Você também pode gostar
- Distribuição da média amostral e Teorema do Limite CentralDocumento36 páginasDistribuição da média amostral e Teorema do Limite CentralArthur FreitasAinda não há avaliações
- Aula 2 - Distribuição de ProbabilidadesDocumento21 páginasAula 2 - Distribuição de ProbabilidadesMaiko AlmeidaAinda não há avaliações
- Intervalo de Confiança 2222Documento5 páginasIntervalo de Confiança 2222Anonymous WGktCmAinda não há avaliações
- ANPEC201901 - Aula 19 - Distribuição Da Média AmostralDocumento18 páginasANPEC201901 - Aula 19 - Distribuição Da Média AmostralJoão Paulo MachadoAinda não há avaliações
- Bioestatistica Testes T para Comparacao de Medias de DoisDocumento26 páginasBioestatistica Testes T para Comparacao de Medias de DoisSergio FalciAinda não há avaliações
- 10 - Inferência EstatísticaDocumento37 páginas10 - Inferência EstatísticaLauren FeitosaAinda não há avaliações
- Aula 7Documento27 páginasAula 7Perreira Gaspar MacanjaAinda não há avaliações
- RESOLUÇÃO TESTE Est II Gestão VersãoADocumento4 páginasRESOLUÇÃO TESTE Est II Gestão VersãoAAna RitaAinda não há avaliações
- 3.1 - Variáveis Aleatórias ContínuasDocumento7 páginas3.1 - Variáveis Aleatórias ContínuasJadson SouzaAinda não há avaliações
- Aula 3 (Distribuição Normal)Documento5 páginasAula 3 (Distribuição Normal)Responde aiAinda não há avaliações
- Teoria Da Amostragem - Distribuição Amostral PDFDocumento13 páginasTeoria Da Amostragem - Distribuição Amostral PDFCastanTNAinda não há avaliações
- 3 Estimação ParamétricaDocumento22 páginas3 Estimação ParamétricaAlexandre GomesAinda não há avaliações
- Algebra Linear e Ciencia de DadosDocumento28 páginasAlgebra Linear e Ciencia de DadosRenato AzevedoAinda não há avaliações
- Anova 1Documento3 páginasAnova 1Zayadiako M. ÁlvaroAinda não há avaliações
- Módulo 3 - ConcImp-corrigidaDocumento13 páginasMódulo 3 - ConcImp-corrigidaArroz CastanhaAinda não há avaliações
- Controle estatístico da qualidade com cartas de ShewhartDocumento19 páginasControle estatístico da qualidade com cartas de ShewhartMaiko AlmeidaAinda não há avaliações
- Trabalho de Estimativa e Parametros FinalDocumento15 páginasTrabalho de Estimativa e Parametros FinalRobison SilvaAinda não há avaliações
- Medição de grandezas físicas e propagação de errosDocumento6 páginasMedição de grandezas físicas e propagação de errosDaniela RibeiroAinda não há avaliações
- 2 Estimação IntervalosConfiancaDocumento39 páginas2 Estimação IntervalosConfiancaGuilherme HenriquesAinda não há avaliações
- RESOLUÇÃO TESTE Est II Gestão VersãoBDocumento4 páginasRESOLUÇÃO TESTE Est II Gestão VersãoBAna RitaAinda não há avaliações
- Testes de comparações múltiplas para análise estatística experimentalDocumento17 páginasTestes de comparações múltiplas para análise estatística experimentalMaxrabelo AndroidAinda não há avaliações
- Capítulo 8Documento11 páginasCapítulo 8Carlos HenriqueAinda não há avaliações
- Variável Aleatória Discreta - EstatísticaDocumento6 páginasVariável Aleatória Discreta - EstatísticatellesbrunoAinda não há avaliações
- Separatrizes e VariabilidadeDocumento31 páginasSeparatrizes e VariabilidadeIago Neto AlvesAinda não há avaliações
- Resolução Dos Exercicios Das AulasDocumento15 páginasResolução Dos Exercicios Das AulasFrancisco GodinhoAinda não há avaliações
- Aula Remota - IC281 06-07-2021Documento59 páginasAula Remota - IC281 06-07-2021Guilherme SouzaAinda não há avaliações
- 3 Distribuiçao ProbabilidadeDocumento13 páginas3 Distribuiçao ProbabilidadeLuiz Gustavo da SilvaAinda não há avaliações
- Distribuição Log - NormaDocumento24 páginasDistribuição Log - NormaIgor GarciaAinda não há avaliações
- Inferência - Intervalo de ConfiançaDocumento24 páginasInferência - Intervalo de ConfiançaDiegoAlbertoAinda não há avaliações
- RESOLUÇÃO Teste Estat II TGD42 VBDocumento4 páginasRESOLUÇÃO Teste Estat II TGD42 VBAna RitaAinda não há avaliações
