
Tarefa 3
Tarefa 3
Você também pode gostar
- Caixa de Mudanças ISHIFTDocumento66 páginasCaixa de Mudanças ISHIFTFabricio Cavalcante100% (16)
- PGR - 2022Documento24 páginasPGR - 2022Johan Sebastian73% (11)
- Análise Da Previdência Social Dos Funcionários Do Aparelho Do Estado MoçambicanoDocumento29 páginasAnálise Da Previdência Social Dos Funcionários Do Aparelho Do Estado Moçambicanorenato saiconde75% (4)
- BH135i 145 165 180 200 Manual Do OperadorDocumento135 páginasBH135i 145 165 180 200 Manual Do OperadorHiago Farias100% (2)
- As 21 LiçõesDocumento161 páginasAs 21 LiçõesDiogo Gonçalves100% (1)
- Gabarito Prova FinalDocumento9 páginasGabarito Prova FinalTony AlvesAinda não há avaliações
- Apostila Distribuição de Energia ElétricaDocumento113 páginasApostila Distribuição de Energia ElétricaTony Alves100% (1)
- Manual Especificações Técnicas de Materiais 00Documento277 páginasManual Especificações Técnicas de Materiais 00Tony AlvesAinda não há avaliações
- Atividade 3.1 - Relatório Escola Normal Superior1Documento15 páginasAtividade 3.1 - Relatório Escola Normal Superior1Tony AlvesAinda não há avaliações
- Roteiro Modelagem EstruturalDocumento3 páginasRoteiro Modelagem EstruturalTony AlvesAinda não há avaliações
- Questão 9Documento4 páginasQuestão 9Tony AlvesAinda não há avaliações
- Alimentos e Execucao - 20231009-1605Documento46 páginasAlimentos e Execucao - 20231009-1605Chauana AlvesAinda não há avaliações
- Manual de Utilizador Monitores Tácteis T06 PDFDocumento34 páginasManual de Utilizador Monitores Tácteis T06 PDFpatgotaAinda não há avaliações
- 2a Via de FaturaDocumento1 página2a Via de FaturaKristen GarciaAinda não há avaliações
- Bpe 071979716668Documento1 páginaBpe 071979716668oliviairinereisAinda não há avaliações
- Caso Prático Sistema de Gestão AmbientalDocumento5 páginasCaso Prático Sistema de Gestão AmbientalJosé Missatidi PauloAinda não há avaliações
- Fis Ciap Û Crédito Icms Sobre Ativo PermanenteDocumento33 páginasFis Ciap Û Crédito Icms Sobre Ativo PermanenteHelio CostaAinda não há avaliações
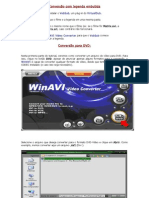
- Tutorial Winavi (Converter para DVD Com Legenda Embutida)Documento4 páginasTutorial Winavi (Converter para DVD Com Legenda Embutida)reginacesAinda não há avaliações
- Edital Estagio 2024Documento8 páginasEdital Estagio 2024gabriel-ortolaneAinda não há avaliações
- Contrato de Prestação de ServiçosDocumento2 páginasContrato de Prestação de ServiçosLan House Net ManiaAinda não há avaliações
- Revisão de Matemática - 7 Classe.Documento1 páginaRevisão de Matemática - 7 Classe.Yamba António Mfulu QI100% (2)
- Tutorial Consultando Um CPF CNPJ No SERASA Via WebServicesDocumento6 páginasTutorial Consultando Um CPF CNPJ No SERASA Via WebServicesMarcos Vinicius MelconianAinda não há avaliações
- Português, Matemática e HistóriaDocumento14 páginasPortuguês, Matemática e Históriadrew do chrisAinda não há avaliações
- Vigas Mistas de Aço e Concreto Biapoiadas: Dimensionamento Via ExcelDocumento58 páginasVigas Mistas de Aço e Concreto Biapoiadas: Dimensionamento Via ExcelJefferson RosaAinda não há avaliações
- Baldan Folheto PSHDocumento2 páginasBaldan Folheto PSHLuan ValadãoAinda não há avaliações
- O SwebokDocumento5 páginasO SwebokWiliam PreislerAinda não há avaliações
- BIOS e UEFI, MBR e GPT, o Que São e Suas DiferençasDocumento4 páginasBIOS e UEFI, MBR e GPT, o Que São e Suas DiferençasJonathan LimaAinda não há avaliações
- Slide LegislaçãoDocumento22 páginasSlide LegislaçãothaisaalvessouzaAinda não há avaliações
- Quesitos de PeríciaDocumento5 páginasQuesitos de PeríciaTatiana FernandesAinda não há avaliações
- O Laboratório D-WPS OfficeDocumento2 páginasO Laboratório D-WPS OfficeIsaias FaqueAinda não há avaliações
- Simulação de Evolução de Financiamento - Crédito ImobiliárioDocumento10 páginasSimulação de Evolução de Financiamento - Crédito ImobiliárioOdilon MachadoAinda não há avaliações
- Calendário de Datas ComemorativasDocumento2 páginasCalendário de Datas Comemorativasbrenda-1232159Ainda não há avaliações
- ParmêDocumento8 páginasParmêMateus FelipeAinda não há avaliações
- Telecurso 2000 - 2º Grau - História Do Brasil - Aulas 31 A 40Documento71 páginasTelecurso 2000 - 2º Grau - História Do Brasil - Aulas 31 A 40Sanderus SenaAinda não há avaliações
- Boleto0943466 14000000000091731Documento1 páginaBoleto0943466 14000000000091731Borges gamesAinda não há avaliações
