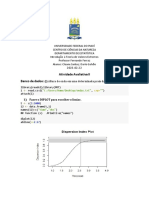
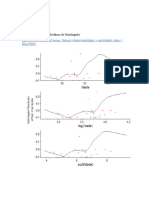
Você também pode gostar
- Monitorando Através Do Visual Basic O Decibelímetro Com O Stm32f103c8 Programado No ArduinoNo EverandMonitorando Através Do Visual Basic O Decibelímetro Com O Stm32f103c8 Programado No ArduinoAinda não há avaliações
- Aula 4 PoeDocumento34 páginasAula 4 PoeTM MarketingAinda não há avaliações
- Manual Stata PDFDocumento16 páginasManual Stata PDFMarceloShinAinda não há avaliações
- Relatorio Fisica Exp 1 Experimento A4Documento10 páginasRelatorio Fisica Exp 1 Experimento A4Thiago DevilartAinda não há avaliações
- Capítulo 1 Experimentos Fatoriais Completamente Cruzados Gerais - Controle de Processos IndustriaisDocumento28 páginasCapítulo 1 Experimentos Fatoriais Completamente Cruzados Gerais - Controle de Processos IndustriaisBreno Benvindo Dos AnjosAinda não há avaliações
- Exercício Aula 3 RespostaDocumento9 páginasExercício Aula 3 RespostaPedro Canassa100% (1)
- Relatório 1 Absenteeism at Work-1 PDFDocumento12 páginasRelatório 1 Absenteeism at Work-1 PDFFrancisco PinhoAinda não há avaliações
- Cartas de Controle para Soma AcumuladaDocumento20 páginasCartas de Controle para Soma AcumuladaJOAO BATISTA DE AZEVEDO JRAinda não há avaliações
- Apostila - Parte IIDocumento6 páginasApostila - Parte IIEdison RibasAinda não há avaliações
- Análise Dos Dados - Estatística e ProbabilidadesDocumento6 páginasAnálise Dos Dados - Estatística e Probabilidadesmigas.as.ferreira23Ainda não há avaliações
- Exercícios Resolvidos de Análise de SobrevivênciaDocumento13 páginasExercícios Resolvidos de Análise de SobrevivênciaFrancisco Huemerson de Sousa Pinto100% (1)
- Regressão Linear - 2023Documento29 páginasRegressão Linear - 2023Maria Clara TavaresAinda não há avaliações
- Método de Adams-Bashford e Adams-MoultonDocumento16 páginasMétodo de Adams-Bashford e Adams-Moultondsmxcbn8w5Ainda não há avaliações
- Dados em Painel (Análise)Documento31 páginasDados em Painel (Análise)Lucian MaxAinda não há avaliações
- Lista de Exercícios de Probabilidade PDFDocumento12 páginasLista de Exercícios de Probabilidade PDFRandy Ambrósio QjAinda não há avaliações
- Relatório Experimento 4Documento5 páginasRelatório Experimento 4Eduarda LealAinda não há avaliações
- Lista 2 So Meu GLMDocumento3 páginasLista 2 So Meu GLMMariana AnçaAinda não há avaliações
- Distribuição Exponencial - Método GráficoDocumento8 páginasDistribuição Exponencial - Método GráficoMarco Antônio SabaráAinda não há avaliações
- 11 - Papel de WeibullDocumento25 páginas11 - Papel de WeibullGildevan JefterAinda não há avaliações
- Segundo Trabalho Valores ExtremosDocumento5 páginasSegundo Trabalho Valores ExtremosDario GalvaoAinda não há avaliações
- Proje To Control e FinalDocumento12 páginasProje To Control e FinalGfyy TsukakushiAinda não há avaliações
- Apostila Introd Quimiometria - Aulas PraticasDocumento15 páginasApostila Introd Quimiometria - Aulas PraticasRafaelAinda não há avaliações
- Segundo Trabalho de Campo Da Disciplina de Estatística Curso de Administração Pública - 1° AnoDocumento13 páginasSegundo Trabalho de Campo Da Disciplina de Estatística Curso de Administração Pública - 1° AnoMarcelo XariaAinda não há avaliações