- Teste de igualdade de médias para três amostrasDocumento5 páginasTeste de igualdade de médias para três amostrasMebels NjanjeAinda não há avaliações
- 02 - Estatística APENC 2022Documento17 páginas02 - Estatística APENC 2022Paula PintonAinda não há avaliações
- Análise de Regressão Linear Simples e MúltiplaDocumento30 páginasAnálise de Regressão Linear Simples e MúltiplaFelipe BarretoAinda não há avaliações
- licao_1Documento9 páginaslicao_1João FernandesAinda não há avaliações
- Delineamento Inteiramente CasualizadoDocumento41 páginasDelineamento Inteiramente CasualizadoFagner MoreiraAinda não há avaliações
- Análise estatística da eficácia do fitoterápico Morosil na redução de pesoDocumento12 páginasAnálise estatística da eficácia do fitoterápico Morosil na redução de pesofilhos são eternos bebêsAinda não há avaliações
- Probabilidade e Estatística - Intervalo de ConfiançaDocumento3 páginasProbabilidade e Estatística - Intervalo de ConfiançaArcénio Nhalungo VIAinda não há avaliações
- Estimativa por intervalos de confiançaDocumento7 páginasEstimativa por intervalos de confiançaBrenoAinda não há avaliações
- Anotacoes de Intervalo de Confianca para A Diferenca de Medias e ProporcoesDocumento3 páginasAnotacoes de Intervalo de Confianca para A Diferenca de Medias e ProporcoesVinicius FreitasAinda não há avaliações
- DIC Completo Com Teste TukeyDocumento12 páginasDIC Completo Com Teste TukeyMarlon AndréAinda não há avaliações
- Aula 3c - Geraldo Goes e Alexandre Ywata - Regressao - Logistica - v1Documento59 páginasAula 3c - Geraldo Goes e Alexandre Ywata - Regressao - Logistica - v1Franciso FreitasAinda não há avaliações
- Intervalo de confiança para média e proporçãoDocumento2 páginasIntervalo de confiança para média e proporçãoMateus GomesAinda não há avaliações
- Introdução À EstatísticaDocumento46 páginasIntrodução À EstatísticaBianca WindbergAinda não há avaliações
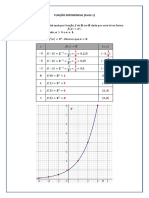
- Função exponencial (Parte 1Documento4 páginasFunção exponencial (Parte 1Claudio JuniorAinda não há avaliações
- VAU e distribuições de probabilidadeDocumento6 páginasVAU e distribuições de probabilidadeLavinia RosaAinda não há avaliações
- Aula 10Documento34 páginasAula 10Sérgio Rafael ZintchaiaAinda não há avaliações
- EDO Aula 2Documento17 páginasEDO Aula 2Fabricio VigolloAinda não há avaliações
- InferenciaDocumento28 páginasInferenciaDaniel ScardiniAinda não há avaliações
- Intervalos de ConfiançaDocumento22 páginasIntervalos de Confiançajoanamdsilva05Ainda não há avaliações
- Medidas de assimetria e curtoseDocumento56 páginasMedidas de assimetria e curtoseIthalo CoelhoAinda não há avaliações
- Teste Qui QuadradoDocumento4 páginasTeste Qui QuadradoDelizio Marcanizzy DBAinda não há avaliações
- 2 EstatisticaDocumento20 páginas2 Estatisticacatarina FerreiraAinda não há avaliações
- Regressão logística explicadaDocumento8 páginasRegressão logística explicadabeta1123 testAinda não há avaliações
- Aula02 - Distribuição de FrequenciaDocumento14 páginasAula02 - Distribuição de FrequenciaErasmoEremithAinda não há avaliações
- Módulo 3 - ConcImp-corrigidaDocumento13 páginasMódulo 3 - ConcImp-corrigidaArroz CastanhaAinda não há avaliações
- Módulo 9 - AEDocumento29 páginasMódulo 9 - AEArroz CastanhaAinda não há avaliações
- Módulo 1 Introdução Ao Curso 2023 2Documento43 páginasMódulo 1 Introdução Ao Curso 2023 2Arroz CastanhaAinda não há avaliações
- "Explorando o Ensino", Módulo SociologiaDocumento306 páginas"Explorando o Ensino", Módulo Sociologiaaba_antropologiaAinda não há avaliações
- Apostila 2 - Distribuicao AmostralDocumento12 páginasApostila 2 - Distribuicao AmostralLeandro AndraosAinda não há avaliações
- Termos estatísticos mais utilizados glossárioDocumento7 páginasTermos estatísticos mais utilizados glossárioDigno da MataAinda não há avaliações
