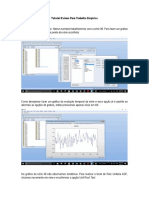
Você também pode gostar
- Análise Fatorial SPSSDocumento16 páginasAnálise Fatorial SPSSDaniel de MatosAinda não há avaliações
- Método Dos Mínimos QuadradosDocumento9 páginasMétodo Dos Mínimos QuadradosRodrigues Almeida GuenhaAinda não há avaliações
- Vijaya MLDocumento26 páginasVijaya MLScribdTranslationsAinda não há avaliações
- Regressão Linear - Interpretação e Análise Dos Resíduos Com SASDocumento7 páginasRegressão Linear - Interpretação e Análise Dos Resíduos Com SASTardocchiAinda não há avaliações
- Regressão: Modelos, Suposições e ValidaçãoDocumento21 páginasRegressão: Modelos, Suposições e ValidaçãoDeográcio Possiano TalegalAinda não há avaliações
- Aula 2Documento22 páginasAula 2Almeida AdilsonAinda não há avaliações
- Programação Estruturada, PONTOS EXTRASDocumento12 páginasProgramação Estruturada, PONTOS EXTRASScribdTranslationsAinda não há avaliações
- Método SimplexDocumento6 páginasMétodo SimplexJaqueline OliveiraAinda não há avaliações
- UFRGS Química Fundamental Algarismos SignificativosDocumento5 páginasUFRGS Química Fundamental Algarismos SignificativosDaniel MircAinda não há avaliações
- Análise de Regressão Linear Simples (SPSS)Documento16 páginasAnálise de Regressão Linear Simples (SPSS)Aylton MangueAinda não há avaliações
- K-Means Clustering no SQLDocumento9 páginasK-Means Clustering no SQLaluysiogcAinda não há avaliações
- Construindo Uma Curva de Gauss NoDocumento9 páginasConstruindo Uma Curva de Gauss NoFernandoconectadoAinda não há avaliações
- Tutorial Eviews ARMA e PrevisãoDocumento13 páginasTutorial Eviews ARMA e PrevisãoRafael MatosAinda não há avaliações
- SEGUNDA PROVA ON LINE - Métodos Quantitativos Aplicados À Administração - 2020 - 1Documento9 páginasSEGUNDA PROVA ON LINE - Métodos Quantitativos Aplicados À Administração - 2020 - 1Mariana MatosAinda não há avaliações
- IBM SPSS Missing ValuesDocumento32 páginasIBM SPSS Missing Valuessebastiao miguel kinangaAinda não há avaliações
- Cap 18Documento5 páginasCap 18re1977searchAinda não há avaliações
- Métodos computacionais MC e bootstrapDocumento2 páginasMétodos computacionais MC e bootstrapRose NascimentoAinda não há avaliações
- Caso Prático - Estatística Básica - Leandro Vidal Da SilDocumento6 páginasCaso Prático - Estatística Básica - Leandro Vidal Da Silgleyce kellem romãoAinda não há avaliações
- Código com erro sintáticoDocumento145 páginasCódigo com erro sintáticoL. CoralAinda não há avaliações
- Tomada de Decisão em Cenários ComplexosDocumento43 páginasTomada de Decisão em Cenários ComplexosPedro AlbuquerqueAinda não há avaliações
- Aluguel Base de Dados AnálisadaDocumento11 páginasAluguel Base de Dados AnálisadaJoão VíctorAinda não há avaliações
- RLS - Usando o SPSSDocumento18 páginasRLS - Usando o SPSSAlphaQuant Consultoria em Métodos QuantitativosAinda não há avaliações
- Análise Descritiva de Dados com Pandas e MatplotlibDocumento1 páginaAnálise Descritiva de Dados com Pandas e Matplotlibsankhasubhra mandalAinda não há avaliações
- Coeficiente de Correlação de PearsonDocumento15 páginasCoeficiente de Correlação de PearsonMarcelino Paulino MateAinda não há avaliações
- Apresentação - Gestão Da QualidadeDocumento16 páginasApresentação - Gestão Da QualidadeGiovanna de OliveiraAinda não há avaliações
- Aula 10 - Correlação e RegressãoDocumento26 páginasAula 10 - Correlação e Regressãonescaudepudim015Ainda não há avaliações
- Validação de CPF com JavaScriptDocumento5 páginasValidação de CPF com JavaScriptMauricio MeloAinda não há avaliações
- IBM SPSS Missing ValuesDocumento30 páginasIBM SPSS Missing ValuesMiguel AngelAinda não há avaliações
