
Escolar Documentos
Profissional Documentos
Cultura Documentos
Apostila de Basis R3
Apostila de Basis R3
Enviado por
Paulo VitorDireitos autorais:
Formatos disponíveis
Você também pode gostar
- Exercicios Implementacao Banco de DadosDocumento17 páginasExercicios Implementacao Banco de DadosAnderson Venancio100% (1)
- Revisao Simulado OracleDocumento2 páginasRevisao Simulado OracleRodrigo MarcellAinda não há avaliações
- Instalação de Certificado Digital Na Strust - SAP BlogsDocumento3 páginasInstalação de Certificado Digital Na Strust - SAP BlogscarlosjanssenrsAinda não há avaliações
- Instalando o SAPROUTER para Conexão SNCDocumento6 páginasInstalando o SAPROUTER para Conexão SNCmkolombeskyAinda não há avaliações
- EF Conciliação AP X AR - V01Documento8 páginasEF Conciliação AP X AR - V01Renata RochaAinda não há avaliações
- PTBR - Configuration Guide - RCS - Nota Fiscal - v1.0Documento42 páginasPTBR - Configuration Guide - RCS - Nota Fiscal - v1.0WpmartinsAinda não há avaliações
- SAP RecClient para Gravações de Logs de Alterações Nas TabelasDocumento8 páginasSAP RecClient para Gravações de Logs de Alterações Nas TabelasValdevy PiresAinda não há avaliações
- DAPI-MM-20140311-20425-Estorno MIGO Entrega Futura (Ref. 17775)Documento10 páginasDAPI-MM-20140311-20425-Estorno MIGO Entrega Futura (Ref. 17775)Rogério Andrade Dos SantosAinda não há avaliações
- Abrir Tabelas IMG Na ProducaoDocumento5 páginasAbrir Tabelas IMG Na ProducaorenatalibaAinda não há avaliações
- BPP - MD04Documento23 páginasBPP - MD04gilmardmAinda não há avaliações
- Curso Crystal Report 8.5Documento28 páginasCurso Crystal Report 8.5Diogenes DausterAinda não há avaliações
- Mapos Ramon SilvaDocumento1 páginaMapos Ramon SilvaJardell NkAinda não há avaliações
- Aulas Capítulo 1 - Introdução - Conceitos e Principais Termos ETLDocumento60 páginasAulas Capítulo 1 - Introdução - Conceitos e Principais Termos ETLAnderson Phil100% (1)
- Treinamento Banco de Dados ToTVS PDFDocumento212 páginasTreinamento Banco de Dados ToTVS PDFPaulo MarcioAinda não há avaliações
- Prova IntegracaoBancoDados PDFDocumento4 páginasProva IntegracaoBancoDados PDFValter PatrickAinda não há avaliações
- Arquiteturas SAPDocumento17 páginasArquiteturas SAPDennerAndradeAinda não há avaliações
- ST para Material de ConsumoDocumento3 páginasST para Material de ConsumoMarcelo PaivaAinda não há avaliações
- Enhancements & ModificaçõesDocumento53 páginasEnhancements & ModificaçõesRoger SudatiAinda não há avaliações
- Manual - Usuário - SAP MM (Cadastro de Fornecedor)Documento19 páginasManual - Usuário - SAP MM (Cadastro de Fornecedor)LUIZA100% (2)
- 2-Apostila Basis - SgarbiDocumento137 páginas2-Apostila Basis - SgarbiFabiano AlvesAinda não há avaliações
- Cats Sap PTDocumento18 páginasCats Sap PTLuan David J. BatistaAinda não há avaliações
- MM 2 - Administração de Materiais - Aula 2 - Exibir Reservas de Materiais - MB23Documento6 páginasMM 2 - Administração de Materiais - Aula 2 - Exibir Reservas de Materiais - MB23Diogo SouzaAinda não há avaliações
- Aula 02Documento21 páginasAula 02Madson CruzAinda não há avaliações
- MM 2 - Administração de Materiais - Aula 2 - Criar Material - MM01Documento11 páginasMM 2 - Administração de Materiais - Aula 2 - Criar Material - MM01Diogo SouzaAinda não há avaliações
- Domicilio Fiscal SAPDocumento2 páginasDomicilio Fiscal SAPRogerio NereAinda não há avaliações
- Apostila Completa Curso de Introdu o Ao SAP 1561952341Documento74 páginasApostila Completa Curso de Introdu o Ao SAP 1561952341Jeferson Massari100% (1)
- TCC Erpsappp 170105110616Documento120 páginasTCC Erpsappp 170105110616Leandro SapAinda não há avaliações
- IOP-ADM-UNI-032 INVENTÁRIO ROTATIVO (PERIÓDICO) Rev 02Documento46 páginasIOP-ADM-UNI-032 INVENTÁRIO ROTATIVO (PERIÓDICO) Rev 02Kilson CalandAinda não há avaliações
- Especificaçao Funcional - SCM - C036 - CaracterísticasDocumento4 páginasEspecificaçao Funcional - SCM - C036 - CaracterísticasMarcelo Pires BatalhaAinda não há avaliações
- SAP MM - Processo de CotaçãoDocumento2 páginasSAP MM - Processo de CotaçãoAndre Gonçalves PereiraAinda não há avaliações
- Como Encontrar Exits e Bapis para Uma TransaçãoDocumento11 páginasComo Encontrar Exits e Bapis para Uma TransaçãoAna Maria FerrazziAinda não há avaliações
- 1J5 S4hana2021 BPD PT BRDocumento57 páginas1J5 S4hana2021 BPD PT BRCleuvison Butinhao100% (1)
- Hierarquia de Documentos para NewGLDocumento15 páginasHierarquia de Documentos para NewGLJusapfiAinda não há avaliações
- Introdução Ao Sap - Fbl1nDocumento10 páginasIntrodução Ao Sap - Fbl1nDaut PoloAinda não há avaliações
- Aula 07 - Lançamento Fiscal - Miro - Mm-Fi. OkDocumento11 páginasAula 07 - Lançamento Fiscal - Miro - Mm-Fi. OkLuiz GonzagaAinda não há avaliações
- Algumas NF-e Não Estão Indo para o GRC. - SAP Q&ADocumento4 páginasAlgumas NF-e Não Estão Indo para o GRC. - SAP Q&ARenata RochaAinda não há avaliações
- Banksync Manual de ImplantaçãoDocumento60 páginasBanksync Manual de ImplantaçãoDiogo Oliveira SilvaAinda não há avaliações
- AFAB - Lançar DepreciaçãoDocumento8 páginasAFAB - Lançar DepreciaçãoQueli BelchiorAinda não há avaliações
- Apostila Arquitetura - e - InstalaçãoDocumento30 páginasApostila Arquitetura - e - InstalaçãoxxmichelxxAinda não há avaliações
- Academia Sap SD Aluno 3008Documento334 páginasAcademia Sap SD Aluno 3008Amanda AraújoAinda não há avaliações
- Como Localizar Nota Fiscal Eletrônica No SAP NFe Usando A Transação J1BNFEDocumento17 páginasComo Localizar Nota Fiscal Eletrônica No SAP NFe Usando A Transação J1BNFEdude28spAinda não há avaliações
- MMCC - Ampliação e Criação de Materiais em MassaDocumento7 páginasMMCC - Ampliação e Criação de Materiais em MassarobertonewsAinda não há avaliações
- Integrador DFe Conector SAP 60 Manual PTDocumento36 páginasIntegrador DFe Conector SAP 60 Manual PTMauricio TakaoAinda não há avaliações
- 3 PDFDocumento17 páginas3 PDFricardo_motta_silvaAinda não há avaliações
- Output Management - Configurando o DANFE (Adobe Forms)Documento16 páginasOutput Management - Configurando o DANFE (Adobe Forms)Daniel FrancoAinda não há avaliações
- Treinamento ABAP-HR ExerciciosDocumento13 páginasTreinamento ABAP-HR ExerciciosMarcos SchmidtAinda não há avaliações
- SAP Netweaver Integration - LISTA de CURSODocumento9 páginasSAP Netweaver Integration - LISTA de CURSOdiegowiskAinda não há avaliações
- Industrialização Por Conta e Ordem de Terceiro - Fácil123Documento4 páginasIndustrialização Por Conta e Ordem de Terceiro - Fácil123Maria CunhaAinda não há avaliações
- Treinamento Sap Apo Planejamento de FornecimentoDocumento103 páginasTreinamento Sap Apo Planejamento de FornecimentoElisangela Henrique Marques Dos Santos100% (1)
- Apresentação SAP Fiori - AndroidDocumento21 páginasApresentação SAP Fiori - AndroidIvanilson XavierAinda não há avaliações
- MIT041 - Especificação Do Processo - SIGALOJA - GAP - Escopo - v4Documento12 páginasMIT041 - Especificação Do Processo - SIGALOJA - GAP - Escopo - v4Paulo RafaelAinda não há avaliações
- MRP Live S4 HanaDocumento7 páginasMRP Live S4 HanaPaulo Celso BarbosaAinda não há avaliações
- ManualDocumento100 páginasManualwellington felipe silvaAinda não há avaliações
- Aula 09 - Análise de Partidas de Clientes e Fornecedores - Fbl5n e Fbl1n. OkDocumento12 páginasAula 09 - Análise de Partidas de Clientes e Fornecedores - Fbl5n e Fbl1n. OkLuiz GonzagaAinda não há avaliações
- NW - Espec - Integração CPJ X SAP - 4.0Documento32 páginasNW - Espec - Integração CPJ X SAP - 4.0Rafael Knevels100% (1)
- Aula 09 - Felipe SAPDocumento12 páginasAula 09 - Felipe SAPDaniel BeloAinda não há avaliações
- Guia para Impressão de Logotipos em Impressoras Zebra No SAPDocumento15 páginasGuia para Impressão de Logotipos em Impressoras Zebra No SAPluizhm0reiraAinda não há avaliações
- Variável para Atualização Dinâmica Do Ano e Mês Corrente Durante A Execução de Um JOBDocumento3 páginasVariável para Atualização Dinâmica Do Ano e Mês Corrente Durante A Execução de Um JOBNeulersAinda não há avaliações
- Linux CentOS 7 - Guia PráticoDocumento3 páginasLinux CentOS 7 - Guia PráticoLuiz Antônio100% (1)
- Bloco K - Guia de Referência - Linha DatasulDocumento32 páginasBloco K - Guia de Referência - Linha Datasulevan100% (1)
- SQVIDocumento9 páginasSQVIHenriqueAinda não há avaliações
- Subcontratacao Com ICMSDocumento8 páginasSubcontratacao Com ICMSdiogolfm27Ainda não há avaliações
- Documentação Configuração NFe InboundDocumento13 páginasDocumentação Configuração NFe InboundMarcos PauloAinda não há avaliações
- Apostila Transporte de QueryDocumento12 páginasApostila Transporte de QueryValdir RocconAinda não há avaliações
- Criar JOB SAPDocumento5 páginasCriar JOB SAPValdevy PiresAinda não há avaliações
- Apresentacao TreportDocumento11 páginasApresentacao TreportEdson BorgesAinda não há avaliações
- Criação de Relatórios em DelphiDocumento10 páginasCriação de Relatórios em DelphiUbirajara Ferreira da SilvaAinda não há avaliações
- Funcoes TriggersDocumento27 páginasFuncoes TriggerseduardosantosAinda não há avaliações
- Banco de Dados Com MySQLDocumento20 páginasBanco de Dados Com MySQLBreno Nogueira Botelho NoccioliAinda não há avaliações
- Apostila - Módulo 3 - Técnico de Banco de Dados PDFDocumento69 páginasApostila - Módulo 3 - Técnico de Banco de Dados PDFAndre FelipeAinda não há avaliações
- Comandos SQL (Continuacao)Documento3 páginasComandos SQL (Continuacao)Paulo EduardoAinda não há avaliações
- Tema 6 - Consulta Com Várias Tabelas No POSTGRESQLDocumento47 páginasTema 6 - Consulta Com Várias Tabelas No POSTGRESQLGabriel CerqueiraAinda não há avaliações
- 9 - Interacao Entre Tarefas - Problemas de CoordenacaoDocumento25 páginas9 - Interacao Entre Tarefas - Problemas de CoordenacaoLuis Felipe ZaguiniAinda não há avaliações
- SQL Server 2000Documento117 páginasSQL Server 2000Daniel Pereira ComimAinda não há avaliações
- Curso Banco de DadosDocumento22 páginasCurso Banco de DadosCarol HonemannAinda não há avaliações
- Exercicios DML - Comando InsertDocumento12 páginasExercicios DML - Comando InsertUnibeducafro EducafroAinda não há avaliações
- Curso 5653 Aula 05 v1Documento173 páginasCurso 5653 Aula 05 v1rodrigokamenachAinda não há avaliações
- 8 Modelagem e Desenvolvimento de Banco de DadosDocumento15 páginas8 Modelagem e Desenvolvimento de Banco de DadosFabio Henrique LimaAinda não há avaliações
- TMS BT Preenchimento Do Campo X2 DISPLAY TPPAXJDocumento12 páginasTMS BT Preenchimento Do Campo X2 DISPLAY TPPAXJGilberto Franco JuniorAinda não há avaliações
- DataWarehouse - Passo A PassoDocumento339 páginasDataWarehouse - Passo A PassoJose Ferreira100% (1)
- Estimativa DespesaDocumento21 páginasEstimativa DespesaBruno BittencourtAinda não há avaliações
- Construção de Tabelas Com Intervalo de ClasseDocumento13 páginasConstrução de Tabelas Com Intervalo de ClasseJoão Pedro BarbosaAinda não há avaliações
- CONSULTAS SQL - INTELIGÊNCIA DE NEGÓCIOS - V12 - AP01 Ok PDFDocumento50 páginasCONSULTAS SQL - INTELIGÊNCIA DE NEGÓCIOS - V12 - AP01 Ok PDFFlavio Almeida100% (1)
- 09 Plano de Backup Senac 1.7 Jun2017Documento11 páginas09 Plano de Backup Senac 1.7 Jun2017JoJo Nascimento LemosAinda não há avaliações
- Aula 05: Desenvolvimento de Software para Concursos - Curso RegularDocumento92 páginasAula 05: Desenvolvimento de Software para Concursos - Curso RegularcarthurpsAinda não há avaliações
- Ufcd 5083Documento2 páginasUfcd 5083pedro mirandaAinda não há avaliações








































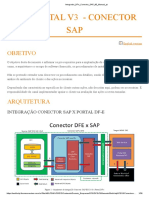













































Apostila de Basis R3
Apostila de Basis R3
Enviado por
Paulo VitorDireitos autorais
Formatos disponíveis
Compartilhar este documento
Compartilhar ou incorporar documento
Você considera este documento útil?
Este conteúdo é inapropriado?
Denunciar este documentoDireitos autorais:
Formatos disponíveis
Apostila de Basis R3
Apostila de Basis R3
Enviado por
Paulo VitorDireitos autorais:
Formatos disponíveis
BASIS
Administrando o SAP R/3
Workshop Basis
Apostila de Administração SAP Basis.
Autor Leonardo Campos Castilho
Cópia Controlada Page 1 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Instance R/3
Mandantes R/3 (ou clients R/3) são organizados independentemente. Cada um tem seu próprio ambiente de
dados, com seus dados mestres e dados transacionais, dados de usuário e também seus próprios parâmetros
de customização.
Usuários em diferentes mandantes coexistem em um mesmo sistema R/3, mas seus dados são isolados e não
podem ser acessados de outro mandante. Somente usuários com as autorizações necessárias podem
visualizar ou processar dados em um mandante específico. Esse conceito de isolamento se reflete na
estruturas das tabelas, tanto em nível de aplicação quanto de customização, que é um nível de adaptação
dependente de cada implementação.
O mandante 000 é definido como o padrão SAP e não pode ser modificado. Ele serve como um modelo para a
criação de outros mandantes.
O número máximo de mandantes em um sistema R/3 é de 997, número dificilmente atingido.
Uma instancia (instance) é um grupo de serviços do R/3 que são iniciados e finalizados em conjunto.
Normalmente, o termo é associado a um dispatcher e seus wp´s correspondentes, mas também pode ser
considerado uma instancia um servidor executando somente o serviço de gateway do SAP.
Central instance (instância central) é a combinação de um dispatcher com todos os processos do R/3, ou seja,
a combinação DVEBMGS. Como exemplo disso, temos a instância C na figura acima, que mostra todos os
processos do R/3 sendo executados, com a exceção do G (gateway), mas que também deve estar presente
em uma central instance.
Um servidor R/3 de aplicação consiste principalmente de um dispatcher, seus wp´s associados e seu banco
de memória.
Em um ambiente R/3, os conceitos “cliente” e “servidor” são geralmente abordados como software, desse
modo vários servidores de aplicação podem ser executados em um só computador.
Do ponto de vista de hardware, entretanto, um servidor de aplicação pode ser definido como um computador
com pelo menos um dispatcher, configuração que também é chamada de instância de dialog.
As seguintes restrições se aplicam ao número permitido para cada tipo de work process:
- Dialog: cada dispatcher precisa de, pelo menos, dois wp´s de dialog
- Spool: pelo menos um por sistema R/3, e os dispatchers podem ter mais de um spool
- Update: pelo menos um por sistema R/3, e os dispatchers podem ter mais de um update
- Background : pelo dois um por sistema R/3, e os dispatchers podem ter mais backgrounds
- Enqueue : somente um wp de enqueue pode existir em um sistema R/3
Cópia Controlada Page 2 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Uma vez estabelecida a conexão com um dispatcher através do SAPGUI, um sessão no sistema R/3 é
iniciada para o usuário
Os dados são passados do SAPGUI para o dispatcher usando o protocolo padrão do SAPGUI, que é
transmitido sobre TCP/IP, e o seguinte processo é iniciado:
- o dispatcher classifica o pedido e coloca-o na fila de pedidos apropriada
- os pedidos são passados por ordem de chagada (FIFO) para um wp de dialog que estiver livre
- o subprocesso taskhandler restaura o contexto do usuário num passo chamado “roll-in”. Esse
contexto contém os dados principais das transações a serem executadas por esse usuário e
também as autorizações específicas do usuário
- o taskhandler chama, então, o processador dynpro para a conversão da tela em variáveis ABAP
- o processador ABAP executa o código referente ao módulo “process after input” (PAI) da tela
precedente seguido do módulo “process before output” (PBO) da tela subsequente. Caso seja
necessário, ele também se comunica com o banco de dados.
- o processador dynpro então converte as variáveis ABAP novamente em campos de tela. Quando
o dynpro é finalizado, o taskhandler assume novamente o processamento.
- O contexto do usuário é novamente armazenado na memória compartilhada dos WP´s.
- Por fim, o resultado do processamento é retornado ao SAPGUI através do dispatcher e o WP´s
que tratou do pedido pode ser liberado novamente
Cópia Controlada Page 3 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Se a transação envolver mais de uma tela, a sequência de passos de dialog descrita anteriormente é,
geralmente, processada por diversos WP´s de dialog diferentes. Essa característica é conhecida como
multiplexação de work process.
Cada pedido de dialog é primeiro colocado pelo dispatcher na fila de pedidos de dialog, de onde ele poderá
ser assumido por um WP de dialog disponível.
O WP não realiza operações no banco de dados. Em vez disso, ele repassa comandos para os processos de
banco de dados através da interface de programação do próprio banco.
Cópia Controlada Page 4 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Start/Stop R/3
Um usuário do sistema operacional loga usando o usuário <sid>adm
Para iniciar o R/3, execute o script de inicialização startsap_<host>_instance_no> a partir do home directory
do usuário <sid>adm. O script startsap_<host>_instance_no> tem um alias “startsap”
startsap inicia o processo sopsocol, que é o coletor de estatísticas de dados do sistema operacional, caso o
mesmo não esteja sendo executado
startsap, então, chama o satrtdb, que inicia o banco de dados, caso o mesmo ainda não estaja sendo
executado.
Depois disso, o startsap inicia a central instance
O administrador pode iniciar instancias adicionais e servidores de aplicação. Para iniciar instancias
independentes do banco de dados, use o startsap:
- startsap r3: verifica se o banco está no ar: se estiver, só a instancia é iniciada
- startsap db: só o banco de dados
- startsap all: default, inicia o banco e a instância
Cópia Controlada Page 5 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O gráfico acima mostra a inicialização do R/3 em maior detalhe.
Passos para a inicialização:
O script startsap chama o programa SAPSTART
O programa SAPSTART lê o perfil de inicialização da instância e inicia os componentes do R/3 listados e
outros serviços
Em uma central instance, SAPSTART inicia os serviços message server, dispatcher, collector e sender. Em
uma instância de dialog, somente o sender e o dispatcher são iniciados. O collector e o sender são usados
para implementar os serviços centrais do log do sistema R/3.
O dispatcher, então, assume o papel de pai dos processos a serem criados. Para isso, ele cria processos
filhos como o gateway e os work processes, de acordo com os perfis de inicialização correspondentes.
Os work processes, então , se conectam ao banco de dados, que, nesse momento, já deve ter sido
inicializado.
Os ID´s de vários processos do R/3 na figura acima mostram a ordem de execução na inicialização.
- sapstart cria o dispatcher, o collector e o sender
- saposcol é iniciado diretamente do script startsap
- o processo init do UNIX tem o ID 1
De modo a construir um procedimento de inicialização, a sequência de leitura dos parâmetros (também
conhecida como sequência de substituição de parâmetros) é definida como:
- o R/3 processa os parâmetros como definido em seu código fonte no kernel R/3 (disp+work)
- o perfil default é lido, e os parâmetros já definidos através do código fonte do kernel são
substituídos pelos correspondentes encontrados no perfil default
- o perfil da instancia é lido e, do mesmo modo, sobreescreve os valores anteriores
Cópia Controlada Page 6 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Esse procedimento garante que os parâmetros de sistema vão refletir as configurações das três fontes.
Durante a inicialização da base de dados, o startsap chama o script startdb, o qual acessa um arquivo de log
para armazenar o processo de inicialização do banco.
Todas os eventos importantes no processo, como inicialização e parada do banco de dados e qualquer erro
na base, são anotados no arquivo de alerta do Oracle. Maiores detalhes são anotados no arquivo de trace.
Cópia Controlada Page 7 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Visão Geral dos Trace Logs
O gráfico acima mostra os possíveis pontos de falha durante o processo de inicialização do R/3.
Cópia Controlada Page 8 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Se ocorrer algum erro, a informação correta deve ser encontrada para se diagnosticar o problema. Abaixo
comentamos algumas das possibilidades de erro:
Se o acesso a recursos como os scripts startsap ou startdb, a causa pode ser, por exemplo:
- as permissões de sistema de arquivo não estão corretas
- o usuário <sid>adm não foi criado corretamente
Se o banco de dados não foi iniciado ou o WP não pode se conectar ao banco, o R/3 não pode ser
inicializado. Algumas das causas que podem levar a base de dados a falhar na inicialização são:
- as variáveis de ambiente não foram configuradas corretamente
- a base de dados está sendo executada no modo DBA
- os arquivos da base estão corrompidos
- os arquivos de dados foram renomeados no banco mas não no sistema operacional
Se o R/3 não inicia, podemos verificar se:
- o kernel do UNIX não foi configurado corretamente
- existem erros no sistema de gerenciamento de memória
- os perfis do R/3 não estão acessíveis
Existem duas razões principais para parar um sistema R/3:
Parada planejada:
- para alterar os parâmetros dos perfis
- para realizar uma atualização do R/3
- para manutenção do sistema operacional ou do hardware
Paradas não planejadas podem ocorrer por diversos fatores (por exemplo, um problema físico nos discos)
Antes de parar o R/3, o administrador deve verificar:
- visão geral dos jobs
- verificar se nenhum job de background de qualquer servidor de aplicação está ativo ou sendo
inicializado por processo externo
- visão dos processos
- verificar se o processo BTC está sendo executado nos servidores de aplicação
Cópia Controlada Page 9 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
- verificar a execução de processos de batch input
- verificar se alguma atualização está pendente no banco de dados
O administrador deverá decidir se interrompe ou não os processos que estiverem pendentes. Um aviso
através de uma mensagem de sistema também pode ser útil.
Para parar um sistema R/3, o administrador deve:
- parar os servidores de aplicação (instâncias de dialog e também a central), o que pode ser feito de
dois modos: através do CCMS ou usando o script stopsap_<host>_<instance_no> ou também
através do alias: stopsap r3
- parar a base de dados usando o stopsap all, o stopdb, pelo Oracle Manager ou pelo SAPDBA
Se a reconexão à base de dados (databese reconnect) estiver configurada no R/3, não é necessário parar um
servidor de aplicação antes de um backup offline. Os buffers do R/3 não são esvaziados, e os work process
configuram o status “reconnect” até que a base de dados seja reinicializada
Durante um backup offline, a execução do banco de dados deve ser interrompida (shut down), e os WP´s
receberão da base de dados uma mensagem com código de erro “reconnect”
Cópia Controlada Page 10 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cada vez que um pedido acontecer ou que o tempo de espera expire, o WP tentará se reconectar ao banco,
por isso, antes da cada backup offline, o administrador deverá mandar uma mensagem avisando aos usuários.
Se a base de dados não puder ser finalizado, a casa pode ser por:
- o banco de dados está fazendo um rollback de transações abortadas pela finalização do R/3.
Dependendo da última atualização do banco de dados em disco, esse processo pode levar muito
tempo.
- um backup online está sendo executado, e deve-se esperar que o mesmo termine
Se não existir nenhuma razão natural para a demora, uma análise mais detalhada deve ser efetuada para se
decidir o que fazer.
Cópia Controlada Page 11 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Clients R/3
Mandantes R/3 (ou clients R/3) são organizados independentemente. Cada um tem seu próprio ambiente de
dados, com seus dados mestres e dados transacionais, dados de usuário e também seus próprios parâmetros
de customização.
Usuários em diferentes mandantes coexistem em um mesmo sistema R/3, mas seus dados são isolados e não
podem ser acessados de outro mandante. Somente usuários com as autorizações necessárias podem
visualizar ou processar dados em um mandante específico. Esse conceito de isolamento se reflete na
estruturas das tabelas, tanto em nível de aplicação quanto de customização, que é um nível de adaptação
dependente de cada implementação.
O mandante 000 é definido como o padrão SAP e não pode ser modificado. Ele serve como um modelo para a
criação de outros mandantes.
O número máximo de mandantes em um sistema R/3 é de 997, número dificilmente atingido.
