningless. Now, this is contrary to everyone's experience with arithmetic. Early on we are
trained to "find the right number." Thus, when people are introduced to Shewhart's charts, this
natural anxiety will surface in the form of questions about how to get the "right limits."
While there are definite rules for computing limits, and right and wrong ways of computing
such limits, the real power of Shewhart's charts lies in the organization's ability to use them to
understand and improve their processes. This use of Shewhart's charts-as an aid for making
decisions-is the true focal point of the charts. But it is so easy to miss and so hard to teach.
The second guideline for computing limits for Shewhart's charts is: The purpose of the limits is
to adequately reflect the voice of the process.
As long as the limits are computed in the correct way and reflect the voice of the process, then
they are "correct limits." (Notice that the definite article is missing-they are just "correct limits,"
not "the correct limits.") Correct limits allow the user to separate probable noise from potential
signals. Shewhart's charts are a tool for filtering out the probable noise. They have been proven
to work in more than 70 years of practice.
Shewhart deliberately chose three-sigma limits. He wanted limits wide enough to filter out the
bulk of the probable noise so that people wouldn't waste time interpreting noise as signals. He
also wanted limits narrow enough to detect the probable signals so that people wouldn't miss
signals of economic importance. In years of practice he found that three-sigma limits provided
a satisfactory balance between these two mistakes.
Therefore, in the spirit of striking a balance between the two mistakes above, the time to
recompute the limits for Shewhart's charts comes when, in your best judgment, they no longer
adequately reflect the voice of the process.
The third guideline for computing limits for Shewhart's charts is: Use the proper formulas for
the computations. The proper formulas for the limits are well-known and widely published.
Nevertheless, novices continually think that they know better and invent shortcuts that are
wrong.
The proper formulas for average and range charts will always use an average or median
dispersion statistic in the computations. No formula that uses a single measure of dispersion is
correct. The proper formula for X-charts (charts for individual values) will always use an
average moving range or a median moving range.
Within these three guidelines lies considerable latitude for computing limits. As Shewhart said,
it is mostly a matter of "human judgment" about the way the process behaves, about the way
the data are collected and about the chart's purpose. Computations and revisions of limits that
heed these three guidelines will work. Calculations that ignore these guidelines won't.
Wheeler’s SPC Toolkit 1996-97 Pag 11 di 36
So, in considering the recalculation of limits, ask yourself:
- Do the limits need to be revised in order for you to take the proper action on the process?
- Do the limits need to be revised to adequately reflect the voice of the process?
- Were the current limits computed using the proper formulas?
So, if the process shifts to a new location and you don't think there will be a change in
dispersion, then you could use the former measure of dispersion, in conjunction with the new
measure of location, to obtain limits in a timely manner. It is all a matter of judgment.
Remember, Shewhart's charts are intended as aids for making decisions, and as long as the
limits appropriately reflect what the process can do, or can be made to do, then they are the
right limits. This principle is seen in the questions used by Perry Regier of Dow Chemical Co.:
- Do the data display a distinctly different kind of behavior than in the past?
- Is the reason for this change in behavior known?
- Is the new process behavior desirable?
- Is it intended and expected that the new behavior will continue?
If the answer to all four questions is yes, then it is appropriate to revise the limits based on
data collected since the change in the process.
If the answer to question 1 is no, then there should be no need for new limits.
If the answer to question 2 is no, then you should look for the assignable cause instead of
tinkering with the limits.
If the answer to question 3 is no, then why aren't you working to remove the detrimental
assignable cause instead of tinkering with the limits?
If the answer to question 4 is no, then you should again be looking for the assignable cause
instead of tinkering with the limits. The objective is to discover what the process can do, or can
be made to do.
Finally, how many data are needed to compute limits? Useful limits may be computed with
small amounts of data. Shewhart suggested that as little as two subgroups of size four would
be sufficient to start computing limits. The limits begin to solidify when 15 to 20 individual
values are used in the computation. When fewer data are available, the limits should be
considered "temporary limits." Such limits would be subject to revision as additional data
become available. When more than 50 data are used in computing limits, there will be little
point in further revisions of the limits.
So stop worrying about the details of computing limits for Shewhart's charts and get busy using
them to understand and improve your processes.
Description or Analysis?
Analysis discourages inappropriate actions by filtering out the noise before potential signals
are identified.
The supervisor of Department 17 has just been asked to write a report-the in-process inventory
of his department was at an all-time high of 2,800 pounds last month. He had to explain this
value at the next management meeting, so he began by analyzing the numbers.
First he looked at the current value of the inventory. The value of 2,800 pounds was 42 percent
above the "plan value." It was also 12 percent above the value for the same month last year.
There was no joy to be found in its current value.
Wheeler’s SPC Toolkit 1996-97 Pag 12 di 36
Next he looked at the year-to-date average of the in-process inventory for Department 17. The
value was 2,160 pounds, which was 9.6 percent above the plan and 5.9 percent above the
year-to-date value for the same month last year-two more bad values.
Then the supervisor compared the percentage differences with the percentage changes in
other departments. He prepared a bar graph for all the measures listed on the monthly report
and discovered that the 42-percent value was the greatest percentage difference on the report.
No luck here, either. In fact, having the greatest percentage difference, he realized that other
managers would start the meeting by asking for his report.
No matter how he packaged the numbers, the story looked bad. While he was required to
explain these values, he had no idea what to say. So he made up something that sounded
plausible and which shifted the blame to forces beyond his control. He hoped no one would quiz
him too closely on the findings in his report.
Sound familiar? It ought-to this little drama is acted out thousands of times each day. Of
course, there are two problems with this "write a report" approach. The first is that these
reports are usually works of fiction whose sole purpose is to enable some manager to pretend
that something is being done about a perceived problem. The second is that the approach is
based upon the assumption that the current value of the in-process inventory is actually a
signal. But is it a signal-or is it just noise? How can you know?
Before you can detect signals within the data, you must first filter out the probable noise. And
to filter out noise, you must start with past data. In short, the supervisor, with his limited
comparisons, could not fully understand the current values, and he suffered the consequences
of his ignorance.
The traditional analysis is nothing more than a collection of descriptive statistics. These days,
most statistical analyses are little more than description. Bar graphs comparing unlike
measures, pie charts showing proportions and rudimentary comparisons like those in the story
above are more descriptive than anything else.
Descriptive measures are concerned with how much or how many. They provide no insight into
why there are so many, or why there is so much. Because analysis focuses on answering "why"
questions, we must analyze data in the context of the question and begin to separate the
potential signals from the probable noise. Managers beginning the analysis process should start
by looking at a measure in a time series plot, which should include methods for filtering out
routine variation.
So what would the story have been for Department 17 if the manager had analyzed the values
of the in-process inventory? Some of the past monthly in-process inventory values are seen on
the X-chart in Figure 1. The limits on this chart define how large or small a single monthly value
must be before its deviation from the historical average can be measured. Here, a monthly
value in excess of 3,160 would be a signal that the amount of in-process inventory had risen.
Likewise, a monthly value below 850 would signal a fall. In either case, you would be justified in
looking for the cause of such movements.
The July value of 2,800 is not a signal. There is no evidence of any real change in the in-process
inventory. This means that asking for an explanation of July's value was futile. There was
nothing to explain. Department 17 had 2,800 because it was averaging 2,004, and the routine
variation caused about half of the values to fall between 2,004 and 3,160. There is no other
explanation for the value of 2,800. Anything else is pure fiction.
Some may feel disconcerted when they see limits that go from 850 to 3,160. Surely we can
hold the in-process inventory more steadily than that! But that is precisely what cannot be
done. At least it cannot be done unless some fundamental changes are made in the underlying
process.
The natural process limits are the voice of the process. They define what the process will
deliver as long as it continues to operate as consistently as possible. The way to calculate
these limits was discussed in the January 1996 "SPC Toolkit."
Wheeler’s SPC Toolkit 1996-97 Pag 13 di 36
When a process displays a reasonable degree of statistical control, it's operating as consistently
as possible. The process doesn't care whether you like the natural process limits, and it
certainly doesn't know what the specifications may be (specifications should be thought of as
the voice of the customer, which is distinctly different from the voice of the process).
Therefore, if you are not pleased with the amount of variation shown by the natural process
limits, then you must change the underlying process, rather than setting arbitrary goals, asking
for reports, jawboning the workers or looking for alternative ways for computing the limits.
Mere description encourages inappropriate actions. It makes routine variation look like signals
that need attention. In this case, there were no signals in the data, yet traditional ways of
viewing the data didn't reveal this absence of signals. Analysis discourages inappropriate
actions by filtering out the noise before potential signals are identified. The difference is
profound.
Better Graphics
You have 30 seconds to communicate the content of your data to your audience: after 30
seconds, their eyes glaze over and you have lost their attention. So, how do you beat the 30-
second rule? The only reliable way is with a graph. But not all graphs are created equal.
Howard Wainer offers an interesting example of this in the Summer 1996 issue of Chance when
he uses a graphic from the Bureau of the Census' Social Indicators III. Figure 1 shows a
facsimile of this graph.
This bar graph attempts to show two things at once; that the total number of elementary
schools has gone down over the period shown, while the number of private elementary schools
has grown slightly. Figure 1 is not a particularly bad graphic. It is legible, even if the vertical
scale is a bit larger than it needs to be.