- Trabalho de Estatistica DescritivaDocumento3 páginasTrabalho de Estatistica DescritivaAntonio Fernando DomingosAinda não há avaliações
- Teste LaplaceDocumento25 páginasTeste LaplaceFábio SoaresAinda não há avaliações
- 2 A Avaliacao Estatistica PesqueiraDocumento4 páginas2 A Avaliacao Estatistica PesqueiraRICARDO MATOS PEREIRAAinda não há avaliações
- Modelo Relatorio Tempos e Metodos - 2024 2Documento4 páginasModelo Relatorio Tempos e Metodos - 2024 2Julia RamosAinda não há avaliações
- Relatorio 03-Leis de KirchhoffDocumento9 páginasRelatorio 03-Leis de KirchhoffJoão Victor Azevedo GonçalvesAinda não há avaliações
- Exercicio CalibracaoDocumento5 páginasExercicio CalibracaoStefany Yumie KawashimaAinda não há avaliações
- Trabalho de Estatistica - Armando 2023Documento14 páginasTrabalho de Estatistica - Armando 2023Paulo MessoAinda não há avaliações
- 2021 PER 3 P 3 OficialDocumento7 páginas2021 PER 3 P 3 OficialLuan MunizAinda não há avaliações
- Benyb AsDocumento15 páginasBenyb AsVénydo DunheAinda não há avaliações
- 1) Sejam Y Vendas de Uma Loja, X1 Vendas Da Equipe de Vendedores Externos X2 Número de Visitas Realizadas Pelos Vendedores.Documento8 páginas1) Sejam Y Vendas de Uma Loja, X1 Vendas Da Equipe de Vendedores Externos X2 Número de Visitas Realizadas Pelos Vendedores.Jhenifer SpliethoffAinda não há avaliações
- Relatório - ERRO ALEATÓRIODocumento8 páginasRelatório - ERRO ALEATÓRIOCleyber Moura da SilvaAinda não há avaliações
- Análises Do Ifr2Documento9 páginasAnálises Do Ifr2Rui V. JoaquimAinda não há avaliações
- Trabalho 02Documento4 páginasTrabalho 02douglasncamiloAinda não há avaliações
- Relatório 1a Aula - 6Documento17 páginasRelatório 1a Aula - 6Caio Eduardo Silva33% (3)
- Estatistica VictorinoDocumento10 páginasEstatistica VictorinoSabio Maria JulioAinda não há avaliações
- Relatorio01 - Alexandre, Luana e Nathália - Turma DDocumento10 páginasRelatorio01 - Alexandre, Luana e Nathália - Turma DAna CarmoAinda não há avaliações
- Trabalho 2 Transcal ERE2Documento8 páginasTrabalho 2 Transcal ERE2Dionéia BertolettiAinda não há avaliações
- At 05Documento4 páginasAt 05Leandro AlmeidaAinda não há avaliações
- Mae (Estatistica)Documento11 páginasMae (Estatistica)AbmamudalziraAinda não há avaliações
- Resolução Lista 2 EQ651 - 2S - 2023Documento9 páginasResolução Lista 2 EQ651 - 2S - 2023larissatsukamotoAinda não há avaliações
- Atividade - MÉTODO DO GRAU DE ATENDIMENTO DEFINIDO PDFDocumento3 páginasAtividade - MÉTODO DO GRAU DE ATENDIMENTO DEFINIDO PDFÜlíô LímáAinda não há avaliações
- TPC2 - EconometriaDocumento8 páginasTPC2 - EconometriaEgas DanielAinda não há avaliações
- RNA EPC-PMC Classificacao PadraoDocumento6 páginasRNA EPC-PMC Classificacao PadraoGustavo Fortes novackAinda não há avaliações
- Mistura Binária de Diisopropílico Éter (1) e Álcool N-Propílico (2) .Documento8 páginasMistura Binária de Diisopropílico Éter (1) e Álcool N-Propílico (2) .MARIANA DA SILVA MELOAinda não há avaliações
- Alex ExpermentacaoDocumento6 páginasAlex ExpermentacaoAltino LucasAinda não há avaliações
