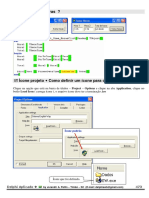
Você também pode gostar
- JPA Eficaz: As melhores práticas de persistência de dados em JavaNo EverandJPA Eficaz: As melhores práticas de persistência de dados em JavaAinda não há avaliações
- Spring Boot: Acelere o desenvolvimento de microsserviçosNo EverandSpring Boot: Acelere o desenvolvimento de microsserviçosAinda não há avaliações
- Java 8 Prático: Lambdas, Streams e os novos recursos da linguagemNo EverandJava 8 Prático: Lambdas, Streams e os novos recursos da linguagemNota: 4.5 de 5 estrelas4.5/5 (3)
- ASP.NET MVC5: Crie aplicações web na plataforma Microsoft®No EverandASP.NET MVC5: Crie aplicações web na plataforma Microsoft®Ainda não há avaliações
- Unidade 2 - ProgramaçãoBDDocumento53 páginasUnidade 2 - ProgramaçãoBDAndre SantosAinda não há avaliações
- Persistência de Dados Com React NativeDocumento75 páginasPersistência de Dados Com React NativeRosangela Neves100% (1)
- Apache Cassandra: Escalabilidade horizontal para aplicações JavaNo EverandApache Cassandra: Escalabilidade horizontal para aplicações JavaAinda não há avaliações
- Ember.js: Conheça o framework para aplicações web ambiciosasNo EverandEmber.js: Conheça o framework para aplicações web ambiciosasAinda não há avaliações
- Especificação Técnica - ToTVS Avaliação e Pesquisa 12.1.2Documento14 páginasEspecificação Técnica - ToTVS Avaliação e Pesquisa 12.1.2Jose Willian NascimentoAinda não há avaliações
- ZLIB Framework Advpl WebservicesDocumento120 páginasZLIB Framework Advpl WebservicesFrancisco Joaquin Gallardo CerecerAinda não há avaliações
- Tema 1 - Sistemas de Base de DadosDocumento34 páginasTema 1 - Sistemas de Base de DadosAmarildoMulandezaAinda não há avaliações
- Banco de DadosDocumento9 páginasBanco de Dadosjheniffer OLIVEIRA100% (1)
- Delphi BD DbexpressDocumento54 páginasDelphi BD Dbexpressabaddon3Ainda não há avaliações
- Tecnologias JPA e JEEDocumento92 páginasTecnologias JPA e JEEAlexandre RochaAinda não há avaliações
- SerializaçãoDocumento3 páginasSerializaçãoLauraAinda não há avaliações
- IntroDocumento3 páginasIntrouuserbackupAinda não há avaliações
- Objectivity DBDocumento11 páginasObjectivity DBAlexandre GonzagaAinda não há avaliações
- Unidade 6 - Introdução Ao HibernateDocumento33 páginasUnidade 6 - Introdução Ao HibernateAndrey Nascimento da SilvaAinda não há avaliações
- Uma Introdução Prática Ao JPA Com Hibernate - Java para Desenvolvimento WebDocumento33 páginasUma Introdução Prática Ao JPA Com Hibernate - Java para Desenvolvimento WebmarcosAinda não há avaliações
- Apostila JPA - CaelumDocumento27 páginasApostila JPA - CaelumAndre NoelAinda não há avaliações
- Persistência de Dados Com React Native 2Documento80 páginasPersistência de Dados Com React Native 2LeandroSilvaAinda não há avaliações
- Tecnologias JPA e JEEDocumento57 páginasTecnologias JPA e JEEleandro morais barbosaAinda não há avaliações
- Resumo Do Livro MysqlDocumento4 páginasResumo Do Livro MysqlAdenilton FerreiraAinda não há avaliações
- Lista 1 PooDocumento6 páginasLista 1 PooBruno SchiavoneAinda não há avaliações
- Curso Spring BootDocumento9 páginasCurso Spring BootEduardo SehnAinda não há avaliações
- Chapter 6 - Assembling A Repository - Clean Android ArchitectureDocumento21 páginasChapter 6 - Assembling A Repository - Clean Android ArchitectureMarcus PassosAinda não há avaliações
- Passo A Passo No SpringBoot Com JPADocumento6 páginasPasso A Passo No SpringBoot Com JPACarol FariasAinda não há avaliações
- Criando Um Projeto Web Com Hibernate e Eclipse KeplerDocumento19 páginasCriando Um Projeto Web Com Hibernate e Eclipse KeplerkalazansAlanAinda não há avaliações
- Camada de Controle - ServiçosDocumento82 páginasCamada de Controle - ServiçosAlesson ThiagoAinda não há avaliações
