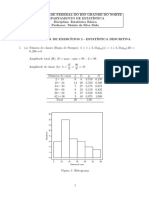
Você também pode gostar
- Gabarito 1Documento22 páginasGabarito 1Mauro MalundoAinda não há avaliações
- Mae (Estatistica)Documento11 páginasMae (Estatistica)AbmamudalziraAinda não há avaliações
- TTH 1 F 6869 EcDocumento3 páginasTTH 1 F 6869 Eceduardoroberto0309Ainda não há avaliações
- Lista3 EstatisticaDocumento9 páginasLista3 EstatisticaDiogo MendonçaAinda não há avaliações
- Trabalho 1 de Estatistica UCMDocumento8 páginasTrabalho 1 de Estatistica UCMEdmilson Horácio JoaquimAinda não há avaliações
- Aula-Matemática Aplicada À NegóciosDocumento6 páginasAula-Matemática Aplicada À NegóciosHerik sandro de souza martinsAinda não há avaliações
- Portifólio 1 - Pré-CalculoDocumento9 páginasPortifólio 1 - Pré-CalculocarlosAinda não há avaliações
- Trabalho de Campo 2 - EstatisticaDocumento5 páginasTrabalho de Campo 2 - EstatisticaPastor NamuehaAinda não há avaliações
- Probabilidade EstatisticaDocumento10 páginasProbabilidade EstatisticaAbel Chacanessa de JesusAinda não há avaliações
- Lista de Exerccios 01Documento3 páginasLista de Exerccios 01Syllas AguiarAinda não há avaliações
- Sheila Estatistica 2Documento4 páginasSheila Estatistica 2calumacicameAinda não há avaliações
- Trabalho de MatematicaDocumento18 páginasTrabalho de MatematicaAdamugi BraimoAinda não há avaliações
- Potenciação e Radiciação - Propriedades 1Documento13 páginasPotenciação e Radiciação - Propriedades 1MoisesNunesAinda não há avaliações
- Razonamiento AlgebraicoDocumento2 páginasRazonamiento AlgebraicoRudy A. Inofuente CaritaAinda não há avaliações
- Regressão QuadráticaDocumento5 páginasRegressão QuadráticaVolnei SoetheAinda não há avaliações
- Isabela Atividade Jogos Matematicos N2Documento10 páginasIsabela Atividade Jogos Matematicos N2Pedro SquirtleAinda não há avaliações
- Trabalho 04Documento4 páginasTrabalho 04Isadora Santana DemunerAinda não há avaliações
- Escoamento Superficial e EvaporaçãoDocumento16 páginasEscoamento Superficial e EvaporaçãoJúnia SoaresAinda não há avaliações
- Matematica 1 Serie Jossara Trabalho Dependencia 2016 1 EtapaDocumento5 páginasMatematica 1 Serie Jossara Trabalho Dependencia 2016 1 EtapaLuis FelipeAinda não há avaliações
- Teste 1 - M2 - Funções Periódicas (Trigonometria) (Apenas Escolha Múltipla)Documento3 páginasTeste 1 - M2 - Funções Periódicas (Trigonometria) (Apenas Escolha Múltipla)Romeu José Meneses TavaresAinda não há avaliações
- Questoes de Estatisticas PDFDocumento5 páginasQuestoes de Estatisticas PDFCamilaAinda não há avaliações
- Matemática Questões ResoluçõesDocumento8 páginasMatemática Questões ResoluçõeshenriqueAinda não há avaliações
- FGV2005 Administracao 1faseDocumento71 páginasFGV2005 Administracao 1faseJhovana Lameu da CruzAinda não há avaliações
- Lista de Exercícios - 02 (Medidas Diretas Teorias de Desvio - Capítulo 03) )Documento8 páginasLista de Exercícios - 02 (Medidas Diretas Teorias de Desvio - Capítulo 03) )João Pedro Lira100% (3)
- EXPONDocumento9 páginasEXPONTaís GarciaAinda não há avaliações
- Gabarito Da Lista 2 - Estatstica BsicaDocumento6 páginasGabarito Da Lista 2 - Estatstica BsicaDANIEL SILVAAinda não há avaliações
