Você também pode gostar
- Curso Grafana Apostila Aulas 1 A 9Documento58 páginasCurso Grafana Apostila Aulas 1 A 9Cristiano Godoy PradoAinda não há avaliações
- Minerando Dados Análise de Dados Com Python Usando PandasDocumento33 páginasMinerando Dados Análise de Dados Com Python Usando PandasAdriel Dos SantosAinda não há avaliações
- Banc 2Documento44 páginasBanc 2Gerailton NascimentoAinda não há avaliações
- Introdução e Modelos de Base de DadosDocumento19 páginasIntrodução e Modelos de Base de DadosFonseca D. Moma100% (1)
- 14 Hábitos de Desenvolvedores Altamente ProdutivosDocumento105 páginas14 Hábitos de Desenvolvedores Altamente Produtivoskhaleesi madu100% (1)
- PostgreSQL Prático PDFDocumento152 páginasPostgreSQL Prático PDFFelipe OliveiraAinda não há avaliações
- Paradigmas LinguagensDocumento76 páginasParadigmas Linguagensmarho contaAinda não há avaliações
- Informatica Basica em PDFDocumento42 páginasInformatica Basica em PDFTzeroAinda não há avaliações
- 1-Banco de DadosDocumento20 páginas1-Banco de DadosCesar Lima100% (1)
- Bases de DadosDocumento107 páginasBases de Dadospccardoso@gmail.comAinda não há avaliações
- Introducao Ao SAS Enterprise GuideDocumento160 páginasIntroducao Ao SAS Enterprise GuideAndre LuizAinda não há avaliações
- Banco de Dados MER e MRDocumento85 páginasBanco de Dados MER e MRjaferjrAinda não há avaliações
- 4 - Gestão de StockDocumento11 páginas4 - Gestão de StockCélia MartinsAinda não há avaliações
- Sistemas de Banco de DadosDocumento148 páginasSistemas de Banco de DadosWelzinLuis100% (1)
- Colaborar - Av - Introdução À Análise de Dados Com PythonDocumento6 páginasColaborar - Av - Introdução À Análise de Dados Com Pythonjover0% (1)
- LDDFRT 6yrhdyDocumento17 páginasLDDFRT 6yrhdyRafazDesignGame RafazDesignAinda não há avaliações
- Introducao Analise de DadosDocumento92 páginasIntroducao Analise de Dadosishigamikyo.sAinda não há avaliações
- Linguagem de Programação: Introdução A Biblioteca PandasDocumento56 páginasLinguagem de Programação: Introdução A Biblioteca PandasNozixAinda não há avaliações
- Linguagem de Programação: Introdução A Biblioteca PandasDocumento45 páginasLinguagem de Programação: Introdução A Biblioteca PandasAlberto GomesAinda não há avaliações
- Linguagem de ProgramaçãoDocumento10 páginasLinguagem de ProgramaçãoNozixAinda não há avaliações
- Abordagens de Aprendizagem de Maquina - Aprendizagem Não Supervisionada Aplicação Do K-MeansDocumento25 páginasAbordagens de Aprendizagem de Maquina - Aprendizagem Não Supervisionada Aplicação Do K-MeansSirleudo EvaristoAinda não há avaliações
- Ebook Manual PandasDocumento26 páginasEbook Manual PandasWellington SouzaAinda não há avaliações
- Linguagem de ProgramaçãoDocumento8 páginasLinguagem de ProgramaçãoAlberto GomesAinda não há avaliações
- Ebook PythonparaanalisededadosDocumento14 páginasEbook PythonparaanalisededadosSilas TorresAinda não há avaliações
- Aulas de Ls Semanas 1 2 e 3-1Documento47 páginasAulas de Ls Semanas 1 2 e 3-1Tércio MatsombeAinda não há avaliações
- Python Tema2 Parte7 BR v2Documento7 páginasPython Tema2 Parte7 BR v2Larissa CerqueiraAinda não há avaliações
- Guia Estudo Lpi 301Documento72 páginasGuia Estudo Lpi 301Joao KimmAinda não há avaliações
