Você também pode gostar
- BFPDocumento12 páginasBFPMarcosXimenes78% (9)
- 10 Passos para Sair Das Dívidas PDFDocumento22 páginas10 Passos para Sair Das Dívidas PDFDaniele MarimAinda não há avaliações
- Modulo de Resistencia Tubo RedondoDocumento7 páginasModulo de Resistencia Tubo RedondoJoao DinizAinda não há avaliações
- SCL 90RDocumento7 páginasSCL 90RNaniberto80% (10)
- ABC de UmbandaDocumento8 páginasABC de UmbandaMarcio Reinaldo Friedrich Costa100% (1)
- Psicanálise e NeurocienciaDocumento10 páginasPsicanálise e NeurocienciaJoelton NascimentoAinda não há avaliações
- Cruzadinha de História - O Começo Da HistóriaDocumento4 páginasCruzadinha de História - O Começo Da HistóriaMary Alvarenga100% (3)
- Álvaro de Campos 12anoDocumento7 páginasÁlvaro de Campos 12anoTania MariaAinda não há avaliações
- Consciência e Verdade - Cardeal Joseph RatzingerDocumento6 páginasConsciência e Verdade - Cardeal Joseph RatzingerAntônio LucasAinda não há avaliações
- 3 (29-09) A Antropologia Económica, Maurice Godelier - P. 161-186Documento18 páginas3 (29-09) A Antropologia Económica, Maurice Godelier - P. 161-186Raphael T. Sprenger100% (2)
- Gnosis Dissidente - Raízes Caucasianas, A Verdadeira Origem EgípciaDocumento11 páginasGnosis Dissidente - Raízes Caucasianas, A Verdadeira Origem EgípciaAlexandre ApoloAinda não há avaliações
- Psicologia Da EducaçãoDocumento29 páginasPsicologia Da EducaçãoClaudson Cerqueira Santana100% (1)
- Cartilha Autocuidado PDFDocumento21 páginasCartilha Autocuidado PDFceila100% (1)
- Sequência Didática Meio Ambiente A Menina Que DesenhavaDocumento2 páginasSequência Didática Meio Ambiente A Menina Que DesenhavaSilvania Pires De Oliveira AraujoAinda não há avaliações
- Variograma (Geoestatística)Documento32 páginasVariograma (Geoestatística)Thális FelipeAinda não há avaliações
- Planilha para Calculo de Engrenagens ConicasDocumento18 páginasPlanilha para Calculo de Engrenagens ConicasandrelorandiAinda não há avaliações
- Cálculo Vazões - Fernanda e GabrielaDocumento4 páginasCálculo Vazões - Fernanda e GabrielaGabriela Nunes AndradeAinda não há avaliações
- Metodo de Picos ConsecutivosDocumento3 páginasMetodo de Picos ConsecutivosGilberto Romão TsamboAinda não há avaliações
- Exo 62 Page 79Documento4 páginasExo 62 Page 79Belabbas mustaphaAinda não há avaliações
- Catalogo Tecnico Cabelauto Cabos MT MVR105 e MVX90Documento37 páginasCatalogo Tecnico Cabelauto Cabos MT MVR105 e MVX90Francisco E.Ainda não há avaliações
- WurthDocumento2 páginasWurthQuezia PereiraAinda não há avaliações
- Catálogo Técnico Cabos MT MVR90 Cobre e Aluminio - CABELAUTODocumento20 páginasCatálogo Técnico Cabos MT MVR90 Cobre e Aluminio - CABELAUTOFrancisco E.Ainda não há avaliações
- Introdução Ao Livro, Panim Meirot U MasbirotDocumento3 páginasIntrodução Ao Livro, Panim Meirot U MasbirotEdmo Edmo Edmo0% (1)
- Lista de RoscasDocumento1 páginaLista de RoscasWillian TrindadeAinda não há avaliações
- Lista 3 - Exercícios Sobre Regressão LinearDocumento6 páginasLista 3 - Exercícios Sobre Regressão LinearFabio QueirozAinda não há avaliações
- Tabela Rompimento Solo Cimento CocoDocumento2 páginasTabela Rompimento Solo Cimento CocoGustavo Pereira JorgeAinda não há avaliações
- Importacao Exportacao - Portugal PALOPsDocumento3 páginasImportacao Exportacao - Portugal PALOPsEmanuel SpencerAinda não há avaliações
- Catalogo Smart Jet FinalDocumento2 páginasCatalogo Smart Jet FinalCarlos SaboiaAinda não há avaliações
- Anatoly Olimpio Luis ValenteDocumento12 páginasAnatoly Olimpio Luis ValenteUssene AbudoAinda não há avaliações
- Matriz de Kraljic - Case Setor FarmaceuticoDocumento4 páginasMatriz de Kraljic - Case Setor Farmaceuticorafael.assecchiAinda não há avaliações
- Valores Normais Do Comprimento Do FemurDocumento2 páginasValores Normais Do Comprimento Do FemurPattyNorrisAinda não há avaliações
