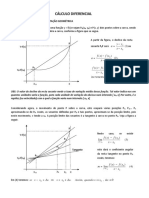
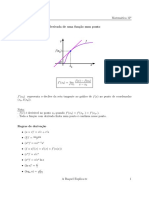
Você também pode gostar
- Introdução Variaveis Aleatorias ContinuasDocumento13 páginasIntrodução Variaveis Aleatorias ContinuasNuno Abreu100% (1)
- Cap4 VADDocumento27 páginasCap4 VADGiovane Xavier100% (1)
- Calculodiferencial - IDocumento12 páginasCalculodiferencial - IGomes CumbulaAinda não há avaliações
- AulaDocumento53 páginasAulaFelipe AugustoAinda não há avaliações
- Calculodiferencial - IDocumento33 páginasCalculodiferencial - IMohammad Shamiz100% (1)
- Derivadas-11º-10 Apontamentos Aula !!Documento2 páginasDerivadas-11º-10 Apontamentos Aula !!antonia44322Ainda não há avaliações
- Tema #2 Variaveis Aleatorias2022Documento23 páginasTema #2 Variaveis Aleatorias2022Xavier Leite ManjateAinda não há avaliações
- Aula 09VariaveisAleatoriasDocumento17 páginasAula 09VariaveisAleatoriastarcmenAinda não há avaliações
- Variáveis Aleatórias Contínuas PDFDocumento70 páginasVariáveis Aleatórias Contínuas PDFFranklin Piauhy NetoAinda não há avaliações
- Calculodiferencial - IDocumento35 páginasCalculodiferencial - IFrank TivaneAinda não há avaliações
- Capítulo 6 Parte 1Documento7 páginasCapítulo 6 Parte 1Carlos HenriqueAinda não há avaliações
- 1 DerivadasDocumento75 páginas1 DerivadasMarta SáAinda não há avaliações
- CALCULODIFERENCIAL - CompletaDocumento35 páginasCALCULODIFERENCIAL - CompletaGomes CumbulaAinda não há avaliações
- Est Apl 3Documento32 páginasEst Apl 3Pedro CruzAinda não há avaliações
- O Método Dos Gradientes Conjugados: Francisco A. M. Gomes MT402 - Matrizes - Junho de 2008Documento35 páginasO Método Dos Gradientes Conjugados: Francisco A. M. Gomes MT402 - Matrizes - Junho de 2008Allan FerreiraAinda não há avaliações
- Aula 13 - Funções DiferenciáveisDocumento10 páginasAula 13 - Funções DiferenciáveisTiago SilvaAinda não há avaliações
- Aula 13 - Funções DiferenciáveisDocumento10 páginasAula 13 - Funções DiferenciáveisMessionAinda não há avaliações
- Derivadas 12º 11Documento2 páginasDerivadas 12º 11Ana CoutoAinda não há avaliações
- CADERNO04Documento24 páginasCADERNO04RAQUEL PEREIRA DA SILVAAinda não há avaliações
- Funcao Afim e InequaçõesDocumento13 páginasFuncao Afim e Inequaçõesprofessor washington luizAinda não há avaliações
- T31b VA Contínuas IntroDocumento2 páginasT31b VA Contínuas IntroMaria CarvalhoAinda não há avaliações
- Tema: Variaveis AleatoriasDocumento8 páginasTema: Variaveis AleatoriasOrlando Penicela Júnior100% (1)
- 6 - Zeros de Funcoes - Parte 3Documento18 páginas6 - Zeros de Funcoes - Parte 3Mateus SantosAinda não há avaliações
- Derivação Das Funções Reais de Variável RealDocumento23 páginasDerivação Das Funções Reais de Variável RealVicente Xavier Chocancunene100% (4)
- Revisões de F.R.V.R.Documento15 páginasRevisões de F.R.V.R.António SobralAinda não há avaliações
- E3 PresDocumento62 páginasE3 PresRaabe SeehagenAinda não há avaliações
- Matemática - 1º Ano Eja - Semana 1Documento5 páginasMatemática - 1º Ano Eja - Semana 1barbara.c.gomesAinda não há avaliações
- DerivadasDocumento36 páginasDerivadastinocas206Ainda não há avaliações
- Derivada 2023Documento1 páginaDerivada 2023souzalimagustavo2005Ainda não há avaliações
- Cálculo Numérico II (Parte 1)Documento28 páginasCálculo Numérico II (Parte 1)daianedonegaAinda não há avaliações
- Trabalho de Pesquisa Matematica - Teste 2Documento25 páginasTrabalho de Pesquisa Matematica - Teste 2Matambo ComercialAinda não há avaliações
- Aula 06 Maximos e Mínimos RevDocumento52 páginasAula 06 Maximos e Mínimos RevCleidson SantosAinda não há avaliações
- Aulas Cap4Documento107 páginasAulas Cap4Rfgd376Ainda não há avaliações
- Variaveis AleatoriasDocumento19 páginasVariaveis AleatoriasCris SimõesAinda não há avaliações
