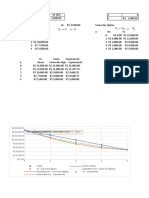
Você também pode gostar
- 2021.1 - Aula 2 - Jogos MatemáticosDocumento42 páginas2021.1 - Aula 2 - Jogos MatemáticosPedro SquirtleAinda não há avaliações
- Modulo4 PontoFlutuanteDocumento23 páginasModulo4 PontoFlutuanteBrunaRochaAinda não há avaliações
- Atividade PO - Luiz HenriqueDocumento7 páginasAtividade PO - Luiz HenriqueLuiz Henrique Rodrigues FariasAinda não há avaliações
- Punto-De-Equilibrio-En-ExcelDocumento4 páginasPunto-De-Equilibrio-En-ExcelAriana RuizAinda não há avaliações
- Probabilidade e Estatística Aplicadas À Contabilidade I: Prof. Dr. Marcelo Botelho Da Costa MoraesDocumento46 páginasProbabilidade e Estatística Aplicadas À Contabilidade I: Prof. Dr. Marcelo Botelho Da Costa MoraesBarros ElenildoAinda não há avaliações
- Autovalores e AutovetoresDocumento62 páginasAutovalores e AutovetoresricardomartinsramosAinda não há avaliações
- Regressão Linear MúltiplaDocumento28 páginasRegressão Linear MúltiplaCarolaine Costa da SilvaAinda não há avaliações
- Medidas de Posição 2Documento29 páginasMedidas de Posição 2danielli.brumAinda não há avaliações
- Ponto de Equilíbrio - QuestõesDocumento23 páginasPonto de Equilíbrio - QuestõesJCavalcanti de OliveiraAinda não há avaliações
- Medidas de Diversidade BiológicaDocumento16 páginasMedidas de Diversidade BiológicaAlline Braga SilvaAinda não há avaliações
- Tabela de Preço - Normas ABNT AMN e ISO - 2019 (CRUB)Documento1 páginaTabela de Preço - Normas ABNT AMN e ISO - 2019 (CRUB)gustavo britoAinda não há avaliações
- Planilha de Gastos MensaisDocumento6 páginasPlanilha de Gastos Mensaisjacson marquesAinda não há avaliações
- Resolução de Sistema Por Gauss SeidelDocumento3 páginasResolução de Sistema Por Gauss SeidelPedro AndrettoAinda não há avaliações
- Tabela 2.1, 2.4 e 2.5Documento9 páginasTabela 2.1, 2.4 e 2.5Emerson CabralAinda não há avaliações
- Risco Por Operação Quantidade de Operações Taxa de Acerto R$ 40.00 50 70%Documento10 páginasRisco Por Operação Quantidade de Operações Taxa de Acerto R$ 40.00 50 70%Henrique AnticristoAinda não há avaliações
- Estudo de Msa Por Varic3a1veis RRDocumento2 páginasEstudo de Msa Por Varic3a1veis RRMATHEUS100% (1)
- Tratamento Por Fatores Imovel Rural 2Documento2 páginasTratamento Por Fatores Imovel Rural 2Isaque LealAinda não há avaliações
- Exp 2 - VerilogDocumento5 páginasExp 2 - VerilogGabriel NazarioAinda não há avaliações
- RESOLUÇÃO - Exercício 1 - Ponto de EquilíbrioDocumento11 páginasRESOLUÇÃO - Exercício 1 - Ponto de EquilíbrioSabrina SilvaAinda não há avaliações
- Redes Neurais ArtificiaisDocumento59 páginasRedes Neurais ArtificiaisMelquisedeque BenvindoAinda não há avaliações
- Aula 4 - 03 de Março de 2021Documento2 páginasAula 4 - 03 de Março de 2021Jhonathan RanniereAinda não há avaliações
- Ferramenta de Formao de Preo de VendaDocumento10 páginasFerramenta de Formao de Preo de VendaAllyson RodriguesAinda não há avaliações
- Desigualdade e Pobreza PDFDocumento33 páginasDesigualdade e Pobreza PDFLeonardo GuedesAinda não há avaliações
