Escolar Documentos
Profissional Documentos
Cultura Documentos
QREN BM Modelos de Dados Existentes No Domínio Da Solução 1.0
Enviado por
bromeroviateclaTítulo original
Direitos autorais
Formatos disponíveis
Compartilhar este documento
Compartilhar ou incorporar documento
Você considera este documento útil?
Este conteúdo é inapropriado?
Denunciar este documentoDireitos autorais:
Formatos disponíveis
QREN BM Modelos de Dados Existentes No Domínio Da Solução 1.0
Enviado por
bromeroviateclaDireitos autorais:
Formatos disponíveis
BRAIN MAP | Entidade Promotora:
Parceiros:
28-05-2010
Modelos de Dados existentes no domnio da soluo
0/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
ndice
Tabela de Figuras............................................................................................................................. 3 Introduo ....................................................................................................................................... 5 Conceitos gerais de armazenagem e acondicionamento de informao ....................................... 6 Modelo de Ficheiros com documentos no estruturados .......................................................... 7 Modelo Relacional ....................................................................................................................... 9 Modelos conceptuais de Bases de Dados ................................................................................. 11 Anotaes de Meta Dados em linguagens como XML .............................................................. 13 Modelo de bases de bases de dados nativas XML .................................................................... 15 Ontologias .................................................................................................................................. 16 Relaes e Grafos Multi-partidos .............................................................................................. 19 Grafos bi-partidos e redes complexas ................................................................................... 19 Propriedades das redes complexas ....................................................................................... 22 Ferramentas de armazenagem e acondicionamento de informao ........................................... 24 Microsoft SQL Server ................................................................................................................. 24 Instalao dinmica ............................................................................................................... 27 Coleco de Dados de Desempenho ..................................................................................... 28 LINQ........................................................................................................................................ 29 Microsoft SQL Server Management Studio ........................................................................... 30 InteliSense .............................................................................................................................. 31 Oracle ......................................................................................................................................... 33 Enterprise Edition .................................................................................................................. 35 Express Edition ....................................................................................................................... 37 Standard Edition..................................................................................................................... 38 Standard Edition One ............................................................................................................. 38
1/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Personal Edition ..................................................................................................................... 39 Database Lite.......................................................................................................................... 39 MySQL ........................................................................................................................................ 40 MySQL Community Server ..................................................................................................... 43 MySQL Enterprise Edition ...................................................................................................... 43 MySQL Standard Edition ........................................................................................................ 44 MySQL Cluester Edition ......................................................................................................... 44 MySQL Cluster Carrier Grade Edition (CGE) ........................................................................... 44 Vertica ........................................................................................................................................ 49 Tamino XML Server.................................................................................................................... 51 Dex ............................................................................................................................................. 55
2/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Tabela de Figuras
Figura 1: Logtipo do SQL Server .................................................................................................. 24 Figura 2: Servios do SQL Server ................................................................................................... 27 Figura 3: Processo de instalao e configurao .......................................................................... 28 Figura 4: Grficos de desempenho do sistema ............................................................................. 29 Figura 5: Utilizao LINQ ............................................................................................................... 30 Figura 6: Interface do SQL Server Management Studio 2008 ....................................................... 30 Figura 7: Menu gerao dos scripts SQL ....................................................................................... 32 Figura 8: Logtipo do sistema ....................................................................................................... 33 Figura 9: SQL *Plus ........................................................................................................................ 34 Figura 10: Pgina de Login do Oracle 11g ..................................................................................... 35 Figura 11: Grficos de Monotorizao .......................................................................................... 36 Figura 12: Enterprise Manager 11g ............................................................................................... 36 Figura 13: Oracle XE pgina inicial ................................................................................................ 38 Figura 14: Funcionamento do Oracle Lite ..................................................................................... 40 Figura 15:Logotipo MySQL ............................................................................................................ 40 Figura 16: Arquitectura do MySQL ................................................................................................ 41 Figura 17: Exemplo do um CMS que requere MySQL ................................................................... 42 Figura 18: Funcionamento do MySQL Cluster Edition .................................................................. 45 Figura 19: Linha de comandos SQL ............................................................................................... 46 Figura 20:MySQL Workbench........................................................................................................ 47 Figura 21: phpMyAdmin no browser ............................................................................................ 48 Figura 22: MySQL Administrator ................................................................................................... 48 Figura 23: Logotipo da Vertica ...................................................................................................... 49 Figura 24:Comparao entre os dois tipos de Bases de Dados .................................................... 49 Figura 25: logotipo da empresa Software AG ............................................................................... 51 Figura 26: Arquitectura do Servdor Tamino.................................................................................. 51 Figura 27: Interface do Tamino XML ............................................................................................. 52 Figura 28: Ferramenta de upload de dados .................................................................................. 53 Figura 29: Tamino Schema Editor ................................................................................................. 54 Figura 30: Logtipo da empresa .................................................................................................... 56 Figura 31: Crculo de vantagens Dex ............................................................................................. 57 Figura 32:Exemplo de aplicao de uma base de dados com grafos............................................ 58
3/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
4/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
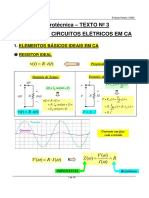
Introduo
Pretende-se com o presente documento efectuar um estudo de modelos de dados no domnio onde se enquadra o projecto Brain Map. Com esse estudo pretende-se adquirir noes no s sobre as diferentes tecnologias de modelos de dados, mas tambm se pretende apurar o mais adequado e aplicvel ao Brain Map, de modo, a que as suas potencialidades e funcionalidades sejam incrementadas e optimizadas. Esta rea de extrema importncia para o projecto, devido a ele, ir conter grandes quantidades de dados e ter de possibilitar o acesso e a visualizao a esses mesmos dados de uma forma rpida, eficaz e eficiente sem desperdcio de recursos. Para alm do levantamento terico dos diferentes conceitos de modelos de dados, tambm ser efectuada uma anlise e levantamento das principais plataformas que implementem esses conceitos, tanto em solues de cariz comercial e open source. O presente documento encontra-se organizado em dois captulos principais, sendo o primeiro dedicado aos conceitos tericos e o segundo referente s ferramentas e aplicaes que implementam alguns desses conceitos. Ao nvel de contextualizao no projecto QREN Brain Map, este documento, encontra-se enquadrado na seco de Estudos Preliminares e responde tarefa Avaliao crtica dos modelos de dados actualmente utilizados na representao de conhecimento heterogneo .
5/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Conceitos gerais de armazenagem e acondicionamento de informao
Por norma e independentemente do domnio de aplicao do sistema, quando h uma grande concentrao de dados ou de informao necessrio recorrer a bancos de dados, mais conhecidos por bases de dados. Uma base de dados um conjunto de registos com informao variada, disposta numa estrutura regular que possibilita a reorganizao dos mesmos e produo de informao til. O modelo de bases de dados mais adoptado hoje em dia o modelo relacional, onde as estruturas tm a forma de tabelas, compostas por linhas e colunas, onde so alocados os diversos dados e informaes.
Uma base de dados normalmente mantida e acedida por via de um software conhecido como Database Management System (DBMS) ou em Portugus, Sistema de Gesto de Base de Dados (SGBD). Um Sistema de Gesto de Bases de Dados, (SGBD) no nada mais do que um conjunto de programas que permitem armazenar, modificar e extrair informao de uma base de dados. H muito tipos diferentes de SGBD. Desde pequenos sistemas que funcionam em computadores pessoais a sistemas de alta complexidade associados a mainframes com vrios TeraBytes de informao. Um Sistema de Gesto de Base de Dados tambm possibilita a manuteno das bases de dados e age como interface entre os diversos programas e aplicaes que acedem aos dados e os ficheiros de dados fsicos. Assim sendo, existem trs componentes fundamentais num SGBD: Linguagem de definio de dados: especifica contedos, estrutura a base de dados e define os elementos de dados; Linguagem de manipulao de dados: para poder inserir, alterar e remover os dados na base de dados;
6/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Dicionrio de dados: guarda definies dos elementos dos dados, assim como metadados e as respectivas caractersticas. Tambm regista quem acede aos dados e quando, assim como quais as operaes efectuadas.
Com a evoluo das tecnologias de conectividade entre as tabelas de uma base de dados e os programas desenvolvidos em linguagens como e.g. Java, Delphi, Visual Basic, C#, C++, a navegao e a apresentao dos dados passou a ser definida pelo programador da aplicao. Sendo que a maioria das linguagens de programao fazem ligaes a bases de dados, a apresentao dos dados tem ficado cada vez mais a critrio dos meios de programao, fazendo com que as bases de dados deixem de se restringir s pesquisas bsicas, dando lugar ao compartilhamento em tempo real, de informaes, mecanismos de busca inteligentes e permissividade de acesso hierarquizado. No entanto existem algumas abordagens de modelos de dados que rompem com o paradigma das convencionais bases de dados. De seguida sero analisadas algumas dessas vias.