- 06 Variaveis Continuas PDFDocumento41 páginas06 Variaveis Continuas PDFTony Domingos SaboneteAinda não há avaliações
- Estatistica TecnicoDocumento37 páginasEstatistica TecnicoLucilia PereiraAinda não há avaliações
- Aplicação Da Derivada Na ContabiliidadeDocumento10 páginasAplicação Da Derivada Na ContabiliidadeJoia chipaique ChipaiqueAinda não há avaliações
- TEMA III ProbabilidadeDocumento15 páginasTEMA III ProbabilidadeTati CatiAinda não há avaliações
- Distribuição Contínuas e Distribuição NormalDocumento13 páginasDistribuição Contínuas e Distribuição NormalPastor NamuehaAinda não há avaliações
- Slides - Cap3 - Variáveis AleatóriasDocumento32 páginasSlides - Cap3 - Variáveis AleatóriasmfroloAinda não há avaliações
- 1 Diferenciabilidade e Derivadas Direcionais: F X F (X H F y F (X KDocumento9 páginas1 Diferenciabilidade e Derivadas Direcionais: F X F (X H F y F (X KGime PitraAinda não há avaliações
- Funções de Duas Variáveis: Cálculo VetorialDocumento25 páginasFunções de Duas Variáveis: Cálculo VetorialMomade Antonio RihelaAinda não há avaliações
- FEPForuns-SebentaESTI 2ºtesteDocumento5 páginasFEPForuns-SebentaESTI 2ºtesteFilipa OliveiraAinda não há avaliações
- Função Linear 1Documento17 páginasFunção Linear 1Alvim AlbertoAinda não há avaliações
- GCET060 - Aula 5 Distribuiçoes Continuas 20221 PDFDocumento14 páginasGCET060 - Aula 5 Distribuiçoes Continuas 20221 PDFStorie Everson ZoioAinda não há avaliações
- Propagação de IncertezasDocumento20 páginasPropagação de IncertezasbeatrizAinda não há avaliações
- Aproximacoes Funcoes PDFDocumento18 páginasAproximacoes Funcoes PDFnaldoAinda não há avaliações
- Lista MPDDocumento16 páginasLista MPDMATHEUS HENRIQUE SILVEIRA SANTANAAinda não há avaliações
- PD6Documento19 páginasPD6Daniel cabezas gonzaloAinda não há avaliações
- Cap2. Variaveis AleatoriasDocumento14 páginasCap2. Variaveis Aleatoriasmessias sorteAinda não há avaliações
- TeoricoDocumento28 páginasTeoricoCowboyAinda não há avaliações
- Lista 2Documento5 páginasLista 2Igor BarbosaAinda não há avaliações
- Complementos Modelos Discretos 1Documento9 páginasComplementos Modelos Discretos 1ManuelAinda não há avaliações
- Aula 7Documento20 páginasAula 7Raul LeitaoAinda não há avaliações
- Calnum IIIDocumento16 páginasCalnum IIIfabio ferreira de almeidaAinda não há avaliações
- Estatistica 1 Trabalho 5 GrupoDocumento15 páginasEstatistica 1 Trabalho 5 GrupoSonia JuizAinda não há avaliações
- M.numericos Livro-6Documento136 páginasM.numericos Livro-6Só Cálculos MoçambiqueAinda não há avaliações
- Lista 5Documento10 páginasLista 5Germano AbudAinda não há avaliações
- Introd Lsub23 1Documento116 páginasIntrod Lsub23 1FELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- MIN114 PlanoEnsino23-1Documento2 páginasMIN114 PlanoEnsino23-1FELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- GlossAlunos2005 2021 2Documento66 páginasGlossAlunos2005 2021 2FELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- Fichaterm EEScomentada 2018Documento1 páginaFichaterm EEScomentada 2018FELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- Exercicios de Probabilidades ENUNCIADODocumento3 páginasExercicios de Probabilidades ENUNCIADOFELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- Conceitos Probabilisticos 2022Documento19 páginasConceitos Probabilisticos 2022FELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- M114 aulaRSubniveis20 1remotoDocumento71 páginasM114 aulaRSubniveis20 1remotoFELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- Aplicação de Pilares Parciais em Lavras Do Tipo Sublevel StopingDocumento8 páginasAplicação de Pilares Parciais em Lavras Do Tipo Sublevel StopingFELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- MIN 225-114-Termin21-2-18mar22Documento8 páginasMIN 225-114-Termin21-2-18mar22FELIPE CAMILO DIAS DE SOUZAAinda não há avaliações
