Você também pode gostar
- A Guide To Singular Value Decomposition For Collaborative FilteringDocumento14 páginasA Guide To Singular Value Decomposition For Collaborative FilteringHoàng Công AnhAinda não há avaliações
- Ijcai2018 YinDocumento7 páginasIjcai2018 YinAjay MukundAinda não há avaliações
- Rec Sys ComparisonDocumento9 páginasRec Sys ComparisonAMANI MhadhbiAinda não há avaliações
- Appm 3310 Final ProjectDocumento13 páginasAppm 3310 Final Projectapi-491772270Ainda não há avaliações
- 10 26599@bdma 2018 9020012Documento9 páginas10 26599@bdma 2018 9020012TeX-CodersAinda não há avaliações
- 2404 16177v1Documento6 páginas2404 16177v1OBXOAinda não há avaliações
- Comparison of Collaborative Filtering Algorithms: Limitations of Current Techniques and Proposals For Scalable, High-Performance Recommender SystemsDocumento33 páginasComparison of Collaborative Filtering Algorithms: Limitations of Current Techniques and Proposals For Scalable, High-Performance Recommender SystemsGautam ThakurAinda não há avaliações
- Recommender: An Analysis of Collaborative Filtering TechniquesDocumento5 páginasRecommender: An Analysis of Collaborative Filtering TechniquesParas MirraAinda não há avaliações
- Miranda 2008 ADocumento5 páginasMiranda 2008 AĐức NguyễnAinda não há avaliações
- Assignment No. - 1 Ques:1 Differentiate Aggregation and Generalization With An Example. Ans:1Documento7 páginasAssignment No. - 1 Ques:1 Differentiate Aggregation and Generalization With An Example. Ans:1Sweta UmraoAinda não há avaliações
- BOOM, Larger-ScaleDocumento23 páginasBOOM, Larger-ScaleLana OliveiraAinda não há avaliações
- Readme PDFDocumento6 páginasReadme PDFKumara SAinda não há avaliações
- RecSys UpdatedDocumento37 páginasRecSys UpdatedShreenidhi M RAinda não há avaliações
- RBM RP 6Documento7 páginasRBM RP 6nikita BhargavaAinda não há avaliações
- TV Programme Recommendation: Marco Lisi 188601Documento5 páginasTV Programme Recommendation: Marco Lisi 188601Marco LisiAinda não há avaliações
- Online Prediction of Aggregated Retailer Consumer Behaviour: (Y.spenrath, M.hassani, B.f.v.dongen) @tue - NLDocumento13 páginasOnline Prediction of Aggregated Retailer Consumer Behaviour: (Y.spenrath, M.hassani, B.f.v.dongen) @tue - NLANA FLAVIA BEGAZO CORNEJOAinda não há avaliações
- ML Lab ProjectDocumento9 páginasML Lab ProjectSubhash SharmaAinda não há avaliações
- Incremental Collaborative Filtering For Binary Ratings: December 2008Documento5 páginasIncremental Collaborative Filtering For Binary Ratings: December 2008Sharif AhamedAinda não há avaliações
- NLMF: Nonlinear Matrix Factorization Methods For Top-N Recommender SystemsDocumento8 páginasNLMF: Nonlinear Matrix Factorization Methods For Top-N Recommender SystemsGuru ReddyAinda não há avaliações
- Recommendation SystemDocumento17 páginasRecommendation SystemTARA TARANNUMAinda não há avaliações
- OOAD NotesDocumento28 páginasOOAD NotesSenthil R0% (1)
- Uniform Representation of Transition Concepts in Domain Specific Visual LanguagesDocumento8 páginasUniform Representation of Transition Concepts in Domain Specific Visual LanguagespaolodtAinda não há avaliações
- Recommender Systems and Their Fairness For User Preferences: A Literature StudyDocumento17 páginasRecommender Systems and Their Fairness For User Preferences: A Literature StudyGS SamridhiAinda não há avaliações
- International Journal of Computational Engineering Research (IJCER)Documento6 páginasInternational Journal of Computational Engineering Research (IJCER)International Journal of computational Engineering research (IJCER)Ainda não há avaliações