However, by placing both measures on the same graph, Figure 1 compresses the time series
for the private schools excessively. One of the principles of good graphics requires that when
the data changes, the graphic should also change. By placing both public and private schools
on the same graph, the difference in magnitude between the two time series makes it
impossible to fully comprehend the private school time series. Figure 2 shows what Figure 1
obscures: a jump in the number of private schools between 1950 and 1960. Of course, the
connected nature of the plot in Figure 2 also helps because it draws the eye the way the mind
wants to go. The bars of Figure 1 do not do this.
Wheeler’s SPC Toolkit 1996-97 Pag 14 di 36
Adding data to Figure 2 will increase insight. By using more points over the same period, the
nature of the changes will be better understood.
Once you have plotted the data in an effective graph, you can see the need to explain certain
data characteristics. While a graph cannot distinguish between an accidental relationship and a
cause-and-effect relationship, it can be the springboard for asking interesting questions. For
example, the baby boom hit elementary schools in 1952. Thus, the trend in Figure 3 lags
behind the increases in the sizes of the elementary school cohorts. So, the baby boom as a
possible explanation is not convincing.
Another possible explanation is the 1954 Supreme Court decision Brown vs. Topeka School
Board, which declared segregated public schools to be illegal. During the following decade,
many private schools were started. This trend continued until the mid-1960s, when two things
happened: the baby boomers were moving on to secondary schools, and the 1964 Civil Rights
Act was passed. Figure 3 does not prove anything, but it certainly does support some
interesting speculation.
Wheeler’s SPC Toolkit 1996-97 Pag 15 di 36
Better graphics communicate the interesting parts of the data more directly. That means that
when the data changes, the graph shows that change. When the data is presented as a time
series, it is better to use connected points than to use a bar chart. The connected points draw
the eye the way the mind wants to go, while the bar chart doesn't do this. The scale should be
sufficient to avoid excessive compression of the graphic. The graphic should "fill up" the graph.
Only rarely will multiple measures be appropriate on a single graph.
Decoration should be avoided. If you denote the points and lines needed to show the data as
"data ink" and denote all other lines, tick-marks, labels and decoration as "nondata ink," better
graphics will always have a high ratio of data ink to nondata ink.
Nowadays, people can easily obtain highly decorated graphs at the push of a button. Yet only
when they understand that the purpose of a graph is to inform rather than to decorate will they
begin to produce better graphics. Experience, practice and good guidance will all help. To this
end, I recommend Edward Tufte's book, The Visual Display of Quantitative Information
(Graphics Press, Cheshire, Connecticut).
Global Warming?
Global warming is a theory in search of supporting data. However, in the search for supporting
data, we should avoid misinterpreting our data.
In the July 4, 1996, issue of Nature, Santer et al. use data such as those in Figure 1 as evidence
of global warming. The values shown represent the annual average air temperatures between
5,000 feet and 30,000 feet at the midlatitude of the Southern Hemisphere. The zero line on the
graph represents the normal temperature, and the values plotted are the deviation from the
norm for each year.
Wheeler’s SPC Toolkit 1996-97 Pag 16 di 36
The data of Figure 1 show a clear upward trend between 1963 and 1986. However, when we fit
a regression line to data, we are imposing our view upon the data.
If we know of some cause-and-effect mechanism that relates one variable to another, then
regression lines are appropriate. But does the year cause the trend shown in Figure 1? While
regression equations are useful in showing relationships, these relationships may be either
causal or casual. At most, the relationship in Figure 1 is casual.
But is the trend in Figure 1 real? Or is it just noise? This question can be answered in two ways:
Check for internal evidence of a trend with a control chart, and check for external evidence of a
trend by adding more data as they become available. Figure 2 shows these 24 data on an X-
chart. The values for 1963, 1978, 1980 and 1986 all appear to differ from the norm. Hence, the
"cool" year of 1963 combined with the "warm" years of 1977 through 1986 do suggest a
possible trend. So there is some internal evidence for a trend in these data.
The limits can be adjusted for this possible trend in the following manner. Compute the average
for the first half of the data. Years 1963 through 1974 had an average of &endash;0.74° C. Plot
this average vs. the midpoint of this period of time -- halfway between 1968 and 1969.
Compute the average for the last half of the data. Years 1975 through 1986 had an average of
4.55° C. Plot this value vs. the point halfway between 1980 and 1981. Connect these two points
to establish a trend line.
The distance from the central line to the limits in Figure 2 was found by multiplying the average
moving range by the scaling factor of 2.660. The average moving range is 2.663° C. Thus,
limits will be placed on either side of the trend line at a distance of: 2.660 x 2.663° C = 7.08° C
(see Figure 3).
So the internal evidence is consistent with a trend for these data. But what about the external
evidence? Professor Patrick Michaels of the University of Virginia added six prior years and
eight following years to the data of Figure 1 (see Figure 4).
Wheeler’s SPC Toolkit 1996-97 Pag 17 di 36
So, if the data for 1963 through 1986 are evidence of global warming, then the subsequent
data show that we solved the problem of global warming in 1991. However, if the interpretation
of the data for 1963 through 1986 is merely wishful thinking, then we may still have some work
to do.
The 38 values are placed on an X-chart in Figure 5. Once again, the central line is taken to be
zero in order to detect deviations from the norm.
So while 1963 was cooler than the norm, and while 1977 through 1990 were detectably warmer
than the norm, there is no evidence in these data to support the extrapolation of the trend line
shown in Figure 1. Obviously, there are cycles in the global climate, and any substantial
evidence for global warming will require a much longer baseline.
The first principle for understanding data is: No data have meaning apart from their context.
We cannot selectively use portions of the data to make our point and ignore other portions that
contradict it.
The second principle is: While all data contain noise, some data may contain signals. Therefore,
before you can detect a signal, you must first filter out the noise. While there are some signals
in these data, there is no evidence of a sustained trend.
Good Limits From Bad Data (Part I)
There are right and wrong ways of computing limits. Many technical journals and much
software use the wrong methods.
Charles, from the home office, was pushing the plant manager to start using control charts. The
plant manager didn't know where to start, so he asked what he should be plotting. Charles
responded that he might want to start with the data they were already collecting in the plant.
To start, they checked the log sheet for batch weights -- a page where the mix operators had
written down the weight of each batch they produced. Charles began to plot the batch weights
on a piece of graph paper. After filling up the first page, he computed limits for an XmR chart.
Of course, the chart was out-of-control and the process was unpredictable. Even though every
batch was weighed and the operators wrote down each weight, the log did not enable them to
produce batches with consistent weights. Unpredictable weights meant that the formulation
was changing in unpredictable ways, which translated into a sense of fatalism downstream.
Wheeler’s SPC Toolkit 1996-97 Pag 18 di 36
How could Charles determine that the process was unpredictable when he was using the data
from the unpredictable process to compute the limits? The answer has to do with the way the
limits are computed. There are right and wrong ways of computing limits. This column
illustrates this difference for the XmR chart.
The first 20 batch weights were:
920 925 830 855 905 925 945
915 940 940 910 860 865 985
970 940 975 1,000 1,035 1,040
The central line for the X chart is commonly the average of the individual values. For these 20
values, the average is 934. (Alternate choices for the central line are a median for the
individual values or, occasionally, when we are interested in detecting deviations from a norm,
a target or nominal value.)
Both of the correct methods for computing limits for the XmR chart begin with the computation
of the moving ranges. Moving ranges are the differences between successive values. By
convention, they are always non-negative. For the 20 data above, the 19 moving ranges are:
5 95 25 50 20 20
30 25 0 30 50 5 120
15 30 35 25 35 5
Correct Method 1:
The most common method of computing limits for XmR charts is to use the average moving
range, which is commonly denoted by either of the symbols: R or mR. The limits for the X chart
will be found by multiplying the average moving range by the scaling factor of 2.660, and then
adding and subtracting this product from the central line. For these data, the average moving
range is: mR = 32.63, so multiplying by 2.660 gives 86.8, and the limits for the individual
values are placed at: 934 ± 86.8 = 847.2 to 1,020.8.
The upper limit for the moving range chart is found by multiplying the average moving range
by the scaling factor 3.268. For these data, this limit is 106.6. Figure 1 shows the XmR chart for
these 20 batch weights. (Notice that the chart in Figure 1 shows three separate signals of
unpredictable variation, even though the data from the unpredictable process were used to
compute the limits.)
Correct Method 2:
The other correct method of computing limits for a chart for individual values is to use the
median moving range, which is commonly denoted by either of the symbols: R or mR. The
limits for the X chart may be found by multiplying the median moving range by the scaling
Wheeler’s SPC Toolkit 1996-97 Pag 19 di 36
factor of 3.145, and then adding and subtracting this product from the central line. For these 19
moving ranges, the median moving range is mR = 30.
Multiplying by the scaling factor of 3.145 gives 94.4, and the limits for the X chart are placed
at: 934 ± 94.4 = 839.6 to 1,028.4. The upper limit for the mR chart is: 3.865 x 30 = 116.0.
These limits are slightly wider than those in Figure 1. However, the same points that fell outside
the limits in Figure 1 would still be outside the limits based upon the median moving range.
There is no practical difference between these two correctly computed sets of limits.
An incorrect method:
A common, but incorrect, method for computing limits for an X chart is to use some measure of
dispersion that is computed using all of the data. For example, the 20 data could be entered
into a statistical calculator, or typed into a spreadsheet, and the standard deviation computed.
