Você também pode gostar
- Privacy in the Modern Age: The Search for SolutionsNo EverandPrivacy in the Modern Age: The Search for SolutionsNota: 4 de 5 estrelas4/5 (3)
- CH 07Documento36 páginasCH 07Quoc TruongAinda não há avaliações
- Information Security CS 526: Topic 21: Data PrivacyDocumento39 páginasInformation Security CS 526: Topic 21: Data PrivacyJhoyxcie Princess J SombilonAinda não há avaliações
- ch06 AnonymizationDocumento40 páginasch06 AnonymizationQuoc TruongAinda não há avaliações
- 2007 78lakjfjikfDocumento11 páginas2007 78lakjfjikfdai itakoAinda não há avaliações
- A Review On K-Anonymization TechniquesDocumento8 páginasA Review On K-Anonymization TechniquesDharmavarapu Balaram ChowdaryAinda não há avaliações
- Robust De-Anonymization of Large Datasets (How To Break Anonymity of The Netflix Prize Dataset)Documento24 páginasRobust De-Anonymization of Large Datasets (How To Break Anonymity of The Netflix Prize Dataset)guanlin HeAinda não há avaliações
- Privacy Preservation For Knowledge Discovery: A Survey: Jalpa Shah, Mr. Vinit Kumar GuptaDocumento8 páginasPrivacy Preservation For Knowledge Discovery: A Survey: Jalpa Shah, Mr. Vinit Kumar GuptaInternational Organization of Scientific Research (IOSR)Ainda não há avaliações
- A Survey On Data Anonymization For Big Data SecurityDocumento4 páginasA Survey On Data Anonymization For Big Data SecurityJournal 4 ResearchAinda não há avaliações
- Week11a - Lecture 7 - Achieving PrivacyDocumento49 páginasWeek11a - Lecture 7 - Achieving Privacynawwad65Ainda não há avaliações
- Ijaerv12n8 25Documento5 páginasIjaerv12n8 25Babila JosephAinda não há avaliações
- Anonimity Via ClusteringDocumento9 páginasAnonimity Via ClusteringaskaterinaAinda não há avaliações
- Differential PrivacyDocumento56 páginasDifferential Privacyduh1988Ainda não há avaliações
- Chapter FourDocumento23 páginasChapter FourBagong Dwi AtmaAinda não há avaliações
- Probabilistic Inference Protection On Anonymized DataDocumento6 páginasProbabilistic Inference Protection On Anonymized DataVincent YanAinda não há avaliações
- Estimating The Success of Re-Identifications in Incomplete Datasets Using Generative ModelsDocumento9 páginasEstimating The Success of Re-Identifications in Incomplete Datasets Using Generative ModelsasAinda não há avaliações
- Econometrics of Panel Data - Michele CinceraDocumento10 páginasEconometrics of Panel Data - Michele CinceramsidamaniAinda não há avaliações
- Current Trends in Data Security: Dan Suciu Joint Work With Gerome MiklauDocumento48 páginasCurrent Trends in Data Security: Dan Suciu Joint Work With Gerome MiklauDheerajAinda não há avaliações
- ENGRD 2700 Lecture #1Documento24 páginasENGRD 2700 Lecture #1anon283Ainda não há avaliações
- An Approach For Privacy Preservation Using XML Distance MeasureDocumento5 páginasAn Approach For Privacy Preservation Using XML Distance MeasureIjesat JournalAinda não há avaliações
- Module 4Documento52 páginasModule 4Aarindam RainaAinda não há avaliações
- Disclosure Risk vs. Data Utility: The R-U Confidentiality MapDocumento31 páginasDisclosure Risk vs. Data Utility: The R-U Confidentiality Mapmohamed el amine brahimiAinda não há avaliações
- User GuideDocumento75 páginasUser GuideManohar GiriAinda não há avaliações
