Você também pode gostar
- Analisador Léxico - Palavras ReservadasDocumento35 páginasAnalisador Léxico - Palavras Reservadastilman_kolks382Ainda não há avaliações
- O Léxico de Anátema e Vulcões de Lama de Camilo Castelo BrancoNo EverandO Léxico de Anátema e Vulcões de Lama de Camilo Castelo BrancoAinda não há avaliações
- 02 Analise Lexica 2Documento34 páginas02 Analise Lexica 2Raimundo BarretoAinda não há avaliações
- Programação e Compiladores - Conceitos Complementares - Outubro-2023Documento19 páginasProgramação e Compiladores - Conceitos Complementares - Outubro-2023Carlos CastroAinda não há avaliações
- Análise Léxica emDocumento45 páginasAnálise Léxica emJose Jordao ConstantinoAinda não há avaliações
- Er AfdDocumento6 páginasEr Afdcarlinigt1080Ainda não há avaliações
- AULA 3 4 5 Aula 345 COMPILADORES-LEXICO2008Documento17 páginasAULA 3 4 5 Aula 345 COMPILADORES-LEXICO2008Gilson Torres DiasAinda não há avaliações
- Conceitos básicos de linguagens formaisDocumento46 páginasConceitos básicos de linguagens formaisCarlos LiúAinda não há avaliações
- Expressão regular em ou menosDocumento10 páginasExpressão regular em ou menosDixonMarinhoAinda não há avaliações
- Expressão regular em ou menosDocumento10 páginasExpressão regular em ou menosDixonMarinhoAinda não há avaliações
- Lex YaccDocumento8 páginasLex YaccRegisAinda não há avaliações
- Aula01 - Expressoes Regulares - Prof. Gustavo AdaptadoDocumento24 páginasAula01 - Expressoes Regulares - Prof. Gustavo AdaptadoRogê Batista GonçalvesAinda não há avaliações
- Análise Léxica com JFlexDocumento19 páginasAnálise Léxica com JFlexnenoAinda não há avaliações
- Aula 3Documento33 páginasAula 3Jigani GomesAinda não há avaliações
- Teoria Dos Compiladores - 2Documento10 páginasTeoria Dos Compiladores - 2santosheltonAinda não há avaliações
- Análise Léxica emDocumento25 páginasAnálise Léxica emCarlos Henrique HenriqueAinda não há avaliações
- Tipos de dados em Pascal: ordinais, cadeias e reaisDocumento7 páginasTipos de dados em Pascal: ordinais, cadeias e reaisdinsouza1Ainda não há avaliações
- Trabalho AllanBontempo 202002709316Documento4 páginasTrabalho AllanBontempo 202002709316Allan BontempoAinda não há avaliações
- Processo de Criaçao de CompiladorDocumento8 páginasProcesso de Criaçao de CompiladorVanerica AlvesAinda não há avaliações
- Tipos de dados em Pascal: ordinais, strings e reaisDocumento6 páginasTipos de dados em Pascal: ordinais, strings e reaisrmbelloniAinda não há avaliações
- Express Es Regulares em PHP 1Documento26 páginasExpress Es Regulares em PHP 1Marci JorgeAinda não há avaliações
- Slides LogicaDocumento1.033 páginasSlides LogicamarigrunAinda não há avaliações
- Teoria AutômatosDocumento19 páginasTeoria AutômatosLênio SandroAinda não há avaliações
- Programação-e-Compiladores-ANALISADORES-SINTÁTICOS-ASCENDENTES-DESCENDENTES-Outubro-2023 - 240120 - 153946 - CópiaDocumento13 páginasProgramação-e-Compiladores-ANALISADORES-SINTÁTICOS-ASCENDENTES-DESCENDENTES-Outubro-2023 - 240120 - 153946 - CópiaevaristotheunstoppableAinda não há avaliações
- 6 Parte04Documento56 páginas6 Parte04MATHEUS LÁZAROAinda não há avaliações
- COMPILADORES: ANÁLISE LÉXICA E RECONHECIMENTO DE TOKENSDocumento14 páginasCOMPILADORES: ANÁLISE LÉXICA E RECONHECIMENTO DE TOKENSVinicius Gomes Santa AnnaAinda não há avaliações
- Apostila de Linguagens Formais e Automatos PDFDocumento53 páginasApostila de Linguagens Formais e Automatos PDFsandrobarros25apAinda não há avaliações
- 03 LexicoDocumento22 páginas03 LexicovlademirjosAinda não há avaliações
- Apostila de Linguagens Formais e AutômatosDocumento53 páginasApostila de Linguagens Formais e AutômatosFernando MayumiAinda não há avaliações
- Aula 03Documento11 páginasAula 03Caio Henrique Noronha JuniorAinda não há avaliações