- PANDASDocumento6 páginasPANDAScostajoaopaulo113Ainda não há avaliações
- PTAmLYndSf-wJi2J3Wn ZG DAC5M4L6R1-ATTACHMENT PORDocumento22 páginasPTAmLYndSf-wJi2J3Wn ZG DAC5M4L6R1-ATTACHMENT PORakleyttonAinda não há avaliações
- Aula 20-02-24Documento7 páginasAula 20-02-24AlessandroAinda não há avaliações
- 12 Python - DicionariosDocumento34 páginas12 Python - DicionariosWendislau SilvaAinda não há avaliações
- Introdução Base DadosDocumento17 páginasIntrodução Base DadosLloydilson Gamboa Do ApertoAinda não há avaliações
- ÍndiceDocumento20 páginasÍndiceMaiv Manuel AugustoAinda não há avaliações
- Informática - Metadados de ArquivosDocumento4 páginasInformática - Metadados de ArquivosAntonio M.Ainda não há avaliações
- Aula 001 - Banco de DadosDocumento17 páginasAula 001 - Banco de DadosValdirene AlvesAinda não há avaliações
- 04 Hive LLAP HDP v02Documento64 páginas04 Hive LLAP HDP v02Daniel FuchsAinda não há avaliações
- Data DictionaryDocumento21 páginasData DictionaryDiego JordãoAinda não há avaliações
- Resumo Do Livro MysqlDocumento4 páginasResumo Do Livro MysqlAdenilton FerreiraAinda não há avaliações
- Resumo 01 - Introdução A Banco de DadosDocumento16 páginasResumo 01 - Introdução A Banco de DadosThiago MaiaAinda não há avaliações
- Big Data Mach Lear Recup Inf Luis Albano Nusp11167417Documento33 páginasBig Data Mach Lear Recup Inf Luis Albano Nusp11167417Luís Albano da SilvaAinda não há avaliações
- Assunto 4 - Bancos de Dados de Famílias de ColunasDocumento18 páginasAssunto 4 - Bancos de Dados de Famílias de ColunasGabriella CarolineAinda não há avaliações
- aHM0ddcrQzSzNHXXK M0Zw DAC5M3L4R1-ATTACHMENT PORDocumento21 páginasaHM0ddcrQzSzNHXXK M0Zw DAC5M3L4R1-ATTACHMENT PORakleyttonAinda não há avaliações
- Dados SemiestruturadosDocumento10 páginasDados Semiestruturadosvital_richard7289Ainda não há avaliações
- 22 Metadados de ArquivosDocumento3 páginas22 Metadados de ArquivoshenriqueAinda não há avaliações
- ImpressaoDocumento18 páginasImpressaoMatheus PinheiroAinda não há avaliações
- Ebook - bdV1-2012 - Historia Dos Bancos de Dados PDFDocumento71 páginasEbook - bdV1-2012 - Historia Dos Bancos de Dados PDFLeonardo Neves100% (1)
- SGBDRDocumento220 páginasSGBDRfernando castro machadoAinda não há avaliações
- TicsDocumento8 páginasTicsRyber KalosAinda não há avaliações
- 04 SlidesModulo4Documento122 páginas04 SlidesModulo4guidhuAinda não há avaliações
- 04 Hive LLAP HDP v03Documento65 páginas04 Hive LLAP HDP v03Daniel FuchsAinda não há avaliações
- Lista 3 - Carregando DadosDocumento1 páginaLista 3 - Carregando DadosCarol MartonAinda não há avaliações
- METADADOS TeoriaDocumento12 páginasMETADADOS TeoriaCintia De Azevedo LourençoAinda não há avaliações
- Atividade 1-Projeto IntegradorDocumento4 páginasAtividade 1-Projeto IntegradorBruno DominguesAinda não há avaliações
- Persistência de DadosDocumento18 páginasPersistência de DadosOsmar JuniorAinda não há avaliações
- Classificação Dos Bancos de Dados Não Relacionais (NoSQL)Documento17 páginasClassificação Dos Bancos de Dados Não Relacionais (NoSQL)Gabriella CarolineAinda não há avaliações
- Minicurso ENUCOMPI 2019Documento18 páginasMinicurso ENUCOMPI 2019RicoSuheteAinda não há avaliações
- 03 DataDocumento27 páginas03 DataWagner de Souza OliveiraAinda não há avaliações