- Concepts and Techniques: Data MiningDocumento80 páginasConcepts and Techniques: Data MiningdivyaAinda não há avaliações
- A New Method of Privacy Protection: Random K-AnonymousDocumento12 páginasA New Method of Privacy Protection: Random K-AnonymousArshiya sadafAinda não há avaliações
- Cours 2 - KedgeDocumento32 páginasCours 2 - KedgeHà Trang ĐặngAinda não há avaliações
- Chapter 6-Data AnonymizationDocumento37 páginasChapter 6-Data AnonymizationelenacharlsblackAinda não há avaliações
- Workshop VI: Quantum Biology: Does It Exist and Is This Important?Documento24 páginasWorkshop VI: Quantum Biology: Does It Exist and Is This Important?SushmitAinda não há avaliações
- JS 115 Forensic DNA Databases 11-15-06Documento59 páginasJS 115 Forensic DNA Databases 11-15-06mohamed.puntforensicsAinda não há avaliações
- Data Preprocessing - Data CleaningDocumento29 páginasData Preprocessing - Data CleaningtierSarge100% (1)
- About This ReportDocumento43 páginasAbout This ReportKRISHAN KUMARAinda não há avaliações
- Big Data PrivacyDocumento28 páginasBig Data PrivacyVairavel ChenniyappanAinda não há avaliações
- Paradox DocumentationDocumento1 páginaParadox DocumentationGabrielaAinda não há avaliações
- 2019-Is Data Privacy Real - Don't Bet On ItDocumento9 páginas2019-Is Data Privacy Real - Don't Bet On ItAlvarian AdnanAinda não há avaliações
- Algorithmics Research On Knowledge Discovery and Data MiningDocumento32 páginasAlgorithmics Research On Knowledge Discovery and Data MiningadvancemindAinda não há avaliações
- Test Bank For Accounting Information Systems 12th Edition RomneyDocumento36 páginasTest Bank For Accounting Information Systems 12th Edition Romneyvolleyedrompeef2q100% (48)
- K Anonymity 2Documento18 páginasK Anonymity 2Byakuya BleachAinda não há avaliações
- T Closeness Privacy Beyond K Anonymity and L DiversityDocumento10 páginasT Closeness Privacy Beyond K Anonymity and L DiversityAntoniouNikosAinda não há avaliações
- Report Regarding Cambridge Analytica LLC and SCL Elections LTDDocumento36 páginasReport Regarding Cambridge Analytica LLC and SCL Elections LTDElias Alboadicto Villagrán DonaireAinda não há avaliações
- Inequality Before The Law The Canadian Experience of Racial ProfilingDocumento97 páginasInequality Before The Law The Canadian Experience of Racial ProfilingPaisley RaeAinda não há avaliações
- Instucciones Proyecto 1Documento10 páginasInstucciones Proyecto 1Mafer LopezAinda não há avaliações
- 02 DataPrec 2 My NotesDocumento104 páginas02 DataPrec 2 My NotesWiam AlAliAinda não há avaliações
- Mining Statistics Canada's: DatabasesDocumento34 páginasMining Statistics Canada's: DatabaseszsiddiquiAinda não há avaliações
- ABF Webinar - Episode 5Documento46 páginasABF Webinar - Episode 5Dwi SusantiAinda não há avaliações
- Gmail - Import AI 366 - 500bn Text Tokens Facebook Vs Princeton Why Small Government Types Hate The Biden EODocumento12 páginasGmail - Import AI 366 - 500bn Text Tokens Facebook Vs Princeton Why Small Government Types Hate The Biden EOEnrique GatoAinda não há avaliações
- 3 Census BureauDocumento12 páginas3 Census BureauRoman TilahunAinda não há avaliações
- Personality Psychology 6th Edition Larsen Test BankDocumento35 páginasPersonality Psychology 6th Edition Larsen Test Bankjovialtybowbentqjkz88100% (18)