- AbstractDocumento12 páginasAbstractofficialfrcAinda não há avaliações
- Day 2 PeopleCodeDocumento43 páginasDay 2 PeopleCodeSan Deep100% (2)
- Filtering and Recommender Systems: Content-Based and CollaborativeDocumento30 páginasFiltering and Recommender Systems: Content-Based and CollaborativeArockiaruby RubyAinda não há avaliações
- Interactive Generation Flexible Programs: of RobotDocumento6 páginasInteractive Generation Flexible Programs: of RobotMuhammad AbkaAinda não há avaliações
- Unifying User-Based and Item-Based Collaborative Filtering Approaches by Similarity FusionDocumento8 páginasUnifying User-Based and Item-Based Collaborative Filtering Approaches by Similarity FusionEvan John O 'keeffeAinda não há avaliações
- Implementation and Comparison of Recommender Systems Using Various ModelsDocumento13 páginasImplementation and Comparison of Recommender Systems Using Various ModelsIshan100% (1)
- Assignment No.: - 2 Ques:1 List The Principles of OOSE With Its Concepts. Ans:1Documento11 páginasAssignment No.: - 2 Ques:1 List The Principles of OOSE With Its Concepts. Ans:1Sweta UmraoAinda não há avaliações
- Monitoring Reverse Top-K Queries Over Mobile Devices: Akrivi Vlachou Christos Doulkeridis Kjetil NørvågDocumento8 páginasMonitoring Reverse Top-K Queries Over Mobile Devices: Akrivi Vlachou Christos Doulkeridis Kjetil NørvågYogita Salvi NaruleAinda não há avaliações
- Efficient Rec SpringerDocumento16 páginasEfficient Rec SpringerQuan VuAinda não há avaliações
- Machin e Learnin G: Lab Record Implementation in RDocumento30 páginasMachin e Learnin G: Lab Record Implementation in RyukthaAinda não há avaliações
- A Novel Collaborative Filtering Model Based On Combination of Correlation Method With Matrix Completion TechniqueDocumento8 páginasA Novel Collaborative Filtering Model Based On Combination of Correlation Method With Matrix Completion TechniquessuthaaAinda não há avaliações
- A Step Towards An Intelligent Debugger: Cristinel Mateis and Markus Stumptner and Dominik Wieland and Franz WotawaDocumento7 páginasA Step Towards An Intelligent Debugger: Cristinel Mateis and Markus Stumptner and Dominik Wieland and Franz WotawaaresnicketyAinda não há avaliações
- Querying Olap DatabasesDocumento10 páginasQuerying Olap DatabasesAmit SinghAinda não há avaliações
- Movie Recommendation System ReportDocumento5 páginasMovie Recommendation System Reportkshitij padwalkarAinda não há avaliações
- Improving The Presentation and Interpretation of Online Ratings Data With Model-Based FiguresDocumento10 páginasImproving The Presentation and Interpretation of Online Ratings Data With Model-Based FiguresEric SampsonAinda não há avaliações
- Interactive Multimedia Summaries of Evaluative Text: Giuseppe Carenini, Raymond T. NG and Adam PaulsDocumento8 páginasInteractive Multimedia Summaries of Evaluative Text: Giuseppe Carenini, Raymond T. NG and Adam Paulsmusaismail8863Ainda não há avaliações
- Personalized Book Recommendation System Using TF-IDF and KNN HybridDocumento5 páginasPersonalized Book Recommendation System Using TF-IDF and KNN HybridIJRASETPublicationsAinda não há avaliações
- A Detailed Comparative Analysis of Two Mechanical Products With A Value Analysis ApproachDocumento10 páginasA Detailed Comparative Analysis of Two Mechanical Products With A Value Analysis ApproachAngel DiosdadoAinda não há avaliações
- The Bellkor 2008 Solution To The Netflix PrizeDocumento21 páginasThe Bellkor 2008 Solution To The Netflix Prizeken_nov21Ainda não há avaliações
- Chapter 4..Documento29 páginasChapter 4..Jiru AlemayehuAinda não há avaliações
- Movie GenreDocumento5 páginasMovie GenrePradeepSinghAinda não há avaliações