- ImpostosDocumento62 páginasImpostosthabata-martins100% (1)



































Você também pode gostar
- Caixa de Mudanças ISHIFTDocumento66 páginasCaixa de Mudanças ISHIFTFabricio Cavalcante100% (16)
- PGR - 2022Documento24 páginasPGR - 2022Johan Sebastian73% (11)
- Análise Da Previdência Social Dos Funcionários Do Aparelho Do Estado MoçambicanoDocumento29 páginasAnálise Da Previdência Social Dos Funcionários Do Aparelho Do Estado Moçambicanorenato saiconde75% (4)
- BH135i 145 165 180 200 Manual Do OperadorDocumento135 páginasBH135i 145 165 180 200 Manual Do OperadorHiago Farias100% (2)
- As 21 LiçõesDocumento161 páginasAs 21 LiçõesDiogo Gonçalves100% (1)
- Gabarito Prova FinalDocumento9 páginasGabarito Prova FinalTony AlvesAinda não há avaliações
- Apostila Distribuição de Energia ElétricaDocumento113 páginasApostila Distribuição de Energia ElétricaTony Alves100% (1)
- Manual Especificações Técnicas de Materiais 00Documento277 páginasManual Especificações Técnicas de Materiais 00Tony AlvesAinda não há avaliações
- Atividade 3.1 - Relatório Escola Normal Superior1Documento15 páginasAtividade 3.1 - Relatório Escola Normal Superior1Tony AlvesAinda não há avaliações
- Roteiro Modelagem EstruturalDocumento3 páginasRoteiro Modelagem EstruturalTony AlvesAinda não há avaliações
- Questão 9Documento4 páginasQuestão 9Tony AlvesAinda não há avaliações
- Alimentos e Execucao - 20231009-1605Documento46 páginasAlimentos e Execucao - 20231009-1605Chauana AlvesAinda não há avaliações
- Manual de Utilizador Monitores Tácteis T06 PDFDocumento34 páginasManual de Utilizador Monitores Tácteis T06 PDFpatgotaAinda não há avaliações
- 2a Via de FaturaDocumento1 página2a Via de FaturaKristen GarciaAinda não há avaliações
- Bpe 071979716668Documento1 páginaBpe 071979716668oliviairinereisAinda não há avaliações
- Caso Prático Sistema de Gestão AmbientalDocumento5 páginasCaso Prático Sistema de Gestão AmbientalJosé Missatidi PauloAinda não há avaliações
- Fis Ciap Û Crédito Icms Sobre Ativo PermanenteDocumento33 páginasFis Ciap Û Crédito Icms Sobre Ativo PermanenteHelio CostaAinda não há avaliações
- Tutorial Winavi (Converter para DVD Com Legenda Embutida)Documento4 páginasTutorial Winavi (Converter para DVD Com Legenda Embutida)reginacesAinda não há avaliações
- Edital Estagio 2024Documento8 páginasEdital Estagio 2024gabriel-ortolaneAinda não há avaliações
- Contrato de Prestação de ServiçosDocumento2 páginasContrato de Prestação de ServiçosLan House Net ManiaAinda não há avaliações
- Revisão de Matemática - 7 Classe.Documento1 páginaRevisão de Matemática - 7 Classe.Yamba António Mfulu QI100% (2)
- Tutorial Consultando Um CPF CNPJ No SERASA Via WebServicesDocumento6 páginasTutorial Consultando Um CPF CNPJ No SERASA Via WebServicesMarcos Vinicius MelconianAinda não há avaliações
- Português, Matemática e HistóriaDocumento14 páginasPortuguês, Matemática e Históriadrew do chrisAinda não há avaliações
- Vigas Mistas de Aço e Concreto Biapoiadas: Dimensionamento Via ExcelDocumento58 páginasVigas Mistas de Aço e Concreto Biapoiadas: Dimensionamento Via ExcelJefferson RosaAinda não há avaliações
- Baldan Folheto PSHDocumento2 páginasBaldan Folheto PSHLuan ValadãoAinda não há avaliações
- O SwebokDocumento5 páginasO SwebokWiliam PreislerAinda não há avaliações
- BIOS e UEFI, MBR e GPT, o Que São e Suas DiferençasDocumento4 páginasBIOS e UEFI, MBR e GPT, o Que São e Suas DiferençasJonathan LimaAinda não há avaliações
- Slide LegislaçãoDocumento22 páginasSlide LegislaçãothaisaalvessouzaAinda não há avaliações
- Quesitos de PeríciaDocumento5 páginasQuesitos de PeríciaTatiana FernandesAinda não há avaliações
- O Laboratório D-WPS OfficeDocumento2 páginasO Laboratório D-WPS OfficeIsaias FaqueAinda não há avaliações
- Simulação de Evolução de Financiamento - Crédito ImobiliárioDocumento10 páginasSimulação de Evolução de Financiamento - Crédito ImobiliárioOdilon MachadoAinda não há avaliações
- Calendário de Datas ComemorativasDocumento2 páginasCalendário de Datas Comemorativasbrenda-1232159Ainda não há avaliações
- ParmêDocumento8 páginasParmêMateus FelipeAinda não há avaliações
- Telecurso 2000 - 2º Grau - História Do Brasil - Aulas 31 A 40Documento71 páginasTelecurso 2000 - 2º Grau - História Do Brasil - Aulas 31 A 40Sanderus SenaAinda não há avaliações
- Boleto0943466 14000000000091731Documento1 páginaBoleto0943466 14000000000091731Borges gamesAinda não há avaliações
- ImpostosDocumento62 páginasImpostosthabata-martins100% (1)