Você também pode gostar
- Flexi EDGE BTS ConfigurationsDocumento52 páginasFlexi EDGE BTS ConfigurationsEm Peerayut100% (16)
- PattersonDocumento46 páginasPattersonsuryaAinda não há avaliações
- Future of Computer ArchitectureDocumento46 páginasFuture of Computer ArchitectureAtharvaAinda não há avaliações
- Smd150 Computer Architecture: Per Lindgren Eislab, Lectures Andrey Kruglyak, Syncsim Johan Eriksson, VHDLDocumento43 páginasSmd150 Computer Architecture: Per Lindgren Eislab, Lectures Andrey Kruglyak, Syncsim Johan Eriksson, VHDLNaveen GowdaAinda não há avaliações
- Chapter 1 - IntroductionDocumento35 páginasChapter 1 - IntroductionWaqqs WaqasAinda não há avaliações
- Par Prog Course Many Core SW Pats OclDocumento90 páginasPar Prog Course Many Core SW Pats OclAnonymous 6gg4EV9AiAinda não há avaliações
- CSE 820 Graduate Computer Architecture: Dr. EnbodyDocumento25 páginasCSE 820 Graduate Computer Architecture: Dr. EnbodykbkkrAinda não há avaliações
- Multi ThreadingDocumento168 páginasMulti ThreadingPrashanth RajendranAinda não há avaliações
- EE 271 Digital Circuits and Systems: Course Specification (Syllabus)Documento41 páginasEE 271 Digital Circuits and Systems: Course Specification (Syllabus)R.R.S. SavichevaAinda não há avaliações
- Ch01 Section1 XP 051Documento42 páginasCh01 Section1 XP 051watchstgAinda não há avaliações
- Day 1Documento25 páginasDay 1Abdul SatharAinda não há avaliações
- Lecture 1 COMP2611 Introduction Spring2018Documento34 páginasLecture 1 COMP2611 Introduction Spring2018jnfzAinda não há avaliações
- Comp422 2011 Lecture1 IntroductionDocumento50 páginasComp422 2011 Lecture1 IntroductionaskbilladdmicrosoftAinda não há avaliações
- Advanced Computer ArchitectureDocumento74 páginasAdvanced Computer ArchitectureMonica ChandrasekarAinda não há avaliações
- CSE2006 Syllabus PDFDocumento9 páginasCSE2006 Syllabus PDFMohit SinghalAinda não há avaliações
- No Exaflops For YouDocumento61 páginasNo Exaflops For YoufcportotriAinda não há avaliações
- Multicore Expo Keynote Gatherer v2rDocumento10 páginasMulticore Expo Keynote Gatherer v2rAhmedAinda não há avaliações
- Unit I-Basic Structure of A Computer: SystemDocumento64 páginasUnit I-Basic Structure of A Computer: SystemPavithra JanarthananAinda não há avaliações
- Advanced Computer Architecture: Tran Ngoc Thinh HCMC University of TechnologyDocumento46 páginasAdvanced Computer Architecture: Tran Ngoc Thinh HCMC University of TechnologyAnkit GuptaAinda não há avaliações
- CIS775: Computer Architecture: Chapter 1: Fundamentals of Computer DesignDocumento43 páginasCIS775: Computer Architecture: Chapter 1: Fundamentals of Computer DesignSwapnil Sunil ShendageAinda não há avaliações
- Chapter 1 Fundamentals of Computer DesignDocumento40 páginasChapter 1 Fundamentals of Computer DesignAbdullahAinda não há avaliações
- CIS775: Computer Architecture: Chapter 1: Fundamentals of Computer DesignDocumento43 páginasCIS775: Computer Architecture: Chapter 1: Fundamentals of Computer DesignPranjal JainAinda não há avaliações
- Examination FormDocumento2 páginasExamination Formprashantsingh singhAinda não há avaliações
- Lec1 IntroductionDocumento23 páginasLec1 IntroductionSAIAinda não há avaliações
- EE5902R Chapter 1 SlidesDocumento46 páginasEE5902R Chapter 1 SlidesShyamSundarAinda não há avaliações