- Gabarito T1 Matfundamental 2012 1Documento3 páginasGabarito T1 Matfundamental 2012 1Gabriel ErnstAinda não há avaliações
- Exercícios de Estatística ResolvidosDocumento10 páginasExercícios de Estatística ResolvidosDionisio NicumaAinda não há avaliações
- Resolución EconometríaDocumento12 páginasResolución EconometríaBill Eglinton Flores MaricahuaAinda não há avaliações
- Resolucao Simulado Semana Basica ManhaDocumento8 páginasResolucao Simulado Semana Basica ManhagustosolindodemorrerAinda não há avaliações
- Mat Basica MoDocumento101 páginasMat Basica MoMatieloAinda não há avaliações
- 12 - EC - TH - Igualdade de Médias PopulacionaisDocumento4 páginas12 - EC - TH - Igualdade de Médias PopulacionaisAna CarolinaAinda não há avaliações
- Simplificar Os RadicaisDocumento3 páginasSimplificar Os RadicaisAdalgiza Vasconcelos75% (4)
- Gabarito Esa 2020 2021Documento28 páginasGabarito Esa 2020 2021Gustavo RibeiroAinda não há avaliações
- Cefet-Rj - 2019 - 2 Fase - Gab. Mat.Documento10 páginasCefet-Rj - 2019 - 2 Fase - Gab. Mat.André OliveiraAinda não há avaliações
- Cefet-Rj - 2019 - 2 Fase - Gab. Mat.Documento10 páginasCefet-Rj - 2019 - 2 Fase - Gab. Mat.André OliveiraAinda não há avaliações
- CEFET-RJ - 2019 - 2 Fase - Gab. Mat. - CompressedDocumento10 páginasCEFET-RJ - 2019 - 2 Fase - Gab. Mat. - CompressedJOSE CASTROAinda não há avaliações
- Cap. 6 - Momento de Inércia Ou Segundo MomentoDocumento16 páginasCap. 6 - Momento de Inércia Ou Segundo MomentoengepescaAinda não há avaliações
- Lista MatrizesDocumento6 páginasLista MatrizesLucília MoraesAinda não há avaliações
- Trabalho de CálculoDocumento8 páginasTrabalho de CálculoKposk NoramAinda não há avaliações
- 3 ListamatDocumento2 páginas3 ListamatraickAinda não há avaliações
- Exercicios Radiciacao Com-RespostaDocumento8 páginasExercicios Radiciacao Com-Respostaisaura lindeAinda não há avaliações
- Potencia Ç ÃoDocumento4 páginasPotencia Ç ÃoCarolina CerriAinda não há avaliações
- Resoluçao de QuestõesDocumento11 páginasResoluçao de QuestõesJason AlexandreAinda não há avaliações
- Gab2 L2 AjusteDocumento6 páginasGab2 L2 AjusteFrancisco Luiz Martins BezerraAinda não há avaliações
- fgvsp2012 AdministracaoDocumento79 páginasfgvsp2012 Administracaosilvaerikvieira300Ainda não há avaliações
- Lista 3Documento7 páginasLista 3belinhanascimento694Ainda não há avaliações
- ExRes - Interp e MMQDocumento11 páginasExRes - Interp e MMQasdasdAinda não há avaliações
- Felipe Galvao Do oDocumento11 páginasFelipe Galvao Do oFelipe Do oAinda não há avaliações
- Ficha de Revisão-Diagnóstico para o 7º AnoDocumento9 páginasFicha de Revisão-Diagnóstico para o 7º AnoAna Rute TeixeiraAinda não há avaliações
- Função QuadráticaDocumento4 páginasFunção QuadráticavnevesAinda não há avaliações
- Potencia Cao 1Documento4 páginasPotencia Cao 1Rodrigo SilvaAinda não há avaliações
- Matematica 2 Sexer 1 2023 2Documento4 páginasMatematica 2 Sexer 1 2023 2felipeoliesilvaAinda não há avaliações
- Apostila Matematica1 12 FUNCAO EXPONENCIAL CassioDocumento24 páginasApostila Matematica1 12 FUNCAO EXPONENCIAL CassioCristina Borges da SilvaAinda não há avaliações
- FGV2012 2 AdministracaoDocumento55 páginasFGV2012 2 AdministracaoSalustiano SalvadorAinda não há avaliações
