Você também pode gostar
- Sistemas operacionais de tempo real e sua aplicação em sistemas embarcadosNo EverandSistemas operacionais de tempo real e sua aplicação em sistemas embarcadosAinda não há avaliações
- Virtude Cibernética: Desafios Éticos E Morais Na Inteligência ArtificialNo EverandVirtude Cibernética: Desafios Éticos E Morais Na Inteligência ArtificialAinda não há avaliações
- Web SemânticaDocumento5 páginasWeb SemânticaJorge MateusAinda não há avaliações
- Introdução A Web SemânticaDocumento82 páginasIntrodução A Web SemânticaJoão Ferreira de Santanna Filho100% (1)
- O que é ciberespaçoDocumento7 páginasO que é ciberespaçoLoL SupremoAinda não há avaliações
- Robótica 2Documento13 páginasRobótica 2salomao lucio dos santos100% (1)
- Programação de CanSats e CubeSats com BIPESDocumento84 páginasProgramação de CanSats e CubeSats com BIPESJANA100% (1)
- Sociedade Da Informação - Sociedade Do ConhecimentoDocumento8 páginasSociedade Da Informação - Sociedade Do Conhecimentokennedy31Ainda não há avaliações
- Manual Do Kit CanSat Júnior v2.1Documento34 páginasManual Do Kit CanSat Júnior v2.1João Costa100% (1)
- O HOMEM NA ERA DIGITALDocumento14 páginasO HOMEM NA ERA DIGITALBeatriz Miranda100% (1)
- Manual Do Kit CanSat Júnior v1.2Documento34 páginasManual Do Kit CanSat Júnior v1.2Com Queda Prá Música100% (1)
- Trabalho Da CiberneticaDocumento13 páginasTrabalho Da CiberneticaMercia Aguas100% (1)
- Ebook PequenosSatelites Dez 2022Documento139 páginasEbook PequenosSatelites Dez 2022ELEANDRO MARQUES100% (1)
- Aula prática sobre propagação de ondas e sistemas de comunicação sem fioDocumento3 páginasAula prática sobre propagação de ondas e sistemas de comunicação sem fioLanguane100% (1)
- Antenas para TelecomunicaçõesDocumento21 páginasAntenas para TelecomunicaçõesEmanuel Francisco100% (1)
- Aula 02Documento53 páginasAula 02Luís Gustavo Almeida100% (1)
- Propagação de Ondas e Antenas na TroposferaDocumento4 páginasPropagação de Ondas e Antenas na TroposferaBorges Amilcar100% (1)
- Antenas de Ondas Longas e Médias2Documento48 páginasAntenas de Ondas Longas e Médias2Sobre tudo e menos nada100% (1)
- CansatDocumento15 páginasCansatHubble team CANSAT 2014100% (1)
- CiberculturaDocumento10 páginasCiberculturaPaola Rodrigues100% (2)
- PROJETO CANSAT 1 PesquisaDocumento5 páginasPROJETO CANSAT 1 PesquisaHubble team CANSAT 2014100% (1)
- Inteligência Artificial: da origem aos conceitos e linguagens de programaçãoDocumento6 páginasInteligência Artificial: da origem aos conceitos e linguagens de programaçãoThiago VelascoAinda não há avaliações
- Modelo ArtigoDocumento14 páginasModelo Artigoapi-26167728100% (1)
- Representações do Pós-Humano na InternetDocumento17 páginasRepresentações do Pós-Humano na InternetPatrick Cavalcante100% (1)
- O que é a Cibernética? Uma introdução à perspectiva interdisciplinarDocumento28 páginasO que é a Cibernética? Uma introdução à perspectiva interdisciplinarLucasAinda não há avaliações
- RUDIGER, Francisco. Teorias Da Cibercultura Perspectivas, Questões e Autores.Documento23 páginasRUDIGER, Francisco. Teorias Da Cibercultura Perspectivas, Questões e Autores.Mariane Nava100% (1)
- Web Semantica FuturoDocumento14 páginasWeb Semantica FuturoLuiz LanaAinda não há avaliações
- Origem Da CiberneticaDocumento11 páginasOrigem Da CiberneticaClaudia Gonzales100% (1)
- Caros Amigos Especial PóDocumento41 páginasCaros Amigos Especial PóGabriel Horn Iwaya100% (1)
- Sociedade Ciberespaço IsabellaDocumento11 páginasSociedade Ciberespaço IsabellaJosé Theobaldo Wendling100% (1)
