Você também pode gostar
- Resumo Banco de DadosDocumento4 páginasResumo Banco de DadosHenrique HipólitoAinda não há avaliações
- Banco de Dados 1Documento19 páginasBanco de Dados 1Jhon MotaAinda não há avaliações
- Desbravando PythonDocumento33 páginasDesbravando PythonWalter Angolar Da SilvaAinda não há avaliações
- 04 Hive LLAP HDP v02Documento64 páginas04 Hive LLAP HDP v02Daniel FuchsAinda não há avaliações
- Class01 SlidesDocumento23 páginasClass01 SlidesEnricco GemhaAinda não há avaliações
- Com300-V19 RevisadoDocumento20 páginasCom300-V19 Revisadocharlescoutinho85Ainda não há avaliações
- Banco de Dados 3Documento44 páginasBanco de Dados 3Jhon MotaAinda não há avaliações
- ptr2355 Aula 5 Sgbde Parte I V 6 9 11Documento82 páginasptr2355 Aula 5 Sgbde Parte I V 6 9 11Age Ovilela Por BemAinda não há avaliações
- Aulas Do Módulo 2 - Programação BásicaDocumento34 páginasAulas Do Módulo 2 - Programação BásicaGabriel FigueiredoAinda não há avaliações
- Introducao A Sistemas de Banco de Dados PDFDocumento8 páginasIntroducao A Sistemas de Banco de Dados PDFAndré Das GraçasAinda não há avaliações
- MongoDB - Persistencia PDFDocumento172 páginasMongoDB - Persistencia PDFSting SilvaAinda não há avaliações
- Mongodb 090912144354 Phpapp02Documento50 páginasMongodb 090912144354 Phpapp02nortonpjr8815Ainda não há avaliações
- 2.introdução Ao SparkDocumento10 páginas2.introdução Ao Sparkklinsmann oliveiraAinda não há avaliações
- Slides - Módulo 2 - Dev & DataDocumento34 páginasSlides - Módulo 2 - Dev & Datajansle.sp3331Ainda não há avaliações
- Organização de Informações em ProjetosDocumento27 páginasOrganização de Informações em ProjetosSidney AlvesAinda não há avaliações
- BigdataDocumento64 páginasBigdataedenAinda não há avaliações
- Gerenciamento Arquivo-Parte1Documento55 páginasGerenciamento Arquivo-Parte1Vitor HagaAinda não há avaliações
- NOSQL Workshop SBCDocumento86 páginasNOSQL Workshop SBCleandroaparecidoAinda não há avaliações
- Sistemas de Banco de Dados: Projeto, Implementação e GestãoDocumento49 páginasSistemas de Banco de Dados: Projeto, Implementação e GestãoEdivaldo FeitosaAinda não há avaliações
- Programação Web 1Documento72 páginasProgramação Web 1Rafael MoreiraAinda não há avaliações
- 06 - Hierarquia de MemóriasDocumento60 páginas06 - Hierarquia de MemóriasRafael B.Ainda não há avaliações
- Aula 3 - SGBD, Fases Da Modelagem de Um Banco de DadosDocumento29 páginasAula 3 - SGBD, Fases Da Modelagem de Um Banco de DadosRafhael CunhaAinda não há avaliações
- Aula 3 - Integrations e Development ToolsDocumento50 páginasAula 3 - Integrations e Development ToolsRenato Cardoso AlvesAinda não há avaliações
- Aula 01 - IntroducaoDocumento29 páginasAula 01 - Introducaomoaninha fofichaAinda não há avaliações
- Modelagem de DadosDocumento40 páginasModelagem de DadosDavi JoséAinda não há avaliações
- Criação de Banco de Dados Utilizando SQLDocumento117 páginasCriação de Banco de Dados Utilizando SQLastarote.nuvemAinda não há avaliações
- Ementa Pós Gradução em Engenharia de DadosDocumento13 páginasEmenta Pós Gradução em Engenharia de DadosJones BillyAinda não há avaliações