The common symbol for this statistic is the lowercase letter "s." For these data: s = 56.68.
This number is then erroneously multiplied by 3.0, and the product is added and subtracted to
the central line to obtain incorrect limits for the X chart: 934 ± 170.0 = 764 to 1,104. Figure 2
shows these limits.
Notice that the chart in Figure 2 fails to detect the signals buried in these data. It is this failure
to detect the signals which are clearly indicated by the other computational methods that
makes this approach incorrect.
Note that it is the methodology of computing a measure of dispersion, rather than the choice of
dispersion statistic, that is the key to the right and wrong ways of obtaining limits. If we used
the range of all 20 data (1,040 - 830 = 210), we would obtain incorrect limits of: 934 ±
(3)(210)/3.735 = 934 ± 168.7 = 765.3 to 1,102.7, which are essentially the same as in Figure
2.
Conclusion
The right ways of computing limits will allow us to detect the signals within the data in spite of
the fact that we used the data containing the signals in our computations. They are always
based upon either an average or median dispersion statistic.
The wrong ways of computing limits will inevitably result in inflated limits when signals are
present within the data, and thus they will tend to hide the very signals for which we are
looking. The wrong ways tend to be based upon a single measure of dispersion that was
computed using all of the data.
This distinction between the right and wrong ways of computing limits has not been made clear
in most books about SPC, but it was there in Shewhart's first book. Many recent articles and
software packages actually use the wrong methods. I can only assume it is because novices
have been teaching neophytes for so many years that the teaching of SPC is out of control.
Wheeler’s SPC Toolkit 1996-97 Pag 20 di 36
Good Limits From Bad Data (Part II)
Continuing the theme from last month, this column will illustrate the difference between the
right and wrong ways of computing limits for average charts.
We begin with a data set consisting of k = 6 subgroups of size n = 4:]
Subgroup -1- -2- -3- -4- -5- -6-
Values 4 0 8 6 3 8
5 2 4 9 2 7
5 1 3 9 0 9
4 5 7 7 3 9
Averages 4.5 2.0 5.5 7.75 2.0 8.25
Ranges 1 5 5 3 3 2
The central line for the average chart (also known as an X-bar chart) is commonly taken to be
the grand average. For these data, the grand average is 5.00.
Average charts done right
The most common method of computing limits for average charts is to use the average range.
The limits for the average chart may be found by multiplying the average range by the scaling
factor A2, and then adding and subtracting this product from the central line.
For these data, the average range is 3.167 and the value of A2 for subgroup size n = 4 is
0.729, therefore the product is 2.31, and the limits for the average chart are: 5.00 ± 2.31 =
2.69 to 7.31.
Instead of using A2 times the average range, you may use any one of several alternatives as
long as you use the correct scaling factors. Some appropriate substitutions are: A4 times the
median range (2.27), A1 times the average RMS deviation (2.44) and A3 times the average
standard deviation (2.44).
While there are other valid alternatives, the four above are the ones most commonly used.
Tables of the scaling factors are found in most textbooks on SPC. No matter which of the
Wheeler’s SPC Toolkit 1996-97 Pag 21 di 36
computational alternatives is used, the chart looks the same: Subgroups 2 and 5 have
averages below the lower limit, and subgroups 4 and 6 have averages above the upper limit.
Thus, all of the correct ways of computing limits for an average chart allow you to obtain good
limits from bad data -- that is, we are able to detect the lack of statistical control even though
we are using the out-of-control data to compute the limits. Of course, this property is subject to
the requirement that the subgrouping is rational -- that each subgroup is logically
homogeneous. As Shewhart observed, the issue of subgrouping is essentially a matter of
judgment. Based on the context for the data, we must be able to argue that the values
collected together within any one subgroup can be thought of as having been collected under
essentially the same conditions. For more on this topic, see this column in the April 1996 issue
of Quality Digest.
Average charts done wrong
Perhaps the most common mistake made in computing limits for an average chart is the use of
a single measure of dispersion computed using all of the data. If all 24 values were entered into
a spreadsheet or statistical calculator, and the standard deviation computed, we would get the
value: s = 2.904.
When this global measure of dispersion is used (inappropriately) to compute limits for an
average chart, it is divided by the square root of the subgroup size and multiplied by 3.0. This
would result in a value of 4.356, which would yield incorrect limits for the average chart of:
5.00 ± 4.36 = 0.64 to 9.36.
This method of computing limits for the average chart is wrong because it results in limits that
do not detect the signals contained in the data. This approach gives you bad limits from bad
data because the computation of a single measure of dispersion using all of the data makes an
implicit assumption that the data are globally homogeneous. In short, this computation
assumes that there is no possibility of any signals within the data, and so it makes sure that
you do not find any signals.
Wheeler’s SPC Toolkit 1996-97 Pag 22 di 36
Average charts done very wrong
The second most common mistake in computing limits for an average chart is the use of a
single measure of dispersion computed using all of the subgroup averages. If the six subgroup
averages were typed into a spreadsheet or entered in a statistical calculator, and the standard
deviation computed, we would get the value: s = 2.706. Because this is the standard
deviation of the subgroup averages, it is (inappropriately) multiplied by 3.0 and used to
construct incorrect limits for the average chart of: 5.00 ± (3.0) (2.706) = 5.00 ± 8.12 = 3.12 to
13.12.
This method of computing limits does not just bury the signals, it obliterates them. Once again,
we get bad limits from bad data. The calculation of the standard deviation of the subgroup
averages implicitly assumes that the subgroup averages are globally homogeneous; that is,
they do not differ except for noise. Because this method assumes that there is no possibility of
any signals within the data, it makes sure that you do not find any signals.
Conclusion
The only way to get good limits from bad data is to use the correct computational approaches.
These correct methods all rely upon either an average dispersion statistic or a median
dispersion statistic and the appropriate scaling factor.
The wrong methods tend to rely upon a single measure of dispersion computed on a single
pass, using either all the data or all the subgroup averages.
The distinction between the right and wrong ways of computing limits was first made by
Shewhart on page 302 of his book, Economic Control of Quality of Manufactured Product (ASQC
Quality Press). It should not be an issue some 65 years later. The fact that it is an issue
suggests that many people who think they know about control charts didn't get the message.
How can you tell the difference? You can use any out-of-control data set to evaluate software
packages -- they should agree with the limits computed by hand. Or you can look at the
formulas or computations used: If the limits are based upon any measure of dispersion that
doesn't have a bar above it, then the limits are wrong. So, if you now catch someone using any
other way than one of the scaling factor approaches, then you know, beyond any doubt, that in
addition to being wrong, they are also either ignorant or dishonest.
Good Limits From Bad Data (Part III)
Wheeler’s SPC Toolkit 1996-97 Pag 23 di 36
When you use rational sampling and rational subgrouping, you will have powerful charts.
In March and April, this column illustrated the difference between the right and wrong ways of
computing control chart limits. Now I would like to discuss how you can make the charts work
for you.
The calculation of control limits is not the end of the exercise, but rather the beginning. The
chief advantage of control charts is the way they enable people -- to reliably separate potential
signals from the probable noise that is common in all types of data. This ability to characterize
the behavior of a process as predictable or unpredictable, and thereby to know when to
intervene and when not to intervene, is the real outcome of the use of Shewhart's charts. The
computations are part of the techniques, but the real objective is insight, not numbers.
To this end, you will need to organize your data appropriately in order to gain the insights. This
appropriate organization of the data has been called rational sampling and rational
subgrouping.
First, you must know the context for the data. This involves the particulars of how the data
were obtained, as well as some appreciation for the process or operations represented by the
data.
Rational sampling involves collecting data in such a way that the interesting characteristics of
the process are evident in the data. For example, if you are interested in evaluating the impact
of a new policy on the operations of a single office, you will need to collect data that pertains to
that office, rather than for a whole region.
Rational subgrouping has to do with how the data are organized for charting purposes. This is
closely linked to the correct ways of computing limits. With average and range charts (X-bar
and R charts), there will be k subgroups of data. The right way to compute limits for these
charts involves the computation of some measure of dispersion within each subgroup (such as
the range for each subgroup). These k measures then combine into an average measure of
dispersion (such as the average range) or a median measure of dispersion (such as a median
range), and this combined measure of dispersion is then used to compute the limits.
The objective of the control chart is to separate the probable noise from the potential signals.
The variation within the subgroups will be used to set up the limits, which we shall use as our
filters. Therefore, we will want the variation within the subgroups to represent the probable
noise, i.e., we want each subgroup to be logically homogeneous. Shewhart said that we should
organize the data into subgroups based upon our judgment that the data within any one
subgroup were collected under essentially the same conditions.
In order to have a meaningful subgrouping, you must take the context of the data into account
as you create the subgroups. You have to actively and intelligently organize the data into
subgroups in order to have effective average and range charts. When you place two or more
values together in a single subgroup, you are making a judgment that, for your purposes, these
data only differ due to background noise. If they have the potential to differ due to some signal,
then they do not belong in the same subgroup.
This is why the average chart looks for differences between the subgroups while the range
chart checks for consistency within the subgroups. This difference between the charts is
inherent in the structure of the computations -- ignore it at your own risk.
But what if every value has the potential to be different from its neighbors, such as happens
with monthly or weekly values? With periodically collected data, the chart of preference is the
chart for individual values and a moving range (the XmR chart). Here, each point is allowed to
sink or swim on its own. The moving range approach to computing limits uses short-term
variation to set long-term limits. In this sense, it is like the average chart, where we use the
variation within the subgroups to set the limits for the variation between the subgroups.