Cópia Controlada Page 12 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Quando um processo SAPGUI é iniciado em uma estação, um comando é enviado indicando uma das
seguintes ações:
- Um dispatcher específico deve ser acessado diretamente
- Um logon no message server deve ser efetuado para se usar o balanceamento de carga
Quando do uso do logon balance, o message server retorna o endereço IP e o número da instancia (instance)
de um dispatcher especítico. O número de dispatchers disponíveis é configurado no sistema. O
balanceamento de carga (logon balance) é útil para associar certos usuários a servidores específicos.
O message server retorna o endereço IP do dispatcher escolhido, tipicamente aquele que estiver com melhor
tempo de resposta nos últimos cinco minutos, estatística que é armazenada no workload data (dados de
utilização do servidor).
O processo de front-end (SAPGUI) se conecta, então, ao dispatcher designado, que escolhe um work process
(wp) de dialog para atender o logon do usuário, comparando os dados da chamada com as informações
contidas nos dados do usuário no sistema.
Se as informações são compatíveis com os dados do usuário no sistema, o logon é permitido, e esse
dispatcher e seus wp´s serão usados durante toda a sessão.
Se o usuário deslogar e logar novamente, o logon balance pode fazer com que o message server selecione
outro dispatcher para o usuário.
Cópia Controlada Page 13 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Uma instancia (instance) é um grupo de serviços do R/3 que são iniciados e finalizados em conjunto.
Normalmente, o termo é associado a um dispatcher e seus wp´s correspondentes, mas também pode ser
considerado uma instancia um servidor executando somente o serviço de gateway do SAP.
Central instance (instância central) é a combinação de um dispatcher com todos os processos do R/3, ou seja,
a combinação DVEBMGS. Como exemplo disso, temos a instância C na figura acima, que mostra todos os
processos do R/3 sendo executados, com a exceção do G (gateway), mas que também deve estar presente
em uma central instance.
Um servidor R/3 de aplicação consiste principalmente de um dispatcher, seus wp´s associados e seu banco
de memória.
Em um ambiente R/3, os conceitos “cliente” e “servidor” são geralmente abordados como software, desse
modo vários servidores de aplicação podem ser executados em um só computador.
Do ponto de vista de hardware, entretanto, um servidor de aplicação pode ser definido como um computador
com pelo menos um dispatcher, configuração que também é chamada de instância de dialog.
As seguintes restrições se aplicam ao número permitido para cada tipo de work process:
- Dialog: cada dispatcher precisa de, pelo menos, dois wp´s de dialog
- Spool: pelo menos um por sistema R/3, e os dispatchers podem ter mais de um spool
- Update: pelo menos um por sistema R/3, e os dispatchers podem ter mais de um update
- Background : pelo dois um por sistema R/3, e os dispatchers podem ter mais backgrounds
- Enqueue : somente um wp de enqueue pode existir em um sistema R/3
Cópia Controlada Page 14 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Uma vez estabelecida a conexão com um dispatcher através do SAPGUI, um sessão no sistema R/3 é
iniciada para o usuário
Os dados são passados do SAPGUI para o dispatcher usando o protocolo padrão do SAPGUI, que é
transmitido sobre TCP/IP, e o seguinte processo é iniciado:
- o dispatcher classifica o pedido e coloca-o na fila de pedidos apropriada
- os pedidos são passados por ordem de chagada (FIFO) para um wp de dialog que estiver livre
- o subprocesso taskhandler restaura o contexto do usuário num passo chamado “roll-in”. Esse
contexto contém os dados principais das transações a serem executadas por esse usuário e
também as autorizações específicas do usuário
- o taskhandler chama, então, o processador dynpro para a conversão da tela em variáveis ABAP
- o processador ABAP executa o código referente ao módulo “process after input” (PAI) da tela
precedente seguido do módulo “process before output” (PBO) da tela subsequente. Caso seja
necessário, ele também se comunica com o banco de dados.
- o processador dynpro então converte as variáveis ABAP novamente em campos de tela. Quando
o dynpro é finalizado, o taskhandler assume novamente o processamento.
- O contexto do usuário é novamente armazenado na memória compartilhada dos WP´s.
- Por fim, o resultado do processamento é retornado ao SAPGUI através do dispatcher e o WP´s
que tratou do pedido pode ser liberado novamente
Cópia Controlada Page 15 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Se a transação envolver mais de uma tela, a sequência de passos de dialog descrita anteriormente é,
geralmente, processada por diversos WP´s de dialog diferentes. Essa característica é conhecida como
multiplexação de work process.
Cada pedido de dialog é primeiro colocado pelo dispatcher na fila de pedidos de dialog, de onde ele poderá
ser assumido por um WP de dialog disponível.
O WP não realiza operações no banco de dados. Em vez disso, ele repassa comandos para os processos de
banco de dados através da interface de programação do próprio banco.
CCMS – Visão geral
O CCMS (Computing Center Management System) é um parte do sistema de administração basis do R/3 que
fornece ferramentas para administração de:
- performance do sistema R/3
- banco de dados e backups
- carga de trabalho do sistema
- velocidade de resposta
- segurança dos dados
Ele pode ser usado para analisar e distribuir a carga de utilização dos usuários e criar relatórios de consumo
de recursos pelo sistema. O CCMS também fornece ferramentas gráficas para monitoramento e
gerenciamento.
O CCMS também fornece os meios para configurar o gerenciamento 24h por dia do controle dos modos de
operação e das instâncias.
Antes de ser usado, o CCMS deve ser configurado corretamente
Antes de ser possível trabalhar com o CCMS, seu ambiente deve ser organizado corretamente. A consistência
e a precisão do funcionamento do CCMS dependem de como ele é configurado inicialmente pelo usuário.
Cópia Controlada Page 16 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
A configuração do CCMS envolve os seguintes passos:
- manutenção correta dos perfis
- definição de, pelo menos, um modo de operação
- designação das definições das instâncias na instalação
- designação das definições das instâncias para cada modo de operação
- definição da tabela de agendamento para os modos de operação
Se as instâncias, os modo de operação ou as tabelas de agendamento não estiverem configuradas
corretamente, o CCMS não irá fornecer informações precisas.
Para a definição das propriedades das instâncias, o R/3 usa os arquivos de perfil (profile), que armazenam as
configurações a serem utilizadas pelo sistema quando da inicialização.
Os parâmetros nos perfis estão associados a recursos, como memória principal, perfil da inicialização (startup)
e da instância, que são configurados automaticamente no perfil default durante a instalação do R/3
Quando a primeira instância do R/3 é criada, os trÊs perfis (default, startup e da instância) são gerados. Na
instalação de instâncias subsequêntes, o perfil default existente é atualizado
Em um sistema distribuído formado por servidores de aplicação de uma mesma plataforma, um diretório
compartilhado para os perfis pode ser criado
Cópia Controlada Page 17 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para se alterar perfis de diferentes servidores de aplicação, os perfis devem ser armazenados na base de
dados. Entretanto, depos da instalçação, os perfis são armazenados no sistema de arquivos. Então, os perfis
devem se importados para que possam ser gerenciados de dentro do R/3.
Depois que os perfis são importados, uma verificação dos parâmetros é efetuada. Os perfis, então, são
armazenados automaticamente na base de dados e sua ativação é feita através do armazenamento também
no sistema de arquivos.
Diferentes versões de um perfil podem ser armazenados na base de dados com o mesmo nome, alterando-se
somente o número da versão do arquivo. Cada vez que uma alteração for salva, um novo número de versão
será criado. A base de dados, então, conterá diferentes cópias de um mesmo perfil, assim como o histórico
documentado de modificação dos parâmetros.
Apesar de estar armazenado no banco de dados, o perfil usado na inicialização de um servidor R/3 é o que
está armazenado no sistema de arquivos. As alterações dos perfis em sistema de arquivos são monitoradas
pelo R/3, e um histórico de modificação (quem, quando, o quê) é documentado pelo próprio sistema
Normalmente, os parâmetros default sugeridos pelo sistema são válidos e só devem ser alterados sob
sugestão da SAP ou de um parceiro SAP, o que pode ser necessário em situações do tipo mudança do banco
de dados, modificação no número de work process etc.
As mudanças nos perfis são verificadas automaticamente, e erros simples ou inconsistência são verificados,
mas as modificações só devem ser feitas com segurança e conhecimento de suas consequências, caso
contrário o sistema pode ser colocado em risco.
A maioria dos parâmetros só terá mudanças ativadas após a próxima inicialização do sistema, com exceção
da alguns parâmetros de gerenciamento de memória da instância, que pode ser ativados dinamicamente.
Cópia Controlada Page 18 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Operation Mode
Normalmente, os sistemas R/3 precisam de mais WP´s dialog durante o dia e mais WP´s background durante
a noite.
Existem dois modos de se ajustar o sistema para se adequar a necessidades diferentes dependendo do
período do dia e do tipo de utilização principal. Isso pode ser feito alternado-se os perfis da instância ou
usando o processo de modo de operação (operation mode).
O uso de modo de operação maximiza a utilização dos recursos nas diferentes fases de atividade do sistema.
A mudança do modo de operação reconfigura o R/3 dinamicamente, o que substitui a alteração dos perfis e a
reinicialização do sistema.
A utilização das mudanças de modo de operação se baseia nos seguintes fatores:
- os serviços ou os tipos de work processes needed
- o intervalo de tempo escolhido
Cópia Controlada Page 19 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Durante o dia, normalmente o modo de operação requer mais processos de dialog , o que permite melhor
tempo de respostas para transações de entrada de dados, por exemplo.
O processamento de dialog é responsável por:
- processamento interativo, como criação de documentos ou de ordens de venda
- envio de um volume limitado de dados para inserção na base de dados
- atividades de usuário com um limite de transações
- processos urgentes
A operação usual do período noturno requer mais processos de background, que devem estar disponíveis
para jobs de alta prioridade e/ou de execução programada
O processamento de background é usado para tarefas que requerem alta atividade do banco de dados e que
consumiriam muito tempo em um dialog, como, por exemplo:
- processos de balanço e pagamentos
- processamento de listas
- alguns processamentos periódicos
- inserção e atualização de um grande volume de dados
Cópia Controlada Page 20 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Instâncias são criadas durante a instalação do R/3.
Para cada instância, os perfis são criados automaticamente.
Depois da definição do primeiro modo de operação, as definições da instância devem ser criadas.
Não há modo para se criar as definições de instâncias manualmente, elas devem ser criadas através da
geração ou da cópia das definições usando o CCMS
Quando da geração das definições de uma instância, o sistema importa os dados correntes da instância de
cada servidor de aplicação que estiver ativo.
Se vocês escolher obter as configurações correntes de uma das instâncias ativas quando for gerar as
definições, cada modo de operação produtivo que foi criado previamente será associado com a disposição do
número corrente de work processes para cada nova definição de instância.
Se nova definição de instância for criada sem se basear em uma instância já ativa, o modo de operação terá
que ser designado manualmente.
Para cada modo de operação associado, é possível adaptar a distribuição dos work processes
correspondentes. Apesar de ser possível mudar o tipo dos work processes, o número total deles deve
permanecer o mesmo e só poderá ser alterado no perfil da instância.
O número mínimo de work processes tanto para dialog quanto para background é 2. O total de WP´s de dialog
é sempre o número total de WP´s menos a quantidade de todos os outros WP´s
Cópia Controlada Page 21 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
É possível reservar um ou mais WP´s de background para processamento de jogs de alta prioridade, ou seja,
jobs classe A.
Durante a mudança de modo de operação, os work processes são redistribuídos automaticamente, sem que a
instância tenha que ser reiniciada. Não há tempo de parada nesse processo, e somente o tipo dos work
processes é que é mudado e não o número de work processes disponíveis.
Se algum dos WP´s a ser alterado estiver processando um job, ele será modificado após o término da tarefa
em andamento. Nenhum processo é interrompido, a performance do sistema é mantida, e os buffers do R/3
(ABAP e table buffers) não são ressetados.
A mudança do modo de operação é registrada no log do sistema. Apesar de excepcional, caso o processo de
mudança no modo de operação não seja completado automaticamente, a mudança poderá ser feitas
manualmente.
No caso de falha na mudança do modo de operação, o administrador deverá investigar as causas da falha,
que, geralmente, está relacionada com inconsistências do sistema como, por exemplo, se houver uma
discrepância entre os diferentes locais de configuração do número de work processes:
- no perfil da instância no sistema de arquivos
- na base de dados
- ou na definição do modo de operação
Se os perfis forem modificados, e o sistema for reiniciado, os modos de operação assim como as definições
da instância devem ser reconfiguradas.
Cópia Controlada Page 22 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Oracle – visão geral
Quando um banco de dados Oracle é iniciado, diversos processos são criados:
- o processo listener é responsável pela comunicação do Oracle com a rede
- um processo shadow dedicado é criado para cada sessão da base de dados
- alguns processos compartilhados, que trabalham para o gerenciamento do banco de dados
A base de dados é armazenada em blocos de 8KB em arquivos de dados no disco.
Para acelerar o acesso de leitura e gravação, esses blocos de dados são armazenados no pool de buffer de
memória principal.
Cópia Controlada Page 23 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Modificações na base de dados são armazenadas nos arquivos de redo log online. Esse processo garante a
integridade e a segurança dos dados. Para garantir a tolerância a falhas na operação sobre a base de dados,
os arquivos de controle (control files) e os arquivos de redo log online do sistema devem ser espelhados.
O sistema de gerenciamento do Oracle mantém os comandos SQL executáveis em uma área de SAL
compartilhado (SQL shared area), que é faz parte do pool de memória compartilhada e disponíveis para todos
os processos.
Cada work processes do R/3:
- se conecta à base de dados como o usuário SAPR3 do banco de dados
- trata requisições de diferentes usuários do R/3
- se comunica com o shadow process correspondente na base de dados
Usuários do R/3 não possuem um usuário correspondente no banco de dados.
O banco de dados Oracle é iniciado em três fases:
- Na fase No Mount, a instanciação da base de dados é construída. Recursos do sistema
operacional são alocados usando a configuração armazenada no arquivo de perfil do Oracle.
- Na fase Mount, os arquivos de controle do banco de dados são avaliados. Então, o sistema lê as
informações da estrutura de arquivos da base da dados. Nenhum arquivo ainda foi aberto.
- Na fase Open, todos os arquivos da base de dados são abertos. Caso necessário, uma
recuperação de instância é imediatamente iniciada. Transações pendentes na base de dados são
finalizadas de acordo com a lógica transacional.
O administrador pode derrubar o banco de dados usando um dos três modos a seguir:
Cópia Controlada Page 24 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
- SHUTDOWN NORMAL : Todos os usuários devem deslogar. A base de dados é fechada
sistematicamente, todos os arquivos são fechados, a base é desmontada, e a instância do banco
é derrubada. A base de dados termina o shutdown com consistência
- SHUTDOWN IMMEDIATE : Somente os comandos correntes são finalizados. PMON finaliza todas
as sessões e faz um rollback das transações abertas. A base de dados é fechada
sestematicamente (como num shutdown normal) e termina o shutdown consistente.
- SHUTDOWN ABORT : usado somente em emergencias. Usuários não são deslogados, e o
rollback das transações abertas não é efetuado. A base de dados não termina o shutdown de
forma consistente, e uma recuperação da instância da base de dados é realizada na próxima
nicialização da base de dados.
Um sistema de banco de dados Oracle tem três processos que gravam informação da Shared Global Area
(SGA) para os arquivos apropriados:
- durante um chackpoint, o Database Writer (DBWR) grava de maneira assíncrona os blocos de
dados que foram modificados da SGA para os arquivos de dados.
- para aumentar a velocidade da gravação, o processo Checkpoint (CKPT) é executado
- o Logwriter (LGWR) grava sincronamente as mudanças no buffer de redolog do SGA para o
arquivo de redolog online corrente.
Em um sistema de produção, a base de dados deve sempre ser executada no modo ARCHIVELOG e ter o
processo Archiver (ARCH) inicializado). O ARCH armazena uma cópia completa do arquivo de redolog online
no arquivo de redolog offline dentro do diretório de archive da base de dados.
Uma vez que o arquivo de redolog offline é criado, o arquivo correspondente de redolog online é liberado e
pode ser sobreescrito com novas dados de log pelo sistema.
Se não houver mais espaço disponível no diretório de archive, o ARCH não irá armazenar o próximo arquivo.
Nesse momento, a base de dados “trava”, depois que um número de mudanças no arquivo de redolog. Novas
modificações na base de dados não podem ser salvas enquanto o travamento do ARCH persistir.
Cópia Controlada Page 25 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O banco de dados Oracle usa tablespaces. Do ponto de vista lógico, uma tablespace é um container para
objetos da base da dados, como tabelas e índices. No disco, uma tablespace consiste de um ou mais
arquivos. A capacidade de uma tablespace pode aumentar adicionando-se mais arquivos à estrutura.
Os objetos criados na SYSTEM (tablespace principal do Oracle), PSAPROLL (rollback da base) e
PSAPTEMP (temporário da base) devem ser exclusivos dos usuários SYSTEM e SYS do Oracle.
Cópia Controlada Page 26 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Os diretórios e arquivos também são criados de acordo com uma convenção de nomes e de localização. Por
exemplo, os arquivos de tablespaces residem no diretório sapdata<n>, e os arquivos de alerta do Oracle são
armazenados no diretório saptrace\background
As tarefas de manutenção diárias do banco de dados incluem:
- backup de toda a base de dados
- backup dos arquivos de redo log offline
- monitoração do sucesso dos backups
Cópia Controlada Page 27 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Fatores externos, erros físicos e lógicos podem levar a perda de dados e parada do sistema
Uma estratégia de backup efetiva e um plano de recuperação de dados são essenciais para minimizar tempo
de parada e perda de dados.
Para garantir a disponibilidade do R/3, uma stratégia de backup deve ser desenvolvida pelo administrador da
base de dados e testada com precisão.
Cada sistema de gerenciamento de base de dados armazena seus dados em estruturas adequadas para a
gravação em disco e grava as modificações nos dados no log da base de dados. No caso do Oracle:
- os dados são armazenados nos arquivos das tablespaces
- o log e anotado no arquivo de redo log online corrente
- dados de administração são armazenados nos arquivos de controle e de parâmetros
Durante um backup da base de dados, os arquivos de dados, do redo log online, os perfis e os arquivos de
controle são armazenados.
Quando o arquivo de redo log online corrente é preenchido completamente, automaticamente o Oracle passa
a gravar no próximo arquivo de redo logo online. O Oracle archiver, então, copia o arquivo de redo log online
preenchido para o diretório de archive. Esse novo arquivo é chamando de arquivo de redo log offline.
Os backps dos arquivos da base da dados quanto do redo log offline são necessários para garantir a
recuperação da base de dados em um ponto de tempo o mais próximo possível de quando os dados foram
perdidos. Para realizar a restauração, o backup dos dados deve ser restaurado desde o início.
Cópia Controlada Page 28 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Um estratégia de backup deve incluir a verificação dos dados e dos backups de dados.
Use a verificação lógica dos dados para verificar a consistência da base de dados Oracle:
- blocos corrompidos (erro ORA-1578) podem aparecer na base de dados R/3 como resultado de
um erro de sistema operacional ou de hardware. Blocos corrompidos podem inutilizar um backup.
- A existência desses blocos só se torna evidente durante a próxima tentativa de leitura da tabela
dentro do bloco afetado. Como esse particular acesso podem não ocorrer frequentemente, e
blocos não validados durante o backup, esses blocos corrompidos podem permanecer
escondidos no sistema por um longo tempo
- Por isso, uma verificação lógica é necessária de tempos em tempos. Por questões de
performance, a verificação deverá ser efetuada em horários de baixa atividade do sistema.
Uma verificação física dos dados nas fitas usadas para o backup também é importante. Para isso, as fitas
devem ser lidas para verificação após o backup.
Quando um backup offline é efetuado, a base de dados deve ser descarregada e permanecer indisponível
durante o backup. Como os arquivos do Oracle permanecem intactos durante o backup, a consistência dos
dados é mantida.
Os seguintes arquivos são copiados durante um backup offline:
- os arquivos de todas as tablespaces pertencentes a uma base de dados
- os arquivos de redo log online
- os arquivos de controlo
- os arqivos de pefil
Depois que o backup offline termina, é necessário armazenar também os arquivos do redo log offline
Apesar de o R/3 poder continuar disponível durante um backup , os usuários não podem acessar a base
nesse período.
Cópia Controlada Page 29 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Durante um backup online, o Oracle e o R/3 permanecem disponíveis. O online backu causa uma pequena
redução de performance do sistema
Os seguintes arquivos são armazenados durante um backup online:
- arquivos de dados de todas as tablespaces da base de dados
- arquivos de controle
- perfis
Atenção:
- backups online por si só não são consistentes, pois os arquivos de dados estão sendo atualizados
concorrentemente ao armazenamento. Um backup online só será consistente em conjunto com as
informações de log gravadas durante o processo do backup. Depois do final do backup, a
ferramenta SAP pode ser usada para mudar a utilização do redo log online para outro arquivo, o
que faz com que o Oracle copie o arquivo anterior para o diretório dos arquivos de redo log offline,
que também deverão ser incluídos no backup para garantir a consistência da cópia.
Não é necessário fazer o backup do redo log online depois que um backup online é finalizado.
Cópia Controlada Page 30 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Os arquivos de redo log offline são copias dos arquivos de redo log online que são gravadas pelo archiver do
Oracle no diretório saparch. Os arquivos de redo log online são sobrescritos ciclicamente.
Registros de lgo são constantemente gerados durante modificação dos dados na base. Assim, espaço em
disco para o diretório de archive dos logs deve sempre estar disponível. Quando o archiver não tiver espaço
disponível para gravar, o Oracle irá retornar o erro 257: Archiver is stuck ou o erro 255: Error archiving log, e o
banco de dados para. Uma mensagem de erro também é gravada nos arquivos de trace do Oracle.
Se, no caso de uma restauração, um dos arquivos do redo log offline não detém um backup válido, pode
ocorrer perda de dados. Os arquivos de redo log offline devem ser armazenados em fita antes de serem
apagados do diretório de archive. Por questões de segurança, faça duas cópias em fitas separadas dos
arquivos de redo log offline.
No caso de uma falha no banco de dados, pode acontecer uma situação na qual não será possível recuperar
as atualizações mais recentes, que não estiverem sido armazenadas no redo log offline. Também é importante
lembrar que um backup online não é útil sem uma cópia dos arquivos de log gerados durante a execução do
backup.
A SAP recomenda um cicleo de backup de quatro semanas.
Grupos de fitas para a base de dados e para o redo log offline são necessários, e eles devem cobrir todo o
período de backup. As fitas podem ser reusadas depois do término do ciclo.
Realize um backup online completo todos os dias. Pelo menos uma vez no ciclo de backup, realize um backup
completo.
Os arquivos de redo log offline devem ser armazenados (em duas cópias em fitas separadas) ao final de cada
dia de trabalho e também depois de cada backup, seja online ou offline.
Para se validar um backup, deve-se verificar a base de dados à procura de erro lógicos e os backups,
principalmente verificando os erros físicos. Essa verificação deve ser realizada pelo menos uma vez durante o
ciclo de backup
A última cópia completa offline de cada cilco deve ser removida do grupo de fitas e armazenada em local
seguro.
Cópia Controlada Page 31 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Backups da base de dados são realizados usando a ferramente BRBACKUP fornecida pela SAP, enquanto os
backups de arquivos de redo log offline são comandados pela ferramenta BRARCHIVE.
Existem três modos de execução do precesso
- usando o SAPDBA
- diretamente através do sistema operacional
- e usando o DBA planning Calendar do R/3
A SAP recomenda o seguinte procedimento:
- programar todos os backups regulares usando o DBA planning Calendar
- realizar backups adicionais através do SAPDBA
Todos os passos do backup são armazenados em arquivos e em tabelas da base de dados.
Para determinar a estratégia de backup devem ser considerados:
- requisitos operacionais
- requisitos de segurança
- componentes de hardware
- disponibilidade do sistema
A implementação deve se preocupar com:
- definição das fitas e locais de armazenamento
- agendamento do processo
- definição de responsabilidades
Cópia Controlada Page 32 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
- configuração das autorizações necessárias
- criação do plano de emergência e responsáveis
Além do plano de emergência, deve ser criado um manual que contenha as informações de cada passo do
backup e que deve estar disponível a todos os responsáveis pelo backup.
Monitoring DB
O R/3 pode configurar o processo de backup para usar compressão de dados.
Para avaliar a taxa de compressão a ser obtida no backup, o administrador pode usar o SAPDBA. Essa
verificação deve ser realizada a cada ciclo de backup
O Backup Log Monitor (transação DB12) mostra informações sobre
- backups da base de dados e dos arquivos de redo log offline
- logs gravados pelo BRBACKUP e pelo BRARCHIVE
- o último backup que falhou
- o último backup com sucesso
- o estado do diretório de archive
- como que os backups de base de dados e de redo log offline podem ser usados em uma
recuperação de base
A transação DB13 mostra informações sobre todos os backups comandados
Para melhorar a performance e minimizar o tempo de parada do sistema, o Oracle deve ser monitorado
diariamente. Para uma visão geral de indicadores de performance, o CCMS fornece os seguintes monitores
- Database System Check Monitor (DB16) mostra uma visão geral das funções principais do banco
e seu estado geral
- Backup Log Monitor (DB12) mostra informações de status dos backups de base de dados e de
redo log offline
- Tables Index Monitor (DB02) mostra uma visão geral da base de dados e seus objetos
- Database Performance Monitor (ST04) mostra uma visão geral da carga dde utilização do banco
de dados
A verificação dessas estatísticas é necessária para previnir:
- informação desatualizada para o Cost-Based Optmizer
- criação de um grande número de extents
- problemas de espaço
Cópia Controlada Page 33 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O otimizador do Oracle pode ser usado para determinar uma estratégia efetiva de acesso aos dados.
Ele analisa várias estatégias de acesso a tabelas e escolhe qual é a mais adequada para uma determinada
situação.
Cada tabela e índice são associados e armazenadas em uma tablespace, que consiste de um ou mais
arquivos.
O Oracle armazena as tabelas e índices em blocos individuais de 8KB de tamanho. Diversos blocos de uma
tabela ou índice são agrupados, o que forma um extent. Esses objetos de dados do Oracle possuem diversos
parâmetros de armazenamento que influenciam seu crescimento.
Cópia Controlada Page 34 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O primeiro extent (initial extent) deve ser grande o bastante para suportar o tamanho esperado da tabela ou
índice. Se um extent é completado durante uma inserção ou atualização de dados, outro extent será alocado
para a tabela dentro do tablespace.
Um objeto pode alocar extents até o máximo definido pelo sistema. No R/3, o default para o máximo é 300. Se
o número máximo de extents de um objeto é atingido, o Oracle retornará a mensagem de erro ORA-1631
(para uma tabela) ou ORA-1632 (para um índice).
