Você também pode gostar
- Guia de Sobrevivência para Blender 3DDocumento4 páginasGuia de Sobrevivência para Blender 3DvaldomiromoraisAinda não há avaliações
- 058 Frameworks GameDesignDocumento12 páginas058 Frameworks GameDesignvaldomiromoraisAinda não há avaliações
- Bombi Adventure Project On BehanceDocumento1 páginaBombi Adventure Project On BehancevaldomiromoraisAinda não há avaliações
- Criação de PersonagensDocumento77 páginasCriação de PersonagensvaldomiromoraisAinda não há avaliações
- Aplicativo Computacional para Dimensionamento de Canais e Estruturas HidráulicasDocumento110 páginasAplicativo Computacional para Dimensionamento de Canais e Estruturas HidráulicasvaldomiromoraisAinda não há avaliações
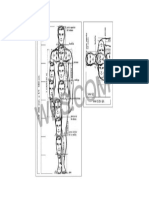
- Escala Do Corpo HumanoDocumento1 páginaEscala Do Corpo HumanovaldomiromoraisAinda não há avaliações
- Jogo de Areia - Os Arquetipos e Os Jogos de Video GameDocumento19 páginasJogo de Areia - Os Arquetipos e Os Jogos de Video GameBeto RodriguesAinda não há avaliações
- Guia Hacker - Introducao Ao HackingDocumento47 páginasGuia Hacker - Introducao Ao Hackingluiskuklinshi0% (1)
- Teclas de AtalhoDocumento11 páginasTeclas de AtalhovaldomiromoraisAinda não há avaliações
- Os 12 Princípios Fundamentais Da ANIMAÇÃODocumento17 páginasOs 12 Princípios Fundamentais Da ANIMAÇÃOvaldomiromoraisAinda não há avaliações
- Geometria ProjetivaDocumento63 páginasGeometria ProjetivalucasmorgAinda não há avaliações
- Os Primeiros Passos para A AnimaçãoDocumento15 páginasOs Primeiros Passos para A AnimaçãovaldomiromoraisAinda não há avaliações
- Sistema para Gerencia de Farmácia 2Documento53 páginasSistema para Gerencia de Farmácia 2valdomiromoraisAinda não há avaliações
- Sistema para Gerencia de FarmáciaDocumento48 páginasSistema para Gerencia de FarmáciavaldomiromoraisAinda não há avaliações
- Simon Sinek Lideres - Se.servem - Por.ultimoDocumento309 páginasSimon Sinek Lideres - Se.servem - Por.ultimoFabio Freitas88% (8)
- DbmodDocumento28 páginasDbmodvaldomiromoraisAinda não há avaliações
- Geometria ProjetivaDocumento63 páginasGeometria ProjetivavaldomiromoraisAinda não há avaliações
- GCC OpçõesDocumento20 páginasGCC OpçõesvaldomiromoraisAinda não há avaliações
- Receitas Semav PDFDocumento52 páginasReceitas Semav PDFRafaella De Aguiar CostaAinda não há avaliações
- Scalable Wireless Communications To Enrich Live Concerts in Large HallsDocumento129 páginasScalable Wireless Communications To Enrich Live Concerts in Large HallsLixo ElectronicoAinda não há avaliações
- Aws Saa-C03Documento63 páginasAws Saa-C03rodrigos130silvaAinda não há avaliações
- Lab-1 Rota Estática PDFDocumento20 páginasLab-1 Rota Estática PDFEndson SantosAinda não há avaliações
- 3º Atividade de IPSSI - Pesquisa Sobre IPDocumento21 páginas3º Atividade de IPSSI - Pesquisa Sobre IPAlice Chellton (Triad-kurihara)Ainda não há avaliações
- Roteador Cisco IOSDocumento31 páginasRoteador Cisco IOSQuiesse MalundoAinda não há avaliações
- (Tutorial) Roteamento Estático - Cisco CCNADocumento3 páginas(Tutorial) Roteamento Estático - Cisco CCNAEdilberto TelesAinda não há avaliações
- Cap4-TCP-IP Principais Caracteríticas - Funcionamento e Vulnerabilidade - RevFinal - 20200602 - 1300Documento55 páginasCap4-TCP-IP Principais Caracteríticas - Funcionamento e Vulnerabilidade - RevFinal - 20200602 - 1300Nayara Tamiris Nunes PintoAinda não há avaliações
- TCC V2Documento11 páginasTCC V2Leandro SouzaAinda não há avaliações
- Micro Center Web - (41) 3673-5879 - Mikrotik Web Proxy e Cache Full No Mikrotik RouterOS 3x e 4xDocumento9 páginasMicro Center Web - (41) 3673-5879 - Mikrotik Web Proxy e Cache Full No Mikrotik RouterOS 3x e 4xRenato Gomes Franca JuniorAinda não há avaliações
- Manual Do Usuário. AP 310 e AP 360.Documento40 páginasManual Do Usuário. AP 310 e AP 360.Rodrigo DelfinoAinda não há avaliações
- Aulão 10 Erros Comuns Com Mikrotik RouterosDocumento55 páginasAulão 10 Erros Comuns Com Mikrotik RouterosFabio Bersan RochaAinda não há avaliações
- Cálculo Endereçamento IPDocumento7 páginasCálculo Endereçamento IPJardy SoaresAinda não há avaliações
- CPD Parte3 2005 1Documento15 páginasCPD Parte3 2005 1Efefante CicaAinda não há avaliações
- 10 ManrsDocumento37 páginas10 ManrsAurélioCoutoArrudaAinda não há avaliações
- PartnerCast - Solutions Architect Associate - Ver2 - 2Documento103 páginasPartnerCast - Solutions Architect Associate - Ver2 - 2gabrielrcoutoAinda não há avaliações