Wheeler’s SPC Toolkit 1996-97 Pag 24 di 36
While the right ways of computing limits will allow you to get good limits from bad data, the
chart will be no better than your organization of the data. When you use rational sampling and
rational subgrouping, you will have powerful charts.
If you organize your data poorly, you can end up with weak charts that obscure the signals.
Until you have the opportunity to develop subgrouping skills, it is good to remember that it is
hard to mess up the subgrouping on an XmR chart.
How Much Data Do I Need?
The relationship between degrees of freedom and the coefficient of variation is the key to
answering the question of how much data you need.
How much data do I need to use when I compute limits?" Statisticians are asked this question
more than any other question. This column will help you learn how to answer this question for
yourself.
Implicit in this question is an intuitive understanding that, as more data are used in any
computation, the results of that computation become more reliable. But just how much more
reliable? When, as more data become available, is it worthwhile to recompute limits? When is it
not worthwhile? To answer these questions, we must quantify the two concepts implicit in the
intuitive understanding: The amount of data used in the computation will be quantified by
something called "degrees of freedom," and the amount of uncertainty in the results will be
quantified by the "coefficient of variation."
The relationship between degrees of freedom and the coefficient of variation is the key to
answering the question of how much data you need. The terminology "degrees of freedom"
cannot be explained without using higher mathematics, so the reader is advised to simply use
it as a label that quantifies the amount of data utilized by a given computation.
The effective degrees of freedom for a set of control limits will depend on the amount of data
used and the computational approach used. For average and range charts (X-bar and R charts),
where the control limits are based upon the average range for k subgroups of size n, the
degrees of freedom for the limits will be: d.f. ~ 0.9k(n1). For example, in April's column, limits
were computed using k = 6 subgroups of size n = 4. Those limits could be said to possess: 0.9
(6) (3) = 16.2 degrees of freedom.
For average and standard deviation charts (X-bar and s charts), where the control limits are
based on the average standard deviation for k subgroups of size n, the degrees of freedom for
the limits will be: d.f. ~ k(n1) 0.2(k1). In my April column, if I had used the average standard
deviation to obtain limits, I would have had: (6) (3) 0.2 (5) = 17 degrees of freedom. As will be
shown below, the difference between 16 d.f. and 17 d.f. is of no practical importance.
For XmR charts, with k subgroups of size n = 1, and limits based on the average moving range,
the degrees of freedom for the limits will be: d.f. ~ 0.62 (k1). In my March column, I computed
limits for an XmR chart using 20 data. Those limits possessed: 0.62 (19) = 11.8 degrees of
freedom.
The better SPC textbooks give tables of degrees of freedom for these and other computational
approaches. However, notice that the formulas are all functions of n and k, the amount of data
available. Thus, the question of "How much data do I need?" is really a question of "How many
degrees of freedom do I need?" And to answer this, we need to quantify the uncertainty of our
results, which we shall do using the coefficient of variation.
Wheeler’s SPC Toolkit 1996-97 Pag 25 di 36
Control limits are statistics. Thus, even when working with a predictable process, different data
sets will yield different sets of control limits. The differences in these limits will tend to be
small, but they will still differ.
We can see this variation in limits by looking at the variation in the average ranges. For
example, consider repeatedly collecting data from a predictable process and computing limits.
If we use k = 5 subgroups of size n = 5, we will have 18 d.f. for the average range. Twenty such
average ranges are shown in the top histogram of Figure 1.
If we use k = 20 subgroups of size n = 5, we will have 72 d.f. for the average range. Twenty
such average ranges are shown in the bottom histogram of Figure 1. Notice that, as the
number of degrees of freedom increase, the histogram of the average ranges becomes more
concentrated. The variation of the statistics decreases as the degrees of freedom increase.
A traditional measure of just how much variation is present in any measure is the coefficient of
variation, which is defined as:
CV = standard deviation of measure/mean of measure
Examining Figure 1, we can see that as the degrees of freedom go up, the coefficient of
variation for the average range goes down. This relationship holds for all those statistics that
we use to estimate the standard deviation of the data. In fact, there is a simple equation that
shows the relationship. For any estimate of the standard deviation of X:
CV = 1/sq.rt.(2d.f.)
This relationship is shown in Figure 2.
So just what can you learn from Figure 2? The curve shows that when you have very few
degrees of freedom -- say less than 10 -- each additional degree of freedom that you have in
Wheeler’s SPC Toolkit 1996-97 Pag 26 di 36
your computations results in a dramatic reduction in the coefficient of variation for your limits.
Since degrees of freedom are directly related to the number of data used, Figure 2 suggests
that when we have fewer than 10 d.f., we will want to revise and update our limits as additional
data become available.
The curve in Figure 2 also shows that there is a diminishing return associated with using more
data in computing limits. Limits based upon 8 d.f. will have half of the variation of limits based
upon 2 d.f., and limits based upon 32 d.f. will have half of the uncertainty of limits based upon
8 d.f. Each 50-percent reduction in variation for the limits requires a four-fold increase in
degrees of freedom. As may be seen from the curve, this diminishing return begins around 10
degrees of freedom, and by the time you have 30 to 40 d.f., your limits will have solidified.
So, if you have fewer than 10 degrees of freedom, consider the limits to be soft, and recompute
the limits as additional data become available. With Shewhart's charts, 10 degrees of freedom
require about 15 to 24 data. You may compute limits using fewer data, but you should
understand that such limits are soft. (While I have occasionally computed limits using as few as
two data, the softest limits I have ever published were based on four data!)
When you have fewer than 10 d.f. for your limits, you can still say that points which are
comfortably outside the limits are potential signals. Likewise, points comfortably inside the
limits are probable noise. With fewer than 10 d.f., only those points close to the limits are
uncertain.
Thus, with an appreciation of the curve in Figure 2, you no longer must be a slave to someone's
arbitrary guideline about how much data you need. Now you can use whatever amount of data
may be available. You know that with fewer than 10 d.f., your limits are soft, and with more
than 30 d.f., your limits are fairly solid. After all, the important thing is not the limits but the
insight into the process behavior that they facilitate. The objective is not to get the "right"
limits but rather to take the appropriate actions on the process.
So use the amount of data the world gives you, and get on with the job of separating potential
signals from probable noise.
Five Ways to Use Shewhart's Charts
The only limitation on the use of Shewhart's charts is your imagination. And the way to
stimulate your imagination is to begin using this powerful technique yourself.
The many different ways of using control charts in both service and manufacturing applications
may be summarized under five major headings. These five categories are arranged below in
order of increasing sophistication.
1. Report card charts. These charts are kept for the files. They may occasionally be used for
information about how things are going or for verification that something has or has not
occurred, but they are not used in real time for operating or improving the processes and
systems present. This is a valid but weak usage of control charts.
2. Process adjustment charts. Some product characteristics may be plotted on a control chart
and used in a feedback loop for making process adjustments, or some input characteristic may
be tracked and used in a feed-forward loop for the same purpose.
In many cases, these process adjustment charts will result in substantially more consistent
operations than was the case prior to the use of control charts. (This assumes that someone
will know how to properly adjust the process. In some cases, such knowledge can only be
gained by some of the following uses of control charts.) However, once this initial improvement
has been achieved, process adjustment charts simply strive to preserve the new status quo.
Wheeler’s SPC Toolkit 1996-97 Pag 27 di 36
The potential for dynamic and continual improvement is missing from this usage of the charts.
Unfortunately, this seems to be the only usage considered in most of the articles recently
published in trade journals.
3. Process trial charts. These charts analyze the data from simple experiments performed upon
the process.
This short-term usage of control charts is a simple and easy-to-understand alternative to the
use of ANOVA and other statistical techniques. This usage is often found in conjunction with the
next category.
4. Extended monitoring charts. This is the use of multiple control charts to simultaneously track
several related characteristics in order to discover just which charts provide the best predictors
of process or product performance.
This usage will generally involve a project team with a specific mission. It is one of the
preliminary steps for both the effective utilization of control charts and the effective use of
process experiments. Without the constancy of purpose evidenced by extended monitoring and
without the process stability obtained by getting the process into statistical control, it is
doubtful that designed experiments will be of any long-term benefit.
5. The use of control charts for continual improvement. It is rare to begin with this usage of the
charts. In many cases, progress to this last category comes only after extended monitoring
and, possibly, process trials run. The control chart becomes a powerful tool for continual
improvement only as those involved with the process learn how to use the chart to identify and
remove assignable causes of uncontrolled variation. Every out-of-control point is an
opportunity.
But these opportunities can be utilized only by those who have prepared themselves in
advance. SPC is ultimately a way of thinking, with the charts acting as a catalyst for this
thought process.
Lloyd Nelson calls a control chart a "when to fix it" chart. Ed Halteman calls it a "has a change
occurred" chart. Sophronia Ward calls it a "process behavior" chart. All of these alternative
names emphasize the interaction between the user and the chart, which is the secret of how
the simple control chart can be the catalyst for continual improvement.
The only limitation on the use of Shewhart's charts is your imagination. And the way to
stimulate your imagination is to begin using this powerful technique yourself.
Three Types of Action
Shewhart's charts are the one tool that will facilitate the continual improvement of both
process and product.