- Privacy Preserving by Anonymization ApproachDocumento5 páginasPrivacy Preserving by Anonymization ApproachEditor IJRITCCAinda não há avaliações
- Lecture2 1Documento16 páginasLecture2 1harsharaikkonenAinda não há avaliações
- Crime Mapping News Vol 4 Issue 4 (Fall 2002)Documento12 páginasCrime Mapping News Vol 4 Issue 4 (Fall 2002)PoliceFoundationAinda não há avaliações
- Health Informatics Course - Unit 2.2a - Privacy - Security - and Confidentiality - Final - 03312020Documento55 páginasHealth Informatics Course - Unit 2.2a - Privacy - Security - and Confidentiality - Final - 03312020Mac Kevin MandapAinda não há avaliações
- 2008 02 Robust De-Anonymization of Large Sparse DatasetsDocumento15 páginas2008 02 Robust De-Anonymization of Large Sparse DatasetsNgoc Son PhamAinda não há avaliações
- To StatisticsDocumento19 páginasTo Statisticscheruku. navyasaiAinda não há avaliações
- Empirical Project 1 Stories From The Atlas: Describing Data Using Maps, Regressions, and CorrelationsDocumento10 páginasEmpirical Project 1 Stories From The Atlas: Describing Data Using Maps, Regressions, and CorrelationslefanAinda não há avaliações
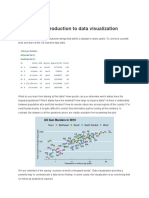
- Chapter 6 Introduction To Data Visualization - Introduction To Data ScienceDocumento4 páginasChapter 6 Introduction To Data Visualization - Introduction To Data ScienceUmar IsmailAinda não há avaliações
- Quick Question42Documento51 páginasQuick Question42Gadaa MeelbaAinda não há avaliações
- Maths Project On StatisticsDocumento7 páginasMaths Project On Statisticschandrasekhar hazraAinda não há avaliações
- Privacy Issues Surrounding Personal Identification SystemsDocumento29 páginasPrivacy Issues Surrounding Personal Identification SystemsKecoa NgesotAinda não há avaliações
- Preprocessing TechniquesDocumento63 páginasPreprocessing TechniquesrekhaAinda não há avaliações
- Seeing Through Statistics 4th Edition Utts Test BankDocumento35 páginasSeeing Through Statistics 4th Edition Utts Test Bankmarianmckinneys6bkar100% (28)
- 5 Isomorphism, SubgraphDocumento32 páginas5 Isomorphism, SubgraphJeena MathewAinda não há avaliações
- CodDocumento5 páginasCodJeena MathewAinda não há avaliações
- Anonymization Enhancing Privacy and SecurityDocumento6 páginasAnonymization Enhancing Privacy and SecurityJeena MathewAinda não há avaliações
- A Survey On Attack Prevention and HandlingDocumento5 páginasA Survey On Attack Prevention and HandlingJeena MathewAinda não há avaliações
- Privacy Preservation in Social NetworkDocumento118 páginasPrivacy Preservation in Social NetworkJeena MathewAinda não há avaliações
- UML Diagrams ReferencesDocumento41 páginasUML Diagrams ReferencespaulminhtriAinda não há avaliações
- Compilers Basics For IBPS IT Officers Exam - Gr8AmbitionZDocumento11 páginasCompilers Basics For IBPS IT Officers Exam - Gr8AmbitionZJeena MathewAinda não há avaliações
- Web Anywhererr PDFDocumento9 páginasWeb Anywhererr PDFJeena MathewAinda não há avaliações
- Machine Learning Tutorial Machine Learning TutorialDocumento33 páginasMachine Learning Tutorial Machine Learning TutorialSudhakar MurugasenAinda não há avaliações
