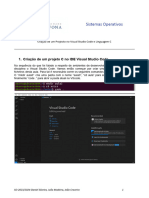
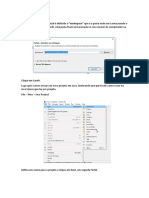
Você também pode gostar
- Análise Comparativa Das Metodologias de Desenvolvimento de Softwares Tradicionais e ÁgeisDocumento74 páginasAnálise Comparativa Das Metodologias de Desenvolvimento de Softwares Tradicionais e ÁgeisAlmir Rivas100% (1)
- Curso Progr Jogos C++Documento145 páginasCurso Progr Jogos C++Silas LimaAinda não há avaliações
- Depurando código em CDocumento14 páginasDepurando código em CAndre LuizAinda não há avaliações
- Introdução aos compiladores e estrutura básica de programas em CDocumento15 páginasIntrodução aos compiladores e estrutura básica de programas em CHeberfrancoAinda não há avaliações
- Utilizando o Dev C++ para transformar pseudocódigoDocumento21 páginasUtilizando o Dev C++ para transformar pseudocódigoAntonio Caetano VasconcelosAinda não há avaliações
- Programaçao em C - FundamentosDocumento209 páginasProgramaçao em C - FundamentosdorasevAinda não há avaliações
- Neto C++Documento27 páginasNeto C++o_picudoAinda não há avaliações
- Algoritmo e Lógica de Programação Com CodeBlocksDocumento62 páginasAlgoritmo e Lógica de Programação Com CodeBlocksnikolausAinda não há avaliações
- Debug Visual StudioDocumento12 páginasDebug Visual StudioRaffa ZanattaAinda não há avaliações
- Temp 7142765869692378166Documento3 páginasTemp 7142765869692378166felipefacundesAinda não há avaliações
- Construir Um Boot LoaderDocumento16 páginasConstruir Um Boot LoaderJosé Antonio NevesAinda não há avaliações
- Apostila de CDocumento36 páginasApostila de CHenrique Honório da Silva100% (3)
- Aula3 Projeto Eclipse Linguagem CDocumento12 páginasAula3 Projeto Eclipse Linguagem CUyi DerickAinda não há avaliações
- Programando em C Usando Linux, Uma Breve Introdução! - SempreUpdateDocumento5 páginasProgramando em C Usando Linux, Uma Breve Introdução! - SempreUpdateLuizAinda não há avaliações
- Segunda AulaDocumento50 páginasSegunda Auladiego leriamAinda não há avaliações
- Linux AulaDocumento14 páginasLinux AulavascolusofonaAinda não há avaliações
- Algoritmos e Linguagem CsharpDocumento21 páginasAlgoritmos e Linguagem CsharpRodrigo MoraesAinda não há avaliações
- Introdução à linguagem C emDocumento37 páginasIntrodução à linguagem C empdntsAinda não há avaliações
- Primeiro Programa em C Com o Dev C++Documento10 páginasPrimeiro Programa em C Com o Dev C++prettuxAinda não há avaliações
- C para Hackers IniciantesDocumento7 páginasC para Hackers Iniciantesalef1908Ainda não há avaliações
- Laboratório 1 - Programação Arduino Apde7Documento29 páginasLaboratório 1 - Programação Arduino Apde7Daniel Juliano de AndradeAinda não há avaliações
- Aulas C#Documento15 páginasAulas C#GilsonJuniorCeAinda não há avaliações
- (LAB) 01 ConceitosBasicosDocumento24 páginas(LAB) 01 ConceitosBasicosabner.violinAinda não há avaliações
- Programação I - Iº ModuloDocumento15 páginasProgramação I - Iº Modulorenatogomessantos15Ainda não há avaliações
- Tutorial de DebugDocumento4 páginasTutorial de DebugFranciele MoreiraAinda não há avaliações
- Introdução à Programação em CDocumento7 páginasIntrodução à Programação em CEduardo AugustoAinda não há avaliações
- Programação para ArduinoDocumento19 páginasProgramação para ArduinoJorge BrandãoAinda não há avaliações
- Advanced PDF Tools v2.0Documento7 páginasAdvanced PDF Tools v2.0rumbleh+scribdAinda não há avaliações
- Allegro para IniciantesDocumento24 páginasAllegro para IniciantesLeandro FerreiraAinda não há avaliações
- Introdução à programação lógica em escada com LDmicroDocumento22 páginasIntrodução à programação lógica em escada com LDmicrorcimplastAinda não há avaliações
