Você também pode gostar
- Unidade III - Geometria Analítica - Retas, Planos e DistânciasDocumento20 páginasUnidade III - Geometria Analítica - Retas, Planos e DistânciasMm1285Ainda não há avaliações
- Guia 3 Parte 1 .De Estudo de Analise Numerica (26.04.2020) - 1Documento16 páginasGuia 3 Parte 1 .De Estudo de Analise Numerica (26.04.2020) - 1Jorge Pedro mateusAinda não há avaliações
- 3 Estimação ParamétricaDocumento22 páginas3 Estimação ParamétricaAlexandre GomesAinda não há avaliações
- Regressão Múltipla, Estimação e Resolução de ExercíciosDocumento8 páginasRegressão Múltipla, Estimação e Resolução de ExercíciosRui Rego0% (1)
- Método dos Mínimos Quadrados para aproximação de funçõesDocumento21 páginasMétodo dos Mínimos Quadrados para aproximação de funçõesViviane MirelyAinda não há avaliações
- Método Dos Elementos de ContornoDocumento11 páginasMétodo Dos Elementos de ContornoEstefânia CanzianAinda não há avaliações
- Autovalores Repetidos: Equações Diferenciais Ordinárias Sistemas de Equações Lineares de Primeira OrdemDocumento7 páginasAutovalores Repetidos: Equações Diferenciais Ordinárias Sistemas de Equações Lineares de Primeira Ordemgabriel juanAinda não há avaliações
- Resumo Calculo 3Documento13 páginasResumo Calculo 3Elisa TresinariAinda não há avaliações
- Resumo MA311 - Cálculo 3Documento20 páginasResumo MA311 - Cálculo 3Alexia NunesAinda não há avaliações
- Interpolação Polinomial com LagrangeDocumento8 páginasInterpolação Polinomial com LagrangeRomulo corceAinda não há avaliações
- 77capítulo Sobre SISTEMAS LINEARES E MATRIZESDocumento11 páginas77capítulo Sobre SISTEMAS LINEARES E MATRIZESRafael De Abreu AlbuquerqueAinda não há avaliações
- Trabalho 2Documento3 páginasTrabalho 2todososnomesexperimentadosAinda não há avaliações
- Modulo 8 - Quadrados MinimosDocumento6 páginasModulo 8 - Quadrados MinimosRomulo corceAinda não há avaliações
- Interpolação linear e de Lagrange em métodos numéricosDocumento7 páginasInterpolação linear e de Lagrange em métodos numéricosRafael GustavoAinda não há avaliações
- Coordenadas Baricêntricas: Pontos Notáveis e FórmulasDocumento6 páginasCoordenadas Baricêntricas: Pontos Notáveis e FórmulasDenis MedeirosAinda não há avaliações
- Lista de Exercícios de Matemática IDocumento49 páginasLista de Exercícios de Matemática IMagnus KellyAinda não há avaliações
- Estabilidade Dos Sistemas Lineares v-01Documento3 páginasEstabilidade Dos Sistemas Lineares v-01Gladis MaesAinda não há avaliações
- RESUMO2_COMBINATORIADocumento2 páginasRESUMO2_COMBINATORIACarlosAinda não há avaliações
- Aproximação de PadéDocumento6 páginasAproximação de PadéBruna RafaelaAinda não há avaliações
- Vetor unitário e expressão cartesianaDocumento20 páginasVetor unitário e expressão cartesianaDanilo MoraisAinda não há avaliações
- Manual de Álgebra LinearDocumento131 páginasManual de Álgebra Linearjoasilainy1996Ainda não há avaliações
- Lista 2 IeDocumento1 páginaLista 2 Iecabanillasb.waAinda não há avaliações
- Sobre As Cadeias de MarkovDocumento12 páginasSobre As Cadeias de MarkovRosaG.Márquez100% (1)
- Vetores - 2Documento48 páginasVetores - 2Renildes FreitaAinda não há avaliações
- Autovalores e AutovetoresDocumento6 páginasAutovalores e AutovetoresLuís FariasAinda não há avaliações
- Análise de normas em M(3×3Documento5 páginasAnálise de normas em M(3×3Nathalie Freitas BicaAinda não há avaliações