Modelo de Ficheiros com documentos no estruturados
Este modelo de dados assume uma organizao da informao em ficheiros de documentos com textos, imagens ou outros dados sem um esquema pr definido para a estrutura dos dados. adequado para modelar a Web onde se pode aceder a documentos que tm muita informao em diferentes formatos, desde ficheiros de texto, html, pdf, etc. Quando se afirma que os ficheiros no tm estrutura, referimo-nos ao facto de no terem uma estrutura comum conhecida, assim, devem ser vistos com tendo informao no estruturada. Numa empresa este modelo de dados pode ser o adequado para representar toda a informao da empresa, pois apesar de haver coleces de documentos, bases de dados, folhas de clculo que individualmente tm uma certa estrutura, quando se olha a informao na sua globalidade e heterogeneidade por vezes difcil uma integrao eficaz.
Adequao do modelo para os vrios tipos de informao um modelo adequado para representar informao no estruturada e heterognea. Quando temos outro tipo de informao, este modelo no permite tirar partido da estrutura da
7/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
informao nos processos de interrogao e na actualizao com novos dados. Este modelo pode ser usado para dados semi-estruturados, mas raramente usado para dados estruturados. Alguns exemplos de documentos de textos que podem ser modelados desta forma: Documentos de texto parcialmente anotados com termos de linguagens de marcao como o HTML ou XML onde se marca o titulo, o autor, a instituio etc. Correio electrnico. Apesar de no usar uma linguagem de marcao para anotaes, possui campos bem definidos como o endereo, o remetente, o assunto, o corpo e os ficheiros anexados. Pginas em HTML geradas automaticamente a partir de dados de bases de dados ou construdas manualmente. As etiquetas HTML induzem uma estrutura no documento que pode ser recuperada. Documentos multimdia. Estes documentos tm uma estrutura que distingue a informao do texto, da informao da imagem, do som, do vdeo, etc.
Interrogao no modelo de dados A interrogao deste modelo de dados feita recorrendo a tcnicas de: Recuperao de Informao em documentos o Modelo de recuperao booleano pode-se construir uma interrogao com termos (palavras) ligados pelos operadores lgicos e, ou e no. O modelo booleano requer a construo de estruturas de dados como por exemplo dicionrios invertidos. o Modelo de recuperao ranked (ordenado). A interrogao feita com texto livre e os resultados so ordenados por ordem de relevncia, tendo em conta as palavras da interrogao, a frequncia relativa das palavras nos documentos, o comportamento do utilizador (interrogaes e preferncia pelo tipo de documentos). o modelo mais usado pelos actuais motores de busca da Web (goolge, yahoo, etc). Este modelo necessita de construir uma srie de ndices sobre a informao dos documentos, e usa uma srie de algoritmos para ordenar os documentos seleccionado pela interrogao. Minerao de texto em documentos e Minerao de dados o Clculo de Agrupamentos (clustering) para classificao ou extraco de relaes.
Introduo de dados no modelo de dados
8/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
A actualizao deste modelo de dados simples, na medida que basta acrescentar os novos ficheiros com a informao a adicionar, mas ser necessrio refazer as estruturas de dados necessrias para os processos de interrogao. A construo das estruturas de dados e os algoritmos de extraco de conhecimento so pesados / complexos em termos computacionais, mas normalmente, so totalmente automticos e no requerem a interveno humana para introduzir a nova informao.
Eficincia da interrogao e da introduo de dados A eficincia dos processos de interrogao e de actualizao depende das tcnicas utilizadas nos processos de interrogao. As tcnicas de recuperao de informao so pesadas (em tempo de computao e espao em disco) na construo das estruturas de dados, dicionrios invertidos e outros indicies. No entanto, so bastante eficientes no tempo de resposta s perguntas / pesquisas do utilizador. As tcnicas de minerao podem ser feitas offline ou online. No caso de serem feitas online o tempo de resposta degrada-se com a quantidade de informao que tem que ser pesquisada. O mesmo se passa em relao ao clculo de agrupamentos (clustering).
Modelo Relacional
O modelo relacional obriga a estruturar a informao a representar em entidades, relaes e atributos definindo o tipo de dados para representar os atributos (e.g. inteiro, texto, data). Este o modelo de dados usado actualmente nos sistemas de gesto de bases de dados (mySql, PosGres, Oracle, etc). Existem outros modelos de dados para bases de dados como o modelo hierrquico e o modelo em rede. A estrutura dos dados no modelo relacional est definida no esquema da base de dados que descrito na Linguagem de Descrio dos Dados (DDL) dos sistemas de gesto de bases de dados.
9/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Adequao do modelo para os vrios tipos de informao O modelo relacional adequado para representar informao estruturada. A integrao dos modelos e contedos das diferentes bases de dados um problema com o qual se ter que lidar. Uma estratgia poder envolver a criao de um novo modelo de dados que inclua os modelos das bases de dados a integrar. Esta estratgia permite obter bons resultados no acesso informao mas a actualizao dos dados nas bases de dados originais poder ser problemtica. Outra estratgia ser recorrer a anotaes OWL-RDF para descrever os meta dados (o esquema) das bases de dados. Para a informao semi-estruturada (pginas em HTML e alguns documentos) e no estruturada (documentos e software) ter que se desenhar um modelo de dados que permita representar a informao considerada relevante. De notar que actualmente, muitos sistemas de gesto de bases de dados permitem representar informao semi-estruturada que inclui objectos grandes como textos com alguns campos bem definidos (autor, titulo, etc) ou documentos com anotaes em XML. A representao de imagens e outros contedos multimdia como objectos de maior dimenso tambm possvel de efectuar em alguns sistemas de gesto de bases de dados, no entanto, no so representados de forma estruturada, s possvel atribuir alguma estrutura s anotaes (metadados) dos documentos. Este modelo no adequado para representar informao de coleces de documentos que no tm estrutura.
Interrogao no modelo de dados A interrogao do Modelo de Relacional feita usando SQL (linguagem estruturada de interrogao) que est implementada em todos os sistemas de gesto de bases de dados. O SQL permite aceder de forma eficiente aos dados de acordo com o modelo de dados. Alternativamente, existem sistemas de gesto de bases de dados que permitem interrogaes sobre objectos sem recorrer ao SQL, nomeadamente usando linguagens de interrogao como o Xquery, uma linguagem de interrogao para dados estruturados em XML.
Introduo de dados no modelo A actualizao de uma base de dados requer que se introduza a informao nas tabelas adequadas respeitando as restries definidas no modelo de dados na definio das tabelas (chaves primrias, estrangeiras, verificao de valores) e pela escrita de restries de
10/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
integridade nos formatos definidos pelos sistema de gesto de bases de dados (scripts, stored procedures). A actualizao dos dados das bases de dados, pode ser feita de forma automtica quando se pretende importar informao em formato digital j estruturada. Quando a informao no est disponvel em formato adequado insero automtica, a insero feita atravs de interfaces desenhadas de forma a permitir a introduo dos dados por humanos garantindo a consistncia da informao.
Eficincia da interrogao e da introduo de dados O SQL uma linguagem de interrogao e pesquisa bastante eficiente para a extraco de informao de bases de dados. As situaes problemticas aparecem quando se est perante interrogaes sobre tabelas muito grandes (milhes de tuplos) que fazem agregaes (funes de agregao como a soma, mdia, etc; e a clausula group by). Nestas situaes necessria recorrer a tcnicas de armazns de dados (Data Warehouse) que importam dados para uma base de dados com o objectivo de tornar estas operaes mais eficientes.
A eficincia da introduo de dados numa base de dados, depende do seu desenho e necessidade de verificar ou no a integridade da informao nos processos de actualizao dos dados. Uma base de dados com o modelo de dados normalizado, em que as restries so definidas na definio do modelo de dados de forma a serem verificadas internamente pelo sistema de gesto de bases de dados, pode ter o processo de actualizao da informao muito eficiente.
Modelos conceptuais de Bases de Dados
Conceptualmente existem diferentes tipos de bases de dados. No entanto em implementaes reais de bases de dados existe por norma uma unio e mistura dos diversos conceitos conceptuais.
11/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
O modelo plano (ou tabular) o mais simples e consiste no conceito de simples matrizes, bidimensionais, compostas por elementos de dados: e.g. inteiros, nmeros reais e strings. Este modelo plano a base das folhas de clculo muito conhecidas do pblico por aplicaes tipo Excel e Open Ofice.
O modelo em rede permite que vrias tabelas sejam usadas simultaneamente atravs do uso de apontadores (ou referncias). Algumas colunas contm apontadores para outras tabelas ao invs de todos os dados estarem reunidos numa nica tabela. Assim, as tabelas so ligadas por referncias, o que pode ser visto como uma rede.
O modelo de rede tem uma variao particular chamada de modelo hierrquico. Tal limita as relaes a uma estrutura semelhante a uma rvore (hierarquia - tronco, ramos, folhas), em que os diversos elementos tm elementos ascendentes e descendentes. J o modelo normal em rede direccionado por simples estruturas em forma de grafos.