- Performance of A ComputerDocumento83 páginasPerformance of A ComputerPrakherGuptaAinda não há avaliações
- VLSI Design MethodologyDocumento72 páginasVLSI Design MethodologyMandovi BorthakurAinda não há avaliações
- ACA (15CS72) MODULE-1: 1.0 ObjectiveDocumento61 páginasACA (15CS72) MODULE-1: 1.0 ObjectiveShameek MangaloreAinda não há avaliações
- Advanced Computer Architecture: 1.0 ObjectiveDocumento27 páginasAdvanced Computer Architecture: 1.0 ObjectiveDhanush RajuAinda não há avaliações
- System On Chip Design and ModellingDocumento131 páginasSystem On Chip Design and ModellingGurram KishoreAinda não há avaliações
- Exploiting ILP, TLP, and DLP With The PDFDocumento21 páginasExploiting ILP, TLP, and DLP With The PDFJoel Ortiz SosaAinda não há avaliações
- CS 133 Parallel & Distributed Computing: Course Instructor: Adam Kaplan Lecture #1: 4/2/2012Documento22 páginasCS 133 Parallel & Distributed Computing: Course Instructor: Adam Kaplan Lecture #1: 4/2/2012Howard NguyenAinda não há avaliações
- DCCT SyllabusDocumento11 páginasDCCT SyllabusmkmaithalAinda não há avaliações
- CMPS375 Class Notes Chap 01Documento17 páginasCMPS375 Class Notes Chap 01Divya SinghAinda não há avaliações
- Analog & Digital VLSI Design: A Perspective EE C443 Instructor-In-ChargeDocumento21 páginasAnalog & Digital VLSI Design: A Perspective EE C443 Instructor-In-ChargeAnurag LaddhaAinda não há avaliações
- ECE 127 Homework 1 Problem 1: Moore's LawDocumento2 páginasECE 127 Homework 1 Problem 1: Moore's LawRobin ScherbatskyAinda não há avaliações
- Lecture 9Documento72 páginasLecture 9david AbotsitseAinda não há avaliações
- C1 Computer InterfacingDocumento95 páginasC1 Computer Interfacingbatrung2906Ainda não há avaliações
- Slide n1 HandoutDocumento40 páginasSlide n1 Handout이예진[학생](대학원 전자정보융합공학과)Ainda não há avaliações
- 6.189 Info SessionDocumento20 páginas6.189 Info SessionMuhammad WasifAinda não há avaliações
- Future of ComputingDocumento42 páginasFuture of ComputingDan Arvin PolintanAinda não há avaliações
- 8085 AllDocumento165 páginas8085 AllLavanya DevallaAinda não há avaliações
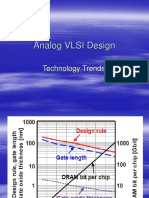
- Analog VLSI Design: Technology TrendsDocumento31 páginasAnalog VLSI Design: Technology TrendsSathyaNarasimmanTiagarajAinda não há avaliações
- 03b - FIE - Parcial #3 PLD - Resumen 04c 09Documento36 páginas03b - FIE - Parcial #3 PLD - Resumen 04c 09amilcar93Ainda não há avaliações
- 10 Lecf 12 ComponentsDocumento7 páginas10 Lecf 12 ComponentsnuurcadeAinda não há avaliações
- Icl Utk 1570 2022Documento26 páginasIcl Utk 1570 2022taldayyeniAinda não há avaliações
- CSE2006 Microprocessor and InterfacingDocumento10 páginasCSE2006 Microprocessor and InterfacingAyyeeeeAinda não há avaliações
- CS 252 Graduate Computer Architecture Lecture 1 - IntroductionDocumento41 páginasCS 252 Graduate Computer Architecture Lecture 1 - IntroductionGusti ArsyadAinda não há avaliações
- Programmable ASIC Design: Haibo Wang ECE Department Southern Illinois University Carbondale, IL 62901Documento25 páginasProgrammable ASIC Design: Haibo Wang ECE Department Southern Illinois University Carbondale, IL 62901Huzur AhmedAinda não há avaliações
- Text Book Introduction To Computer Programming CIT-113Documento355 páginasText Book Introduction To Computer Programming CIT-113Suleman AsifAinda não há avaliações