- Method of Designing Zvs Boost Converter: Mirosáaw Luft, Elībieta Szychta, Leszek SzychtaDocumento5 páginasMethod of Designing Zvs Boost Converter: Mirosáaw Luft, Elībieta Szychta, Leszek SzychtaJeena MathewAinda não há avaliações
- Web Anywhere PDFDocumento8 páginasWeb Anywhere PDFJeena MathewAinda não há avaliações
- Method of Designing Zvs Boost Converter: Mirosáaw Luft, Elībieta Szychta, Leszek SzychtaDocumento5 páginasMethod of Designing Zvs Boost Converter: Mirosáaw Luft, Elībieta Szychta, Leszek SzychtaJeena MathewAinda não há avaliações
- Relevantmultimediaquestionanswering 140426114308 Phpapp02Documento73 páginasRelevantmultimediaquestionanswering 140426114308 Phpapp02Jeena MathewAinda não há avaliações
- ID3 AllanNeymarkDocumento22 páginasID3 AllanNeymarkRajesh KumarAinda não há avaliações
- Project Report For MEDocumento49 páginasProject Report For MEsumitAinda não há avaliações
- Prediction of Student Academic Performance by An Application of K-Means Clustering AlgorithmDocumento3 páginasPrediction of Student Academic Performance by An Application of K-Means Clustering AlgorithmJeena MathewAinda não há avaliações
- Decision Tree 2Documento20 páginasDecision Tree 2nguyenxuanthai140585Ainda não há avaliações
- WdecDocumento35 páginasWdecJeena MathewAinda não há avaliações
- Machine Learning Tutorial Machine Learning TutorialDocumento33 páginasMachine Learning Tutorial Machine Learning TutorialSudhakar MurugasenAinda não há avaliações
- Sample Data Mining Project PaperDocumento32 páginasSample Data Mining Project PaperAdisu Wagaw100% (1)
- Project Hand GestureDocumento69 páginasProject Hand Gesturenguyenxuanthai140585Ainda não há avaliações
- Vol1issue3 Paper63Documento9 páginasVol1issue3 Paper63Jeena MathewAinda não há avaliações
- Expert Systems With Applications: Florin Gorunescu, Smaranda Belciug, Marina Gorunescu, Radu BadeaDocumento9 páginasExpert Systems With Applications: Florin Gorunescu, Smaranda Belciug, Marina Gorunescu, Radu BadeaJeena MathewAinda não há avaliações
- V2i7 0007 PDFDocumento7 páginasV2i7 0007 PDFJeena MathewAinda não há avaliações
- 9 Mining Student Data Using Decision Trees - ACIT 2006Documento5 páginas9 Mining Student Data Using Decision Trees - ACIT 2006Jeena MathewAinda não há avaliações
- R M S - D R C: Esource Anagement For Oftware Efined Adio LoudsDocumento10 páginasR M S - D R C: Esource Anagement For Oftware Efined Adio LoudsJeena MathewAinda não há avaliações
- V3i8 0105 PDFDocumento4 páginasV3i8 0105 PDFJeena MathewAinda não há avaliações
- Achievement 2Documento10 páginasAchievement 2jingle_flores07Ainda não há avaliações
- From Data Mining To Knowledge Discovery in Databases PDFDocumento18 páginasFrom Data Mining To Knowledge Discovery in Databases PDFAhmar Taufik SafaatAinda não há avaliações
- RFQ - Printer Cartridge HP - A0066Documento1 páginaRFQ - Printer Cartridge HP - A0066منتظر عليAinda não há avaliações
- Thermal Plasma TechDocumento4 páginasThermal Plasma TechjohnribarAinda não há avaliações
- Versidrain 30: Green RoofDocumento2 páginasVersidrain 30: Green RoofMichael Tiu TorresAinda não há avaliações
- SMILE System For 2d 3d DSMC ComputationDocumento6 páginasSMILE System For 2d 3d DSMC ComputationchanmyaAinda não há avaliações