Prior to the Industrial Revolution, manufacturing consisted of making things by hand. Each part
was custom-made to fit in with the other parts in each assembly, with the result that every
product was unique and expensive.
As early as 1793, Eli Whitney had the idea of the interchangeability of parts. While this idea
was revolutionary, it was also difficult to implement. The problem was how to make the parts
interchangeable. Try as one might, the parts would not turn out to be identical. Therefore,
manufacturers had to be content with making them similar. Specifications were developed to
define how similar the parts had to be in order to fit, and all variation was classified as either
permissible (within the specifications) or excessive (outside the specifications).
The specification was a guide for defining the difference between a "good" part and a "bad"
part. But it did not tell manufacturers how to make good parts, nor did it help them discover
Wheeler’s SPC Toolkit 1996-97 Pag 28 di 36
why bad parts were being produced. All they could do with specifications is sort the good stuff
from the bad stuff at the end of the production line. Thus, manufacturing became an endless
cycle of fabrication, inspection and rework, with some good product escaping every now and
then.
Of course, the customer needed more good product than was leaking out of the manufacturing
process, and so the manufacturers began to write deviations from the specifications in order to
get more good stuff to ship. And this is the origin of the perpetual argument about how good
the parts must be. Manufacturers seek relaxed specifications, customers demand tighter
specifications, and the engineers are caught in the middle.
This conflict obscured the original and fundamental issue -- how to manufacture parts with as
little variation as possible. The original ideal had been to make parts that were essentially
identical. But how can we do this? A state of virtually uniform product can be achieved only
through the careful study of the sources of variation in the process, and through action by
management to reduce -- or to eliminate entirely -- sources of extraneous variation. Shewhart's
charts provide a way to do just this.
Shewhart's control charts allow you to characterize a given process as being predictable or
unpredictable. A predictable process operates as consistently as possible; an unpredictable
process does not. And this distinction is the beginning of the journey of continual improvement.
When your process is unpredictable, it will display excessive variation that can be attributed to
assignable causes. By the very way the charts are set up, it will be worthwhile to look for any
assignable cause of unpredictable process changes. As the charts guide you to those points in
space and time that are connected with the unpredictable process changes, they help you
discover ways to improve your process, often with little or no capital expense.
On the other hand, when your process is predictable, it will be a waste of time to look for
assignable causes of excessive variation. There is no evidence of the presence of assignable
causes, and looking for such will simply be a waste of time and effort. When a process is
already operating as consistently as possible, the only way to improve it will be to change it in
some fundamental manner.
A predictable process operates up to its potential; an unpredictable process does not. Are you
getting the most out of your process?
Shewhart's charts give you the means of identifying the voice of the process. This is distinctly
different from specifications, which are, at best, the voice of the customer. Thus, we need to
distinguish between three different types of action:
1. Specifications are for taking action on the product -- to separate the good stuff from the bad
stuff after the fact.
2. Shewhart's charts are for taking action on the process -- to look for assignable causes when
they are present, with an eye toward process improvement, and to refrain from looking for
assignable causes when they are absent.
3. Actions to align the two voices are desirable -- While this has been tried in the past, the lack
of a well-defined voice of the process has made alignment difficult to achieve.
These three types of action have different objectives. All are valid, all are reasonable, but the
first and the third are strictly concerned with maintaining the status quo. Shewhart's charts are
the one tool that will facilitate the continual improvement of both process and product.
What Is a Rational Subgroup?
Wheeler’s SPC Toolkit 1996-97 Pag 29 di 36
In the April column, I outlined three ways to compute the limits for an average chart: the right
way, a wrong way and a very wrong way. Several readers wrote that they were using the very
wrong way and that they were happy with this method.
I have seen dozens of examples given in attempts to justify the incorrect ways of computing
limits. In every case, the problem was a failure to subgroup the data in a rational manner.
We compute limits for an average chart based upon the average range. The average range is
the average amount of variation within the subgroups. Thus, the limits on an average chart
depend upon the amount of variation inside the subgroups. You must organize the data into
subgroups in such a way that this computation makes sense. We want to collect into each
subgroup a set of values that were collected under essentially the same conditions.
For example, some asthma patients measure their peak exhalation flow rates four times each
day: morning before and after medication, and evening before and after medication. The data
for one patient is shown in Figure 1.
Now think about what happens when we make each column in the table into a subgroup of
size 4. Within each subgroup, we would have the four scores from a single day, and from one
subgroup to the next, we would have the day-to-day variation. But the four scores for a single
day are collected under different conditions!
The variation within a subgroup is more than just background variation -- it includes both the
medication effects and the morning-to-evening swings of the patient. These effects will make
the ranges larger than they need to be to characterize the day-to-day variation. As a result of
this subgrouping, the limits will be far too wide, and the averages and ranges will hug the
central lines. This mistake is called stratification.
What if we made each row of the table into a subgroup of size 5? Now the different conditions
would no longer be contained within the subgroups. But what about the variation inside these
subgroups? With this arrangement of the data, the day-to-day variation would be within each
subgroup. Because the variation within the subgroups is used to construct the limits, this
subgrouping will result in limits that make allowance for the day-to-day variation, but do not
make any allowance for the variation morning to evening, or before and after medication. This
average chart will be "out of control." But did we really need to prove that there is a difference
morning to evening and pre-medication to post-medication? Unless we are trying to document
these differences, this is an inappropriate subgrouping.
So we must avoid the two errors of stratification and inappropriate subgrouping. Two conditions
are required for any subgrouping to be rational: Each subgroup must be logically
homogeneous, and the variation within the subgroups must be the proper yardstick for setting
limits on the routine variation between subgroups.
When the values within the subgroups are not collected under essentially the same conditions,
you have failed to satisfy the homogeneity condition.
When the variation from subgroup to subgroup represents sources of variation that are not
present within the subgroups, and when these sources of variation from subgroup to subgroup
are known to be larger than the sources of variation within the subgroups, then you have failed
the yardstick criterion.
Wheeler’s SPC Toolkit 1996-97 Pag 30 di 36
In either case, the computations will break down because you will have failed to create rational
subgroups. The remedy is not to change the computations, but to change the subgrouping into
one that is appropriate for your data.
While the data in the table do constitute a time series, they are not easily arranged into
rational subgroups because each value is collected under different conditions. In other words,
our logical subgroup size is n = 1. You will learn more about the data in the table by plotting
them as a time series of 20 values than you ever will by subgrouping them and using an
average and range chart.
At the same time, you should resist the temptation to turn this time series of 20 values into an
XmR chart. The fact that this time series is a mixture of values collected under different
conditions will contaminate the moving ranges and make the limits meaningless.
There is more to rational subgrouping than can be presented in this column. However, the two
principles above should get you started down the right road.
Collecting Good Count Data
Obtaining good count data is a mixture of planning and common sense
Counts are simple. But obtaining the count is only half the job. In addition, you also must know
the area of opportunity for that count. In fact, the area of opportunity defines the count.
And just what is the area of opportunity for a count? It depends on what is being counted, how
it is being counted and what possible restrictions there might be upon the count.
Let's begin with the problem of tracking complaints. How do you count them? Do you count the
number of complaints received each month? Or do you count the number of customers who
complained? You will need careful instruction before you can begin to collect useful count data.
A certain pediatrics unit reported the number of concerns on a monthly basis. The values for
one period of 21 months were, respectively, 20, 22, 9, 12, 13, 20, 8, 23, 16, 11, 14, 9, 11, 3, 5,
7, 3, 2, 1, 7 and 6. But even though you know the counts, you don't know the whole story
because you don't know the context for the counts. Before anyone can make sense of these
counts, certain questions must be answered.
For instance, how is "concern" defined? Are these customer complaints or internally generated
counts? Where is the border between a concern and a nonconcern?
Why does the number of concerns drop? And what about the rumor that the hospital
administrator is using these numbers to challenge the orthopedics unit to improve?
If you don't know the area of opportunity for a count, you don't know how to interpret that
count.
If the area of opportunity changes over time, then the counts will not be comparable. To obtain
comparable values when the area of opportunity changes, you must divide each count by its
area of opportunity.
Let's assume that concerns is just an antiseptic term for complaints. You could characterize the
area of opportunity for these complaints in several ways: by the number of office visits,
procedures performed or hours worked by primary caregivers. The area of opportunity will
determine the ways you can use the counts to understand your process. And what constitutes
a complaint? Does a complaint about a chilly reception room count?
Wheeler’s SPC Toolkit 1996-97 Pag 31 di 36
Don't despair. You can collect useful count data. The essence of the count data problem is
twofold: What should you include in your count, and what area of opportunity would you use to
adjust the counts to make them comparable?
Begin with a written description of what to include in your count. What is the threshold for
inclusion? Give examples; the more specific the better.
Next, what is an appropriate area of opportunity for your count? You must choose an area that
can be measured or counted, and that bears some clear relationship to the count. The test here
is rationality. Find some logical connection between the size of the area of opportunity and the
size of the count. Any one count may have several possible ways to characterize the area of
opportunity, and for this reason alone, you must make an initial choice.
Say you track sales generated through your Web site. The number of Web site orders divided
by the number of Web site visits would be a proportion based upon counts. But you might also
want to know the proportion of sales that came from these Web site orders. This would require
a ratio of measurements.
There is no simple formula for obtaining good count data. It's basically a mixture of planning
and common sense, with some thought given to adjusting for variable areas of opportunity.