- Modulo1 IntroducaoateoriadeBDDocumento22 páginasModulo1 IntroducaoateoriadeBDJonathan Gomes ReinaldoAinda não há avaliações
- Aula 01 - Informática InstrumentalDocumento24 páginasAula 01 - Informática InstrumentalRafael FerrazAinda não há avaliações
- Material de Apoio - Módulo 3 - Aula 4Documento17 páginasMaterial de Apoio - Módulo 3 - Aula 4MateriaisAinda não há avaliações
- 04 Hive LLAP HDP v03Documento65 páginas04 Hive LLAP HDP v03Daniel FuchsAinda não há avaliações
- Aula 02 - Conceitos BDDocumento25 páginasAula 02 - Conceitos BDShazam Strong100% (1)
- Fundamentos Da TI - ProgramaçãoDocumento13 páginasFundamentos Da TI - ProgramaçãoPrisma Caos ViajanteAinda não há avaliações
- NSQOL Aula 6 MongoDBDocumento39 páginasNSQOL Aula 6 MongoDBLuciano ContriAinda não há avaliações
- Hierarquia de MemóriaDocumento61 páginasHierarquia de MemóriaJonas ResendeAinda não há avaliações
- Capitulo 2 Conceitos Arquitetura NavatheDocumento25 páginasCapitulo 2 Conceitos Arquitetura NavathewrbiscaroAinda não há avaliações
- Cloud Computing e Big Data: Pós-GraduaçãoDocumento21 páginasCloud Computing e Big Data: Pós-GraduaçãoJoice Almeida da SilvaAinda não há avaliações
- Banco de Dados - Aula 2Documento73 páginasBanco de Dados - Aula 2pedro.cunhaAinda não há avaliações
- Banco de Dados - Aula 1Documento61 páginasBanco de Dados - Aula 1pedro.cunhaAinda não há avaliações
- Conceitos de Banco de Dados e SGBDs - SlidesDocumento41 páginasConceitos de Banco de Dados e SGBDs - Slidesanizete7575Ainda não há avaliações
- Tipos de Banco de Dados - Uma Visão GeralDocumento3 páginasTipos de Banco de Dados - Uma Visão GeralGCleiton SilvaAinda não há avaliações
- Aula 001 - Banco de DadosDocumento17 páginasAula 001 - Banco de DadosValdirene AlvesAinda não há avaliações
- Informática Básica - Aula 06 - Introdução LibreOfficeDocumento15 páginasInformática Básica - Aula 06 - Introdução LibreOfficeAdriana Paula de souzaAinda não há avaliações
- Rotinas Administrativas - Parte - InformáticaDocumento242 páginasRotinas Administrativas - Parte - InformáticaGiancarlo FisichellaAinda não há avaliações
- Introdução Á Internet - Navegação NaDocumento11 páginasIntrodução Á Internet - Navegação Nafilippereira93_86221Ainda não há avaliações
- Aula1 - BigdataDocumento33 páginasAula1 - BigdataMatheusAinda não há avaliações
- Aula 2 - Modelo de DadosDocumento9 páginasAula 2 - Modelo de DadosRogério A MedeirosAinda não há avaliações
- SGBD - Visão Geral, Usuários e TiposDocumento32 páginasSGBD - Visão Geral, Usuários e Tiposamerico86Ainda não há avaliações
- Programação para Data Science: Jony Arrais Pinto JuniorDocumento45 páginasProgramação para Data Science: Jony Arrais Pinto JuniorFrank CampolinaAinda não há avaliações
- Aula 1 - Introdução (DDM)Documento25 páginasAula 1 - Introdução (DDM)Henrique HoffmannAinda não há avaliações
- 01 Historia Dos Bds (Modo de Compatibilidade)Documento47 páginas01 Historia Dos Bds (Modo de Compatibilidade)voide CratuaAinda não há avaliações