- PTC ThermistorsDocumento9 páginasPTC ThermistorsbuspersAinda não há avaliações
- Final Drive Transmission Assembly - Prior To SN Dac0202754 (1) 9030Documento3 páginasFinal Drive Transmission Assembly - Prior To SN Dac0202754 (1) 9030Caroline RosaAinda não há avaliações
- Performance Measurement. The ENAPS ApproachDocumento33 páginasPerformance Measurement. The ENAPS ApproachPavel Yandyganov100% (1)
- Mechanics Guidelines 23 Div ST Fair ExhibitDocumento8 páginasMechanics Guidelines 23 Div ST Fair ExhibitMarilyn GarciaAinda não há avaliações
- CV FaisalDocumento3 páginasCV FaisalAnonymous UNekZM6Ainda não há avaliações
- ("Love",:Ruby) .Each ( - I - P I)Documento32 páginas("Love",:Ruby) .Each ( - I - P I)hervalAinda não há avaliações
- Philips New Pricelist July 2022Documento3 páginasPhilips New Pricelist July 2022PravinAinda não há avaliações
- Thesis Process MiningDocumento98 páginasThesis Process MiningRamyapremnathAinda não há avaliações
- Zombie RPGDocumento30 páginasZombie RPGBo100% (3)
- Aluminium Composite PanelsDocumento46 páginasAluminium Composite PanelsSashwat GhaiAinda não há avaliações
- K9900 Series Level GaugeDocumento2 páginasK9900 Series Level GaugeBilly Isea DenaroAinda não há avaliações
- sw8 chp06Documento22 páginassw8 chp06api-115560904Ainda não há avaliações
- Check Mode Procedure: Hand-Held TesterDocumento1 páginaCheck Mode Procedure: Hand-Held TesterClodoaldo BiassioAinda não há avaliações
- Códigos de Fallas de Problemas Específicos de PEUGEOTDocumento8 páginasCódigos de Fallas de Problemas Específicos de PEUGEOTJesus GarciaAinda não há avaliações
- P-L-N-Statistik 2011Documento104 páginasP-L-N-Statistik 2011Ahmad AfandiAinda não há avaliações
- Computer Reviewer For Grade 6Documento4 páginasComputer Reviewer For Grade 6Cyril DaguilAinda não há avaliações
- WSO&WSP Excel Shortcuts Cheat SheetsDocumento7 páginasWSO&WSP Excel Shortcuts Cheat SheetsAndy ZouAinda não há avaliações
- Datasheet Borne SiemensDocumento3 páginasDatasheet Borne Siemenslorentz franklinAinda não há avaliações
- Design For ReliabilityDocumento32 páginasDesign For ReliabilityArman CustodioAinda não há avaliações
- Rules For Building and Classing Marine Vessels 2022 - Part 5C, Specific Vessel Types (Chapters 1-6)Documento1.087 páginasRules For Building and Classing Marine Vessels 2022 - Part 5C, Specific Vessel Types (Chapters 1-6)Muhammad Rifqi ZulfahmiAinda não há avaliações
- Orbital Rendezvous Using An Augmented Lambert Guidance SchemeDocumento0 páginaOrbital Rendezvous Using An Augmented Lambert Guidance Schemegirithik14Ainda não há avaliações
- SAP OKES - Splitting StructureDocumento9 páginasSAP OKES - Splitting StructureneoclessAinda não há avaliações
- Flame Arrester Installation and Maintenance Instructions ForDocumento3 páginasFlame Arrester Installation and Maintenance Instructions Forhk168Ainda não há avaliações
- Information Leaflet: 1. Introduction To PieasDocumento4 páginasInformation Leaflet: 1. Introduction To Pieascensored126Ainda não há avaliações
- Shot Blasting Machines: Laser PeeningDocumento2 páginasShot Blasting Machines: Laser Peeningrahul srivastavaAinda não há avaliações
- WWW - Manaresults.Co - In: Set No. 1Documento1 páginaWWW - Manaresults.Co - In: Set No. 1My Technical videosAinda não há avaliações