- Elementos finitos linearesDocumento11 páginasElementos finitos linearesTheFlurryAinda não há avaliações
- Ortogonal entre retasDocumento3 páginasOrtogonal entre retasMax PauloAinda não há avaliações
- 1 Lista de MA11 (1 Parte)Documento5 páginas1 Lista de MA11 (1 Parte)Magnetico concursosAinda não há avaliações
- ELD - Aula 13Documento14 páginasELD - Aula 13Luiza RochaAinda não há avaliações
- Lista de Exercícios 5Documento12 páginasLista de Exercícios 5Dannan cenouritahAinda não há avaliações
- Derivadas - Regras básicasDocumento1 páginaDerivadas - Regras básicasVulcana IvoneteAinda não há avaliações
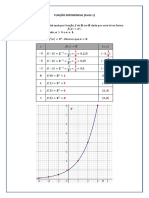
- Função exponencial (Parte 1Documento4 páginasFunção exponencial (Parte 1Claudio JuniorAinda não há avaliações
- Trans 2Documento28 páginasTrans 2pedrofrancischetoAinda não há avaliações
- Física Computacional com Python: Operações BásicasDocumento62 páginasFísica Computacional com Python: Operações BásicasCICERO RODRIGO SANTOS DA SILVAAinda não há avaliações
- NOÇÕES DE CONJUNTOS - Teoria e AprofundamentoDocumento6 páginasNOÇÕES DE CONJUNTOS - Teoria e AprofundamentoLuccas SilvaAinda não há avaliações
- Teorema das Funções Implícitas e Aplicações em MacroeconomiaDocumento8 páginasTeorema das Funções Implícitas e Aplicações em MacroeconomiaEmanuel McbrainAinda não há avaliações
- Rodrigo Pena Teobaldo - 09 17 2023Documento5 páginasRodrigo Pena Teobaldo - 09 17 2023Rodrigo PenaAinda não há avaliações
- Capitulo 7Documento8 páginasCapitulo 7Carlos HenriqueAinda não há avaliações
- Equações diferenciais ordináriasDocumento4 páginasEquações diferenciais ordináriasFelipe DornelesAinda não há avaliações
- listaDocumento17 páginaslistaJEAN CARLOS MACARIAinda não há avaliações
- Ajustamento Das Observações - Parte 2Documento49 páginasAjustamento Das Observações - Parte 2Vagner CostaAinda não há avaliações
- AULA 07 RETAS NO EspaçoDocumento13 páginasAULA 07 RETAS NO EspaçoVinicius LinsAinda não há avaliações
- Análise de normas em espaços vetoriais de matrizesDocumento8 páginasAnálise de normas em espaços vetoriais de matrizesNathalie Freitas BicaAinda não há avaliações
- Reviso Clculo IDocumento11 páginasReviso Clculo IJoana D'arck BarbosaAinda não há avaliações
- Análise de Regressão Linear Simples e MúltiplaDocumento30 páginasAnálise de Regressão Linear Simples e MúltiplaFelipe BarretoAinda não há avaliações
- Estatística - Índices, Probabilidades e DistribuiçõesDocumento2 páginasEstatística - Índices, Probabilidades e DistribuiçõesRuben StineAinda não há avaliações
- Exercícios Livro Conway 2 EdDocumento3 páginasExercícios Livro Conway 2 EdJunio Cesar FerreiraAinda não há avaliações
- Reta e Plano Geometria AnalíticaDocumento28 páginasReta e Plano Geometria Analítica.Ainda não há avaliações
- Função exponencial de base e e suas propriedadesDocumento4 páginasFunção exponencial de base e e suas propriedadescristina silvaAinda não há avaliações
- Combinações no Triângulo de PascalDocumento22 páginasCombinações no Triângulo de PascalSandra PintoAinda não há avaliações
- Aula04 - Un03 - Interpolação Polinomial - v04Documento14 páginasAula04 - Un03 - Interpolação Polinomial - v04TATIANA APARECIDA COSTAAinda não há avaliações
- Diferenciabilidade e analiticidadeDocumento10 páginasDiferenciabilidade e analiticidadeExpainAinda não há avaliações
- CL Gerador LIDocumento48 páginasCL Gerador LImomadesantos49Ainda não há avaliações
