Você também pode gostar
- Matemática 7ºs Anos1Documento6 páginasMatemática 7ºs Anos1melosouza100% (1)
- Subtração nos números naturais e inteiros relativosDocumento116 páginasSubtração nos números naturais e inteiros relativosJuliana Rodighero100% (1)
- Multiplicação de números inteirosDocumento4 páginasMultiplicação de números inteirosFlávia FerreirinhaAinda não há avaliações
- Aerodinâmica comentada ANACDocumento14 páginasAerodinâmica comentada ANACdutifrancaAinda não há avaliações
- Operações com númerosDocumento3 páginasOperações com númerosAline RibeiroAinda não há avaliações
- 2012 - Matemática - M Renato - Medidas - Tendência Central PDFDocumento10 páginas2012 - Matemática - M Renato - Medidas - Tendência Central PDFEdnilson M. C. PereiraAinda não há avaliações
- CT-0460 - SRP 4075E Flex - 2021-08 - (Trilingue) - REV.004Documento24 páginasCT-0460 - SRP 4075E Flex - 2021-08 - (Trilingue) - REV.004André DavidAinda não há avaliações
- Desenho Técnico II - SENAI PRDocumento145 páginasDesenho Técnico II - SENAI PRValquiria BrazAinda não há avaliações
- Simulado Eear I 2011Documento6 páginasSimulado Eear I 2011Pedro Henrique MachadoAinda não há avaliações
- Lista de Exercícios de AlgoritmosDocumento19 páginasLista de Exercícios de AlgoritmosLuiz CarlosAinda não há avaliações
- ABNT Normas TécnicasDocumento4 páginasABNT Normas TécnicasIonara PizettaAinda não há avaliações
- Sistema de Injeção Rochester EFI MULTEC 700Documento7 páginasSistema de Injeção Rochester EFI MULTEC 700silvio ortizAinda não há avaliações
- Instrumentação e controle em processos industriaisDocumento19 páginasInstrumentação e controle em processos industriaisMarcos AfonsoAinda não há avaliações
- Resolução Atividade 3 - RosemeireDocumento11 páginasResolução Atividade 3 - RosemeireRose NascimentoAinda não há avaliações
- Curso Matlab 2023 - Cap 7Documento4 páginasCurso Matlab 2023 - Cap 7sergiopenedoAinda não há avaliações
- Lista 1Documento9 páginasLista 1Grazielle Tomaz NevesAinda não há avaliações
- Mathcad TutorialDocumento63 páginasMathcad TutorialEderley Soares MarquesAinda não há avaliações
- Exame - 2021 - ResoluçãoDocumento6 páginasExame - 2021 - ResoluçãoEfigénia GabrielAinda não há avaliações
- Algoritmos e Estruturas de Dados II - 1a Lista de ExercíciosDocumento9 páginasAlgoritmos e Estruturas de Dados II - 1a Lista de ExercíciosNetoberolaAinda não há avaliações
- Trabalho 3Documento21 páginasTrabalho 3Alexandre LamborghiniAinda não há avaliações
- Atividade01 MS211Documento5 páginasAtividade01 MS211Gabriel SilvaAinda não há avaliações
- Analises NuméricasDocumento16 páginasAnalises NuméricasAna Paula Magalhães MachadoAinda não há avaliações
- Operações matemáticas básicas e expressões algébricasDocumento6 páginasOperações matemáticas básicas e expressões algébricasflamengofisico100% (1)
- Conhecimentos Gerais MatematicaDocumento116 páginasConhecimentos Gerais Matematicaguardarpdf matlabAinda não há avaliações
- Como Criar Animações Com o MATLABDocumento16 páginasComo Criar Animações Com o MATLABAdailton FreitasAinda não há avaliações
- Aula 1 - Geraldo Goes e Alexandre Ywata - Introdução À Regressão LinearDocumento32 páginasAula 1 - Geraldo Goes e Alexandre Ywata - Introdução À Regressão LinearFranciso FreitasAinda não há avaliações