O processo de alocação de extents garante que um objeto só pedirá mais espaço quando necessário. Se não
houver condições para que o Oracle consiga espaço livre contínuo, o sistema retornará a menssagem de erro
ORA-1653 (para tabelas) ou ORA-1654 (para índice).
As mensagens de erro são gravadas nos logs do Oracle e no log de sistema do R/3 (transação SM21)
Use o SAPDBA para verificar o seguinte:
- fragmenteção de tabelas e índices
- preenchimento de uma tablespace
- consistência da base de dados
Cópia Controlada Page 35 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
- log de mensagens críticas de erro
- parâmetros do Oracle
- problemas de base de dados específicos do R/3
Programe a execução semanal do SAPDBA usando o DBA Planning Check ou o comando sapdba –check
O resultado da verificação pode ser observado através da transação DB16
Para evitar problemas com extents, o SAPDBA possui um ajuste automático de extents (-next)
A transação DB12 pode ser usada para verificar um lista de tabelas e índices que alocaram mais de um extent
nas últimas quatro semanas.
O Database system Check Monitor (transação DB16) pode ser usado para informar quais objetos estão
excedendo um limite de extents (default de 80) ou se aproximando do limite máximo de extents
O Monitor de tabelas e índices (transação DB02) pode ser usado para:
- analisar as tablespaces que frequentemente apresentam problemas de espaço
- verificar o nível de preenchimento para determinar quais tabelas estão próximas de problemas
Use o Database System Check Monitor (transação DB16) para analisar problemas de espaço no banco
Cópia Controlada Page 36 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para monitorar o processo de execução dos backups, o R/3 disponibiliza o Backup Log Monitor (transação
DB12), que fornece informações sobre:
- backups de base de dados e de arquivos de redo log offline
- arquivos de log gravados pela execução do BRBACKUP e do BRARCHIVE
- o último backup que falhou
- o último backup com sucesso
- o estado do diretório de archive
- como que os backups de base de dados e de redo log offline podem ser usados em uma
recuperação de base
Cópia Controlada Page 37 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Uma parada no archiver pode acontecer quando:
- a base de dados está no modo ativo, mas o archiver do Oracle não está funcionando. Se isso
acontecer, o SAPDBA retorna uma mensagem de erro. Nesse caso há uma chance de se reiniciar
o archiver.
- o diretório de archive atinge seu limite máximo de tamanho devido às atualizações do banco.
Nesse caso, mais espaço deverá ser disponibilizado no diretório de archive
Se uma parada do archiver acontecer, o banco de dados ficará impedido de:
- gravar nos arquivos de redo log online
- realizar qualquer modificação na base de dados
- o SAPDBA não poderá se conectar ao banco
Em uma parada do archiver, o monitor da base da dados salva uma entrada de erro nos arquivos de log.
Para liberar mais espaço no diretório de archive, uma das soluções é armazenar em fita os arquivos de redo
log offline e apagá-los. Confiar em uma só fita é sob essa circunstância é uma situação arriscada.
Se houver espaço disponível, arquivos ‘temporários” podem ser criados manualmente para ocupar espaço a
ser liberado no caso de uma parada do archiver por falta de espaço.
Cópia Controlada Page 38 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
New User Setup
Para os procedimentos de verificação de todos os documentos e autorizações, o usuário deve estar criado.
Existem 2 meios de criar um usuário : Copiando um existente ou criando um novo.
Quando criar um usuário por cópia, verifique se o perfil de segurança é válido para o usuário criado.
Entre com a transação SU01 ou pelo caminho : Tools _ Administration, then User maintenance _ Users.
1. Digite o user id (por exemplo, gary) que será o modelo para o novo usuário.
2. Selecione Copy.
Cópia Controlada Page 39 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
3. Na janela do Copy Users, entre com o nome do novo usuário.
4. Selecione Copy.
.
5. Digite a password inicial (por exemplo, init). Re-entre a mesma no segundo campo.
6. No User group, entre o grupo que este usuário irá pertencer. (por exemplo, ACCT).
7. Você pode usar o combo box para verificar quais grupos existem.
3
Cópia Controlada Page 40 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
8. Digite a data limite que o usuário terá acesso ao sistema
9. Selecione a pasta Address para alterar o endereço do novo usuário.
10,11,12,13,14,15 são informações do usuário.1
16. selecione Defaults.
12
13
Cópia Controlada Page 41 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
17. Verifique qual a linguagem que o usuário irá trabalhar. O default é Inglês.
18. Sobre o Output Controller, selecione Output immediately e Delete after output. (indica que a impressão
sairá imediatamente e será deletada após).
19. Verifique em qual time zone o usuário irá trabalhar.
20. Sobre o Decimal notation, selecione o sinal decimal que o usuário irá trabalhar.
21. Sobre o formato da data, selecione (por exemplo, MM/DD/YYYY).
22. Clique no Save.
17
18
Cópia Controlada Page 42 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Algumas vezes são necessário criar um usuário novo do nada “scratch.”
1. Digite a transação SU01.
2. Digite o user ID (por exemplo gary) que você quer criar.
3. Selecione Create.
4.,5,6,7,8,9. Entre os dados do usuário.
10. Selecione a pasta Logon data.
2
Cópia Controlada Page 43 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
11. Digite a password inicial (por exemplo, init). Re-entre a mesma no segundo campo.
12. No User group, entre o grupo que este usuário irá pertencer. (por exemplo, ACCT).
13. Entre com a data limite para o usuário ter acesso ao sistema .
14. Selecione Defaults.
11
12
Cópia Controlada Page 44 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
13
15. Verifique qual a linguagem que o usuário irá trabalhar. O default é Inglês.
16. Sobre o Output Controller, selecione Output immediately e Delete after output. (indica que a impressão
sairá imediatamente e será deletada após).
17. Verifique em qual time zone o usuário irá trabalhar.
18. Sobre o Decimal notation, selecione o sinal decimal que o usuário irá trabalhar.
19. Sobre o formato da data, selecione (por exemplo, MM/DD/YYYY).
20. Clique no Save.
21. Entre no Profile Generator (PFCG) para criar ou assinalar um perfil de acesso para este usuário.
(veja Authorizations Made Easy Guidebook).
15
16
Cópia Controlada Page 45 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
18
Antes de fazer uma manutenção no usuário, verifique com a sua auditoria se as mudanças são permitidas.
1. Digite a transação SU01 e tecle Enter.
2. Entre com o user id (por exemplo garyn).
3. Selecione Change. (Lápis vermelho).
A tela de Maintain User permite que você altere : endereço, data de logon, password, grupo do usuário, e
outros.
4. Quando terminar as alterações clique em Save.
Cópia Controlada Page 46 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Resetting a Password
A maior razão para zerar um usuário (reset) é com relação a sua password.
Quando o usuário esquece sua password e tenta por um número de vezes entrar no sistema o usuário é
automáticamente bloqueado. Reveja na profile do SAP (RZ10) os seguintes parâmetros para controle de login.
Login/ext_security = Acesso ao sistema com segurança externa.
Login/failed_user_auto_unlock = se 1, sistema automaticamente desbloqueia usuários que estejam
suspensos por logons inválidos às 24h e 1min.
Login/fails_to_session_end = número de logons inválidos permitidos por um User Master record até que o
procedimento de logon seja interrompido.
Login/fails_to_user_lock = número de logons inválidos permitidos por um User Master record até que o
logon seja rejeitado para esse usuário. Uma entrada é registrada em System Log e (Audit Log a partir da
verão 4.0) O Bloqueio é liberado a meia-noite - (Veja parâmetro acima)
Login/min_password_lng = comprimento mínimo de senha.
Login/password_expiration_time = valor 0 significa que usuários não são forçados a mudar suas senhas.
Valor maior que 0 especifica o número de dias que os usuários têm para mudar sua senha de logon.
Login/system_client = Client padrão do sistema.
Rdisp/gui_auto_logout = número de segundos após o qual a seção do usuário é interrompida por
inatividade.
1. Digite a transação SU01 e Enter.
2. Entre o user ID (por exemplo, GARYN).
3. Selecione Change password.
Cópia Controlada Page 47 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
4. Na janela do Change Password, digite a password temporária.
5. Selecione Copy.
Para uma maior segurança, você deve setar a password do usuário com o valor inicial, e deixar para
o usuário alterar a sua própria password.
Locking or Unlocking a User
Locking
Se um usuário sair da empresa, ou é designado para um grupo diferente, os acessos no R/3 devem ser
removidos. A função lock permite que o usuário e suas autorizações fiquem no sistema R/3 mas bloqueado
para uso.
Unlocking
O usuário é desbloqueado, verifique antes se a requisição para esta tarefa é autorizada pela auditoria.
4
1. Digite a transação SU01 e Enter
2. Entre com o user ID (por exemplo GARYN).
3. Selecione Lock/unlock (desenho do cadeado).
4. Na próxima janela marque o usuário que será bloqueado.
5. Selecione Lock/Unlock (desenho do cadeado).
Cópia Controlada Page 48 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
2
3
6. Aparecerá a mensagem que o usuário foi bloqueado/ desbloqueado.
Deleting a User’s Session (Transaction SM04)
Use a transação SM04 para terminar uma sessão do usuário, ela mostra quais usuários estão ativos para o
R/3.
Um usuário pode ter sua sessão terminada quando: sua transação está travada, seu programa está em looping, ter
um deadlock de transação, etc.
1. Verifique se o usuário não está logado no R/3, verifique ligações físicas.
2. Digite a transação SM04.
6
3. Selecione o user ID que será deletado. (Verifique bem pois é muito comum clicar no usuário errado).
4. Selecione Sessions.
5. Selecione a sesão que será deletada.
Cópia Controlada Page 49 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
6. Selecione End session.
7. Repita os passos 5 e 6 até que a sessão seja totalmente deletada.
6
Printing/Spool System
Existem dois tipos básicos de ligação entre o R/3 e as impressora que ele poderá utilizar, são eles:
Impressoras com ligação direta na rede (impressora remota)
impressora ligadas através de um micro na rede.
Impressoras com ligação direta na rede
Neste caso o procedimento será o seguinte:
1. Indentifique o endereço IP que esta impressora possuirá na sua rede e o endereço IP do micro que está
administrando a mesma.
2. Cadastre-os no arquivo hosts no servidor R/3 (/etc/hosts).
3. Crie esta impressora no sistema operacional (UNIX) do servidor R/3.
4. Teste-a com enviando algum documento para impressão através do sistema operacional (UNIX) do
servidor R/3.
5. Concluido a instalação da mesma no sistema operacional, vamos agora criar está impressora no R/3
através da transação SPAD.
Cópia Controlada Page 50 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
6. Selecione o botão dispositivos de saída, está tela exibirá todos os dispositivos de saída configurados para
o R/3.
7. Selecione o botão modificar e para criar um novo dispositivo acesse selecione o botão criar.
8. Na tela de criação do dispositivo você terá as seguintes informações:
Dispositivo de saída: nome que este dispositivo será chamado no R/3.
Nome Breve: abreviação do nome do dispositivo de saída no R/3.
Cópia Controlada Page 51 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Ctg. de dispositivo: selecione o driver que seja compatível com o dispositivo de saída.
Servidor de edição: selecione o servidor R/3 que irá administrar este dispositivo.
Impressora host: informe o nome que este dispositivo possui no sistema operacional (obedecendo letras
maiúsculas e minúsculas).
Classe aparelho: selecione o tipo de dispositivo que está sendo instalado, no nosso caso Impressora
normal.
Tipo acoplam.p/spool host: informe o modo que o R/3 se comunicará com o dispositivo, no nosso caso nós
utilizaremos a opção L - Impressão local via LP/LPR.
Modelo: informe o modelo da impressora (Opcional).
Localização: informe aonde a impressora está localizada (Opcional).
Mensagem: informe uma mensagem que o usuário visualizará impressão.
Bloquear impressora págSAP: se selecionado bloqueia a utilização deste dispositivo.
Folha de rosto SAP: se selecionado emitirá uma folha de rosto para cada trabalho a ser impresso.
9. Preenchido estas informações, salve-as e a partir deste momento este dispositivo estará disponível para
os usuários do R/3. Observe o exemplo abaixo.
Cópia Controlada Page 52 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Impressora ligadas através de um micro na rede
Segue abaixo o procedimento para instalar impressoras com está característica no sistema R/3.
1. A impressora a ser utilizada pelo R/3 deve estar instalada no sistema operacional do micro que possui
acesso ao R/3.
2. Deverá ser acionado um aplicativo chamado SAPLPD que é instalado junto com o front end. Você
observará que ao acioná-lo ele exibirá o endereço IP que este micro está utilizando na rede e o nome do
mesmo, como no exemplo abaixo.
3. Estes dois dados deverão constar no arquivo hosts (/etc/hosts) do servidor R/3, viabilizando a
comunicação do servidor (UNIX) com este micro (Windows). Note que este micro deverá possuir um
endereço IP fixo na rede, pois se o mesmo está configurado para receber o seu endereço
Cópia Controlada Page 53 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
automaticamente através do DHCP ele poderá ter o seu endereço IP trocado tornando a comunicação
com o servidor R/3 (UNIX) inviável pois o mesmo não será atualizado pelo DHCP.
4. No R/3 você acessará a transação SPAD.
5. Selecione o botão dispositivos de saída, está tela exibirá todos os dispositivos de saída configurados para
o R/3.
Cópia Controlada Page 54 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
6. Selecione o botão modificar e para criar um novo dispositivo acesse selecione o botão criar.
7. Na tela de criação do dispositivo você terá as seguintes informações:
Dispositivo de saída: nome que este dispositivo será chamado no R/3.
Nome Breve: abreviação do nome do dispositivo de saída no R/3.
Ctg. de dispositivo: selecione o driver que seja compatível com o dispositivo de saída (Neste caso,
independente da impressora que estamos utilizando, será selecionado a opção SAPWIN - Rel
4.x/SAPLPD 4.x ONLY!).
Servidor de edição: selecione o servidor R/3 que irá administrar este dispositivo.
Host de comutação: informe o nome do micro que possui a impressora que será instalada.
Opções...: ele exibirá três campos de configuração, são eles: Tmp.estr.conex (tempo de timeout para
conexão em segundos, padrão 60s), Tempo resposta (especifica o tempo limite para receber uma
resposta do dispositivo, o valor padrão está definido no parâmetro rspo/tcp_timeout_connect no profile da
instance) e Número de porta (número da porta disponível para comunicação com o dispositivo).
Impressora host: informe o nome que este dispositivo possui no sistema operacional (obedecendo letras
maiúsculas e minúsculas).
Classe aparelho: selecione o tipo de dispositivo que está sendo instalado, no nosso caso Impressora
normal.
Tipo acoplam.p/spool host: informe o modo que o R/3 se comunicará com o dispositivo, no nosso caso nós
utilizaremos a opção L - Impressão local via LP/LPR.
Modelo: informe o modelo da impressora (Opcional).
Localização: informe aonde a impressora está localizada (Opcional).
Mensagem: informe uma mensagem que o usuário visualizará impressão.
Bloquear impressora págSAP: se selecionado bloqueia a utilização deste dispositivo.
Folha de rosto SAP: se selecionado emitirá uma folha de rosto para cada trabalho a ser impresso.
Cópia Controlada Page 55 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Observe que os campos Host de comutação e o botão opções apareceram para o preenchimento depois que
você tentar salvar as configurações.
TMS Authorization Concept
Cópia Controlada Page 56 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O usuário que irá configurar o TMS deverá estar logado no client 000 e possuir autorização S_CTS_ADMIN.
Para evitar um acesso indevido no R/3 através do TMS:
O TMS sempre verifica a autorização no sistema destino.
O RFC do sistema destino são gerados durante a configuração e não podem ser modificados.
O Transport Domain do R/3 externo não pode acessar o Trasnport Domain do meu R/3.
Selecione :
Overview > system > R/3 system > check > connection test para verificar a conexão com o RFC.
Overview > system > R/3 system > check > trasnport directory para verificar a disponibilidade do sistema de
transporte.
Overview > system > R/3 system > check > transport tool para verificar o programa TP.
Overview > system > configuration > distribute para distribuir a configuração do Domain Controler para os
outros sistemas R/3.
Overview > system > configuration > activate > in all domain para ativar todos os Transport Domain.
Overview > system > configuration > activate > local para ativar o Transport Domain local.
Change Management for Development
Cópia Controlada Page 57 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O sistema R/3 pode ser ajustado de acordo com o negócio da empresa que estiver implementando-o da
seguintes formas :
Customizing : Ajusta os processos do negócio da empresa ao R/3 de acordo com as funcionalidades do IMG.
Personalization : Alterar algumas telas, campos, pré-determina valores do existente no R/3.
Modification : Alterar os objetos repositórios existentes.
Enhancement : Altera os objetos repositórios utilizando de user exit.
Customer Development : Cria novos programas ABAP.
Cópia Controlada Page 58 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Todos objetos repositório que são alterados e criados através do ABAP WORKBENCH são registrados numa
Change Request.
A transção SE09, mostra as Change Requests, informações dos transportes , e provê acesso de suas
ferramentas.
Cópia Controlada Page 59 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
A Change Request registra as mudanças nos objetos repositórios ou nasentrada de tabelas.
O conteúdo da Change Request são armazenados nas TASKS correspôndentes ao desenvolvedor específico.
Com a SE09, podemos criar, alterar, liberar e deletar request, adicionar usuário para uma request existente,
adicionar tasks a uma request.
Cópia Controlada Page 60 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Todo início de um projeto , o líder do projeto cria uma Change Request e assinala membros do time de projeto
nesta request.
O sistema R/3 assinala um número para as requests <SID>K9<nnnn>, ex DESK900001.
A TASk desta forma contém todas as alterações na qual o time de projeto produziu.
Um membro do projeto quando termina seu trabalho, libera a task , e quando todos os outros membros do
projeto terminarem seus trabalhos liberam as suas que por sua vez estando amarado a uma Change Request,
O líder do projeto libera esta request com as demais tasks juntas.
A Change Request desta forma possui todas as mudanças que forma criadas no projeto.
Cópia Controlada Page 61 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
S_A.SYSTEM = usada por um superusuário com todos os direitos no CTS.
S_A.CUSTOMIZ = usado pelo Líder de projeto acesso total as Requests.
S_A.DEVELOP = usada por desenvolvedores e customizadores, acesso total as Tasks.
S_A.SHOW = usada por Basis visualização do CTS.
Registering Developers in SSCR
Cópia Controlada Page 62 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Todo desenvolvedor ABAP, deve ter o seu código no SSCR (Sap Software Change Registration) na qual é
obtida através do OSS.
Somente um desenvolvedor registrado pode criar e modificar objetos no repositório.
Para prevenir conflitos com os nomes de objetos, quando criamos nossos objetos, existe uma convenção para
os nomes.
Os programas desenvolvidos por terceiros fora a SAP, devem começar com Z ou Y – veja nota 16466.
System Change Option
Cada sistema R/3 tem a sua opção de deixar o System Change Option modifícavel ou não.
Selecione : Tools > Administration > transpot > installation > follow up work > goto > system Change option
(SE06).
Erro: System setting does not allow changes to be made objects!!.
Cópia Controlada Page 63 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Indica que o System change option não esta liberado para modificações, devemos entrar na SE06 e alterar o
global setting para modifícavel.
Erro: System change option does not allow changes to SAP objects display !!
Indica que estamos tentando alterar um programa standard que já foi alterado por outra pessoa.
Development Class
Todos os objetos são assinalados a uma classe de desenvolvimento.
A classe de desenvolvimento são objetos de ABAP Workbench e podem ser criados pelo Browser do
repositório.
As classes de desenvolvimento que não são standard começam com:
Z ou Y – classe de desenvolvimento que o objeto pode ser transportado.
S - classe de desenvolvimento com objetos termporários e não serão transportados.
T - classe de desenvolvimento para objetos locais que estão ligados ao workbench Organizer.
STMP – é usado quando o objeto é salvo no repositório local e não é registrado numa classe de
desenvolviemnto.
Criar uma classe de desenvolvimento – selecione a transação SE80 – marque o nome da classe e clique no
display.
Cópia Controlada Page 64 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
R/3 Repository Object Locking
Os objetos originais podem ser modificados por desenvolvedores que estejam assinalados no Workbench
change request.
Existem 2 meios de bloquear objetos que serão modificados:
O editor de programa trabalha com enfileiramento de work process e isto assegura que somente um
desenvolvedor por vez pode modificar um objeto.
O workbench change request assegura que o objeto do desenvolvedor seja assinalado para uma task numa
request e que quando este objeto for sofrer uma alteração, só poderá ser feito pelo desenvolvedor assinalado
na request.
Os objetos também podem ser manualmente inseridos na request, mas esses objetos não são
automáticamente bloqueados; Para isso temos que bloquea-lo manualmente através do caminho :
Request task > object list > lock objects.
Cópia Controlada Page 65 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Quando liberamos uma request :
Grava-se a versão mais nova do objeto no banco de dados.
Desbloqueia os objetos.
Exporta os dados contidos na request quando a mesma é transportada.
A versão do objeto no repositório pode ser comparada e restaurada.
O Development DB contém as versões ativas e temporárias.
O Version DB contém todas as versões gravadas através de uma liberação de request.
Cópia Controlada Page 66 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para acessar o Repository Browse, use a transação SE80.
Para acessar o Workbench Organizer, use a transação SE09.
Os return codes válidos são :
00 – o export foi executado com sucesso.
04 – Existem warning, porém o export foi executado.
08 – Um dos objetos contidos no request não foi transportado.
12 – Erro crítico.
Cópia Controlada Page 67 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Na SE09, visualizamos os transportes e repair. O semáforo indica o resultado do transporte.
Execução OK.
Execução com Warning.
Execução com erros.
Quando um erro é identificado, o atributo da request pode ser alterado pressionando o ícone Error Corrected
Na tela da SE09 .
Cópia Controlada Page 68 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Os tipos de objetos são :
PROG – Programa ABAP
DEVC – Classe de desenvolvimento.
VIEW – Visão de tabela.
FORM – Form ABAP
COMM – Arquivos com comandos
CHD0 – Mudança de documentos
Somente o usuário DDIC poderá alterar os atributos dos objetos, exceto o Original Language.
O caminho é SE09 > tools > abap workbench > overview > workbench organizer > goto > tools > object
directory.
Repair Flag – são todos os objetos modificados, sendo standard ou não.
Generation Flag – são objetos gerados automáticamente por customizing.
Os objetos são originais somente num sistema, nos outros são tidos como cópia.
Cópia Controlada Page 69 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Antes de um Upgrade todas as Repairs devem ser confirmadas e liberadas através da ferramenta PREPARE.
Para ajustar o dicionário de Dados durante o Upgrade use a transação SPDD.
A transação SPAU consolida todos os objetos do repositório.
Cópia Controlada Page 70 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para ativar o Transport Erros global, selecione : Tools > abap workbench > overview > workbench organizer
> goto > tools > administration > global customizing workbench e marque a opção Globally Activated.
Para um usuário específico marque a opção Can be set for specific user.
Cópia Controlada Page 71 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Change Management for Customizing
Customização típica, cria e altera entrada de várias tabelas através de visões (View) e de client dependent.
A SAP provê várias ferramentas para suportar a implementação :
Cópia Controlada Page 72 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Customizing :
Implementation Guide (IMG) – é a principal ferramenta de customização.
Customizing Organizer (CO) – SE10 grava as alterações de customizações na Change request com o tipo
CUST.
Development:
Abap Development Workbench – desenvolvimento abap.
Workbench Organizer (SE09) – grava o desenvolvimento abap na Change request de tipo SYST.
Implementation Guide
Um projeto no IMG pode ser gerado para cada sistema R/3.
As funções selecionadas podem ser alteradas e regeradas, a transação utilizada para acessar o IMG é SPRO.
Cópia Controlada Page 73 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O IMG provê todas as transações de customização para o projeto.
Oferece acesso online de todas as informações requeridas na customização e ferramenta de gerenciamento
Do projeto..
Para visualizar os itens do IMG que são Client Dependence, selecione : tools > business engineer >
customizing > enterprise IMG > information > title and IMG info > client dependence.
Para visualizar os itens do IMG que são transport Dependence, selecione : tools > business engineer >
customizing > enterprise IMG > information > title and IMG info > transport dependence.
Cópia Controlada Page 74 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para acessar o Client change Option use a transação SCC4.
Change without automatic recording permite que se altere as tabelas mas não inclue automáticamente essas
mudanças na request.
Pode se incluir as alterações manualmente na request, da seguinte maneira:
1- Entre na transação de customização.
2- Use a opção Table/View Transport.
3- Preencha as informações da request.
4- Selecione as entradas que serão incluidas na request aberta.
5- Clique na opção Include in transport.
6- Salve.
Automatic Recording of Changes permite que se altere as tabelas e esta alteração é incluida automáticamente
Na request.
No Changes Allowed Não permite alteração nas tabelas.
No Transport Allowed permite que as tabelas sejam alteradas mas não permite que sejam transportadas.
Cópia Controlada Page 75 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Por causa do dinâmismo de acesso as tabelas durante a customização, ambos clients (dependente e
independente) não estão protegidos contra regravação. As tabelas são bloqueadas enquanto as transações
de customizações estão sendo usadas, mas são desbloqueadas quando as alterações são completadas e
salvas na request.
Para ativar o LOGIN para Changes to Customizing Tables, selecione a transação OY18.
Geralmente todos os objetos são transportados para o sistema Destino na qual eles existem no sistema Fonte,
os objetos transportados do sistema fonte regravam os objetos no sistema destino que tem o mesmo nome,
estes objetos são deletados do sistema destino se eles não existirem no sistema fonte.
Cópia Controlada Page 76 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Release and Export – copia as entradas das tabelas do banco de dados para um arquivo do sistema
operacional (no sistema fonte).
Release to Request – libera e copia a change request de customização para change requst transportavel.
Após liberar a change request customizing, lembre-se de verificar a execução do EXPORT pela transação
SE10.
Cópia Controlada Page 77 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Transport Management
Quando é feito o EXPORT, os arquivos de dados são armazenados no diretório usr/sap/trans/data e os
arquivos de controle no usr/sap/trans/cofiles.
Cópia Controlada Page 78 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para visualizar a fila de import no sistema R/3, selecione na tela de Import Overview a opção import Queue >
display. A fila é mostrada na ordem que as requests são importadas
Em casos excepcionais, a request pode ser retornada para outro sistema R/3 e depois ser importada para o
sistema destino.
A Change request pode ser deletada ou adicionada na fila de import. Note que uma vez que os objetos são
dependentes, pode causar uma inconsistência de dados no sistema destino. Ex. Se você deletar uma request
que contém novos elementos de dados, todas as outras request que contém tabelas dependendo deste
elemento ficarão com falha.