- Aula 1 Computação em Nuvem Conceitos e Aspectos Gerais - SlidesDocumento8 páginasAula 1 Computação em Nuvem Conceitos e Aspectos Gerais - SlidesCarlos AlexandreAinda não há avaliações
- Algoritmos de EscalonamentoDocumento24 páginasAlgoritmos de EscalonamentoEmynence KalendaAinda não há avaliações
- Mikrotik - Aula 5-ForwardDocumento29 páginasMikrotik - Aula 5-ForwardRoberto PronetAinda não há avaliações
- Escalonamento CooperativoDocumento7 páginasEscalonamento CooperativoQueli BiancaAinda não há avaliações
- Protocolos - Trabalho - Osvaldo GeraldoDocumento7 páginasProtocolos - Trabalho - Osvaldo GeraldoOsvaldo Geraldo ManjateAinda não há avaliações
- Programação de Rede UNIX PDFDocumento879 páginasProgramação de Rede UNIX PDFdanilomatias19Ainda não há avaliações
- Resumidamente Lista de Material para Provedor de InternetDocumento11 páginasResumidamente Lista de Material para Provedor de InternetdnsantiagoAinda não há avaliações
- 134.4917.24 - DmOS 8.6.0 - Descritivo Do ProdutoDocumento25 páginas134.4917.24 - DmOS 8.6.0 - Descritivo Do ProdutoRegis Augusto CardozoAinda não há avaliações
- Erii Camada de Rede 4 2 InsticDocumento34 páginasErii Camada de Rede 4 2 InsticBruno NiangaAinda não há avaliações
- NT - ONT 423-41WAC - Configuração PPPoE Dual StackDocumento12 páginasNT - ONT 423-41WAC - Configuração PPPoE Dual StackEdnardo PedrosaAinda não há avaliações
- Thome - Mikrotik04 INSTALAÇÃODocumento6 páginasThome - Mikrotik04 INSTALAÇÃOSamuelAinda não há avaliações
- Manual - Do - Usuário - WRN 140 - Roteador Wireless N 150 Mbps - PortuguêsDocumento60 páginasManual - Do - Usuário - WRN 140 - Roteador Wireless N 150 Mbps - Portuguêsh2carlosAinda não há avaliações
- 03 LINUX Configuracao de Redes PDFDocumento9 páginas03 LINUX Configuracao de Redes PDFsantostecservAinda não há avaliações
- Cópia de Lista Top Fornecedores RevisadaDocumento67 páginasCópia de Lista Top Fornecedores RevisadabomsucessoltdaAinda não há avaliações
- Quero ser empreendedor, e agora?: Guia prático para criar sua primeira startupNo EverandQuero ser empreendedor, e agora?: Guia prático para criar sua primeira startupNota: 5 de 5 estrelas5/5 (26)
- Guia Definitivo Para Dominar o Bitcoin e as CriptomoedasNo EverandGuia Definitivo Para Dominar o Bitcoin e as CriptomoedasNota: 4 de 5 estrelas4/5 (5)
- Inteligência artificial: Como aprendizado de máquina, robótica e automação moldaram nossa sociedadeNo EverandInteligência artificial: Como aprendizado de máquina, robótica e automação moldaram nossa sociedadeNota: 5 de 5 estrelas5/5 (3)
- 37 Regras para um Negócio Online de Sucesso: Como Desistir do Seu Emprego, Mudar Para o Paraíso e Ganhar Dinheiro Enquanto DormeNo Everand37 Regras para um Negócio Online de Sucesso: Como Desistir do Seu Emprego, Mudar Para o Paraíso e Ganhar Dinheiro Enquanto DormeNota: 1.5 de 5 estrelas1.5/5 (2)
- Inteligência artificial: O guia completo para iniciantes sobre o futuro da IANo EverandInteligência artificial: O guia completo para iniciantes sobre o futuro da IANota: 5 de 5 estrelas5/5 (6)
- Consultoria Especializada e Estratégias De Trade De ForexNo EverandConsultoria Especializada e Estratégias De Trade De ForexAinda não há avaliações
- Fundamentos de Segurança da Informação: com base na ISO 27001 e na ISO 27002No EverandFundamentos de Segurança da Informação: com base na ISO 27001 e na ISO 27002Nota: 5 de 5 estrelas5/5 (8)
- Gerenciamento da rotina do trabalho do dia-a-diaNo EverandGerenciamento da rotina do trabalho do dia-a-diaNota: 5 de 5 estrelas5/5 (2)
- Blockchain Ethereum: Fundamentos de arquitetura, desenvolvimento de contratos e aplicaçõesNo EverandBlockchain Ethereum: Fundamentos de arquitetura, desenvolvimento de contratos e aplicaçõesAinda não há avaliações
- Sua Primeira Startup: O Guia de Negócios Startup, da Ideia ao LançamentoNo EverandSua Primeira Startup: O Guia de Negócios Startup, da Ideia ao LançamentoAinda não há avaliações
- Lean Game Development: Desenvolvimento enxuto de jogosNo EverandLean Game Development: Desenvolvimento enxuto de jogosAinda não há avaliações
- Introdução Às Redes De Computadores: Modelos Osi E Tcp/ipNo EverandIntrodução Às Redes De Computadores: Modelos Osi E Tcp/ipAinda não há avaliações
- HACKED: O Livro Guia Definitivo De Linux Kali E Hacking Sem Fio Com Ferramentas De Testes De Segurança E DeNo EverandHACKED: O Livro Guia Definitivo De Linux Kali E Hacking Sem Fio Com Ferramentas De Testes De Segurança E DeAinda não há avaliações