Você também pode gostar
- Line Drawing Algorithm: Mastering Techniques for Precision Image RenderingNo EverandLine Drawing Algorithm: Mastering Techniques for Precision Image RenderingAinda não há avaliações
- Algorithms in The Real World: Data Compression: Lectures 1 and 2Documento55 páginasAlgorithms in The Real World: Data Compression: Lectures 1 and 2Rakesh InaniAinda não há avaliações
- Lemp El Ziv CompressionDocumento6 páginasLemp El Ziv CompressionssfofoAinda não há avaliações
- Digital Communication Systems: ECE-4001 TASK-3Documento12 páginasDigital Communication Systems: ECE-4001 TASK-3Aniket SaxenaAinda não há avaliações
- Digital Communication Systems: ECE-4001 TASK-3Documento11 páginasDigital Communication Systems: ECE-4001 TASK-3Aniket SaxenaAinda não há avaliações
- Multimedia Assignment2Documento5 páginasMultimedia Assignment2bandishtiAinda não há avaliações
- Why Needed?: Without Compression, These Applications Would Not Be FeasibleDocumento11 páginasWhy Needed?: Without Compression, These Applications Would Not Be Feasiblesmile00972Ainda não há avaliações
- Fast Implementations of RSA CryptographyDocumento8 páginasFast Implementations of RSA Cryptographyandct1081Ainda não há avaliações
- Low-Power Design of Reed-Solomon Encoders: Wei Zhang, Jing Wang Xinmiao ZhangDocumento4 páginasLow-Power Design of Reed-Solomon Encoders: Wei Zhang, Jing Wang Xinmiao ZhangKrishna PrasadAinda não há avaliações
- Viterbi DecodingDocumento4 páginasViterbi DecodingGaurav NavalAinda não há avaliações
- Illuminating The Structure Code and Decoder Parallel Concatenated Recursive Systematic CodesDocumento6 páginasIlluminating The Structure Code and Decoder Parallel Concatenated Recursive Systematic Codessinne4Ainda não há avaliações
- NoneDocumento23 páginasNoneAnkit YadavAinda não há avaliações
- Software-Defined Radio Lab 2: Data Modulation and TransmissionDocumento8 páginasSoftware-Defined Radio Lab 2: Data Modulation and TransmissionpaulCGAinda não há avaliações
- Tornado Codes and Luby Transform Codes PDFDocumento12 páginasTornado Codes and Luby Transform Codes PDFpathmakerpkAinda não há avaliações
- 09 CM0340 Basic Compression AlgorithmsDocumento73 páginas09 CM0340 Basic Compression AlgorithmsShobhit JainAinda não há avaliações
- Mid-Term Q. Paper DCNDocumento2 páginasMid-Term Q. Paper DCNm0nster eenoAinda não há avaliações
- Expt-2 - Lab Manual - TE LabDocumento8 páginasExpt-2 - Lab Manual - TE LabRuham RofiqueAinda não há avaliações
- PCM 1Documento5 páginasPCM 1Jose David Ramos RiosAinda não há avaliações
- General Packet Radio Service Physical-Layer Performance SimulationDocumento6 páginasGeneral Packet Radio Service Physical-Layer Performance SimulationAdeeb HusnainAinda não há avaliações
- Exam #1 For Computer Networks (CIS 6930) SOLUTIONS : Problem #1Documento5 páginasExam #1 For Computer Networks (CIS 6930) SOLUTIONS : Problem #187bbAinda não há avaliações
- Rawan Ashraf 2019 - 13921 Comm. Lab5Documento17 páginasRawan Ashraf 2019 - 13921 Comm. Lab5Rawan Ashraf Mohamed SolimanAinda não há avaliações
- 7 - PCM - Baseband Signaling - Line CodesDocumento21 páginas7 - PCM - Baseband Signaling - Line CodesMichel Abou HaidarAinda não há avaliações
- Low-Density Parity-Check CodesDocumento6 páginasLow-Density Parity-Check CodesAhmed TorkiAinda não há avaliações
- A Matlab Implementation of A DPCM Encoder and DecoderDocumento11 páginasA Matlab Implementation of A DPCM Encoder and DecodervishalAinda não há avaliações
