Você também pode gostar
- Criando Tabelas, Importando Dados e Executando Cunsultas No postgreSQLDocumento5 páginasCriando Tabelas, Importando Dados e Executando Cunsultas No postgreSQLKevin KleyAinda não há avaliações
- Definicoes de ChavesDocumento12 páginasDefinicoes de ChavesDesignic WebAinda não há avaliações
- Apostila de SQLDocumento12 páginasApostila de SQLDiogo FerreiraAinda não há avaliações
- Apostila Comandos SQLDocumento2 páginasApostila Comandos SQLIgor SiqueiraAinda não há avaliações
- MySQL - Introdução ao banco de dados e comandos SQLDocumento52 páginasMySQL - Introdução ao banco de dados e comandos SQLEMERSON CAMARA ALVES DA SILVAAinda não há avaliações
- TLP-12-INFORMÁTICA - Aula 1 - SGBD MySQLDocumento18 páginasTLP-12-INFORMÁTICA - Aula 1 - SGBD MySQLmarciosiga3Ainda não há avaliações
- BD Aula02Documento41 páginasBD Aula02Gabriel BlaserAinda não há avaliações
- Capítulo VI - SQLDocumento32 páginasCapítulo VI - SQLVinicius FelicianoAinda não há avaliações
- Introdução à Linguagem SQLDocumento20 páginasIntrodução à Linguagem SQLJunior JuarezAinda não há avaliações
- Manual Básico de SQL para Iniciantes (Banco de Dados)Documento13 páginasManual Básico de SQL para Iniciantes (Banco de Dados)mundo10Ainda não há avaliações
- Aula 06Documento20 páginasAula 06GabrielAinda não há avaliações
- Mysql Li CoesDocumento35 páginasMysql Li CoesRoque Laecio Dos SantosAinda não há avaliações
- 16.1 24 - Curso de SQLDocumento194 páginas16.1 24 - Curso de SQLJoão Carlos FernandesAinda não há avaliações
- Apostila Basica SQL V2Documento25 páginasApostila Basica SQL V2luizagnolAinda não há avaliações
- Delphi - AgendaDocumento24 páginasDelphi - AgendamarciodreschAinda não há avaliações
- Apostila SQLDocumento90 páginasApostila SQLGiorgi MartinsAinda não há avaliações
- SQLDocumento60 páginasSQLMarcelo Santos SantosAinda não há avaliações
- Criando e usando campos calculados no MySQLDocumento3 páginasCriando e usando campos calculados no MySQLMarceloAinda não há avaliações
- Introdução à SQL e conceitos básicosDocumento8 páginasIntrodução à SQL e conceitos básicoswellington_silva_wfsAinda não há avaliações
- SQL Avançada: Views, Stored Procedures e TriggersDocumento6 páginasSQL Avançada: Views, Stored Procedures e TriggersLuídne Mota100% (1)
- Lembrete Programação em BDDocumento6 páginasLembrete Programação em BDtony29dealmeida29Ainda não há avaliações
- Curso SQL Básico em FirebirdDocumento21 páginasCurso SQL Básico em Firebirdcleber_jrAinda não há avaliações
- SQL Banco DadosDocumento41 páginasSQL Banco DadosLeandro Sanches SilvaAinda não há avaliações
- Mini Guia Básico de SQL - Lucas BezerraDocumento7 páginasMini Guia Básico de SQL - Lucas BezerraTshung SamAinda não há avaliações
- Modelagem BD PostgreSQL com DBDesignerDocumento5 páginasModelagem BD PostgreSQL com DBDesignerRaphael Patricio PereiraAinda não há avaliações
- Apostila DelphiDocumento79 páginasApostila DelphiJoao AlvesAinda não há avaliações
- Cantinho Dos Amantes Do Access - SQL PráticoDocumento7 páginasCantinho Dos Amantes Do Access - SQL PráticoEdimilson PereiraAinda não há avaliações
- Apostila de SQLServerDocumento37 páginasApostila de SQLServerAdriana SabinoAinda não há avaliações
- Revisão conceitos BD e SQLDocumento59 páginasRevisão conceitos BD e SQLAndre SantosAinda não há avaliações
- CriaçãoBD PRÁTICADocumento9 páginasCriaçãoBD PRÁTICAmoisesbmenezes123Ainda não há avaliações
