Você também pode gostar
- Planejamento ExperimentalDocumento61 páginasPlanejamento ExperimentalMagno Felipe TeixeiraAinda não há avaliações
- Resumo Calculo 1 e 2Documento5 páginasResumo Calculo 1 e 2Andre CostaAinda não há avaliações
- Exame - Estatistica FelizardaDocumento17 páginasExame - Estatistica FelizardaRafael100% (6)
- Exame Normal de Estatistica II Cont. & Auditoria 2anoDocumento2 páginasExame Normal de Estatistica II Cont. & Auditoria 2anoJoao Raimundo Feniasse MequeAinda não há avaliações
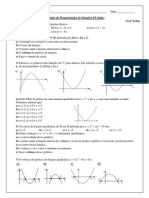
- Funções Afim e QuadráticasDocumento2 páginasFunções Afim e QuadráticasTalita MazzaliAinda não há avaliações
- Curso de CalculadoraDocumento24 páginasCurso de CalculadoraFabio GomesAinda não há avaliações
- IntensivoDocumento186 páginasIntensivoMurillo Pyaia100% (1)
- Distribuições de Probabilidade PDFDocumento8 páginasDistribuições de Probabilidade PDFAna Maria SouzaAinda não há avaliações
- Ava 2 e 3Documento20 páginasAva 2 e 3MAIQ ALBERTO MONTEIRO COSTAAinda não há avaliações
- EaD 2017 02 NBR 14280 Cadastro de AcidentesDocumento75 páginasEaD 2017 02 NBR 14280 Cadastro de AcidentesÍkaro Kauã Lopes AragãoAinda não há avaliações
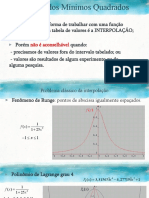
- ExRes - Interp e MMQDocumento11 páginasExRes - Interp e MMQasdasdAinda não há avaliações
- Aula ScilabDocumento74 páginasAula Scilabadriasiq3068Ainda não há avaliações
- Aula7 KrigDocumento17 páginasAula7 KrigManuel Castro RibeiroAinda não há avaliações
- AnlisecomputacionalMatlab Scilabc0 20220408081012Documento16 páginasAnlisecomputacionalMatlab Scilabc0 20220408081012Rafael PoleziAinda não há avaliações
- Mathcad TutorialDocumento63 páginasMathcad TutorialEderley Soares MarquesAinda não há avaliações
- Exercício - 8.ipynb - ColaboratoryDocumento5 páginasExercício - 8.ipynb - ColaboratorycunhacamilaAinda não há avaliações
- Unidade II - Aula 10. Inferencia Estatística (Krigagem Indicativa)Documento54 páginasUnidade II - Aula 10. Inferencia Estatística (Krigagem Indicativa)Lorena TrindadeAinda não há avaliações
- Python Data Science Handbook - Jake VanderPlas (254-354)Documento101 páginasPython Data Science Handbook - Jake VanderPlas (254-354)eduardo mendesAinda não há avaliações
- Apostila MCAEDocumento78 páginasApostila MCAEDébora VitóriaAinda não há avaliações
- Curso Matlab 2023 - Cap 7Documento4 páginasCurso Matlab 2023 - Cap 7sergiopenedoAinda não há avaliações
- Licao 1Documento9 páginasLicao 1João FernandesAinda não há avaliações
- Homework 4...Documento8 páginasHomework 4...maxAinda não há avaliações
- 04 Ganancioso DinamicaDocumento54 páginas04 Ganancioso DinamicaROGINALDO FERNANDO DOS REISAinda não há avaliações
- Resolução Lista 2Documento6 páginasResolução Lista 2Rose NascimentoAinda não há avaliações
- ExameNormal MNP2015 MatrizDocumento2 páginasExameNormal MNP2015 MatrizBeneditoAinda não há avaliações
- Aula I - Erros Nas Aproximações NuméricasDocumento7 páginasAula I - Erros Nas Aproximações NuméricasIvan Renner GamaAinda não há avaliações