- Kasraian ECET375 Week2Documento42 páginasKasraian ECET375 Week2Raul PerdomoAinda não há avaliações
- Data Communication - Spring'17Documento60 páginasData Communication - Spring'17tasmia abedinAinda não há avaliações
- Lets Discuss (How, What and Why) : 16 QAM Simulation in MATLABDocumento7 páginasLets Discuss (How, What and Why) : 16 QAM Simulation in MATLABpreetik917Ainda não há avaliações
- Sequential Decoding by Stack AlgorithmDocumento9 páginasSequential Decoding by Stack AlgorithmRam Chandram100% (1)
- Soft Output DemapperDocumento5 páginasSoft Output DemapperSomendra SahuAinda não há avaliações
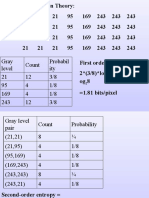
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Documento51 páginasGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaAinda não há avaliações
- When To Use System Objects Instead of MATLAB Functions: RandiDocumento14 páginasWhen To Use System Objects Instead of MATLAB Functions: RandiDeko Gallegos AlegriaAinda não há avaliações
- SC 12Documento45 páginasSC 12Warrior BroAinda não há avaliações
- 390 Hills SystemDocumento25 páginas390 Hills SystemKarthick NarayananAinda não há avaliações
- 20.5 Arithmetic CodingDocumento6 páginas20.5 Arithmetic CodingVinay GuptaAinda não há avaliações
- Exam in Computer Networks A (Datornätverk A) : Magnus - Eriksson@miun - SeDocumento6 páginasExam in Computer Networks A (Datornätverk A) : Magnus - Eriksson@miun - SeHjernquistAinda não há avaliações
- 8 - DPCM-Linear Prediction-DMDocumento37 páginas8 - DPCM-Linear Prediction-DMMichel Abou HaidarAinda não há avaliações
- Pulse Code ModulationDocumento16 páginasPulse Code ModulationKissi MissiAinda não há avaliações
- Wireless Comm Systems2Documento23 páginasWireless Comm Systems2abdulsahibAinda não há avaliações
- Performance Analysis of 16 Qam Modulation Systems in Awgn Channel Using MatlabDocumento6 páginasPerformance Analysis of 16 Qam Modulation Systems in Awgn Channel Using MatlabAnonymous elrSyA30Ainda não há avaliações
- Principles Comm EXP 9 Student Manual NEWDocumento13 páginasPrinciples Comm EXP 9 Student Manual NEWsamiul mostafiz inzamAinda não há avaliações
- SPA Against An FPGA-Based RSA Implementation With A High-Radix Montgomery MultiplierDocumento4 páginasSPA Against An FPGA-Based RSA Implementation With A High-Radix Montgomery MultiplierAlexis GhillisAinda não há avaliações
- COMMUNICATION 2 (Reviewer)Documento22 páginasCOMMUNICATION 2 (Reviewer)Jovel Jhon Opiana100% (1)
- Compression IIDocumento51 páginasCompression IIJagadeesh NaniAinda não há avaliações
- Wireless Com. Report 20111115 - EnglishDocumento23 páginasWireless Com. Report 20111115 - EnglishHoang MaiAinda não há avaliações
- Slot24 25 26 TextProcessing 2021 04Documento58 páginasSlot24 25 26 TextProcessing 2021 04Công QuânAinda não há avaliações
- (Y2006) A Scalable Architecture For High-Throughput Regular-Expression Pattern MatchingDocumento26 páginas(Y2006) A Scalable Architecture For High-Throughput Regular-Expression Pattern MatchingGhilli TecAinda não há avaliações
- Serial Concatenated Convolutional Codes Design and AnalysisDocumento6 páginasSerial Concatenated Convolutional Codes Design and Analysisosho_peace100% (1)
- Chapter Six 6A ICDocumento30 páginasChapter Six 6A ICRobera GetachewAinda não há avaliações
- Key Private KeyDocumento5 páginasKey Private KeyShakiraAinda não há avaliações
- Golomb CodeDocumento11 páginasGolomb CodeBranimir PetrovićAinda não há avaliações