- Discrete Simulation Software Ranking - A Top List of The Worldwide Most Popular and Used ToolsDocumento12 páginasDiscrete Simulation Software Ranking - A Top List of The Worldwide Most Popular and Used ToolsPuneet VermaAinda não há avaliações
- Discrete Simulation Software RankingDocumento12 páginasDiscrete Simulation Software RankingRapidEyeMovementAinda não há avaliações
- The Who-To-Follow System at Twitter Strategy, Algorithms, and Revenue ImpactDocumento4 páginasThe Who-To-Follow System at Twitter Strategy, Algorithms, and Revenue ImpactU.N.OwenAinda não há avaliações
- OOSD Question Bank - 2Documento16 páginasOOSD Question Bank - 2pubg64645Ainda não há avaliações
- Report Sentiment Analysis Marcos MatheusDocumento12 páginasReport Sentiment Analysis Marcos Matheusjfernandesj13Ainda não há avaliações
- Amcse 18Documento6 páginasAmcse 18Gopal SohunAinda não há avaliações
- Classifying Component Interaction in Product-Line ArchitecturesDocumento12 páginasClassifying Component Interaction in Product-Line ArchitecturesSravankumar MarurAinda não há avaliações
- Change-Proneness of Software ComponentsDocumento4 páginasChange-Proneness of Software ComponentsInternational Organization of Scientific Research (IOSR)Ainda não há avaliações
- The International Journal of Engineering and Science (The IJES)Documento5 páginasThe International Journal of Engineering and Science (The IJES)theijesAinda não há avaliações
- Narayana Engineering College::Nellore Department of Cse CDF: Definition of Dataflow TestingDocumento5 páginasNarayana Engineering College::Nellore Department of Cse CDF: Definition of Dataflow Testingp rakshaAinda não há avaliações
- OO ConceptsDocumento69 páginasOO ConceptsDivyansh GuptaAinda não há avaliações
- GeneralDocumento5 páginasGeneralapi-3775463Ainda não há avaliações
- Advanced C++ Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo EverandAdvanced C++ Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesAinda não há avaliações
- A New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeNo EverandA New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeAinda não há avaliações
- Pepe Habichuela - AlegriasDocumento2 páginasPepe Habichuela - Alegriassiddiqui16Ainda não há avaliações
- Dynamical Gaussian Mixture Model For Tracking Elliptical Living ObjectsDocumento5 páginasDynamical Gaussian Mixture Model For Tracking Elliptical Living Objectssiddiqui16Ainda não há avaliações
- Web Content Mining and NLP: Bing Liu Department of Computer Science University of Illinois at Chicago Liub@cs - Uic.eduDocumento59 páginasWeb Content Mining and NLP: Bing Liu Department of Computer Science University of Illinois at Chicago Liub@cs - Uic.edusiddiqui16Ainda não há avaliações
- Stream PluginDocumento3 páginasStream Pluginsiddiqui16Ainda não há avaliações
- Ghar Aor Ghaata by Umera AhmedDocumento16 páginasGhar Aor Ghaata by Umera Ahmedsiddiqui16Ainda não há avaliações
- Hadji Murad by Leo TolstoyDocumento135 páginasHadji Murad by Leo Tolstoysiddiqui16Ainda não há avaliações
- A Literary Nightmare, by Mark Twain (1876)Documento5 páginasA Literary Nightmare, by Mark Twain (1876)skanzeniAinda não há avaliações
- Resistance & Resistivity: Question Paper 1Documento15 páginasResistance & Resistivity: Question Paper 1leon19730% (1)
- Lightning Protection Measures NewDocumento9 páginasLightning Protection Measures NewjithishAinda não há avaliações
- Tyler Nugent ResumeDocumento3 páginasTyler Nugent Resumeapi-315563616Ainda não há avaliações
- Natural Cataclysms and Global ProblemsDocumento622 páginasNatural Cataclysms and Global ProblemsphphdAinda não há avaliações