Cópia Controlada Page 79 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O transporte não deve ser de responsabilidade de uma única pessoa, mas requer o esfoço de várias pessoas,
cada um com sua função.
Líder de projeto tem a funçao de organizar o desenvolvimento ou a customização do projeto usando o
gerenciamento das Change requests e se possível o IMG.
Verifica o conteúdo da request antes do RELEASE e após o IMPORT e verificar os arquivos de logs.
Administrador R/3 tem a função de usar o TMS para importar as requests e verificar o resultado do import,
testar o conteúdo da request não é função do administrador e sim do líder de projeto e do time de quality
assurance.
Time Quality Assurance tem a função de verificar e testar todas as funcionalidades contidas na change
request. Este time deve ser representado por pessoas de diversos departamentos da empresa, par que juntos
possam validar os processos , relatórios e transações antes de serem enviadas para produção.
Cópia Controlada Page 80 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cópia Controlada Page 81 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Transport Directory File Name Conventions
O programa TP processa em diferentes sistemas operacionais, mas sempre segue uma convenção de nomes:
<source SID>K9<5 dígitos> - onde o K9 indica request de customização.
No diretório actlog o arquivo <source SID>Z<6 dígitos> grava cada ação executada da request.
No diretório sapnames é criado um arquivo com o nome do usuário que fez um transporte e atualiza quando o
usuário libera a request.
Buffer quando a change request é liberada o import buffer do sistema destino é atualizado.
Data contém os arquivos R9<5 dígitos>.<source SID> onde ficam os objetos exportados. Quando os
arquivos começarem com D9<5 dígitos>.<source SID> é um (ADO – Application Defined objetcts) que foi
transportado
Log contém todas os arquivos de logs,tanto os ULOGS, ALOGS, SLOGS e os arquivos:
N<data>.<action SID> para cada step de conversão de estrutura.
P<data>.<action SID> para cada step de nametabs.
Cópia Controlada Page 82 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cópia Controlada Page 83 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Import Mode :
0 – importa do buffer sem deletar.
1 – ignora o que a change request já importou.
2 - regrava os originais.
3 – regrava os objetos do sistema específico.
6 – regrava os objetos não confirmando Repair.
8 – ignora as restrições.
9 – ignora que o sistema está bloqueado para este tipo de transporte.
Os comando do Buffer são :
TP SHOWBUFFER <SID> mostra as entradas contidas no buffer <SID>.
TP ADDTOBUFFER <change request> <SID destino> registra na fila de requests do buffer para ser
importada.
TP DELFROBUFFER <change request><SID destino> deleta uma entrada da fila.
TP CLEANBUFFER <SID> remove do buffer as requests que foram importadas com sucesso.
TP SETSTOPMARK <SID> coloca uma marca na lista de request que estão no buffer, e qdo importar as
request, só importará as requests antes da marca.
TP DELSTOPMARK <SID> retira a marca da lista de request.
Cópia Controlada Page 84 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Os comando do Buffer são :
TP SHOWBUFFER <SID> mostra as entradas contidas no buffer <SID>.
TP ADDTOBUFFER <change request> <SID destino> registra na fila de requests do buffer para ser
importada.
TP DELFROBUFFER <change request><SID destino> deleta uma entrada da fila.
TP CLEANBUFFER <SID> remove do buffer as requests que foram importadas com sucesso.
TP SETSTOPMARK <SID> coloca uma marca na lista de request que estão no buffer, e qdo importar as
request, só importará as requests antes da marca.
TP DELSTOPMARK <SID> retira a marca da lista de request.
Cópia Controlada Page 85 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para limpar o diretório de transporte, use os comandos TP CHECK ALL e TP CLEAROLD ALL.
Cópia Controlada Page 86 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
TP check all – pesquisa nos diretórios os arquivos que não são mais necesssários, aqueles arquivos que
correspondem a request não marcadas para import.
TP clearold all – usa o resultado da lista gerada pelo tp check all gravada no arquivo (ALL_OLD.LIS) para
localizar os arquivos que excederam o seu tempo de permanência nos diretórios.
Este tempo é definido no arquivo TPPARAM nos parâmetros :
Datalifetime – move os arquivos do usr/sap/trans/data conforme o tempo estabelecido para o olddata, os
arquivos do subdiretório LOG e COFILES são deletados se excederam o tempo específicado no loglifetime e
cofilifetime.
Os arquivos do OLDDATA são deletados de acordo com o olddatalifetime.
Antes de limpar o diretório de transporte, a SAP recomenda salvar uma cópia do diretório para auditoria, veja
notas 41732 no OSS.
Client Tools
Cópia Controlada Page 87 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para fazer uma cópia de client local :
1. Verifique o espaço disponível nas tablespaces (via sapdba).
2. Deslique o Archive do banco de dados (via sapdba)
3. Copia de customizing – 130MG – 200MG.
4. Se logue no client destino. Ex. se for fazer a cópia do client 010 no 030, se logue no 030
5. Execute a transação SSCL
6. Selecione o perfil desejado, “SAP_ALL” e escolha o mandante origem e mestre usuário
7. Na tela de verificação – escolha SIM
8. Na tela de confirmação, anote o número de registros e escolha SIM
9. Execute a transação SCC3 para acompanhar a cópia.
Quando o processo estiver processando a seguinte mensagem será mostrada se alguem tentar se logar no
client : The client is wrently locked againt.
De acordo com a nota 68896 o tempo de cópia de client é :
120MB por hora para cópia
80MB por hora para deleção
200MB por hora para Export
80MB por hora para Import
Para validar a cópia , verifique as tabelas BSEG e MSEG, caso der erro na cópia client veja as notas 22514 e
69444..
Cópia Controlada Page 88 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cópia de Client muito grande:
Delete antes as tabelas muito grande pelo SQLPLUS
Delete FROM BKPF WHERE MANDT = ‘350’
Verifique as segunites notas : Missing indices nota 15374
Exclusive lockwaits nota 15374
Rollback segments 10146, 60233, 102034
NOTAS 68896 - Acelera a Deleção
96296 - Transparent Table
15374 - Check List de Performance
70643 - Deleção de Client
118823 - Sizing Client
89188 - R3 System Copy
48400 - Spoll
Cópia de client com User Master de um client e Master Data de outro:
Execute a transação SE38 e rode o programa “RSADRCK2”.
Cópia Controlada Page 89 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para fazer uma cópia de client remoto :
1. Escolha o perfil para cópia (SAP_EXPA – Perfil para gerar os independentes) escolha o client de origem
do dados e o client de origem dos dados de usuários.
2. Escolha a opção execução de fundo (executar em background).
3. Aperte o botão Escalonar job e confira o dados para a cópia.
4. Clique no botão Sim e escalone o job na tela a seguir apertando imediatamente e em seguida, salve.
5. Na próxima tela será solicitado um dispositivo de saída para impressão do andamento da cópia (Se você
não quiser este protocolo basta não selecionar nenhum dispositivo) clique em gravar.
6. Neste momento a sua cópia já está em execução. Para verificar o seu andamento entre na transação
SCC3. Escolha o client de destino que você deseja ver o protocolo.
7. Gera 5 arquivos : usr/sap/trans/data/Ronnnnnnn.SID
Usr/sap/trans/data/RTnnnnnnn.SID
Usr/sap/trans/data/SXnnnnnnn.SID
Usr/sap/trans/cofile/KOnnnnnn.SID
Usr/sap/trans/cofile/KTnnnnnn.SID
Os arquivos KO são tabelas de client Independ
KT são tabelas client –depend.
SX são sapscript.
8. No sistema destino, copie os arquivos gerados nos mesmos diretórios.
9. No prompt do sistema operacional, no diretório de transporte USR/SAP/TRANS/BIN execute o comando
“TP ADDTOBUFFER <SID>Konnnnn <SID atual> para carregar o request para o buffer do sistema .
Execute o comando “TP IMPORT <SID>Konnnnn <SID> CLIENT=xxx U12368
10. Repetir a etapa 13 para o KT. (Para erros nas tabelas INSCHK e INSCHKB ignorar pois estas tabelas são
exclusivas do sistema origem).
11. Execute a transação SCC2(30F) ou SCC7(40B) no sistema destino, marque a opção IMPORT e de
<ENTER>, digite o nome da request do KT e execute em Background.
12. Caso não apareça o request, execute a transação SE38 e com o programa “RSCLIIMP” e coloque o nome
do arquivo KT e execute em background.
13. Execute o programa “RSTXR3TR”, digite o nome do arquivo <SID>KXnnnnn no campo Transport Request
Data Set Name – digite o caminho /usr/sap/trans/data/SXnnnnn.<SID>
Binary File – não preencher
Mode - IMPORT
Display Dataset – não preencher
Language Vector – preencher com as linguagens instaladas (Deve ser na mesma seqüência do parâmetro
de language na instance.
Veja nota 47502 para cópia remota.
Cópia Controlada Page 90 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Após o processo de Import ter sido completado, a atividade Pós-Import é requerida pelos textos Sapscript
e alguns objetos gerados nesta fase.
Selecione : tools > administration > administration > client admin > client transport > post process import.
Cópia Controlada Page 91 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cópia Controlada Page 92 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para deletar um client , se logue no client que será deletado e selecione : tools > Adminitration >
administration > client admin > special function > delete client.
Pelo sistema opercional , crie um job com os seguintes comandos:
CLIENTREMOVE
CLIENT=n_client
SELECT *
No diretório usr/sap/trans/bin, execute o job criado com o comando r3trans: R3TRANS –v batch_deleção
Quando terminar a delação entre na transação SM31 – edite a tabela T000 – clique em maintain – delete a
entrada do client.
Cópia Controlada Page 93 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para usar a função COMPARE selecione : tools > administration > administration > client admin > special
function > table analyses.
Podemos utilizar esta função quando :
1- Após um Upgrade ou import language.
2- Durante um cenário de Rollout.
3- Comparando uma customização de client independente antes de um rollout.
Cópia Controlada Page 94 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cópia Controlada Page 95 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Proteção 0 – nenhuma restrição.
Proteção 1 – O client não pode ser regravado por uma cópia de client.
Proteção 2 – Também não pode ser regravado por cópia de client e é protegido contra leitura de outro client
durante uma cópia ou uma comparação.
Cópia Controlada Page 96 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cópia Controlada Page 97 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
R/3 Upgrade and OCS Patches
A evolução típica do sistema R/3 em produção segue:
Alterações e customizações para novos deenvolvimentos.
Aplicação de correções da SAP, os OCS (Online Correction Service).
Cópia Controlada Page 98 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Aplique as correções na sequência : SPAM update, Hot package e LCP e as CRT´s.
Cópia Controlada Page 99 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
SPAM update é a alteração da versão da transação SPAM.
Hot Packages são grupos de correções e devem ser aplicados na sequência. Os nomes das hot´s são
SAPKH<release N.><sequência numérica>, são aplicados pela transação SPAU.
CRT (Conflit Resolution Transports) fornece adicionais objetos para resolver conflitos entre o R/3 e o SAP
ADD-ON.
LCS (Legal Change Patches) são correções usadas para aplicações de HR.
1- Requisitar os patches do OSS ou SAPNET.
2- Fazer download dos patches no servidor de desenvolvimeto usr/sap/trans/EPS.
3- Use a SPAM para :
a. Definir a fila de patches.
b. Selecione a SPAM.
c. Aplique os patches da fila.
d. Faça os ajustes caso sejam necessários.
e. Verifique os logs.
f. Confirme os patches.
4- Verifique e valide o ambiente.
Veja nota 33525.
Cópia Controlada Page 100 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Verificar o Patch Level do sistema.
1-) Entre na SM51.
2-) Posicione o cursor sobre a instance .
3-) Clique na tecla Release Notes.
Administrando o Banco de Dados
Quando começamos a falar de banco de dados com R/3, nos preocupamos com Performance, segue uma
série de dicas de como devemos analisar as transações voltadas para Performance de Banco de Dados
independente de qual seja ele (SQL, Oracle, Informix, etc)
- Fazer a pergunta: é um problema generalizado (afeta todos os usuários), localizado (afeta somente a
execução de algumas transações) ou ainda um problema localizado que, quando ocorre, leva a um
problema generalizado de performance (uma transação que, ao ser executada, “derruba” o servidor de
banco de dados)?
Parte dos ajustes que podem ser realizados a fim de melhorar o desempenho de um sistema R/3 estão
relacionados a configurações dos componentes do R/3, como Sistema Operacional (tamanho de swap,
presença de processos externos), Banco de Dados (parâmetros que controlam o tamanho do data buffer,
shared pool), Instâncias R/3 (número e tipos de work processes, tamanho das regiões locais e
compartilhadas de memória como buffers e extended memory) e Rede.
Uma configuração não otimizada dos componentes acima leva a problemas generalizados de
performance.
Podem haver problemas de performance mais localizados, ocorrendo apenas em uma ou algumas
transações, causados por fatores mais específicos. Detectadas estas transações, devemos submetê-las a
uma análise mais detalhada, analisando os trechos que realizam processamentos muito longos, ligados à
execução de programas ABAP ou ao acesso à tabelas no banco de dados. Após detectar o gargalo dentro
da transação, devemos levantar as possíveis ações para amenizá-lo ou até mesmo eliminá-lo.
Transações com gargalos durante suas execuções caracterizam problemas localizados de performance
que podem, eventualmente, levar a problemas generalizados de performance.
COMPOSIÇÃO DO TEMPO DE RESPOSTA
Wait Time é o Tempo que o request do usuário aguarda na fila do dispatcher até ser “despachado” para um
work process.
Roll Time é oTempo para copiar a parte inicial do contexto do usuário para dentro do work process – da roll
memory (shared) para a roll_first da roll_area (local do WP).
Load Time é o Tempo de carga do “load” (objeto compilado) de programa ABAP, telas, menus para dentro do
buffer correspondente (na instância R/3).
Processing Time é o Tempo gasto na execução dos comandos ABAP do programa chamado.
Deve ser calculado da seguinte forma:
Processing Time = TR – Wait – Roll – Load – DB Request Time
DB Request Time é o Tempo aguardando a resposta do gerenciador de banco de dados a uma solicitação
passada através da Database Interface (componente do WP).
Cópia Controlada Page 101 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Enqueue Time é Tempo gasto para realizar “lock” – muito pequeno.
CPU Time Corresponde ao tempo de utilização de CPU pelos componentes do Tempo de Resposta que
envolvem CPU do Application Server (Roll, Load e Processing). Não é possível determinar quanto de CPU foi
gasto em cada um dos componentes. Desta forma, parte do CPU Time está em Roll, parte em Load e parte
em Processing. Espera-se que o CPU Time seja próximo do Processing Time; caso contrário, é provável que
haja problemas de gargalos de hardware.
Dispatch Time é o tempo gasto pelo request dentro do Work Process. A fórmula para o cálculo é:
Dispatch Time = TR –Wait Time.
O Dispatch Time ajuda muito na análise do tempo de resposta, por exemplo: uma transação tem um TR médio
de 4s, mas o Wait Time médio é 3.5s. Desta forma, o Dispatch Time é de 0.5s (rápido). O ajuste para esta
situação é completamente diferente em um outro caso, onde o TR médio de uma transação também é 4s, mas
o Wait Time é 0.2s. Neste caso, o Dispatch Time é 3.8s (alto). O que quer dizer que o dispatcher encontra um
work process disponível rapidamente, mas o tempo gasto dentro dele é muito alto. Para acessar as
estatísticas devemos usar a transação ST03. Em seguida escolhemos qual o período a ser analisado, o que
deve ser feito cuidadosamente. Selecionamos o botão "Performance database", em
seguida o aplication server a ser analisado, e finalmente o período de análise. A próxima tela apresenta as
estatísticas do sistema, com os valores dos componentes do tempo de resposta para cada um diferentes
tipos de processamento (Dialog, Update, Background, etc).
VALORES ÓTIMOS DOS COMPONENTES
Wait Time < 10% do TR
Roll Time (in/out) < 50ms
Load Time < 10% do TR
Processing Time < 40% do Dispatch Time (TR – Wait)
DB Request Time < 40% do Dispatch Time (TR – Wait)
CPU Time > (Processing Time/2) (maior que metade do Processing Time)
Baseado nesses valores ótimos dos componentes do tempo de resposta, devemos analisá-los para cada
tipo de processamento (para selecionar o tipo de processamento, devemos usar os botões na parte inferior
da janela.
Analisados cada um deles, podemos determinar os sintomas dos problemas que eles identificam:
Wait Time Tempo de espera para obter work processes
Roll Time (in/out) Problemas com CPU ou memória do Sistema SAP R/3
Load Time Problemas nos buffers do Sistema SAP Sistema SAP R/3 (muito pequenos)
Processing Time Problemas no programa ABAP ou no banco de dados.
DB Request Time Problemas no banco de dados (SQL, índices, estatísticas, etc).
CPU Time Problemas de programas ABAP, grandes tabelas, CPU, rede, S.O.
PRINCIPAIS TRANSAÇÕES PARA ANÁLISE DE PERFORMANCE
ST03 Analisa o TR médio de um período. É possível realizar consultas “quebradas” por horário, memória, e
principalmente por Transação (Transaction Profile).
SM50/SM66 Visão geral de work processes
ST06 Monitor de Hardware e Sistema Operacional.
ST02 Monitor de memória e buffers
ST04 Monitor do banco de dados
Cópia Controlada Page 102 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
ST05 SQL Trace
SE30 Runtime Analysis (ABAP Trace)
ST10 Estatísticas de chamadas a tabelas
BUFFER DE PROGRAMAS E IMPACTOS NA PERFORMANCE.
Para que um programa chamado por um usuário seja executado, o seu “load” (objeto compilado) deve estar
presente no buffer de programa da instância R/3 onde o usuário está conectado. Quando um programa é
chamado pela primeira vez (ainda não está no buffer), o work process tenta localizar o “load” no banco de
dados, nas tabelas D010*. Se não existir um load, o R/3 compila o programa fonte (parte do Load Time) e
gera esse load. Em seguida,o WP lê esse load do banco de dados para dentro do buffer de programa (parte
do DB Req. Time). A partir daí, este work process passa a executar o programa. Em execuções
subseqüentes deste programa, os WP localizarão o programa em buffer (Load Time) e não haverá a
necessidade de carregá-lo novamente a partir do banco de dados.
Se o buffer de programa foi definido com um tamanho ideal, todos os programas chamados pelos usuários
serão carregados dentro dele e ainda sobrará espaço livre. Com o tempo, os mesmos programas vão sendo
chamados, e a taxa de eficiência do buffer (hitratio) vai subindo, já que os programas são localizados em
buffer, não havendo a necessidade de carregá-los a partir do banco. Contudo, se o buffer de programa for
pequeno para a quantidade de programas chamados, haverá um momento em que ele estará 100%
utilizado, só que mais programas ainda precisam ser carregados em buffer. A partir deste momento,
começam o ocorrer SWAPS. O indicador “swaps” indica o número de objetos (no caso, programas) que
foram retirados do buffer para que outros objetos pudessem ser carregados. Quando ocorrem swaps,
podem aparecer os GAPS, que são resultado da fragmentação do buffer (desaloca um programa de 5MB e
carrega outro de 4.5MB – gap de 0.5MB).
Um buffer de programas fragmentado pode levar a um problema generalizado de performance. Se estão
ocorrendo swaps, programas estão sendo retirados do buffer. Estes programas, se forem chamados mais
tarde por usuários, deverão obrigatoriamente ser carregados a partir do banco de dados, e sua carga
acarretará no swap de um ou mais programas do buffer, perpetuando o problema. Se um programa que já
havia sido carregado em buffer sofreu um swap e precisa ser recarregado (reload), o WP fica ocupado por
mais tempo, pois precisa carregar o “load” a partir do banco de dados (tabelas D010*) para dentro do Buffer
de programa.
- Ficando o WP ocupado por mais tempo (maior DB Request Time), diminui a disponibilidade de work
processes.
- Diminuindo a disponibilidade de work processes, aumenta a concorrência por eles.
- Aumentando a concorrência por work processes, aumenta o Wait Time.
- Aumentando o Wait Time, aumenta o Tempo de Resposta.
O que observar:
SM50/SM66 Action: Load Report
Action: Direct Read / Table: D010*
ST02 Program Buffer:
HitRatio < 90%
Swaps > 0
Gaps = Free Space
Cópia Controlada Page 103 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
ST03 TR médio das transações alto
Wait Time alto
Load Time alto
DB Request Time alto
GERENCIAMENTO DE MEMÓRIA E IMPACTOS NA PERFORMANCE
Cada instância de R/3 aloca diferentes regiões de memória para diferentes propósitos. Algumas são
consideradas LOCAIS, pois são acessíveis somente por um WP (roll area, paging area e heap area). Outras
são consideradas COMPARTILHADAS, pois são acessíveis por todos os WPs (roll buffer, paging buffer,
extended memory e buffer).
As principais considerações na definição destas áreas são:
- Garantir que a memória virtual total alocada pelo R/3 não exceda 50% acima da memória física do
servidor
- Evitar que um usuário, ao executar transações que consomem muita memória, entre em modo “PRIV”,
pois o WP que estiver utilizando assume status “stopped” e fica exclusivo para este usuário, até que ele
conclua a transação. Desta forma, diminui o número de WPs disponíveis, aumentando a concorrência,
aumentando Wait Time, aumentando Tempo de Resposta.
O que observar:
SM50/SM66 Status: “stopped” / Reason: “PRIV”
Err > 0
ST02 SAP Memory:
Extended Memory: Current Use > 80%
Heap Memory
Mode List – memória alocada por sessão de usuários
GARGALOS DE HARDWARE E IMPACTOS NA PERFORMANCE
O tempo de processamento depende diretamente da capacidade e disponibilidade dos processadores do
servidor. Quanto maior utilização ou concorrência, maior o tempo de processamento. Há ainda outros
fatores que podem influenciar o tempo de processamento, como I/O e rede.
O consultor deve analisar estes fatores em cada servidor que tem uma instância de R/3. Devem ser
observados indicadores sobre utilização de CPU, processos que mais consomem CPU, load average e
taxas de paginação do sistema operacional. Nunca deve haver um gargalo de hardware no servidor de
banco de dados, o que causaria um problema generalizado de performance que afetaria todos os usuários.
Os processos que mais consomem CPU devem ser processos ligados ao R/3 – work processes, saposcol,
processos do banco de dados. Caso algum processo externo seja o responsável por um consumo
considerável de CPU, o mesmo deve ser reavaliado e até mesmo cancelado.
Quando há gargalos de hardware, os componentes do TR que utilizam CPU apresentam valores altos,
embora o valor total de CPU seja baixo em relação a eles. Isso indica alguns “buracos” ocorridos durante
estes componentes. Ex: Processing Time de 1s e CPU total de 300ms. O ideal seria que todo o Processing
Time fosse preenchido com CPU Time.
O que observar:
Cópia Controlada Page 104 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
ST06 CPU Idle < 20%
Load Average > 3
Pages Out
Top CPU Processes (processos ligados ao R/3 ou processos externos?)
ST03 CPU Time < (Processing Time/2)
Processing Time alto
às vezes, Roll Time e Load Time altos (porque dependem de CPU)
A ferramenta CCMS disponível no R/3 monitora o banco, analisando o seu crescimento, capacidade, I/O
Statistics, e alertas.
Para monitorar a performance do Database,a transação ST04 é uma ferramenta independente do database,
que analisa e afina os seguintes componentes:
Memory and Buffer usage
Space Usage,
CPU usage
SQL requests
Detail SQL
A transação ST04 ou pelo menu Tools>Administration>Monitor>Performance>Database>St04>activity
Cópia Controlada Page 105 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Na tela acima visualizamos : Sistema Operacional, CPU e memória. O Microsoft SQL Server permite uma
análise de atributos específicos relacionado com memória, espaço, I/O e qualidade da leitura e gravação nas
tabelas.
As informações podem sinalizar ajustes necessários para melhorar a performance do database.
O detalhe 2b. Server Enginer Elapsed mostra como a CPU está trabalhando os processo do SQL. Neste
quadro temos que analisar os campos Ratio of Busy e Idle time.
2c. SQL Request permite uma imagem de como as queries SQL são utilizadas para acessar ar tabelas
relacionadas aos index e o total de tabelas.
A maior taxa de full table scan X Index scan pode indicar problemas de performance.
2d. Detail analysis – mostra os detalhes.
Cópia Controlada Page 106 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
2c2a
Tarefas de um DBA.
Um DBA geralmente efeta as seguintes tarefas:
Planejamento do banco de dados.
Configuração do sistema.
Criação do banco de dados.
Gerenciamento do espaço físico.
Administração da segurança (direitos de acesso, usuários e roles).
Gerenciamento de Backup/Recovery
Ajuste de desempenho.
Auditoria no banco de dados.
Startup do Sistema SAP R/3.
Para iniciar o sistema, entrar com o seguinte comando, conectado como <SAPSID>adm:
$ startsap
Esse programa STARTSAP é um alias para o verdadeiro script responsável pelo Startup do Sistema SAP R/3:
startsap_<hostname>_<no>
Os seguintes procedimentos são, então, feitos:
1. Verifica o sistema operacional, os parâmetros e o ambiente de execução.
2. Executa o programa SAPOSCOLL.
3. Executa o programa:
Cópia Controlada Page 107 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
/usr/sap/<SAPSID>/SYS/exe/run/startdb
Esse script inicializa o banco de dados, através dos seguintes procedimentos:
Lê o arquivo de parâmetros $ORACLE_HOME/DBS/INIT<SID>.ORA.
Aloca a SGA.
Cria os processos em background.
Abre os arquivos de TRACE para os processos em background.
Abre o arquivo de ALERTAS no diretório especificado pelo parâmetro
BACKGROUND_DUMP_DEST.
Abre os arquivos de controle (monta o banco de dados).
Abre o banco de dados (arquivos de dados e de log).
Esse script escreve um arquivo de log chamado STARTDB.LOG no diretório $HOME.
4. Executa o programa SAPSTART:
/usr/sap/<SAPSID>/SYS/exe/run/sapstart pf=<profile_filename>
Esse programa escreve um arquivo de log chamado STARTSAP_<hostname>_<no> no diretório
$HOME. Escreve também seus outros logs no diretório: /usr/sap/<SAPSID>/DVEBMS<no>/work.
Os profiles são buscados no diretório: /usr/sap/<SAPSID>/SYS/profile.
Em seguida, esse programa chama os programas do profile START_DVEMGS<no>:
Dispatcher
SE Syslog Send Daemon
MS Message Server
CO Syslog Collector Daemon
Shutdown do Sistema SAP R/3.