- Information Theory, Coding and Cryptography Unit-5 by Arun Pratap SinghDocumento79 páginasInformation Theory, Coding and Cryptography Unit-5 by Arun Pratap SinghArunPratapSingh100% (2)
- Data Transmission Lab: Communication SystemDocumento8 páginasData Transmission Lab: Communication SystemHoang MaiAinda não há avaliações
- FALLSEM2022-23 CSE4019 ETH VL2022230104728 2022-10-19 Reference-Material-IDocumento33 páginasFALLSEM2022-23 CSE4019 ETH VL2022230104728 2022-10-19 Reference-Material-ISRISHTI ACHARYYA 20BCE2561Ainda não há avaliações
- Huffman Coding TechniqueDocumento13 páginasHuffman Coding TechniqueAnchal RathoreAinda não há avaliações
- 16-QAM Digital ModulationDocumento8 páginas16-QAM Digital ModulationGowtham Sivakumar100% (1)
- CABAC Encoder: Context Based Adaptive Binary Arithmetic Coding EncoderDocumento8 páginasCABAC Encoder: Context Based Adaptive Binary Arithmetic Coding EncoderKeshav AwasthiAinda não há avaliações
- Lab 2Documento4 páginasLab 2Risinu WijesingheAinda não há avaliações
- Izzat Bin Zainal Abidin (41496) Tutorial 3: SolutionDocumento3 páginasIzzat Bin Zainal Abidin (41496) Tutorial 3: SolutionZA IzatAinda não há avaliações
- Simulation of Digital Communication Systems Using MatlabNo EverandSimulation of Digital Communication Systems Using MatlabNota: 3.5 de 5 estrelas3.5/5 (22)
- Image EnhancementDocumento38 páginasImage EnhancementRakesh InaniAinda não há avaliações
- L10 - Walsh & Hadamard TransformsDocumento25 páginasL10 - Walsh & Hadamard TransformsRakesh Inani100% (1)
- FirpmDocumento5 páginasFirpmnotthetupAinda não há avaliações
- Frequency Domain FiltersDocumento43 páginasFrequency Domain FiltersRakesh InaniAinda não há avaliações
- JPEGDocumento29 páginasJPEGRakesh InaniAinda não há avaliações
- Cyclic Redundancy CheckDocumento9 páginasCyclic Redundancy CheckRakesh InaniAinda não há avaliações
- DFT PropertiesDocumento37 páginasDFT PropertiesRakesh InaniAinda não há avaliações
- Concave Function: From Wikipedia, The Free EncyclopediaDocumento3 páginasConcave Function: From Wikipedia, The Free EncyclopediaRakesh InaniAinda não há avaliações
- Deflate: From Wikipedia, The Free EncyclopediaDocumento9 páginasDeflate: From Wikipedia, The Free EncyclopediaRakesh InaniAinda não há avaliações
- Histogram ProcessingDocumento27 páginasHistogram ProcessingRakesh InaniAinda não há avaliações
- ARC (File Format)Documento5 páginasARC (File Format)Rakesh InaniAinda não há avaliações
- Convex Function: From Wikipedia, The Free EncyclopediaDocumento7 páginasConvex Function: From Wikipedia, The Free EncyclopediaRakesh InaniAinda não há avaliações
- Haar TransformDocumento12 páginasHaar TransformRakesh InaniAinda não há avaliações
- Burrows-Wheeler Transform - Wikipedia, The Free EncyclopediaDocumento10 páginasBurrows-Wheeler Transform - Wikipedia, The Free EncyclopediaRakesh InaniAinda não há avaliações
- Entropy CodingDocumento18 páginasEntropy CodingRakesh InaniAinda não há avaliações
- Run-Length, Golomb, and Tunstall Codes: Thinh Nguyen Oregon State UniversityDocumento26 páginasRun-Length, Golomb, and Tunstall Codes: Thinh Nguyen Oregon State UniversityRakesh InaniAinda não há avaliações
- Mathematical PrelimsDocumento13 páginasMathematical PrelimsRakesh InaniAinda não há avaliações
- The Burrows-Wheeler TransformDocumento64 páginasThe Burrows-Wheeler TransformRakesh InaniAinda não há avaliações
- Transform Coding IIDocumento19 páginasTransform Coding IIRakesh InaniAinda não há avaliações
- Lossy Compression Iii - 1Documento21 páginasLossy Compression Iii - 1Rakesh InaniAinda não há avaliações