- Lista 1 - Cálculo I - Prof. Rodrigo SantosDocumento13 páginasLista 1 - Cálculo I - Prof. Rodrigo SantosRodrigo SantosAinda não há avaliações
- ListaNumerico Python 12 08Documento4 páginasListaNumerico Python 12 08MARCELO DOS SANTOSAinda não há avaliações
- Folhas - de - Exercicios MAT LABDocumento36 páginasFolhas - de - Exercicios MAT LABMiguel Pereira da CostaAinda não há avaliações
- Lista de Exercícios - Circuitos CombinacionaisDocumento2 páginasLista de Exercícios - Circuitos CombinacionaisCarlinhosAinda não há avaliações
- Limite e ContinuidadeDocumento19 páginasLimite e ContinuidadeHeitor Claro da SilvaAinda não há avaliações
- FT 02 Trigonometria EN TI Gráficos Calculadora ResoluçãoDocumento23 páginasFT 02 Trigonometria EN TI Gráficos Calculadora ResoluçãoJosé PedroAinda não há avaliações
- Curvas de Nivel MathematicaDocumento4 páginasCurvas de Nivel MathematicaslacklucasAinda não há avaliações
- Exercícios Cap 04Documento2 páginasExercícios Cap 04Luccas UnipAinda não há avaliações
- Pex 16 - SPM 12º 2021Documento10 páginasPex 16 - SPM 12º 2021Inês DiasAinda não há avaliações
- Aula 1 ScilabDocumento6 páginasAula 1 ScilabHenry FerreiraAinda não há avaliações
- Metodos QuantitativosDocumento34 páginasMetodos QuantitativosCaioBenattiAinda não há avaliações
- PSI-3431 - Processamento Estat Istico de Sinais Lista de Exerc Icios 1Documento3 páginasPSI-3431 - Processamento Estat Istico de Sinais Lista de Exerc Icios 1IgorCostaCorreiaAinda não há avaliações
- Aula MatLabDocumento33 páginasAula MatLabAlisson DiegoAinda não há avaliações
- IntegraçãoDocumento6 páginasIntegraçãolemaun5712Ainda não há avaliações
- 06 SMT Solver z3Documento28 páginas06 SMT Solver z3gemilson1Ainda não há avaliações
- Exercíciosobjetivos-Matemática-Exercícios Sobre Função Quadrática e Inequação Do 2° Grau-24-06-2021Documento8 páginasExercíciosobjetivos-Matemática-Exercícios Sobre Função Quadrática e Inequação Do 2° Grau-24-06-2021Ana Julya LopesAinda não há avaliações
- IPB Teste1 20 21Documento3 páginasIPB Teste1 20 21estudantematildeAinda não há avaliações
- Calcnum PyDocumento14 páginasCalcnum PyGilberto MourãoAinda não há avaliações
- Experimento 5Documento3 páginasExperimento 5AventrilhandoAinda não há avaliações
- Atividade 5 FuncaoDocumento6 páginasAtividade 5 FuncaoVictor GonçalvesAinda não há avaliações
- Lista de Exercicios CepDocumento30 páginasLista de Exercicios CepWesley WaltersAinda não há avaliações
- Lista Calculo NumericoDocumento4 páginasLista Calculo NumericoAnonymous 1QsclBAinda não há avaliações
- ComplexidadeDocumento42 páginasComplexidadeTiago VieiraAinda não há avaliações
- Apostila Calc Numerico 2008Documento114 páginasApostila Calc Numerico 2008victorusa88Ainda não há avaliações
- MAT229 Slides3Documento5 páginasMAT229 Slides3SufersAinda não há avaliações
- Lista M4Documento14 páginasLista M4stevebrancobaleiaAinda não há avaliações
- P1 SolucaoDocumento16 páginasP1 SolucaoLuizAinda não há avaliações
- Não É AconselhávelDocumento33 páginasNão É AconselhávelMaluAinda não há avaliações