Para encerrar o sistema, entrar com o seguinte comando, conectado como <SAPSID>adm:
$ stopsap
Esse programa STARTSAP é um alias para o verdadeiro script responsável pelo Shutdown do Sistema SAP
R/3:
stopsap_<hostname>_<no>
Os seguintes procedimentos são, então, feitos:
1. Verifica o sistema operacional e o ambiente de execução.
2. Executa o programa KILL.SAP que remove todos os processos do Sistema SAP R/3:
/usr/sap/<SAPSID>/DVEBMGS<no>/work/kill.sap
3. Escreve o arquivo PXANEW:
/usr/sap/<SAPSID>/DVEBMGS<no>/pxanew
3. Executa o programa:
Cópia Controlada Page 108 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
/usr/sap/<SAPSID>/SYS/exe/run/stopdb
Esse script inicializa o banco de dados, através dos seguintes procedimentos:
Fecha o database (arquivos de dados e de log).
Fecha os arquivos de controle (desmonta o banco de dados).
Fecha todos os arquivos de TRACE.
Encerra os processos em background.
Desaloca a SGA.
Esse script escreve dois arquivos de log, chamados STOPDB.LOG e STOPSAP.LOG, no diretório
$HOME.
Estrutura de diretórios do Sistema SAP R/3.
Cópia Controlada Page 109 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
CENTRAL INSTANCE
usr sapmnt oracle
sap SAPSID SAPSID
trans SAPSID global profile exe saparch origlogA origlogB ..... sapdata
dvebmg SYS
data log work global profile exe
dbg opt run
DIALOG INSTANCE
usr sapmnt
sap SAPSID
trans SAPSID global profile exe
dvebmg SYS
data log work global profile exe
dbg opt run
Quando ajustar?
Cópia Controlada Page 110 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Custo
Benefício
Análise Desenvolvimento Produção
Métodos de otimização.
Entendimento da arquitetura do Oracle7.
Ajustar as regras de negócio.
Planejamento da capacidade dos sistemas.
Ajustar o desenho dos dados.
Organização e criação do melhor banco de dados.
Ajustar o desenho das aplicações.
Ajustar a estrutura lógica do banco de dados.
Consideração da performance durante o desenho de um sistema.
Otimização durante o desenvolvimento.
Ajustar os comandos SQL.
Ajustar os caminhos de acesso.
Otimização de um sistema em produção.
Ajustar a alocação de memória.
Ajustar o I/O e as estruturas físicas do banco de dados.
Ajustar a contenção.
Ajustes específicos das plataforma.
Facilidades de monitoração.
Visões V$, conhecidas como visões dinâmicas com informações sobre performance, fazem parte do
esquema SYS.
Script UTLMONTR.SQL, que se encontra no diretório $ORACLE_HOME/RDBMS/ADMIN.
Essas visões são baseadas nas tabelas X$ - estruturas em memória que contém as informações
básicas da instância. Todas elas podem ser visualizadas através de uma simples pesquisa na visão
V$FIXED_TABLE.
OEM – Oracle Enterprise Manager
CCMS – Computing Center Management System.
Suporte a SNMP.
Cópia Controlada Page 111 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
A instância e o banco de dados Oracle7.
PMON SMON RECO LCK
System Global Area
Shared Pool Redo Log Buffer
Database Buffer Cache
CKPT DBWR LGWR ARCH
Arquivo
de Arquivos
Controle de
Arquivos
Dados Armazenamento
de Redo
de Logs Offline
Log
Instância.
Banco de dados.
Processos em background.
Processos do Sistema SAP R/3.
Program Interface.
Arquitetura do SQL*Net.
Simulação de uma transação completa.
Cópia Controlada Page 112 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Os blocos de dados.
A estruturação dos blocos de dados.
Descrição dos blocos de dados.
Os parâmetros INITRANS e MAXTRANS.
Os parâmetros PCTFREE e PCTUSED.
T M X N M A X I N S
PCTFREE *100
TMX
TMX Tamanho máximo da linha, em byte.
NMAXINS Número máximo de bytes inseridos por linha atualizada.
Efeitos dos parâmetros PCTFREE e PCTUSED.
As extensões.
Definição de extensões.
A alocação das extensões.
A desalocação das extensões.
Os segmentos.
Tipos de segmentos.
A cláusula STORAGE.
STORAGE ( INITIAL integer [K|M] ]
[NEXT integer [K|M] ]
[PCTINCREASE integer]
[MINEXTENTS integer]
[MAXEXTENTS integer]
[OPTIMAL {integer [K|M] | NULL}]
[FREELIST GROUPS integer]
[FREELISTS integer] )
Os segmentos de índices.
Neste comando existe a possibilidade da especificação dos parâmetros de armazenamento para as
extensões do segmento de índice, inclusive o nome da tablespace que deve receber o segmento
desejado; o segmento de dados de uma tabela e o segmento de índice para os índices associados à
tabela não precisam residir necessariamente na mesma tablespace.
Na verdade, é uma boa prática criarmos as tabelas e seus índices associados em diferentes
tablespaces, para melhorarmos a performance do banco de dados.
Os segmentos de rollback.
Cada banco de dados pode conter um ou mais segmentos de rollback.
Eles são criados pelo DBA para armazenar temporariamente as informações usadas para a
recuperação do banco de dados em caso de falhas, para gerar o efeito da consistência de leitura, para
efetuar a recuperação das transações feitas pelos usuários que não tiverem sido efetivadas com o
comando COMMIT e para desfazer uma transação, inteiramente ou em parte, que tenha sido terminada
com o comando ROLLBACK.
As informações em um segmento de rollback, portanto, consistem em diversas entradas de rollback.
Entre outras coisas, uma entrada num segmento de rollback inclui informações sobre o bloco (o nome
do arquivo e a identificação do bloco que foi alterado) e o dado existente antes de uma operação.
Essas informações de rollback de uma mesma transação são ligadas entre si e, desse modo, elas
podem ser facilmente localizadas quando for necessário.
Os segmentos de rollback não podem ser acessados (ou mesmo lidos) pelos usuários de um banco de dados,
nem mesmo pelo DBA.
Cópia Controlada Page 113 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Eles são escritos e lidos estritamente pelo próprio Oracle7 (através do esquema SYS).
Todas as entradas de rollback são registradas nos arquivos de redo log. Esse registro é muito
importante para o controle das transações ativas que ainda não tenham sido efetivadas.
Se ocorrer uma falha do sistema, as informações do segmento de rollback, incluindo as entradas das
transações ativas, são automaticamente recuperadas como parte da recuperação da instância.
O processo de descartar as transações não efetivadas com o comando COMMIT é feito após a
completa recuperação.
O Oracle7 mantém uma tabela de transações para cada segmento de rollback contido em um banco de
dados.
Essa tabela é uma lista de todas as transações que usam o segmento de rollback associado e as
entradas de rollback para as alterações feitas pelas transações.
Para cada transação, uma nova alteração é ligada à alteração anterior.
Se uma transação precisar ser desfeita, as alterações são aplicadas aos blocos de dados em uma
ordem tal que os valores são retornados aos valores anteriores a elas.
Similarmente, quando o Oracle7 necessita garantir a consistência de leitura para um grupo de pesquisas nas
tabelas de um banco de dados, podem ser utilizadas as informações do segmento de rollback para criar um
grupo de dados consistentes com o momento de execução das consultas (as tabelas são congeladas e, com o
segmento de rollback, a consistência da leitura torna-se possível).
Todos os tipos de rollback usam os mesmos procedimentos:
Rollback a nível de comando por causa de uma falha qualquer (por exemplo, na ocorrência de um
dead-lock).
Rollback até um ponto definido da transação (SAVEPOINT).
Rollback de uma transação devido a uma solicitação de um usuário.
Rollback de uma transação devido ao término anormal de um processo.
Rollback de uma transação devido a uma falha da instância.
Rollback das transações incompletas durante os procedimentos de recuperação de um banco.
A cada momento em que uma transação se inicia, ela é automaticamente associada a um segmento de
rollback.
Uma transação pode ser automaticamente assinalada ao próximo segmento de rollback disponível e
isso ocorre no momento da execução do primeiro comando DDL ou DML.
As transações do tipo READ-ONLY (transações que contêm somente consultas) nunca são assinaladas
a um único segmento de rollback.
Uma transação pode ser explicitamente assinalada a um segmento de rollback específico a uma
aplicação, no momento da sua inicialização. Com essa característica o usuário ou desenvolvedor pode
selecionar um segmento grande ou pequeno, de acordo com as características de sua transação.
Durante uma transação, o processo do usuário associado escreve as informações de rollback somente
no segmento de rollback assinalado.
Quando uma transação é efetivada (COMMIT) as informações de rollback são liberadas, mas não
imediatamente destruídas.
Essas informações permanecem no segmento de rollback para permitir a consistência da leitura dos
dados lidos pelas consultas solicitadas antes da transação ser confirmada.
Quando a última extensão de um segmento de rollback é completamente preenchida, o Oracle7
continua escrevendo as informações de rollback na primeira extensão utilizada, de forma circular.
Entretanto, para algumas transações muito extensas, o Oracle7 pode requerer uma nova extensão a
ser alocada para o segmento.
Cópia Controlada Page 114 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cada segmento de rollback pode manipular um certo número de transações de uma instância. Este número é
específico do sistema operacional e varia conforme o tamanho dos blocos de dados.
A menos que as transações sejam explicitamente assinaladas a um segmento de rollback específico, o
Oracle7 as distribui entre os outros disponíveis, sendo que todos os segmentos possuem assinalados o
mesmo número de transações ativas.
A distribuição das transações não depende do tamanho dos segmentos de rollback.
Quando eles são criados, os parâmetros de armazenamento podem ser utilizados para especificar como a
alocação do espaço é controlada. Pelo menos duas extensões devem ser alocadas para cada segmento de
rollback.
Uma transação escreve as informações seqüencialmente e usa somente um segmento ao mesmo
tempo.
Por outro lado, diversas transações ativas podem compartilhar o mesmo segmento de rollback, inclusive
uma mesma extensão, mas os blocos de dados somente podem conter informações sobre uma única
transação.
Quando uma extensão se torna completamente cheia e não existe mais espaço para uma transação, o
Oracle7 localiza uma outra extensão disponível no mesmo segmento de rollback.
Para isso, ele reutiliza uma outra extensão já alocada ou aciona e aloca uma nova extensão para o
segmento.
A primeira transação que precisar acionar mais espaço no segmento de rollback verifica a próxima
extensão e, caso não exista nenhuma transação nela pendente, o Oracle7 a utiliza para amazenar as
informações de rollback de todas as transações que necessitarem.
Quando um segmento de rollback é criado ou alterado, o parâmetro de armazenamento OPTIMAL, que
é utilizado somente para esses tipos de segmentos, pode ser usado para especificar o melhor tamanho,
em bytes.
Se uma transação precisa continuar a escrever as entradas de rollback em uma outra extensão, o
Oracle7 compara o tamanho do segmento com o tamanho ótimo (parâmetro OPTIMAL).
Se o segmento de rollback é maior que o tamanho ótimo e a extensão seguinte está inativa, o Oracle7
desaloja extensões consecutivas não ativas para o segmento até que o seu tamanho total seja igual ou
maior ao tamanho ótimo.
Um segmento de rollback configurado com o parâmetro OPTIMAL não pode ser menor do que o espaço
combinado destinado ao número mínimo de extensões de um segmento.
Quando um segmento de rollback é eliminado, todas as extensões são retornadas para a tablespace e
ficam disponíveis para outros segmentos.
Quando uma instância abre um banco de dados, pode acionar um ou mais segmentos de rollback e
assim controlar informações de rollback produzidas por transações subseqüentes.
Os segmentos de rollback acionados por uma instância podem ser públicos ou privados.
Um segmento de rollback privado é aquele explicitamente acionado quando o banco de dados é aberto.
Os segmentos de rollback públicos formam um grupo de segmentos que podem ser usados por
qualquer instância.
Qualquer número de segmentos de rollback, privados ou públicos, podem existir em um banco de
dados.
Assim que uma instância abre um banco de dados, experimenta acionar um ou mais segmentos de rollback
de acordo com as seguintes regras:
Uma instância pode acionar no mínimo um segmento de rollback. Se somente uma instância está
acessando um banco de dados, ela aciona o segmento SYSTEM; se uma instância é apenas mais uma
das que acessam um banco de dados, ela aciona o segmento de rollback SYSTEM e pelo menos um
outro segmento. Se esse outro segmento de rollback não pode ser acionado, um erro é retornado e a
instância não pode abrir o banco de dados.
Cópia Controlada Page 115 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
A instância, em primeiro lugar tenta acionar todos os segmentos de rollback privados especificados pelo
parâmetro ROLLBACK_SEGMENTS. Se uma instância abre um banco de dados e tenta acionar um
segmento de rollback privado já utilizado por outra instância, a primeira recebe uma mensagem de erro
durante a inicialização do banco de dados. Um erro também ocorre se uma instância tenta acionar um
segmento de rollback privado que não existe.
Se uma instância for acionada com um número suficiente de segmentos de rollback privados, nenhuma
outra ação é necessária. Entretanto, se mais segmentos forem necessários, a instância aciona os
públicos.
Uma instância sempre tenta acionar no mínimo o número de segmentos de rollback igual ao quociente
dos valores dos seguintes parâmetros de inicialização:
TRANSACTIONS
CEIL
TRANSACTIONS_ PER_ ROLLBACK_ SEGMENT
O parâmetro TRANSACTIONS_PER_ROLLBACK_SEGMENT não limita o número de transações que
podem acessar um segmento de rollback. Ao contrário, ele determina o número de segmentos de
rollback acionados quando uma instância abre um banco de dados. O parâmetro TRANSACTIONS é
especificado de acordo com o valor do parâmetro PROCESSES:
TRANSACTIONS = PROCESSES * 1.1
Os diferentes status de um segmento de rollback podem ser um dos seguintes:
OFFLINE Não acionado por nenhuma instância.
ONLINE Está sendo acionado por uma instância e pode conter dados de uma transação
ativa.
NEEDS Contém dados de transações não efetivadas que não podem ser desfeitas pelo
RECOVERY fato dos arquivos envolvidos estarem inacessíveis ou com problemas.
PARTLY Contém dados de uma transação distribuída ainda não resolvida.
AVAILABLE
INVALID Foi eliminado (o espaço uma vez alocado para um segmento de rollback pode
ser reutilizado mais tarde quando um novo segmento for criado).
Os estados PARTLY AVAILABLE e NEEDS RECOVERY são bastante parecidos.
O primeiro indica que o segmento está sendo utilizado por uma transação distribuída que não pode ser
resolvida por causa de uma falha na rede.
O estado NEEDS RECOVERY indica que o segmento está sendo utilizado em uma transação local ou
distribuída que não pode ser resolvida por causa de uma falha nos dispositivos de armazenamento do
banco de dados, como por exemplo um arquivo não existente ou com problemas.
O Oracle7 ou mesmo o DBA podem tornar um segmento de rollback com o estado PARTLY
AVAILABLE disponível para uso (ONLINE), mas o segmento de rollback no estado NEEDS RECOVERY
deve ser alterado para OFFLINE antes de ser deixado disponível (se um banco de dados é recuperado,
o Oracle7 automaticamente altera o estado do segmento de rollback para OFFLINE).
O DBA pode remover um segmento de rollback no estado NEEDS RECOVERY, mas não se o
segmento estiver no estado PARTLY AVAILABLE.
Cópia Controlada Page 116 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Os segmentos temporários.
Os segmentos temporários são alocados quando necessários durante a sessão de um usuário e são
eliminados quando o comando executado termina.
As características de armazenamento das suas extensões são determinadas pelas características da
própria tablespace utilizada pelo segmento temporário.
Com o comando CREATE USER e ALTER USER podemos especificar a tablespace temporária de um
usuário através da cláusula TEMPORARY TABLESPACE.
Opcionalmente, podemos criar uma classe especial de tablespace para conter esses segmentos. São as
chamadas tablespaces temporárias! Podemos criá-las através do comando CREATE TABLESPACE com a
cláusula TEMPORARY.
Consideremos, na sua criação, especificarmos o valor dos parâmetros INITIAL e NEXT como múltiplos do
parâmetro SORT_AREA_SIZE e PCTINCREASE como 0. Uma tablespace assim identificada não pode conter
qualquer outro objeto que não seja um único segmento temporário, usado por toda a instância e criado
automaticamente pelo Oracle7 para as ordenações quando o primeiro comando que requer a ordenação é
emitido.
O seu crescimento é de acordo com a demanda e seus extents podem ser usados pelas diferentes operações
de ordenações. A descrição desse segmento temporário especial é descrito em uma estrutura da SGA
chamada Sort Extent Pool (SEP). Podemos monitorar o segmento de ordenacão através da visão
V$SORT_SEGMENT:
CURRENT_USERS Número de usuários ativos.
TOTAL_EXTENTS Número total de extents.
USED_EXTENTS Número de extents atualmente alocados para as ordenações.
EXTENTS_HITS Número de vezes que um extent não usado foi encontrado no pool da SGA
(SEP).
MAX_USED_BLOCKS Número máximo de blocos usados.
MAX_SORT_BLOCKS Número máximo de blocos usados por uma única ordenação.
A tablespace SYSTEM é a tablespace temporária padrão para os usuários que não foram associados a
nenhuma outra, explicitamente.
Pelo fato dos segmentos temporários serem alocados e desalocados muito freqüentemente, é uma boa
prática a utilização de uma tablespace específica para contê-los.
Ganhamos com isso a efetiva distribuição do I/O entre diferentes acionadores de disco e uma melhoria
na fragmentação da tablespace SYSTEM e de outras tablespaces usadas para os segmentos
temporários.
As informações de redo log não contêm qualquer entrada das alterações feitas nos segmentos
temporários.
Esses segmentos, na verdade, devem ser distribuídos em uma ou mais tablespaces separadas de
todas as outras, visto que são eles que causam os maiores problemas de fragmentação dos dados.
Cópia Controlada Page 117 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Os diversos tipos de segmentos de um banco de dados.
REM ********************
REM CKSEGTYP.SQL
REM Espaco alocado para cada tipo de segmento
REM ********************
BREAK ON OWNER
SELECT SUBSTR(owner,1,20) "OWNER",
SUBSTR(tablespace_name,1,15) "TABLESPACE",
SUBSTR(segment_type,1,15) "SEGMENT_TYPE",
SUM(bytes) "BYTES"
FROM dba_extents
GROUP BY SUBSTR(owner,1,20),
SUBSTR(tablespace_name,1,15),
SUBSTR(segment_type,1,15);
REM ********************
SQL> @CKSEGTYP.SQL
OWNER TABLESPACE SEGMENT_TYPE BYTES
-------------------- --------------- --------------- ----------
SCOTT TOOLS INDEX 471040
TOOLS TABLE 5365760
SYS RBS ROLLBACK 18380800
SYSTEM CACHE 2048
SYSTEM CLUSTER 4751360
SYSTEM INDEX 21923840
SYSTEM ROLLBACK 204800
SYSTEM TABLE 67946496
TREINAMENTO ROLLBACK 1269760
USERS TABLE 368640
SYSTEM TOOLS INDEX 1658880
TOOLS TABLE 7188480
TREINAMENTO TABLE 10240
USERS TABLE 3072000
Cópia Controlada Page 118 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O que são as tablespaces?
Uma tablespace é usada para agrupar outras estruturas lógicas relacionadas entre si e, dessa forma,
organizar o banco de dados. Por exemplo, geralmente as tablespaces agrupam todos os objetos de uma
aplicação para simplificar certas tarefas administrativas.
Um ou mais arquivos de dados são criados explicitamente para cada tablespace, ou seja, cada uma
delas é formada por um ou mais arquivos no sistema operacional. Portanto, os dados de uma
tablespace são armazenados coletivamente nos arquivos de dados que a formam.
Quando um objeto de um esquema é criado, como uma tabela ou índice, o seu segmento é também
criado em uma tablespace específica.
O segmento de um objeto aloca espaço em somente uma tablespace.
O tamanho combinado dos arquivos de dados que formam uma tablespace ditam a sua capacidade
total de armazenamento.
A combinação da capacidade de armazenamento de todas as tablespaces que formam um banco forma
a capacidade total de armazenamento desse banco de dados.
O uso das tablespaces.
Uma tablespace pode estar acessível ou não (dizemos comumente que pode estar ONLINE ou OFFLINE) e
geralmente permanece ONLINE, disponível para os usuários. Entretanto, para algumas tarefas administrativas
ou em algumas situações especiais, é possível deixá-las OFFLINE. Elas são usadas para:
Controlar a alocação do espaço em disco para os dados de um banco de dados.
Assinalar quotas específicas de espaço para os usuários.
Controlar a disponibilidade dos dados.
Executar operações parciais de cópia e recuperação de um banco de dados.
Alocar o armazenamento dos dados entre diferentes dispositivos de armazenamento para melhorar a
performance do banco de dados.
A tablespace SYSTEM.
Podemos criar novas tablespaces, adicionar e remover arquivos de dados, configurar e alterar os parâmetros
de armazenamento para os segmentos criados e, naturalmente, podemos removê-las sem maiores
problemas. Cada banco de dados Oracle7 contém uma tablespace chamada SYSTEM, que é criada
automaticamente na criação do banco.
Essa tablespace contém os dados das tabelas do dicionário de dados.
Um banco de dados pequeno pode ter apenas a tablespace SYSTEM; entretanto é recomendável que
pelo menos uma outra seja criada para armazenar os dados dos usuários separados das informações
do dicionário de dados. Isto permite mais flexibilidade em várias tarefas administrativas e pode reduzir a
contenção (acesso simultâneo aos objetos por processos de diversos usuários) entre os objetos do
dicionário de dados e os objetos dos esquemas dos usuários.
Essa tablespace precisa sempre estar disponível (ONLINE) para o banco.
Tablespaces ONLINE e OFFLINE.
Podemos tornar qualquer tablespace disponível (ONLINE) ou não disponível (OFFLINE) quando um banco de
dados é aberto.
A única exceção, segundo o comentário anterior, é que a tablespace SYSTEM nunca pode ser deixada
no estado OFFLINE, pois o dicionário de dados precisa ficar sempre disponível para o banco de dados.
Todos os programas gerados pela opção procedural (procedures, funções, packages e triggers)
geralmente são armazenados na tablespace SYSTEM. Portanto, se qualquer um desses objetos for
criado em um banco, precisamos planejar o espaço requerido na tablespace SYSTEM.
Cópia Controlada Page 119 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Quando uma tablespace está OFFLINE (não disponível) o Oracle7 não permite qualquer comando SQL
que referencie os objetos lá contidos. As transações ativas que possuem comandos SQL que acessam
os dados de uma tablespace que tornou-se não disponível, gravam os dados de rollback em segmentos
de rollback especiais cedidos pelo Oracle7 (deferred rollback segments), na tablespace SYSTEM.
Quando a tablespace volta a ficar disponível, o Oracle7, se necessário, aplica o segmento de rollback
cedido.
Uma tablespace não pode tornar-se inacessível enquanto existir pelo menos um segmento de rollback
ativo. O Oracle7 automaticamente pode alternar o estado de uma tablespace, de ONLINE para
OFFLINE, quando certos tipos de erros acontecem (por exemplo, quando um processo falha em
diversas tentativas de escrever um dado na tablespace).
Os usuários que tentam acessar uma tablespace com problemas recebem uma mensagem de erro e,
caso esse erro seja proveniente de uma falha de disco, a tablespace deve ser recuperada após a
resolução do problema.
Alterando o tamanho de uma tablespace.
Para aumentar um banco de dados, um ou mais arquivos de dados podem ser adicionados, aumentando
assim o espaço disponível na tablespace correspondente. Alternativamente podemos criar outras tablespaces
para aumentar o tamanho de um banco. Também podemos dinamicamente alterar o tamanho dos arquivos de
dados que formam uma tablespace. Conseguimos isso através do seguinte comando:
SQL> ALTER DATABASE DATAFILE '/usr/app/oracle/product/8.0.3/dbs/user01.dbf' RESIZE 30M;
DATAFILE filespec { RESIZE integer [K|M]
| AUTOEXTEND { OFF
| ON [NEXT integer [K|M]
[MAXSIZE [UNLIMITED | integer [K|M]]]}}
Onde:
RESIZE Aumenta ou diminui o tamanho de um datafile.
AUTOEXTEND Liga ou desliga o crescimento automático de um datafile.
MAXSIZE É o tamanho máximo que um arquivo pode aumentar automaticamente. O valor default é
UNLIMITED, ou seja, limitado pelo sistema operacional.
NEXT É o tamanho mínimo de aumento de um datafile. O valor default é o número de bytes que
formam um bloco de dados do Oracle7.
Cópia Controlada Page 120 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Os diversos tipos de tablespaces.
Um número mínimo de tablespaces devem ser criadas, além da tablespace SYSTEM. A tabela mostrada a
seguir apresenta esses tipos e o que cada uma deve conter.
Tablespace O que contém?
SYSTEM Somente segmentos do dicionário de dados.
TEMP Somente segmentos temporários.
RBS Somente segmentos de rollback.
TOOLS Segmentos de propósito geral.
USER Segmentos de usuários quaisquer.
DATA Contém segmentos de dados para os objetos dos seus sistemas. Na prática, você
deve usar diversas tablespaces de dados, pois esta é a forma que o Oracle7
possui para que você possa particionar o conteúdo do banco de dados em
diversos arquivos físicos para a otimização do seu sistema.
INDEX Segmentos de índices referentes aos segmentos de dados que se encontram nas
tablespaces de dados (DATA).
Precisamos considerar as características dos dados antes da determinação das estruturas das tablespaces
para o banco de dados. Para isso, devemos considerar a configuração da estrutura de diretórios do sistema
operacional, a minimização da fragmentação e da contenção em disco, a separação de segmentos distintos e
o armazenamento dos arquivos do banco de dados.
As tablespaces READ-ONLY.
O Oracle7 permite-nos uma facilidade que, se bem aproveitada, pode facilitar bastante o gerenciamento de
nossos bancos de dados. São as tablespaces READ-ONLY. Essas tablespaces não permitem quaisquer
operações de gravação nos seus datafiles. Temos diversas vantagens que podemos conseguir com o seu
uso: os seus arquivos não precisam de backups freqüentes, já que não são modificados; eles também não
precisam de RECOVERY; e, finalmente, elas podem residir em dispositivos READ-ONLY, como um CD-ROM
ou um write-once-read-many (WORM). Assim, tabelas estáticas muito grandes com informações históricas
que devem permanecer disponíveis podem tirar proveito dessas facilidades.
As tablespaces READ-ONLY somente podem voltar a ficar disponíveis para gravação para o banco de dados
no qual foram criadas. Antes de tornarmos uma tablespace READ-ONLY, devemos seguir as seguintes
considerações:
A tablespace deve estar ONLINE.