O modelo de Bases de dados relacionais consiste principalmente em trs componentes: a coleco de estruturas de dados, nomeadamente relaes ou informalmente conhecidas por tabelas; uma coleco de operadores de lgebra e de clculo relacional; e uma coleco de restries da integridade, definindo o conjunto consistente de estados da base de dados e de alteraes de estados possveis. As restries de integridade podem ser de trs tipos: domnio ou tipo, atributo, ou de varivel relacional.
Ao contrrio dos modelos hierrquico e de rede, no existem quaisquer apontadores, de acordo com o Princpio de Informao, toda a informao tem de ser representada como dados; qualquer tipo de atributo representa relaes entre conjuntos de dados. As bases de dados relacionais permitem aos utilizadores (incluindo programadores) escreverem consultas (queries) que no foram antecipadas por quem projectou a base de dados. Como resultado, a base de dados relacional pode ser utilizada por vrias aplicaes em formas que os seus criadores originais no previram, o que especialmente importante em bases de dados que podem ser utilizadas durante dcadas. Isto tem tornado as bases de dados relacionais muito populares no meio empresarial.
12/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
O modelo relacional uma teoria matemtica desenvolvida por Edgard Frank Codd, matemtico e investigador da IBM que serviu para estruturar como as bases de dados deveriam funcionar. Essa teoria a base de todas as bases de dados relacionais, no entanto poucos ou nenhuns sistemas reais seguem letra toda a teoria do modelo relacional.
Anotaes de Meta Dados em linguagens como XML
A integrao de informao heterognea um problema com que as empresas tm necessidade de lidar e que no tm uma resposta simples e definitiva pois tambm um tpico de investigao actual. Uma das solues actuais envolve o uso de uma linguagem de marcao de metadados como o XML (eXtensible Markup Language) que permite a integrao de bases de dados heterogneas, bases de documentos heterogneas, pginas Web de portais, etc. O XML uma linguagem de anotao de documentos para estruturar a informao. A informao estruturada possui contedo (e.g. palavras, imagens) e a indicao sobre o papel do contedo. e.g. o contedo do titulo de uma seco diferente do contedo de uma nota de rodap, que significa algo diferente do titulo de uma figura ou do contedo de uma tabela. Todos os documentos tm alguma estrutura, uma linguagem de anotao um mecanismo para identificar essa estrutura.
Adequao do modelo para os vrios tipos de informao Este modelo de dados no adequado para representar informao no estruturada. As anotaes textuais devem dar alguma estrutura aos dados e necessrio definir quais so as anotaes que podem ser feitas num esquema XML. Este modelo adequado para representar informao semi-estruturada, pois permite que s algumas partes dos documentos estejam anotadas e tenham uma anotao prevista. A representao de informao estruturada neste modelo possvel e permite a representao e interpretao de restries sobre os dados (e.g. chaves primrias, chaves estrangeiras).
13/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Interrogao no modelo de dados A interrogao de dados em XML pode ser feita usando uma das vrias linguagens desenhadas para o efeito como por exemplo o XQuery (Wc3:xquery). Esta linguagem de interrogao usa a estrutura do XML de forma inteligente permitindo construir interrogaes sobre todo o tipo de dados, quer estejam fisicamente armazenados em XML ou armazenados noutros suportes que possam ser vistos como XML.
Introduo de dados no modelo Este modelo requer que se defina o esquema XML para a anotao dos dados. Este esquema, pode ser muito simples ou algo to complexo como o esquema de uma base de dados. Para a modelao do esquema XML j existem ferramentas semelhantes ao modelo Entidade Relao e ao UML. A introduo de informao no modelo ter que ser feita anotando os documentos com a informao desejada, esta anotao pode ser parcialmente automatizada.
Eficincia da interrogao e da introduo de dados A eficincia das linguagens de interrogao para o XML, por exemplo o XQuery ou o XPath, no garantida pois depende da organizao dos dados em XML, do parser XML e da necessidade de verificar ou no a consistncia da informao na interpretao da pergunta. Os documentos XML podem estar fisicamente na mesma mquina, em mquinas diferentes no mesmo edifcio ou espalhados na Web. A introduo de dados neste tipo de modelos de dados pode ser muito ineficiente em termos de espao pois so adicionadas vrias etiquetas de texto que podem aumentar bastante o volume de dados a armazenar. H vrias formas de melhorar este aspecto como por exemplo a compactao dos documentos que ter como contrapartida uma degradao no desempenho da interrogao.
14/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Modelo de bases de bases de dados nativas XML
Por norma os modelos relacionais so bases de dados genricas que suportam dados em formatos bastante diversificados. Essa generalidade muito til na maioria dos casos. No entanto h situaes em que tal caracterstica pode afectar a performance. Um caso desses quando existe a necessidade de armazenar e manter grandes quantidades de informao no formato XML.
O standard XML cada vez mais utilizado para representar informao nos mais diferentes patamares de aplicaes, assim necessrio que exista uma maneira eficaz de tratar e armazenar esses documentos.
Numa base de dados XML nativa a unidade elementar de informao o documento XML, como estamos a lidar com dados semiestruturados, podemos possuir muitas informaes redundantes, por isso necessrio uma ateno especial nas operaes de actualizao de dados. De seguida so apresentados algumas necessidades que so perfeitamente suplantadas nas caractersticas das bases de dados nativas em XML: Existncia de mais consultas do que actualizaes; Necessidade de acompanhar/investigar a origem dos dados; No h necessidade de mudanas no modelo de dados ou no necessrio o seu controle, o XML no exige modelo de dados estveis e pr-definidos; Necessidade de mudana na normalizao do modelo. (Com o a utilizao de XML, mudar ocorrncias de 1 para N causa menos impacto do que em base de dados relacionais; Necessidade de distino entre dados, lgica e apresentao; Utilizao de lgica orientada a objectos;
15/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Facilidade e possibilidade em utilizar as funcionalidades de validao e de integridade de XML Schema e Schematron directamente sobre os dados e usufruir das suas funcionalidades; Linkagem de dados com altas performances utilizando X-Link directamente sobre os dados.
Actualmente j existem diversas implementaes de bases de dados nativas em XML que suportam a aplicao directa das vrias tecnologias de consulta e manipulao de XML. Estas tecnologias de consulta e manipulao (e.g. X-Path, X-Link, X-Query, XML Schema, XProc) podem ser aplicadas sobre os dados na base de dados, sendo de certa forma equivalente ao SQL de consultas das convencionais bases de dados relacionais. Usar estas tecnologias directamente sobre as bases de dados para alm de ser mais cmodo e intuitivo para o utilizador tambm permite obter mais funcionalidades e sobretudo melhores performances dado o seu cariz nativo. As bases de dados de XML Nativas mais difundidas, desenvolvidas e conhecidas so a eXist e a Tamino. A eXist open source e gratuita, sendo a Tamino comercial.
Ontologias
O OWL uma linguagem formal standard para a descrio de ontologias destinadas publicao/partilha na World Wide Web (WWW). Utiliza sintaxe baseada em XML/RDF para descrever propriedades, regras e relaes/dependncias (axiomas) entre objectos do conhecimento (indivduos) o que origina representaes escalonveis e partilhveis. Existe nas variedades/dialectos Lite, DL e Full que incluem (sucessivamente) mais/diferentes primitivas de modelao ontolgica. A mais recente extenso linguagem OWL denomina-se OWL2 (WC3:OWL2) e engloba tambm distintas variedades, nomeadamente os perfis EL, QL e RL que variam relativamente capacidade de integrao em Sistemas de Gesto de Bases de Dados e aplicabilidade a ontologias extensas/complexas. Dado o armazenamento em sistema de ficheiros, a representao modular e facilmente disponibilizada a agentes embora com fraco desempenho em ontologias extensas.
16/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
O OWL constitui a lngua franca na componente/etapa da Web 3.0 denominada Semantic Web. Um dos objectivos desta etapa representar o conhecimento em cada elemento da WWW (servios, sites, redes sociais) de forma a ser entendido e manipulvel por mquinas/algoritmos (i.e. Internet of Machines). Devido existncia de ontologias anteriores ascenso do OWL a standard de representao ontolgica, essencial o aparecimento de ferramentas para converso destas ontologias para OWL de modo a permitir a sua utilizao em ambientes distribudos (como a WWW) evitando repetir todo o processo de modelao e introduo de dados. Em sistemas de gesto ontolgica mais eficientes na construo (e armazenamento) de ontologias extensas, estas ferramentas proporcionam uma forma de utilizar tais ontologias em contextos definidos para o OWL.
