Você também pode gostar
- 4a Aula Síncrona Leis de NewtonDocumento64 páginas4a Aula Síncrona Leis de NewtonJorge twttAinda não há avaliações
- CIFRA - Pra Sempre ReinaraDocumento1 páginaCIFRA - Pra Sempre ReinaraSergio MarquesAinda não há avaliações
- Memoria Descritiva - Cobertura Metalica - COLEPDocumento60 páginasMemoria Descritiva - Cobertura Metalica - COLEPstar_starAinda não há avaliações
- Ebook ANSIEDADEDocumento7 páginasEbook ANSIEDADEJade FalcãoAinda não há avaliações
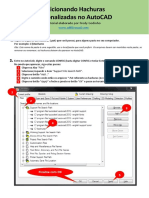
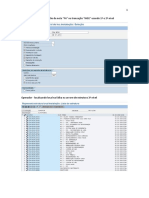
- Adicionando Hachuras Personalizadas No AutoCAD PDFDocumento2 páginasAdicionando Hachuras Personalizadas No AutoCAD PDFValter AraujoAinda não há avaliações
- Desemprego Tecnológico, Eliminação e Criação de Profissões: Aluno: Ricardo França Resende de Lima Matrícula: 20201107241Documento5 páginasDesemprego Tecnológico, Eliminação e Criação de Profissões: Aluno: Ricardo França Resende de Lima Matrícula: 20201107241Ricardo FrançaAinda não há avaliações
- Vocabulário Bilíngue - Terena Português PDFDocumento110 páginasVocabulário Bilíngue - Terena Português PDFJulieth13AquinoAinda não há avaliações
- Rio Grande (Do Norte) : História e HistoriografiaaDocumento33 páginasRio Grande (Do Norte) : História e HistoriografiaaLívia BarbosaAinda não há avaliações
- Organograma - 11 PDFDocumento1 páginaOrganograma - 11 PDFcidj_6Ainda não há avaliações
- Lotes 24 e 29 - Leonardo - Venc 10ago22Documento1 páginaLotes 24 e 29 - Leonardo - Venc 10ago22LeonardoAinda não há avaliações
- Zine - Organizando Um Coletivo Feminista - Um Guia Pratico - GarrafeministaDocumento19 páginasZine - Organizando Um Coletivo Feminista - Um Guia Pratico - GarrafeministaCarolina SoaresAinda não há avaliações
- Operador de Videomonitoramento PDFDocumento28 páginasOperador de Videomonitoramento PDFMarcelo Fonseca100% (2)
- Instrucao de Uso - Termometro Premium T81Documento2 páginasInstrucao de Uso - Termometro Premium T81CristianAinda não há avaliações
- V5 Ficha de CoterieDocumento1 páginaV5 Ficha de CoterieDavi GonçalvesAinda não há avaliações
- Passo A Passo IT Registro e Atendimento FalhaDocumento13 páginasPasso A Passo IT Registro e Atendimento Falhajefferson gomesAinda não há avaliações
- Corpo e Ancestralidade Fabio LimaDocumento14 páginasCorpo e Ancestralidade Fabio LimaDenise David CaxiasAinda não há avaliações
- Redação 9º AnoDocumento6 páginasRedação 9º AnoCheysa AbdallaAinda não há avaliações
- Kevin Reed - Membresia de IgrejaDocumento3 páginasKevin Reed - Membresia de IgrejaJessica Juntocom MiqueiasAinda não há avaliações
- Resumo Beatriz SarloDocumento8 páginasResumo Beatriz SarloPatrícia Argôlo RosaAinda não há avaliações
- 7º Ano - Módulo 2 - GeografiaDocumento11 páginas7º Ano - Módulo 2 - GeografiaANDREA VINCHI LAPELLIGRINIAinda não há avaliações
- Matriz Ansoff e Integração VerticalDocumento2 páginasMatriz Ansoff e Integração VerticalVitor Valadares0% (1)
- Sede PerfeitosDocumento31 páginasSede PerfeitosRoberta Montellato100% (1)
- A Morte Do PúlpitoDocumento3 páginasA Morte Do PúlpitoRafael Pasqualotto100% (1)
- Manual BR Ip00285a KL1312 3.0Documento22 páginasManual BR Ip00285a KL1312 3.0CENTRO OESTEAinda não há avaliações
- A Influência Dos Youtubers Na Vida Dos AdolescentesDocumento1 páginaA Influência Dos Youtubers Na Vida Dos AdolescentesThuany GomesAinda não há avaliações
- A Chufa Pode e Deve Ser Consumida No Contexto de Uma Alimentação EquilibradaDocumento2 páginasA Chufa Pode e Deve Ser Consumida No Contexto de Uma Alimentação EquilibradaAna d'AlmeidaAinda não há avaliações
- A Fina Lâmina Da Palavra PDFDocumento30 páginasA Fina Lâmina Da Palavra PDFJoão NetoAinda não há avaliações
- RESUMO Adm de VendasDocumento2 páginasRESUMO Adm de VendastainaraAinda não há avaliações
- Campo Harmonico e Transposição - EmanuelDocumento7 páginasCampo Harmonico e Transposição - EmanuelDarci Pinheiro MdfAinda não há avaliações
- Capim SudaoDocumento11 páginasCapim SudaoAline DutraAinda não há avaliações
- Focar: Supere a procrastinação e aumente a força de vontade e a atençãoNo EverandFocar: Supere a procrastinação e aumente a força de vontade e a atençãoNota: 4.5 de 5 estrelas4.5/5 (53)
- Elaboração de programas de ensino: material autoinstrutivoNo EverandElaboração de programas de ensino: material autoinstrutivoAinda não há avaliações
- O fim da ansiedade: O segredo bíblico para livrar-se das preocupaçõesNo EverandO fim da ansiedade: O segredo bíblico para livrar-se das preocupaçõesNota: 5 de 5 estrelas5/5 (16)
- Técnicas Proibidas de Manipulação Mental e PersuasãoNo EverandTécnicas Proibidas de Manipulação Mental e PersuasãoNota: 5 de 5 estrelas5/5 (3)
- Psicologia sombria: Poderosas técnicas de controle mental e persuasãoNo EverandPsicologia sombria: Poderosas técnicas de controle mental e persuasãoNota: 4 de 5 estrelas4/5 (92)
- E-TRAP: entrevista diagnóstica para transtornos de personalidadeNo EverandE-TRAP: entrevista diagnóstica para transtornos de personalidadeNota: 5 de 5 estrelas5/5 (3)
- Como aprender mais rápido: Métodos e dicas para se tornar mais inteligenteNo EverandComo aprender mais rápido: Métodos e dicas para se tornar mais inteligenteNota: 3.5 de 5 estrelas3.5/5 (8)
- Trading online de uma forma simples: Como aprender o comércio em linha e descobrir as bases para uma negociação bem sucedidaNo EverandTrading online de uma forma simples: Como aprender o comércio em linha e descobrir as bases para uma negociação bem sucedidaNota: 5 de 5 estrelas5/5 (1)