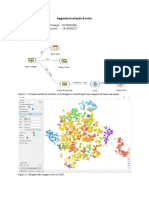
Você também pode gostar
- Deep Learning PL Aula1 MLPDocumento17 páginasDeep Learning PL Aula1 MLPAlex DomenteAinda não há avaliações
- Aprendizagem Com Redes NeuronaisDocumento8 páginasAprendizagem Com Redes NeuronaisMaria Inês Vasconcellos FurtadoAinda não há avaliações
- Tutorial Rna MatlabDocumento12 páginasTutorial Rna MatlabLeonardo Pereira SilvaAinda não há avaliações
- Solução Concorrente para Multiplicação de Matrizes (Java)Documento8 páginasSolução Concorrente para Multiplicação de Matrizes (Java)Paula Peçanha100% (1)
- VC - SlideDocumento39 páginasVC - SlideCleitonAinda não há avaliações
- Back PropagationDocumento14 páginasBack PropagationJosé Antonio NevesAinda não há avaliações
- Semana 09Documento4 páginasSemana 09Hobbies CristãoAinda não há avaliações
- Lista05 BCC326 PLEDocumento2 páginasLista05 BCC326 PLEBRIHAN DE JESUS BRANDAOAinda não há avaliações
- E Book XGB by Odemir Depieri 1683592886Documento20 páginasE Book XGB by Odemir Depieri 1683592886Lorrayne SilvaAinda não há avaliações
- Tutorial Qgis ClassificacaoDocumento13 páginasTutorial Qgis ClassificacaoPaola P. VillegasAinda não há avaliações
- Tutorial ScilabDocumento19 páginasTutorial ScilabLauro JoseAinda não há avaliações
- Relatório JOEL - BackpropagationDocumento21 páginasRelatório JOEL - BackpropagationDev BranvierAinda não há avaliações
- Relatorio PDFDocumento13 páginasRelatorio PDFAmanda PereiraAinda não há avaliações
- RNA's em JavaDocumento7 páginasRNA's em JavaTiago LisboaAinda não há avaliações
- Orientaçõest - Backpropagation2023.4Documento1 páginaOrientaçõest - Backpropagation2023.4gustavorocha5456Ainda não há avaliações
- Deep Learning PL Aula2 MLP ImagemDocumento11 páginasDeep Learning PL Aula2 MLP ImagemAlex DomenteAinda não há avaliações
- Artigo LinpackDocumento12 páginasArtigo LinpackRenato JustoAinda não há avaliações
- Calc Num FM Lista 01Documento6 páginasCalc Num FM Lista 01Maria SilvaAinda não há avaliações
- Exercicios Computação Evolutiva e ConexionistaDocumento11 páginasExercicios Computação Evolutiva e ConexionistaElaine Alves100% (1)
- Aula 02Documento60 páginasAula 02ricksant2003Ainda não há avaliações
- Aula 5 - RNA-Algoritmos de Treinamento e Metricas de AvaliaoDocumento49 páginasAula 5 - RNA-Algoritmos de Treinamento e Metricas de AvaliaoLucas HaasAinda não há avaliações
- SSS Lab1b MatlabDocumento8 páginasSSS Lab1b MatlabDouglas LourençoAinda não há avaliações
- Redes MultisaidaDocumento2 páginasRedes MultisaidaDaniel FiuzaAinda não há avaliações
- Efemm en PTDocumento63 páginasEfemm en PTanon_351258748Ainda não há avaliações
- Método Monte Carlo de varredura de domínio (MCS)No EverandMétodo Monte Carlo de varredura de domínio (MCS)Ainda não há avaliações
- Fundamentos Do Desenvovimento Objective C para Apple Ios - Algoritmos - TP2Documento9 páginasFundamentos Do Desenvovimento Objective C para Apple Ios - Algoritmos - TP2Marcos AndréAinda não há avaliações
- RN Aula Pratica 1 2021 1Documento20 páginasRN Aula Pratica 1 2021 1Paulo Henrique OrenbuchAinda não há avaliações
- Tipos de ModelosDocumento25 páginasTipos de ModelosSaymon ReisAinda não há avaliações
- Escalonador Shortest Job FirstDocumento20 páginasEscalonador Shortest Job FirstsosinsanoAinda não há avaliações
- Arena Aula 1Documento9 páginasArena Aula 1h3nrykAinda não há avaliações
- Introdução Ao PycaretDocumento11 páginasIntrodução Ao PycaretWashington VidaAinda não há avaliações