Adequao do modelo para os vrios tipos de informao As ontologias no so adequadas para representar informao sem estrutura. As ontologias em particular o OWL2 permitem representar informao semi-estruturada associando, por exemplo, os objectos no estruturados a propriedades de instncias da ontologia. As ontologias so usadas para representar informao estruturada, i.e. conhecimento acerca do mundo ou parte dele, consistindo conjuntos de tipos, propriedades e relaes de tipos. As actuais ontologias partilham muitas estruturas similares, independentemente da linguagem em que so expressas. A maioria das ontologias descreve indivduos (instncias), classes (conceitos), atributos, e relaes. Qualquer representao de conhecimento com primitivas de modelao descreve uma ontologia. No entanto, a qualidade da ontologia pode ser determinada pela granularidade da representao e pela expressividade das relaes. Inicialmente a investigao em ontologias tinha por objectivo resolver os problemas de representao. Aps definido um conjunto de primitivas elementares para a construo de ontologias, a investigao foi redireccionada para o contedo e metodologia de construo de ontologias. Numa ontologia podemos representar o contedo de bases de dados, o contedo de documentos, de pginas em HTML, etc. A combinao entre bases de dados relacionais e ontologias OWL/RDF um tema de investigao activa. Para alm das j referidas converses
17/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
ad-hoc de sistemas ontolgicos (eventualmente proprietrios) para OWL, existem ainda abordagens em sentido inverso que registam ontologias OWL em bases de dados relacionais como forma de utilizar modelos ontolgicos com o desempenho, robustez e fiabilidade das bases de dados.
Interrogao no modelo de dados A interrogao de ontologias por exemplo em OWL2 pode ser feita usando uma linguagem de interrogao como por exemplo o SPARQL, uma ferramenta desenvolvida pelo W3C Data Access Working Group, que permite interrogaes nas ontologias com o poder expressivo do SQL, i.e. interrogaes sobre as instncias indicando a estrutura da ontologia. As interrogaes podem ser feitas sobre recursos em diferentes suportes (RDF, XML, Bases de Dados, etc) espalhados na WEB. Assente sobre lgica descritiva, o OWL permite a utilizao de mecanismos de raciocnio/inferncia denominados reasoners (so exemplos o FaCT++, Pellet ou HermiT) que deduzem conhecimento implcito (consequncias lgicas) na representao de conhecimento, agindo como interpretadores de OWL. O OWL SAIQL e o SQWRL so exemplos de linguagens de interrogao para o OWL-DL, que permitem interrogar usando as suas descries lgicas, definio de propriedades classes e restries.
Introduo de dados no modelo A introduo dos dados numa ontologia ter que ser feita traduzindo a informao a representar para a ontologia definida para a representar. Esta tarefa pode ser automatizada definindo processos automticos de extraco de conhecimento usando por exemplo tcnicas de minerao de dados ou texto. A definio de uma ontologia que permita representar a informao desejada deve ser feita recorrendo a metodologias por especialistas no domnio da informao a representar e especialistas na rea de representao de conhecimento em ontologias. Para integrar a informao de fontes heterogneas, a ontologia poder ser definida de forma abrangente prevendo a representao da informao de todas as fontes, ou podem-se definir ontologias especificas para as diferentes fontes de informao e depois poder-se- recorrer a mtodos de fuso de ontologias (merge). Nalguns casos tambm se pode gerar automaticamente a ontologia a partir da documentao.
18/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Eficincia da interrogao e da introduo de dados O SPARQL uma linguagem de interrogao cuja eficincia depende do suporte do OWL, que pode ser documentos RDF/XML e neste caso tem um desempenho pobre, ou podem ser bases de dados com os triplos RDF inseridos em tabelas de forma eficiente e nesse caso, ter um desempenho to eficiente como o SQL. A eficincia da introduo de dados neste modelo de dados tambm depende do suporte usado, em documentos de texto (formato RDF/XML) pode originar grandes quantidades de dados que degradam o desempenho da interrogao, representando as instncias em bases de dados, o desempenho da interrogao e o armazenamento dos dados tem um desempenho semelhante ao dos Sistemas de Gesto de Bases de Dados. Relativamente interrogao e com linguagens sobre o OWL-DL e ao processo de definio de ontologias, em particular para a verificao de consistncia, o desempenho no bom, pois tem que recorrer a sistemas de inferncia que nalguns casos tem complexidade no polinomial.
Relaes e Grafos Multi-partidos
Na representao de conhecimento til representar grafos a partir de relaes. Estas podero ser booleanas ou difusas (pesadas). Estas relaes so em geral relaes multidimensionais onde os objectos pertencem a diversos conjuntos distintos, exemplo de uma relao onde temos trs tipos de objectos R(X,Y,Z). Estas relaes so normalmente representadas em subconjuntos de relaes binrias, exemplo R(X,Y,Z) em R(X,Y), R(X,Z) e R(Y,Z). Estas representaes podem ser vistas como grafos bi-partidos. Na seco seguinte podemos ver como construir e representar grafos bi-partidos R(X,Y) em grafos R(X,X) e R(Y,Y).
Grafos bi-partidos e redes complexas A partir de grafos bi-partidos crisp ou difusos podemos criar grafos difusos (pesados). Um grafo uma relao booleana entre entidades (Objectos) do mesmo tipo. Mais formalmente um grafo G(V,E) uma relao finita de entidades. O conjunto V chamado o conjunto de vrtices ou ns V={v1,v2, , vn} e o conjunto E o conjunto de arcos E={e12,e21,
19/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
, eij}, onde eij representa o arco entre o vrtice vi e vj. O conjunto de arcos E toma valores no conjunto {0,1}. O grafo difuso (pesado) uma relao WG(V,E) onde V como anteriormente o conjunto de entidades chamados vrtices ou ns do grafo e E o conjunto de arcos na relao WG. Neste caso E toma valores no intervalo [0,1] aps normalizao. Um grafo bi-partido uma relao booleana ou no que relaciona dois tipos de entidades (objectos), i.e. tem dois tipos de vrtices ou ns.
Exemplo Suponhamos que temos o seguinte grafo bi-partido, relao entre utilizadores (users) e alguma espcie de items (objectos), por exemplo filmes (Movies). A relao mostra os votos na escala de 0-5 dos users em relao aos movies.
Movie 1 User 1 User 2 User 3 5 3 2
Movie 2 0 2 1
Movie 3 2 1 0
Movie 4 1 0 0
Grafo bi-Partido Relao entre Users e Movies Da relao entre users-movies podemos aplicar uma medida de similaridade para construir dois tipos de grafos difusos com a similaridade entre users ou entre movies. A figura 1 mostra estas duas possibilidades.
20/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
UxM
UxU
MxM
Figura 1 Dois tipos de grafos obtidos pela aplicao de uma funo de similaridade.
Uma das medidas de similaridade possveis Jaccard similarity. A Jaccard Similarity definida para relaes booleanas como:
J ij
# ( xi x j ) # ( xi x j )
x onde , x i e j so os vectores linha ou coluna da relao bi-partida. Podemos estender a medida Jaccard para valores no intervalo [0,1] por:
J ij
min( x
k k
ik
, x jk ) , x jk )
max( x
ik
x Onde, x i e j so os vectores linha ou coluna da relao bi-partida.
No nosso exemplo teremos de primeiro normalizar a relao no intervalo [0,1], usando por exemplo a normalizao linear z=(x-min(x))/(max(x)-min(x)).
21/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Movie 1 User 1 User 2 User 3 1 0.6 0.4
Movie 2 0 1 0.5
Movie 3 1 0.5 0
Movie 4 1 0 0
Normalizao linear da relao bi-partida
Depois de aplicarmos a medida de Jaccard relao normalizada obtemos os grafos para utilizadores e para filmes: User 1 User 1 User 2 User 3 1 0.2750 0.1143 User 2 0.2750 1 0.4286 User 3 0.1143 0.4286 1
Grafo difuso entre users (depois Jaccard)
Movie 1 Movie 1 Movie 2 Movie 3 Movie 4 1 0.4000 0.7500 0.5000
Movie 2 0.4000 1 0.2000 0.0000
Movie 3 0.7500 0.2000 1 0.6667
Movie 4 0.5000 0.0000 0.6667 1
Grafo difuso entre Movies (depois Jaccard)
Propriedades das redes complexas ainda importante referir algumas das propriedades mais utilizadas no contexto dos grafos e das redes complexas. Por exemplo:
22/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
O grau do n (degree) uma medida que d por exemplo a importncia dos vrtices. O clustering coefficient d-nos uma medida de transitividades entre vrtices Betweeness importante para a deteco de comunidades em redes complexas e o caminho mais curto d-nos a noo de distancia entre vrtices.
23/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Ferramentas de armazenagem e acondicionamento de informao
Neste captulo sero ento abordadas solues comerciais e open source que utilizam alguns dos conceitos anteriormente introduzidos e aprofundados.
Microsoft SQL Server
O SQL Server um sistema de gesto de bases de dados (SGBD) da Microsoft, utilizado para criar e gerir bases de dados relacionais. Este sistema est disponvel no mercado desde 1988, ano em que a Microsoft em parceria com a empresa Sybase, colocaram o mesmo como uma ferramenta do Windows NT. Em 1994 a parceria terminou e a partir dessa altura a Microsoft ficou responsvel pela evoluo do sistema.