- Lect 01 PDFDocumento33 páginasLect 01 PDFVijendra PandeyAinda não há avaliações
- Chap 01Documento11 páginasChap 01Zerihun BekeleAinda não há avaliações
- Vector IRAM: A Microprocessor Architecture For Media ProcessingDocumento15 páginasVector IRAM: A Microprocessor Architecture For Media ProcessingNoman Ali ShahAinda não há avaliações
- New CS432 - Module 01 - Computer Abstractions and TechnologyDocumento75 páginasNew CS432 - Module 01 - Computer Abstractions and Technologyh_shatAinda não há avaliações
- High Performance Computing: 772 10 91 Thomas@chalmers - SeDocumento75 páginasHigh Performance Computing: 772 10 91 Thomas@chalmers - SetedlaonAinda não há avaliações
- Week 1 VerilogDocumento45 páginasWeek 1 VerilogDeekshith KumarAinda não há avaliações
- Computer ArchitectureDocumento667 páginasComputer Architecturevishalchaurasiya360001Ainda não há avaliações
- Lecture 01ddDocumento36 páginasLecture 01ddAmir SollehinAinda não há avaliações
- Modern Component Families and Circuit Block DesignNo EverandModern Component Families and Circuit Block DesignNota: 5 de 5 estrelas5/5 (1)
- Open-Source Robotics and Process Control Cookbook: Designing and Building Robust, Dependable Real-time SystemsNo EverandOpen-Source Robotics and Process Control Cookbook: Designing and Building Robust, Dependable Real-time SystemsNota: 3 de 5 estrelas3/5 (1)
- Bebop to the Boolean Boogie: An Unconventional Guide to ElectronicsNo EverandBebop to the Boolean Boogie: An Unconventional Guide to ElectronicsAinda não há avaliações
- B.e.cseDocumento107 páginasB.e.cseSangeetha ShankaranAinda não há avaliações
- Map ReduceDocumento8 páginasMap ReducemeerashekarAinda não há avaliações
- Cyclic Redundancy CheckDocumento3 páginasCyclic Redundancy CheckmeerashekarAinda não há avaliações
- Future of Computer ArchitectureDocumento46 páginasFuture of Computer ArchitecturemeerashekarAinda não há avaliações
- Xen Compared To Other HypervisorsDocumento6 páginasXen Compared To Other HypervisorspravinusturageAinda não há avaliações
- Map ReduceDocumento8 páginasMap ReducemeerashekarAinda não há avaliações
- To Work in The Field of Engineering Education.: ResumeDocumento5 páginasTo Work in The Field of Engineering Education.: ResumemeerashekarAinda não há avaliações
- Challenges in Securing The Interface Between The Cloud and Pervasive SystemsDocumento5 páginasChallenges in Securing The Interface Between The Cloud and Pervasive SystemsmeerashekarAinda não há avaliações
- University Questions DMDocumento7 páginasUniversity Questions DMmeerashekarAinda não há avaliações
- SQL Interview Questions and AnswersDocumento9 páginasSQL Interview Questions and AnswersmeerashekarAinda não há avaliações
- #Include #Include Void Main (CLRSCRDocumento36 páginas#Include #Include Void Main (CLRSCRmeerashekarAinda não há avaliações
- Web MiningDocumento53 páginasWeb MiningmeerashekarAinda não há avaliações
- 54AC/74AC14 Hex Inverter With Schmitt Trigger Input: General DescriptionDocumento7 páginas54AC/74AC14 Hex Inverter With Schmitt Trigger Input: General DescriptionJose FeghaliAinda não há avaliações
- Ece V Digital Signal Processing (10ec52) NotesDocumento160 páginasEce V Digital Signal Processing (10ec52) NotesVijay SaiAinda não há avaliações
