Você também pode gostar
- Curso 223678 Aula 15 c4f0 CompletoDocumento102 páginasCurso 223678 Aula 15 c4f0 Completoeduardo netoAinda não há avaliações
- Raspagem De Dados Com Jsoup No Java No Ambiente Intellij IdeaNo EverandRaspagem De Dados Com Jsoup No Java No Ambiente Intellij IdeaAinda não há avaliações
- TCC Vitor Felicio Salema PDFDocumento79 páginasTCC Vitor Felicio Salema PDFVítor SalemaAinda não há avaliações
- Estatística Aplicada Ao Cálculo De Análise Assimétrica Programado No PythonNo EverandEstatística Aplicada Ao Cálculo De Análise Assimétrica Programado No PythonAinda não há avaliações
- ApostilaDocumento183 páginasApostilaAyorius XAinda não há avaliações
- Estatística Aplicada A Cálculo De Desvio Padrão Programado No PythonNo EverandEstatística Aplicada A Cálculo De Desvio Padrão Programado No PythonAinda não há avaliações
- Apostila 00 - PMBOKDocumento63 páginasApostila 00 - PMBOKmejikaAinda não há avaliações
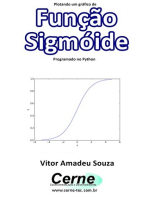
- Plotando Um Gráfico De Função Sigmóide Programado No PythonNo EverandPlotando Um Gráfico De Função Sigmóide Programado No PythonAinda não há avaliações
- Apostila PHP MySqlDocumento90 páginasApostila PHP MySqlIgor SchmidtAinda não há avaliações
- Estatística Aplicada Ao Cálculo De Covariância Programado No PythonNo EverandEstatística Aplicada Ao Cálculo De Covariância Programado No PythonAinda não há avaliações
- Aula 08 - Ia - Machine LearningDocumento184 páginasAula 08 - Ia - Machine Learningeainfor100% (1)
- Estatística Aplicada Ao Cálculo De Curtose Programado No PythonNo EverandEstatística Aplicada Ao Cálculo De Curtose Programado No PythonAinda não há avaliações
- TCC VirtualizacaoDocumento114 páginasTCC VirtualizacaoneorpdAinda não há avaliações
- WindowsDocumento77 páginasWindowsHenry AdministraçãoAinda não há avaliações
- Aula 30 - TI - Machine LearningDocumento117 páginasAula 30 - TI - Machine LearningChegamais FiscalAinda não há avaliações
- Curso 228255 Aula 02 1c73 Completo PDFDocumento238 páginasCurso 228255 Aula 02 1c73 Completo PDFtatianna trindade amadorAinda não há avaliações
- Tecnologia Da Informação - Apostila - Aula 3Documento90 páginasTecnologia Da Informação - Apostila - Aula 3Perito Criminal100% (1)
- Rede de ComputadoresDocumento56 páginasRede de ComputadoresSamuel Lima100% (1)
- Algoritmos I.E BookDocumento124 páginasAlgoritmos I.E BookPRAGA BLINDADA100% (2)
- HardwareDocumento67 páginasHardwareJônatas Sena100% (1)
- Machine Learning - Pt1Documento37 páginasMachine Learning - Pt1AlfaAinda não há avaliações
- Curso 223678 Aula 03 7626 CompletoDocumento133 páginasCurso 223678 Aula 03 7626 Completoeduardo neto0% (1)
- Aula 03Documento116 páginasAula 03Thiago Rodrigues BarbosaAinda não há avaliações
- Excel 2Documento107 páginasExcel 2AlyssonmarcioAinda não há avaliações
- Curso 256556 Aula 01 87e2 CompletoDocumento144 páginasCurso 256556 Aula 01 87e2 CompletoLucas CampanaAinda não há avaliações
- Aula 36 - TI - Engenharia de Software - Análise de Pontos de FunçãoDocumento143 páginasAula 36 - TI - Engenharia de Software - Análise de Pontos de FunçãoChegamais FiscalAinda não há avaliações
- Lógica e PythonDocumento40 páginasLógica e PythonHerogeek 05Ainda não há avaliações
- GeografiaDocumento13 páginasGeografiaDuda ZambottiAinda não há avaliações
- Aula 09: TSE - Concurso Unificado - Informática - 2022 (Pré-Edital)Documento176 páginasAula 09: TSE - Concurso Unificado - Informática - 2022 (Pré-Edital)Irasuian NascimentoAinda não há avaliações