Figura 1: Logtipo do SQL Server
Actualmente encontra-se na verso 10.50, tambm conhecida como SQL Server 2008 R2. Esta verso fornece aos utilizadores uma plataforma mais dinmica, mas sobretudo mais inteligente. O SQL Server est disponvel em diversas verses, com caractersticas e pblicos-alvo diferentes, estando dividido da seguinte forma: Edies gerais o Datacenter: a verso geral com o maior nmero de ferramentas, dirigido a grandes datacenters que necessitem do mximo de escalabilidade possvel e de grande poder de
24/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
processamento. Esta verso oferece suporte para 256 processadores paralelos e no tem limite de memria virtual; o Enterprise: Inclui um grande nmero de ferramentas para a criao e manuteno do sistema do SQL Server, possuindo os servios chave de gesto da base de dados. Com esta verso do sistema o administrador da base de dados pode gerir bases de dados at 524 Petabytes (1 Petabyte = 1 024 Terabytes) e utiliza at 2 Terabytes de memria virtual com 8 processadores; o Standard: A verso Standard direccionada para o mesmo pblico-alvo da verso Enterprise sendo a nica diferena a menor capacidade de processamento. Nesta verso o administrador est limitado a um menor nmero de instncias do SQL Server, ou seja, existe um nmero mximo de ns no cluster a executar o SQL Server. Em termos de ferramentas apenas no possui as ferramentas que fazem a gesto da memria que seria usada caso no tivesse limite; o Web: A verso Web Edition uma verso exclusivamente web, e dirigida sobretudo para utilizao de empresas que precisam de servios de alojamento de site e aplicaes web. uma verso altamente escalvel pois consoante as necessidades do utilizador e com o mnimo de custos associados. utilizado principalmente como SKU (Stock Keeping Unit). Uma pesquisa recente conclui que cerca de 90% dos utilizadores que utilizam a verso Standard apenas necessitavam utilizar a verso Web. o Workgroup: Idntica a verso Standard, contem tambm as funcionalidades principais para criao de bases de dados, mas no tem os restantes servios adicionais, para optimizao e anlise da base de dados. Normalmente utilizada para integrar outros projectos em SQL Server j existente. o Express: A verso Express utilizada como uma espcie de amostra das capacidades do SQL Server e pode ser descarregada gratuitamente do site. Apresenta limitaes, principalmente ao nvel da capacidade de processamento e armazenamento das bases de dados. O utilizador pode criar o nmero de bases de dados que entender, mas est limitado a um nico processador, e a um tamanho mximo de 10 Gigabytes.
25/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Edies especializadas o Azure: Esta verso do SQL Server, uma verso que embora seja visto como um sistema separado, criado com base no SQL Server. Este servio assenta na cloud computing, ou seja funciona a partir de servidores remotos algures na web, no sendo necessrio instalar e armazenar os dados localmente. O nome completo da verso Microsoft SQL Azure Database, o que indica a exclusividade deste Software as a Service presenta apenas atravs dos servios na nuvem da plataforma da Microsoft, o Windows Azure. o Compact: A verso Compact uma base de dados embutida e baseada no SQL Mobile. Esta verso utilizada como uma biblioteca de apoio a uma aplicao, e fornece a essa aplicao as funes necessrias de manuteno e gesto de uma pequena base de dados. Utilizado sobretudo com aplicaes mveis ou com poucos recursos, permite a gesto de bases de dados at 4Gigabytes. o Embedded: Est verso igual verso Express mas com configurao especifica para ser utilizada e acedida por um grupo de Servios do Windows, normalmente instalada em servidores dedicados a bases de dados. o Developer: A verso developer uma verso em tudo idntica verso Datacenter, com a nica diferena que apenas pode ser utilizada para o desenvolvimento e testes de bases de dados. A licena concedida ao utilizador da verso developer no lhe permite colocar esta verso a executar em ambiente de produo. Caso seja estudante o utilizador pode fazer o download gratuito da aplicao. o Evaluation: uma verso do tipo trial, que permite aos seus utilizadores testarem as funcionalidades do SQL Server antes de adquirem a licena. Encontra-se limitada a um perodo de 180 dias, a partir do qual as ferramentas continuam a executar mas os servios do servidor da base de dados no. o Fast Track: Esta verso especificamente desenhada para empresas que utilizam Data Warehouses e com necessidade de grandes recursos de Business Intelligence. Est totalmente construda para a integrao com sistemas de hardware optimizado para Fast Track (configurao de hardware definida por padres) o Parallel Data Warehouse: uma verso do SQL Server para processamento paralelo em massa, dedicado a Data Warehouses com centenas de Terabyes.
26/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 2: Servios do SQL Server
Todas as verses esto desenvolvidas com base no ncleo do SQL Server, mas consoante a verso existem mais ou menos caractersticas e ferramentas especificas dessa aplicao (Figura 6). Sero abordadas, de seguida, algumas dessas caractersticas mais relevantes do sistema SQL Server.
Instalao dinmica
Atravs da instalao dinmica as empresas conseguem instalar novas instncias do sistema com as configuraes correctas, evitando demasiado tempo em novas configuraes. Os diferentes tipos de instalaes necessrios para os diversos ambientes e fins dentro da empresa podem ser definidos numa espcie de template para facilitar e automatizar o processo em necessidades futuras.
27/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 3: Processo de instalao e configurao
Coleco de Dados de Desempenho
A ltima verso do SQL Server, fornece aos administradores das bases de dados, uma ampla coleco de dados de informao sobre o desempenho do sistema. Tambm foram adicionadas novas ferramentas para monitorizao e criao de relatrios.
28/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 4: Grficos de desempenho do sistema
LINQ
Linguage Integrated Query (LINQ) uma linguagem suportada pelo SQL Server 2008, que permite aos programadores substituir as declaraes de SQL por linguagens de programao como o C# e o Visual Basic. A utilizao dessa linguagem permite consultas transparentes, intuitivas e orientadas a um conjunto, podendo as mesmas ser realizadas a partir de um objecto ou criar um objecto a partir dos resultados das mesmas.
29/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 5: Utilizao LINQ
Microsoft SQL Server Management Studio
Figura 6: Interface do SQL Server Management Studio 2008
30/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Como forma de aumentar a produtividade dos utilizadores ao trabalharem com o SQL Server, tambm disponibilizado o Microsoft SQL Server Management Studio (Figura 6). Esta ferramenta ajuda bastante o desenvolvimento, criao e alterao das bases de dados. tambm atravs desta ferramenta que o administrador da base de dados tem acesso a informao relativas ao desempenho das queries por ele realizadas. Com a ferramenta o administrador liga-se base de dados em questo e tem acesso a vrias funcionalidades grficas, sem ser necessrio escrever cdigo SQL. Tarefas como insero de dados, alterao de tarefas ou criao de bases de dados, podem tambm ser executadas automaticamente recorrendo a ficheiro com cdigo SQL de forma a automatizar as tarefas.
InteliSense
Na (Figura 6) tambm visvel outra das funcionalidade do Management Studio, o InteliSense, normalmente conhecido como auto-complete, este extra do Management Studio foi herdado do Visual Studio, e auxilia o programador a completar os scripts SQL atravs da sugesto de palavras ou conjuntos de cdigo que melhor se enquadrem naquele cdigo em especifico.
31/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 7: Menu gerao dos scripts SQL
Outra ferramenta bastante til o backup da base de dados, e o restauro de bases de dados a partir de ficheiros. As bases de dados podem tambm ser convertidas para ficheiros com cdigo SQL para posterior criao noutra instancia do SQL Server ou qualquer tipo de base de dados SQL.
32/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Oracle
O Oracle um sistema de gesto de base de dados que surgiu no mercado em 1970, por parte da empresa Oracle Corporation. Nessa altura as bases de dados comeavam a ser utilizadas mas no numa forma de produto. Foi ento que a empresa foi criada tirando partido dessa oportunidade de negcio. Actualmente a Oracle uma das maiores empresas mundiais de software relacionado com bases de dados. A ltima verso lanada do Oracle a verso 11g. Com cada verso que lana para mercado a Oracle tem melhorado a sua escalabilidade, funcionalidade e a capacidade de gesto.
Figura 8: Logtipo do sistema
O Oracle faz uso de trs linguagens; SQL, Java e o PL/SQL. O Java foi desenvolvido pela SUN mas, no ano 2009 a Oracle comprou a SUN e actualmente a responsvel pelo desenvolvimento do Java. O PL/SQL foi desenvolvido pela prpria empresa aquando da evoluo do Oracle, e est disponvel no SGBD desde 1988. De seguida, vo ser abordadas quais as principais funes dessas linguagens na criao e manuteno de bases de dados com o Oracle. SQL: A linguagem SQL (Structured Query Language) definida pelo padro ANSI e representa apenas algumas funes bsicas no Oracle. Atravs de cdigo SQL o administrador pode manipular os dados, controlar transaces ou pesquisar por determinados campos na base de dados. Maioritariamente o administrador no necessita recorrer a linguagem propriamente dita podendo utilizar aplicaes que realizam esse processo por ele. Essas aplicaes apresentam ao utilizador uma interface simples e inteligente e escondem o cdigo SQL e a sua complexidade. PL/SQL: Sendo uma linguagem da empresa Oracle, bastante utilizada no Oracle, para criao e implementao de programao em lgica em certas aplicaes. Com esta linguagem o administrador pode criar procedimentos automticos como triggers, e
33/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
looping controls, mas pode tambm ser utilizada para consultas condicionais base de dados ou tratamentos de erros.