- Avaliação Programação Servidor em Sistemas WebDocumento3 páginasAvaliação Programação Servidor em Sistemas WebRenan RochaAinda não há avaliações
- DBExpressDocumento16 páginasDBExpressJuarez SoaresAinda não há avaliações
- Componentes HadoopDocumento11 páginasComponentes Hadoopsilvio rodriguesAinda não há avaliações
- Banco de Dados Orientado A ObjetosDocumento15 páginasBanco de Dados Orientado A ObjetosAndre Luis Oliveira FonsecaAinda não há avaliações
- Web Service Aula 1Documento4 páginasWeb Service Aula 1Robusto SilvaAinda não há avaliações
- 1 Lista de Exercicios - Poo - Lucas Zuque - 2268710Documento7 páginas1 Lista de Exercicios - Poo - Lucas Zuque - 2268710Lucas ZuqueAinda não há avaliações
- Revista Mundo JavaDocumento12 páginasRevista Mundo JavaNeydson Candido0% (1)
- Unidade 2 - Introdução JavaServer Pages Standard TagDocumento22 páginasUnidade 2 - Introdução JavaServer Pages Standard TagAndrey Nascimento da SilvaAinda não há avaliações
- Python Estr de DadosDocumento5 páginasPython Estr de DadosRafaela PCAinda não há avaliações
- Conceitos de Banco de Dados e SGBDs - SlidesDocumento41 páginasConceitos de Banco de Dados e SGBDs - Slidesanizete7575Ainda não há avaliações
- Banco de Dados Orientado A ObjetosDocumento11 páginasBanco de Dados Orientado A ObjetosJaisson DuarteAinda não há avaliações
- Programação Orientada À Objetos - Visual BasicDocumento35 páginasProgramação Orientada À Objetos - Visual BasicDário LimaAinda não há avaliações
- Artigo MAPEAMENTO OBJETO RELACIONAL COM HIBERNATE (Benefrancis Do Nascimento)Documento27 páginasArtigo MAPEAMENTO OBJETO RELACIONAL COM HIBERNATE (Benefrancis Do Nascimento)Benefrancis100% (1)
- Exame Normal - SGBD - 2022A - Laboral Manha Guiao CorreccaoDocumento7 páginasExame Normal - SGBD - 2022A - Laboral Manha Guiao CorreccaoKelvin CondulaAinda não há avaliações
- Java (Sobrecarga e SobrescritaDocumento10 páginasJava (Sobrecarga e SobrescritaÁdamo Ferreira ReutherAinda não há avaliações
- Apostila HibernateDocumento37 páginasApostila HibernateJadson Souza FariaAinda não há avaliações
- DBA Oracle 11gDocumento4 páginasDBA Oracle 11gAgápito LugoAinda não há avaliações
- Tema 3 - PROGRAMAÇÃO SERVIDOR COM JAVADocumento72 páginasTema 3 - PROGRAMAÇÃO SERVIDOR COM JAVArafaelxulipaAinda não há avaliações
- JavaDocumento63 páginasJavaricardodesouza440Ainda não há avaliações
- Orientação A Objetos No JavaDocumento8 páginasOrientação A Objetos No JavaRamadhane FrancyscoAinda não há avaliações
- Bancos de Dados Orientados A Objetos (Resumo)Documento6 páginasBancos de Dados Orientados A Objetos (Resumo)Anne PachecoAinda não há avaliações
- Administração Do PostgreSQLDocumento84 páginasAdministração Do PostgreSQLAlsizio SiabalaAinda não há avaliações
- Aula5-JDBC IDocumento33 páginasAula5-JDBC ITrinity RecitouAinda não há avaliações
- Aula 01Documento37 páginasAula 01AndersonAinda não há avaliações
- (SAYÃO) Metadados para Preservação DigitalDocumento67 páginas(SAYÃO) Metadados para Preservação Digitalfariashcrf100% (1)
- ADocumento3 páginasAPaulo CésarAinda não há avaliações
- JSP e JSTLDocumento17 páginasJSP e JSTLLetícia FernandesAinda não há avaliações
- Lista 1 de ExerciciosDocumento5 páginasLista 1 de ExerciciosmariabertelliAinda não há avaliações
- Metricas de Software IIIDocumento49 páginasMetricas de Software IIILingui Joaquim MoianaAinda não há avaliações
- Edma Trabalho FinalDocumento11 páginasEdma Trabalho FinalLingui Joaquim MoianaAinda não há avaliações
- Informática Nas Empresas (Guardado Automaticamente) 1Documento6 páginasInformática Nas Empresas (Guardado Automaticamente) 1Lingui Joaquim MoianaAinda não há avaliações
