Você também pode gostar
- Build A 10 Ton Hydraulic PressDocumento10 páginasBuild A 10 Ton Hydraulic PressManuel SterlingAinda não há avaliações
- MCS-011 Solved Assignment 2015-16 IpDocumento12 páginasMCS-011 Solved Assignment 2015-16 IpJigar NanduAinda não há avaliações
- Mastering Microcontrollers Helped by ArduinoDocumento23 páginasMastering Microcontrollers Helped by ArduinoMeri Terihaj100% (2)
- Computer Science (9608)Documento38 páginasComputer Science (9608)Attique RehmanAinda não há avaliações
- Is 15707 2006Documento23 páginasIs 15707 2006anupam789Ainda não há avaliações
- Heat ExchangersDocumento25 páginasHeat ExchangersMohammed Kabiruddin100% (7)
- Image Compression Coding SchemesDocumento96 páginasImage Compression Coding Schemesresmi_ng50% (4)
- Tailless AircraftDocumento17 páginasTailless AircraftVikasVickyAinda não há avaliações
- Modern Introduction to Object Oriented Programming for Prospective DevelopersNo EverandModern Introduction to Object Oriented Programming for Prospective DevelopersAinda não há avaliações
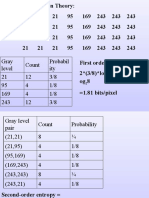
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Documento51 páginasGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaAinda não há avaliações
- Image Compression (Chapter 8) : CS474/674 - Prof. BebisDocumento128 páginasImage Compression (Chapter 8) : CS474/674 - Prof. Bebissrc0108Ainda não há avaliações
- Why Needed?: Without Compression, These Applications Would Not Be FeasibleDocumento11 páginasWhy Needed?: Without Compression, These Applications Would Not Be Feasiblesmile00972Ainda não há avaliações
- 3.multimedia Compression AlgorithmsDocumento23 páginas3.multimedia Compression Algorithmsaishu sillAinda não há avaliações
- Mad Unit 3-JntuworldDocumento53 páginasMad Unit 3-JntuworldDilip TheLipAinda não há avaliações
- Chapter Six 6A ICDocumento30 páginasChapter Six 6A ICRobera GetachewAinda não há avaliações
- DIP Image Compression 1.11.2015Documento66 páginasDIP Image Compression 1.11.2015LayaAinda não há avaliações
- Text and Image CompressionDocumento57 páginasText and Image Compressionoureducation.in100% (1)
- Lec6 - Scalar Abnd Vector QuantizationDocumento32 páginasLec6 - Scalar Abnd Vector QuantizationAli AhmedAinda não há avaliações
- Image CompressionDocumento50 páginasImage CompressionVipin SinghAinda não há avaliações
- GROUP 3 Image CompressionDocumento31 páginasGROUP 3 Image CompressionPrayerAinda não há avaliações
- Huffman Coding TechniqueDocumento13 páginasHuffman Coding TechniqueAnchal RathoreAinda não há avaliações
- Image Compression (Chapter 8) : CS474/674 - Prof. BebisDocumento75 páginasImage Compression (Chapter 8) : CS474/674 - Prof. BebisKoushik SupercalifragilisticAinda não há avaliações
- Arithmetic Coding: Implementation Details and ExamplesDocumento11 páginasArithmetic Coding: Implementation Details and ExamplesShunmuga PriyanAinda não há avaliações
- UNIT5 Part 2Documento54 páginasUNIT5 Part 2Venkateswara RajuAinda não há avaliações
- UNIT5 Part 2-1-19Documento19 páginasUNIT5 Part 2-1-19Venkateswara RajuAinda não há avaliações
- UNIT5 Part 2-1-35Documento35 páginasUNIT5 Part 2-1-35Venkateswara RajuAinda não há avaliações
- Image CompressionDocumento133 páginasImage CompressionDeebika KaliyaperumalAinda não há avaliações
- Tornado Codes and Luby Transform Codes PDFDocumento12 páginasTornado Codes and Luby Transform Codes PDFpathmakerpkAinda não há avaliações
- Arithmetic Coding: Presented By: Einat & KimDocumento48 páginasArithmetic Coding: Presented By: Einat & Kimjigar16789Ainda não há avaliações