- 4 ARM Parallelism PDFDocumento10 páginas4 ARM Parallelism PDFjehuAinda não há avaliações
- Ohm - Electronics General - Board Automation EditionDocumento50 páginasOhm - Electronics General - Board Automation EditionErmenegildo Morcillo CifuentesAinda não há avaliações
- Product Specifications: CharacteristicsDocumento3 páginasProduct Specifications: Characteristicseslam salmonyAinda não há avaliações
- Elek TrimDocumento23 páginasElek Trimsri_handainaAinda não há avaliações
- BMED Duplex Vertical 3-5HP Oil-Less Rotary Vacuum NFPA Technical Datasheet EN 4107951081Documento2 páginasBMED Duplex Vertical 3-5HP Oil-Less Rotary Vacuum NFPA Technical Datasheet EN 4107951081ARN18Ainda não há avaliações
- Yamaha EMX5000 12Documento36 páginasYamaha EMX5000 12Anonymous d7AHJZQketAinda não há avaliações
- Corneta 855-BN-D30-BDocumento3 páginasCorneta 855-BN-D30-BnelsonAinda não há avaliações
- PID Controller For 2 Wheel RobotDocumento15 páginasPID Controller For 2 Wheel Robotkazi shahadatAinda não há avaliações
- Control Concepts Surge Protective Device Training ManualDocumento23 páginasControl Concepts Surge Protective Device Training ManualCatagña AnyAinda não há avaliações
- AeroTrak-Portable-9350-9550 A4 5001205 RevR WebDocumento2 páginasAeroTrak-Portable-9350-9550 A4 5001205 RevR WebTrung PhanAinda não há avaliações
- Malabar Cements LimitedDocumento16 páginasMalabar Cements LimitedachyuachyuthanAinda não há avaliações
- Logosol Supervisor I/O Controller CNC-SK-2310g2Documento24 páginasLogosol Supervisor I/O Controller CNC-SK-2310g2Ilhami DemirAinda não há avaliações
- Manual Allem BradleyDocumento212 páginasManual Allem BradleyKaaberAinda não há avaliações
- Ifr6015 Military Flight Line Test Set Brochures enDocumento2 páginasIfr6015 Military Flight Line Test Set Brochures enhennryns100% (1)
- Murphy PDFDocumento3 páginasMurphy PDFeduardo100% (1)
- MSM SolenoidDocumento27 páginasMSM Solenoidparahu ariefAinda não há avaliações
- Automatic Generation Control in A Deregulated Power SystemDocumento6 páginasAutomatic Generation Control in A Deregulated Power SystemamaytaAinda não há avaliações
- Public Address and Music Systems SECTION 27 51 16Documento13 páginasPublic Address and Music Systems SECTION 27 51 16Gamal AhmedAinda não há avaliações
- Automatic Meter ReadingDocumento17 páginasAutomatic Meter Readingpradeep513Ainda não há avaliações
- Am25ck PDFDocumento2 páginasAm25ck PDFLogan Marquez AguayoAinda não há avaliações
- SDM530CT-MODBUS TableDocumento20 páginasSDM530CT-MODBUS TableChrisAinda não há avaliações
- Onan YB GenManualDocumento41 páginasOnan YB GenManualBentley WestfieldAinda não há avaliações
- PV Module Safety Qualification According To IEC 61730:2004 EN 61730:2007Documento6 páginasPV Module Safety Qualification According To IEC 61730:2004 EN 61730:2007Vinko RazlAinda não há avaliações
- EM Waves Use and ApplicationDocumento3 páginasEM Waves Use and ApplicationFourth World Music100% (1)
- English User Manual K3110Documento14 páginasEnglish User Manual K3110rohitrizAinda não há avaliações
- SoC Design FlowDocumento21 páginasSoC Design FlowSatinder Paul SinghAinda não há avaliações
- Empowerment Chapter-1Documento27 páginasEmpowerment Chapter-1John Lester M. Dela Cruz100% (1)