- Econometria I - EESPDocumento127 páginasEconometria I - EESPBruno SalesAinda não há avaliações
- Bioestatística - PDocumento3 páginasBioestatística - PVeronica Mendes100% (2)
- If DefinitivoDocumento2 páginasIf DefinitivoJaqueline SantosAinda não há avaliações
- Recuperação EstatísticaDocumento27 páginasRecuperação EstatísticaRafael Santana RodirguesAinda não há avaliações
- Lista1 P1 Mat013Documento3 páginasLista1 P1 Mat013Lucas FrancoAinda não há avaliações
- Análise de RegressãoDocumento21 páginasAnálise de RegressãoDeográcio Possiano TalegalAinda não há avaliações
- Propagacao de Erros Ou DesviosDocumento18 páginasPropagacao de Erros Ou DesviosAnne Ketri Pasquinelli da FonsecaAinda não há avaliações
- Curso 161000 Aula 02 v6Documento84 páginasCurso 161000 Aula 02 v6DOUGLAS CAMPOS DE ARAÚJO ESPÍNDULAAinda não há avaliações
- Estatística Descritiva Parte 1Documento121 páginasEstatística Descritiva Parte 1Jessica NeryAinda não há avaliações
- Monografia - Marcelina Ramia 2016Documento40 páginasMonografia - Marcelina Ramia 2016Miguel Alberto LinoAinda não há avaliações
- Livro - Regressão LinearDocumento97 páginasLivro - Regressão LinearJosé Fernandes dos SantosAinda não há avaliações
- Aula 09 Parte2Documento59 páginasAula 09 Parte2viniciusltAinda não há avaliações
- Minitab - Resumo Dos ComandosDocumento32 páginasMinitab - Resumo Dos ComandosMilton Perceus MeloAinda não há avaliações
- Estatística - Ficha 1 - Estatística Descritiva - Proposta de ResoluçãoDocumento9 páginasEstatística - Ficha 1 - Estatística Descritiva - Proposta de ResoluçãoRaíssa MachadoAinda não há avaliações
- Modelos ContinuosDocumento4 páginasModelos ContinuosJm Zemas da VeigaAinda não há avaliações
- Material Curso de Férias 2022 - RobérioDocumento22 páginasMaterial Curso de Férias 2022 - RobérioRobério BacelarAinda não há avaliações
- Exercicios de Modelos Discretos.Documento3 páginasExercicios de Modelos Discretos.Jm Zemas da VeigaAinda não há avaliações
- AO02 - Formulario para Alunos BIOESTATISTICADocumento8 páginasAO02 - Formulario para Alunos BIOESTATISTICAjovinoAinda não há avaliações
- Testes de HipótesesDocumento11 páginasTestes de HipótesesrafaelrqfAinda não há avaliações
- Diagnose Do Estado Nutricional Das Plantas - FNP 1 AtualDocumento90 páginasDiagnose Do Estado Nutricional Das Plantas - FNP 1 AtualArilene FranklinAinda não há avaliações
- Lista de Exercícios 2 - Estatística - Variaveis AleatoriasDocumento2 páginasLista de Exercícios 2 - Estatística - Variaveis AleatoriasLuciano BassoAinda não há avaliações
- Aula 6 Teoria de EstimacaoDocumento8 páginasAula 6 Teoria de EstimacaoAcélio SimõesAinda não há avaliações
- Avaliação - Unidade III - Revisão Da TentativaDocumento7 páginasAvaliação - Unidade III - Revisão Da TentativaRamon SouzaAinda não há avaliações
- In 24 - BebidasDocumento8 páginasIn 24 - Bebidasana claraAinda não há avaliações
- Apostila - Estatistica - II - (JAIR CROCE FILHO) (Séries Temporais)Documento95 páginasApostila - Estatistica - II - (JAIR CROCE FILHO) (Séries Temporais)smoikawaAinda não há avaliações
- Ajustamento de ObservaçõesDocumento2 páginasAjustamento de Observaçõesime_cartografia0% (1)
- Questões de Estatística para ConcursosDocumento74 páginasQuestões de Estatística para ConcursosRicardo Sousa0% (1)
- AlfaCon Simulados Carreiras PoliciaisDocumento18 páginasAlfaCon Simulados Carreiras PoliciaisEdson SousaAinda não há avaliações
- Dist TeoricaDocumento6 páginasDist TeoricaAniceto Ernesto MbalaneAinda não há avaliações
- Aula 7 - 2016Documento18 páginasAula 7 - 2016ALEXANDRE SALES BRAZ JUNIORAinda não há avaliações