- Pré DimensionamentosDocumento6 páginasPré DimensionamentosRICARDO MOTELEWICZAinda não há avaliações
- Tabelas de UPs (Mágico)Documento9 páginasTabelas de UPs (Mágico)Vitor HugoAinda não há avaliações
- Orçamentaria DCAD ElétricoDocumento10 páginasOrçamentaria DCAD Elétricokledson luis oliveira gomesAinda não há avaliações
- Conduspar - Flex HEPR 1kVDocumento3 páginasConduspar - Flex HEPR 1kVchmatias3Ainda não há avaliações
- Depreciação Utilizando A Tabela RossDocumento2 páginasDepreciação Utilizando A Tabela RossVandoir GoncalvesAinda não há avaliações
- BioestDocumento10 páginasBioestkarolinyAinda não há avaliações
- Tabela Rompimento Solo Cimento ArrozDocumento2 páginasTabela Rompimento Solo Cimento ArrozGustavo Pereira JorgeAinda não há avaliações
- Dimensionamento de Tubos RevestidosDocumento3 páginasDimensionamento de Tubos RevestidosTathiane FerreiraAinda não há avaliações
- Exercício Previsão de Demanda 1Documento4 páginasExercício Previsão de Demanda 1CamilaAinda não há avaliações
- Exemplo MDFDocumento13 páginasExemplo MDFkucomkAinda não há avaliações
- Tabela de Arraçomento para Acompanhamento de Desenvolvimento ZootecnicoDocumento6 páginasTabela de Arraçomento para Acompanhamento de Desenvolvimento ZootecnicoSolarAinda não há avaliações
- Do Enc As Respirator I As CronicasDocumento158 páginasDo Enc As Respirator I As CronicasMeury SouzaAinda não há avaliações
- Alvenius Tabela Dimensional e Propriedades FisicasDocumento2 páginasAlvenius Tabela Dimensional e Propriedades FisicasMauricio Rodrigues FernandesAinda não há avaliações
- Mapa PCP 54-2022Documento11 páginasMapa PCP 54-2022Renato PasquotoAinda não há avaliações
- Planilha Aula 6Documento17 páginasPlanilha Aula 6Lohanny RodriguesAinda não há avaliações
- Catalogo - Linha de Contatores AX - Portugues PDFDocumento112 páginasCatalogo - Linha de Contatores AX - Portugues PDFNuno HenriquesAinda não há avaliações
- 1av EstatísticaDocumento11 páginas1av EstatísticaGisele BragaAinda não há avaliações
- Coeficiente de Recalque Vertical, KVDocumento1 páginaCoeficiente de Recalque Vertical, KVNaldinho MonteiroAinda não há avaliações
- Estudo Dirigido Revisao P2-12022Documento19 páginasEstudo Dirigido Revisao P2-12022Cecília UsaiAinda não há avaliações
- Fichas TecnicasDocumento1 páginaFichas Tecnicasmarijo707Ainda não há avaliações
- Programa Nutricional Viveiro - TilápiaDocumento5 páginasPrograma Nutricional Viveiro - TilápialuizdaaopAinda não há avaliações
- Medição 14 - Consórcio Saraiva Rv1Documento9 páginasMedição 14 - Consórcio Saraiva Rv1Gabriel PralonAinda não há avaliações
- Atividade Avaliativa 6Documento13 páginasAtividade Avaliativa 6MARLON ANDRÉ MARQUES MOREIRAAinda não há avaliações
- 02 - Alta Garden - EsquadriasDocumento5 páginas02 - Alta Garden - EsquadriasJarbas PereiraAinda não há avaliações
- Area Barra Redonda PinturaDocumento3 páginasArea Barra Redonda PinturaDirceu Éwerton Costa MaiaAinda não há avaliações
- LIVRO THOMAS AGUA MINERAL DEMANDA Exercício 1 Economia AmbientalDocumento7 páginasLIVRO THOMAS AGUA MINERAL DEMANDA Exercício 1 Economia AmbientalElizangela BeckmannAinda não há avaliações
- Atividade 1Documento21 páginasAtividade 1Rafael SantosAinda não há avaliações
- WordfisicaDocumento3 páginasWordfisicajackson vilellaAinda não há avaliações
- Cálculo de Notas para A Prova Final - 2022Documento2 páginasCálculo de Notas para A Prova Final - 2022Waldenir GramsAinda não há avaliações
- Curva de AquecimentoDocumento3 páginasCurva de AquecimentoMaytê MachadoAinda não há avaliações
- Caso MurphyDocumento4 páginasCaso Murphykarla_palomino_6Ainda não há avaliações
- Tabela SEGER R$ 4.315,00Documento1 páginaTabela SEGER R$ 4.315,00Bernardo SoneghetAinda não há avaliações
- DCP 30-05 - Alterosa Pagina 2Documento1 páginaDCP 30-05 - Alterosa Pagina 2Lucas SinoAinda não há avaliações