- Tutorial Batch CompletoDocumento50 páginasTutorial Batch Completoharrison_scribdAinda não há avaliações
- Linguagem de Programação C++Documento98 páginasLinguagem de Programação C++agashmidtgmailcom100% (1)
- Programação básica em BatchDocumento21 páginasProgramação básica em BatchDaniel SouzaAinda não há avaliações
- Allegro para IniciantesDocumento22 páginasAllegro para IniciantesShadowAinda não há avaliações
- Aula02 UtilizandoCodeBlocksDocumento21 páginasAula02 UtilizandoCodeBlocksGabriel MathiasAinda não há avaliações
- CES10 Cap 2-cDocumento44 páginasCES10 Cap 2-c4sd1l9vwbAinda não há avaliações
- Aula 05 LógicaDocumento35 páginasAula 05 LógicaEconomia Unespar 2018AAinda não há avaliações
- Dev C++ PrimeiroDocumento20 páginasDev C++ Primeirokdin1Ainda não há avaliações
- Assembly Program DebuggingDocumento12 páginasAssembly Program DebuggingRenê PaivaAinda não há avaliações
- Apostila C# Parte 1Documento64 páginasApostila C# Parte 1João Luis Chagas SanchesAinda não há avaliações
- Hello Nim - Introdução à linguagemDocumento41 páginasHello Nim - Introdução à linguagemAlan CalazansAinda não há avaliações
- Aula 05Documento33 páginasAula 05Yuri MoraesAinda não há avaliações
- Programação de Computadores I Apostila de CDocumento37 páginasProgramação de Computadores I Apostila de CAldair FranciscoAinda não há avaliações
- Aula 1 de Introducao A Linguagem CDocumento28 páginasAula 1 de Introducao A Linguagem CFabioAinda não há avaliações
- Apostila C básicaDocumento6 páginasApostila C básicaRenan AlmeidaAinda não há avaliações
- Processo de criação de programas assemblyDocumento14 páginasProcesso de criação de programas assemblynikinha2011Ainda não há avaliações
- Tutorial - Allegro para IniciantesDocumento26 páginasTutorial - Allegro para IniciantesmikekunAinda não há avaliações
- Arduino - Conceitos BasicosDocumento48 páginasArduino - Conceitos BasicosThiago AdavidAinda não há avaliações
- Introdução À Linguagem C PDFDocumento33 páginasIntrodução À Linguagem C PDFAfrânio JuniorAinda não há avaliações
- Apostila Python básicoDocumento12 páginasApostila Python básicoadrianoduarte_bioAinda não há avaliações
- Programação em C para iniciantesDocumento22 páginasProgramação em C para iniciantesPedro HenriqueAinda não há avaliações
- Fundamentos Programação CDocumento89 páginasFundamentos Programação CJuliana Ramires Y GarciaAinda não há avaliações
- Aprenda programação com VisualGDocumento34 páginasAprenda programação com VisualGNathan MendozaAinda não há avaliações
- EliseuDocumento8 páginasEliseuKD EliseuAinda não há avaliações
- Aula2-Codeblocks Anderson Moulais Parte 3Documento31 páginasAula2-Codeblocks Anderson Moulais Parte 3AndersonAinda não há avaliações
- Capitulo 10 - SubprogramasDocumento45 páginasCapitulo 10 - Subprogramasmargaridasiquila305Ainda não há avaliações
- Algoritmos CCDocumento17 páginasAlgoritmos CCzedanevesAinda não há avaliações
- Aula02-UtilizandoCodeBlocksDocumento21 páginasAula02-UtilizandoCodeBlocksWilliam Roberto MalvezziAinda não há avaliações
- C# Windows Forms Programação GUIDocumento10 páginasC# Windows Forms Programação GUISusana SantosAinda não há avaliações
- Anotações Aula 5Documento31 páginasAnotações Aula 5Eduardo AlfaiatariaAinda não há avaliações
- Anotações Aula 6Documento18 páginasAnotações Aula 6Eduardo AlfaiatariaAinda não há avaliações
- SP Taubate Pref Edital3 Ed 1947pdf 58174Documento30 páginasSP Taubate Pref Edital3 Ed 1947pdf 58174Eduardo AlfaiatariaAinda não há avaliações
- Técnico em Desenvolvimento de Sistemas OnlineDocumento14 páginasTécnico em Desenvolvimento de Sistemas OnlineTatiana DuarteAinda não há avaliações