- Autômatos e linguagens formaisDocumento3 páginasAutômatos e linguagens formaisFelipe BenevidesAinda não há avaliações
- Elementos SintáticosDocumento4 páginasElementos SintáticosJean AchilleAinda não há avaliações
- 03 - Linguagens e GramaticasDocumento63 páginas03 - Linguagens e Gramaticassebastiao007Ainda não há avaliações
- av1-LFAC: Elementos Da Matemática DiscretaDocumento6 páginasav1-LFAC: Elementos Da Matemática DiscretaheloisaAinda não há avaliações
- Linguagens de Programação e Análise LéxicaDocumento38 páginasLinguagens de Programação e Análise LéxicaHorácio BotaAinda não há avaliações
- Linguagens Recursivamente Enumeráveis e Sensíveis ao ContextoDocumento27 páginasLinguagens Recursivamente Enumeráveis e Sensíveis ao Contextosebastiao007Ainda não há avaliações
- Expressões Regulares para Programação de ScriptsDocumento16 páginasExpressões Regulares para Programação de ScriptsAdoniram JudsonAinda não há avaliações
- Análisador LéxicoDocumento21 páginasAnálisador LéxicoArnaldo Roberto J VicenteAinda não há avaliações
- Cadeias de CaracteresDocumento8 páginasCadeias de CaracteresAurélio GabbanaAinda não há avaliações
- Análise Léxica de Compiladores: Funcionamento e TemasDocumento16 páginasAnálise Léxica de Compiladores: Funcionamento e TemasrockrochaAinda não há avaliações
- Lpo Book 2022Documento148 páginasLpo Book 2022Ricardo FernandesAinda não há avaliações
- Teoria Da Computacao LFA Aula04Documento24 páginasTeoria Da Computacao LFA Aula04Jullya CastroAinda não há avaliações
- Construção de CompiladoresDocumento109 páginasConstrução de Compiladoreskill78945612Ainda não há avaliações
- Desenvolvimento de analisador léxico com GALSDocumento16 páginasDesenvolvimento de analisador léxico com GALSFlavio RodriguesAinda não há avaliações
- Teoria da Computação: Linguagens Formais e AutômatosDocumento24 páginasTeoria da Computação: Linguagens Formais e AutômatosjolaioAinda não há avaliações
- 01 - Lógica Sentencial e de Primeira Ordem e Enumeração Por RecursoDocumento8 páginas01 - Lógica Sentencial e de Primeira Ordem e Enumeração Por RecursoMicilda MachadoAinda não há avaliações
- UNIFACS - CPL.Capitulo 01 - Linguagens Formais e AutômatosDocumento23 páginasUNIFACS - CPL.Capitulo 01 - Linguagens Formais e AutômatosOtacilio PereiraAinda não há avaliações
- 03 AnáliseSintatica1 2023Documento2 páginas03 AnáliseSintatica1 2023Lucas MartinsAinda não há avaliações
- Lista Ii - CompiladoresDocumento3 páginasLista Ii - CompiladoresGardênia Oliveira0% (2)
- ACFrOgCNuWQRGKhw1PK0w-7oRvtcAGXvabhcOnGxttxQuilLAYunQRM04uIrDFVZMS Og26dSUtRi0T0zkOE i9 VyW XEIw5zDG69v1i4mGLYdXcPb3FfR-RTYrJvkYTputc2en2bkx3Bn240WHDocumento17 páginasACFrOgCNuWQRGKhw1PK0w-7oRvtcAGXvabhcOnGxttxQuilLAYunQRM04uIrDFVZMS Og26dSUtRi0T0zkOE i9 VyW XEIw5zDG69v1i4mGLYdXcPb3FfR-RTYrJvkYTputc2en2bkx3Bn240WHRafael Antônio AraújoAinda não há avaliações
- 05gramaticas 4Documento32 páginas05gramaticas 4DjScratch OmOnStRoAinda não há avaliações
- Slides de Aula - Unidade IDocumento43 páginasSlides de Aula - Unidade IAntonio Carlos Da SilvaAinda não há avaliações
- 07 ErDocumento9 páginas07 Erfernando25ribeirogtAinda não há avaliações
- Análise LéxicaDocumento1 páginaAnálise LéxicaCarlos Ramon MoreiraAinda não há avaliações
- Aula 2Documento11 páginasAula 2Pedro CarvalhoAinda não há avaliações
- Análise LéxicaDocumento24 páginasAnálise LéxicahigorpnovoAinda não há avaliações
- GalsDocumento17 páginasGalsmasterbsbAinda não há avaliações
- Conversão de AFN em AFDDocumento8 páginasConversão de AFN em AFDPascual Figueroa0% (1)
- Lista de Exercícios 12 de CompiladoresDocumento2 páginasLista de Exercícios 12 de CompiladoresArtur CremonezAinda não há avaliações
- Lista de Exercícios 13 de CompiladoresDocumento2 páginasLista de Exercícios 13 de CompiladoresArtur CremonezAinda não há avaliações