- Intro Scilab Com400Documento24 páginasIntro Scilab Com400Leonardo AquinoAinda não há avaliações
- PidDocumento23 páginasPidNatan Dos SantosAinda não há avaliações
- Redes NeuraisDocumento2 páginasRedes NeuraisSérgio CustódioAinda não há avaliações
- Matlab ExerciciosDocumento5 páginasMatlab ExerciciosJhonatan GonçalvesAinda não há avaliações
- FPGADocumento14 páginasFPGARafael MatosAinda não há avaliações
- Artigo ERADDocumento5 páginasArtigo ERADfernando souzaAinda não há avaliações
- Análise de Desempenho Usando Técnicas de Vetorização Blocagem e ConcorrênciaDocumento20 páginasAnálise de Desempenho Usando Técnicas de Vetorização Blocagem e ConcorrênciaJaguaraci Silva100% (1)
- Assembly 0001Documento9 páginasAssembly 0001Pablo PinheiroAinda não há avaliações
- Exercicios JavaDocumento28 páginasExercicios JavaSebastião JorgeAinda não há avaliações
- Segunda Avaliação EscritaDocumento12 páginasSegunda Avaliação EscritaMaycon Da Silva NunesAinda não há avaliações
- Atividades Sistemas MicroprocessadosDocumento4 páginasAtividades Sistemas MicroprocessadosLeandroAinda não há avaliações
- 3.2 - Cap 4 - Estruturas Condicionais e de SeleçãoDocumento20 páginas3.2 - Cap 4 - Estruturas Condicionais e de SeleçãoMVT EDITION BRAinda não há avaliações
- Aula 3 - Lógica de ProgramaçãoDocumento27 páginasAula 3 - Lógica de Programaçãobabitakelly0% (1)
- EA773 - Projeto FinalDocumento4 páginasEA773 - Projeto FinalGabriela ShimaAinda não há avaliações
- Assunto: Programação de PLC Usando A Linguagem LADDERDocumento1 páginaAssunto: Programação de PLC Usando A Linguagem LADDERSérgio fabiao pita MbofanaAinda não há avaliações
- Datamine Apostila Wireframes StudioOP2.7Documento82 páginasDatamine Apostila Wireframes StudioOP2.7Luis Henrique Rossi PerácioAinda não há avaliações
- TutorialDocumento27 páginasTutorialIcaro AbreuAinda não há avaliações
- Sistemas Inteligentes - Trabalho PráticoDocumento24 páginasSistemas Inteligentes - Trabalho PráticoJoaquim ManoelAinda não há avaliações
- RN 6 MLP 2Documento35 páginasRN 6 MLP 2CARLOS HENRIQUEAinda não há avaliações
- Exercícios Organização de ComputadoresDocumento31 páginasExercícios Organização de ComputadoresMattheus Santos0% (2)
- Geração de Números AleatóriosDocumento13 páginasGeração de Números AleatóriosLiliana OliveiraAinda não há avaliações
- Tarefa 1Documento5 páginasTarefa 1alexandreleonardo269Ainda não há avaliações
- TCC SimulaçãoDocumento40 páginasTCC Simulaçãobiblioteca DOD100% (1)
- Projeto Sinais FinalDocumento34 páginasProjeto Sinais FinalMateus AbdalaAinda não há avaliações
- Trabalho Da Disciplina ED1 - Parte 2 e 3Documento6 páginasTrabalho Da Disciplina ED1 - Parte 2 e 3nooneknowstrueAinda não há avaliações
- Artigo Integradora 1 1Documento4 páginasArtigo Integradora 1 1Elise Scheibel PrezziAinda não há avaliações
- OPL e CPLEXDocumento21 páginasOPL e CPLEXalex240574Ainda não há avaliações
- Prova1-Parte A-INE5645Documento4 páginasProva1-Parte A-INE5645Fernando Montoya CubasAinda não há avaliações
- Descritivo Tecnico Radar BrasilDocumento65 páginasDescritivo Tecnico Radar BrasilBruno de Oliveira AlvesAinda não há avaliações
- Informatica Na Formacao DocenteDocumento37 páginasInformatica Na Formacao DocentevaldeciAinda não há avaliações
- Engenharia de MétodosDocumento17 páginasEngenharia de MétodosTiago GonçalvesAinda não há avaliações