- Teste de Transformador GERMANDocumento5 páginasTeste de Transformador GERMANSilvio Ricardo RibeiroAinda não há avaliações
- Relatório 5 - Ensaio CBR - Ìndice de Suporte CalifórniaDocumento8 páginasRelatório 5 - Ensaio CBR - Ìndice de Suporte CalifórniaPolyana PontesAinda não há avaliações
- Ad1 2017 - 2 PDFDocumento8 páginasAd1 2017 - 2 PDFCíntia AparecidaAinda não há avaliações
- Unidade 1Documento52 páginasUnidade 1Leonardo AsevedoAinda não há avaliações
- Thays ExpDocumento3 páginasThays ExpThaysAinda não há avaliações
- Relatorio Termopar REVISADO E COM TABELAS FINALDocumento14 páginasRelatorio Termopar REVISADO E COM TABELAS FINALFlavio_H_BAinda não há avaliações
- Métodos de Regressão KernelDocumento5 páginasMétodos de Regressão KernelalbaroAinda não há avaliações
- Tutorial Sequencia para Testes de Rele 7UT No Software MICROPROCDocumento10 páginasTutorial Sequencia para Testes de Rele 7UT No Software MICROPROCJhonatan TerraAinda não há avaliações
- Relatório Laboratório de Fisíca PDFDocumento9 páginasRelatório Laboratório de Fisíca PDFJuliana MoraesAinda não há avaliações
- MedidasdetempoDocumento4 páginasMedidasdetempoJulia BzrrAinda não há avaliações
- Practica Calificada 3aDocumento11 páginasPractica Calificada 3aIvan FernandezAinda não há avaliações
- Relatório OscilaçõesDocumento8 páginasRelatório OscilaçõesMATHEUS DA SILVA RODRIGUESAinda não há avaliações
- PHD Thesis Jorge Miguel BravoDocumento592 páginasPHD Thesis Jorge Miguel BravoGustavo GuerraAinda não há avaliações
- Modelos Mistos Lineares em Análise de Dados Longitudinais em Genótipos de Feijão VagemDocumento108 páginasModelos Mistos Lineares em Análise de Dados Longitudinais em Genótipos de Feijão VagemGustavo GuerraAinda não há avaliações
- 121879-Texto Do Artigo-267994-1-10-20170921Documento21 páginas121879-Texto Do Artigo-267994-1-10-20170921Gustavo GuerraAinda não há avaliações
- Me Strado Alexandra BorgesDocumento78 páginasMe Strado Alexandra BorgesGustavo GuerraAinda não há avaliações
- Modelos - Lineares Versao3.6Documento128 páginasModelos - Lineares Versao3.6Ana Paula BertãoAinda não há avaliações
- Apresenta o Cap 7Documento39 páginasApresenta o Cap 7Gustavo GuerraAinda não há avaliações
- Modelagem Hidrologica Deterministica e EstocasticaDocumento16 páginasModelagem Hidrologica Deterministica e EstocasticaGustavo GuerraAinda não há avaliações
- Apresenta o Cap 7Documento39 páginasApresenta o Cap 7Gustavo GuerraAinda não há avaliações
- 1 PB PDFDocumento26 páginas1 PB PDFJosevandro Chagas SoaresAinda não há avaliações
- 17394716022012matematica para o Ensino Fundamental Aula 4Documento10 páginas17394716022012matematica para o Ensino Fundamental Aula 4Gustavo GuerraAinda não há avaliações
- Aula 7 - O Que Poderia Significar A Educação Matemática Crítica para Diferentes Grupos de EstudantesDocumento20 páginasAula 7 - O Que Poderia Significar A Educação Matemática Crítica para Diferentes Grupos de EstudantesGustavo GuerraAinda não há avaliações
- Desenho Geometrico 1Documento32 páginasDesenho Geometrico 1eliseu5Ainda não há avaliações