Figura 9: SQL *Plus
Esta linguagem (PL/SQL) pode ser compilada e posteriormente armazenada na base de dados para ser utilizada directamente pela base de dados de forma autnoma. Atravs do SQL *Plus, programa para execuo de cdigo PL/SQL do tipo linha de comandos, o administrador pode executar blocos de cdigo PL/SQL atravs de uma ferramenta interactiva que vem includa em todas as verses do Oracle. Java: A partir do Oracle 8i, os administradores e programadores dos sistemas Oracle puderam comear a utilizar a linguagem Java como uma linguagem para a criao de processos. Foi introduzido no Oracle uma mquina virtual, inicialmente chamada JServer, que permitia ao utilizadores executarem cdigo Java para criao de aplicaes Oracle. Estas aplicaes podem ser distribudas por clientes, no Servidor de Aplicaes ou na prpria base de dados.
Alm da grande variedade de linguagens de programao disponibilizadas aos administradores da base de dados so tambm instaladas com o Oracle um grande nmero de ferramentas para auxiliar ao desenvolvimento e manuteno das bases de dados. As ferramentas agrupam-se em sete grupos consoante as caractersticas que apresentam: Desenvolvimento de Aplicaes para a base de dados Ligao a bases de dados externas Criao e manuteno de bases de dados distribudas Deslocamento de dados
34/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Performance Gesto de bases de dados Anlise de performance
Figura 10: Pgina de Login do Oracle 11g
A Oracle geralmente lana novas verses do seu sofware a cada trs / quatros anos. Com esses novos lanamentos a empresa introduz novas caractersticas no sistema. A verso 11g (Figura 10) apresenta vrias edies, que embora partilhem o mesmo cdigo fonte principal, apresentam funcionalidades que as distinguem. Esta famlia de produtos inclui:
Enterprise Edition
A Entreprise Edition a principal fonte de rendimento da Oracle, principalmente no que diz respeito a bases de dados. a verso destinada a criao de bases de dados de larga escala que requeiram todo o conjunto de caractersticas e funcionalidades. As caractersticas utilizadas em Data Warehouses esto disponveis apenas nesta verso, ferramentas como Compactao de Valores Repetidos, Gesto de Tempo de Vida da Informao, Aplicao de Data Mining e Partio de dados, so exclusivas da verso Enterprise.
35/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 11: Grficos de Monotorizao
Nesta verso esto tambm algumas das mais importantes ferramentas de anlise de performance da base de dados, como o caso do Analisador de Performance de SQL e o Total Recall que cria um arquivos de Dados Flashback para manter em memria o resultado de consultas antigas. Possui tambm mecanismos de monitorizao do sistema onde o Oracle est instalado, como a quantidade de memria em utilizao, percentagem de processador em utilizao, nmero de sesses activas e velocidade de resposta a queries SQL (Figura 11).
Figura 12: Enterprise Manager 11g
36/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Para realizar a manuteno e gesto das suas bases de dados, os administradores utilizam uma ferramenta chamada Enterprise Manager (Figura 12). Esta ferramenta era inicialmente instalada como um software parte da instalao do Oracle, o administrador devia ento posteriormente, configurar a ferramenta para que esta se ligasse sua base de dados. A partir da verso 10g da Oracle Enterprise Edition esta ferramenta passou a ser instalada em simultneo com a base de dados e abandonou a forma de software local, passando a ser utilizado atravs do browser como se de uma pgina web se tratasse. O administrador configura o endereo IP onde pretende aceder e a partir da esse endereo local abre a pgina do Enterprise Manager.
Express Edition
Esta verso da base de dados Oracle, tambm conhecida como Oracle XE, serve como uma amostra das funcionalidades das outras verses. Est disponvel no site para download gratuito, para os sistemas operativos Windows e Linux. A verso XE est limitada a 1GB de memria mxima e a bases de dados com o mximo de 4GB no disco. Apresenta algumas ferramentas da verso Standard Edition One, e no suporta a execuo de cdigo Java pois no possui a Mquina Virtual Java. No apresenta suporte para funcionalidades como cpias de segurana ou recuperao de dados do servidor. A gesto desta verso no realizada pelo Enterprise Manager mas sim atravs de uma verso antiga utilizada anteriormente pela verso enterprise chamada HTML-DB (Figura 13).
37/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 13: Oracle XE pgina inicial
Standard Edition
A verso Standard destinada a pequenas ou mdias empresas que necessitem de implementar bases de dados Oracle e limitada a servidores com 4 CPUs num nico sistema. A configurao tambm vlida para Clusters com o mesmo nmero de CPUs. Este sistema tem tambm disponvel uma ferramenta com o nome, Real Application Cluster que faz a gesto e distribuio do sistema pelo Cluster.
Standard Edition One
Como o prprio nome indica, destinado a implementaes pequenas e singulares, com baixa necessidade de poder de processamento, sendo possvel apenas instalar esta verso num nico servidor com um mximo de 2 CPUs. Esta verso igual Standard Edition, com excepo do Real Application Cluster, visto no ser possvel instala-lo num Cluster essa ferramenta desnecessria.
38/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Personal Edition
A verso Personal Edition a verso utilizada por administradores de bases de dados, para criar e realizar testes a bases de dados. A licena associada a esta verso no permite a utilizao desta em ambientes de produo, sendo um licena uni-utilizador. A nica diferena entre esta verso e a verso Enterprise apenas o tipo de licena que adquirida com o sistema.
Database Lite
Esta verso no se enquadra no mesmo grupo das anteriores, mas bastante utilizada no mercado mvel. Esta verso chama-se Oracle Database Lite e um conjunto de ferramentas que permite o uso em dispositivos portteis, como telemveis, PDAs e tablets, que utilizem aplicaes que necessitem de bases de dados. O Oracle Database Lite constitudo pela core da base de dados Oracle Lite, pelo Mobile Development Kit e o Portatil Server. Esta verso do Oracle varia em 50KB at 1MB de tamanho dependendo da plataforma em que se instala e pode ser utilizada por aplicaes escritas em Java ou C++. O funcionamento do Oracle Database Lite apenas de armazenamento de dados presentes em outras bases de dados Oracle de maior dimenso, com as quais o sistema realiza sincronizaes sempre que necessrio (Figura 14).
39/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 14: Funcionamento do Oracle Lite
MySQL
O MySQL um sistema de gesto de bases de dados relacionais que utiliza como principal linguagem o SQL. Considera-se actualmente como um dos sistemas de bases de dados mais populares existentes na web, tendo mais de 10 milhes de instalaes em todo o mundo. Alguns dos principais clientes deste sistema de base de dados so, entre outros, empresas como: NASA, Friendster, Banco Bradesco, HP, Nokia, Sony, Lufthansa, U.S. Army, U.S. Federal Reserve Bank, Alcatel, Cisco Systems, Google entre outros.
Figura 15:Logotipo MySQL
40/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
O MySQL comeou a ser desenvolvido por trs programadores nrdicos em 1994 e actualmente existem cerca de 400 pessoas envolvidas neste sistema. No incio era distribudo exclusivamente de forma gratuita e sob a licena GPL. Estava apenas disponvel numa nica verso e tinha como pblico-alvo a maioria dos utilizadores e administradores de bases de dados simples. No dia 16 de Janeiro de 2008, a MySQL foi adquirida pela Sun Microsystems, por cerca de 1 bilio de dlares. Passado pouco mais de um ano aps essa compra, dia 20 de Abril de 2009, a Oracle comprou a Sun Microsystems e houve grande receio por parte de toda a comunidade de clientes MySQL, visto a Oracle ter o seu prprio sistema de bases de dados relacionais. A Oracle manteve o MySQL e iniciou a comercializao de verses mais especficas e com ferramentas e pblicos-alvo diferentes, mas com a mesma arquitectura base (Figura 16).
Figura 16: Arquitectura do MySQL
O MySQL est totalmente desenvolvido em C e C++ e o seu grande sucesso deveu-se grande maioria dos Content Management System, como o Joomla o Wordpress ou o Drupal requeressem o MySQL como base de dados para os contedos dos mesmos. O facto de ser gratuito tambm aumentou bastante a sua utilizao.
