Você também pode gostar
- Método Monte Carlo de varredura de domínio (MCS)No EverandMétodo Monte Carlo de varredura de domínio (MCS)Ainda não há avaliações
- AV2 - ESTRUTURA de DADOSDocumento8 páginasAV2 - ESTRUTURA de DADOSRoberto Costa e SilvaAinda não há avaliações
- Programação Paralela e Distribuída: com MPI, OpenMP e OpenACC para computação de alto desempenhoNo EverandProgramação Paralela e Distribuída: com MPI, OpenMP e OpenACC para computação de alto desempenhoAinda não há avaliações
- Processadores e Computadores de Alto DesempenhoDocumento17 páginasProcessadores e Computadores de Alto DesempenhoLaís NogueiraAinda não há avaliações
- 60CBC0158 PDFDocumento16 páginas60CBC0158 PDFRenato FilhoAinda não há avaliações
- Geração de Números AleatóriosDocumento13 páginasGeração de Números AleatóriosLiliana OliveiraAinda não há avaliações
- Construa Seu Proprio Cluster Beowulf em CasaDocumento8 páginasConstrua Seu Proprio Cluster Beowulf em CasaUriel100% (4)
- Matriz EsparsaDocumento4 páginasMatriz EsparsaWeslley AssisAinda não há avaliações
- Ana Beatriz Trabalho 05 CIV0436 Metálicas ManhãDocumento14 páginasAna Beatriz Trabalho 05 CIV0436 Metálicas ManhãAna Beatriz LimaAinda não há avaliações
- Resolucao Da Atividade Objetiva 5 - 0704 A 290413Documento10 páginasResolucao Da Atividade Objetiva 5 - 0704 A 290413Eduardo CézarAinda não há avaliações
- Siqueira ThaisGamade DDocumento98 páginasSiqueira ThaisGamade DRicardoAinda não há avaliações
- Relatório Algoritmos de OrdenaçãoDocumento21 páginasRelatório Algoritmos de OrdenaçãogesspinheiroAinda não há avaliações
- New Apostila Do ProModelDocumento30 páginasNew Apostila Do ProModelKlinsman Barbosa LopesAinda não há avaliações
- Elementos de Analise de Sistemas de Potencia - William StevensonDocumento236 páginasElementos de Analise de Sistemas de Potencia - William StevensonDaphne SchAinda não há avaliações
- Apostila Excel OkDocumento307 páginasApostila Excel OkAlexandre ItoAinda não há avaliações
- Provas Presenciais ESAB Engenharia de SoftwareDocumento24 páginasProvas Presenciais ESAB Engenharia de SoftwareVictor100% (1)
- AlgoritmoDocumento17 páginasAlgoritmoAnlaue sufoAinda não há avaliações
- Omie API Quick StartDocumento16 páginasOmie API Quick StartNelson GamaAinda não há avaliações
- Caixeiro ViajanteDocumento10 páginasCaixeiro ViajanteGabriel ChagasAinda não há avaliações
- Análise Comparativa Das Metodologias de Desenvolvimento de Softwares Tradicionais e ÁgeisDocumento74 páginasAnálise Comparativa Das Metodologias de Desenvolvimento de Softwares Tradicionais e ÁgeisAlmir Rivas100% (1)
- Estudo Experimental de Um Protótipo de Micro Geração de Energia Elétrica Nas Tubulações de Água PrediaisDocumento8 páginasEstudo Experimental de Um Protótipo de Micro Geração de Energia Elétrica Nas Tubulações de Água PrediaisengenheirojarmesonAinda não há avaliações
- Lista de Exercicios Pressao 1Documento6 páginasLista de Exercicios Pressao 1m23tt5Ainda não há avaliações
- Atividade Avaliativa Especial - Prova 2Documento3 páginasAtividade Avaliativa Especial - Prova 2José EvertonAinda não há avaliações
