Você também pode gostar
- Estudo Comparativo Entre Modelos de Classificação para Behavior Scoring em ProcedimentosDocumento12 páginasEstudo Comparativo Entre Modelos de Classificação para Behavior Scoring em ProcedimentosDeborahAinda não há avaliações
- 1887-Texto Do Artigo-8976-1-10-20150119Documento28 páginas1887-Texto Do Artigo-8976-1-10-20150119Wagner R.Ainda não há avaliações
- Análise de Risco de Crédito Aplicando Regressão Logística, Neural Modelos de Redes e Algoritmos GenéticosDocumento12 páginasAnálise de Risco de Crédito Aplicando Regressão Logística, Neural Modelos de Redes e Algoritmos GenéticosFernando SilvaAinda não há avaliações
- Exemplo de Projeto de PesquisaDocumento2 páginasExemplo de Projeto de PesquisaSilas Rodrigues RamosAinda não há avaliações
- A Avaliação Do Risco Do Crédito É A Chance Que A Espectativa Do Reembolso Dos Recursos Não Se CumprirDocumento4 páginasA Avaliação Do Risco Do Crédito É A Chance Que A Espectativa Do Reembolso Dos Recursos Não Se Cumprirflavia noveleAinda não há avaliações
- Modelos Estatísticos de Behaviour ScoreDocumento35 páginasModelos Estatísticos de Behaviour ScoreElvisAinda não há avaliações
- Case - Estatistica DecisoriaDocumento8 páginasCase - Estatistica Decisoriagabriel ResendeAinda não há avaliações
- Modelagem de RiscoDocumento23 páginasModelagem de RiscoFelipe PretelAinda não há avaliações
- Exemplo5.TCC PredicaoDocumento18 páginasExemplo5.TCC PredicaotalesfdsAinda não há avaliações
- Análise de CréditoDocumento14 páginasAnálise de CréditoFrancisco AraújoAinda não há avaliações
- 9098 1117 7393 1 10 20200108 DesbloqueadoDocumento4 páginas9098 1117 7393 1 10 20200108 DesbloqueadoLeonardo SouzaAinda não há avaliações
- Modelagem Do Risco de Crédito Um Estudo Do Segmento de Pessoas Físicas em Um Banco de VarejoDocumento25 páginasModelagem Do Risco de Crédito Um Estudo Do Segmento de Pessoas Físicas em Um Banco de VarejoericthiagoAinda não há avaliações
- Uma Metaheurística Híbrida de Dois Níveis para Pontuação de CréditoDocumento11 páginasUma Metaheurística Híbrida de Dois Níveis para Pontuação de CréditoFernando SilvaAinda não há avaliações
- B3 Uma Análise Do Uso de Redes Neurais para A Avaliação Do Risco de Crédito de EmpresaDocumento49 páginasB3 Uma Análise Do Uso de Redes Neurais para A Avaliação Do Risco de Crédito de EmpresaEvandro S. MottaAinda não há avaliações
- Resumo Sobre Avaliação Da Usabilidade de Sites de E-Commerce ComDocumento3 páginasResumo Sobre Avaliação Da Usabilidade de Sites de E-Commerce ComCleber Santos Pinto JuniorAinda não há avaliações
- Aula 2Documento6 páginasAula 2Rafael FreitasAinda não há avaliações
- Tese Doutoramento Antonio MS Batista - ScoringDocumento155 páginasTese Doutoramento Antonio MS Batista - ScoringCristina Delgado GonçalvesAinda não há avaliações
- Behavior ScoringDocumento20 páginasBehavior ScoringRicardo HondaAinda não há avaliações
- Desafio Profissional - Administração 8 SemestreDocumento12 páginasDesafio Profissional - Administração 8 SemestreLuciana FonsecaAinda não há avaliações
- VsmosDocumento17 páginasVsmosRonaldo José DelaAinda não há avaliações
- Ganhos Potenciais Do Uso Do Blockchain Na AvaliacaDocumento19 páginasGanhos Potenciais Do Uso Do Blockchain Na AvaliacaCariElpídioAinda não há avaliações
- Brochura Tecnica DelinquencyDocumento12 páginasBrochura Tecnica DelinquencymarcosfsousaAinda não há avaliações