41/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 17: Exemplo do um CMS que requere MySQL
A ltima verso do MySQL suporta o maior nmero de sistemas operativos possvel, podendo o utilizador instalar este sistema de gesto de bases de dados em cerca de 20 ambientes diferentes de onde se destacam sistemas operativos como: FreeBSD Linux Mac OS X Microsoft Windows NetBSD OpenBSD Solaris Symbian SunOS
42/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Actualmente encontra-se na verso 5.8. Esta verso, j desenvolvida pela Oracle, apresentou algumas melhorias na verso anterior e introduziu novas ferramentas. O MySQL tem como principais caractersticas: Portabilidade Elevada compatibilidade Grande desempenho e estabilidade Pouco exigente no que diz respeito a recursos de hardware Facilidade de instalao e utilizao Verses em que funciona como software livre com base na GPL
O MySQl est disponvel para o utilizador em diversas verses, consoante o tipo de utilizao que o mesmo pretende e a quantidade de informao e processamento que necessita retirar do mesmo. Vamos de seguida abortar as verses que esto disponveis no site do MySQL.
MySQL Community Server
A verso Community Server a verso desenvolvida pela comunidade e que est disponvel gratuitamente para o utilizador descarregar do site. Est verso embora seja grtis, no apresenta grande perda de ferramentas em relao verso paga. Esta verso desenvolvida pela grande comunidade de programadores e entusiastas do MySQL.
MySQL Enterprise Edition
A Enterprise Edition a verso comercial do sistema de gesto de bases de dados, vendido pela Oracle atravs de 3 licenas separadas consoante a utilizao e instalao que o cliente pretende. Pode ser descarregado e testado gratuitamente durante um perodo de 30 dias. A verso Enterprise dirigida a empresas com bases de dados grandes, mas que estejam alojadas num nico servidor, pois no apresenta ferramentas para gesto do MySQL em cluster ou
43/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
sistemas distribudos. Esta verso alm da base de dados MySQL instala trs ferramentas exclusivas: MySQL Enterprise Backup MySQL Enterprise Monitor MySQL Workbench Standard Edition
MySQL Standard Edition
uma verso paga, semelhante Enterprise Edition, mas um pouco mais limitada em termos de ferramentas externas. dirigido a empresas com bases de dados intermdias onde a quantidade de dados no justifica o enorme investimento da verso Enterprise. A verso Standard apenas disponibiliza como ferramentas externas o MySQL Replication e o MySQL Workbench SE.
MySQL Cluester Edition
Esta verso, embora seja dirigida a clusters distribuda gratuitamente. dirigida sobretudo a administradores e estudantes de bases de dados, com instigao e desenvolvimento na rea de clusters e de bases de dados distribudas. Pode ser descarregada do site em formato de executvel e est disponvel para os principais sistemas operativos sobre a licena GNU.
MySQL Cluster Carrier Grade Edition (CGE)
Esta verso do cluster uma verso comercial e tambm a verso que oferece o mximo de ferramentas aos utilizadores. destinada a grandes empresas com bases de dados na casa dos Petabytes. O cliente adquire uma licena anual e a partir dai tem todo o suporte por parte da
44/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Oracle quer seja na instalao e configurao do sistema, como actualizaes ou servios de consultoria. Apresenta ferramentas exclusivas como o MySQL Cluster Manager e o MySQL Cluster Geo-Replication.
Figura 18: Funcionamento do MySQL Cluster Edition
Como forma de trabalhar sobre as bases de dados MySQL o utilizador no obrigado a escolher uma ferramenta em particular, podendo optar por 3 tipos de abordagem: Linha de comandos: bastante bsica, embora apresente a maioria das funcionalidades do MySQL requer grandes conhecimentos sobre a linguagem SQL e sobre os diversos sistemas do MySQL
45/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 19: Linha de comandos SQL
MySQL Workbench: Sendo a ferramenta oficial do MySQL, que oferece total suporte ao utilizador, fcil configurao da bases de dados e um grande nmero das mais diversas ferramentas grficas para auxiliar no desenvolvimento e manuteno das bases de dados. Esta ferramenta est disponvel em 2 verses, uma desenvolvida pela comunidade open source, que pode ser descarregada gratuitamente, outra que acompanha a verso entreprise que inclui as ferramentas da primeira, mas com alguns ajustes e melhoramentos, e outras funcionalidades exclusivas.
46/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 20:MySQL Workbench
Ferramentas de terceiros: Existe um grande nmero de ferramentas produzidas por outras empresas ou comunidades para auxiliar o utilizador nas bases de dados MySQL. Podem ser pagas ou gratuitas e o cliente pode escolher a que melhor se adequar. As mais conhecidas so talvez a interface atravs do browser apresentada com o nome phpMyAdmin (Figura 21), o software pago da empresa NaviCat, com o nome Navicat for MySQL ou o MySQL Administrator (Figura 22) que integra a gesto de dados e manuteno dos mesmos num ambiente nico e gratuito.
47/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 21: phpMyAdmin no browser
Figura 22: MySQL Administrator
48/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Vertica
A Vertica um sistema de bases de dados orientada por colunas. Esta ferramenta um produto da empresa Vertica Systems e foi lanado para o mercado no ano de 2005. Actualmente a Vertica Systems faz parte do grupo HP, sendo neste momento explorado pela mesma.
Figura 23: Logotipo da Vertica
Estas bases de dados so utilizadas em grandes conjuntos de dados quando na maioria dos casos apenas necessrio extrair um pequeno nmero de colunas presentes numa linha. Aplicando este algoritmo a pesquisa pode-se tornar extremamente rpida quando o nmero de colunas elevado.
Figura 24:Comparao entre os dois tipos de Bases de Dados
49/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Alm da velocidade de pesquisa, neste tipo de base de dados as ferramentas de anlise de dados e de minerao de dados tambm conseguem atingir uma maior velocidade de tratamento dos dados visto todos estarem organizados na mesma linha, consoante o tipo de informao que se pretende analisar. Empresas como a Yahoo e o Google utilizam em algumas das suas bases de dados este formato.
As principais vantagens destas bases de dados a grande velocidade de pesquisa de valores muito especficos, e a grande capacidade de compresso que oferecem. tambm bastante til este tipo de base de dados quando necessrio uma constante alterao de valores, pois atravs desta aproximao, quando o administrador altera um valor em concreto no necessrio alterar todos os dados dessa linha. A empresa, alm da base de dados disponibiliza tambm aos seus clientes outros produtos com os quais podem realizar os mais variados testes e analises s bases de dados. De seguida, sero apresentadas as vantagens que mais se destacam nesses produtos: Real-Time Query & Loading Advanced In-Database Analytics Database Designer & Administration Tools Columnar Storage & Execution Aggressive Data Compression Scale-Out MPP Architecture Automatic High Availability Optimizer, Execution Engine & Workload Management Native BI, ETL, & Hadoop/MapReduce Integration
50/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Tamino XML Server
O Tamino foi o primeiro servidor de bases de dados em formato XML. Desenvolvido pela Software AG capaz de armazenar directamente dados do tipo XML na sua forma nativa, sem necessidade de transformao dos mesmos.
Figura 25: logotipo da empresa Software AG
O Tamino XML Server (Figura 26) um servidor para gesto dos dados, baseado ele prprio em XML, que no s armazena dados em XML mas tambm, alguns tipos de dados em formatos multimdia e integra-os em outras plataformas, permitindo acesso a essas informaes via WEB. Assim, possibilita facilmente o desenvolvimento de aplicaes do tipo e-business, pois integra-se facilmente com aplicaes externas.
Figura 26: Arquitectura do Servdor Tamino
51/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
O Tamino Server gerido atravs do browser, sendo de simples instalao e configurao, e como no distribudo como um software especifico a interface totalmente desenvolvida em HTML (Figura 27). Uma das principais caractersticas do Tamino o facto de suportar a maioria dos padres utilizados pela W3C, como por exemplo: XML Schemas: Para definio de dados Xpath: Como linguagem de consulta XSLT/XSL-FO/SGV/CSS: para formatos de apresentao Soap: Como formato para arquivo de mensagens entre aplicaes
Figura 27: Interface do Tamino XML
O Tamino tambm possui servios que permitem a comunicao com sistemas de informao, telemveis, PDA's e interaco com os principais sistemas de gesto de bases de dados do mercado. Como a maioria das ferramentas de bases de dados o Tamino possui: Controlo de concorrncia, Manuteno de ndices e vises, Triggers,
52/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Backups Logging.
Para a consulta das informaes, tambm possvel a utilizao da linguagem de consulta SQL, podendo gerar tabelas e confrontar estes dados com outros semi-estruturados. Tambm disponibiliza interface para as seguintes linguagens de programao: Java, JavaScript, C/C++, ActiveX e Perl.
Figura 28: Ferramenta de upload de dados
De seguida apresentam-se algumas caractersticas mais relevantes do Tamino: Grava e recupera documentos XML (Figura 28); Permite segurana nos acessos as informaes; Utiliza HTTP como protocolo de comunicao para troca de dados; Utiliza como linguagem de consulta um subconjunto de XQL; Processa Stylesheets utilizadas com objetos XML( XSL style sheets, CSS); Implementa DOM; Utiliza ODBC1 como interface para base de dados externas; Suporte a SQL dinmicos e embebidos (para programas na linguagem C); Permite data mapping baseado em padres XML;
53/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Administrao central baseada em WEB browsers.