- Redes Neurais ArtificiaisDocumento59 páginasRedes Neurais ArtificiaisDiegoGonçalvesAinda não há avaliações
- Questões Dissertativas Dos Efeitos Dos Tributos Sobre PreçosDocumento8 páginasQuestões Dissertativas Dos Efeitos Dos Tributos Sobre PreçosHenrique FrangullysAinda não há avaliações
- Algebra BooleanaDocumento3 páginasAlgebra BooleanaSamuel RibeiroAinda não há avaliações
- v2 HT FT Stats Gestao de BancaDocumento170 páginasv2 HT FT Stats Gestao de BancaLucas ViniciusAinda não há avaliações
- Atividade 03 (RESOLUÇÃO)Documento5 páginasAtividade 03 (RESOLUÇÃO)Crislainy RiosAinda não há avaliações
- Sd10peac Exercícios Codificadores e DescodificadoresDocumento2 páginasSd10peac Exercícios Codificadores e Descodificadoresnuno silvestreAinda não há avaliações
- HT FT Stats Gestao de BancaDocumento171 páginasHT FT Stats Gestao de BancaRafael AlvesAinda não há avaliações
- Comparação Entre LançamentosDocumento38 páginasComparação Entre LançamentosIzabella D'PauloAinda não há avaliações
- Planilha Forex DólarDocumento10 páginasPlanilha Forex DólarGustavo ShockAinda não há avaliações
- Feiticeiros - Com - Tecnica - Editavel RaphaelaDocumento4 páginasFeiticeiros - Com - Tecnica - Editavel RaphaelaZe ninguem SouzaAinda não há avaliações
- Aula 27092022 Destilacao Retificacao ContDocumento13 páginasAula 27092022 Destilacao Retificacao ContThais OliveiraAinda não há avaliações
- Questoes de Estatisticas PDFDocumento5 páginasQuestoes de Estatisticas PDFCamilaAinda não há avaliações
- Relatorio Reflexao e RefracaoDocumento5 páginasRelatorio Reflexao e RefracaoAmandaBensiAinda não há avaliações
- Avaliaçao 9boxDocumento101 páginasAvaliaçao 9boxJosaneAinda não há avaliações
- Formato de Estado de Costos de Produccion y VentasDocumento21 páginasFormato de Estado de Costos de Produccion y Ventasdanna00cocoAinda não há avaliações
- Aula 05Documento31 páginasAula 05Arthur MeloAinda não há avaliações
- Slide JomarDocumento68 páginasSlide JomarKaiky WosllonAinda não há avaliações
- Custos - Equação UniprodutoDocumento11 páginasCustos - Equação UniprodutoSabrina SilvaAinda não há avaliações
- Aula 3 - Modelo de Regressão Múltipla - IntroduçãoDocumento8 páginasAula 3 - Modelo de Regressão Múltipla - IntroduçãoLeonel FerreiraAinda não há avaliações
- 1 Resolucao ExercicioDocumento7 páginas1 Resolucao ExercicioJessica SantosAinda não há avaliações
- Exercicios Metodos IterativosDocumento2 páginasExercicios Metodos IterativosJosé Henrique MerloAinda não há avaliações
- Lista de Exercícios 4 - MicroeconomiaDocumento5 páginasLista de Exercícios 4 - MicroeconomiaLeonardo BrognoliAinda não há avaliações
- Perceptron de Uma CamadaDocumento22 páginasPerceptron de Uma CamadaAri MacedoAinda não há avaliações
- Lista - de - Exerccios - 02 - Estrutura - de - Mercado - Comp. - Perfeita - e - Monoplio (1) Matheus FavaDocumento4 páginasLista - de - Exerccios - 02 - Estrutura - de - Mercado - Comp. - Perfeita - e - Monoplio (1) Matheus FavaGuilherme AndradeAinda não há avaliações