- Modelo de regressão para prever salários bancáriosDocumento22 páginasModelo de regressão para prever salários bancáriosSamuel NhantumboAinda não há avaliações
- Manual Lindo v2Documento8 páginasManual Lindo v2JenoirDeVargasMachadoAinda não há avaliações
- AP2Documento3 páginasAP2Dhiogo MaquineAinda não há avaliações
- Classificação e regressão com k-vizinhosDocumento16 páginasClassificação e regressão com k-vizinhosPedro MeloAinda não há avaliações
- Prova CebraspeDocumento6 páginasProva CebraspeClóvis Guerim VieiraAinda não há avaliações
- 3.3 - Regressão Linear MúltiplaDocumento1 página3.3 - Regressão Linear MúltiplaGustavo DiasAinda não há avaliações
- Workshop de SPSS - Aula 02 - Segredos Da Correla oDocumento14 páginasWorkshop de SPSS - Aula 02 - Segredos Da Correla oLucas ApolianoAinda não há avaliações
- Acp11fatores 1Documento6 páginasAcp11fatores 1Filipa RomãoAinda não há avaliações
- Análise de regressão linear emDocumento19 páginasAnálise de regressão linear emBruno RiosAinda não há avaliações
- Relatório IADocumento2 páginasRelatório IAPedro CarvalhoAinda não há avaliações
- Regressão Linear Multipla TeoriaDocumento22 páginasRegressão Linear Multipla TeoriaNatercia RodriguesAinda não há avaliações
- Regressão quadrática ajusta curva de demandaDocumento4 páginasRegressão quadrática ajusta curva de demandaJoao Paulo CaetanoAinda não há avaliações
- Como calcular intervalo de confiança para média a partir de uma amostraDocumento16 páginasComo calcular intervalo de confiança para média a partir de uma amostraAnonymous UYDJtUnAinda não há avaliações
- Palestra Cointegração - Gustavo D'almeidaDocumento14 páginasPalestra Cointegração - Gustavo D'almeidaGustavo d'AlmeidaAinda não há avaliações
- Módulo 6Documento42 páginasMódulo 6lucaslucas10Ainda não há avaliações
- REGRESSÃO LINEAR MÚLTIPLADocumento27 páginasREGRESSÃO LINEAR MÚLTIPLAAdriano BelucoAinda não há avaliações
- Redes Neurais - Artigo (1)Documento28 páginasRedes Neurais - Artigo (1)Lucas EspindolaAinda não há avaliações
- Estatística MultivariadaDocumento33 páginasEstatística Multivariadacarla cristinaAinda não há avaliações
- Aula 6Documento26 páginasAula 6Fernando BatistaAinda não há avaliações
- Projeto 1Documento13 páginasProjeto 1Joana SaraivaAinda não há avaliações
- Quadratura Gaussiana: Fórmulas de Newton-CotesDocumento1 páginaQuadratura Gaussiana: Fórmulas de Newton-CotesAmorine Fernanda Matos de MeloAinda não há avaliações
- ENG1456 Trabalho4 FuzzyDocumento16 páginasENG1456 Trabalho4 FuzzyDaniel CarvalhoAinda não há avaliações
- Agrupamento de dados por variáveis categóricas para análise de preços de veículosDocumento1 páginaAgrupamento de dados por variáveis categóricas para análise de preços de veículossankhasubhra mandalAinda não há avaliações
- Múltipla.: Regressão LinearDocumento13 páginasMúltipla.: Regressão LinearMargarida PerestreloAinda não há avaliações
- Guia para Uso Do RStudioDocumento8 páginasGuia para Uso Do RStudioAna Carolina KiryuAinda não há avaliações
- Teorema de LaplaceDocumento3 páginasTeorema de LaplaceDe Lana JeanAinda não há avaliações
- ChemSep - Primeiros PassosDocumento13 páginasChemSep - Primeiros PassosdubequimaoAinda não há avaliações
- Projetos Em Clp Ladder Baseado No Twidosuite Parte ViiNo EverandProjetos Em Clp Ladder Baseado No Twidosuite Parte ViiAinda não há avaliações
- Texto Proposta App MarketplaceDocumento3 páginasTexto Proposta App MarketplaceLucasAinda não há avaliações
- RespDocumento7 páginasRespLucasAinda não há avaliações
- Texto Proposta App MarketplaceDocumento3 páginasTexto Proposta App MarketplaceLucasAinda não há avaliações