- Ado 7 - Distribuição Binomial e NormalDocumento4 páginasAdo 7 - Distribuição Binomial e NormalNox Passei DiretoAinda não há avaliações
- Matlab - Comandos Basicos e SimulaçõesDocumento16 páginasMatlab - Comandos Basicos e SimulaçõesDavid de Almeida FiorilloAinda não há avaliações
- 4 BCC740 CPSsDocumento3 páginas4 BCC740 CPSsxawibiyAinda não há avaliações
- 15 Derivadas Funcoes TrigonométricasDocumento3 páginas15 Derivadas Funcoes Trigonométricasmarta_oliveira_pvAinda não há avaliações
- PDS Lab06 RoteiroDocumento11 páginasPDS Lab06 RoteiromthslibrasAinda não há avaliações
- Aula03 - OpenCVDocumento8 páginasAula03 - OpenCVHenrique FerreiraAinda não há avaliações
- Apostila - de - Cálculo - II - Prof. ReginaldoDocumento84 páginasApostila - de - Cálculo - II - Prof. ReginaldoMaria DuarteAinda não há avaliações
- Exercícios de Revisão - FUNÇÃO DO 1o. GRAU .Documento5 páginasExercícios de Revisão - FUNÇÃO DO 1o. GRAU .Aline Sant'AnaAinda não há avaliações
- MILLER - A Era Do Homem Sem QualidadesDocumento21 páginasMILLER - A Era Do Homem Sem QualidadesRicardo MégreAinda não há avaliações
- BIOESTATISTICA E EPIDEMIOLOGIA Atividade 2Documento3 páginasBIOESTATISTICA E EPIDEMIOLOGIA Atividade 2Caroline AndradeAinda não há avaliações
- Teste de Hipoteses - ConceitosDocumento10 páginasTeste de Hipoteses - ConceitosRafael Rangel MachadoAinda não há avaliações
- Pesquisa Lagarto 12-11Documento2 páginasPesquisa Lagarto 12-11NE NotíciasAinda não há avaliações
- Lista de Exercícios Testes de HipótesesDocumento1 páginaLista de Exercícios Testes de HipótesesGuilhermeVarellaAinda não há avaliações
- BNCC - Ensino Fundamental MatematicaDocumento8 páginasBNCC - Ensino Fundamental Matematicaalesdelf02Ainda não há avaliações
- Estatística Usando ExcelDocumento23 páginasEstatística Usando ExcelSérgio SantosAinda não há avaliações
- Afa CadernoDocumento25 páginasAfa Cadernoinês SantosAinda não há avaliações
- Re Mat7 Atividade Enlmar20Documento6 páginasRe Mat7 Atividade Enlmar20nunomnm1959Ainda não há avaliações
- Estatistica nº2 Mathsuccess (1)Documento4 páginasEstatistica nº2 Mathsuccess (1)lara832006Ainda não há avaliações
- Rel Final Rend Ener 03 03 16Documento74 páginasRel Final Rend Ener 03 03 16Jerci SousaAinda não há avaliações
- Ipl Relatorio FinalDocumento41 páginasIpl Relatorio Finalcontaozzy777Ainda não há avaliações
- Grudis Final 2023Documento57 páginasGrudis Final 2023a.rafael.holanda14Ainda não há avaliações
- Apol 1 ExploratoriaDocumento8 páginasApol 1 Exploratoriaricardufreitas1991Ainda não há avaliações
- EstatísticaDocumento4 páginasEstatísticaTarcio RochaAinda não há avaliações
- Ti-Nspire Ts Guide PTDocumento526 páginasTi-Nspire Ts Guide PTLuís Pedro100% (1)
- Artigo Abordagem Quantitativa, Qualitativa e A Utilização Da Pesquisa-AçãoDocumento9 páginasArtigo Abordagem Quantitativa, Qualitativa e A Utilização Da Pesquisa-AçãoCeveAinda não há avaliações
- GABARITO Avaliação 1 - Individual DISCIPLINA Estatística (MAT99)Documento10 páginasGABARITO Avaliação 1 - Individual DISCIPLINA Estatística (MAT99)Milto Cezar GomesAinda não há avaliações