Não pode haver nenhuma transação ativa na mesma (isso é necessário para que tenhamos garantia de
que nenhuma informação de rollback seja necessário ser aplicada à mesma).
Cópia Controlada Page 121 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
A tablespace não pode conter qualquer segmento de rollback ativo. Recomendamos que eles sejam
removidos da tablespace antes dela tornar-se READ-ONLY.
A tablespace não pode estar envolvida em um procedimento de backup ONLINE, por que o END
BACKUP atuali za os
headers dos seus arquivos.
O parâmetro COMPATIBLE deve ser configurado para a versão 7.1.0 ou superior.
Precisamos possuir o privilégio de ALTER TABLESPACE.
A tablespace SYSTEM nunca pode ser tornada READ-ONLY pois ela contém o segmento de rollback
SYSTEM e as tabelas e visões do dicionário de dados que sempre precisam estar disponíveis. As tablespaces
temporárias não são boas candidatas a tornarem-se READ-ONLY, já que são necessárias para a criação dos
segmentos temporários. Devemos considerar colocar o banco de dados no modo RESTRICT para que
somente os usuários com o privilégio RESTRICT SESSION consigam as conexões ao mesmo.
ALTER TABLESPACE tablespace
{ ADD DATAFILE { filespec
[AUTOEXTEND [ OFF
| ON [NEXT integer [K|M]]
[MAXSIZE {UNLIMITED | integer[K|M] ]
[, filespec ...] }
| RENAME DATAFILE 'filename' [,'filename'] ...
TO 'filename' [,'filename'] ...
| DEFAULT STORAGE storage_clause
| COALESCE
| ONLINE
| OFFLINE [NORMAL | TEMPORARY | IMMEDIATE]
| READ ONLY
| READ WRITE
| {BEGIN | END} BACKUP}
Onde:
READ ONLY Significa que a tablespace permanecerá no modo READ-ONLY, sem receber qualquer
gravação, somente consultas.
READ WRITE Significa que a tablespace permanecerá no modo READ-WRITE, podendo receber
operações de leitura e gravação. Esse é o modo default.
Podemos usar a cláusula RENAME DATAFILE para copiarmos os datafiles para os dispositivos READ-ONLY.
O privilégio de ALTER TABLESPACE é necessário para alterarmos o status das tablespaces. Devemos nos
lembrar de voltar ao modo READ-WRITE antes de retornamos a uma versão anterior do Oracle7. Devemos
copiar as tablespaces READ-ONLY dos dispositivos READ-ONLY para um READ-WRITE antes de voltar ao
seu status default. Todos os datafiles da tablespace devem permanecer ONLINE antes de alterarmos o seu
status.
Quanto ao backup, não necessitamos copiar as tablespace READ-ONLY pois ela não são atualizadas, ou
seja, seus datafiles não sofrem quaisquer operações. Para garantirmos a integridade de nossos dados, basta
que façamos um backup em seguida à ação de tornarmos as tablespace READ-ONLY. Podemos, inclusive,
executarmos um backup ONLINE em qualquer momento, sem ao menos usarmos o comando ALTER
TABLESPACE BEGIN/END BACKUP.
Não podemos nos esquecer de usar o comando ALTER DATABASE BACKUP CONTROLFILE TO TRACE em
todas as vezes que o banco de dados sofrer alguma alteração estrutural, o que pode ser necessário para
recriarmos os arquivos de controle (esse procedimento deve ser usado mesmo quando trabalhamos com as
tablespace READ-ONLY). Consideremos também que se não pudermos restaurar os datafiles de uma
tablespace READ-ONLY para a localização correta, devemos usar o comando ALTER DATABASE RENAME
para alterarmos os ponteiros do arquivo de controle para a nova localização. Os procedimentos para
Cópia Controlada Page 122 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
recuperarmos uma tablespace usando um backup do arquivo de controle é basicamente o mesmo para as
tablespaces normais, exceto que precisamos tornar a tablespace ONLINE depois que o banco de dados é
aberto.
Minimizando a fragmentação.
É importante a aplicação da técnica da separação dos grupos de objetos com diferentes características de
fragmentação entre as tablespaces.
Consideremos a tabela seguinte das características de fragmentação:
Tipo de segmento Características de fragmentação
Dicionário de dados Não causam fragmentação ou possuem tendência à fragmentação zero.
Temporários Causam os mais sérios problemas de fragmentação.
Rollback Podem causar graves problemas de fragmentação, mas geralmente possuem
moderada propensão.
Miscelâneas Geralmente possuem moderada tendência à fragmentação.
Dados e índices Possuem baixa propensão à fragmentação.
As características de cada um dos tipos de segmentos acima, mostra que um cuidado especial deve ser
tomado com a separação dos segmentos com alta tendência à fragmentação daqueles de moderada e baixa
propensão.
Dessa forma é possível minimizarmos a fragmentação do banco de dados, melhorando assim a performance.
A fragmentação ocorre quando o banco de dados não possui o seu espaço usado continuamente. Essa
fragmentação pode ser no disco ou nas tablespaces.
A fragmentação em disco degrada a performance do banco de dados e pode ser causada pela
fragmentação das linhas entre os blocos de dados e pelo aumento e encolhimento excessivo do número
das extensões que formam os diversos segmentos.
Cópia Controlada Page 123 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Minimizando a contenção em disco.
A contenção em disco pode ser minimizada através da separação dos grupos de segmentos mais acessados
em tablespaces diferentes. Devemos considerar a possibilidade da separação dos segmentos do dicionário de
dados de todos os outros segmentos, assim como os segmentos de rollback e os segmentos de dados de
seus segmentos de índices correspondentes. Um cuidado extra deve ser tomado com os arquivos de redo log,
já que geralmente são eles que causam os mais sérios problemas de contenção em disco.
A separação dos segmentos também precisa seguir alguns critérios que, aplicados, podem melhorar os
procedimentos de cópia e recuperação do banco de dados, assim como permite-nos uma maior clareza na
organização e uma garantia extra de segurança para os dados. Esses critérios podem ser resumidos em:
Separar segmentos com diferentes necessidades de backup. Essa técnica permite uma melhor clareza,
segurança e funcionalidade para os procedimentos de cópia do banco de dados, bem como facilita uma
possível recuperação.
Separar segmentos de acordo com a disponibilidade dos dados para os usuários. Com a aplicação
dessa técnica é possível proibirmos o acesso a determinadas aplicações, somente tornando OFFLINE a
tablespace que contém os objetos acessados por elas.
Separar segmentos considerando o tempo de vida das aplicações que os utilizam. Caso exista alguma
aplicação a ser desativada dentro de pouco tempo, o armazenamento dos segmentos acessados por
ela em uma tablespace deve ser considerado. Quando da necessidade de tirá-la de produção, basta
removermos a tablespace.
Os arquivos de controle e redo log devem ser mantidos em cópias ONLINE em discos diferentes
(técnica conhecida como espelhamento). Os arquivos de controle não podem nunca ser perdidos e o
uso de pelo menos dois deles em diferentes dispositivos físicos é altamente recomendado.
Aos arquivos de redo log também devemos prestar especial atenção, visto que eles causam um dos
mais sérios problemas de contenção nos discos; por isso devem ser mantidos espelhados em
diferentes dispositivos físicos, para melhorar não somente a contenção como também para garantir uma
maior segurança no caso de erro irrecuperável.
É imprescindível a monitoração do banco de dados em busca de possíveis problemas de contenção em
disco.
Finalmente, a separação dos arquivos que compõem as tablespaces em diferentes discos, assim como
o transporte de segmentos muito acessados para outras tablespaces armazenadas em dispositivos
diversos, devem ser considerados.
Cópia Controlada Page 124 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Preparando o ambiente do sistema operacional.
Precisamos decidir o nome para a instância e para o banco de dados, que deve ser único, e configurar o
ambiente do sistema operacional.
Nos sistemas UNIX, geralmente esse nome é incorporado ao nome do arquivo de parâmetros, o que
facilita o gerenciamento, pois o Oracle7 tenta localizá-lo no diretório $ORACLE_HOME/DBS.
Por exemplo, se uma instância possui o nome TEST, o seu arquivo de parâmetros pode ter o nome
initTEST.ora.
Caso uma outra instância tenha o nome Prod8, o nome do seu arquivo de parâmetros provavelmente
deve ser identificado por initProd8.ora.
Consideremos que as letras maiúsculas e minúsculas fazem diferença nos sistemas UNIX.
Assim, para uma verificação de quais os nomes que não podem ser usados para a instância de um novo
banco de dados, podemos listar o conteúdo do diretório $ORACLE_HOME/DBS com o seguinte comando:
$ ls $ORACLE_HOME/dbs/init*.ora
/usr/oracle/dbs/initTEST.ora /usr/oracle/dbs/initProd8.ora
Uma outra forma de verificação dos nomes das instâncias é com o uso do comando PS do UNIX, conforme o
exemplo abaixo, que nos mostra os processos em memória:
$ ps -ef | grep ora
oracle 186 1 0 07:20:14 console 0:00 -sh
oracle 413 186 3 08:37:06 console 0:00 grep ora
oracle 414 413 9 08:37:06 console 0:00 ps -ef
oracle 400 1 0 08:36:18 ? 0:00 ora_pmon_TEST
oracle 402 1 0 08:36:22 ? 0:00 ora_smon_TEST
oracle 401 1 0 08:36:20 ? 0:00 ora_dbwr_TEST
oracle 404 1 0 08:36:26 ? 0:00 ora_lgwr_TEST
oracle 405 1 0 07:40:12 ? 0:00 ora_pmon_Prod7
oracle 406 1 0 07:40:13 ? 0:00 ora_smon_Prod7
oracle 408 1 0 07:40:15 ? 0:00 ora_dbwr_Prod7
oracle 409 1 0 07:40:16 ? 0:00 ora_lgwr_Prod7
É o identificador do sistema, ou ORACLE_SID, uma variável de ambiente do UNIX, que determina qual é o
nome da instância a que podemos nos conectar.
É através desse nome, no caso de estarmos emulando o UNIX, que o Oracle7 consegue localizar o
arquivo de parâmetros no diretório $ORACLE_HOME/DBS, pois conforme vimos, o nome da instância é
incorporado ao nome desse arquivo.
Nos sistemas UNIX, podemos configurar o nome da instância através dessa variável.
Com a inserção, no arquivo .PROFILE dos usuários no sistema operacional UNIX, das linhas abaixo,
podemos configurar o nome de uma instância como TEST.
ORACLE_SID=TEST
export TEST
Para configurar o nome da instância como Prod8, devemos inserir as linhas abaixo no mesmo arquivo
.PROFILE dos usuários ou através da linha de comando do SHELL do sistema operacional:
$ ORACLE_SID=Prod8
$ export ORACLE_SID
Cópia Controlada Page 125 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Essa variável de ambiente nos sistemas UNIX determina a instância a que os usuários podem se conectar. O
nome pode ser formado de um a oito caracteres.
Configuração da SGA.
A configuração da SGA passa necessariamente pela configuração do kernel do UNIX, que possui o parâmetro
SHMMAX para determinar o tamanho máximo de uma região ou segmento de memória alocada. Dentre os
diversos parâmetro de inicialização, quatro deles são de extrema importância para a configuração da SGA:
DB_BLOCK_BUFFERS, DB_BLOCK_SIZE, SORT_AREA_SIZE e SHARED_POOL_AREA. Devemos
configurá-los da melhor maneira possível para determinarmos o tamanho ideal para a SGA, para que ela se
comporte nos limites aceitáveis da memória disponível no UNIX. Podemos calcular o tamanho da SGA como:
SGALen = (DB_BLOCK_BUFFERS * DB_BLOCK_SIZE)
+ SORT_AREA_SIZE
+ SHARED_POOL_SIZE
+ 1M
Onde:
SGALen Tamanho da SGA.
Para determinarmos o tamanho exato da SGA de uma instância, podemos usar o comando SHOW SGA,
através da ferramenta SQL*DBA ou do Server Manager:
SVRMGR> SHOW sga
Total System Global Area 21849580 bytes
Fixed Size 47932 bytes
Variable Size 19720880 bytes
Database Buffers 2048000 bytes
Redo Buffers 32768 bytes
O roteiro abaixo pode ser usado para obtermos uma perfeita visão dos componentes da SGA:
REM ********************
REM COMPOSGA.SQL
REM Componentes da SGA
REM ********************
TTITLE LEFT "Monitorando os componentes da SGA SKIP 1
BTITLE OFF
SET ECHO OFF
SET FEEDBACK OFF
SET LINESIZE 80
SET NULL "Null"
SET PAGESIZE 10000
SET SHOWMODE OFF
SET TAB OFF
SET TERMOUT OFF
SET TRIMOUT ON
SET VERIFY OFF
SET WRAP ON
COLUMN value FORMAT 999,999,999,999
COLUMN bytes FORMAT 999,999,999,999
SELECT *
FROM v$sga
ORDER BY value DESC
/
Cópia Controlada Page 126 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
TTITLE OFF
SELECT *
FROM v$sgastat
ORDER BY bytes DESC
/
REM ********************
SQL> @COMPOSGA.SQL
NAME VALUE
-------------------- ----------------
Variable Size 19,680,136
Database Buffers 2,048,000
Redo Buffers 163,840
Fixed Size 47,932
NAME BYTES
-------------------------- ----------------
sql area 8,558,456
library cache 4,733,536
db_block_buffers 2,048,000
dictionary cache 1,837,096
PL/SQL MPCODE 1,308,472
free memory 850,400
PL/SQL DIANA 632,080
sessions 319,504
event statistics 264,600
VIRTUAL CIRCUITS 227,448
db_block_hash_buckets 222,008
log_buffer 163,840
gc_* 149,392
enqueue_locks 118,848
processes 100,800
transactions 68,176
miscellaneous 56,848
fixed_sga 47,932
db_block_multiple_hashcha 37,152
messages 25,600
db_files 24,608
trigger defini 24,464
DML locks 20,000
character set memory 18,408
SEQ S.O. 18,000
db_multiblock_read 16,120
enqueue_resources 14,400
character set object 8,192
ENQUEUE STATS 6,944
transaction_branches 5,760
table definiti 5,696
UNDO INFO 4,728
PLS non-lib hp 2,104
fixed allocation callback 200
kzull 96
O comando IPCS do sistema operacional (existente no HP-UX) nos mostra a sua própria memória
compartilhada. A SGA é mostrada dentro dela (no exemplo abaixo, ela está assinalada em negrito). Perceba
que a SGA, que possui 21849580, cabe inteiramente na memória do sistema operacional:
$ ipcs -b
Cópia Controlada Page 127 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
IPC status from /dev/kmem as of Mon Sep 23 13:50:10 1996
T ID KEY MODE OWNER GROUP QBYTES
Message Queues:
q 0 0x3c04188c -Rrw--w--w- root root 32768
q 1 0x3e04188c --rw-r--r-- root root 264
q 2 0x04917dff --rw-rw-rw- root root 2400
q 3 0x0045dcf8 --rw-rw-rw- root root 5520
q 4 0x0d5dcf71 --rw-rw-rw- root root 5520
T ID KEY MODE OWNER GROUP SEGSZ
Shared Memory:
m 0 0x41041844 --rw-rw-rw- root root 512
m 1 0x41041896 --rw-rw-rw- root root 14620
m 2 0x4104280b --rw-rw-rw- root root 8192
m 3 0xff040009 --rw-rw-rw- root root 84
m 4 0xfe040009 --rw-rw-rw- root root 24652
m 5 0xfd040009 --rw-rw-rw- root root 2608
m 6 0xfc040009 --rw-rw-rw- root root 20812
m 7 0x4013ba9b --rw-rw---- oracle dba 21850120
T ID KEY MODE OWNER GROUP NSEMS
Semaphores:
s 0 0x41041896 --ra-ra-ra- root root 2
s 1 0x4104280d --ra-ra-ra- root root 2
s 2 0x00446f6d --ra-r--r-- root root 1
s 3 0x01090522 --ra-r--r-- root root 1
s 4 0xff040009 --ra-ra-ra- root root 1
s 5 0x00000000 --ra-ra---- oracle dba 200
Podemos usar, adicionalmente, o comando TSTSHM, do UNIX, para obtermos mais informações sobre a
memória:
$ tstshm
Number of segments gotten by shmget() = 50
Number of segments attached by shmat() = 12
Segments attach at higher addresses
Shared memory non-attachable at specific addresses!
Default shared memory address = 0xc14ef000
Lowest shared memory address = 0xc14ef000
Highest shared memory address = 0xffffffff
Total shared memory range = 1053888511
Total shared memory attached = 25165824
Largest single segment size = 2097152
Segment boundaries (SHMLBA) = 4096 (0x1000)
Devemos nos preocupar também com a configuração do seguintes parâmetros do kernel do UNIX:
SHMMAX Estabelece o tamanho máximo, em bytes, de um segmento de memória compartilhada.
Recomendamos o valor 0x4000000 (64 MB).
SEMMNI Estabelece o número máximo de segmentos de memória no sistema. Recomendamos o valor
100.
SHMSEG Estabelece o número máximo de segmentos que um processo pode usar. Recomendamos o
valor 12.
SEMMNS Estabelece o número de semáforos no sistema. Recomendamos o valor 128. Cada processo
requer no mínimo um semáforo.
SEMMNI Estabelece a quantidade máxima de memória que pode ser alocada. Recomendamos o valor 10.
Se o tamanho da SGA exceder o tamanho máximo de um segmento de memória (SHMMAX), o Oracle7
Cópia Controlada Page 128 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
experimenta usar mais segmentos.
O parâmetro SHMSEG estabelece o número máximo de segmentos que podem ser usados por um
processo.
A SGA deve estar contida inteiramente na memória principal.
O valor default para o parâmetro SHMMAX para o HP 9000 serie 800 é de 64 MB. O tamanho da SGA
deve ser delimitado pela área de swap, no disco.
Conforme vimos, antes da instância ser criada, o Oracle7 lê o seu arquivo de parâmetros. Uma instância pode
ser inicializada (ou posteriormente alterada) em um modo restrito somente aos usuários que possuem o
privilégio RESTRICT SESSION. Nesses casos, quem não possui este privilégio não consegue conectar-se ao
banco de dados.
Em circunstâncias fora do comum, quando um banco de dados é finalizado, pode ocorrer de alguns processos
terem ficado pendentes.
Nessas situações o banco de dados pode retornar um erro durante uma tentativa de inicialização normal da
instância. Para resolvermos este problema, devemos eliminar todos os processos remanescentes da instância
anterior e inicializar uma nova instância.
Para sabermos o tempo decorrido desde a última vez que a instância foi acionada, podemos usar um dos
seguintes scripts:
REM ********************
REM LASTSTR1.SQL
REM ********************
SELECT TO_CHAR(TO_DATE(d.value,'J'),'MM/DD/YYYY')||' '||
TO_CHAR(TO_DATE(s.value,'SSSSS'),'HH24:MI:SS')
startup_time
FROM v$instance d,
v$instance s
WHERE d.key = 'STARTUP TIME - JULIAN'
AND s.key = 'STARTUP TIME - SECONDS';
REM ********************
SQL> LASTSTR1.SQL
STARTUP_TIME
-------------------
05/14/1998 11:13:47
REM ********************
REM LASTSTR2.SQL
REM ********************
COLUMN STTime FORMAT A30
SELECT name "Database",
TO_DATE(a.value,'J')
|| ':'|| FLOOR(b.value/3600)
|| ':'|| (FLOOR(b.value/60) - (FLOOR(b.value/3600) * 60))
|| ':'|| (b.value - (FLOOR(b.value/60) * 60)) STTime
FROM v$instance a, v$instance b, v$database c
WHERE b.key LIKE 'STARTUP TIME - S%'
AND a.key LIKE 'STARTUP TIME - J%';
REM ********************
Cópia Controlada Page 129 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
SQL> @LASTSTR2.SQL
Database STTIME
--------- -------------------
ORCL 14-MAY-98:11:13:47
BRTOOLS Backup Tasks
O gerenciamento do Banco de Dados Oracle será acompanhado pela transações DB02, onde diariamente
estaremos acompanhando o crescimento das tabelas, indexes e tablespace. Para através da ferramenta
DBACOCKPIT prestar-mos a manutenção necessária nas tabelas; Alterando um paramêtro de maxextent,
reorganizando uma tabela ou um tablespace, etc.
Os Backup utilizam informações que estão contidas no arquivo INIT<SID>.SAP, localizado no diretório
Orant\Backup do servidor SAP. Trata-se de um arquivo TXT, que pode ser editado com qualquer editor de
texto. Caso seja editado salvar as alterações como somente texto, sem formatação.
Este arquivo é configurado somente no inicio da implantação das rotinas de backup, não sendo portanto
editado diariamente, somente em eventuais alterações.
O processo de backup do SAP envolve o backup do Database Oracle e também dos Off-Line Redo log Files,
que são alterações feitas no Database.
Isto significa que cada operação de Backup, terá de ser executada em 2 fases:
A ferramenta de backup e restore do SAP R/3 é o SAPDBA, por ela, é que devemos gerenciar o banco de
dados, independente de qual seja ele.
Se logar no UNIX com o usuário ora<SID> e execute o comando BRTOOLS.
Cópia Controlada Page 130 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Na tela SAP DATABASE ADMINISTRATION , selecione a letra H para fazer um backup da base de dados.
4. Selecione a opção A – Backup Function.
5. tecle enter.
Cópia Controlada Page 131 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
6. Digite B para inicializar a fita de backup.
7. Pressione Enter.
8. Enter q (Return).
9. Pressione Enter.
10. Note a descrição da linha que mostra Initialize BRBACKUP tape.
11. Se você só tem uma fita para inicializar, vá para o passo 16. Caso tenha mais de uma fita para inicializar
entre com a opção D e digite o numero de fitas.
12. Pressione Enter.
13. Enter o numero da fita para ser inicializada.
14. Pressione Enter
.
15. O numero de fitas deve aparecer na linha da opção D.
Cópia Controlada Page 132 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
16. Enter s (Start BRBACKUP).
17. Pressione Enter.
6
10
11
A tela acima mostra a fita que foi inicializada com sucesso, pressione Enter.
Podemos inicializar um fita pelo PROMPT do sistema operacional : brbackup –i force –n 1 –v <nome fita>.
-n indica o numero de fitas.
-v o nome da fita.
15
Cópia Controlada Page 133 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Digite a opção I
O Archive Tape pode ser feito por 2 caminhos :
_ Usando o SAPDBA
_ Usando o BRARCHIVE
1 -No prompt, enter SAPDBA, pressione Enter.
2- Na tela acima digite a opção I (Backup offline redo logs).
3- Pressione Enter.
4. Enter a (Archive function).
5. Pressione Enter.
1
Cópia Controlada Page 134 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
6. Enter k (Initialize BRARCHIVE tape).
7. Pressione Enter.
8. Enter q para retornar ao menu.
9. Pressione Enter.
9. Note a mensagem a direita -> Initialize BRARCHIVE tape.
O numero da fita inicializada pode ser trocada pelo mesmo caminho do BRBACKUP.
Enter d (Number of tapes)
Pressione Enter.
Enter o número da fita que será inicializada.
Pressione Enter.
10. Enter s para iniciar o BRARCHIVE e pressione Enter.
11. Quando termina o processo aparecerá a mensagem : BRARCHIVE executed successfully displays.
12. Remova a fita e atualize o seu controle de backup de acordo com suas normas internas.
Cópia Controlada Page 135 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para executar o backup Offline:
_ Parar o R/3
_ Ter as fitas de backup inicializadas.
1. No prompt, enter SAPDBA, pressione Enter.
2. Entre h (Backup database).
3. Pressione Enter.
2
4. Verifique que no campo Backup Function aparece -> Normal Backup.
Cópia Controlada Page 136 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
5. Reveja a linha e (Backup type) para determinar que tipo de backup está configurado (Online ou Offline).
6. O tipo de Backup pode ser alterado, selecione opção e (Backup type), e selecione :
_ a (online backup)
_ b (offline backup)
7. Tecle Enter.
8. Escolha uma opção (por ex. a).
9. Pressione Enter.
10. Digite q (Return) para voltar a tela anterior.
11. Pressione Enter.
12. Enter S (Start BRBACKUP).
13. Pressione Enter.
6
8
Cópia Controlada Page 137 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
14. No prompts você recebe a mensagem para troca da fita quando for necessário.
15. Digite cont, para continuar o processo.
16. Pressione Enter.
17. Quando o Backup termina , aparece a mensagem : BRBACKUP terminated successfully
18. Remova a fita e armazene-a num lugar seguro.
Para o Backup dos Achives Logs, devemos ter as fitas inicializadas.
Usamos o SAPDBA para executar este backup, e também podemos executar o BRARCHIVE atrvés de um
job chron.
1. No prompt, enter SAPDBA, pressione Enter.
Cópia Controlada Page 138 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
2. Digite i (Backup offline redo logs).
3. Pressione Enter.
4. Entre com a opção a (Archive function).
5. Pressione Enter.
24
6. Digite a letra do tipo de Archive que será executado. (Recomendamos marcar 2 cópias do Oracle
Archive Logs).
7. Pressione Enter.
8. Digite s (Start BRARCHIVE).
9. Pressione Enter.
10. Quando o archive logs termina ele mostra a seguinte mensagem :
BRARCHIVE executed successfully appears.
11. Pressione Enter.
Cópia Controlada Page 139 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
6
Nunca deixe de fazer o backup deles, pois se faltar espaçõ no disco físico onde se encontram os archives o
R/3 trava.
Para destravar execute o comando BRARCHIVE –sd no prompt do sistema operacional.
Recomendamos as seguintes notas : 68059, 43499, 43491, 43489.
Outras Funções do SAPDBA
Opção A da tela do SAP Database Administration , é utilizada para conectar e desconectar o banco de dados.
Opção B da tela do SAP Database Administration, é utilizada para mostrar informações da Instance do R/3
que estamos conectados.
Cópia Controlada Page 140 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Opção C do SAP Database Administration , é utilizada para mostrar informações sobre as table-spaces, isto é
como estão os espaços alocados por cada tabela, as table-space com mais de 80% de utilização devem ter
seus EXTENT extendidos.
Na opção C, você terá os percentuais de cada table-space.
Na opção F você altera o tamanho da table-space escolhida (verifique a que tiver mais de 80% ). Este item
mostra valores sugeridos pelo próprio sistema, recomendamos aceitar este valor.
Este processo pode ser feito com o banco operando (Online).
Cópia Controlada Page 141 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Opção D do SAP Database Administration , é utilizada para reorganizar uma tabela ou uma table-space, isto é
feito quando não se tem mais espaço para alocar extents nas mesmas.
