Você também pode gostar
- Guiao Correcao Teste2 Bioestatistica Biologia 2022Documento4 páginasGuiao Correcao Teste2 Bioestatistica Biologia 2022daniel pascoalAinda não há avaliações
- Estatística Aplicada À Química - Aula 4Documento31 páginasEstatística Aplicada À Química - Aula 4Daniel SantosAinda não há avaliações
- Est2 en Maio2022 Com SolDocumento10 páginasEst2 en Maio2022 Com SolcatarinaAinda não há avaliações
- Exemplo ModeloEquilibrioQuimico H2 O2Documento6 páginasExemplo ModeloEquilibrioQuimico H2 O2Giulio Domenico BordinAinda não há avaliações
- Atividade 02 - Antonio Carlos Soares AraujoDocumento5 páginasAtividade 02 - Antonio Carlos Soares AraujoLindalva Alves100% (1)
- Tempo de Meia VidaDocumento7 páginasTempo de Meia VidaangelalameidaAinda não há avaliações
- Trigonometria e Funções Trigonométricas - TESTEDocumento2 páginasTrigonometria e Funções Trigonométricas - TESTEDiogo Alves DiasAinda não há avaliações
- Exame Normal - Guia de Correcao - Inferencia EstatisticaDocumento5 páginasExame Normal - Guia de Correcao - Inferencia EstatisticaMebels NjanjeAinda não há avaliações
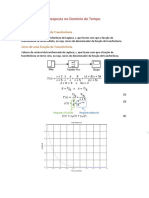
- Resposta No Domínio Do TempoDocumento6 páginasResposta No Domínio Do TempoRenan Oliveira NunesAinda não há avaliações
- Exercícios (27-03-2023)Documento11 páginasExercícios (27-03-2023)EdneyAinda não há avaliações
- Aula #2 - WeibullDocumento40 páginasAula #2 - WeibullEugenio Benito JuniorAinda não há avaliações
- Trabalho 1 de FMODocumento7 páginasTrabalho 1 de FMODelson Freitas SalvadorAinda não há avaliações
- Cópia de MATEMATICA ENQUADRAMENTO PRODUTO E SOMADocumento14 páginasCópia de MATEMATICA ENQUADRAMENTO PRODUTO E SOMARita100% (1)
- "Generalizando" o Conceito de Reta Tangente - Parte 2Documento20 páginas"Generalizando" o Conceito de Reta Tangente - Parte 2SuperRafa1111Ainda não há avaliações
- 2 - Prova - 35M12 - Com SoluçãoDocumento4 páginas2 - Prova - 35M12 - Com SoluçãoEmerson RochaAinda não há avaliações
- Resolução Do Banco de Questão de Cálculo 1Documento265 páginasResolução Do Banco de Questão de Cálculo 1Rinvysson SouzaAinda não há avaliações
- Atividade 2 - ResoluçãoDocumento3 páginasAtividade 2 - ResoluçãoViolet ZoeAinda não há avaliações
- Roteiro de Estudos 5 - Álgebra I - GabaritoDocumento5 páginasRoteiro de Estudos 5 - Álgebra I - GabaritoHomem Macho0% (1)
- Gabarito - Prova - Final - 2020 - 2Documento4 páginasGabarito - Prova - Final - 2020 - 2Luana Rodrigues CastiglioniAinda não há avaliações
- Wa0016.Documento31 páginasWa0016.engenheiraelvasAinda não há avaliações
- 3 - Estatistica - Medidas de Posição e DispersãoDocumento18 páginas3 - Estatistica - Medidas de Posição e DispersãoMarcelo AugustoAinda não há avaliações
- Trabalho Feito de Estatistica (DADOS AGRUPADOS)Documento5 páginasTrabalho Feito de Estatistica (DADOS AGRUPADOS)Ali Ussene Mecussete100% (1)
- FichaRevisaoTeste04 CorrecaoDocumento18 páginasFichaRevisaoTeste04 CorrecaoRick RollAinda não há avaliações
- Analise Combinatoria - ProbabilidadesDocumento12 páginasAnalise Combinatoria - ProbabilidadesdreamcitAinda não há avaliações
- Ficha de Exemplos e ExerciciosDocumento2 páginasFicha de Exemplos e ExerciciosTimotio Jaime NomboraAinda não há avaliações
- APX1 ALI 2022 1 GabaritoDocumento5 páginasAPX1 ALI 2022 1 GabaritoNina BrandaoAinda não há avaliações
- Matemática - MMB501 - Semana 4Documento3 páginasMatemática - MMB501 - Semana 4Reall SoaresAinda não há avaliações
- Aula B2 - Colisao Inelastica - Grafico MonologDocumento6 páginasAula B2 - Colisao Inelastica - Grafico MonologDaniela RibeiroAinda não há avaliações
- Propriedades DeterminantesDocumento8 páginasPropriedades Determinantesztvrqgy6d8Ainda não há avaliações
- 01 ANO ROTEIRO - Semana 02 - GAALDocumento8 páginas01 ANO ROTEIRO - Semana 02 - GAALWilsonFabioDavidAinda não há avaliações
- Figura 1. CurtoseDocumento8 páginasFigura 1. CurtoseBobby GudMan VIAinda não há avaliações