- Amiga Da Manu MateriaDocumento13 páginasAmiga Da Manu MateriaessabeluxoAinda não há avaliações
- Trabalho Final MLGDocumento17 páginasTrabalho Final MLGVénydo DunheAinda não há avaliações
- 870-Artigo Final-4084-1-4-20211209Documento10 páginas870-Artigo Final-4084-1-4-20211209Rey VocêAinda não há avaliações
- 3 09 Coc CréditoDocumento22 páginas3 09 Coc CréditoandreaAinda não há avaliações
- A3 - Ciencia de DadosDocumento20 páginasA3 - Ciencia de DadosVitória AndradeAinda não há avaliações
- Dissertação FidelidadeDocumento108 páginasDissertação FidelidadeAna Denise Ceolin VelosoAinda não há avaliações
- Análise de Crédito PJ - IjbDocumento6 páginasAnálise de Crédito PJ - IjbPedro WinterAinda não há avaliações
- III TeoricoDocumento30 páginasIII TeoricoHudson SantosAinda não há avaliações
- Conceito de Rating, Behavior e Credit ScoringDocumento3 páginasConceito de Rating, Behavior e Credit ScoringThiagoAinda não há avaliações
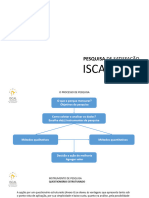
- Pesquisa 2024 Satisfação IscalDocumento17 páginasPesquisa 2024 Satisfação IscalAlicio Maffra JuniorAinda não há avaliações
- M6 - Thadeu MeloDocumento2 páginasM6 - Thadeu Melothadeu meloAinda não há avaliações
- Atividade 1 - Modelagem de SistemasDocumento2 páginasAtividade 1 - Modelagem de SistemasSilvania SalesAinda não há avaliações
- XXVIIICBC Artigo 0083Documento16 páginasXXVIIICBC Artigo 0083Richardson BorgesAinda não há avaliações
- Faculdade Metropolitana de ManausDocumento5 páginasFaculdade Metropolitana de ManausAdrianaKBAinda não há avaliações
- Visão Geral Da Análise de Dados - Training - Microsoft LearnDocumento4 páginasVisão Geral Da Análise de Dados - Training - Microsoft LearnLucas GonçalvesAinda não há avaliações
- O Futuro Do Setor BancarioDocumento3 páginasO Futuro Do Setor BancariolukkinhasmattosAinda não há avaliações
- 5 Cs Do CréditoDocumento4 páginas5 Cs Do CréditoMaria Tainan CostaAinda não há avaliações
- Programação Estatística FinalDocumento4 páginasProgramação Estatística FinalOrlando Oliveira OrlandoAinda não há avaliações
- Apostila - Área Do PMBOK - Gerenciamento Da QualidadeDocumento8 páginasApostila - Área Do PMBOK - Gerenciamento Da QualidadeGuilton SilvaAinda não há avaliações
- Importante - Analise BalançosDocumento20 páginasImportante - Analise BalançosOnis CesarAinda não há avaliações
- Mauria AnteprojectoDocumento7 páginasMauria AnteprojectoOctávio Paulo PauloAinda não há avaliações
- Ventas Credito LiquidezDocumento6 páginasVentas Credito LiquidezJUDIT ROMAN SOLANOAinda não há avaliações
- Introdução À Modelagem PreditivaDocumento24 páginasIntrodução À Modelagem PreditivaFilipe DuarteAinda não há avaliações
- TCC Modelo 2 - UsarDocumento19 páginasTCC Modelo 2 - UsarWillian SartórioAinda não há avaliações
- Resumo ArtigoDocumento3 páginasResumo ArtigoTom NachbarAinda não há avaliações
- Modelos de Escoragem de Crédito Aplicados A Empréstimo Pessoal Com ChequeDocumento44 páginasModelos de Escoragem de Crédito Aplicados A Empréstimo Pessoal Com ChequepauloAinda não há avaliações
- Aprendizado de Máquina - Apostila - Un V - RevDocumento12 páginasAprendizado de Máquina - Apostila - Un V - RevÍsis Casagrande D'AngelisAinda não há avaliações
- Dimensòes de Qualidade em ServiçosDocumento18 páginasDimensòes de Qualidade em Serviçosdanielavaz12Ainda não há avaliações
- Análise Qualitativa e Quantitativa de Riscos - Conceitos e DiferençasDocumento7 páginasAnálise Qualitativa e Quantitativa de Riscos - Conceitos e DiferençasdmercesAinda não há avaliações