Opção E do SAP Database Administration, é utilizada para se fazer um EXPORT/IMPORT da base do Oracle
interia, muito utilizado para se fazer uma cópia do banco para uma outra instalação.
Cópia Controlada Page 142 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Opção F do SAP Database Administration , é utilizada para se abilitar o archive, isto é com o archive setado
ON, o banco criará arquivos de 20 MB cada, onde conterá cópias das informações contidas no banco de
dados. Com o archive setado OFF, isto não ocorrera. A opção a seta o archive para ON ou OFF.
Opção G do SAP Database Administration , é utilizada para lhe dar informações adicionais sobre o próprio
SAPDBA, serve para executar comando SQL, e mostar informações estatísticas do sistema.
Cópia Controlada Page 143 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Opção J do SAP Database Administration , é utilizada para restaurar a base de dados ou uma tabela
especifica ou uma table-space. E também para recuperar a base numa eventual perda das informações.
Opção K do SAP Database Administration , é utilizada para verificar a base de dados.
Cópia Controlada Page 144 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Opção L do SAP Database Administration, é utilizada para mostrar os logs de backup, de archives, etc.
Cópia Controlada Page 145 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Opção M do SAP Database Administration , é utilizada para mostrar informações do usuário do R/3 e sobre
segurança.
Opção N do SAP Database Administration, é utilizada para se conectar com a SAP.
1- INTRODUCTION SOFTWARE LOGISTICS
Cópia Controlada Page 146 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Uma instancia (instance) é um grupo de serviços do R/3 que são iniciados e finalizados em conjunto.
Normalmente, o termo é associado a um dispatcher e seus wp´s correspondentes, mas também pode ser
considerado uma instancia um servidor executando somente o serviço de gateway do SAP.
Central instance (instância central) é a combinação de um dispatcher com todos os processos do R/3, ou
seja, a combinação DVEBMGS. Como exemplo disso, temos a instância C na figura acima, que mostra todos
os processos do R/3 sendo executados, com a exceção do G (gateway), mas que também deve estar
presente em uma central instance.
Um servidor R/3 de aplicação consiste principalmente de um dispatcher, seus wp´s associados e seu banco
de memória.
Em um ambiente R/3, os conceitos “cliente” e “servidor” são geralmente abordados como software, desse
modo vários servidores de aplicação podem ser executados em um só computador.
Do ponto de vista de hardware, entretanto, um servidor de aplicação pode ser definido como um computador
com pelo menos um dispatcher, configuração que também é chamada de instância de dialog.
As seguintes restrições se aplicam ao número permitido para cada tipo de work process:
- Dialog: cada dispatcher precisa de, pelo menos, dois wp´s de dialog
- Spool: pelo menos um por sistema R/3, e os dispatchers podem ter mais de um spool
- Update: pelo menos um por sistema R/3, e os dispatchers podem ter mais de um update
- Background : pelo dois um por sistema R/3, e os dispatchers podem ter mais backgrounds
- Enqueue : somente um wp de enqueue pode existir em um sistema R/3
Mandantes R/3 (ou clients R/3) são organizados independentemente. Cada um tem suo próprio ambiente de
dados, com seus dados mestres e dados transacionais, dados de usuário e também seus próprios parâmetros
de customização.
Cópia Controlada Page 147 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Usuários em diferentes mandantes coexistem em um mesmo sistema R/3, mas seus dados são isolados e não
podem ser acessados de outro mandante. Somente usuários com as autorizações necessárias podem
visualizar ou processar dados em um mandante específico. Esse conceito de isolamento se reflete na
estruturas das tabelas, tanto a nível de aplicação quanto de customização, que é um nível de adaptação
dependente de cada implementação.
O mandante 000 é definido como o padrão SAP e não pode ser modificado. Ele serve como um modelo para a
criação de outros mandantes.
O número máximo de mandantes em um sistema R/3 é de 997, número dificilmente atingido.
O conceito de Mandantes do SAP é integrar várias companhias.
Cópia Controlada Page 148 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cópia Controlada Page 149 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Temos que assegurar que o mandante em Produção não poderá ser alterado, isto é somente por transporte
de request.
Os 3 sistemas Landscape são recomendados porque devemos utilizar o Development para criar, montar as
novas customizações , transporta-las para o Quality Assurance para valida-las e transporta-las para o
Production.
Os Transportes são requeridos para mover as mudanças entre os mandantes através do Landscape.
Mais de 800 processos de negócios estão associados as funcionalidades do R/3.
Cópia Controlada Page 150 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
No R/3 existem ferramentas para criar, documentar e distribuir as mudanças entre o sistema Landscape.
O Change Transport Organizer (CTO) , organiza e suporta o desenvolvimento do projeto, sendo ele de
qualquer tamanho, centralizado ou descentralizado.
O Transport Management System (TMS) , organiza, monitora, e executa todos os transportes do R/3.
As ferramentas de transporte (TP e R3TRANS) são executadas no sistema operacional que comunicam o R/3
ao banco de dados e gera arquivos de controle durante o processo de Export.
Cópia Controlada Page 151 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Administrando o Banco de Dados
Quando começamos a falar de banco de dados com R/3, nos preocupamos com Performance, segue uma
série de dicas de como devemos analisar as transações voltadas para Performance de Banco de Dados
independente de qual seja ele (SQL, Oracle, Informix, etc)
- Fazer a pergunta: é um problema generalizado (afeta todos os usuários), localizado (afeta somente a
execução de algumas transações) ou ainda um problema localizado que, quando ocorre, leva a um
problema generalizado de performance (uma transação que, ao ser executada, “derruba” o servidor de
banco de dados)?
Parte dos ajustes que podem ser realizados a fim de melhorar o desempenho de um sistema R/3 estão
relacionados a configurações dos componentes do R/3, como Sistema Operacional (tamanho de swap,
presença de processos externos), Banco de Dados (parâmetros que controlam o tamanho do data buffer,
shared pool), Instâncias R/3 (número e tipos de work processes, tamanho das regiões locais e
compartilhadas de memória como buffers e extended memory) e Rede.
Uma configuração não otimizada dos componentes acima leva a problemas generalizados de
performance.
Podem haver problemas de performance mais localizados, ocorrendo apenas em uma ou algumas
transações, causados por fatores mais específicos. Detectadas estas transações, devemos submetê-las a
uma análise mais detalhada, analisando os trechos que realizam processamentos muito longos, ligados à
execução de programas ABAP ou ao acesso à tabelas no banco de dados. Após detectar o gargalo dentro
da transação, devemos levantar as possíveis ações para amenizá-lo ou até mesmo eliminá-lo.
Transações com gargalos durante suas execuções caracterizam problemas localizados de performance
que podem, eventualmente, levar a problemas generalizados de performance.
Composição do tempo de resposta
Cópia Controlada Page 152 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Wait Time é o Tempo que o request do usuário aguarda na fila do dispatcher até ser “despachado” para um
work process.
Roll Time é oTempo para copiar a parte inicial do contexto do usuário(atributos de logon, autorizações, e
outras informações relevantes) para dentro do work process – da roll memory (shared) para a roll_first da
roll_area (local do WP).
Cópia Controlada Page 153 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Load Time é o Tempo de carga do “load” (objeto compilado) de programa ABAP, telas, menus para dentro do
buffer correspondente (na instância R/3).
Processing Time é o Tempo gasto na execução dos comandos ABAP do programa chamado.
Deve ser calculado da seguinte forma:
Processing Time = TR – Wait – Roll – Load – DB Request Time
DB Request Time é o Tempo aguardando a resposta do gerenciador de banco de dados a uma solicitação
passada através da Database Interface (componente do WP).
Enqueue Time é Tempo gasto para realizar “lock” – muito pequeno.
CPU Time Corresponde ao tempo de utilização de CPU pelos componentes do Tempo de Resposta que
envolvem CPU do Application Server (Roll, Load e Processing). Não é possível determinar quanto de CPU foi
gasto em cada um dos componentes. Desta forma, parte do CPU Time está em Roll, parte em Load e parte
em Processing. Espera-se que o CPU Time seja próximo do Processing Time; caso contrário, é provável que
haja problemas de gargalos de hardware.
Dispatch Time é o tempo gasto pelo request dentro do Work Process. A fórmula para o cálculo é:
Dispatch Time = TR –Wait Time.
O Dispatch Time ajuda muito na análise do tempo de resposta, por exemplo: uma transação tem um TR médio
de 4s, mas o Wait Time médio é 3.5s. Desta forma, o Dispatch Time é de 0.5s (rápido). O ajuste para esta
situação é completamente diferente em um outro caso, onde o TR médio de uma transação também é 4s, mas
o Wait Time é 0.2s. Neste caso, o Dispatch Time é 3.8s (alto). O que quer dizer que o dispatcher encontra um
work process disponível rapidamente, mas o tempo gasto dentro dele é muito alto. Para acessar as
estatísticas devemos usar a transação ST03. Em seguida escolhemos qual o período a ser analisado, o que
deve ser feito cuidadosamente. Selecionamos o botão "Performance database", em
seguida o aplication server a ser analisado, e finalmente o período de análise. A próxima tela apresenta as
estatísticas do sistema, com os valores dos componentes do tempo de resposta para cada um diferentes
tipos de processamento (Dialog, Update, Background, etc).
Dialog Step: Database Time
Network
Cópia Controlada Page 154 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Netw
Se o processo requer dados do database, esta requisição é enviada para o interface database, mas antes
pesquisa no shared memory buffers.
Dialog Step: Roll out time
Após terminar a transação o work process libera o contexto do usuário.
Cópia Controlada Page 155 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Valores Ótimos dos Componentes
Wait Time < 10% do TR
Roll Time (in/out) < 50ms
Load Time < 10% do TR
Processing Time < 40% do Dispatch Time (TR – Wait)
DB Request Time < 40% do Dispatch Time (TR – Wait)
CPU Time > (Processing Time/2) (maior que metade do Processing Time)
Baseado nesses valores ótimos dos componentes do tempo de resposta, devemos analisá-los para cada
tipo de processamento (para selecionar o tipo de processamento, devemos usar os botões na parte inferior
da janela.
Analisados cada um deles, podemos determinar os sintomas dos problemas que eles identificam:
Wait Time Tempo de espera para obter work processes
Roll Time (in/out) Problemas com CPU ou memória do Sistema SAP R/3
Load Time Problemas nos buffers do Sistema SAP Sistema SAP R/3 (muito pequenos)
Processing Time Problemas no programa ABAP ou no banco de dados.
DB Request Time Problemas no banco de dados (SQL, índices, estatísticas, etc).
CPU Time Problemas de programas ABAP, grandes tabelas, CPU, rede, S.O.
Principais Transações para Análise de Performance
ST03 Analisa o TR médio de um período. É possível realizar consultas “quebradas” por horário, memória, e
principalmente por Transação (Transaction Profile).
SM50/SM66 Visão geral de work processes
ST06 Monitor de Hardware e Sistema Operacional.
ST02 Monitor de memória e buffers
ST04 Monitor do banco de dados
ST05 SQL Trace
SE30 Runtime Analysis (ABAP Trace)
ST10 Estatísticas de chamadas a tabelas
Buffer de Programas e impactos na Performance.
Para que um programa chamado por um usuário seja executado, o seu “load” (objeto compilado) deve estar
presente no buffer de programa da instância R/3 onde o usuário está conectado. Quando um programa é
chamado pela primeira vez (ainda não está no buffer), o work process tenta localizar o “load” no banco de
dados, nas tabelas D010*. Se não existir um load, o R/3 compila o programa fonte (parte do Load Time) e
gera esse load. Em seguida,o WP lê esse load do banco de dados para dentro do buffer de programa (parte
Cópia Controlada Page 156 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
do DB Req. Time). A partir daí, este work process passa a executar o programa. Em execuções
subseqüentes deste programa, os WP localizarão o programa em buffer (Load Time) e não haverá a
necessidade de carregá-lo novamente a partir do banco de dados.
Se o buffer de programa foi definido com um tamanho ideal, todos os programas chamados pelos usuários
serão carregados dentro dele e ainda sobrará espaço livre. Com o tempo, os mesmos programas vão sendo
chamados, e a taxa de eficiência do buffer (hitratio) vai subindo, já que os programas são localizados em
buffer, não havendo a necessidade de carregá-los a partir do banco. Contudo, se o buffer de programa for
pequeno para a quantidade de programas chamados, haverá um momento em que ele estará 100%
utilizado, só que mais programas ainda precisam ser carregados em buffer. A partir deste momento,
começam o ocorrer SWAPS. O indicador “swaps” indica o número de objetos (no caso, programas) que
foram retirados do buffer para que outros objetos pudessem ser carregados. Quando ocorrem swaps,
podem aparecer os GAPS, que são resultado da fragmentação do buffer (desaloca um programa de 5MB e
carrega outro de 4.5MB – gap de 0.5MB).
Um buffer de programas fragmentado pode levar a um problema generalizado de performance. Se estão
ocorrendo swaps, programas estão sendo retirados do buffer. Estes programas, se forem chamados mais
tarde por usuários, deverão obrigatoriamente ser carregados a partir do banco de dados, e sua carga
acarretará no swap de um ou mais programas do buffer, perpetuando o problema. Se um programa que já
havia sido carregado em buffer sofreu um swap e precisa ser recarregado (reload), o WP fica ocupado por
mais tempo, pois precisa carregar o “load” a partir do banco de dados (tabelas D010*) para dentro do Buffer
de programa.
- Ficando o WP ocupado por mais tempo (maior DB Request Time), diminui a disponibilidade de work
processes.
- Diminuindo a disponibilidade de work processes, aumenta a concorrência por eles.
- Aumentando a concorrência por work processes, aumenta o Wait Time.
- Aumentando o Wait Time, aumenta o Tempo de Resposta.
O que observar:
SM50/SM66 Action: Load Report
Action: Direct Read / Table: D010*
ST02 Program Buffer:
HitRatio < 90%
Swaps > 0
Gaps = Free Space
ST03 TR médio das transações alto
Wait Time alto
Load Time alto
DB Request Time alto
Gerenciamento de Memória
Cada instância de R/3 aloca diferentes regiões de memória para diferentes propósitos. Algumas são
consideradas LOCAIS, pois são acessíveis somente por um WP (roll area, paging area e heap area). Outras
são consideradas COMPARTILHADAS, pois são acessíveis por todos os WPs (roll buffer, paging buffer,
extended memory e buffer).
As principais considerações na definição destas áreas são:
- Garantir que a memória virtual total alocada pelo R/3 não exceda 50% acima da memória física do
servidor
- Evitar que um usuário, ao executar transações que consomem muita memória, entre em modo “PRIV”,
pois o WP que estiver utilizando assume status “stopped” e fica exclusivo para este usuário, até que ele
conclua a transação. Desta forma, diminui o número de WPs disponíveis, aumentando a concorrência,
aumentando Wait Time, aumentando Tempo de Resposta.
Cópia Controlada Page 157 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
O que observar:
SM50/SM66 Status: “stopped” / Reason: “PRIV”
Err > 0
ST02 SAP Memory:
Extended Memory: Current Use > 80%
Heap Memory
Mode List – memória alocada por sessão de usuários
Gargalos de Hardware
O tempo de processamento depende diretamente da capacidade e disponibilidade dos processadores do
servidor. Quanto maior utilização ou concorrência, maior o tempo de processamento. Há ainda outros
fatores que podem influenciar o tempo de processamento, como I/O e rede.
O consultor deve analisar estes fatores em cada servidor que tem uma instância de R/3. Devem ser
observados indicadores sobre utilização de CPU, processos que mais consomem CPU, load average e
taxas de paginação do sistema operacional. Nunca deve haver um gargalo de hardware no servidor de
banco de dados, o que causaria um problema generalizado de performance que afetaria todos os usuários.
Os processos que mais consomem CPU devem ser processos ligados ao R/3 – work processes, saposcol,
processos do banco de dados. Caso algum processo externo seja o responsável por um consumo
considerável de CPU, o mesmo deve ser reavaliado e até mesmo cancelado.
Quando há gargalos de hardware, os componentes do TR que utilizam CPU apresentam valores altos,
embora o valor total de CPU seja baixo em relação a eles. Isso indica alguns “buracos” ocorridos durante
estes componentes. Ex: Processing Time de 1s e CPU total de 300ms. O ideal seria que todo o Processing
Time fosse preenchido com CPU Time.
O que observar:
ST06 CPU Idle < 20%
Load Average > 3
Pages Out
Top CPU Processes (processos ligados ao R/3 ou processos externos?)
ST03 CPU Time < (Processing Time/2)
Processing Time alto
às vezes, Roll Time e Load Time altos (porque dependem de CPU)
Checklists Diário
Veremos as principais transações diárias que devemos analisar : O CCMS (Computing Center Management
System) é uma parte do sistema de administração basis do R/3 que fornece ferramentas para administração
de:
- performance do sistema R/3
- banco de dados e backups
- carga de trabalho do sistema
- velocidade de resposta
- segurança dos dados
Backup Log – DB12
– Verifica os logs dos backups diários.
Cópia Controlada Page 158 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Verifica todos os Servidores de Aplicação – SM51
SM51 – Permite visualizar todos os servidores de seu landscape (Database server e Application server).
Cópia Controlada Page 159 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Dando um duplo clique na linha, você verifica o que está processando no servidor.
Cópia Controlada Page 160 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
visualisa detalhes do processo (arquivo de trace do WP). Podemos também visualizarmos pelo sistema
operacional em /sapmnt/<SID>/<instance>/work
CCMS - Computing Center Management System – RZ20
Cópia Controlada Page 161 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
A transação RZ20 é centralizada no alert monitor. Você pode gerenciar seu sistema através deste monitor
central.
O alerta do Oracle só foram adicionados no rel. 4.5.
De um duplo clique no Operating System e verifique os alertas.
Cópia Controlada Page 162 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
De um duplo clique na linha escolhida e verifique os detalhes.
o ícone mostra os valores setados para o alerta.
Cópia Controlada Page 163 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
No campo Change from YELLOW to Red 200 PG/S – mostra que ao atingir uma paginação de 200 páginas
por segundo o MTE CLASS de page_out fica vermelho.
O ícone na tela inicial, inicializa a analisa da ferramenta.
Cópia Controlada Page 164 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Failed Updates – SM13
•Esta transação mostra alterações canceladas. Isto nunca deve ocorrer em produção. Estas alterações devem
ser reporatadas e corrigidas pela equipe de desenvolvimento.
De um clique no botão para visualizar os Updates Fails
Dê um duplo clique numa linha que contem erros.
Cópia Controlada Page 165 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Dê um duplo clique na linha que contém o erro, e visualize o Abap dump.
Você pode chamar o programa pelo Editor ou visualizar o Dump pelo ABAP Short dump.
Cópia Controlada Page 166 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
System Log – SM21
•Todas as manhãs as mensagens de erro devem ser analizadas e corrigidas. Este procedimento deve ser
documentado no formulário de Gerenciamento de Tasks.
A empresa deverá seguir como padrão o acompanhamento das seguintes transações conforme
procedimentos ASAP. Abaixo segue documento para se fazer o acompanhamento:
System Name_____________
Date_____________
SM21 System Log
Data Mensagem de erro Ação OSS Note
1/1/91 User Lockout (I001748) Unlock user none
Cópia Controlada Page 167 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
No campo Problem Class , você tem classe K – erros para analise de basis e W – erros de warning.
Cópia Controlada Page 168 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Backgroud Jobs – SM37
•O administrador deve examinar todos os jobs cancelados. Esses jobs devem ser analizados e reparados se
necessário. Problemas e resoluções devem ser documentados. O administrador deve checar todos os logs,
incluindo listagem de output os logs de aplicações. Devem ser liberados todos os jobs schedulados pelos
usuários que não foram liberados.
Cópia Controlada Page 169 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
liberar um job.
cancelar um job.
deletar um job já agendado.
visualizar spool do job referenciado.
visualizar detalhes do job.
visualizar o passo atual do job.
visualizar todos os steps do job
•RSBTCDEL
•Este programa limpa os jobs em background. Este programa é usado para remover todos os registros de jobs
executados com sucesso nos ultimos X dias.
Frequencia Recomendada : diário.
Nome do Job : SAP_REORG_JOBS
Variante: sim
Client Depende: sim
•RSPO0041
•Este programa é responsável por remover objetos do spooling. A fila de impressão vai aumentando com
relatórios que falharam ou não, cabendo ao administrador o critério para deleção.
Frequencia Recomendada : diário.
Nome do Job : SAP_REORG_SPOOL
Variante : sim.
Client Depende: sim
Cópia Controlada Page 170 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
•RSM13002
•Este programa limpa os processos requisitados de Update. É necessário somente se a deleção automatica
dos processos requisitados de updadte estiver setado TURNED OFF. Frequencia Recomendada : diário.
Nome do Job : SAP_REORG_UPDATERECORDS
Variante: não
Client Depende: não
•RSBDCREO
•Este programa é responsável em limpar o log dos batch input.
Frequencia Recomendada : diário.
Nome do Job : SAP_REORG_BATCHINPUT
Variante : sim.
Client Depende: sim
•RSSNAPDL
•Este programa limpa os dumps gerados por programas abap/4. Processar na madrugada. Frequencia
Recomendada : diário.
Nome do Job : SAP_REORG_ABAPDUMPS
Variante: sim
Client Depende: não
•RSBPCOLL
•Este programa acumula informações de de estatística, ele calcula a média de tempo de processamentodo job
que termino com sucesso. Estes dados são armazenados numa tabela chamada BTCJSTAT, esta tabela
necessita periodicamente de reorganização.
Frequencia Recomendada : diário.
Nome do Job : SAP_COLLECTOR_FOR_JOBSTATISTIC
Variante : não.
Client Depende: não
•RSBPSTDE
•Este programa limpas informações de estatísticas. Este job deleta as informações que não foram alteradas
num determinado período.
Frequencia Recomendada : mensal.
Nome do Job : SAP_REORG_JOBSTATISTIC
Variante: sim
Client Depende: não
•RSCOLL00
•Este programa coleta dados de performance.
Frequencia Recomendada : toda hora.
Nome do Job : SAP_COLLECTOR_FOR_PERFMONITOR
Variante : não.
Client Depende: não
Cópia Controlada Page 171 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Locks – SM12
•De tempos em tempos, o usuário pode travar um objeto (lock an object) quando esse está trabalhando, e se
ocorrer um erro de perda de conexão ou erro do programa, esse objeto pode ficar travado (lock). Esta
transação verifica e corrige isto.
Cópia Controlada Page 172 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Active Users – SM04 and AL08
Estas transações mostram todos os usuários que estão logados no sistema.
Cópia Controlada Page 173 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Mostra os usuários por instance (AL08).
Cópia Controlada Page 174 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Check Spool – SP01
•Falha de impressão de Jobs pode ser restartado. Geralmente essas falhas ocorrem por problemas com o
client (ex. o PC esta processando e o SAPLPD está desabilitado). Por causa que o R/3 encaminha os jobs de
impressão para a fila destino, não são garantidos os jobs de impressão com status de sucesso para o controle
de saida. Para jobs de impressão critica, deve ser confirmado com o usuário final se a impressão está ok
antes de deletar o spool.
Cópia Controlada Page 175 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Marque a linha e clique no para visualizar o relatório.
Clique no para visualizar o status da impressora.
Cópia Controlada Page 176 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Batch Input Jobs, in error or to be processed – SM35
•Batch Input logs devem ser checados após cada processamento. O batch input processado marca o erro e se
for possível você pode repará-lo.
Cópia Controlada Page 177 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
ABAP Dump Analysis – ST22
Análise de dump.
De um duplo clique no erro escolhido e analise o ABAP Dump.
O botão visualiza as seções do abap dump.
Cópia Controlada Page 178 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Workload Analysis – ST03
•Quando o sistema R/3 estiver processando, o administrador deve analizar o numero de workload,
especialmente para prever problemas de performance. Em se tendo uma visão do quadro limpo do
acompanhamento do sistema, é mais fácil quando houver um problema de performance, achar rapidamente o
mesmo.
Cópia Controlada Page 179 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Clique no botão
Marcar Last minute load ....
Cópia Controlada Page 180 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Temos que analisar o Av. response time .
Clique no Transaction profile.
Cópia Controlada Page 181 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Posicione o cursor na coluna Response Time e clique no SORT.
Poucas transações standard superam 1 segundo no tempo de resposta:
Create Sales Order – VA01 – 1,500 ms
Change Sales Order – VA02 – 1,500 ms
Display Sales Order – VA03 – 1,000 ms
Create Billing Document – VF01 – 1,500 ms
Create Delivery - VL01 – 2,000 ms
Maintain Master data HR – PA30 – 1,000 ms
Cópia Controlada Page 182 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Buffers – ST02
•Os Buffers devem ser monitorados regularmente pela equipe de Basis, como, taxas de proporção, espaços
livres, e areas de swap. Este processo ajuda o administrador a se familiarizar com os valores para numa
próxima checagem ir analizando os numeros obtidos.
A- Hit Ratio, deve ser maior ou igual a 95%, quando o sistema inicia este valor é baixo, porem com o passar
do tempo ele aumenta. Ele indica a utilização dos buffers.
B- Swaps, o valor deve ser menor que 1,000. O swap ocorre quando dados necessários não estão no buffer.
Cópia Controlada Page 183 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Database Tasks
•AL02 Database Alert Monitor
•Todos os alertas devem ser reconhecidos, analizados, corrigidos e documentados.
Clique na linha para visualisar o detalhe.
Drill down na tablespace PSAPBTABD (Oracle), mostra o gráfico a seguir.
Cópia Controlada Page 184 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
A- Indica a data atual, B- o passado e C- o futuro.
Cópia Controlada Page 185 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
•ST04 Database Logs
•Monitora os logs de erros do database.
Clique no botão Detail Analysis Menu – Error Logs.
Verifique as mensagens de erros.
Cópia Controlada Page 186 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Operating System Tasks
OS06 – Verifica os logs do sistema operacional.
•Todos os alertas devem ser reconhecidos, analizados, corrigidos e documentados.
Clique na opção Detail analysis menu.
Selecione OS Log.
Cópia Controlada Page 187 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Esta tela acima é similar ao event log do NT.
A tela abaixo é similar ao UNIX log.
Cópia Controlada Page 188 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Scheduled Weekly Tasks
DB02 - Storage Management
•Monitora o database, tabelas e index.
Selecione DB Space History – clique no botão Files.
3- Mostra o espaço livre.
Cópia Controlada Page 189 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para Oracle Selecione Back e clique na opção Tablespace.
Esta tela mostra o espaço livre das tablespaces, para obter o histórico da tablespace, basta dar um duplo
clique.
A coluna A- mostra o espaço livre (Kbyte), a coluna B- mostra o total usado (Kbyte).