- Index - Matemática BásicaDocumento36 páginasIndex - Matemática Básicam tiAinda não há avaliações
- UntitledDocumento1 páginaUntitledHENRIQUE JULIANI BALDEZAinda não há avaliações
- EstatísticaDocumento6 páginasEstatísticapedroAinda não há avaliações
- Associação Entre Variáveis QuantitativasDocumento39 páginasAssociação Entre Variáveis QuantitativasWilliam Guna DiasAinda não há avaliações
- Estatística - Intervalo de ConfiançaDocumento27 páginasEstatística - Intervalo de ConfiançaCamila GonçalvesAinda não há avaliações
- Mapa Mental Idd 33 Estatistica 200 1 - Vg4LzOQDocumento1 páginaMapa Mental Idd 33 Estatistica 200 1 - Vg4LzOQPriscila ZimerAinda não há avaliações
- Atividade Contextualizada de BioestatíticaDocumento5 páginasAtividade Contextualizada de BioestatíticaSuzy RodriguesAinda não há avaliações
- Aula 4 Medidas NumericasDocumento6 páginasAula 4 Medidas NumericasHercoAinda não há avaliações
- Carta de Controle Por Variáveis - TendênciaDocumento5 páginasCarta de Controle Por Variáveis - TendênciaFrancisco Jesuino Fernandes Jr.Ainda não há avaliações
- MAE0116 - Noções de EstatísticaDocumento11 páginasMAE0116 - Noções de EstatísticaWillian FugiharaAinda não há avaliações
- ATIVIDADE DE REVISÃO - 3º Trim - Parcial 2 - ContinuaçãoDocumento3 páginasATIVIDADE DE REVISÃO - 3º Trim - Parcial 2 - ContinuaçãozuannyAinda não há avaliações
- Estatística - Pedro Campos - 04.2Documento12 páginasEstatística - Pedro Campos - 04.2JessicaGuimaraesAinda não há avaliações
- Aula 04 - Unidade 1Documento81 páginasAula 04 - Unidade 1Tiago MouraAinda não há avaliações
- Pesquisa QualitativaDocumento30 páginasPesquisa QualitativaDaniel Dalla VecchiaAinda não há avaliações
- FF-Estatística e Calculadora - TI NspireDocumento26 páginasFF-Estatística e Calculadora - TI NspireMariassAinda não há avaliações
- Probabilidade Área 3Documento26 páginasProbabilidade Área 3Morgana FalabrettiAinda não há avaliações
- Livro-Texto - Unidade IIDocumento62 páginasLivro-Texto - Unidade IIMaybeeSanchezFerreyraAinda não há avaliações
- Prova1 GEOESTATÍSTICA - ResolvidaDocumento8 páginasProva1 GEOESTATÍSTICA - ResolvidaVitorNoviicAinda não há avaliações
- 2 Estatistica - Medidas de PosiçãoDocumento76 páginas2 Estatistica - Medidas de PosiçãoEmanuel CarlosAinda não há avaliações
- (A1) Avaliação Do Módulo 1 - Análise Exploratória de Dados - Revisão Da TentativaDocumento9 páginas(A1) Avaliação Do Módulo 1 - Análise Exploratória de Dados - Revisão Da TentativaSamuel NunesAinda não há avaliações
- EST031Documento2 páginasEST031BrunoLimaAinda não há avaliações
- Estatistica DescritivaDocumento150 páginasEstatistica DescritivaSamuel FigueiredoAinda não há avaliações
- 1 Lista de Exercícios - MAT020 - GabaritoDocumento4 páginas1 Lista de Exercícios - MAT020 - GabaritoGleiciane SantosAinda não há avaliações
- Slides Aula 2 Semana 1 Estatística DescritivaDocumento25 páginasSlides Aula 2 Semana 1 Estatística DescritivalavanholiAinda não há avaliações
- Ficha 1 - Estatística DiscritivaDocumento6 páginasFicha 1 - Estatística DiscritivaBruno CartasAinda não há avaliações
- Guiao de Correccao Exame de EstatísticaDocumento3 páginasGuiao de Correccao Exame de EstatísticawarrotaAinda não há avaliações