- Universidade Católica de MoçambiqueDocumento16 páginasUniversidade Católica de MoçambiqueLingui Joaquim MoianaAinda não há avaliações
- Trabalho MediçãoDocumento21 páginasTrabalho MediçãoLingui Joaquim MoianaAinda não há avaliações
- Universidade ZambezeDocumento4 páginasUniversidade ZambezeLingui Joaquim MoianaAinda não há avaliações
- VoleibolDocumento19 páginasVoleibolLingui Joaquim MoianaAinda não há avaliações
- Trabalho de CompiladorDocumento14 páginasTrabalho de CompiladorLingui Joaquim MoianaAinda não há avaliações
- Persistencia JavaDocumento11 páginasPersistencia JavaLingui Joaquim MoianaAinda não há avaliações
- Trabalho IndividualDocumento2 páginasTrabalho IndividualLingui Joaquim MoianaAinda não há avaliações
- Httpslearn Us East 1 Prod Fleet02 Xythos - Content.blackboardcdn - Com5d152e0e8981d54554777x Blackboard S3 Bucket Learn Us EasDocumento14 páginasHttpslearn Us East 1 Prod Fleet02 Xythos - Content.blackboardcdn - Com5d152e0e8981d54554777x Blackboard S3 Bucket Learn Us EasCamila MaranhãoAinda não há avaliações
- Tema PL SQL 2022 Pag01 A 15Documento15 páginasTema PL SQL 2022 Pag01 A 15kamilAinda não há avaliações
- Dummies-Oracle 12cDocumento70 páginasDummies-Oracle 12cImre KissAinda não há avaliações
- 05 BD-II 5aLista-BlocoDocumento4 páginas05 BD-II 5aLista-BlocoJose da SilvaAinda não há avaliações
- Exercicio Estudar ProvaDocumento4 páginasExercicio Estudar ProvaBruno Soncino0% (1)
- Projeto Integrado 3 AdsDocumento15 páginasProjeto Integrado 3 Adslurovoca02Ainda não há avaliações
- Como Fazer o CRUD em PHP Com Mysqli - ConnectDocumento8 páginasComo Fazer o CRUD em PHP Com Mysqli - ConnectGustavo LinharesAinda não há avaliações
- Atividade Avaliativa Especial - Prova 1 RESOLVIDA 343 - 5107Documento3 páginasAtividade Avaliativa Especial - Prova 1 RESOLVIDA 343 - 5107RicardoAntunesCristovaoAinda não há avaliações
- Manipulacao de Dados Com SQL Demo PDFDocumento26 páginasManipulacao de Dados Com SQL Demo PDFJacqueline Karla AlvesAinda não há avaliações
- Slides de Aula - Módulo 02Documento512 páginasSlides de Aula - Módulo 02JohnAinda não há avaliações
- Delphi Aplicado Módulo 4ADocumento160 páginasDelphi Aplicado Módulo 4ArlffortesAinda não há avaliações
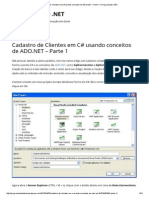
- Cadastro de Clientes em C# Usando Conceitos de ADO - Net - Parte 1 - ProgramandoDocumento24 páginasCadastro de Clientes em C# Usando Conceitos de ADO - Net - Parte 1 - ProgramandomariamartafalvesAinda não há avaliações
- Guia Básico de SQLDocumento2 páginasGuia Básico de SQLJessica Amorim100% (1)
- 4.5 Prática Sobre Restrições de Integridade ReferencialDocumento2 páginas4.5 Prática Sobre Restrições de Integridade ReferencialEmerson PereiraAinda não há avaliações
- Apostila Banco de DadosDocumento37 páginasApostila Banco de DadosrikiAinda não há avaliações
- CRUD Com Bootstrap, PHP & MySQL - Parte IV - Web Dev AcademyDocumento21 páginasCRUD Com Bootstrap, PHP & MySQL - Parte IV - Web Dev AcademyAnselmo NicoskiAinda não há avaliações
- Faculdade Metropolitana de Rio Do Sul APDocumento82 páginasFaculdade Metropolitana de Rio Do Sul APAnabela SantosAinda não há avaliações
- Banco de Dados Não RelacionalDocumento1 páginaBanco de Dados Não RelacionalDiego São JoãoAinda não há avaliações
- G-53 Bibala Projecto Final 1.5Documento49 páginasG-53 Bibala Projecto Final 1.5Silvestre Nhongueno MussonoAinda não há avaliações
- LOJA - BT - Template Drogaria - Geracao XML 20 - TGVPHIDocumento9 páginasLOJA - BT - Template Drogaria - Geracao XML 20 - TGVPHIpauloimmanuelAinda não há avaliações
- Configurações de Memória DB - Configurador Do DbaseivDocumento8 páginasConfigurações de Memória DB - Configurador Do Dbaseivjosé_alencar_57Ainda não há avaliações