Of course, there is always the problem of counting events that include different degrees of
severity. Many times this problem is addressed by creating categories for the different degrees
and then awarding different numbers of "demerits" for each category. While it may be helpful
to create such categories, you should resist the temptation of adding up the demerits.
An example of the absurdities that can result if you do comes from the University of Texas,
where, in the 1960s, the campus police could issue tickets to students. The tickets came in
three flavors: minor, major and flagrant. Minor violations included such things as jaywalking
and littering. Four minor violations would get you expelled. Major violations included parking in
a faculty space or hitting a pedestrian with your car. Two major violations would get you
expelled.
And then there was the flagrant category. The only infraction listed for a flagrant citation was
moving a campus police barricade. So, if you had to make a choice between hitting a barricade
or a jaywalker, you chose the pedestrian every time -- you got two of them for each barricade.
The Four Possibilities for Any Process
Every unpredictable process is subject to the effects of assignable causes.
Successful quality control requires making a clear distinction between product and process.
Products may be characterized by conformance to specifications. Processes may be
characterized by predictability. When combined, these two classification systems yield four
possibilities for any process:
1. Conforming and predictable -- the ideal state
2. Nonconforming and predictable -- the threshold state
3. Conforming yet unpredictable -- the brink of chaos
4. Nonconforming and unpredictable -- the state of chaos
The ideal state occurs when a process is predictable and produces a 100-percent conforming
product. Such predictability in a process results from using Shewhart's charts to identify
assignable causes in order to remove their effects. Product conformity results from having
natural process limits that fall within the specification limits.
Wheeler’s SPC Toolkit 1996-97 Pag 32 di 36
How can a process achieve the ideal state? Only by satisfying four conditions:
1. The process must remain inherently stable over time.
2. The process must operate in a stable and consistent manner.
3. The process average must be set at the proper level.
4. The natural process spread must not exceed the product's specified tolerance.
Not satisfying any one of these conditions increases the risk of shipping a nonconforming
product. When a process fulfills these four conditions, then a consistently conforming product
results. The only way to determine that these four conditions apply to your process and
subsequently are established and maintained day after day is by using Shewhart's charts.
The threshold state occurs when a process is predictable but produces some nonconforming
product. Sorting out nonconforming product is always imperfect and often very costly. The
ultimate solution requires a change in either the process or the specifications.
If the nonconformity occurs because of an incorrectly set process average, then adjusting the
process aim should help. Here Shewhart's charts can determine when to make adjustments. If
the nonconformity occurs because the process's natural variation exceeds the specified
tolerance, a reduction in the process variation may work. However, because a predictable
process performs as consistently as possible, reducing the process variation will require a
fundamental process change, which in turn will require evaluation.
As a final resort, the specifications themselves could change, with customer approval. Here,
too, Shewhart's charts will prove invaluable. They are essential not only in getting any process
into the threshold state, but they also are critical in any attempt to move from the threshold to
the ideal state.
In the third state, the brink of chaos, processes are unpredictable even though they currently
produce a 100-percent conforming product. While product conformity will lead to benign
neglect, process unpredictability will result in periodic rude awakenings. The change from a
100-percent conforming product to some nonconforming product can come at any time and
without the slightest warning.
Every unpredictable process is subject to the effects of assignable causes, the trouble source
for any process. The only way to overcome the unpredictability of a process on the brink of
chaos is to eliminate the effects of these assignable causes. This will require the use of
Shewhart's charts.
The state of chaos exists when an unpredictable process produces some nonconforming
product. The process's unpredictable nature will make some days look better than others but
will also prevent effective elimination of the nonconforming product. Efforts to correct the
problem ultimately will be foiled by the random process changes resulting from assignable
causes.
Needed process modifications will produce only short-term successes because the assignable
causes continue to change the process. With unnecessary modifications, a fortuitous shift by
assignable causes may mislead. As a result, companies despair of ever operating the process
rationally and begin to speak in terms of magic and art.
The only way to move a process out of chaos is to eliminate the effects of assignable causes.
This requires the use of Shewhart's charts; no other approach will work consistently.
All processes belong to one of these four states, although processes may move from one state
to another. In fact, entropy acts on every process, causing it to move toward deterioration and
Wheeler’s SPC Toolkit 1996-97 Pag 33 di 36
decay, wear and tear, breakdowns and failures. Because of entropy, every process will
naturally and inevitably migrate toward the state of chaos. The only way to overcome this
migration is by continually repairing entropy's effects.
Because processes in the state of chaos obviously require change, chaos managers inevitably
are appointed to drag the process back to the brink of chaos, erroneously considered the "out-
of-trouble" state in most operations. Once the process returns to the brink of chaos, then chaos
managers leave to work on other problems. As soon as their backs are turned, the process
begins to move back down the entropy slide toward chaos.
New technologies, process upgrades and other magic bullets can never overcome this cycle of
despair. Technologies may change, but the benign neglect that inevitably occurs when the
process teeters on the brink of chaos will allow entropy to drag the process back down to the
state of chaos. Thus, focusing solely on conformance to specifications will condemn an
organization to cycle forever between the two states.
Entropy places a process in the cycle of despair, and assignable causes doom it to stay there.
Thus, it is important to identify both the effects of entropy and the presence of assignable
causes. Shewhart's charts will consistently and reliably provide the necessary information in a
clear and understandable form.
The traditional chaos-manager approach focuses on conformance to specifications but doesn't
attempt to characterize or understand the behavior of a process. Therefore, about the best this
approach can achieve is to get the process to operate on the brink of chaos some of the time.
Which explains why any process operated without Shewhart's charts is doomed to operate in
the state of chaos.
Analyzing Data
The problem is not in knowing how to manipulate numbers but rather in not knowing how to
interpret them.
From the beginning of our education, we have all learned that "two plus two is equal to four."
The very definiteness of this phrase summarizes the unequivocal nature of arithmetic. This
phrase is used to characterize that which is inevitable, solid and beyond argument. It is the first
item in our educational catechism, which is beyond dispute.
This bit of arithmetic has been elevated to a cliché for the following reasons. During the years
when we were learning our sums and our multiplication tables, we were also learning to spell
and to write. This means that we had to learn about irregular spellings. We had to learn to use
irregular verbs. And we had to learn to cope with many of the idiosyncrasies of language. In
contrast to this, we learned that there are no irregular spellings in arithmetic. Whether you
multiply three by two or multiply two by three, the result is always six. Addition, subtraction,
multiplication and division contain no irony; they contain no hyperbole. The multiplication
tables contain no sarcasm.
As a result, we receive a subliminal message: Numbers are concrete, regular and precise, but
words are inconstant, vague and changing. The contrast between the regularity (and for some,
the sterility) of mathematics and the complexity (and richness) of language leaves us all with
an inherent belief that numbers possess some native objectivity that words do not possess.
Hence, when we want to indicate a solid and dependable truth, we are prone to recall the first
rule in the mathematical catechism: Two plus two is equal to four.
Because of this subliminal belief, we feel that we have some sort of control over those things
we can measure. If we can express it in numbers, then we have made it objective, and we
therefore know that with which we are dealing. Moreover, due to all the uncertainty we
routinely must deal with, this ability to quantify things is so reassuring, so comforting, that we
Wheeler’s SPC Toolkit 1996-97 Pag 34 di 36
gladly embrace measurements as being solid, real and easy to understand.
Hence, today we have gone beyond measuring the physical world. We have gone beyond the
accounting of wealth. Now we are trying to measure everything. If we can quantify it, then we
can deal with it "scientifically." So now we "measure" attitudes, we measure satisfaction, and
we measure performance. And once we have measured these things, we feel that we know
them objectively, definitively and concretely.
But, having obtained these measurements, how do you analyze them? Do the normal rules of
arithmetic apply?
Unfortunately, all of our mathematical education has not prepared us to properly analyze such
measurements. Our very first lessons taught us that two numbers which are not the same are
different. So when the numbers differ, we conclude that the things being measured are also
different. That this is not so is a fact that seems to have escaped the attention of almost
everyone.
And when we think the things are different, we tend to rank them and publish a list. For
example, a recent article in my local newspaper reported that Nashville and Knoxville were,
respectively, the 25th and 27th "most violent cities in the country." This ranking was based on
the number of crimes against persons reported to the FBI by the local law enforcement
agencies. But just what is entailed in such numbers? Is purse snatching a burglary (a crime
against property) or a robbery (a crime against a person)? Is domestic violence reported as an
assault or as disturbing the peace? These and other crimes are reported differently in different
cities.
Finally, even if the crimes were categorized and reported the same way, would the crime rates
make the proper comparison? The incorporated portion of Nashville includes all of Davidson
County and consists of urban, suburban and rural areas. In contrast, only half the population of
greater Knoxville lives within the city limits-the rest live in the unincorporated portions of Knox
County. Therefore Knoxville contains a much higher proportion of urban environments than
does Nashville. If crime rates are higher in an urban setting, then dividing the number of
reported crimes by the city's population will artificially inflate Knoxville's rate compared to that
of Nashville.
Considerations such as these can raise more than a reasonable doubt about the
appropriateness of most of the published rankings we hear about every day. Many comparisons
made by those who compile lists are virtually meaningless. The only thing that is worse than
the compilation of such rankings is the use of these rankings for business decisions.