- Porfírio Silva, A Cibernética - Onde Os Reinos Se FundemDocumento144 páginasPorfírio Silva, A Cibernética - Onde Os Reinos Se Fundemespeculativa100% (2)
- Antenas Propagação 40Documento124 páginasAntenas Propagação 40Gilvan Duarte100% (1)
- Curso Completo sobre Redes VSATDocumento19 páginasCurso Completo sobre Redes VSATteste100% (1)
- Ciberespaço PDFDocumento15 páginasCiberespaço PDFMariana GuedesAinda não há avaliações
- Cansat PDFDocumento9 páginasCansat PDFHubble team CANSAT 2014100% (1)
- Resenha - Sociedade Midiatizada PDFDocumento4 páginasResenha - Sociedade Midiatizada PDFZalikkaAinda não há avaliações
- A Informação Após A Virada CibernéticaDocumento21 páginasA Informação Após A Virada CibernéticaJoaoAinda não há avaliações
- Stockinger Gottfried Teoria Sociologica ComunicacaoDocumento218 páginasStockinger Gottfried Teoria Sociologica ComunicacaoclaudioimperadorAinda não há avaliações
- Introdução à CiberculturaDocumento27 páginasIntrodução à CiberculturaValdecy Moreira100% (1)
- A Importância Das Telecomunicações e Das Novas TecnologiasDocumento4 páginasA Importância Das Telecomunicações e Das Novas TecnologiasMericia GouveiaAinda não há avaliações
- Fundamentos Redes Computadores PB Capa 20100729 ISBNDocumento50 páginasFundamentos Redes Computadores PB Capa 20100729 ISBNSávio FelipeAinda não há avaliações
- A produção do conhecimento em redes sociais na era digitalDocumento8 páginasA produção do conhecimento em redes sociais na era digitalRegiane LauraAinda não há avaliações
- O termo ciberespaço na literatura, ciência e filosofiaDocumento21 páginasO termo ciberespaço na literatura, ciência e filosofiaJoão PauloAinda não há avaliações
- IA: Conceitos e AplicaçõesDocumento14 páginasIA: Conceitos e AplicaçõesRodrigo MartinsAinda não há avaliações
- Cibersegurança e Os Ataques CibernéticosDocumento6 páginasCibersegurança e Os Ataques CibernéticosArthemis LacroutAinda não há avaliações
- MetaversoDocumento8 páginasMetaversodouglas fernandesAinda não há avaliações
- Propagaao de Ondas e Antenas Profdr Leonardo Lorenzo Bravo Roger PDF FreeDocumento10 páginasPropagaao de Ondas e Antenas Profdr Leonardo Lorenzo Bravo Roger PDF FreeLanguane100% (1)
- Comunicações Móveis 6GDocumento32 páginasComunicações Móveis 6GRodrigo Facco100% (1)
- Internet Das CoisasDocumento38 páginasInternet Das CoisasRM Empreendimentos100% (1)
- Escola de Hackers Nivel 2A Redes I PDFDocumento216 páginasEscola de Hackers Nivel 2A Redes I PDFalddannenAinda não há avaliações
- Definições fundamentais de parâmetros de antenasDocumento15 páginasDefinições fundamentais de parâmetros de antenasbm1au100% (1)
- Internet das Coisas: Tecnologias e AplicaçõesDocumento7 páginasInternet das Coisas: Tecnologias e AplicaçõesAna Paula DallegraveAinda não há avaliações
- Telefonia - Parte 1Documento123 páginasTelefonia - Parte 1PauloAinda não há avaliações
- Trabalho de TelecomunicaçõesDocumento14 páginasTrabalho de TelecomunicaçõesLeandro Gielow FerroAinda não há avaliações
- CIBERANTROPOLOGIADocumento22 páginasCIBERANTROPOLOGIAMaristela GuimarãesAinda não há avaliações
- EmailefaceDocumento391 páginasEmailefacekatiahvcAinda não há avaliações
- Aula 08 Redes WirelessDocumento30 páginasAula 08 Redes WirelesscleinhaAinda não há avaliações
- Joins Banco DadosDocumento2 páginasJoins Banco DadostcriccoAinda não há avaliações
- Resumo Progressões AritméticasDocumento2 páginasResumo Progressões AritméticasGilcineyJardimAinda não há avaliações