- Passo A Passo EclipseDocumento4 páginasPasso A Passo EclipseEduardo AlfaiatariaAinda não há avaliações
- Aula Atividade AlunoDocumento5 páginasAula Atividade AlunoAldo Dos SantosAinda não há avaliações
- Manual Completo Do Debian GNU - LinuxDocumento628 páginasManual Completo Do Debian GNU - Linuxckaua5636Ainda não há avaliações
- Sistemas Gereciadores de Banco de DadosDocumento109 páginasSistemas Gereciadores de Banco de Dadosmarcos100% (1)
- TOTVS Microsiga Protheus OMSDocumento13 páginasTOTVS Microsiga Protheus OMSWilliam NaujorksAinda não há avaliações
- IBMR DL - Programação Orientada A ObjetosDocumento35 páginasIBMR DL - Programação Orientada A ObjetosCarolyne OliveiraAinda não há avaliações
- FNRH - Ministério Do TurismoDocumento16 páginasFNRH - Ministério Do TurismoFausto HenriqueAinda não há avaliações
- Revista Front-End Magazine - Ed 02Documento36 páginasRevista Front-End Magazine - Ed 02Wallace TolentinoAinda não há avaliações
- MONOGRAFIA - Gerenciamento e Monitoração de Redes de Computadores Utilizando-Se ZabbixDocumento68 páginasMONOGRAFIA - Gerenciamento e Monitoração de Redes de Computadores Utilizando-Se ZabbixShamirAinda não há avaliações
- ContinueDocumento3 páginasContinueConectadosAinda não há avaliações
- Hospedagem Ruby On Rails - Suporte HostGatorDocumento9 páginasHospedagem Ruby On Rails - Suporte HostGatorRogério OliveiraAinda não há avaliações
- Documentação SUKEattDocumento13 páginasDocumentação SUKEattBruno MVAinda não há avaliações
- Curso de Pydjango - Python e DjangoDocumento205 páginasCurso de Pydjango - Python e Djangowereworf100% (2)
- Desenhar Uma Caixa Retangular html5Documento9 páginasDesenhar Uma Caixa Retangular html5EvertonBarrosAinda não há avaliações
- Capitulo 07Documento19 páginasCapitulo 07Jessica MouraAinda não há avaliações
- Menu e métodos em exercícios práticos de LP2Documento2 páginasMenu e métodos em exercícios práticos de LP2Gabriel StróbAinda não há avaliações
- Sistema Locadora FilmesDocumento22 páginasSistema Locadora FilmesTárcio SoaresAinda não há avaliações
- Tópicos Especiais de Programação Unip Unid - 1Documento55 páginasTópicos Especiais de Programação Unip Unid - 1MESTREEM AndroidAinda não há avaliações
- Windows Explorer Não Atualiza Pastas Ao Criar, Deletar e RenomearDocumento2 páginasWindows Explorer Não Atualiza Pastas Ao Criar, Deletar e RenomearDiegoLúcio360Ainda não há avaliações
- Debian FinalDocumento65 páginasDebian FinalKauan Lucas ToldoAinda não há avaliações
- AvaliaçãoDocumento5 páginasAvaliaçãoHigor MnAinda não há avaliações
- Programação Orientada À ObjetosDocumento16 páginasProgramação Orientada À ObjetosPark PandaAinda não há avaliações
- 12 - Aula Pratica - Pentest - 1Documento5 páginas12 - Aula Pratica - Pentest - 1jean paulAinda não há avaliações
- Avaliando o aprendizado - teste seus conhecimentos sobre Engenharia de SoftwareDocumento1 páginaAvaliando o aprendizado - teste seus conhecimentos sobre Engenharia de SoftwareMarlonAinda não há avaliações
- Estruturas de DecisaoDocumento19 páginasEstruturas de DecisaoEverton OliveiraAinda não há avaliações
- Otavio Larrosa CurriculoDocumento3 páginasOtavio Larrosa CurriculoOtávio LarrosaAinda não há avaliações
- Metodos de Desenvolvimento de Softaware - CatalysisDocumento32 páginasMetodos de Desenvolvimento de Softaware - CatalysisCaio TeixeiraAinda não há avaliações
- Interface Gráfica MatlabDocumento51 páginasInterface Gráfica Matlabrodrigoneto08Ainda não há avaliações
- Manual Kace 901-963Documento63 páginasManual Kace 901-963Cesar LopesAinda não há avaliações