- CH 3 DatalinkDocumento35 páginasCH 3 DatalinksimayyilmazAinda não há avaliações
- Error-Free Compression: Variable Length CodingDocumento13 páginasError-Free Compression: Variable Length CodingVanithaAinda não há avaliações
- EntropyDocumento10 páginasEntropyRajesh TripathyAinda não há avaliações
- Dip 4 Unit NotesDocumento10 páginasDip 4 Unit NotesMichael MariamAinda não há avaliações
- Channel CodingDocumento45 páginasChannel CodingTu Nguyen NgocAinda não há avaliações
- Data CompressionDocumento22 páginasData CompressionPrachi TrehanAinda não há avaliações
- Notes For Turbo CodesDocumento15 páginasNotes For Turbo CodesMaria AslamAinda não há avaliações
- Design of Convolutional Encoder and Viterbi Decoder Using MATLABDocumento6 páginasDesign of Convolutional Encoder and Viterbi Decoder Using MATLABThu NguyễnAinda não há avaliações
- DC Unit Test 2 Question BankDocumento4 páginasDC Unit Test 2 Question BankSiva KrishnaAinda não há avaliações
- Ece 306L - Experiment 4: Signal QuantizationDocumento10 páginasEce 306L - Experiment 4: Signal QuantizationAndy CaoAinda não há avaliações
- Data CompressionDocumento28 páginasData CompressionKimAinda não há avaliações
- ImageCompression-UNIT-V-students MaterialDocumento88 páginasImageCompression-UNIT-V-students MaterialHarika JangamAinda não há avaliações
- The Data Link LayerDocumento35 páginasThe Data Link Layernitu2012Ainda não há avaliações
- 09 CM0340 Basic Compression AlgorithmsDocumento73 páginas09 CM0340 Basic Compression AlgorithmsShobhit JainAinda não há avaliações
- Fault Tolerant Huffman Coding For JPEG Image Coding SystemDocumento11 páginasFault Tolerant Huffman Coding For JPEG Image Coding SystemMymy SuityAinda não há avaliações
- Low Density Parity Check CodesDocumento21 páginasLow Density Parity Check CodesPrithvi Raj0% (1)
- Chapter 8-Image CompressionDocumento61 páginasChapter 8-Image CompressionAshish GauravAinda não há avaliações
- Convolutional Codes Turbo Codes LDPC CodesDocumento49 páginasConvolutional Codes Turbo Codes LDPC CodesveerutheprinceAinda não há avaliações
- H.264 / MPEG-4 Part 10 White Paper Variable-Length Coding 1Documento7 páginasH.264 / MPEG-4 Part 10 White Paper Variable-Length Coding 1sadsdaAinda não há avaliações
- H.264 / MPEG-4 Part 10 White Paper Variable-Length Coding 1Documento7 páginasH.264 / MPEG-4 Part 10 White Paper Variable-Length Coding 1sadsdaAinda não há avaliações
- Chapter ThreeDocumento30 páginasChapter ThreemekuriaAinda não há avaliações
- Lec8 ConvDocumento28 páginasLec8 ConvYaseen MoAinda não há avaliações
- HasanDocumento8 páginasHasansumeiranAinda não há avaliações
- FALLSEM2022-23 CSE4019 ETH VL2022230104728 2022-10-19 Reference-Material-IDocumento33 páginasFALLSEM2022-23 CSE4019 ETH VL2022230104728 2022-10-19 Reference-Material-ISRISHTI ACHARYYA 20BCE2561Ainda não há avaliações
- 1.1.1 Reed - Solomon Code:: C F (U, U, , U, U)Documento4 páginas1.1.1 Reed - Solomon Code:: C F (U, U, , U, U)Tân ChipAinda não há avaliações
- Arithmetic Code Discussion and ImplementationDocumento11 páginasArithmetic Code Discussion and ImplementationperhackerAinda não há avaliações
- Lempel-Ziv Codes: 5 .1 Lemp El - Ziv P Ar SingDocumento12 páginasLempel-Ziv Codes: 5 .1 Lemp El - Ziv P Ar SingPablo MontalvoAinda não há avaliações
- Convolutional CodeDocumento15 páginasConvolutional CodeDhivya LakshmiAinda não há avaliações
- Development of Wimax Physical Layer Building BlocksDocumento5 páginasDevelopment of Wimax Physical Layer Building BlocksSandeep Kaur BhullarAinda não há avaliações
- Error Control Coding3Documento24 páginasError Control Coding3DuongMinhSOnAinda não há avaliações