Alm dos servios de base de dados reservados ao servidor do Tamino, este servio apresenta um grande nmero de ferramentas complementares, para auxiliar e facilitar a vida aos administradores da base de dados.
Os principais componentes do Tamino Server so: Schema Editor (Figura 29): Responsvel pela criao de esquemas em xml para posterior utilizao pela base de dados.
Figura 29: Tamino Schema Editor
X-Maxine e XML Store - So responsveis por processar, transformar e manter internamente os documentos XML. Apresentam uma srie de componentes como: o XML Parser - Verifica se o documento XML est bem formado; o Object Processor - usado no armazenamento de dados no Tamino. Este componente contm as informaes requeridas no esquema Tamino para armazenar os dados XML e/ou SQL;
54/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
o XML Query Interpreter - Recebe uma requisio de consulta (XQL), interpreta a linguagem e interage com o Object Composer para que seja retornado um objeto XML de acordo com o esquema armazenado; o Object Composer - usado quando uma informao deve ser retornada. O Object Composer constri as informaes dos objectos e devolve um documento XML de acordo com as especificaes da consulta;
SQL Engine e SQL Store - so responsveis por gerir e armazenar os dados no modelo relacional e permitem a utilizao do SQL. X-node - responsvel por disponibilizar padres de interface para aplicaes, base de dados ou arquivos externos. Com isso, possvel a apresentao de dados como se estivessem armazenadas em uma nica fonte de dados. Data Map- responsvel por definir as regras de armazenamento, indexao e mapeamento dos dados, como, por exemplo: Schemas, DTD's, Stylesheets, vocabulrios.
Dex
O sistema de bases de dados Dex uma ferramenta desenvolvida para armazenar a manipular bases de dados de grafos. Desenvolvido pela empresa Sparsity Technologies, foi lanado em 2008 e actualmente encontra-se na verso 4.2. Foi construdo para possibilitar o constante armazenamento de grafos em certas bases de dados e ter uma arquitectura com grandes capacidades de escalonamento.
55/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 30: Logtipo da empresa
O Dex desenvolvido em Java e C++ e actualmente possvel utilizar o mesmo nos principais sistemas operativos; Windows, Mac OS X e Linux. A pensar nos programadores, o Sparsity Technologies disponibiliza tambm um grande nmero de bibliotecas para desenvolvimento de aplicaes com integrao do Dex, sendo possvel desenvolver ferramentas em Java e linguagens .NET. O Dex apresenta um grande nmero de vantagens (Figura 31), tanto em termos de armazenamento de grafos como de elevada performance na anlise dos mesmos.
56/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
Figura 31: Crculo de vantagens Dex
Os principais cenrios de aplicao dos sistemas de gesto de bases de dados Dex so: Redes Sociais o Twitter, Facebook, Linkedin, Flickr, Delicious, MySpace Redes de Informao o Bases de dados bibliogrficas, Wikipedia, IMDB Redes de segurana e deteco de fraudes o Anlise de transaces econmicas Recomendaes a utilizadores o E-Commerce Anlise de ficheiros Media
57/1 Projecto em curso com o apoio de:
BRAIN MAP | Entidade Promotora:
Parceiros:
o Recomendao e comparao de contedos audiovisuais Construo de redes o Transportes, Redes elctricas, Redes de telecomunicaes o Logstica, Transporte, Distribuio Elctrica, Redes de Telecomunicaes Redes biolgicas o Redes de ADN e comparao de clulas
Figura 32:Exemplo de aplicao de uma base de dados com grafos
58/1 Projecto em curso com o apoio de:
Você também pode gostar
- Mobilidade e Sistema de Transporte ColetivoDocumento28 páginasMobilidade e Sistema de Transporte ColetivodantascardosoAinda não há avaliações
- Ficha Tecnica - ACIII - PreconDocumento5 páginasFicha Tecnica - ACIII - PreconRodolfo RabeloAinda não há avaliações
- Apostila CompletaDocumento312 páginasApostila Completamarmaduke32Ainda não há avaliações
- Introdução Ao Circuito HidráulicoDocumento7 páginasIntrodução Ao Circuito HidráulicoleandroschroederAinda não há avaliações
- Imetro Modulos FotovoltaicosDocumento10 páginasImetro Modulos FotovoltaicosMauricio PassosAinda não há avaliações
- CerradoDocumento389 páginasCerradoMiguel Machado ManhãesAinda não há avaliações
- Unidade 8 - MACNA - Negociação e Administração de Conflitos-12-21Documento2 páginasUnidade 8 - MACNA - Negociação e Administração de Conflitos-12-21frederico fredAinda não há avaliações
- Baterias de Íons de Sódio Prontas para o MercadoDocumento4 páginasBaterias de Íons de Sódio Prontas para o Mercado@nanesojAinda não há avaliações
- Auditoria de ProntuáriosDocumento35 páginasAuditoria de ProntuáriosceresncostaAinda não há avaliações
- Catálogo Peças V3 2019 ReafrioDocumento48 páginasCatálogo Peças V3 2019 ReafrioCarlosAinda não há avaliações
- Revista Téchne - As Causas Do Acidente Da Estação Pinheiros Da Linha 4 Do Metrô de São PauloA Versão Do Consórcio Via Amarela Sobre o Acidente Da Estação Pinheiros Do Metrô - Engenharia CivilDocumento4 páginasRevista Téchne - As Causas Do Acidente Da Estação Pinheiros Da Linha 4 Do Metrô de São PauloA Versão Do Consórcio Via Amarela Sobre o Acidente Da Estação Pinheiros Do Metrô - Engenharia CivilMarcio MeirellesAinda não há avaliações
- Notebook HP Pavilion dv5 Quanta qt6 Uma Rev2a PDFDocumento44 páginasNotebook HP Pavilion dv5 Quanta qt6 Uma Rev2a PDFgeorgevenczelAinda não há avaliações
- Aulão 4.0 Ciclos de Refrigeração AutomotivaDocumento4 páginasAulão 4.0 Ciclos de Refrigeração AutomotivaLeandro CadeuAinda não há avaliações
- Produção 2 - Lista de Funções Na Produção CinematográficaDocumento8 páginasProdução 2 - Lista de Funções Na Produção CinematográficaKarla NoronhaAinda não há avaliações
- Estudo de Caso Ed. FidalgaDocumento13 páginasEstudo de Caso Ed. Fidalgagi_rbAinda não há avaliações
- Análise de Circuitos Elétricos em CA Clever PereiraDocumento16 páginasAnálise de Circuitos Elétricos em CA Clever PereiratchepssilveiraAinda não há avaliações
- BM 3001 PTDocumento1 páginaBM 3001 PTHFAinda não há avaliações
- Centrais Térmicas A Vapor-GVDocumento137 páginasCentrais Térmicas A Vapor-GVRodolfo PalharesAinda não há avaliações
- Vygotsky e o Desenvolvimento HumanoDocumento6 páginasVygotsky e o Desenvolvimento HumanoAnderson Alfonso100% (1)
- IT - SEG.13 - Integração de Prestadores de ServiçosDocumento10 páginasIT - SEG.13 - Integração de Prestadores de ServiçosMoises MaestroAinda não há avaliações
- WAKE UP AND LIVE (TRADUÇÃO) - Bob Marley - Letras - Mus PDFDocumento2 páginasWAKE UP AND LIVE (TRADUÇÃO) - Bob Marley - Letras - Mus PDFeduardomacieldelimaAinda não há avaliações
- Estações Sedimentométricas: Professor: Roberto Caribé Aula 7Documento15 páginasEstações Sedimentométricas: Professor: Roberto Caribé Aula 7mayaraAinda não há avaliações
- Alejandro AravenaDocumento23 páginasAlejandro AravenaEliane GalloAinda não há avaliações
- Criando Bibliotecas em Dev-C++Documento6 páginasCriando Bibliotecas em Dev-C++Tonin OliveiraAinda não há avaliações
- Estudo de Barramentos Rígidos em Subestações PDFDocumento40 páginasEstudo de Barramentos Rígidos em Subestações PDFplinokioAinda não há avaliações
- Gestão de PessoasDocumento76 páginasGestão de PessoassouseuAinda não há avaliações
- Catálogo FISE 5º Edição PDFDocumento44 páginasCatálogo FISE 5º Edição PDFBaldex esquadriasAinda não há avaliações
- TT Sae 1045Documento13 páginasTT Sae 1045Giba Gilberto JuniorAinda não há avaliações
- 20141017162421416poster III Jepex - Projeto e Construcao de Mini BajaDocumento1 página20141017162421416poster III Jepex - Projeto e Construcao de Mini BajaMarcos Alfena Pozzato0% (1)
- Práticas de Auditoria-Conhecimento OrganizacionalDocumento3 páginasPráticas de Auditoria-Conhecimento OrganizacionalHélio René Lopes da RochaAinda não há avaliações