- Diario - Classe PRO 120 23 2Documento2 páginasDiario - Classe PRO 120 23 2laurab.rodrigues26Ainda não há avaliações
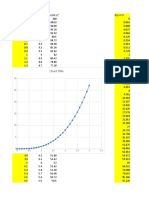
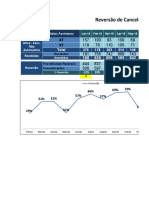
- Analise de Cancelamentos e Renovações - 12 MesesDocumento1.373 páginasAnalise de Cancelamentos e Renovações - 12 MesesDanilo RomãoAinda não há avaliações
- Pasta 1Documento2 páginasPasta 1denilson carvalho guimaraesAinda não há avaliações
- Mat 7 Teste 2 R EENDocumento8 páginasMat 7 Teste 2 R EENMax de CarvalhoAinda não há avaliações
- Tubos QuadradosDocumento2 páginasTubos QuadradosGilmar Boeira Da SilvaAinda não há avaliações
- Análise Do Enem (2009 - 2023)Documento3 páginasAnálise Do Enem (2009 - 2023)Samuel HolandaAinda não há avaliações
- Cartilha Engenharia de Producao 2021Documento35 páginasCartilha Engenharia de Producao 2021Vinicius Zenatti SerilloAinda não há avaliações
- Relógio Parede 6468 084 Herweg Moderno - Google ShoppingDocumento2 páginasRelógio Parede 6468 084 Herweg Moderno - Google ShoppingceilaAinda não há avaliações
- Psicopatologia Da Infância e Da AdolescênciaDocumento8 páginasPsicopatologia Da Infância e Da AdolescênciaceilaAinda não há avaliações
- Streaming 21-22 2Documento1 páginaStreaming 21-22 2ceilaAinda não há avaliações
- Diario Ed1777 03-09Documento10 páginasDiario Ed1777 03-09ceilaAinda não há avaliações
- 300 Perguntas e Respostas Sobre A MaçonariaDocumento34 páginas300 Perguntas e Respostas Sobre A MaçonariaCarlosAlexandreAinda não há avaliações
- Filosofia e Filosofia Da EducaçãoDocumento3 páginasFilosofia e Filosofia Da EducaçãoLucas Emanoel0% (1)
- Resumo-Livro - Extensão Ou Comunicação Paulo FreireDocumento2 páginasResumo-Livro - Extensão Ou Comunicação Paulo FreireAlexandre Damaceno67% (3)
- A Cor Como Linguagem - Da Fisiologia À CulturaDocumento3 páginasA Cor Como Linguagem - Da Fisiologia À CulturaNaiara RochaAinda não há avaliações
- Atlas Linguistico Do Estado de Minas Gerais PDFDocumento13 páginasAtlas Linguistico Do Estado de Minas Gerais PDFLUCIANA244Ainda não há avaliações
- Geografia Conceitos e Temas, Iná de CastroDocumento4 páginasGeografia Conceitos e Temas, Iná de CastroMarcinha AlvesAinda não há avaliações
- 7717 27171 2 PBDocumento147 páginas7717 27171 2 PBVerônica G. BrandãoAinda não há avaliações
- Relatório de Análise - Desligamentos Forçados - Edição 2016Documento347 páginasRelatório de Análise - Desligamentos Forçados - Edição 2016Andresa LemesAinda não há avaliações
- A Concepção de Cidade em Diferentes Matrizes Teóricas Das Ciências SociaisDocumento10 páginasA Concepção de Cidade em Diferentes Matrizes Teóricas Das Ciências SociaisplataomacAinda não há avaliações
- Marginais Evel RochaDocumento6 páginasMarginais Evel RochaAnderson Santana100% (1)
- O Que É Espanhol InstrumentalDocumento3 páginasO Que É Espanhol InstrumentalrafinhamachadooAinda não há avaliações
- Ócio CriativoDocumento3 páginasÓcio CriativoCarlos Roberto de CastroAinda não há avaliações
- Modelo de Relatório de Visita Técnica PDFDocumento2 páginasModelo de Relatório de Visita Técnica PDFVivaldo de Albuquerque PintoAinda não há avaliações
- Resumo Livro PerrenoudDocumento5 páginasResumo Livro Perrenoudangela_oreentreacaoAinda não há avaliações
- A Dança Como Prevenção e Tratamento Da Depressão Na Terceira IdadeDocumento1 páginaA Dança Como Prevenção e Tratamento Da Depressão Na Terceira Idadefernando tortelliAinda não há avaliações
- Wa0002 PDFDocumento169 páginasWa0002 PDFAlisson UrsulinoAinda não há avaliações
- Concurso Prefeitura Cascalho RicoDocumento48 páginasConcurso Prefeitura Cascalho RicoErika AmaralAinda não há avaliações
- O Direito À Memória Familiar - Olga Von SimsomDocumento6 páginasO Direito À Memória Familiar - Olga Von SimsomRicardo LuizAinda não há avaliações
- Resenha Filme o Ovo Da SerpenteDocumento5 páginasResenha Filme o Ovo Da SerpenteHanna Helena100% (1)