- Combinatoria, Triangulo e Binomio 2 CADAVAL 2017-2018 ResoluçãoDocumento4 páginasCombinatoria, Triangulo e Binomio 2 CADAVAL 2017-2018 ResoluçãomanuelsppmAinda não há avaliações
- GAAL Aula9 20221Documento45 páginasGAAL Aula9 20221Luigi FalconiAinda não há avaliações
- Exercicios para Primeiro Ano Adm 2Documento5 páginasExercicios para Primeiro Ano Adm 2viAinda não há avaliações
- Apostila EL33L 1S2018Documento15 páginasApostila EL33L 1S2018Gabriel JulekAinda não há avaliações
- Dimensionamento Das Longarinas - 28-08Documento22 páginasDimensionamento Das Longarinas - 28-08CR engenhariaAinda não há avaliações
- Metodos NumerosDocumento14 páginasMetodos NumerosAndres MorenoAinda não há avaliações
- 10 - Inferência EstatísticaDocumento37 páginas10 - Inferência EstatísticaLauren FeitosaAinda não há avaliações
- Resolução FQ 2020 V1 F1-2Documento8 páginasResolução FQ 2020 V1 F1-2mdumashAinda não há avaliações
- AD1 2019 1 Estatistica Aplicada A AdminiDocumento22 páginasAD1 2019 1 Estatistica Aplicada A AdminiNEVTONAinda não há avaliações
- Técnicas de DemonstraçãoDocumento26 páginasTécnicas de DemonstraçãoCultura Nerd/GeekAinda não há avaliações
- Construção de Tabelas Com Intervalo de ClasseDocumento13 páginasConstrução de Tabelas Com Intervalo de ClasseJoão Pedro BarbosaAinda não há avaliações
- AL 1.1 Lançamento Horizontal PDFDocumento4 páginasAL 1.1 Lançamento Horizontal PDFANA FRAGOSOAinda não há avaliações
- Módulo 2-DistAmostraiseEstDocumento30 páginasMódulo 2-DistAmostraiseEstArroz CastanhaAinda não há avaliações
- Sub 2020-2Documento3 páginasSub 2020-2Eduardo OliveiraAinda não há avaliações
- Aula 8 REGRESSÃODocumento56 páginasAula 8 REGRESSÃOYurssula ADAMUGYAinda não há avaliações
- Cap. 4 - Comparação de ReatoresDocumento60 páginasCap. 4 - Comparação de ReatoresGabriel MazzarottoAinda não há avaliações
- Média, Variância e Desvio Padrão: 3 Série Aula 15 - 3º BimestreDocumento24 páginasMédia, Variância e Desvio Padrão: 3 Série Aula 15 - 3º BimestreLucas gamesAinda não há avaliações
- Lista 02 - Fenômenos Eletricos - Campo Elétrico - (Resolvida)Documento15 páginasLista 02 - Fenômenos Eletricos - Campo Elétrico - (Resolvida)Havoc GamerAinda não há avaliações
- Medida de Posição 17 - 10 - 2022Documento18 páginasMedida de Posição 17 - 10 - 2022João Pedro BarbosaAinda não há avaliações
- Trabalho de Matematica AplicadaDocumento12 páginasTrabalho de Matematica AplicadaTúrquio José AfonsoAinda não há avaliações
- 10-AjusteCurvas MinimosQuadradosDocumento16 páginas10-AjusteCurvas MinimosQuadradosMATHEUS HENRIQUE SILVEIRA SANTANAAinda não há avaliações
- Guia de Correcção T1 V1 TMMDocumento6 páginasGuia de Correcção T1 V1 TMMJulio joaquim tembisseAinda não há avaliações
- FT 29 - GenralidadesSobreSucessões - 3Documento3 páginasFT 29 - GenralidadesSobreSucessões - 3Cantinho do EstudoAinda não há avaliações
- Slide P ApresentaçãoMínimos QuadradosDocumento21 páginasSlide P ApresentaçãoMínimos QuadradosViviane MirelyAinda não há avaliações
- 3 - ReservatóriosDocumento31 páginas3 - ReservatóriosBruno OtávioAinda não há avaliações
- O Ensino Da Matemática Na Educação Básica Através Do Software GeogebraNo EverandO Ensino Da Matemática Na Educação Básica Através Do Software GeogebraAinda não há avaliações
- Exame Externo - Revisão Da Tentativa GESTAO de QUALIDADEDocumento19 páginasExame Externo - Revisão Da Tentativa GESTAO de QUALIDADEDjerson jaharAinda não há avaliações
- TRABALHODocumento13 páginasTRABALHODjerson jaharAinda não há avaliações
- Avaliação de Recorrência - SIGDocumento15 páginasAvaliação de Recorrência - SIGDjerson jaharAinda não há avaliações
- Exame Externo - Revisão Da Tentativa QUIMICA AMBIENTALDocumento17 páginasExame Externo - Revisão Da Tentativa QUIMICA AMBIENTALDjerson jaharAinda não há avaliações
- Avaliação 1 - Port IIDocumento9 páginasAvaliação 1 - Port IIDjerson jaharAinda não há avaliações
- Avaliaçao 3-Historia Da Antigas AmericasDocumento8 páginasAvaliaçao 3-Historia Da Antigas AmericasDjerson jaharAinda não há avaliações