- Alocação dinâmica de memória em CDocumento7 páginasAlocação dinâmica de memória em Civan bragaAinda não há avaliações
- Métodos de Ordenação paraDocumento8 páginasMétodos de Ordenação parashantzu123Ainda não há avaliações
- Apostila de Estatistica Experimental Parte I 2019 MVDocumento130 páginasApostila de Estatistica Experimental Parte I 2019 MVCONTROLE DE QUALIDADEAinda não há avaliações
- 01 - Introdução Ao ScilabDocumento5 páginas01 - Introdução Ao ScilabjmcarrizoAinda não há avaliações
- 1 - Programacao - em - RDocumento3 páginas1 - Programacao - em - RRodrigo BertelliAinda não há avaliações
- Comparação Gráfica Entre Métodos Numérico e Analítico Do Comportamento de Uma Barra Sob TensãoDocumento12 páginasComparação Gráfica Entre Métodos Numérico e Analítico Do Comportamento de Uma Barra Sob TensãoMatheus SalesAinda não há avaliações
- Séries de Fourier - Solução Analítica e em MATLABDocumento9 páginasSéries de Fourier - Solução Analítica e em MATLABLuanaRechAinda não há avaliações
- IPB Teste1 20 21Documento3 páginasIPB Teste1 20 21estudantematildeAinda não há avaliações
- MEC 2325 - Transmissão de Calor – Condução - 2021.1Documento22 páginasMEC 2325 - Transmissão de Calor – Condução - 2021.1Edgardo Rafael Castro PachecoAinda não há avaliações
- Funções racionais: domínio, assimptotas e representação gráficaDocumento5 páginasFunções racionais: domínio, assimptotas e representação gráficagrunhoAinda não há avaliações
- Matemática Básica e Comercial: Conjuntos Números e ExpressõesDocumento40 páginasMatemática Básica e Comercial: Conjuntos Números e ExpressõesJeane Pereira LimaAinda não há avaliações
- Simulação Digital Matlab Controle de Malha FechadaDocumento9 páginasSimulação Digital Matlab Controle de Malha Fechadalucas.paschoalAinda não há avaliações
- Gráficos de controle np e X-barra-RDocumento24 páginasGráficos de controle np e X-barra-RHérmaneWegelisAinda não há avaliações
- Cálculo Numérico para Oficiais Da Marinha MercanteDocumento18 páginasCálculo Numérico para Oficiais Da Marinha MercanteFernando Willy Medeiros100% (1)
- Introdução ao R para Análise de Dados AltimétricosDocumento52 páginasIntrodução ao R para Análise de Dados AltimétricosLeonardo AsevedoAinda não há avaliações
- Captura de Tela 2022-07-23 À(s) 11.50.25Documento11 páginasCaptura de Tela 2022-07-23 À(s) 11.50.25Marcio José da SilvaAinda não há avaliações
- Lista de exercícios de aritmética de ponto flutuanteDocumento3 páginasLista de exercícios de aritmética de ponto flutuanteFelipe BerettaAinda não há avaliações
- Apostila de Matemática, Funções, Derivadas E IntegraisDocumento32 páginasApostila de Matemática, Funções, Derivadas E IntegraisMarcus BertoldoAinda não há avaliações
- Custos de processo por setor com matrizesDocumento7 páginasCustos de processo por setor com matrizesWilsonFabioDavidAinda não há avaliações
- Algoritmos e Estruturas de Dados: Funções e PonteirosDocumento3 páginasAlgoritmos e Estruturas de Dados: Funções e PonteirosThais RibeiroAinda não há avaliações
- Prova 3 de Física Computacional - Thays Simeia Rocha BarrosDocumento8 páginasProva 3 de Física Computacional - Thays Simeia Rocha BarrosThays Simeia Rocha BarrosAinda não há avaliações