- Apostila - Módulo 3 - Bootcamp Desenvolvedor (A) NODEJSDocumento30 páginasApostila - Módulo 3 - Bootcamp Desenvolvedor (A) NODEJSBruno OrtizAinda não há avaliações
- Conceitos de Banco de Dados e SGBDs - SlidesDocumento41 páginasConceitos de Banco de Dados e SGBDs - Slidesanizete7575Ainda não há avaliações
- 04 - Revisão Banco de DadosDocumento24 páginas04 - Revisão Banco de DadosCatarina Luise C.LAinda não há avaliações
- BaseDocumento6 páginasBaseRogério Maurício MiguelAinda não há avaliações
- Modelo DadosDocumento12 páginasModelo DadosCarlos Mendes JrAinda não há avaliações
- Tipos de Herança Do HibernateDocumento10 páginasTipos de Herança Do HibernateraroldoAinda não há avaliações
- 4 Recursos Dispon Veis Na Integra o Excel Python 1693430041Documento6 páginas4 Recursos Dispon Veis Na Integra o Excel Python 1693430041Mudança de HábitoAinda não há avaliações
- Apostila SQL 2962Documento43 páginasApostila SQL 2962mcardoso10Ainda não há avaliações
- Diploma GraduaçãoDocumento2 páginasDiploma GraduaçãoFilipe HenriqueAinda não há avaliações
- Apostila Introducao ShellDocumento22 páginasApostila Introducao ShellkrlseduAinda não há avaliações
- Devconf2018 Camila Campos ArquiteturaDocumento100 páginasDevconf2018 Camila Campos ArquiteturaFilipe HenriqueAinda não há avaliações
- Eventos BrmallsDocumento1 páginaEventos BrmallsFilipe HenriqueAinda não há avaliações
- 7 - Configurações Orçamento PDFDocumento2 páginas7 - Configurações Orçamento PDFFilipe HenriqueAinda não há avaliações
- 8 - Alterações Na Modulação PDFDocumento3 páginas8 - Alterações Na Modulação PDFFilipe HenriqueAinda não há avaliações
- CheckList VulnerabilidadeDocumento3 páginasCheckList VulnerabilidadeFilipe HenriqueAinda não há avaliações
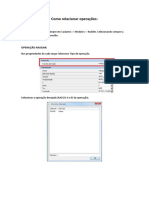
- 4 - Como Relacionar As OperaçõesDocumento5 páginas4 - Como Relacionar As OperaçõesFilipe HenriqueAinda não há avaliações
- 10 - Integração Biblioteca Builder e Biblioteca Studio PDFDocumento2 páginas10 - Integração Biblioteca Builder e Biblioteca Studio PDFFilipe HenriqueAinda não há avaliações
- Carteira de Vacinação fILIPEDocumento2 páginasCarteira de Vacinação fILIPEFilipe HenriqueAinda não há avaliações
- 6 - Como Ordenar A Operações PDFDocumento1 página6 - Como Ordenar A Operações PDFFilipe HenriqueAinda não há avaliações
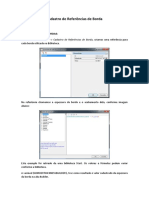
- 5 - Cadastro de Referencias de Borda PDFDocumento2 páginas5 - Cadastro de Referencias de Borda PDFFilipe HenriqueAinda não há avaliações
- ChatLog O02 - T21 2016 - 06 - 08 23 - 07Documento4 páginasChatLog O02 - T21 2016 - 06 - 08 23 - 07Filipe HenriqueAinda não há avaliações
- 9 - Definições de Volume PDFDocumento2 páginas9 - Definições de Volume PDFFilipe HenriqueAinda não há avaliações
- 2 - AtributosDocumento22 páginas2 - AtributosFilipe HenriqueAinda não há avaliações
- ChatLog O02 - T21 2016 - 06 - 15 21 - 04Documento1 páginaChatLog O02 - T21 2016 - 06 - 15 21 - 04Filipe HenriqueAinda não há avaliações
- MonografiaDocumento20 páginasMonografiaFilipe HenriqueAinda não há avaliações
- Questionario para Vaga - Java SeniorDocumento1 páginaQuestionario para Vaga - Java SeniorFilipe HenriqueAinda não há avaliações
- Dadoiuken Aushduasd Asd AsvxcvxcvdadDocumento1 páginaDadoiuken Aushduasd Asd AsvxcvxcvdadFilipe HenriqueAinda não há avaliações