- Avaliação 1 - OcidentalDocumento7 páginasAvaliação 1 - OcidentalDjerson jaharAinda não há avaliações
- HM - 2 - Avaliação 2Documento2 páginasHM - 2 - Avaliação 2Djerson jaharAinda não há avaliações
- Avaliação 3 de História MedievalDocumento10 páginasAvaliação 3 de História MedievalDjerson jaharAinda não há avaliações
- Trabalho Climatologia IiDocumento14 páginasTrabalho Climatologia IiDjerson jaharAinda não há avaliações
- Ciências Naturais-02Documento30 páginasCiências Naturais-02Djerson jahar100% (1)
- Avaliação Final - Revisão Da Tentativa ESTATDocumento19 páginasAvaliação Final - Revisão Da Tentativa ESTATDjerson jahar100% (7)
- Avaliação Final - Revisão Da Tentativa TEOEDocumento19 páginasAvaliação Final - Revisão Da Tentativa TEOEDjerson jaharAinda não há avaliações
- BIOESTATISTICA - Unidade IIDocumento57 páginasBIOESTATISTICA - Unidade IIrafa141088Ainda não há avaliações
- If DefinitivoDocumento2 páginasIf DefinitivoJaqueline SantosAinda não há avaliações
- Revisão AV1 - Estatística - GabaritoDocumento8 páginasRevisão AV1 - Estatística - GabaritoWagner TagarroAinda não há avaliações
- Universidade Católica de Moçambique Centro de Ensino À DistânciaDocumento10 páginasUniversidade Católica de Moçambique Centro de Ensino À DistânciaJoaquim Mateus ZamboAinda não há avaliações
- Métodos Quantitativos em Medicina. Prof. Neli OrtegaDocumento28 páginasMétodos Quantitativos em Medicina. Prof. Neli OrtegaWagner JorcuvichAinda não há avaliações
- Lista09 PDFDocumento2 páginasLista09 PDFzarodasilvaAinda não há avaliações
- APOSTILA2Documento23 páginasAPOSTILA2Concursando PersistenteAinda não há avaliações
- Aula 3 Medidas NumericasDocumento11 páginasAula 3 Medidas NumericasShelton UamusseAinda não há avaliações
- MainDocumento109 páginasMainmarcusAinda não há avaliações
- Aula 11bDocumento36 páginasAula 11bCarolina Parra MartínezAinda não há avaliações
- R Teste HipDocumento57 páginasR Teste HipAndré OliveiraAinda não há avaliações
- ESTATISTICA AVA Completo Atividades e QuestionariosDocumento15 páginasESTATISTICA AVA Completo Atividades e QuestionariosSamara Regina Siqueira LimaAinda não há avaliações
- Prova 4Documento4 páginasProva 4André OliveiraAinda não há avaliações
- Apostila PeEDocumento113 páginasApostila PeEhcmm100% (3)
- Viga Benkelman - VS01Documento2 páginasViga Benkelman - VS01Henrique AraujoAinda não há avaliações
- Lista1 Exercicios Inventario FlorestalDocumento5 páginasLista1 Exercicios Inventario FlorestalJessica Terra SoaresAinda não há avaliações
- Slides - Aula 4Documento11 páginasSlides - Aula 4Lania MarinhoAinda não há avaliações
- Lista 13Documento5 páginasLista 13Laís CaladoAinda não há avaliações
- Moda, Média, MedianaDocumento4 páginasModa, Média, MedianaDaniel Antonio Martins AlmeidaAinda não há avaliações
- Exercício Aula 5Documento10 páginasExercício Aula 5Lucas Mendonça0% (1)
- Estadistica DescriptivaDocumento30 páginasEstadistica DescriptivaAnonymous rZh8yjkAinda não há avaliações
- 11 e 12 - Graficos de Controle Por VariaveisDocumento40 páginas11 e 12 - Graficos de Controle Por VariaveisJesaías KendsonAinda não há avaliações
- Burger e Delitti 2008Documento7 páginasBurger e Delitti 2008anacorteAinda não há avaliações
- Testes de Hipóteses e RegressãoDocumento19 páginasTestes de Hipóteses e Regressãosusana catarina roqueAinda não há avaliações
- Medidas de Variabilidade e Sua Aplicação Na Análise de Dados GeográficosDocumento11 páginasMedidas de Variabilidade e Sua Aplicação Na Análise de Dados GeográficosAlex MonitoAinda não há avaliações
- Formulas EstatisticasDocumento5 páginasFormulas EstatisticasCerasel2Ainda não há avaliações
- Lista de Exercícios 01 - Estatística IIDocumento2 páginasLista de Exercícios 01 - Estatística IIFelipe de Souza LopesAinda não há avaliações
- Estatística Descritiva Aula 1Documento86 páginasEstatística Descritiva Aula 1londemonAinda não há avaliações