- Comandos DDLDocumento16 páginasComandos DDLkonicaludyAinda não há avaliações
- Cadastro de Clientes em CDocumento14 páginasCadastro de Clientes em CDavid BlessAinda não há avaliações
- Apostila Transact SQL OficialDocumento80 páginasApostila Transact SQL OficialAdemir OliveiraAinda não há avaliações
- sqlDocumento88 páginassqlOmar Cunha LopesAinda não há avaliações
- Apostila SQLDocumento15 páginasApostila SQLLeandro CorreaAinda não há avaliações
- Comandos SQL e dicas para manipulação de dados no PostgresDocumento10 páginasComandos SQL e dicas para manipulação de dados no Postgresalexandrecamelo2009Ainda não há avaliações
- SQL Comandos BásicosDocumento16 páginasSQL Comandos BásicosninahfAinda não há avaliações
- Banco de Dados: Jordana S. SalamonDocumento44 páginasBanco de Dados: Jordana S. Salamonjujuzinha222Ainda não há avaliações
- Fundamentos de Base Dados Aula - 4Documento24 páginasFundamentos de Base Dados Aula - 4Hélder Vasco CinturãoAinda não há avaliações
- SQLite: Um Poderoso Banco de Dados em Apenas 7KBDocumento2 páginasSQLite: Um Poderoso Banco de Dados em Apenas 7KBbasswanderAinda não há avaliações
- Manipulação de triggers no MySQLDocumento6 páginasManipulação de triggers no MySQLNelma Regina Dos Santos TeixeiraAinda não há avaliações
- Modelagem Dbdesigner PostgresqlDocumento5 páginasModelagem Dbdesigner Postgresqlsinister182Ainda não há avaliações
- Apostila BDDocumento30 páginasApostila BDirineuAinda não há avaliações
- Stored Procedures no MySQLDocumento6 páginasStored Procedures no MySQLPedro PradoAinda não há avaliações
- Cadastro de Clientes em C# Parte 1 e 2 e 3Documento20 páginasCadastro de Clientes em C# Parte 1 e 2 e 3galhardoro100% (1)
- O que é MySQL e como criar e gerenciar bancos e tabelasDocumento35 páginasO que é MySQL e como criar e gerenciar bancos e tabelasValcides Di MoraisAinda não há avaliações
- Cartilha SQLDocumento3 páginasCartilha SQLCatulo Kruuse HansenAinda não há avaliações
- Introdução ao Oracle: tabelas, colunas, constraints e tipos de dadosDocumento43 páginasIntrodução ao Oracle: tabelas, colunas, constraints e tipos de dadosStefani BrancoAinda não há avaliações
- IntroduçãoDocumento5 páginasIntroduçãostu.320202001Ainda não há avaliações
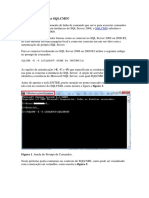
- SQL Server Pelo Utilitario SQLCMDDocumento7 páginasSQL Server Pelo Utilitario SQLCMDjoop01Ainda não há avaliações
- Dicas de Consultas SQL ServerDocumento47 páginasDicas de Consultas SQL ServerEduardo GabinaAinda não há avaliações
- SQL-modulo_3_aula.pdf - 30Documento10 páginasSQL-modulo_3_aula.pdf - 30Wesley O'BrainAinda não há avaliações
- Curso Pdv Passo A Passo Delphi Com FiredacNo EverandCurso Pdv Passo A Passo Delphi Com FiredacAinda não há avaliações
- Aprenda Na Prática Comandos Sql De Consulta Para Banco De DadosNo EverandAprenda Na Prática Comandos Sql De Consulta Para Banco De DadosNota: 5 de 5 estrelas5/5 (1)
- Implementação de Banco de DadosDocumento5 páginasImplementação de Banco de DadosAsé FunfunAinda não há avaliações
- Validando campos Oracle Forms 6iDocumento12 páginasValidando campos Oracle Forms 6iSergio CostaAinda não há avaliações
- Backup: conceitos e tiposDocumento83 páginasBackup: conceitos e tiposLeandro SousaAinda não há avaliações
- Mecanismo de Busca Com NodeJS + MongoDBDocumento50 páginasMecanismo de Busca Com NodeJS + MongoDBLuiz Fernando Duarte Jr.Ainda não há avaliações