- Lista 08Documento3 páginasLista 08Artur CremonezAinda não há avaliações
- Compiladores - Aula 04Documento74 páginasCompiladores - Aula 04Artur CremonezAinda não há avaliações
- Compiladores - Aula 05Documento10 páginasCompiladores - Aula 05Artur CremonezAinda não há avaliações
- Compiladores - Aula 03Documento27 páginasCompiladores - Aula 03Artur CremonezAinda não há avaliações
- Programação Concorrente JavaDocumento40 páginasProgramação Concorrente JavaMariana Melo CameloAinda não há avaliações
- Assistente Desenvolvimento Sistemas Lógica ProgramaçãoDocumento21 páginasAssistente Desenvolvimento Sistemas Lógica ProgramaçãoMayara SantosAinda não há avaliações
- Material para Aulas de Programação Estruturfada de Computadores 2022.4Documento33 páginasMaterial para Aulas de Programação Estruturfada de Computadores 2022.4Thiago FariasAinda não há avaliações
- Aula 5 - Mapas de KarnaughDocumento38 páginasAula 5 - Mapas de KarnaughLessany NassiffAinda não há avaliações
- Respostas da lista 0 de MAT2453 - POLI-2014Documento2 páginasRespostas da lista 0 de MAT2453 - POLI-2014Lucas LopesAinda não há avaliações
- Exercicios de Switch CaseDocumento4 páginasExercicios de Switch CaseHugo santos magalhãesAinda não há avaliações
- Lógica dos quantificadores e conjuntos numéricosDocumento52 páginasLógica dos quantificadores e conjuntos numéricosEmersonAinda não há avaliações
- Ficha de Trabalho Nº 3 CorretaDocumento8 páginasFicha de Trabalho Nº 3 CorretasadoveiroAinda não há avaliações
- Módulo IDocumento28 páginasMódulo IAlan SouzaAinda não há avaliações
- Sistema: HexadecimalDocumento10 páginasSistema: HexadecimalClara GonçalvesAinda não há avaliações
- CriacaoDeAplicacoesESistemas - Super Live 2Documento18 páginasCriacaoDeAplicacoesESistemas - Super Live 2Giovanna JavarottiAinda não há avaliações
- Gabarito Linguagem de Programação II 26105.PDF (1) - Algoritmos e Linguagem de Programação IIDocumento7 páginasGabarito Linguagem de Programação II 26105.PDF (1) - Algoritmos e Linguagem de Programação IIks informaticaAinda não há avaliações
- Sistema de Numeracao Decimal 4º e 5º ANODocumento1 páginaSistema de Numeracao Decimal 4º e 5º ANOEva Alves85% (27)
- Expressões NuméricasDocumento2 páginasExpressões NuméricasAna Patricia SantosAinda não há avaliações
- C++: Uma introdução à linguagem de programaçãoDocumento17 páginasC++: Uma introdução à linguagem de programaçãoMilton Lau EmiloyAinda não há avaliações
- Mapa de Karnaugh 5 variáveisDocumento15 páginasMapa de Karnaugh 5 variáveisAldair GonçalvesAinda não há avaliações
- Apostila de WindowsDocumento106 páginasApostila de WindowsJojoAinda não há avaliações
- Armazenamento em Memória SecundáriaDocumento12 páginasArmazenamento em Memória SecundáriaLetícia LeonelAinda não há avaliações
- Questões Linguagem ProgramaçãoDocumento3 páginasQuestões Linguagem ProgramaçãoLindomar FabricioAinda não há avaliações
- Trilha Das Operações Com MonômiosDocumento2 páginasTrilha Das Operações Com MonômiosVanessa Machado100% (5)
- 2 Aval DigitaisDocumento1 página2 Aval DigitaisDanAinda não há avaliações
- Termos de uma fração quiz matemáticoDocumento5 páginasTermos de uma fração quiz matemáticopedro afonsoAinda não há avaliações
- Função Exponencial A9 Aula 1Documento1 páginaFunção Exponencial A9 Aula 1Paula VivasAinda não há avaliações
- Codificação Aritmética x HuffmanDocumento3 páginasCodificação Aritmética x HuffmanGabriel OzórioAinda não há avaliações
- Variáveis e Tipos de Dados PLCDocumento13 páginasVariáveis e Tipos de Dados PLCnatanaelAinda não há avaliações
- Segunda AulaDocumento50 páginasSegunda Auladiego leriamAinda não há avaliações
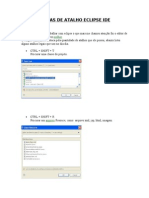
- Teclas de Atalho Eclipse IdeDocumento6 páginasTeclas de Atalho Eclipse IdeCarlos CoelhoAinda não há avaliações