- Texto Proposta App MarketplaceDocumento3 páginasTexto Proposta App MarketplaceLucasAinda não há avaliações
- PT - Security Center User Guide 5.10Documento695 páginasPT - Security Center User Guide 5.10Thiberio Anchieta NazarioAinda não há avaliações
- Operação com trator agrícolaDocumento69 páginasOperação com trator agrícolaGeison Silva67% (3)
- Inventor Básico - 2011 PDFDocumento122 páginasInventor Básico - 2011 PDFLucas LaraAinda não há avaliações
- ddd - Pesquisa GoogleDocumento2 páginasddd - Pesquisa GooglegschiavonplayAinda não há avaliações
- Apresentação EconomiaDocumento11 páginasApresentação EconomiaNuno PalmaAinda não há avaliações
- Apostila-Ms-Project-Básico-Completa PDFDocumento84 páginasApostila-Ms-Project-Básico-Completa PDFAlmir Macario Barros100% (2)
- SQL PIVOT para transformar linhas em colunas em relatório de vendasDocumento11 páginasSQL PIVOT para transformar linhas em colunas em relatório de vendasjmarcellocAinda não há avaliações
- Manual Floboss 407Documento200 páginasManual Floboss 407Alber Almeida100% (1)
- Unidade II - Etapas de Um Projeto de Banco de DadosDocumento20 páginasUnidade II - Etapas de Um Projeto de Banco de DadosJesué Lucas Diogo100% (1)
- Guia definitivo do R4 DS/M3Documento10 páginasGuia definitivo do R4 DS/M3alefersalAinda não há avaliações
- Golpistas Invadem Conta No Mercado Livre e Dão Prejuízo de R$ 300 Mil - 05 - 01 - 2023 - UOL TILTDocumento10 páginasGolpistas Invadem Conta No Mercado Livre e Dão Prejuízo de R$ 300 Mil - 05 - 01 - 2023 - UOL TILTAlex - MCZAinda não há avaliações
- Fundamentos Mecânicos v.02Documento278 páginasFundamentos Mecânicos v.02Mauricio VeberAinda não há avaliações
- Manual JV33 160 PDFDocumento122 páginasManual JV33 160 PDFUederImpressão100% (1)
- 06 - Exercícios 2Documento2 páginas06 - Exercícios 2Rafael Theis DittgenAinda não há avaliações
- Manual Tecnico de Aterramento e Curto Circuitamento TemporárioDocumento14 páginasManual Tecnico de Aterramento e Curto Circuitamento Temporáriobutcher_affAinda não há avaliações
- Apostila Desenho - Arquitetura FAGDocumento103 páginasApostila Desenho - Arquitetura FAGfabioppimenta1997100% (2)
- Geometria 6o AnoDocumento16 páginasGeometria 6o AnoHevany OliveiraAinda não há avaliações
- 3.3.1.5 Packet Tracer - Configuring PVSTDocumento3 páginas3.3.1.5 Packet Tracer - Configuring PVSTMauro LucioAinda não há avaliações
- Casio Historia 1Documento8 páginasCasio Historia 1Roberto SpindolaAinda não há avaliações
- Ficha de Tarefas Global FuncoesDocumento6 páginasFicha de Tarefas Global Funcoesjonas_666Ainda não há avaliações
- Ts-129i Um - Pb231ts129iuma01a Rev BDocumento38 páginasTs-129i Um - Pb231ts129iuma01a Rev BHellington SantanaAinda não há avaliações
- Megômetro Eletrônico Megabrás Mi5500eDocumento21 páginasMegômetro Eletrônico Megabrás Mi5500eHugo Santana100% (3)
- Eb CMDB Business Value 6 StepsDocumento22 páginasEb CMDB Business Value 6 StepsWalter VallariAinda não há avaliações
- Como Conectar o Controlador Syntec CNC À Sua Rede LocalDocumento7 páginasComo Conectar o Controlador Syntec CNC À Sua Rede Localedu0% (1)
- Catalago Portas DoormaniaDocumento16 páginasCatalago Portas DoormaniaJonathanAinda não há avaliações
- Contracheque 9 2021Documento1 páginaContracheque 9 2021FRANCISCA oliAinda não há avaliações
- Método de Roubar Conta FF Explanado by CapuzinnDocumento1 páginaMétodo de Roubar Conta FF Explanado by CapuzinnKiraAinda não há avaliações
- Sergio 6Documento26 páginasSergio 6Octacilio SchiaviAinda não há avaliações
- Manual Ômega 7025Documento14 páginasManual Ômega 7025sandropetrilli100% (2)
- VivoDocumento1 páginaVivocristhian sepulchroAinda não há avaliações