- Apostila Construções Geometricas PDFDocumento200 páginasApostila Construções Geometricas PDFMário EduardoAinda não há avaliações
- Desenho e Metodos Gráficos1 PDFDocumento26 páginasDesenho e Metodos Gráficos1 PDFMan SkyAinda não há avaliações
- Desenho e Metodos Gráficos1 PDFDocumento26 páginasDesenho e Metodos Gráficos1 PDFMan SkyAinda não há avaliações
- ATIVIDADE AVALIATIVA Portugues 8Documento2 páginasATIVIDADE AVALIATIVA Portugues 8Harry DobrevAinda não há avaliações
- Relatà Rio Seleà à o Natural (Beatriz Costa, Beatriz Rodrigues, Ema, Tiago)Documento13 páginasRelatà Rio Seleà à o Natural (Beatriz Costa, Beatriz Rodrigues, Ema, Tiago)mariaAinda não há avaliações
- Texto - Teoria Das TransiçõesDocumento21 páginasTexto - Teoria Das TransiçõesNinha DruAinda não há avaliações
- Guia Completo GBC LIFE Mar21Documento135 páginasGuia Completo GBC LIFE Mar21Elton ElvesAinda não há avaliações
- Icuria Dunensis ModelagemDocumento18 páginasIcuria Dunensis ModelagemAbilio Rafael Mucavele100% (1)
- O Lugar Do Psicomotricista Na Estimulação Precoce - Abordagem InterdisciplinarDocumento23 páginasO Lugar Do Psicomotricista Na Estimulação Precoce - Abordagem InterdisciplinarIsadora R. OliveiraAinda não há avaliações
- Novo ApresentaçãoDocumento11 páginasNovo ApresentaçãoandrechicoAinda não há avaliações
- MAPA NUMEROLÓGICO PESSOAL HUMBERTO JOSe de OLIVEIRA PEREIRADocumento68 páginasMAPA NUMEROLÓGICO PESSOAL HUMBERTO JOSe de OLIVEIRA PEREIRAhumbertopereira@gmail.comAinda não há avaliações
- Sistema Digestório de RuminantesDocumento18 páginasSistema Digestório de RuminantesLorrayne BorgesAinda não há avaliações
- MoluscosDocumento26 páginasMoluscosKatti EberleAinda não há avaliações
- ArticulaçõesDocumento3 páginasArticulaçõesEllen Gonçalves MoreiraAinda não há avaliações
- Genética Na Agropecuária Capítulo 6 - Interações Alélicas e Não AlélicasDocumento28 páginasGenética Na Agropecuária Capítulo 6 - Interações Alélicas e Não AlélicasMarilene SantosAinda não há avaliações
- Construção de Embarcações PequenasDocumento62 páginasConstrução de Embarcações PequenasHuascar Brito FeijoAinda não há avaliações
- Etica Moral e Direito No Transumanismo eDocumento20 páginasEtica Moral e Direito No Transumanismo eDeicon Davi Siqueira PiresAinda não há avaliações
- TranscriçãoDocumento2 páginasTranscriçãoVicttoria MeloAinda não há avaliações
- 08 - Sam Crescent - The Alpha Shifter - Fate MateDocumento186 páginas08 - Sam Crescent - The Alpha Shifter - Fate MateRaquel Ferreira100% (3)
- Tiffany Roberts - Aliens Among Us 1 - Taken by The Alien Next DoorDocumento684 páginasTiffany Roberts - Aliens Among Us 1 - Taken by The Alien Next Doorkamilaamp147Ainda não há avaliações
- Unicamp Um Assunto Por QuestaoDocumento65 páginasUnicamp Um Assunto Por QuestaoLuiz WickAinda não há avaliações
- Guia - de Projetos.Documento32 páginasGuia - de Projetos.Francinei MeninAinda não há avaliações
- PavlovDocumento2 páginasPavlovPedro CostaAinda não há avaliações
- Livro - Biologia, Histologia e EmbriologiaDocumento52 páginasLivro - Biologia, Histologia e EmbriologiaJoão PedroAinda não há avaliações