- Planilha de Inspeção de Equipamento: PERFURATRIZ #Documento1 páginaPlanilha de Inspeção de Equipamento: PERFURATRIZ #FRANCISCO NETOAinda não há avaliações
- Grelha de Avaliação de Trabalhos EscritosDocumento4 páginasGrelha de Avaliação de Trabalhos Escritoslidiamendes100% (32)
- Apostila Lógica de Programação - Scratch - Python - Semana 2Documento3 páginasApostila Lógica de Programação - Scratch - Python - Semana 2Jocimeire MacielAinda não há avaliações
- Eletricista Residencial E PredialNo EverandEletricista Residencial E PredialNota: 3 de 5 estrelas3/5 (1)
- Inteligência artificial: O guia completo para iniciantes sobre o futuro da IANo EverandInteligência artificial: O guia completo para iniciantes sobre o futuro da IANota: 5 de 5 estrelas5/5 (6)
- Motores automotivos: evolução, manutenção e tendênciasNo EverandMotores automotivos: evolução, manutenção e tendênciasNota: 5 de 5 estrelas5/5 (1)
- Gerenciamento da rotina do trabalho do dia-a-diaNo EverandGerenciamento da rotina do trabalho do dia-a-diaNota: 5 de 5 estrelas5/5 (2)
- Inteligência artificial: Como aprendizado de máquina, robótica e automação moldaram nossa sociedadeNo EverandInteligência artificial: Como aprendizado de máquina, robótica e automação moldaram nossa sociedadeNota: 5 de 5 estrelas5/5 (3)
- Introdução a Data Science: Algoritmos de Machine Learning e métodos de análiseNo EverandIntrodução a Data Science: Algoritmos de Machine Learning e métodos de análiseAinda não há avaliações
- Quero ser empreendedor, e agora?: Guia prático para criar sua primeira startupNo EverandQuero ser empreendedor, e agora?: Guia prático para criar sua primeira startupNota: 5 de 5 estrelas5/5 (25)
- Dimensionamento e Planejamento de Máquinas e Implementos AgrícolasNo EverandDimensionamento e Planejamento de Máquinas e Implementos AgrícolasNota: 1 de 5 estrelas1/5 (2)
- Análise técnica de uma forma simples: Como construir e interpretar gráficos de análise técnica para melhorar a sua actividade comercial onlineNo EverandAnálise técnica de uma forma simples: Como construir e interpretar gráficos de análise técnica para melhorar a sua actividade comercial onlineNota: 4 de 5 estrelas4/5 (4)
- O Que Todo Atirador Precisa Saber Sobre BalísticaNo EverandO Que Todo Atirador Precisa Saber Sobre BalísticaNota: 5 de 5 estrelas5/5 (1)
- Liberdade digital: O mais completo manual para empreender na internet e ter resultadosNo EverandLiberdade digital: O mais completo manual para empreender na internet e ter resultadosNota: 5 de 5 estrelas5/5 (10)
- Manual Do Proprietário - Para Operação, Uso E Manutenção Das Edificações Residenciais.No EverandManual Do Proprietário - Para Operação, Uso E Manutenção Das Edificações Residenciais.Nota: 5 de 5 estrelas5/5 (1)
- Inteligência artificial: Análise de dados e inovação para iniciantesNo EverandInteligência artificial: Análise de dados e inovação para iniciantesAinda não há avaliações
- Python e mercado financeiro: Programação para estudantes, investidores e analistasNo EverandPython e mercado financeiro: Programação para estudantes, investidores e analistasNota: 5 de 5 estrelas5/5 (3)
- Gramática fácil: Para falar e escrever bemNo EverandGramática fácil: Para falar e escrever bemNota: 4 de 5 estrelas4/5 (18)
- Estruturas de Dados: Domine as práticas essenciais em C, Java, C#, Python e JavaScriptNo EverandEstruturas de Dados: Domine as práticas essenciais em C, Java, C#, Python e JavaScriptAinda não há avaliações
- Email marketing eficaz: Como conquistar e fidelizar clientes com uma newsletterNo EverandEmail marketing eficaz: Como conquistar e fidelizar clientes com uma newsletterNota: 5 de 5 estrelas5/5 (1)
- Programação Didática com Linguagem CNo EverandProgramação Didática com Linguagem CNota: 3.5 de 5 estrelas3.5/5 (2)