- Curso 245873 Aula 00 BDCD CompletoDocumento243 páginasCurso 245873 Aula 00 BDCD Completobrunopessoa_meloAinda não há avaliações
- Aula 30 - Linguagem R - Prof Thiago CavalcantiDocumento61 páginasAula 30 - Linguagem R - Prof Thiago CavalcantiRicardo TeixeiraAinda não há avaliações
- Detecção de AnomaliasDocumento62 páginasDetecção de AnomaliasDaniel Valério LeiteAinda não há avaliações
- Montagem Manutencao Computadores WebDocumento70 páginasMontagem Manutencao Computadores WebLamare LacerdaAinda não há avaliações
- Domínio Produtivoda Informáticapescrituráriodo Banrisul Aula 1Documento67 páginasDomínio Produtivoda Informáticapescrituráriodo Banrisul Aula 1Jovem LAinda não há avaliações
- Excel - Estratégia - ApostilaDocumento133 páginasExcel - Estratégia - ApostilaBruno AndradeAinda não há avaliações
- Livro Introdução A Visão Computacional Com Python e OpenCV 3Documento68 páginasLivro Introdução A Visão Computacional Com Python e OpenCV 3AndersonPintoAinda não há avaliações
- Tecnologia de InformaçãoDocumento9 páginasTecnologia de InformaçãoNilto MassangoAinda não há avaliações
- Computação Na Nuvem e Correio Eletrônico Curso-4439-Aula-05-V1Documento147 páginasComputação Na Nuvem e Correio Eletrônico Curso-4439-Aula-05-V1Roy Flu OrangeAinda não há avaliações
- Professor: Equipe Informática e TI, Thiago Rodrigues CavalcantiDocumento59 páginasProfessor: Equipe Informática e TI, Thiago Rodrigues CavalcantiCristiano Borges MilhomemAinda não há avaliações
- Apostila TiDocumento123 páginasApostila TiAlmeida SantosAinda não há avaliações
- Azure e Inteligencia ArtificialDocumento345 páginasAzure e Inteligencia Artificialwggonzaga100% (1)
- Módulo 11. Machine Learning - Introdução Às Técnicas e Modelos AplicáveisDocumento62 páginasMódulo 11. Machine Learning - Introdução Às Técnicas e Modelos Aplicáveispedro100% (1)
- Unidade 1Documento34 páginasUnidade 1Mário Cesar Soares TeixeiraAinda não há avaliações
- Tecnologia Da Informação - Apostila - Aula 1Documento152 páginasTecnologia Da Informação - Apostila - Aula 1Perito CriminalAinda não há avaliações
- Curso 1Documento68 páginasCurso 1Jb SantosaAinda não há avaliações
- Curso 19304 Aula 00 Prof Celson Junior 8fe2 CompletoDocumento123 páginasCurso 19304 Aula 00 Prof Celson Junior 8fe2 CompletogilsonAinda não há avaliações
- ApostilaDocumento161 páginasApostilaAyorius XAinda não há avaliações
- Apostila - Módulo 1 - Bootcamp Arquiteto (A) de Machine LearningDocumento71 páginasApostila - Módulo 1 - Bootcamp Arquiteto (A) de Machine LearningBruno Ferreira AlencarAinda não há avaliações
- Montador e Reparador de ComputadoresDocumento132 páginasMontador e Reparador de ComputadoresrmscavalcanteAinda não há avaliações
- TCC - Analise e Desenvolvimento de Sistemas - Pet ShopDocumento85 páginasTCC - Analise e Desenvolvimento de Sistemas - Pet ShopCaioFredericoMendesAinda não há avaliações
- Curso 223678 Aula 01 849e CompletoDocumento147 páginasCurso 223678 Aula 01 849e Completoeduardo neto100% (2)
- Arquitetura de ComputadoresDocumento179 páginasArquitetura de Computadorestsf2012Ainda não há avaliações
- Sistema Control e A Present A Ç ÃoDocumento40 páginasSistema Control e A Present A Ç ÃoPaulo Ricardo SilvaAinda não há avaliações
- Hardware 2Documento27 páginasHardware 2AlyssonmarcioAinda não há avaliações
- Osi Mais CompletoDocumento145 páginasOsi Mais CompletoCarine AzevedoAinda não há avaliações
- Curso 228532 Aula 03-1-9ef6 CompletoDocumento133 páginasCurso 228532 Aula 03-1-9ef6 Completomjcs181123Ainda não há avaliações
- ApostilaDocumento111 páginasApostilanjuliana59123456Ainda não há avaliações