- Aula 3Documento4 páginasAula 3luiz schefferAinda não há avaliações
- Dickson Everton - Avaliação de Inferência em Estatística Aplicada A Avaliações de ImóveisDocumento7 páginasDickson Everton - Avaliação de Inferência em Estatística Aplicada A Avaliações de ImóveisArquimedesAinda não há avaliações
- Tomada de Decisão - Relação Custo X Volume X LucroDocumento49 páginasTomada de Decisão - Relação Custo X Volume X LucroMaicon OliveiraAinda não há avaliações
- 03 Engenharia de CardapioDocumento46 páginas03 Engenharia de CardapioIgue MorelliAinda não há avaliações
- ANOVA Caso No BalanceadoDocumento9 páginasANOVA Caso No Balanceadocamilo pardoAinda não há avaliações
- Apostila de Circuitos SequenciaisDocumento86 páginasApostila de Circuitos SequenciaisArmando Célio LealAinda não há avaliações
- Nota de Aula Regressão em DICDocumento9 páginasNota de Aula Regressão em DICDHEYNNE ALVESAinda não há avaliações
- Thiago Cambiaghi 10191Documento8 páginasThiago Cambiaghi 10191Grasi FerrazAinda não há avaliações
- Aula 01 - AnotaçõesDocumento26 páginasAula 01 - AnotaçõesJonatan CostaAinda não há avaliações
- Apresentação Aulas - ETAPA 4Documento75 páginasApresentação Aulas - ETAPA 4Marcio PaesAinda não há avaliações
- Métodos Numéricos - Aula 07 PDFDocumento33 páginasMétodos Numéricos - Aula 07 PDFPaulo Cec FigueredoAinda não há avaliações
- Cinemática 22 01Documento8 páginasCinemática 22 01Cristian Alexandre MoraesAinda não há avaliações
- Legislação ABINDocumento4 páginasLegislação ABINCristian Alexandre MoraesAinda não há avaliações
- Cinemática Escalar: Depende de Um Ponto de Referência Cliclista em Relação À Bicicleta Ciclista em Relação À ÁrvoreDocumento15 páginasCinemática Escalar: Depende de Um Ponto de Referência Cliclista em Relação À Bicicleta Ciclista em Relação À ÁrvoreCristian Alexandre MoraesAinda não há avaliações
- 539 1652 1 PBDocumento12 páginas539 1652 1 PBEduardo SBenettiAinda não há avaliações
- Soft SensorDocumento55 páginasSoft SensorCristian Alexandre MoraesAinda não há avaliações
- 20 Intervencoes Metalicas em Edificacoes de Valor HistricoDocumento15 páginas20 Intervencoes Metalicas em Edificacoes de Valor HistricoLuiza NadaluttiAinda não há avaliações
- Física I e Cálculo I - 2022Documento61 páginasFísica I e Cálculo I - 2022Cristian Alexandre MoraesAinda não há avaliações
- Manual de Capacitação em Resgate VeicularDocumento142 páginasManual de Capacitação em Resgate VeicularCristian Alexandre MoraesAinda não há avaliações
- Código Transito Brasileiro Lei 9503 de 1997Documento32 páginasCódigo Transito Brasileiro Lei 9503 de 1997ChatranAinda não há avaliações
- Aula PME ProbabilidadeDocumento124 páginasAula PME ProbabilidadeCristian Alexandre MoraesAinda não há avaliações
- Aula PME ProbabilidadeDocumento124 páginasAula PME ProbabilidadeCristian Alexandre MoraesAinda não há avaliações
- Carteira Recomendada Itaú de Fundos Imobiliários Fev 2020Documento25 páginasCarteira Recomendada Itaú de Fundos Imobiliários Fev 2020Cristian Alexandre MoraesAinda não há avaliações