- Gcs Aula09Documento43 páginasGcs Aula09Patricia AlvesAinda não há avaliações
- Aula01-DCC603 - Apresentação e Introdução NoSQLDocumento25 páginasAula01-DCC603 - Apresentação e Introdução NoSQLAcauan RibeiroAinda não há avaliações
- Aula 2 - Conceitos de Banco de DadosDocumento38 páginasAula 2 - Conceitos de Banco de DadosRafhael CunhaAinda não há avaliações
- APRESENTAÇÃO Da Instalação Do S.O. DebianDocumento14 páginasAPRESENTAÇÃO Da Instalação Do S.O. DebianNeto FregatiAinda não há avaliações
- IBPAD CIÊNCIA DE DADOS COM R Ementa CompletaDocumento6 páginasIBPAD CIÊNCIA DE DADOS COM R Ementa CompletaFrancisco AraújoAinda não há avaliações
- Modelagem Conceitual, Lógica e Física PDFDocumento13 páginasModelagem Conceitual, Lógica e Física PDFMelissa TheodoroAinda não há avaliações
- Aula01 ModelagemDocumento28 páginasAula01 ModelagememarchettisilvaAinda não há avaliações
- Aula Apres OODocumento130 páginasAula Apres OOmarquirosAinda não há avaliações
- 3 MongodbDocumento3 páginas3 Mongodbklinsmann oliveiraAinda não há avaliações
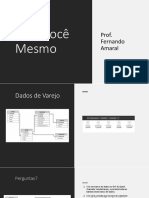
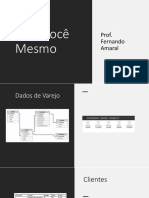
- 9.faça Você MesmoDocumento3 páginas9.faça Você Mesmoklinsmann oliveiraAinda não há avaliações
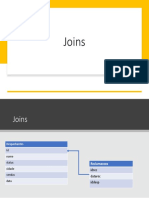
- 6 JoinsDocumento2 páginas6 Joinsklinsmann oliveiraAinda não há avaliações
- 2 PostgresqlDocumento3 páginas2 Postgresqlklinsmann oliveiraAinda não há avaliações
- 1.conectado A Outras FontesDocumento2 páginas1.conectado A Outras Fontesklinsmann oliveiraAinda não há avaliações
- 1 SparkSQLDocumento6 páginas1 SparkSQLklinsmann oliveiraAinda não há avaliações
- 2 DataFrameDocumento5 páginas2 DataFrameklinsmann oliveiraAinda não há avaliações
- 1 ApresentaçãoDocumento2 páginas1 Apresentaçãoklinsmann oliveiraAinda não há avaliações
- 1.1.RDD, Dataset e DataFrameDocumento7 páginas1.1.RDD, Dataset e DataFrameklinsmann oliveiraAinda não há avaliações
- 9.faça Você MesmoDocumento8 páginas9.faça Você Mesmoklinsmann oliveiraAinda não há avaliações
- 4.context e SessionDocumento3 páginas4.context e Sessionklinsmann oliveiraAinda não há avaliações
- 1.introdução Sobre InstalaçãoDocumento5 páginas1.introdução Sobre Instalaçãoklinsmann oliveiraAinda não há avaliações
- 3.arquitetura e ComponentesDocumento15 páginas3.arquitetura e Componentesklinsmann oliveiraAinda não há avaliações
- DistanciasDocumento5 páginasDistanciasklinsmann oliveiraAinda não há avaliações
- 2.introdução Ao SparkDocumento10 páginas2.introdução Ao Sparkklinsmann oliveiraAinda não há avaliações
- Prova Banco de DadosDocumento5 páginasProva Banco de Dadosklinsmann oliveiraAinda não há avaliações
- Prova Logica ProgramacaoDocumento6 páginasProva Logica Programacaoklinsmann oliveiraAinda não há avaliações
- ItensDocumento5 páginasItensklinsmann oliveiraAinda não há avaliações
- Forcia - Tyranto TyranDocumento3 páginasForcia - Tyranto Tyranklinsmann oliveiraAinda não há avaliações
- DC CronologiaDocumento25 páginasDC Cronologiaklinsmann oliveiraAinda não há avaliações
- DC CronologiaDocumento26 páginasDC Cronologiaklinsmann oliveiraAinda não há avaliações