- Distância entre ponto e planoDocumento12 páginasDistância entre ponto e planoHoracio JuniorAinda não há avaliações
- Derivadas de funções reais de variável realDocumento32 páginasDerivadas de funções reais de variável realCarmoAinda não há avaliações
- Distância entre pontos no plano cartesianoDocumento18 páginasDistância entre pontos no plano cartesianoLUANA APARECIDA DA SILVA TOLEDOAinda não há avaliações
- Método da posição falsa para encontrar zeros de funçõesDocumento62 páginasMétodo da posição falsa para encontrar zeros de funçõesIdney SilvaAinda não há avaliações
- IEC082 - Cálculo Numérico - v2017Documento1 páginaIEC082 - Cálculo Numérico - v2017Márcio da Trindade MaramaldoAinda não há avaliações
- PolinomiosDocumento6 páginasPolinomiosEmanuel SantosAinda não há avaliações
- Exemplos - Métodos Matemáticos em EngenhariaDocumento79 páginasExemplos - Métodos Matemáticos em EngenhariaCristiano da silvaAinda não há avaliações
- Métodos numéricos para resolução de equações não lineares e sistemas linearesDocumento122 páginasMétodos numéricos para resolução de equações não lineares e sistemas linearesMaria SilvaAinda não há avaliações
- Num Métodos Solução Problemas EngenhariaDocumento2 páginasNum Métodos Solução Problemas EngenhariaLUCAS DE SOUZA OLIVEIRAAinda não há avaliações
- ListaDocumento15 páginasListafabricio bittcAinda não há avaliações
- Cap 4Documento44 páginasCap 4Edilson CabralAinda não há avaliações
- Sistemas de Equacoes1Documento28 páginasSistemas de Equacoes1Bryan JonathanAinda não há avaliações
- ESCALONAMENTODocumento19 páginasESCALONAMENTOBaixos até o talo OficialAinda não há avaliações
- Determinação da raiz de um polinômio da velocidade de propagação por métodos numéricosDocumento2 páginasDeterminação da raiz de um polinômio da velocidade de propagação por métodos numéricosAlessandro PaulinAinda não há avaliações
- Lista de Exercícios Avaliativa - 7 Série - 2º BimestreDocumento1 páginaLista de Exercícios Avaliativa - 7 Série - 2º Bimestrehugoleonardodemoraes100% (6)
- Modelos de elementos finitos identificados experimentalmente para análise dinâmica de estruturasDocumento366 páginasModelos de elementos finitos identificados experimentalmente para análise dinâmica de estruturasTiago Castelani100% (1)
- Calculo Numerico - AOL5Documento8 páginasCalculo Numerico - AOL5rogersampaiocostaAinda não há avaliações
- GABARITO Avaliação 3 - Individual DISCIPLINA Cálculo Numérico (MAT28)Documento10 páginasGABARITO Avaliação 3 - Individual DISCIPLINA Cálculo Numérico (MAT28)Milto Cezar GomesAinda não há avaliações
- Analise Numerica 01-ErrosDocumento54 páginasAnalise Numerica 01-Errosfabio933Ainda não há avaliações
- SVD aplicações decomposição matrizesDocumento25 páginasSVD aplicações decomposição matrizesLeticia TonettoAinda não há avaliações
- Análise de estabilidade de taludes em mina de calcárioDocumento106 páginasAnálise de estabilidade de taludes em mina de calcárioNanda RibeiroAinda não há avaliações
- Métodos numéricos: aproximação de númerosDocumento5 páginasMétodos numéricos: aproximação de númerosPrincipe Mimado100% (2)
- Zeros Reais Newton Raphson e Secante 2018 2Documento8 páginasZeros Reais Newton Raphson e Secante 2018 2HORUS_KHANAinda não há avaliações
- Matemática - Livro 3 PDFDocumento162 páginasMatemática - Livro 3 PDFLuis Antonio Lay100% (2)