- Exame AED EN 20-21 - Resolução DetalhadaDocumento9 páginasExame AED EN 20-21 - Resolução DetalhadaGabriel PereiraAinda não há avaliações
- Resumo de OctaveDocumento13 páginasResumo de OctavebiopoweredAinda não há avaliações
- Isoladas Matematica Do Zero Na FCC Dudan Aula 3 ResolvidoDocumento24 páginasIsoladas Matematica Do Zero Na FCC Dudan Aula 3 ResolvidoDavid XavierAinda não há avaliações
- 1 49adDocumento22 páginas1 49adErland GarciaAinda não há avaliações
- Operações com Números RacionaisDocumento10 páginasOperações com Números RacionaisGerson OliveiraAinda não há avaliações
- Curso de Matemática Básica: Números e OperaçõesQuando uma dízima periódica não termina, dizemos que ela éDocumento58 páginasCurso de Matemática Básica: Números e OperaçõesQuando uma dízima periódica não termina, dizemos que ela éPetrucio TenorioAinda não há avaliações
- Exercicio de AlgoritmoDocumento18 páginasExercicio de AlgoritmoMarcos JoseAinda não há avaliações
- Métodos de integração numérica e erros de integraçãoDocumento52 páginasMétodos de integração numérica e erros de integraçãoClemente JuniorAinda não há avaliações
- Projeto de Sistemas de Controle - Espaço de Estados Malha FechadaDocumento22 páginasProjeto de Sistemas de Controle - Espaço de Estados Malha FechadaDorival OliveiraAinda não há avaliações
- IntroduçãoDocumento7 páginasIntroduçãostu.320202001Ainda não há avaliações
- PMR5215 Otimização Lista4Documento9 páginasPMR5215 Otimização Lista4diegoAinda não há avaliações
- Operações com números decimaisDocumento2 páginasOperações com números decimaisKátia RenêAinda não há avaliações
- Cálculo Numérico 1Documento5 páginasCálculo Numérico 1Astell EngenhariaAinda não há avaliações
- Curso MATLAB Controle Servomec Introdução Vetores Matrizes GráficosDocumento5 páginasCurso MATLAB Controle Servomec Introdução Vetores Matrizes GráficosVictor Hugo FerreiraAinda não há avaliações
- CAL - Regra Da CadeiaDocumento23 páginasCAL - Regra Da CadeiaRebecca MorenaAinda não há avaliações
- Relatorio 11Documento9 páginasRelatorio 11Elyan GabrielAinda não há avaliações
- Controle Vetorial, Máquina De Indução E Métodos NuméricosNo EverandControle Vetorial, Máquina De Indução E Métodos NuméricosAinda não há avaliações
- Instituições financeiras - Origem, definição e tiposDocumento6 páginasInstituições financeiras - Origem, definição e tiposTiago SoaresAinda não há avaliações
- Regressão Linear Simples - ResumoDocumento2 páginasRegressão Linear Simples - ResumoTiago SoaresAinda não há avaliações
- Valores MobiliáriosDocumento10 páginasValores MobiliáriosTiago SoaresAinda não há avaliações
- Mercado Securitário - Regulação Do Mercado FinanceiroDocumento6 páginasMercado Securitário - Regulação Do Mercado FinanceiroTiago SoaresAinda não há avaliações
- Recuperação da fabricante de ônibus Comil S.ADocumento4 páginasRecuperação da fabricante de ônibus Comil S.ATiago SoaresAinda não há avaliações
- O estresse no trabalho dos entregadores autônomos e seus impactos na vida pessoal e familiar retratados no filme Você Não Estava AquiDocumento4 páginasO estresse no trabalho dos entregadores autônomos e seus impactos na vida pessoal e familiar retratados no filme Você Não Estava AquiTiago SoaresAinda não há avaliações