- Teste Conhecijento EstacioDocumento6 páginasTeste Conhecijento EstacioEduardo Vaz RibeiroAinda não há avaliações
- Pthreads em CDocumento20 páginasPthreads em CalmodenahAinda não há avaliações
- Estrutura de Dados - Si PDFDocumento3 páginasEstrutura de Dados - Si PDFizaiassbAinda não há avaliações
- Exercícios de Arquitetura de ComputadoresDocumento5 páginasExercícios de Arquitetura de ComputadoresDuarlem RobertoAinda não há avaliações
- Trabalho Redes 62 Questo EsDocumento11 páginasTrabalho Redes 62 Questo Es111babem100% (1)
- 4 - 1 Introducao Ao OpenDSSDocumento36 páginas4 - 1 Introducao Ao OpenDSSwillian teixeira olivioAinda não há avaliações
- Lista Arvores 2010Documento6 páginasLista Arvores 2010Gabriel BrunAinda não há avaliações
- Mapa - Teoria Das Estruturas II - 51-2024Documento5 páginasMapa - Teoria Das Estruturas II - 51-2024admcavaliniassessoriaAinda não há avaliações
- Tutorial PromodelDocumento31 páginasTutorial PromodelSara Katiuska HuamanAinda não há avaliações
- OctaveDocumento22 páginasOctaveLuana BarretoAinda não há avaliações
- Plano de Ensino Seminarios em Computacao - DCOMP/UFSDocumento7 páginasPlano de Ensino Seminarios em Computacao - DCOMP/UFSRogério Patrício Chagas Do NascimentoAinda não há avaliações
- Modelos de Parâmetros Concentrados e Distribuídos para Análise Térmica de Elementos Combustíveis ParticuladosDocumento173 páginasModelos de Parâmetros Concentrados e Distribuídos para Análise Térmica de Elementos Combustíveis ParticuladosrocguedesAinda não há avaliações
- Teoria Do Controle Moderno IIDocumento2 páginasTeoria Do Controle Moderno IIHenry HcAinda não há avaliações
- Algoritmo de Substituição de Páginas LRUDocumento2 páginasAlgoritmo de Substituição de Páginas LRUAJ Coostaa0% (1)
- QEMUDocumento2 páginasQEMUIvanilce MoraesAinda não há avaliações
- Especificacao de Requisitos v2.0Documento53 páginasEspecificacao de Requisitos v2.0Henrique DalpossoAinda não há avaliações
- Fot 13650aula 14-Exebcicios PDF Aula 14-ExerciciosDocumento2 páginasFot 13650aula 14-Exebcicios PDF Aula 14-ExerciciosJeydson Lopes da SilvaAinda não há avaliações
- Caixeiro ViajanteDocumento14 páginasCaixeiro ViajanteDiego MoahAinda não há avaliações
- Construção, Instrumentação, Identificação e Controle de Um Pêndulo Invertido RotatórioDocumento22 páginasConstrução, Instrumentação, Identificação e Controle de Um Pêndulo Invertido RotatórioEduardo Martins dos SantosAinda não há avaliações
- Aula 05 - SQL e MySQLDocumento101 páginasAula 05 - SQL e MySQLManuel BusinessAinda não há avaliações
- GTM30Documento9 páginasGTM30Marco Antonio Esquivel BarretoAinda não há avaliações
- Trabalho MinixDocumento26 páginasTrabalho MinixRicardo StepanskiAinda não há avaliações
- Modelo Plano Projeto de SW OODocumento6 páginasModelo Plano Projeto de SW OORogerio P C do NascimentoAinda não há avaliações
- Funcoes para Impressoras Termicas PDFDocumento13 páginasFuncoes para Impressoras Termicas PDFAnonymous m1U7o4ksCAinda não há avaliações
- CC297 Projeto 01Documento50 páginasCC297 Projeto 01Alexandre MedinaAinda não há avaliações
- Awd 12 H 31 o 2 HG 49 AsdDocumento169 páginasAwd 12 H 31 o 2 HG 49 AsdJ0urn3y GamerAinda não há avaliações