- 0742 Clu Ever 2005Documento4 páginas0742 Clu Ever 2005Samir ChouchaneAinda não há avaliações
- VTU Exam Question Paper With Solution of 17EC741 Multimedia Communication Feb-2021-Prof. Aritri DebnathDocumento38 páginasVTU Exam Question Paper With Solution of 17EC741 Multimedia Communication Feb-2021-Prof. Aritri DebnathShreya m YenagiAinda não há avaliações
- Data Compression Data Compression: Chapter FourDocumento22 páginasData Compression Data Compression: Chapter FourDawit BassaAinda não há avaliações
- Error-Correction on Non-Standard Communication ChannelsNo EverandError-Correction on Non-Standard Communication ChannelsAinda não há avaliações
- Line Drawing Algorithm: Mastering Techniques for Precision Image RenderingNo EverandLine Drawing Algorithm: Mastering Techniques for Precision Image RenderingAinda não há avaliações
- VarPlus Can - BLRCH104A125B48Documento2 páginasVarPlus Can - BLRCH104A125B48Achira DasanayakeAinda não há avaliações
- Jun SMSDocumento43 páginasJun SMSgallardo0121Ainda não há avaliações
- Chip DielDocumento45 páginasChip DielJUANCANEXTAinda não há avaliações
- EFR32BG1 Blue Gecko BluetoothDocumento102 páginasEFR32BG1 Blue Gecko BluetoothLullaby summerAinda não há avaliações
- SECTION 1213, 1214, 1215: Report By: Elibado T. MaureenDocumento19 páginasSECTION 1213, 1214, 1215: Report By: Elibado T. MaureenJohnFred CativoAinda não há avaliações
- Recent Developments in Crosslinking Technology For Coating ResinsDocumento14 páginasRecent Developments in Crosslinking Technology For Coating ResinsblpjAinda não há avaliações
- An Overview of Subspace Identification: S. Joe QinDocumento12 páginasAn Overview of Subspace Identification: S. Joe QinGodofredoAinda não há avaliações
- ManpasandDocumento16 páginasManpasandJacob MathewAinda não há avaliações
- Mumbai BylawsDocumento110 páginasMumbai BylawsLokesh SharmaAinda não há avaliações
- Notes Mechanism of Methanol Synthesis From Carbon Monoxide and Hydrogen On Copper CatalystsDocumento4 páginasNotes Mechanism of Methanol Synthesis From Carbon Monoxide and Hydrogen On Copper CatalystsArif HidayatAinda não há avaliações
- VX-1700 Owners ManualDocumento32 páginasVX-1700 Owners ManualVan ThaoAinda não há avaliações
- VAPORISERDocumento62 páginasVAPORISERAshish ChavanAinda não há avaliações
- Ecg Signal Thesis1Documento74 páginasEcg Signal Thesis1McSudul HasanAinda não há avaliações
- Wri Method FigDocumento15 páginasWri Method Figsoumyadeep19478425Ainda não há avaliações
- Raft TheoryDocumento37 páginasRaft Theorymuktha mukuAinda não há avaliações
- Quotation 98665Documento5 páginasQuotation 98665Reda IsmailAinda não há avaliações
- DVMDocumento197 páginasDVMLeonardLapatratAinda não há avaliações
- Misc Forrester SAP Competence CenterDocumento16 páginasMisc Forrester SAP Competence CenterManuel ParradoAinda não há avaliações
- Tutorial Class 1 Questions 1Documento2 páginasTutorial Class 1 Questions 1Bố Quỳnh ChiAinda não há avaliações
- Design Procedure For Journal BearingsDocumento4 páginasDesign Procedure For Journal BearingsSwaminathan100% (1)
- MB m.2 Support Am4Documento2 páginasMB m.2 Support Am4HhhhCaliAinda não há avaliações
- Activation and Deactivation of CatalystsDocumento16 páginasActivation and Deactivation of Catalystsshan0214Ainda não há avaliações
- Paper AeroplaneDocumento19 páginasPaper Aeroplanejkb SudhakarAinda não há avaliações
- Research Papers in Mechanical Engineering Free Download PDFDocumento4 páginasResearch Papers in Mechanical Engineering Free Download PDFtitamyg1p1j2Ainda não há avaliações