- Voucher Insurance D-202106171954Documento3 páginasVoucher Insurance D-202106171954camilaAinda não há avaliações
- Poo Exercicios 03 Heranca v01Documento2 páginasPoo Exercicios 03 Heranca v01Taise BomfimAinda não há avaliações
- Ficha Silabário Letra CursivaDocumento2 páginasFicha Silabário Letra CursivaLaureano PamelaAinda não há avaliações
- Jogo TransRisco Identificacao Do ComportDocumento11 páginasJogo TransRisco Identificacao Do ComportArthur AlvesAinda não há avaliações
- Projeto ABNT NBR ISO - IEC 29134 - ConsultaNacionalDocumento56 páginasProjeto ABNT NBR ISO - IEC 29134 - ConsultaNacionalcarolina nevesAinda não há avaliações
- Passo A Passo Cadastro Pat FornecedoraDocumento3 páginasPasso A Passo Cadastro Pat FornecedoraJoseAinda não há avaliações
- RH AdelanteDocumento24 páginasRH AdelanteCamila DinizAinda não há avaliações
- 2012 BT GER 034 I INFORMATIVO MANUAL E PROGRAMAÇÃO KCO0061Documento7 páginas2012 BT GER 034 I INFORMATIVO MANUAL E PROGRAMAÇÃO KCO0061João Pedro LopesAinda não há avaliações
- Mappa LGG Chs Uc2Documento108 páginasMappa LGG Chs Uc2Leon CurtisAinda não há avaliações
- Texto 4. Pesquisa - Marcelo BadaróDocumento21 páginasTexto 4. Pesquisa - Marcelo BadaróRoberval JuniorAinda não há avaliações
- Reflexão Do Módulo CLC6 MARINADocumento15 páginasReflexão Do Módulo CLC6 MARINAmarina machadoAinda não há avaliações
- Manual - Cpa 10-15 - Ed 2015-09 - BQDDocumento84 páginasManual - Cpa 10-15 - Ed 2015-09 - BQDSabrina MagalhãesAinda não há avaliações
- Lance SsimplesDocumento5 páginasLance SsimplesAlexandre Ferreira LeiteAinda não há avaliações
- Manual PCC1301 PortuguesDocumento87 páginasManual PCC1301 Portugueseverton moreiraAinda não há avaliações
- Libreoffice Calc 6 PDFDocumento36 páginasLibreoffice Calc 6 PDFThiago S. CarvalhoAinda não há avaliações
- Classe de Execução de Estrutura MetalicaDocumento55 páginasClasse de Execução de Estrutura MetalicaRicardo RAinda não há avaliações
- Portugues CNC 700 70 Manual InstructionDocumento666 páginasPortugues CNC 700 70 Manual Instructiongui_nf661874% (19)
- Apostila de Introdução À Informática by DayaDocumento45 páginasApostila de Introdução À Informática by DayaAbdalaAinda não há avaliações
- CC Integrada Q1Documento3 páginasCC Integrada Q1Vinicius AnicetoAinda não há avaliações
- Projeto Residencial 3 v5 18 15681183377749 9731Documento51 páginasProjeto Residencial 3 v5 18 15681183377749 9731Marcelo PerruciAinda não há avaliações
- Pedalboard e Set-Up Set-Up de Zakk WyldeDocumento28 páginasPedalboard e Set-Up Set-Up de Zakk WyldeMarcos Augusto BentoAinda não há avaliações
- (1.0) KIT 5 - Circuito - Liga - DesligaDocumento2 páginas(1.0) KIT 5 - Circuito - Liga - DesligaBRENNAND DE AZEVEDO VENCESLAUAinda não há avaliações
- AfroDev - Semana1Documento69 páginasAfroDev - Semana1Z. O.Ainda não há avaliações
- Treinamento Tecnico de Medição - Cadastros SGC ContratosDocumento62 páginasTreinamento Tecnico de Medição - Cadastros SGC ContratosThiago Moraes Nascimento100% (1)
- 3 Dimensionamento Estrutural de Fundacoes Superficiais e ProfundasDocumento8 páginas3 Dimensionamento Estrutural de Fundacoes Superficiais e ProfundasRoberto GnoattoAinda não há avaliações
- Processo Produtivo para Desenho 2dDocumento1 páginaProcesso Produtivo para Desenho 2dclaudinei egidioAinda não há avaliações
- A Inteligência Artificial Como Força DisruptivaDocumento18 páginasA Inteligência Artificial Como Força DisruptivaLeduc MarquesAinda não há avaliações