- Análise Estatística de DadosDocumento8 páginasAnálise Estatística de DadosMichel Machado100% (1)
- Decisão MulticritérioDocumento3 páginasDecisão MulticritérioMarcus LamenhaAinda não há avaliações
- RELATORIOS DE PESQUISA EM ENGENHARIA DE PRODUCAO v.15 N. A2 P. 8 19Documento12 páginasRELATORIOS DE PESQUISA EM ENGENHARIA DE PRODUCAO v.15 N. A2 P. 8 19verybad19Ainda não há avaliações
- Atividade 1.Documento1 páginaAtividade 1.romeiroliAinda não há avaliações
- APRENDIZADO DE MÁQUINA - APOSTILA - UN V - REV - OkDocumento10 páginasAPRENDIZADO DE MÁQUINA - APOSTILA - UN V - REV - OkÍsis Casagrande D'AngelisAinda não há avaliações
- Monografia Risco de Crédito Alsénio Ngalula NunesDocumento65 páginasMonografia Risco de Crédito Alsénio Ngalula NunesAlsénio Ngalula Nunes100% (1)
- Anhanguera Educacional: Anhanguera Cândido MotaDocumento11 páginasAnhanguera Educacional: Anhanguera Cândido MotaVinicius GarridoAinda não há avaliações
- Estudo de Caso - O Desafio de MarianaDocumento3 páginasEstudo de Caso - O Desafio de MarianaEvandro S. MottaAinda não há avaliações
- A1 - Estimativa de Inadimplência Na Concessão de Crédito Agrícola Regressão LOGDocumento23 páginasA1 - Estimativa de Inadimplência Na Concessão de Crédito Agrícola Regressão LOGEvandro S. MottaAinda não há avaliações
- Material 1.livro - Metodos - Quantitativos - EadDocumento128 páginasMaterial 1.livro - Metodos - Quantitativos - EadEvandro S. MottaAinda não há avaliações
- A3 - Estratégias para Combater A Sonegação Fiscal Um Modelo para o Icms Baseado em Redes Neurais ArtificiaisDocumento23 páginasA3 - Estratégias para Combater A Sonegação Fiscal Um Modelo para o Icms Baseado em Redes Neurais ArtificiaisEvandro S. MottaAinda não há avaliações
- Importancia Da Estatistica para o Processo de Conh PDFDocumento19 páginasImportancia Da Estatistica para o Processo de Conh PDFEdson Saide XavierAinda não há avaliações
- FORMULÁRIODocumento2 páginasFORMULÁRIOEvandro S. MottaAinda não há avaliações
- TUTORIAL - Instalação Do ANACONDA Com PythonDocumento1 páginaTUTORIAL - Instalação Do ANACONDA Com PythonEvandro S. MottaAinda não há avaliações
- Arquitetura de Software - UnisinosDocumento110 páginasArquitetura de Software - UnisinosEvandro S. MottaAinda não há avaliações
- Arquitetura de Software - UnisinosDocumento110 páginasArquitetura de Software - UnisinosEvandro S. MottaAinda não há avaliações
- Livro 2 RoboticaDocumento88 páginasLivro 2 RoboticaElison RamosAinda não há avaliações
- Michel - Debrun - em - Botucatu o Conceito de Auto OrgDocumento15 páginasMichel - Debrun - em - Botucatu o Conceito de Auto Orgoklinger2767Ainda não há avaliações
- TCC Ayrton LimaDocumento74 páginasTCC Ayrton LimaMarcus BranchAinda não há avaliações
- 3 Passos para Criar Um Negócio 100 - DigitalDocumento16 páginas3 Passos para Criar Um Negócio 100 - DigitalmarcelomoraAinda não há avaliações
- "A Invasão Dos Estorninhos" - PALOMARDocumento14 páginas"A Invasão Dos Estorninhos" - PALOMARgf_minossoAinda não há avaliações
- Detecção de Objetos Com YOLODocumento67 páginasDetecção de Objetos Com YOLODiegoGonçalvesAinda não há avaliações
- FTP FTP - Dca.fee - Unicamp.br Pub Docs Vonzuben Ia006 03 Topico5 03Documento48 páginasFTP FTP - Dca.fee - Unicamp.br Pub Docs Vonzuben Ia006 03 Topico5 03AngelRibeiro10Ainda não há avaliações