- Capitalismo e trabalho na indústria americanaDocumento4 páginasCapitalismo e trabalho na indústria americanaTiago SoaresAinda não há avaliações
- Uberização Do TrabalhoDocumento4 páginasUberização Do TrabalhoTiago SoaresAinda não há avaliações
- Apresentação ItapeviDocumento9 páginasApresentação ItapeviTiago SoaresAinda não há avaliações
- Frases de Céticos e AteusDocumento20 páginasFrases de Céticos e AteusPaulo AcostaAinda não há avaliações
- Centro Baiano de Computação de Alto DesempenhoDocumento70 páginasCentro Baiano de Computação de Alto DesempenhoGeronimo AmaralAinda não há avaliações
- Trabalho Avaliativo - Hidrostática - PressãoDocumento2 páginasTrabalho Avaliativo - Hidrostática - PressãoCarla Cristina Alves da SilvaAinda não há avaliações
- O Conflito Como SociaçãoDocumento7 páginasO Conflito Como SociaçãoLarissa GuimarãesAinda não há avaliações
- Relatório 6Documento12 páginasRelatório 6Felipe SouzaAinda não há avaliações
- Medições elétricas: projetos de instrumentosDocumento7 páginasMedições elétricas: projetos de instrumentosMarcelo José CividiniAinda não há avaliações
- Isomeria Química FundamentosDocumento65 páginasIsomeria Química FundamentosDaniel SantanaAinda não há avaliações
- Livro Eletrônico sobre FísicaDocumento26 páginasLivro Eletrônico sobre Físicagalileu galileiAinda não há avaliações
- DynaGateway DUO comunicação DynaLoggers DynamoxDocumento1 páginaDynaGateway DUO comunicação DynaLoggers DynamoxOrlando MarucaAinda não há avaliações
- Mapa - Pesquisa Operacional - 51-2024Documento3 páginasMapa - Pesquisa Operacional - 51-2024admcavaliniassessoriaAinda não há avaliações
- Campo Mourao 2009 ADocumento126 páginasCampo Mourao 2009 AAlessandre OliveiraAinda não há avaliações
- Resumo Progressões AritméticasDocumento2 páginasResumo Progressões AritméticasGilcineyJardimAinda não há avaliações
- Interrupto UTDocumento122 páginasInterrupto UTJere GlinkaAinda não há avaliações
- Consumo Energia Elétrica AparelhosDocumento4 páginasConsumo Energia Elétrica AparelhosAfonso BentesAinda não há avaliações
- Artigo 433Documento10 páginasArtigo 433AnnaAinda não há avaliações
- Ger Proc - Escalonamento de ProcessosDocumento36 páginasGer Proc - Escalonamento de ProcessosDiego AraújoAinda não há avaliações
- Combatente - Raciocínio Lógico - Módulo 02 - Proposições e ConectivosDocumento6 páginasCombatente - Raciocínio Lógico - Módulo 02 - Proposições e Conectivoscarloscharles1210Ainda não há avaliações
- Método de Custo MínimoDocumento12 páginasMétodo de Custo MínimoEdson Arlindo Nhatuve100% (1)
- Estudos clínicos de não-inferioridadeDocumento7 páginasEstudos clínicos de não-inferioridadeRoberto DiasAinda não há avaliações
- Pirólise de PequiDocumento72 páginasPirólise de PequiIara SilveiraAinda não há avaliações
- Manual do DesenvolvedorDocumento52 páginasManual do DesenvolvedorDihego CostaAinda não há avaliações
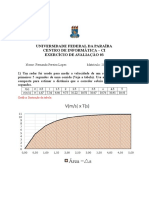
- Estimando distância com regra de SimpsonDocumento5 páginasEstimando distância com regra de SimpsonFernanda LopesAinda não há avaliações
- MODELODocumento2 páginasMODELOmbsarmento1Ainda não há avaliações
- Automação na fundição sob pressãoDocumento13 páginasAutomação na fundição sob pressãoJuliana OliveiraAinda não há avaliações