- Prova de Cálculo NuméricoDocumento2 páginasProva de Cálculo NuméricoFaruk WandersonAinda não há avaliações
- 2 - Capítulo 2 - Propriedades Termodinâmicas PDFDocumento22 páginas2 - Capítulo 2 - Propriedades Termodinâmicas PDFChristian StrobelAinda não há avaliações
- Respostas Esab Sistemas OperacionaisDocumento2 páginasRespostas Esab Sistemas OperacionaisKleiton ChagasAinda não há avaliações
- José AlmeidaDocumento23 páginasJosé AlmeidaPedro C. C. PimentaAinda não há avaliações
- Numerica PDFDocumento123 páginasNumerica PDFGil LeiteAinda não há avaliações
- 21 InteligenteDocumento24 páginas21 Inteligentecarlos augusto100% (1)
- Analise de Valor para A DeterminacaoDocumento6 páginasAnalise de Valor para A DeterminacaoGABRIEL BRAGAAinda não há avaliações
- Resumo Arqcomp 4.2 - 4.3Documento3 páginasResumo Arqcomp 4.2 - 4.3Ana LuisaAinda não há avaliações
- Atividade de ComputaçãoDocumento2 páginasAtividade de ComputaçãoKaique LimaAinda não há avaliações
- Lista08 HW de Memória (v02)Documento1 páginaLista08 HW de Memória (v02)DanieleValverdeAinda não há avaliações
- Topico6 - Sistema de Memória Organização e ArquiteturaDocumento29 páginasTopico6 - Sistema de Memória Organização e ArquiteturaIdagilson AmaralAinda não há avaliações
- Teste Do Capítulo 3 - Attempt ReviewDocumento6 páginasTeste Do Capítulo 3 - Attempt ReviewAlice CabralAinda não há avaliações
- Teste Do Capítulo 5 - Attempt ReviewDocumento5 páginasTeste Do Capítulo 5 - Attempt ReviewAlice CabralAinda não há avaliações
- Teste Do Capítulo 2 - Attempt ReviewDocumento6 páginasTeste Do Capítulo 2 - Attempt ReviewAlice CabralAinda não há avaliações
- Teste Do Capítulo 1 - Attempt ReviewDocumento6 páginasTeste Do Capítulo 1 - Attempt ReviewAlice CabralAinda não há avaliações
- Teste Do Capítulo 4 - Attempt ReviewDocumento6 páginasTeste Do Capítulo 4 - Attempt ReviewAlice Cabral100% (1)
- IA 4 PeriodoDocumento1 páginaIA 4 PeriodoAlice CabralAinda não há avaliações
- Implementa o de GrafosDocumento4 páginasImplementa o de GrafosAlice CabralAinda não há avaliações
- Grafos Trabalho 2Documento3 páginasGrafos Trabalho 2Alice CabralAinda não há avaliações
- IA Trabalho PR Tico Classifica o Homic Dios EUADocumento8 páginasIA Trabalho PR Tico Classifica o Homic Dios EUAAlice CabralAinda não há avaliações
- PAA Trabalho Ordena oDocumento6 páginasPAA Trabalho Ordena oAlice CabralAinda não há avaliações
- Redes I Automatic Network Slicing For IoT in Smart CityDocumento2 páginasRedes I Automatic Network Slicing For IoT in Smart CityAlice CabralAinda não há avaliações
- PAI Trabalho Diagn Stico de OsteoartriteDocumento7 páginasPAI Trabalho Diagn Stico de OsteoartriteAlice CabralAinda não há avaliações
- PAA Trabalho FinalDocumento6 páginasPAA Trabalho FinalAlice CabralAinda não há avaliações
- PAA Trabalho ExtraDocumento6 páginasPAA Trabalho ExtraAlice CabralAinda não há avaliações
- Metodologia de Reabilitação Fluvial IntegradaDocumento177 páginasMetodologia de Reabilitação Fluvial IntegradaDaniel OliveiraAinda não há avaliações