- Aula 14 - Sistema de MemóriaDocumento30 páginasAula 14 - Sistema de MemóriaInês Pacheco VieiraAinda não há avaliações
- Guia de Referência Do QuerydslDocumento43 páginasGuia de Referência Do QuerydslapcejamAinda não há avaliações
- Portfólio IV - Linguagem de Programação PDFDocumento11 páginasPortfólio IV - Linguagem de Programação PDF1001nutilidades OficialAinda não há avaliações
- 04-A-Estrutura de Diretorios e Sistemas de Arquivos PDFDocumento20 páginas04-A-Estrutura de Diretorios e Sistemas de Arquivos PDFheldergonzagaAinda não há avaliações
- Árvores binárias balanceadas e implementaçõesDocumento10 páginasÁrvores binárias balanceadas e implementaçõesKenny RalphAinda não há avaliações
- Oracle9i Fundamental - Final PDFDocumento437 páginasOracle9i Fundamental - Final PDFJenner Patrick Lopes Brasil100% (1)
- TMS BT Preenchimento Do Campo X2 DISPLAY TPPAXJDocumento12 páginasTMS BT Preenchimento Do Campo X2 DISPLAY TPPAXJGilberto Franco JuniorAinda não há avaliações
- Comparação Paradox x InterBaseDocumento5 páginasComparação Paradox x InterBaseEngenharia Elétrica UniplacAinda não há avaliações
- 00-Bases de Dados - Sistemas de Gestão 5411Documento2 páginas00-Bases de Dados - Sistemas de Gestão 5411Carlos MarquesAinda não há avaliações
- SQL Banco Dados Tabelas RestriçõesDocumento37 páginasSQL Banco Dados Tabelas RestriçõesAntonio BritoAinda não há avaliações
- Introdução a Bancos de Dados emDocumento16 páginasIntrodução a Bancos de Dados emHamilton RibeiroAinda não há avaliações
- Clonando Uma ParticaoDocumento8 páginasClonando Uma ParticaosalvianoleaoAinda não há avaliações
- PHP + PostgreSql - Conexão Com Banco de Dados - Rafael ClaresDocumento29 páginasPHP + PostgreSql - Conexão Com Banco de Dados - Rafael ClaresWagner FreiriaAinda não há avaliações
- Apostila SQL Prof MSC Rodrigo Santos - 27-11-2009 v4 PDFDocumento119 páginasApostila SQL Prof MSC Rodrigo Santos - 27-11-2009 v4 PDFKatia Regina de FreitasAinda não há avaliações
- Unidade 2 - Principais Características de Um SGBDDocumento15 páginasUnidade 2 - Principais Características de Um SGBDPaulo FonsecaAinda não há avaliações
- Tópicos avançados de Apex para desenvolvimento de aplicaçõesDocumento18 páginasTópicos avançados de Apex para desenvolvimento de aplicaçõesWill CostaAinda não há avaliações
- Administrador de Banco de Dados - IntroduçãoDocumento56 páginasAdministrador de Banco de Dados - IntroduçãoGabinete WellingtonAinda não há avaliações
- Principio Banco de DadosDocumento199 páginasPrincipio Banco de DadosDanilo Duarte100% (2)
- Manual AccessDocumento48 páginasManual AccessJairson MonteiroAinda não há avaliações
- Base de DadosDocumento54 páginasBase de DadosNiraliLauraAinda não há avaliações
- Comandos Linux EssenciaisDocumento23 páginasComandos Linux EssenciaismajesconAinda não há avaliações
- Modelagem de DadosDocumento22 páginasModelagem de DadosVicente de PauloAinda não há avaliações
- GERADOR DE SAIDAS - V12 - AP02 OkDocumento56 páginasGERADOR DE SAIDAS - V12 - AP02 OkAntonio Marcos Pereira100% (2)
- ADO adoquery exemplo básicoDocumento3 páginasADO adoquery exemplo básicoadmgilAinda não há avaliações
- Descobrindo bancos de dados e Oracle 12cDocumento70 páginasDescobrindo bancos de dados e Oracle 12cImre KissAinda não há avaliações
- SQLJ: Uma alternativa de alto nível a JDBCDocumento57 páginasSQLJ: Uma alternativa de alto nível a JDBCFahad KalilAinda não há avaliações