The problem here is not a problem of arithmetic. It is not a problem of not knowing how to
manipulate numbers but rather in not knowing how to interpret them. All the arithmetic, all the
algebra, all the geometry, all the trigonometry and all the calculus you have ever had was
taught in the world of pure numbers. This world is one where lines have no width, planes have
no thickness and points have no dimensions at all. While things work out very nicely in this
world of pure numbers, we do not live there.
Numbers are not exact in the world in which we live. They always contain variation. As noted
above, there is variation in the way numbers are generated. There is variation in the way
numbers are collected. There is variation in the way numbers are analyzed. And finally, even if
none of the above existed, there would still be variation in the measurement process itself.
Thus, without some understanding of all this variation, it is impossible to interpret the numbers
of this world.
If a manufacturer applies two film coatings to a surface, and if each coating is two microns
thick, will the combined thickness of the two coatings be exactly four microns thick? If we
measure with sufficient care and precision, the combined thickness is virtually certain to be
some other value than four microns. Thus, when we add one thing that is characterized by the
value 2.0 to another thing characterized by the value 2.0, we end up with something which is
only equal to four on the average.
Wheeler’s SPC Toolkit 1996-97 Pag 35 di 36
What we see here is not a breakdown in the rules of arithmetic but a shift in what we are doing
with numbers. Rather than working with pure numbers, we are now using numbers to
characterize something in this world. When we do this, we encounter the problem of variation.
In every measurement, and in every count, there is some element of variation. This variation is
connected to both the process of obtaining the number and to the variation in the
characteristic being quantified. This variation tends to "fuzz" the numbers and undermine all
simple attempts to analyze and interpret the numbers.
So how, then, should we proceed? How can we use numbers? When we work with numbers in
this world, we must first make allowances for the variation that is inherent in those numbers.
This is exactly what Shewhart's charts do-they filter out the routine variation so that we can
spot any exceptional values which may be present. (One way of doing this was described in this
column last month.) This filtering, this separation of all numbers into "probable noise" and
"potential signals" is at the very heart of making sense of data. While it is not good to miss a
signal, it is equally bad to interpret noise as if it were a signal. The real trick is to strike an
economic balance between these two mistakes, and this is exactly what Shewhart's charts do.
They filter out virtually all of the probable noise, so that anything left over may be considered a
potential signal.
Whether or not you acknowledge variation, it is present in all of the numbers with which you
deal each day.
If you choose to learn about variation, it will change the way you interpret all data. You will still
detect those signals that are of economic importance, but you will not be derailed by noise.
If you choose to ignore variation, then for you, two plus two will still be equal to four, and you
will continue to be misled by noise. You will also tend to reveal your choice by the way you talk
and by the mistakes you make when you interpret data.
Two plus two is only equal to four on the average. The sooner you understand this, the sooner
you can begin to use numbers effectively.
Wheeler’s SPC Toolkit 1996-97 Pag 36 di 36
Você também pode gostar
- How To Make Process Behavior Charts Work For You - WheelerDocumento2 páginasHow To Make Process Behavior Charts Work For You - Wheelertehky63Ainda não há avaliações
- Process Performance Models: Statistical, Probabilistic & SimulationNo EverandProcess Performance Models: Statistical, Probabilistic & SimulationAinda não há avaliações
- Axioms of Data Analysis - WheelerDocumento7 páginasAxioms of Data Analysis - Wheelerneuris_reino100% (1)
- PSDMDocumento6 páginasPSDMPallav KumarAinda não há avaliações
- Design of Experiments OverviewDocumento6 páginasDesign of Experiments Overviewdaveawoods100% (1)
- What Happens After The Experiment?: Donald J. WheelerDocumento7 páginasWhat Happens After The Experiment?: Donald J. Wheelertehky63Ainda não há avaliações
- Lean Six Sigma Green Belt Info SheetDocumento1 páginaLean Six Sigma Green Belt Info SheetayanAinda não há avaliações
- Measurement UncertaintyDocumento140 páginasMeasurement UncertaintyALPER ORHAN100% (1)
- Bosch Quality Management Guide - Evaluation of Measurement SeriesDocumento116 páginasBosch Quality Management Guide - Evaluation of Measurement SeriesnelsonhugoAinda não há avaliações
- A Simple Guide To Gage R&R For Destructive Testing - MinitabDocumento7 páginasA Simple Guide To Gage R&R For Destructive Testing - MinitabVictor HugoAinda não há avaliações
- E-Book - SQC For Six Sigma Green BeltDocumento364 páginasE-Book - SQC For Six Sigma Green BeltMUNIS100% (2)
- Statistical Process Control FundamentalsDocumento32 páginasStatistical Process Control FundamentalsEd100% (1)
- RGNQA Parameters ConsolidatedDocumento186 páginasRGNQA Parameters ConsolidatedpendialaAinda não há avaliações
- Kim H. Pries-Six Sigma For The New Millennium - A CSSBB Guidebook, Second Edition-ASQ Quality Press (2009)Documento456 páginasKim H. Pries-Six Sigma For The New Millennium - A CSSBB Guidebook, Second Edition-ASQ Quality Press (2009)Elvis Sikora100% (1)
- Lean Six Sigma Asq Road MapDocumento2 páginasLean Six Sigma Asq Road Maphj100% (4)
- Control ChartsDocumento29 páginasControl Chartsmbstutextile100% (1)
- Kepner Tregoe Problem Analysis MethodDocumento16 páginasKepner Tregoe Problem Analysis MethodRahul_regal100% (1)
- Grady Klein, Alan Dabney - The Cartoon Introduction To Statistics-Hill and Wang (2013)Documento248 páginasGrady Klein, Alan Dabney - The Cartoon Introduction To Statistics-Hill and Wang (2013)Kishore JohnAinda não há avaliações
- Short Run Statistical Process ControlDocumento21 páginasShort Run Statistical Process ControlEdAinda não há avaliações
- A Study of Q Chart For Short Run PDFDocumento37 páginasA Study of Q Chart For Short Run PDFEd100% (1)
- A Better Way to R&R Studies with EMP ApproachDocumento10 páginasA Better Way to R&R Studies with EMP ApproachJosé Esqueda LeyvaAinda não há avaliações
- Chapter 4 Statistical Process ControlDocumento20 páginasChapter 4 Statistical Process Controlamity_acel100% (1)
- Applied Predictive Modeling - Max KuhnDocumento57 páginasApplied Predictive Modeling - Max KuhnDavid75% (4)
- FMEA Tool Identifies Risks in Design and ProcessDocumento35 páginasFMEA Tool Identifies Risks in Design and Processsa_arunkumarAinda não há avaliações
- Capability of Measurement and Test ProcessesDocumento98 páginasCapability of Measurement and Test ProcessesNELSONHUGOAinda não há avaliações
- MINITAB User's Guide Chap - 11Documento32 páginasMINITAB User's Guide Chap - 11Ernesto Neri100% (3)
- 01 Process CapabilityDocumento33 páginas01 Process CapabilitySrinivasagam Venkataramanan100% (1)
- Cqe Sampl ExamDocumento11 páginasCqe Sampl ExamRaghavendra Kalyan100% (1)
- FMEA & Measurement Systems AnalysisDocumento23 páginasFMEA & Measurement Systems AnalysisViswanathan SrkAinda não há avaliações
- Multivariate Statistical Process Control With Industrial Applications - Mason, Young - Asa-Siam, 2002 PDFDocumento277 páginasMultivariate Statistical Process Control With Industrial Applications - Mason, Young - Asa-Siam, 2002 PDFMestddl100% (3)
- Residual AnalysisDocumento6 páginasResidual AnalysisGagandeep SinghAinda não há avaliações
- Shainin Tools PDFDocumento17 páginasShainin Tools PDFDEVIKA PHULEAinda não há avaliações
- Statistical Method from the Viewpoint of Quality ControlNo EverandStatistical Method from the Viewpoint of Quality ControlNota: 4.5 de 5 estrelas4.5/5 (5)
- Agilent-Introduction ISO 17025 & AccreditationDocumento27 páginasAgilent-Introduction ISO 17025 & AccreditationediwskiAinda não há avaliações
- Acceptence SamplingDocumento24 páginasAcceptence SamplingFaysal AhmedAinda não há avaliações
- MSA & Destructive TestDocumento4 páginasMSA & Destructive Testanon_902607157100% (1)
- Lean Six Sigma Analyze Phase Tollgate TemplateDocumento30 páginasLean Six Sigma Analyze Phase Tollgate TemplateSteven Bonacorsi91% (11)
- Understanding Gage R and RDocumento5 páginasUnderstanding Gage R and Rmax80860% (1)