- Apostila de Administração Enfase em Departamento PessoalDocumento50 páginasApostila de Administração Enfase em Departamento Pessoalgabriela_saldan2552Ainda não há avaliações
- Bicicleta Estrada Triban 500Documento4 páginasBicicleta Estrada Triban 500Antonio Mendes0% (1)
- Organização e Disciplina No TrabalhoDocumento27 páginasOrganização e Disciplina No TrabalhoIuri Custodio100% (2)
- Primeira Lista 2021-01Documento2 páginasPrimeira Lista 2021-01Rodrigo MartinsAinda não há avaliações
- E-Book GRADIENT BOOSTINGDocumento36 páginasE-Book GRADIENT BOOSTINGDiogo Lima BarretoAinda não há avaliações
- Pi PR 034.2Documento1 páginaPi PR 034.2CHARLES FONSECAAinda não há avaliações
- Consequências Dos SemáforosDocumento2 páginasConsequências Dos SemáforosIsa SilvaAinda não há avaliações
- Almanaque MontemorDocumento27 páginasAlmanaque MontemorMaria DiasAinda não há avaliações
- E.r.9 Ano v3 - Cad 02.super - EnsinoDocumento22 páginasE.r.9 Ano v3 - Cad 02.super - EnsinoROSENILSON RODRIGUESAinda não há avaliações
- Como Produzir Conservas Que Não Estragam - Antonino PaixãoDocumento64 páginasComo Produzir Conservas Que Não Estragam - Antonino PaixãoJosemar SilvaAinda não há avaliações
- Avaliação Autismo em AdultoDocumento4 páginasAvaliação Autismo em AdultoAdriana Rubio WodewotzkiAinda não há avaliações
- Catalogo CorfioDocumento28 páginasCatalogo CorfioJoão MenegazAinda não há avaliações
- 1 Ano Quimica Da VidaDocumento24 páginas1 Ano Quimica Da VidaDaniel ViníciusAinda não há avaliações
- Manual Vassoura PDFDocumento20 páginasManual Vassoura PDFtiagopmoreira1982Ainda não há avaliações
- Gerenciamento de ProjetosDocumento94 páginasGerenciamento de ProjetosGustavoAinda não há avaliações
- Plano de Curso - Patrimonio, Memoria e Identidade - Versao FinalDocumento9 páginasPlano de Curso - Patrimonio, Memoria e Identidade - Versao FinalHermes De Sousa VerasAinda não há avaliações
- Habilidades para Uma Carreira de Sucesso Na EngenhariaDocumento5 páginasHabilidades para Uma Carreira de Sucesso Na EngenhariaAna Julia BicalhoAinda não há avaliações
- Plano 6 Ano GeoDocumento2 páginasPlano 6 Ano GeoELIANA DIAS DE SOUZAAinda não há avaliações
- Fagifor. FortalezaDocumento61 páginasFagifor. FortalezaMécia costaAinda não há avaliações
- Lista 1Documento6 páginasLista 1Ricardo de AlmeidaAinda não há avaliações
- PH 03Documento19 páginasPH 03MafefefesinhaAinda não há avaliações
- 10 - TransaçõesDocumento23 páginas10 - Transaçõeschiquim6Ainda não há avaliações
- Aula 1 - Logística e Cadeia de SuprimentosDocumento37 páginasAula 1 - Logística e Cadeia de SuprimentosEMANUEL_CHAVESAinda não há avaliações
- Descomplicando o Treino em Casa - 1 PDFDocumento125 páginasDescomplicando o Treino em Casa - 1 PDFAcauan RibeiroAinda não há avaliações
- AFRODITE DeusaDocumento20 páginasAFRODITE DeusaLopes Adriana100% (2)
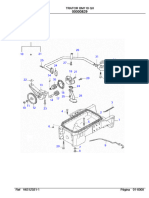
- Trator Trator Bm110 Bm110 Gii GIIDocumento2 páginasTrator Trator Bm110 Bm110 Gii GIIWashington SAinda não há avaliações
- Comportamento Do Consumidor - Questões-85Documento1 páginaComportamento Do Consumidor - Questões-85Allyf FerreiraAinda não há avaliações
- Gabarito - Volume 09Documento10 páginasGabarito - Volume 09gabytottidulliusAinda não há avaliações