- Aula 05 - SimplificadoDocumento44 páginasAula 05 - Simplificadogiwilo3274Ainda não há avaliações
- Regulamento PROGRAMA DF SUPERIOR Graduação EAd e Presencial Vs 06.10.2022Documento8 páginasRegulamento PROGRAMA DF SUPERIOR Graduação EAd e Presencial Vs 06.10.2022Priscila RodriguesAinda não há avaliações
- Negócios Na Era DigitalDocumento62 páginasNegócios Na Era DigitalGil RibeiroAinda não há avaliações
- Data Mesh Como Paradigma de Arquitetura de DadosDocumento2 páginasData Mesh Como Paradigma de Arquitetura de DadosRafael Assis AmancioAinda não há avaliações
- Av - Comunicação de Marketing em Meios DigitaisDocumento1 páginaAv - Comunicação de Marketing em Meios DigitaisWEYDSON PORTELA100% (3)
- Data Warehouse Big Data - EbookDocumento53 páginasData Warehouse Big Data - EbookJoão CorreiaAinda não há avaliações
- Análise de DadosDocumento14 páginasAnálise de DadosJorge John JerrãoAinda não há avaliações
- O Que É A Logística 4.0 IntroduçãoDocumento21 páginasO Que É A Logística 4.0 IntroduçãoMonia Pereira - Vitória ESAinda não há avaliações
- Introdução Ao Data MiningDocumento19 páginasIntrodução Ao Data MiningRichelieu ValentinAinda não há avaliações
- Big Data & IoT PDFDocumento30 páginasBig Data & IoT PDFGilberto FernandesAinda não há avaliações
- Management Information Systems (2017) (001-067) .En - PT PDFDocumento67 páginasManagement Information Systems (2017) (001-067) .En - PT PDFLuciano Naate Avelino BispoAinda não há avaliações
- BigModels BigData-Caetano SilvaDocumento16 páginasBigModels BigData-Caetano SilvaWanderlei BorgesAinda não há avaliações
- 06.10 Cientistas de Dados Especializados em Detecção de FraudeDocumento3 páginas06.10 Cientistas de Dados Especializados em Detecção de FraudeAlexandre BaldoinoAinda não há avaliações
- Currículo Do Sistema de Currículos Lattes (Thiago de Jesus Rodrigues)Documento3 páginasCurrículo Do Sistema de Currículos Lattes (Thiago de Jesus Rodrigues)Thiago RodriguesAinda não há avaliações
- O Mercado Brasileiro de Soluções para Cidades Inteligentes2 - CompressedDocumento111 páginasO Mercado Brasileiro de Soluções para Cidades Inteligentes2 - CompressedEddy AguirreAinda não há avaliações
- Data Mining IDocumento15 páginasData Mining IRafael MedradoAinda não há avaliações
- MONOGRAFIA - Bruno CamposDocumento53 páginasMONOGRAFIA - Bruno CamposBruno CamposAinda não há avaliações
- Apostila Power BiDocumento169 páginasApostila Power BiAJURI RENOR LIMA DE CARVALHO100% (8)
- Entendendo o Mindset de Big DataDocumento29 páginasEntendendo o Mindset de Big DataTiago Coutinho Raiane LopesAinda não há avaliações
- Estudo de Caso Indústria 4.0 Comprovando A Rentabilidade Da AplicaçãoDocumento33 páginasEstudo de Caso Indústria 4.0 Comprovando A Rentabilidade Da AplicaçãoLays SangiAinda não há avaliações
- Indústria 4.0Documento7 páginasIndústria 4.0Renan Lima100% (1)
- Apostila Data Mining 2Documento62 páginasApostila Data Mining 2Vitor Gabriel100% (1)
- Aula 4 - Sistemas de Gestão e Big DataDocumento26 páginasAula 4 - Sistemas de Gestão e Big DataRafael RianiAinda não há avaliações
- Reinaldo Gandelini - 5 Passos para Mudança de CarreiraDocumento51 páginasReinaldo Gandelini - 5 Passos para Mudança de CarreiraAline VerenaAinda não há avaliações
- Resultado 1 FASE - IC2022Documento15 páginasResultado 1 FASE - IC2022silia renataAinda não há avaliações
- Introdução A Big Data e Internet Das Coisas 1Documento3 páginasIntrodução A Big Data e Internet Das Coisas 1Larissa SantosAinda não há avaliações
- Capítulo Amostra Big Data No Trabalho PDFDocumento12 páginasCapítulo Amostra Big Data No Trabalho PDFrafaeloaleAinda não há avaliações