Cópia Controlada Page 190 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Checking for Tables nearing their Maximum Extents
•Este ponto é muito importante para uma análise de performance. No Oracle 8.x o valor do MaxExtents é
teoricamente ilimitado, mas na prática devemos manter um número não tão alto de extents.
Quando uma tabela tem muitos extents (acima 100), esta deve ser reorganizada, para se obter um acesso
mais rápido aos dados contidos nela.
Para verificarmos quais tabelas estão com mais de 100 extents, devemos proceder da seguinte maneira:
Execute a transação SA38 e execute o programa RSORATC5.
5- marque com o valor 100, e execute.
A coluna 7- mostra a quantidade de extents existentes, caso seja maior que 100, a reorganização do objeto ou
da tablespace é necessária.
Cópia Controlada Page 191 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Checking File System Space Usage
Entre na transação RZ20.
Selecione SAP CCMS Monitor Templates – Operating System – Filesystem .
De um duplo clique na linha escolhida ou clique no botão Complete Alerts.
Cópia Controlada Page 192 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
o ícone mostra os valores setados para o alerta.
No campo Change from YELLOW to Red – mostra que no filesystem só temos 500MB de espaço livre.
O ícone na tela inicial, inicializa a analisa da ferramenta.
Cópia Controlada Page 193 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Cópia Controlada Page 194 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Planing the system Clients
Mandantes R/3 (ou clients R/3) são organizados independentemente. Cada um tem seu próprio ambiente de
dados, com seus dados mestres e dados transacionais, dados de usuário e também seus próprios parâmetros
de customização.
Produção
Protótipo Quality
PRD
DES QAS
400
300
200 Master Client Production
Master Client
310
210 Quality Testing
Development
320
220 Batch Input
Sand Box
340
Integrated Testing
2XX
Descrições dos Clients:
Customizing/Development – Aqui se cria o protótipo do sistema, todas as customizações de aplicações são
desenvolvidas neste client.
Sandbox – É um client de teste geral, inicialmente criado do client 000, é utilizado pelos Key-users se
familiarizarem com o sistema, testarem aplicações e customizações.
Customizing/Development Testing – É usado para testarem as mudanças feitas no client de customizing e
development.
Quality Assurance Testing – É usado para testar as mudanças de configuração e customizações feitas no
client de customizing e development. E serve para testar o transporte dessas informações.
End-User Training – É o treinamento dos usuários finais.
Customizing/Development Master – É usado para checar todas as mudanças feitas antes de se transportá-
las para produção.
Cópia Controlada Page 195 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Instance Changes and Client-Independent Protection: Client
Client Transports for Client– Object Change Copier and Comparison
Dependent Objects Tool
DES 200 No change allowed No changes to Protection Level 0:
Instance repository and client- No restriction
N 00 ind. customizing
allowed
210 Automatic recording Changes to repository Protection Level 0:
of changes and client-ind. No restriction
customizing allowed
220 Automatic recording No changes to Protection Level 0:
of changes repository and client- No restriction
independent cust. obj.
230 No change allowed No changes to Protection Level 0:
repository and client- No restriction
ind. customizing
allowed
QAS 300 No changes allowed No changes to Protection Level 0:
InstanceN repository and client- No restriction
00 independent cust. obj.
310 No changes allowed No changes to Protection Level 0:
repository and client- No restriction
independent cust. obj.
320 No changes allowed No changes to Protection Level 0:
repository and client- No restriction
independent cust. obj.
340 No changes allowed No changes to Protection Level 1:
repository and client- No overwriting
independent cust. obj.
PRD 400 No changes allowed No changes to Protection Level 1:
Instance repository and client- No overwriting
N 00 independent cust. obj.
Cópia Controlada Page 196 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Na política de Refresh, podemos adotar.
Produção
Protótipo Quality
PRD
DES QAS
300
200 Master Client
Master Client
310
210 Quality Testing
Development
400
220 Production
Sand Box
320
Batch Input
340
2XX
Integrated Testing
O client de produção nunca sofrerá refresh, somente será atualizado por transporte.
Cópia Controlada Page 197 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Na política de Transporte, podemos adotar.
Produção
Protótipo Quality
PRD
DES QAS
300
200 Master Client
Master Client
310
210 Quality Testing
Development
400
220 Production
Sand Box
320
Batch Input
340
2XX
Integrated Testing
Cópia Controlada Page 198 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Logon Balancing
O Logon Balancing é usado para distribuir os usuários do R/3 nos servidores de aplicação.
O grupo de logon são instalados e gerenciados pelo R/3. Se define um tempo de resposta máximo
por servidor de aplicação e o número máximo de usuários por servidor.
Para criar Logon group: Selecione transação SMLG.
Clique no create entry
Criar grupo e marcar a
Instance.
Para salvar clique em
copy.
Cópia Controlada Page 199 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para assinalar o tempo de resposta máximo para cada grupo de logon, clique no botão de avanço:
Frontend – Marque o endereço IP do servidor assinalado.
Resp.Time – deve se definir um mesmo tempo para todos os grupos da mesma instance.
Users – É o numero máximo de usuários configurados que podem se logar nesta instance.
A tela acima mostra como estão as distribuição dos usuários por instance.
Clique em GOTO – LOAD DISTRIBUTION
Cópia Controlada Page 200 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Operation Mode
Normalmente, os sistemas R/3 precisam de mais WP´s dialog durante o dia e mais WP´s background durante
a noite.
Existem dois modos de se ajustar o sistema para se adequar a necessidades diferentes dependendo do
período do dia e do tipo de utilização principal. Isso pode ser feito alternado-se os perfis da instância ou
usando o processo de modo de operação (operation mode).
O uso de modo de operação maximiza a utilização dos recursos nas diferentes fases de atividade do sistema.
A mudança do modo de operação reconfigura o R/3 dinamicamente, o que substitui a alteração dos perfis e a
reinicialização do sistema.
A utilização das mudanças de modo de operação se baseia nos seguintes fatores:
- os serviços ou os tipos de work processes needed
- o intervalo de tempo escolhido
Cópia Controlada Page 201 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para configurar o Operation Mode, digite a transação RZ04.
1-) Clique em Operation Mode – New – crie o novo modo de operação Noturno e Diurno – SALVE !!!
2-) Clique no botão Instance/OP modes – Settings – Based on act status – new instance – create.
3-) Dar duplo clique no Operation-Day e programe as quantidades de processos de dialog e background.
4-) Repetir o passo 3 para Operation-Night.
Cópia Controlada Page 202 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Para configurar a tabela TIMETABLE.
1-) Clicar no Operation Mode – Timetable – clique no botão Change.
2-) De duplo clique num intervalo de hora, para que o mesmo fique marcado, após clique no botão Assign.
3-) Escolha o Operation Mode, e salve.
Cópia Controlada Page 203 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
System Administration Assistant - SSAA
A transação SSAA foi desenvolvida para dar um roteiro de gerenciamento para os profissionais de basis.
Ela lista todas as tarefas que são necessárias para o dia/dia.
1. Execute a transação SSAA. e 2. Selecione Entire View tab.
2
3. Selecione o botão do óculos.
Cópia Controlada Page 204 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
4
4- Selecione o botão acima.
5- Selecione no Menu a opção View –Transaction Code para visualizar os códigos das transações, na medida
que você for executando-as o semáforo ficará verde.
Cópia Controlada Page 205 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Audit Information System - SECR
Esta transação deverá ser utilizada pela Auditoria interna da empresa, pois nela temos todas as informações
sobre nosso sistema, isto é, acesso a todas as transações de sistemas e de negócios. Este acesso é somente
READ ONLY quando utilizado o perfil próprio de auditor.
Todos os relatórios gerados pelo AIS podem ser salvos e exportados para outras ferramentas de Auditoria
como ACL, e outras.
Não é necessário aumentar espaço em disco para a utilização desta ferramenta, e caso a estrutura do AIS
não esteja disponível, basta aplicar um nota para que isto seja feito.
Perfil Funções
ZBC-AUDITOR SAP_CA_AUDITOR_APPL_ADMIN
ZBC-AUDITOR SAP_CA_AUDITOR_SYSTEM
ZBC-AUDITOR SAP_CA_AUDITOR_DS
ZBC-AUDITOR SAP_CA_AUDITOR_HR
ZBC-AUDITOR SAP_CA_AUDITOR_APPL
Entre com a transação SECR.
1. Selecione Complete audit e 2- execute.
3. Clique no nó(+) para expandir :
1
2
3
Cópia Controlada Page 206 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
1. Sob o System Audit, clique no nó(+) para expandir Repository / Tables.
2. Clique no nó(+) para expandir Table Information.
3. Selecione Data Dictionary display.
Cópia Controlada Page 207 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
4. Quando a transação é executada, visualizamos a seguinte tela.
5. Selecione Back.
5
1. Sob o Business Audit, clique no nó(+) para Closing (FI-GL). 2. (+) Balance Sheet/ P&L/Balances.
3. Clique (+) Balance Sheet/ P&L , você pode executar diferentes relatórios para inspecionar balancos
financeiros. 4. Selecione Profit and Loss Projection.
1
2
3
Cópia Controlada Page 208 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
6
5
Criar uma Visão de Auditoria:
Entre na transação SECR e selecione 2- User-defined audit. 3. entre com o nome da Visão(ZVUE).
4. Selecione o botão para criar. (os nomes devem começar com “Y” or “Z.”)
5. Entre com o nome da visão ZVUE.
6. Selecione Manual selection. 7- e execute.
8. Selecione 9. crie e 10- gerar a visão.
2
Cópia Controlada Page 209 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
12
13
Cópia Controlada Page 210 of 211
Preparado: Leonardo Campos Castilho
BASIS
Administrando o SAP R/3
Exemplos :
1.0 Tentativa de acesso não autorizado à Transação
Caminho System Audit – System Logs and Status Display – system Log – System Log File
Obs. Não foi encontrado nenhuma tentativa de acesso não autorizado no período de 01/02/2002 à
22/02/2002.
Recomendamos acompanhar o log semanalmente.
2.0 Tentativa de acesso aos objetos críticos
Caminho System Audit – User Admin – Info System Authorization & User – users – By complex search criteria
Objetos Activity User Group Usuarios
S_USER_GRP 01 ou 02 * BZAAI, BZAMH, BZAPO, BZINTERFACE, BZSAG, DDIC, OSS, SAP*, WF-
BATCH
S_USER_PRO 01,02,07,22 * BZAAI, BZAMH, BZAPO, BZINTERFACE, BZSAG, DDIC, OSS, SAP*, WF-
BATCH
S_USER_AUT 01 ou 02 S* BZAAI, BZAMH, BZAPO, BZINTERFACE, BZSAG, DDIC, OSS, SAP*, WF-
BATCH
S_TABU_DIS 02 SS BZAAI, BZAMH, BZAPO, BZINTERFACE, BZSAG, DDIC, OSS, SAP*, WF-
BATCH
S_TRANSPRT 01 ou 02 * BZAAI, BZAMH, BZAPO, BZINTERFACE, BZSAG, DDIC, OSS, SAP*, WF-
BATCH
S_DEVELOP * * Ver anexo
S_ARCHIVE * * BZAAI, BZAMH, BZAPO, BZINTERFACE, BZSAG, DDIC, OSS, SAP*, WF-
BATCH
S_NUMBER 02,11,13 * BZAAI, BZAMH, BZAPO, BZINTERFACE, BZSAG, DDIC, OSS, SAP*, WF-
BATCH
S_PROGRAM * * BZAAI, BZAMH, BZAPO, BZINTERFACE, BZSAG, DDIC, OSS, SAP*, WF-
BATCH
Obs. Recomendamos rever os usuários com estes objetos.
3.0 Tabelas desenvolvidas sem atribuição de grupos de autorização
Caminho System audit – Repository table – table information – data browser
Tabela Verificar Observação
TDDAT Z* ou Y*
Obs. Ok não foi encontrada nenhuma tabela desenvolvida sem uma autorização.
4.0 Parâmetros de Login
Caminho System audit – user administration – authorization – system parameters
Parâmetros Descrição RSPARAM
1- Login/ext_security Acesso ao sistema com segurança externa N
2- Login/failed_user_auto_unlock Se 1 o sistema desbloqueia usuário após a 24H e 1 min. 1
3- Login/fails_to_user_lock Numeros de logon invalido permitido 3
4- Login/min_password_ing Comprimento minimo de senha 8
5- Login/no_automatic_user_sapstar Controle de login do usuario SAP* 0
6- Login/password_expiration_time Numero de dias que o usuario deve trocar sua senha 30
7- Login/multi_login_users Permite que um usuario só se logue uma vez (valor 1)
8- Rdisp/gui_auto_logout Numero de segundos que uma seção é interrompida por inatividade 0
Obs. Rever parâmetros 1,2,5,7 e 8,
Cópia Controlada Page 211 of 211
Preparado: Leonardo Campos Castilho
Você também pode gostar
- Exercicios Implementacao Banco de DadosDocumento17 páginasExercicios Implementacao Banco de DadosAnderson Venancio100% (1)
- Revisao Simulado OracleDocumento2 páginasRevisao Simulado OracleRodrigo MarcellAinda não há avaliações
- Instalação de Certificado Digital Na Strust - SAP BlogsDocumento3 páginasInstalação de Certificado Digital Na Strust - SAP BlogscarlosjanssenrsAinda não há avaliações
- Instalando o SAPROUTER para Conexão SNCDocumento6 páginasInstalando o SAPROUTER para Conexão SNCmkolombeskyAinda não há avaliações
- EF Conciliação AP X AR - V01Documento8 páginasEF Conciliação AP X AR - V01Renata RochaAinda não há avaliações
- PTBR - Configuration Guide - RCS - Nota Fiscal - v1.0Documento42 páginasPTBR - Configuration Guide - RCS - Nota Fiscal - v1.0WpmartinsAinda não há avaliações
- SAP RecClient para Gravações de Logs de Alterações Nas TabelasDocumento8 páginasSAP RecClient para Gravações de Logs de Alterações Nas TabelasValdevy PiresAinda não há avaliações
- DAPI-MM-20140311-20425-Estorno MIGO Entrega Futura (Ref. 17775)Documento10 páginasDAPI-MM-20140311-20425-Estorno MIGO Entrega Futura (Ref. 17775)Rogério Andrade Dos SantosAinda não há avaliações
- Abrir Tabelas IMG Na ProducaoDocumento5 páginasAbrir Tabelas IMG Na ProducaorenatalibaAinda não há avaliações
- BPP - MD04Documento23 páginasBPP - MD04gilmardmAinda não há avaliações
- Curso Crystal Report 8.5Documento28 páginasCurso Crystal Report 8.5Diogenes DausterAinda não há avaliações
- Mapos Ramon SilvaDocumento1 páginaMapos Ramon SilvaJardell NkAinda não há avaliações
- Aulas Capítulo 1 - Introdução - Conceitos e Principais Termos ETLDocumento60 páginasAulas Capítulo 1 - Introdução - Conceitos e Principais Termos ETLAnderson Phil100% (1)
- Treinamento Banco de Dados ToTVS PDFDocumento212 páginasTreinamento Banco de Dados ToTVS PDFPaulo MarcioAinda não há avaliações
- Prova IntegracaoBancoDados PDFDocumento4 páginasProva IntegracaoBancoDados PDFValter PatrickAinda não há avaliações
- Arquiteturas SAPDocumento17 páginasArquiteturas SAPDennerAndradeAinda não há avaliações
- ST para Material de ConsumoDocumento3 páginasST para Material de ConsumoMarcelo PaivaAinda não há avaliações
- Enhancements & ModificaçõesDocumento53 páginasEnhancements & ModificaçõesRoger SudatiAinda não há avaliações
- Manual - Usuário - SAP MM (Cadastro de Fornecedor)Documento19 páginasManual - Usuário - SAP MM (Cadastro de Fornecedor)LUIZA100% (2)
- 2-Apostila Basis - SgarbiDocumento137 páginas2-Apostila Basis - SgarbiFabiano AlvesAinda não há avaliações
- Cats Sap PTDocumento18 páginasCats Sap PTLuan David J. BatistaAinda não há avaliações
- MM 2 - Administração de Materiais - Aula 2 - Exibir Reservas de Materiais - MB23Documento6 páginasMM 2 - Administração de Materiais - Aula 2 - Exibir Reservas de Materiais - MB23Diogo SouzaAinda não há avaliações
- Aula 02Documento21 páginasAula 02Madson CruzAinda não há avaliações
- MM 2 - Administração de Materiais - Aula 2 - Criar Material - MM01Documento11 páginasMM 2 - Administração de Materiais - Aula 2 - Criar Material - MM01Diogo SouzaAinda não há avaliações
- Domicilio Fiscal SAPDocumento2 páginasDomicilio Fiscal SAPRogerio NereAinda não há avaliações
- Apostila Completa Curso de Introdu o Ao SAP 1561952341Documento74 páginasApostila Completa Curso de Introdu o Ao SAP 1561952341Jeferson Massari100% (1)
- TCC Erpsappp 170105110616Documento120 páginasTCC Erpsappp 170105110616Leandro SapAinda não há avaliações
- IOP-ADM-UNI-032 INVENTÁRIO ROTATIVO (PERIÓDICO) Rev 02Documento46 páginasIOP-ADM-UNI-032 INVENTÁRIO ROTATIVO (PERIÓDICO) Rev 02Kilson CalandAinda não há avaliações
- Especificaçao Funcional - SCM - C036 - CaracterísticasDocumento4 páginasEspecificaçao Funcional - SCM - C036 - CaracterísticasMarcelo Pires BatalhaAinda não há avaliações
- SAP MM - Processo de CotaçãoDocumento2 páginasSAP MM - Processo de CotaçãoAndre Gonçalves PereiraAinda não há avaliações
- Como Encontrar Exits e Bapis para Uma TransaçãoDocumento11 páginasComo Encontrar Exits e Bapis para Uma TransaçãoAna Maria FerrazziAinda não há avaliações
- 1J5 S4hana2021 BPD PT BRDocumento57 páginas1J5 S4hana2021 BPD PT BRCleuvison Butinhao100% (1)
- Hierarquia de Documentos para NewGLDocumento15 páginasHierarquia de Documentos para NewGLJusapfiAinda não há avaliações
- Introdução Ao Sap - Fbl1nDocumento10 páginasIntrodução Ao Sap - Fbl1nDaut PoloAinda não há avaliações
- Aula 07 - Lançamento Fiscal - Miro - Mm-Fi. OkDocumento11 páginasAula 07 - Lançamento Fiscal - Miro - Mm-Fi. OkLuiz GonzagaAinda não há avaliações
- Algumas NF-e Não Estão Indo para o GRC. - SAP Q&ADocumento4 páginasAlgumas NF-e Não Estão Indo para o GRC. - SAP Q&ARenata RochaAinda não há avaliações
- Banksync Manual de ImplantaçãoDocumento60 páginasBanksync Manual de ImplantaçãoDiogo Oliveira SilvaAinda não há avaliações
- AFAB - Lançar DepreciaçãoDocumento8 páginasAFAB - Lançar DepreciaçãoQueli BelchiorAinda não há avaliações
- Apostila Arquitetura - e - InstalaçãoDocumento30 páginasApostila Arquitetura - e - InstalaçãoxxmichelxxAinda não há avaliações
- Academia Sap SD Aluno 3008Documento334 páginasAcademia Sap SD Aluno 3008Amanda AraújoAinda não há avaliações
- Como Localizar Nota Fiscal Eletrônica No SAP NFe Usando A Transação J1BNFEDocumento17 páginasComo Localizar Nota Fiscal Eletrônica No SAP NFe Usando A Transação J1BNFEdude28spAinda não há avaliações
- MMCC - Ampliação e Criação de Materiais em MassaDocumento7 páginasMMCC - Ampliação e Criação de Materiais em MassarobertonewsAinda não há avaliações
- Integrador DFe Conector SAP 60 Manual PTDocumento36 páginasIntegrador DFe Conector SAP 60 Manual PTMauricio TakaoAinda não há avaliações
- 3 PDFDocumento17 páginas3 PDFricardo_motta_silvaAinda não há avaliações
- Output Management - Configurando o DANFE (Adobe Forms)Documento16 páginasOutput Management - Configurando o DANFE (Adobe Forms)Daniel FrancoAinda não há avaliações
- Treinamento ABAP-HR ExerciciosDocumento13 páginasTreinamento ABAP-HR ExerciciosMarcos SchmidtAinda não há avaliações
- SAP Netweaver Integration - LISTA de CURSODocumento9 páginasSAP Netweaver Integration - LISTA de CURSOdiegowiskAinda não há avaliações
- Industrialização Por Conta e Ordem de Terceiro - Fácil123Documento4 páginasIndustrialização Por Conta e Ordem de Terceiro - Fácil123Maria CunhaAinda não há avaliações
- Treinamento Sap Apo Planejamento de FornecimentoDocumento103 páginasTreinamento Sap Apo Planejamento de FornecimentoElisangela Henrique Marques Dos Santos100% (1)
- Apresentação SAP Fiori - AndroidDocumento21 páginasApresentação SAP Fiori - AndroidIvanilson XavierAinda não há avaliações
- MIT041 - Especificação Do Processo - SIGALOJA - GAP - Escopo - v4Documento12 páginasMIT041 - Especificação Do Processo - SIGALOJA - GAP - Escopo - v4Paulo RafaelAinda não há avaliações
- MRP Live S4 HanaDocumento7 páginasMRP Live S4 HanaPaulo Celso BarbosaAinda não há avaliações
- ManualDocumento100 páginasManualwellington felipe silvaAinda não há avaliações
- Aula 09 - Análise de Partidas de Clientes e Fornecedores - Fbl5n e Fbl1n. OkDocumento12 páginasAula 09 - Análise de Partidas de Clientes e Fornecedores - Fbl5n e Fbl1n. OkLuiz GonzagaAinda não há avaliações
- NW - Espec - Integração CPJ X SAP - 4.0Documento32 páginasNW - Espec - Integração CPJ X SAP - 4.0Rafael Knevels100% (1)
- Aula 09 - Felipe SAPDocumento12 páginasAula 09 - Felipe SAPDaniel BeloAinda não há avaliações
- Guia para Impressão de Logotipos em Impressoras Zebra No SAPDocumento15 páginasGuia para Impressão de Logotipos em Impressoras Zebra No SAPluizhm0reiraAinda não há avaliações
- Variável para Atualização Dinâmica Do Ano e Mês Corrente Durante A Execução de Um JOBDocumento3 páginasVariável para Atualização Dinâmica Do Ano e Mês Corrente Durante A Execução de Um JOBNeulersAinda não há avaliações
- Linux CentOS 7 - Guia PráticoDocumento3 páginasLinux CentOS 7 - Guia PráticoLuiz Antônio100% (1)
- Bloco K - Guia de Referência - Linha DatasulDocumento32 páginasBloco K - Guia de Referência - Linha Datasulevan100% (1)
- SQVIDocumento9 páginasSQVIHenriqueAinda não há avaliações
- Subcontratacao Com ICMSDocumento8 páginasSubcontratacao Com ICMSdiogolfm27Ainda não há avaliações
- Documentação Configuração NFe InboundDocumento13 páginasDocumentação Configuração NFe InboundMarcos PauloAinda não há avaliações
- Apostila Transporte de QueryDocumento12 páginasApostila Transporte de QueryValdir RocconAinda não há avaliações
- Criar JOB SAPDocumento5 páginasCriar JOB SAPValdevy PiresAinda não há avaliações
- Apresentacao TreportDocumento11 páginasApresentacao TreportEdson BorgesAinda não há avaliações
- Criação de Relatórios em DelphiDocumento10 páginasCriação de Relatórios em DelphiUbirajara Ferreira da SilvaAinda não há avaliações
- Funcoes TriggersDocumento27 páginasFuncoes TriggerseduardosantosAinda não há avaliações
- Banco de Dados Com MySQLDocumento20 páginasBanco de Dados Com MySQLBreno Nogueira Botelho NoccioliAinda não há avaliações
- Apostila - Módulo 3 - Técnico de Banco de Dados PDFDocumento69 páginasApostila - Módulo 3 - Técnico de Banco de Dados PDFAndre FelipeAinda não há avaliações
- Comandos SQL (Continuacao)Documento3 páginasComandos SQL (Continuacao)Paulo EduardoAinda não há avaliações
- Tema 6 - Consulta Com Várias Tabelas No POSTGRESQLDocumento47 páginasTema 6 - Consulta Com Várias Tabelas No POSTGRESQLGabriel CerqueiraAinda não há avaliações
- 9 - Interacao Entre Tarefas - Problemas de CoordenacaoDocumento25 páginas9 - Interacao Entre Tarefas - Problemas de CoordenacaoLuis Felipe ZaguiniAinda não há avaliações
- SQL Server 2000Documento117 páginasSQL Server 2000Daniel Pereira ComimAinda não há avaliações
- Curso Banco de DadosDocumento22 páginasCurso Banco de DadosCarol HonemannAinda não há avaliações
- Exercicios DML - Comando InsertDocumento12 páginasExercicios DML - Comando InsertUnibeducafro EducafroAinda não há avaliações
- Curso 5653 Aula 05 v1Documento173 páginasCurso 5653 Aula 05 v1rodrigokamenachAinda não há avaliações
- 8 Modelagem e Desenvolvimento de Banco de DadosDocumento15 páginas8 Modelagem e Desenvolvimento de Banco de DadosFabio Henrique LimaAinda não há avaliações
- TMS BT Preenchimento Do Campo X2 DISPLAY TPPAXJDocumento12 páginasTMS BT Preenchimento Do Campo X2 DISPLAY TPPAXJGilberto Franco JuniorAinda não há avaliações
- DataWarehouse - Passo A PassoDocumento339 páginasDataWarehouse - Passo A PassoJose Ferreira100% (1)
- Estimativa DespesaDocumento21 páginasEstimativa DespesaBruno BittencourtAinda não há avaliações
- Construção de Tabelas Com Intervalo de ClasseDocumento13 páginasConstrução de Tabelas Com Intervalo de ClasseJoão Pedro BarbosaAinda não há avaliações
- CONSULTAS SQL - INTELIGÊNCIA DE NEGÓCIOS - V12 - AP01 Ok PDFDocumento50 páginasCONSULTAS SQL - INTELIGÊNCIA DE NEGÓCIOS - V12 - AP01 Ok PDFFlavio Almeida100% (1)
- 09 Plano de Backup Senac 1.7 Jun2017Documento11 páginas09 Plano de Backup Senac 1.7 Jun2017JoJo Nascimento LemosAinda não há avaliações
- Aula 05: Desenvolvimento de Software para Concursos - Curso RegularDocumento92 páginasAula 05: Desenvolvimento de Software para Concursos - Curso RegularcarthurpsAinda não há avaliações
- Ufcd 5083Documento2 páginasUfcd 5083pedro mirandaAinda não há avaliações