- Failure Mode and Effect Analysis (FMEA)Documento7 páginasFailure Mode and Effect Analysis (FMEA)Anonymous 21xH6NcvcAinda não há avaliações
- Chapter - 6: Statistical Process Control Using Control ChartsDocumento43 páginasChapter - 6: Statistical Process Control Using Control ChartsKartikeya Khatri100% (1)
- Acceptance Sampling in Quality ControlDocumento709 páginasAcceptance Sampling in Quality ControlJong-Jang Lin100% (2)
- Process Capability AnalysisDocumento37 páginasProcess Capability Analysisabishank09100% (1)
- Measurement Systems Analysis - How ToDocumento72 páginasMeasurement Systems Analysis - How Towawawa1100% (1)
- Presented By:: ASQ Section 0700 ASQ Section 0701Documento35 páginasPresented By:: ASQ Section 0700 ASQ Section 0701fennyAinda não há avaliações
- Minitab - Quality ControlDocumento310 páginasMinitab - Quality ControlRajesh Sharma100% (4)
- Glossary of Key Terms (LSSGB)Documento8 páginasGlossary of Key Terms (LSSGB)Sweety ShuklaAinda não há avaliações
- DOE Taguchi Basic Manual1Documento121 páginasDOE Taguchi Basic Manual1alikhan_nazeer80100% (6)
- Practical Design of Experiments (DOE)Documento26 páginasPractical Design of Experiments (DOE)Majid ShakeelAinda não há avaliações
- Errors of Regression Models: Bite-Size Machine Learning, #1No EverandErrors of Regression Models: Bite-Size Machine Learning, #1Ainda não há avaliações
- Practical Design of Experiments: DoE Made EasyNo EverandPractical Design of Experiments: DoE Made EasyNota: 4.5 de 5 estrelas4.5/5 (7)
- Statistical Quality Control A Complete Guide - 2020 EditionNo EverandStatistical Quality Control A Complete Guide - 2020 EditionAinda não há avaliações
- Experimental Design Techniques in Statistical Practice: A Practical Software-Based ApproachNo EverandExperimental Design Techniques in Statistical Practice: A Practical Software-Based ApproachNota: 3 de 5 estrelas3/5 (1)
- En 10204Documento30 páginasEn 10204Gaurav Narula95% (19)
- Welcome To Time Management: I Am Damn Sure That You Will Really Like ThisDocumento69 páginasWelcome To Time Management: I Am Damn Sure That You Will Really Like ThisGaurav NarulaAinda não há avaliações
- Casting HandbookDocumento18 páginasCasting HandbookGaurav NarulaAinda não há avaliações
- LDX2101 Spec SheetDocumento2 páginasLDX2101 Spec SheetGaurav NarulaAinda não há avaliações
- Hanuman Chalisa With Meaning3Documento7 páginasHanuman Chalisa With Meaning3oraveen100% (1)
- MH Dalmia OCL Healthy - LifeDocumento25 páginasMH Dalmia OCL Healthy - LifeGaurav Narula100% (1)
- Will PowerDocumento10 páginasWill PowerGaurav Narula0% (1)
- How Management Works - A StoryDocumento25 páginasHow Management Works - A Storyashutoshkj100% (1)
- Atlas Grade Datasheet 2507 Rev May 2008Documento2 páginasAtlas Grade Datasheet 2507 Rev May 2008Gaurav NarulaAinda não há avaliações
- Welcome To Time Management: I Am Damn Sure That You Will Really Like ThisDocumento69 páginasWelcome To Time Management: I Am Damn Sure That You Will Really Like ThisGaurav NarulaAinda não há avaliações
- Corporate Social RespDocumento5 páginasCorporate Social RespGaurav NarulaAinda não há avaliações
- IPL Player Register 2009Documento9 páginasIPL Player Register 2009Gaurav Narula100% (1)
- En 10204Documento30 páginasEn 10204Gaurav Narula95% (19)
- TN3-0506-Properties and Equivalent GradesDocumento4 páginasTN3-0506-Properties and Equivalent GradesGaurav Narula100% (1)
- Inventory ManagementDocumento102 páginasInventory ManagementGaurav Narula100% (7)
- ISO 9001:2008 EditionDocumento25 páginasISO 9001:2008 EditionGaurav Narula100% (15)
- Welcome To Time Management: I Am Damn Sure That You Will Really Like ThisDocumento69 páginasWelcome To Time Management: I Am Damn Sure That You Will Really Like ThisGaurav NarulaAinda não há avaliações
- Quality Manual CalibrationDocumento30 páginasQuality Manual CalibrationsaidvaretAinda não há avaliações
- Supply Chain ManagementDocumento35 páginasSupply Chain ManagementGaurav Narula100% (1)
- CPK Index - How To Calculate For All Types of TolerancesDocumento15 páginasCPK Index - How To Calculate For All Types of TolerancesGaurav Narula100% (6)
- World Business CultureDocumento275 páginasWorld Business CultureGaurav Narula100% (8)
- French For English PeoplesDocumento568 páginasFrench For English PeoplesManoj Kumar Jha100% (30)
- Explore The Big Cats PDFDocumento65 páginasExplore The Big Cats PDFvarcolacAinda não há avaliações
- Solar SystemDocumento105 páginasSolar Systemv155r100% (18)
- Creative Time - Manage The Mundane - Create The ExtraordinaryDocumento32 páginasCreative Time - Manage The Mundane - Create The ExtraordinarySolomon100% (3)
- Setting SMARt TargetsDocumento3 páginasSetting SMARt TargetsGaurav Narula100% (5)
- Inspiring StoriesDocumento21 páginasInspiring StoriesGaurav Narula100% (2)
- Kings and Queens of England: The Whole BookDocumento85 páginasKings and Queens of England: The Whole Bookestudo35Ainda não há avaliações
- Vertical PumpsDocumento4 páginasVertical PumpsGaurav NarulaAinda não há avaliações
- Torque Flow PumpsDocumento4 páginasTorque Flow PumpsGaurav Narula0% (1)
- Overcurrent Protection of Transmission LinesDocumento19 páginasOvercurrent Protection of Transmission LinesPratham VaghelaAinda não há avaliações
- Chapter 6 Interest Rates and Bond ValuationDocumento14 páginasChapter 6 Interest Rates and Bond ValuationPatricia CorpuzAinda não há avaliações
- Fast Formula GuideDocumento96 páginasFast Formula GuideRinita BhattacharyaAinda não há avaliações
- Cognos CSDocumento2 páginasCognos CSSuganthi RavindraAinda não há avaliações
- Half wave rectifier experimentDocumento9 páginasHalf wave rectifier experimentSidhartha Sankar RoutAinda não há avaliações
- Technical Specification PC 1060 I: Atlas Copco PowercrusherDocumento4 páginasTechnical Specification PC 1060 I: Atlas Copco PowercrusheralmirAinda não há avaliações
- Thesis Antenna HfssDocumento5 páginasThesis Antenna Hfssafkofvidg100% (2)
- Signature FileDocumento28 páginasSignature FileLaxmi BlossomAinda não há avaliações
- T20000 Series: - DATEDocumento41 páginasT20000 Series: - DATESaraiva EquipamentosAinda não há avaliações
- "Bye Bye Birdie" score/CD InfoDocumento3 páginas"Bye Bye Birdie" score/CD InfoCasey on the KeysAinda não há avaliações
- GDM Ch-17 Abuts Ret WallsDocumento136 páginasGDM Ch-17 Abuts Ret WallsNguyen Ngoc DuyenAinda não há avaliações
- Fanuc Hardware Connection MNL, GFZ 036867291Documento560 páginasFanuc Hardware Connection MNL, GFZ 036867291zcadAinda não há avaliações
- LTC3108 EnergyHarvestDocumento3 páginasLTC3108 EnergyHarvestliawyssbdAinda não há avaliações
- Ete 1 - Xi - Applied MathsDocumento5 páginasEte 1 - Xi - Applied MathsVyshnavi T MAinda não há avaliações
- Mean From A Table3Documento1 páginaMean From A Table3Duvall McGregorAinda não há avaliações
- Calculus For Engineers: Chapter 16 - Laplace TransformsDocumento41 páginasCalculus For Engineers: Chapter 16 - Laplace TransformsscreamAinda não há avaliações
- Biology Practical Guide TeachersDocumento37 páginasBiology Practical Guide TeachersGazar88% (8)
- Helicopter GearboxDocumento9 páginasHelicopter GearboxlvrevathiAinda não há avaliações
- The Iodine Clock Reaction LabDocumento3 páginasThe Iodine Clock Reaction LabVruti Shah100% (1)
- Bread and Pastry Production NC IIDocumento88 páginasBread and Pastry Production NC IIjhessica ibal50% (2)
- Speed of Light - OdtDocumento1 páginaSpeed of Light - OdtFlorenz Pintero Del CastilloAinda não há avaliações
- Admmodule s1112ps Iiic 15Documento12 páginasAdmmodule s1112ps Iiic 15Lebz RicaramAinda não há avaliações
- Task-Based Lesson Plan 2Documento6 páginasTask-Based Lesson Plan 2api-242013573Ainda não há avaliações
- Problems: Heat TransferDocumento7 páginasProblems: Heat TransferKinna VnezhAinda não há avaliações
- S50MC-C8 - 2 Man B&WDocumento381 páginasS50MC-C8 - 2 Man B&WhaizriAinda não há avaliações
- Bioorganic & Medicinal ChemistryDocumento7 páginasBioorganic & Medicinal ChemistryIndah WulansariAinda não há avaliações
- Static Equipment Installation SpecificationDocumento17 páginasStatic Equipment Installation Specificationonur gunes100% (2)
- 219 Ho SBC (WJB) 9-30-02Documento36 páginas219 Ho SBC (WJB) 9-30-02arkhom1Ainda não há avaliações
- Motion Sensor For Security Light Using Pir SensorDocumento3 páginasMotion Sensor For Security Light Using Pir SensorSamaira Shahnoor Parvin100% (1)
- Historic Investigation of Legendre's Proof About The 5th Postulate of "Elements" For Reeducation of Mathematics TeacherDocumento6 páginasHistoric Investigation of Legendre's Proof About The 5th Postulate of "Elements" For Reeducation of Mathematics TeacherYanh Vissuet OliverAinda não há avaliações