- Salice Exedra - DerechaDocumento55 páginasSalice Exedra - DerechaEduardo Sanchez FontesAinda não há avaliações
- Programacao Orientada A Objetos Atividade ContextualizadaDocumento7 páginasProgramacao Orientada A Objetos Atividade ContextualizadaWillian LiraAinda não há avaliações
- Manual EcoSOlysDocumento2 páginasManual EcoSOlysWaudelia Gonçalves Dos Santos SilvaAinda não há avaliações
- Passo A Passo Pontomais 2.0Documento3 páginasPasso A Passo Pontomais 2.0André AlvesAinda não há avaliações
- PDF - Alta Produtividade No ExcelDocumento44 páginasPDF - Alta Produtividade No ExcelMichael LopesAinda não há avaliações
- Hpweb Jet AdminDocumento537 páginasHpweb Jet AdminsilivondelaAinda não há avaliações
- Convenções CamelCaseDocumento3 páginasConvenções CamelCaseEdh KlassenAinda não há avaliações
- Engenharia de Software - Aula 03 - 11SET2023Documento92 páginasEngenharia de Software - Aula 03 - 11SET2023cristiano soaresAinda não há avaliações
- Aula05-Projetos de Robótica Com o Arduínov2Documento21 páginasAula05-Projetos de Robótica Com o Arduínov2GiuseppeAinda não há avaliações
- 1 Introducao Ao Uso Do Sistema Ojs3-OthDocumento6 páginas1 Introducao Ao Uso Do Sistema Ojs3-OthPaulo MorenoAinda não há avaliações
- Como Usar o Google Chrome para Acessar Remotamente o Seu Computador PDFDocumento4 páginasComo Usar o Google Chrome para Acessar Remotamente o Seu Computador PDFsena1901@gmail.comAinda não há avaliações
- Curso 142580 Aula 11 v1Documento167 páginasCurso 142580 Aula 11 v1Leandro SousaAinda não há avaliações
- Plano de TrabalhoDocumento3 páginasPlano de TrabalhoDayane Souza SantosAinda não há avaliações
- Varnish-Cache: Velocidade e Disponibilidade para Aplicações WebDocumento19 páginasVarnish-Cache: Velocidade e Disponibilidade para Aplicações WebRafael ToledoAinda não há avaliações
- Exame Programacao Funcional SchemeDocumento1 páginaExame Programacao Funcional SchemeDaniel GimoAinda não há avaliações
- Acesso Remoto PDFDocumento28 páginasAcesso Remoto PDFMonica ReginaAinda não há avaliações
- Manual Do Usuário-Conjunto - v3.0Documento22 páginasManual Do Usuário-Conjunto - v3.0ruthAinda não há avaliações
- 1-TCC1 - Tiago Controle e AutomaçãoDocumento19 páginas1-TCC1 - Tiago Controle e AutomaçãoTiago IzumisawaAinda não há avaliações
- 1 Controlador LocalDocumento1 página1 Controlador LocalLEANDRO LUIZ LOPESAinda não há avaliações
- Bingo Do Alfabeto 28-01-2024Documento11 páginasBingo Do Alfabeto 28-01-2024Miria AlmiraliceAinda não há avaliações
- TISS - Gerar Hash Do XML Manualmente Com Notepad++ - Dellanio AlencarDocumento5 páginasTISS - Gerar Hash Do XML Manualmente Com Notepad++ - Dellanio AlencarEverton Mateus FernandesAinda não há avaliações
- Manual de Utilização OneDrive-SharePointDocumento9 páginasManual de Utilização OneDrive-SharePointLayanne Kelly Gomes SantosAinda não há avaliações
- Conhecimenos Gerais PF 2018Documento4 páginasConhecimenos Gerais PF 2018Kaína MaiaAinda não há avaliações
- Implantação ParceirosDocumento46 páginasImplantação Parceirosduartevictor8Ainda não há avaliações
- Manual Do Usuário Do Car Head Up Display C1Documento18 páginasManual Do Usuário Do Car Head Up Display C1Ricardo Bonetti TadenAinda não há avaliações