- Sistema de Injeção Rochester EFI MULTEC 700Documento7 páginasSistema de Injeção Rochester EFI MULTEC 700silvio ortizAinda não há avaliações
- Mapa - Pesquisa Operacional - 51-2024Documento3 páginasMapa - Pesquisa Operacional - 51-2024admcavaliniassessoriaAinda não há avaliações
- Fundamentos dos fluidos de perfuração: classificação e conceitos-chave de sistemas dispersosDocumento122 páginasFundamentos dos fluidos de perfuração: classificação e conceitos-chave de sistemas dispersosValécia Dantas100% (2)
- Manual do DesenvolvedorDocumento52 páginasManual do DesenvolvedorDihego CostaAinda não há avaliações
- Exercícios de Física sobre Forças e MovimentoDocumento16 páginasExercícios de Física sobre Forças e MovimentoMendelça Da Vinci Bartolomeu0% (1)
- Aerodinâmica comentada ANACDocumento14 páginasAerodinâmica comentada ANACdutifrancaAinda não há avaliações
- Centro Baiano de Computação de Alto DesempenhoDocumento70 páginasCentro Baiano de Computação de Alto DesempenhoGeronimo AmaralAinda não há avaliações
- Campo Mourao 2009 ADocumento126 páginasCampo Mourao 2009 AAlessandre OliveiraAinda não há avaliações
- Combatente - Raciocínio Lógico - Módulo 02 - Proposições e ConectivosDocumento6 páginasCombatente - Raciocínio Lógico - Módulo 02 - Proposições e Conectivoscarloscharles1210Ainda não há avaliações
- Artigo 433Documento10 páginasArtigo 433AnnaAinda não há avaliações
- Verão Matemática 2017Documento9 páginasVerão Matemática 2017Wat handsAinda não há avaliações
- Simulado Eear I 2011Documento6 páginasSimulado Eear I 2011Pedro Henrique MachadoAinda não há avaliações
- Manual de Informática básica com foco no Microsoft Office 2007Documento66 páginasManual de Informática básica com foco no Microsoft Office 2007Cheveia100% (1)
- Automação na fundição sob pressãoDocumento13 páginasAutomação na fundição sob pressãoJuliana OliveiraAinda não há avaliações
- Mapa Cotação-20-12Documento2 páginasMapa Cotação-20-12Euclecio MoreiraAinda não há avaliações
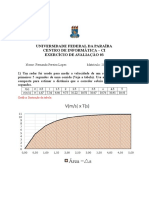
- Estimando distância com regra de SimpsonDocumento5 páginasEstimando distância com regra de SimpsonFernanda LopesAinda não há avaliações
- MODELODocumento2 páginasMODELOmbsarmento1Ainda não há avaliações
- Pirólise de PequiDocumento72 páginasPirólise de PequiIara SilveiraAinda não há avaliações
- CT-0460 - SRP 4075E Flex - 2021-08 - (Trilingue) - REV.004Documento24 páginasCT-0460 - SRP 4075E Flex - 2021-08 - (Trilingue) - REV.004André DavidAinda não há avaliações
- Manual de Piloto PrivadoDocumento106 páginasManual de Piloto PrivadoRodrigo Cesar RighiAinda não há avaliações
- Ger Proc - Escalonamento de ProcessosDocumento36 páginasGer Proc - Escalonamento de ProcessosDiego AraújoAinda não há avaliações
- 2 POSTAGEM - MA - 6º AnoDocumento4 páginas2 POSTAGEM - MA - 6º AnoCida NorbertoAinda não há avaliações
- Como Fazer Queijo GorgonzolaDocumento4 páginasComo Fazer Queijo GorgonzolaRoberta SabinoAinda não há avaliações
- 03 Apostila Versao Digital Raciocinio Logico Atualizada 002.575.571!48!1645656821Documento134 páginas03 Apostila Versao Digital Raciocinio Logico Atualizada 002.575.571!48!1645656821jucilene DantasAinda não há avaliações
- Gabarito - Aulas5 6 8Documento50 páginasGabarito - Aulas5 6 8Tarso RezendeAinda não há avaliações
- Catalogo Rapido CAT 924KDocumento61 páginasCatalogo Rapido CAT 924KEvandro100% (1)
- Modelo de Avaliação BimestralDocumento1 páginaModelo de Avaliação BimestralLucas MarcelinoAinda não há avaliações
- Vida e Matematica 6 AnoDocumento11 páginasVida e Matematica 6 AnoJoão Ricardo Chiodi100% (1)