- Case Anelise InvestimentosDocumento1 páginaCase Anelise InvestimentosCristian Alexandre MoraesAinda não há avaliações
- Código Transito Brasileiro Lei 9503 de 1997Documento32 páginasCódigo Transito Brasileiro Lei 9503 de 1997ChatranAinda não há avaliações
- Legislacao de Transito e Direcao Defensiva CFS e CFC Ten EidtDocumento71 páginasLegislacao de Transito e Direcao Defensiva CFS e CFC Ten EidtMatthew HarrisAinda não há avaliações
- Estagio - MotoresDocumento1 páginaEstagio - MotoresCristian Alexandre MoraesAinda não há avaliações
- Leandro CoelhoDocumento2 páginasLeandro CoelhoCristian Alexandre MoraesAinda não há avaliações
- Atualizacao MonetariaDocumento2 páginasAtualizacao MonetariaCristian Alexandre MoraesAinda não há avaliações
- Case Anelise InvestimentosDocumento1 páginaCase Anelise InvestimentosCristian Alexandre MoraesAinda não há avaliações
- Coligativas e ViscosidadeDocumento4 páginasColigativas e ViscosidadeCristian Alexandre MoraesAinda não há avaliações
- Legislacao de Transito e Direcao Defensiva CFS e CFC Ten EidtDocumento71 páginasLegislacao de Transito e Direcao Defensiva CFS e CFC Ten EidtMatthew HarrisAinda não há avaliações
- Apostila Produtos PerigososDocumento43 páginasApostila Produtos PerigososCristian Alexandre MoraesAinda não há avaliações
- Soraia Zaioncz BDocumento73 páginasSoraia Zaioncz BMônica MattanaAinda não há avaliações
- Apostila Maquinas Eletricas 1 - CEFET - SCDocumento49 páginasApostila Maquinas Eletricas 1 - CEFET - SCdanielcp0% (1)
- Apostila Produtos PerigososDocumento43 páginasApostila Produtos PerigososCristian Alexandre MoraesAinda não há avaliações
- Caterpillar Curso Cat Power TrainDocumento89 páginasCaterpillar Curso Cat Power TrainAndrei Bleoju93% (15)
- Estrutura Dos Materiais PolimericosDocumento14 páginasEstrutura Dos Materiais PolimericosAndré Luiz Dos SantosAinda não há avaliações
- Apostila Maquinas Eletricas 1 - CEFET - SCDocumento49 páginasApostila Maquinas Eletricas 1 - CEFET - SCdanielcp0% (1)
- Fundamentos de Circuitos Eletricos-Aula 2-V2Documento30 páginasFundamentos de Circuitos Eletricos-Aula 2-V2Cristian Alexandre MoraesAinda não há avaliações
- Modelagem Equacoes Estruturais PDFDocumento453 páginasModelagem Equacoes Estruturais PDFTiagoAinda não há avaliações
- Prova Soldado PM 2021 TIPO ADocumento23 páginasProva Soldado PM 2021 TIPO AkelsonbrotherAinda não há avaliações
- 3 PBDocumento4 páginas3 PBIsabela BuenoAinda não há avaliações
- Prescrição de Psico em Pacientes Com TPBDocumento9 páginasPrescrição de Psico em Pacientes Com TPBStéfanie FAinda não há avaliações
- You Are Dog ManDocumento23 páginasYou Are Dog ManKidsonAinda não há avaliações
- Carina Martiny Historia DissertaçãoDocumento366 páginasCarina Martiny Historia DissertaçãoArthur OrlandoAinda não há avaliações
- A Arte de Escrever CartasDocumento8 páginasA Arte de Escrever CartasJulia ValoisAinda não há avaliações
- 2tema - Conhecendo Algumas Ferramentas Utilizadas Nas Fases Do DMAIC PDFDocumento19 páginas2tema - Conhecendo Algumas Ferramentas Utilizadas Nas Fases Do DMAIC PDFfernandocrottiAinda não há avaliações