- Aula 12Documento29 páginasAula 12Adriano CardosoAinda não há avaliações
- Livro Estatistica II PDFDocumento113 páginasLivro Estatistica II PDFJacinto Andre Muzonda50% (2)
- Probabilidades e Estat Istica CDocumento192 páginasProbabilidades e Estat Istica Cpedropereira66675% (4)
- Distribuição normal - Exemplos e exercícios de intervalo de confiançaDocumento63 páginasDistribuição normal - Exemplos e exercícios de intervalo de confiançaFabinho BrandãoAinda não há avaliações
- Exercícios de Estatística (1991-2007) - Inferência EstatísticaDocumento25 páginasExercícios de Estatística (1991-2007) - Inferência EstatísticaCarmelia Maria Tavares de Barros100% (1)
- 85 - Intervalo de ConfiançaDocumento6 páginas85 - Intervalo de Confiançajunior freitas tavaresAinda não há avaliações
- Medidas de posição: média, mediana e modaDocumento26 páginasMedidas de posição: média, mediana e modaSaavedra Tchokombonge JoséAinda não há avaliações
- Aula 72 - Estatistica - Aula 04Documento93 páginasAula 72 - Estatistica - Aula 04Hugo Pollok0% (1)
- Gerencia de Risco PDFDocumento200 páginasGerencia de Risco PDFRonilton CharlesAinda não há avaliações
- Estudo Sobre Distribuições ProbabilísticasDocumento48 páginasEstudo Sobre Distribuições ProbabilísticasThiago Christiano SilvaAinda não há avaliações
- Distribuição amostral da média em aula sobre estatísticaDocumento15 páginasDistribuição amostral da média em aula sobre estatísticaLucas LobãoAinda não há avaliações
- 411934Documento27 páginas411934Reginaldo SoteroAinda não há avaliações
- Tutorial SisvarDocumento104 páginasTutorial Sisvarvanderwill93% (15)
- IC médias e proporçõesDocumento35 páginasIC médias e proporçõesYanvu OficialAinda não há avaliações
- Estatistica - Resumo ImportanteDocumento23 páginasEstatistica - Resumo ImportanteJessika EuricoAinda não há avaliações
- Apostila de Estatística IndutivaDocumento32 páginasApostila de Estatística IndutivaDiegoAinda não há avaliações
- Cálculos de capacidade de processo e poder do gráfico de controle para variável com distribuição normalDocumento32 páginasCálculos de capacidade de processo e poder do gráfico de controle para variável com distribuição normalGabriel Victor SantanaAinda não há avaliações
- Probabilidade Aula UfrjDocumento41 páginasProbabilidade Aula UfrjGerson RosenbergAinda não há avaliações
- AFRFB Racioc Logico Traumatizados Exercicios Aula 19Documento136 páginasAFRFB Racioc Logico Traumatizados Exercicios Aula 19Ricardo Canassa100% (1)
- Correlação e regressão linear: análise de dados de consumo de combustívelDocumento26 páginasCorrelação e regressão linear: análise de dados de consumo de combustíveljavaAinda não há avaliações
- Inferência - Estatística - (Ehlers) - (2006ver.) - (Todos+Listas) - BDocumento171 páginasInferência - Estatística - (Ehlers) - (2006ver.) - (Todos+Listas) - BsssAinda não há avaliações
- A Estatística No ExcelDocumento3 páginasA Estatística No ExcelCarlos ManoelAinda não há avaliações
- EA (Estatistica Aplicada) - CadernoDocumento101 páginasEA (Estatistica Aplicada) - CadernoMarcelo Barreira MirandaAinda não há avaliações
- IPAEE 2002 Tópico4 Parte1Documento13 páginasIPAEE 2002 Tópico4 Parte1Thiago Victor da Silva BonfimAinda não há avaliações
- Distribuià à Es AmostraisDocumento24 páginasDistribuià à Es AmostraisTito MapireAinda não há avaliações
- Testes de Hipóteses e Estatística InferencialDocumento79 páginasTestes de Hipóteses e Estatística InferencialLouise100% (1)
- Lista Estatística Normal Com GabaritoDocumento31 páginasLista Estatística Normal Com GabaritoSérgio GonçalvesAinda não há avaliações
- Estatística para PF: inferência, estimação e intervalos de confiançaDocumento112 páginasEstatística para PF: inferência, estimação e intervalos de confiançaDOUGLAS CAMPOS DE ARAÚJO ESPÍNDULAAinda não há avaliações