- LLM Letter Short LogoDocumento1 páginaLLM Letter Short LogoKidMonkey2299Ainda não há avaliações
- Sanskrit Subhashit CollectionDocumento110 páginasSanskrit Subhashit Collectionavinash312590% (72)
- Project Chalk CorrectionDocumento85 páginasProject Chalk CorrectionEmeka Nicholas Ibekwe100% (6)
- Embedded Systems Online TestingDocumento6 páginasEmbedded Systems Online TestingPuspala ManojkumarAinda não há avaliações
- MS Lync - Exchange - IntegrationDocumento29 páginasMS Lync - Exchange - IntegrationCristhian HaroAinda não há avaliações
- Operating Instructions: HTL-PHP Air Torque PumpDocumento38 páginasOperating Instructions: HTL-PHP Air Torque PumpvankarpAinda não há avaliações
- Getting Started With Citrix NetScalerDocumento252 páginasGetting Started With Citrix NetScalersudharaghavanAinda não há avaliações
- Lesson 1: Composition: Parts of An EggDocumento22 páginasLesson 1: Composition: Parts of An Eggjohn michael pagalaAinda não há avaliações
- Week - 2 Lab - 1 - Part I Lab Aim: Basic Programming Concepts, Python InstallationDocumento13 páginasWeek - 2 Lab - 1 - Part I Lab Aim: Basic Programming Concepts, Python InstallationSahil Shah100% (1)
- Essentials: Week by WeekDocumento18 páginasEssentials: Week by WeekHirenkumar ShahAinda não há avaliações
- Albert Roussel, Paul LandormyDocumento18 páginasAlbert Roussel, Paul Landormymmarriuss7Ainda não há avaliações
- Bioinformatics Computing II: MotivationDocumento7 páginasBioinformatics Computing II: MotivationTasmia SaleemAinda não há avaliações
- Acetylcysteine 200mg (Siran, Reolin)Documento5 páginasAcetylcysteine 200mg (Siran, Reolin)ddandan_2Ainda não há avaliações
- Working Capital Management 2012 of HINDALCO INDUSTRIES LTD.Documento98 páginasWorking Capital Management 2012 of HINDALCO INDUSTRIES LTD.Pratyush Dubey100% (1)
- RSC Article Template-Mss - DaltonDocumento15 páginasRSC Article Template-Mss - DaltonIon BadeaAinda não há avaliações
- ET4254 Communications and Networking 1 - Tutorial Sheet 3 Short QuestionsDocumento5 páginasET4254 Communications and Networking 1 - Tutorial Sheet 3 Short QuestionsMichael LeungAinda não há avaliações
- Seizure Control Status and Associated Factors Among Patients With Epilepsy. North-West Ethiopia'Documento14 páginasSeizure Control Status and Associated Factors Among Patients With Epilepsy. North-West Ethiopia'Sulaman AbdelaAinda não há avaliações
- The Body Shop Case Analysis. The Challenges of Managing Business As Holistic ConfigurationDocumento28 páginasThe Body Shop Case Analysis. The Challenges of Managing Business As Holistic ConfigurationHanna AbejoAinda não há avaliações
- Power System TransientsDocumento11 páginasPower System TransientsKhairul AshrafAinda não há avaliações
- Additional Article Information: Keywords: Adenoid Cystic Carcinoma, Cribriform Pattern, Parotid GlandDocumento7 páginasAdditional Article Information: Keywords: Adenoid Cystic Carcinoma, Cribriform Pattern, Parotid GlandRizal TabootiAinda não há avaliações
- Cultural Sensitivity BPIDocumento25 páginasCultural Sensitivity BPIEmmel Solaiman AkmadAinda não há avaliações
- Priest, Graham - The Logic of The Catuskoti (2010)Documento31 páginasPriest, Graham - The Logic of The Catuskoti (2010)Alan Ruiz100% (1)
- Report DR JuazerDocumento16 páginasReport DR Juazersharonlly toumasAinda não há avaliações
- European Construction Sector Observatory: Country Profile MaltaDocumento40 páginasEuropean Construction Sector Observatory: Country Profile MaltaRainbootAinda não há avaliações
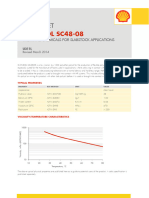
- Caradol sc48 08Documento2 páginasCaradol sc48 08GİZEM DEMİRAinda não há avaliações