- Fundamentos de EntomologiaDocumento47 páginasFundamentos de EntomologiaSousa LusieneAinda não há avaliações
- LactoseDocumento1 páginaLactoseJoãoPinheiroAinda não há avaliações
- Hemograma Completo: Kevin Santos de OliveiraDocumento6 páginasHemograma Completo: Kevin Santos de OliveiraKevin Santos de OliveiraAinda não há avaliações
- Trabalho de BiologiaDocumento20 páginasTrabalho de BiologiaManuela AquinoAinda não há avaliações
- Lado7 Oficina SET 22 A1 2aDocumento39 páginasLado7 Oficina SET 22 A1 2agmattosgAinda não há avaliações
- LIVRO - A Psicologia Da Criança - NOVODocumento143 páginasLIVRO - A Psicologia Da Criança - NOVODepto. de Condomínios100% (1)
- FIRE - Proibido e Perigoso - Jussara LealDocumento305 páginasFIRE - Proibido e Perigoso - Jussara LealRobson SodréAinda não há avaliações
- Simulado 3 (Mat. 5º Ano) - Blog Do Prof. WarlesDocumento2 páginasSimulado 3 (Mat. 5º Ano) - Blog Do Prof. WarlesRicardo Santos100% (1)
- Filo Chordata PeixesDocumento48 páginasFilo Chordata PeixesGabriel OliveiraAinda não há avaliações
- Biomecânica Básica dos Exercícios: Membros InferioresNo EverandBiomecânica Básica dos Exercícios: Membros InferioresNota: 3.5 de 5 estrelas3.5/5 (8)
- Treinamento cerebral: Compreendendo inteligência emocional, atenção e muito maisNo EverandTreinamento cerebral: Compreendendo inteligência emocional, atenção e muito maisNota: 4.5 de 5 estrelas4.5/5 (169)
- Hackeando Darwin: Engenharia genética e o futuro da humanidadeNo EverandHackeando Darwin: Engenharia genética e o futuro da humanidadeAinda não há avaliações
- Uma viagem pelo cérebro: A via rápida para entender neurociência: 1ª edição revisada e atualizadaNo EverandUma viagem pelo cérebro: A via rápida para entender neurociência: 1ª edição revisada e atualizadaNota: 4 de 5 estrelas4/5 (13)
- Aprender mais rápido: Habilidades de estudo, memória e neurociênciaNo EverandAprender mais rápido: Habilidades de estudo, memória e neurociênciaNota: 4 de 5 estrelas4/5 (5)
- Tudo tem uma explicação: A biologia por trás de tudo aquilo que você nunca imaginouNo EverandTudo tem uma explicação: A biologia por trás de tudo aquilo que você nunca imaginouNota: 4 de 5 estrelas4/5 (5)
- Fitoenergética: A Energia das Plantas no Equilíbrio da AlmaNo EverandFitoenergética: A Energia das Plantas no Equilíbrio da AlmaNota: 5 de 5 estrelas5/5 (17)
- Suplementação proteica: Aminoacidemia e saúde vascularNo EverandSuplementação proteica: Aminoacidemia e saúde vascularAinda não há avaliações
- O Licenciamento Ambiental no Brasil na PráticaNo EverandO Licenciamento Ambiental no Brasil na PráticaNota: 1 de 5 estrelas1/5 (2)
- Abismos Narcísicos: A Psicodinâmica do Amadurecimento e da IndividuaçãoNo EverandAbismos Narcísicos: A Psicodinâmica do Amadurecimento e da IndividuaçãoNota: 5 de 5 estrelas5/5 (2)
- Psicoterapia: Teorias e técnicas psicoterápicasNo EverandPsicoterapia: Teorias e técnicas psicoterápicasNota: 5 de 5 estrelas5/5 (4)
- Reflexões sobre o Luto: Práticas Interventivas e Especificidades do Trabalho com Pessoas EnlutadasNo EverandReflexões sobre o Luto: Práticas Interventivas e Especificidades do Trabalho com Pessoas EnlutadasAinda não há avaliações