- Phill Kotler: - Marketing Lateral E VerticalDocumento35 páginasPhill Kotler: - Marketing Lateral E VerticalMarcos ÁlvaresAinda não há avaliações
- Liberdade digital: O mais completo manual para empreender na internet e ter resultadosNo EverandLiberdade digital: O mais completo manual para empreender na internet e ter resultadosNota: 5 de 5 estrelas5/5 (10)
- Inteligência artificial: Como aprendizado de máquina, robótica e automação moldaram nossa sociedadeNo EverandInteligência artificial: Como aprendizado de máquina, robótica e automação moldaram nossa sociedadeNota: 5 de 5 estrelas5/5 (3)
- Inteligência artificial: O guia completo para iniciantes sobre o futuro da IANo EverandInteligência artificial: O guia completo para iniciantes sobre o futuro da IANota: 5 de 5 estrelas5/5 (6)
- Quero ser empreendedor, e agora?: Guia prático para criar sua primeira startupNo EverandQuero ser empreendedor, e agora?: Guia prático para criar sua primeira startupNota: 5 de 5 estrelas5/5 (26)
- 365 Ideias De Posts Para Ter Um Instagram De Sucesso!No Everand365 Ideias De Posts Para Ter Um Instagram De Sucesso!Ainda não há avaliações
- Análise técnica de uma forma simples: Como construir e interpretar gráficos de análise técnica para melhorar a sua actividade comercial onlineNo EverandAnálise técnica de uma forma simples: Como construir e interpretar gráficos de análise técnica para melhorar a sua actividade comercial onlineNota: 4 de 5 estrelas4/5 (4)
- Consultoria Especializada e Estratégias De Trade De ForexNo EverandConsultoria Especializada e Estratégias De Trade De ForexAinda não há avaliações
- IoT: Como Usar a "Internet Das Coisas" Para Alavancar Seus NegóciosNo EverandIoT: Como Usar a "Internet Das Coisas" Para Alavancar Seus NegóciosNota: 4 de 5 estrelas4/5 (2)
- Eletricista Residencial E PredialNo EverandEletricista Residencial E PredialNota: 3 de 5 estrelas3/5 (1)
- Gerenciamento da rotina do trabalho do dia-a-diaNo EverandGerenciamento da rotina do trabalho do dia-a-diaNota: 5 de 5 estrelas5/5 (2)
- Segurança Da Informação DescomplicadaNo EverandSegurança Da Informação DescomplicadaAinda não há avaliações
- 37 Regras para um Negócio Online de Sucesso: Como Desistir do Seu Emprego, Mudar Para o Paraíso e Ganhar Dinheiro Enquanto DormeNo Everand37 Regras para um Negócio Online de Sucesso: Como Desistir do Seu Emprego, Mudar Para o Paraíso e Ganhar Dinheiro Enquanto DormeNota: 1.5 de 5 estrelas1.5/5 (2)
- Modelos De Laudos Para Avaliação De Imóveis Urbanos E RuraisNo EverandModelos De Laudos Para Avaliação De Imóveis Urbanos E RuraisAinda não há avaliações
- Análise de Dados para Negócios: Torne-se um Mestre em Análise de DadosNo EverandAnálise de Dados para Negócios: Torne-se um Mestre em Análise de DadosAinda não há avaliações
- React Native: Desenvolvimento de aplicativos mobile com ReactNo EverandReact Native: Desenvolvimento de aplicativos mobile com ReactNota: 5 de 5 estrelas5/5 (1)
- A lógica do jogo: Recriando clássicos da história dos videogamesNo EverandA lógica do jogo: Recriando clássicos da história dos videogamesAinda não há avaliações