- Cenários Prospectivos - 2016 A 2018Documento30 páginasCenários Prospectivos - 2016 A 2018fabipecAinda não há avaliações
- Revisar Envio Do Teste - QUESTIONÁRIO UNIDADE IV - 7046-..Documento8 páginasRevisar Envio Do Teste - QUESTIONÁRIO UNIDADE IV - 7046-..Daniel PaesAinda não há avaliações
- E CommerceDocumento67 páginasE Commercerai86hAinda não há avaliações
- Manufatura 4.0Documento27 páginasManufatura 4.0Jailson RamosAinda não há avaliações
- Focar: Supere a procrastinação e aumente a força de vontade e a atençãoNo EverandFocar: Supere a procrastinação e aumente a força de vontade e a atençãoNota: 4.5 de 5 estrelas4.5/5 (53)
- Técnicas Proibidas de Manipulação Mental e PersuasãoNo EverandTécnicas Proibidas de Manipulação Mental e PersuasãoNota: 5 de 5 estrelas5/5 (3)
- Treinamento cerebral: Compreendendo inteligência emocional, atenção e muito maisNo EverandTreinamento cerebral: Compreendendo inteligência emocional, atenção e muito maisNota: 4.5 de 5 estrelas4.5/5 (169)
- Psicologia sombria: Poderosas técnicas de controle mental e persuasãoNo EverandPsicologia sombria: Poderosas técnicas de controle mental e persuasãoNota: 4 de 5 estrelas4/5 (92)
- Diálogo entre Terapia do Esquema e Terapia Focada na Compaixão: Contribuição à integração em Psicoterapias Cognitivo-ComportamentaisNo EverandDiálogo entre Terapia do Esquema e Terapia Focada na Compaixão: Contribuição à integração em Psicoterapias Cognitivo-ComportamentaisNota: 5 de 5 estrelas5/5 (1)
- Bololô: contém ferramentas de treinamento para pais e filhosNo EverandBololô: contém ferramentas de treinamento para pais e filhosAinda não há avaliações
- Técnicas De Terapia Cognitivo-comportamental (tcc)No EverandTécnicas De Terapia Cognitivo-comportamental (tcc)Ainda não há avaliações
- O fim da ansiedade: O segredo bíblico para livrar-se das preocupaçõesNo EverandO fim da ansiedade: O segredo bíblico para livrar-se das preocupaçõesNota: 5 de 5 estrelas5/5 (16)
- Simplificando o Autismo: Para pais, familiares e profissionaisNo EverandSimplificando o Autismo: Para pais, familiares e profissionaisAinda não há avaliações
- Psicanálise de boteco: O inconsciente na vida cotidianaNo EverandPsicanálise de boteco: O inconsciente na vida cotidianaNota: 5 de 5 estrelas5/5 (1)
- Treinamento cerebral: Como funcionam a inteligência e o pensamento cognitivo (2 em 1)No EverandTreinamento cerebral: Como funcionam a inteligência e o pensamento cognitivo (2 em 1)Nota: 4.5 de 5 estrelas4.5/5 (29)
- Treino de Habilidades Sociais: processo, avaliação e resultadosNo EverandTreino de Habilidades Sociais: processo, avaliação e resultadosNota: 5 de 5 estrelas5/5 (2)
- 35 Técnicas e Curiosidades Mentais: Porque a mente também deve evoluirNo Everand35 Técnicas e Curiosidades Mentais: Porque a mente também deve evoluirNota: 5 de 5 estrelas5/5 (3)
- Como aprender mais rápido: Métodos e dicas para se tornar mais inteligenteNo EverandComo aprender mais rápido: Métodos e dicas para se tornar mais inteligenteNota: 3.5 de 5 estrelas3.5/5 (8)
- Elaboração de programas de ensino: material autoinstrutivoNo EverandElaboração de programas de ensino: material autoinstrutivoAinda não há avaliações
- Consciência fonológica: coletânea de atividades orais para a sala de aulaNo EverandConsciência fonológica: coletânea de atividades orais para a sala de aulaNota: 5 de 5 estrelas5/5 (2)
- Cartas de um terapeuta para seus momentos de criseNo EverandCartas de um terapeuta para seus momentos de criseNota: 4 de 5 estrelas4/5 (11)