- PFC Angelo Baruffi Nogueira - 2018-2Documento78 páginasPFC Angelo Baruffi Nogueira - 2018-2Gustavo AugustoAinda não há avaliações
- Redes NeuraisDocumento34 páginasRedes NeuraisTatiana VieiraAinda não há avaliações
- Sistemas InteligentesDocumento78 páginasSistemas InteligentesRodney FormagginiAinda não há avaliações
- Automação de Processos Através Da RPA para Transformação DigitalDocumento94 páginasAutomação de Processos Através Da RPA para Transformação Digitalpatrick vieiraAinda não há avaliações
- Aprenda A Gerar Imagens Incríveis Com o Stable DiffusionDocumento21 páginasAprenda A Gerar Imagens Incríveis Com o Stable DiffusionjunkAinda não há avaliações
- Cefet/Rj Bacharelado em Ci Encia Da Computa C Ao GCC1917 - T Opicos Especiais em Programa C Ao 2021.2 Trabalho 1Documento5 páginasCefet/Rj Bacharelado em Ci Encia Da Computa C Ao GCC1917 - T Opicos Especiais em Programa C Ao 2021.2 Trabalho 1Igor FeitalAinda não há avaliações
- Um Sistema de Aprendizagem de Jogos de DamasDocumento145 páginasUm Sistema de Aprendizagem de Jogos de DamaseducasolAinda não há avaliações
- Andre Lima - Resumo Do Ciclo Da Autossabotagem PDFDocumento7 páginasAndre Lima - Resumo Do Ciclo Da Autossabotagem PDFLeandro SilvaAinda não há avaliações
- CB 18 Deep Learning PDFDocumento22 páginasCB 18 Deep Learning PDFbesafeAinda não há avaliações
- RedesNeurais UN 3Documento20 páginasRedesNeurais UN 3McJoeAinda não há avaliações
- Análise Do Desgaste de Ferramentas Via Emissão Acústica Com Aplicações de Redes NeuraisDocumento24 páginasAnálise Do Desgaste de Ferramentas Via Emissão Acústica Com Aplicações de Redes NeuraissaccaroAinda não há avaliações
- Introdução Às Redes Neurais ArtificiaisDocumento41 páginasIntrodução Às Redes Neurais Artificiaisn0tl3Ainda não há avaliações
- Desafios Bioeticos Do Uso Da InteligenciDocumento12 páginasDesafios Bioeticos Do Uso Da InteligenciMaria de Lourdes BarcelosAinda não há avaliações
- ctc17 Cap1 PDFDocumento58 páginasctc17 Cap1 PDFmpperesAinda não há avaliações
- Montagem e Funcionamento Do Mechatronics Control KitDocumento47 páginasMontagem e Funcionamento Do Mechatronics Control KitCésar Rocha100% (1)
- Tese Algoritimos Day TradeDocumento92 páginasTese Algoritimos Day TradeBruno MedeirosAinda não há avaliações
- Usando Redes Neurais para Reconstruir Traços de Sessões de Usuários de Sistemas de Larga EscalaDocumento63 páginasUsando Redes Neurais para Reconstruir Traços de Sessões de Usuários de Sistemas de Larga EscalaFABÍOLA ROCHAAinda não há avaliações
- Inteligência Artificial E Educação: Conceitos, Aplicações E Implicações No Fazer DocenteDocumento19 páginasInteligência Artificial E Educação: Conceitos, Aplicações E Implicações No Fazer DocenteCarolina VieiraAinda não há avaliações
- Psicologia Junguiana A Luz Da NeurocienciaDocumento4 páginasPsicologia Junguiana A Luz Da NeurocienciaTAGAinda não há avaliações
- Diário Do Comércio MG 19 05 2023Documento18 páginasDiário Do Comércio MG 19 05 2023Antonio CarlosAinda não há avaliações
- Teorico Aprender 4Documento28 páginasTeorico Aprender 4Arnaldo VivianAinda não há avaliações
- Processamento de Linguagem Natural - Aula 17 - Redes Neurais ProfundasDocumento24 páginasProcessamento de Linguagem Natural - Aula 17 - Redes Neurais ProfundasQualidadeSidertecnicAinda não há avaliações
- A3 - Ciencia de DadosDocumento20 páginasA3 - Ciencia de DadosVitória AndradeAinda não há avaliações