- Perfil de Metadados Geoespaciais Do Brasil - CONCARDocumento197 páginasPerfil de Metadados Geoespaciais Do Brasil - CONCARLaysson AlbuquerqueAinda não há avaliações
- Petrobrás - Pim ViDocumento20 páginasPetrobrás - Pim ViAlex SilvaAinda não há avaliações
- Poemas Infantis - Depois Da Página 216 PDFDocumento314 páginasPoemas Infantis - Depois Da Página 216 PDFJeanAinda não há avaliações
- Curso Insp DRS - Notas de AulaDocumento274 páginasCurso Insp DRS - Notas de AulaEduardo CalegarioAinda não há avaliações
- Espaços Educativos e Produção Das Subjetividades GaysDocumento25 páginasEspaços Educativos e Produção Das Subjetividades Gaysthaisrithielli1410Ainda não há avaliações
- Livro Levantamento Bibliografico Genero No Meio Rural DPMRDocumento243 páginasLivro Levantamento Bibliografico Genero No Meio Rural DPMRJo KuninAinda não há avaliações
- DISSERTAÇÃO - O Alinhamento Estratégico Da Gestão de Recursos HumanosDocumento109 páginasDISSERTAÇÃO - O Alinhamento Estratégico Da Gestão de Recursos HumanosAnderson OliveiraAinda não há avaliações
- Perfil Comunicativo de Seus Filhos AUTISMODocumento9 páginasPerfil Comunicativo de Seus Filhos AUTISMOSabrina ReisAinda não há avaliações
- Plano Trabalho PDFDocumento6 páginasPlano Trabalho PDFMarina MayaAinda não há avaliações
- AnteProjecto ShelseaDocumento22 páginasAnteProjecto Shelseabio afonsoAinda não há avaliações
- ANEXO I Roteiro PontuacIsectaI83o de CVDocumento3 páginasANEXO I Roteiro PontuacIsectaI83o de CVMateus Gregorio dos SantosAinda não há avaliações
- CORAZZA. 2002. Labirintos Da Pesquisa, Diante Dos FerrolhosDocumento15 páginasCORAZZA. 2002. Labirintos Da Pesquisa, Diante Dos FerrolhoskemilytoledoAinda não há avaliações
- Estatística - Avaliação FinalDocumento14 páginasEstatística - Avaliação FinalFausto JoseAinda não há avaliações
- Tornando-Se Pai, CLEBERDocumento12 páginasTornando-Se Pai, CLEBERgeovanaapdossantosAinda não há avaliações
- F.0023.09 - Modelo de Plano de Ação Corretiva - PacDocumento4 páginasF.0023.09 - Modelo de Plano de Ação Corretiva - PacSatya Franquilin Dos SantosAinda não há avaliações
- Validação de Método Analítico - Determinação de Cálcio em Águas Método Titulométrico Do Edta ComplexometriaDocumento6 páginasValidação de Método Analítico - Determinação de Cálcio em Águas Método Titulométrico Do Edta ComplexometriattattalittaAinda não há avaliações
- Apostila METODOLOGIA FAETERJDocumento40 páginasApostila METODOLOGIA FAETERJCLYBYOAinda não há avaliações
- OCIRDocumento76 páginasOCIRJAILENE PIRESAinda não há avaliações
- Livro Febrace Resumos 2009Documento354 páginasLivro Febrace Resumos 2009emersonsoutofiaAinda não há avaliações
- Diretrizes Metodológicas Reforço Escolar 2021Documento47 páginasDiretrizes Metodológicas Reforço Escolar 2021Helena Leandro de SousaAinda não há avaliações
- O Feminino Do Fim de AnaliseDocumento163 páginasO Feminino Do Fim de AnaliseLorena Amorelli ReinatoAinda não há avaliações