Você também pode gostar
- Guia Prático para Publicação de Dados Abertos Conectados na WebNo EverandGuia Prático para Publicação de Dados Abertos Conectados na WebAinda não há avaliações
- FCRB Vocabulario Sistematizado A Experiencia Da Fundacao Casa de Rui BarbosaDocumento18 páginasFCRB Vocabulario Sistematizado A Experiencia Da Fundacao Casa de Rui BarbosaMaria Dalva Pereira SouzaAinda não há avaliações
- Ferramentas de busca na InternetDocumento19 páginasFerramentas de busca na InternetRany PretaAinda não há avaliações
- Comparing bibliographic softwareDocumento11 páginasComparing bibliographic softwareNai AlflenAinda não há avaliações
- Projeto HipermídiaDocumento18 páginasProjeto HipermídiaJeferson CamargoAinda não há avaliações
- Dissertações em Literatura e Cinema. Florianópolis: SC, 2015Documento6 páginasDissertações em Literatura e Cinema. Florianópolis: SC, 2015Cedinho Chite Amine NhengaAinda não há avaliações
- Teoria do Conceito em Bibliotecas DigitaisDocumento13 páginasTeoria do Conceito em Bibliotecas DigitaisRicardo AlvesAinda não há avaliações
- Trabalho Final - Artigo Modelos Conceituais RDA - Ana Lúcia TiagoDocumento14 páginasTrabalho Final - Artigo Modelos Conceituais RDA - Ana Lúcia TiagoFrederico HipólitoAinda não há avaliações
- Design de Periódios CientíficosDocumento11 páginasDesign de Periódios CientíficosDhanielle EvangelistaAinda não há avaliações
- Comparativo de softwares de referênciasDocumento11 páginasComparativo de softwares de referênciasRafaelAinda não há avaliações
- Os Conceitos Básicos Da Tecnologia Da Informação e Comunicação (TICS) para o Entendimento Dos FRBR: A Experiência Da UFRJDocumento11 páginasOs Conceitos Básicos Da Tecnologia Da Informação e Comunicação (TICS) para o Entendimento Dos FRBR: A Experiência Da UFRJGEPCAT - Grupo de Estudos e Pesquisas em CatalogaçãoAinda não há avaliações
- Linked data prototype for semantic catalogingDocumento18 páginasLinked data prototype for semantic catalogingMaria Vilani Alves MoscatelliAinda não há avaliações
- Letramento digital: conceito em revisão sistemáticaDocumento14 páginasLetramento digital: conceito em revisão sistemáticaadrinalvesAinda não há avaliações
- Modelagem de Bibliotecas Digitais Usando A Abordagem 5S - Um Estudo de CasoDocumento14 páginasModelagem de Bibliotecas Digitais Usando A Abordagem 5S - Um Estudo de CasoCidaOliveiraAinda não há avaliações
- EstigmaEsquizofrenia ERMAC2023 v4 IdentificadoDocumento8 páginasEstigmaEsquizofrenia ERMAC2023 v4 IdentificadoRogério MainardesAinda não há avaliações
- Interoperabilidade No Uso de Esquemas de Metadados para Disseminação de Informação ArquivísticaDocumento13 páginasInteroperabilidade No Uso de Esquemas de Metadados para Disseminação de Informação ArquivísticaisraelAinda não há avaliações
- Perspectivas da Biblioteconomia de Dados e do Bibliotecário de DadosDocumento20 páginasPerspectivas da Biblioteconomia de Dados e do Bibliotecário de DadosFrederico HipólitoAinda não há avaliações
- Novas tecnologias, novas mídias: aprimorando a interface para escolha de bases e periódicosDocumento16 páginasNovas tecnologias, novas mídias: aprimorando a interface para escolha de bases e periódicosNilson CortesAinda não há avaliações
- Buchingeretalli2014 MBA AnalisequantitativaDocumento14 páginasBuchingeretalli2014 MBA AnalisequantitativaLeonardo GiannineAinda não há avaliações
- Artigo Satisfação Usuário Sistemas InformaçãoDocumento12 páginasArtigo Satisfação Usuário Sistemas InformaçãoblackguiitarAinda não há avaliações
- Revisão da Literatura IntegradoraDocumento17 páginasRevisão da Literatura IntegradorarochinhaadryaAinda não há avaliações
- Modelo CIDOC CRMDocumento7 páginasModelo CIDOC CRMBernardo ArribadaAinda não há avaliações
- Projeto OntolegisDocumento10 páginasProjeto OntolegisontolegisAinda não há avaliações
- As bibliotecas universitárias brasileiras e as plataformas de serviçosDocumento13 páginasAs bibliotecas universitárias brasileiras e as plataformas de serviçosAna GattoAinda não há avaliações
- Bibliometria, Cientometria, Infometria e WebometriaDocumento5 páginasBibliometria, Cientometria, Infometria e WebometriaJosué SallesAinda não há avaliações
- TESAURO Linguagem de Representação Da Memória Documentária PDFDocumento119 páginasTESAURO Linguagem de Representação Da Memória Documentária PDFnubinanda85% (13)
- 161 203 1 PBDocumento13 páginas161 203 1 PBJanice AbreuAinda não há avaliações
- Classificação de Documentos de Patentes Usando o Doc2vecDocumento12 páginasClassificação de Documentos de Patentes Usando o Doc2vecKelby1981Ainda não há avaliações
- Lima 2007Documento11 páginasLima 2007Leonora DuarteAinda não há avaliações
- 1206-Texto Do Artigo-4741-1-10-20210802Documento21 páginas1206-Texto Do Artigo-4741-1-10-20210802Guilherme Matheus Pereira DiasAinda não há avaliações
- Ferramentas Web para A Construção de Uma BibliotecaDocumento16 páginasFerramentas Web para A Construção de Uma BibliotecaCibele Vasconcelos DziekaniakAinda não há avaliações
- Bibliotecas Digitais e MetadadosDocumento10 páginasBibliotecas Digitais e MetadadosPrince JuniorAinda não há avaliações
- 2011 - Analise de Redes de Coautoria Por Meio de Redes SemânticasDocumento12 páginas2011 - Analise de Redes de Coautoria Por Meio de Redes SemânticasAbilio PeixotoAinda não há avaliações
- Paradigma Colaborativo: Desafios, Metáforas e Práticas de Análise Collaborative Paradigm: Challenges, Metaphors and Analysis PracticesDocumento20 páginasParadigma Colaborativo: Desafios, Metáforas e Práticas de Análise Collaborative Paradigm: Challenges, Metaphors and Analysis Practicesmiriam moraesAinda não há avaliações
- VANTI, Nadia Auroura P. Da Bibliometria À Webometria.Documento11 páginasVANTI, Nadia Auroura P. Da Bibliometria À Webometria.marlon_francis1Ainda não há avaliações
- Boletim Informativo KatiussaDocumento3 páginasBoletim Informativo KatiussaRogeria FariaAinda não há avaliações
- Obtenção de Sucesso em Buscas Por Usuários Do Portal de Periódicos Da CAPESDocumento12 páginasObtenção de Sucesso em Buscas Por Usuários Do Portal de Periódicos Da CAPESDebora VianaAinda não há avaliações
- Apresentação Conferencia em Maputo FIMDocumento24 páginasApresentação Conferencia em Maputo FIMUlysses VarelaAinda não há avaliações
- PDF - 9fd59eb3a9 - 0012231 POTENCIAIS APLICAÇÕES DA INTELIGÊNCIADocumento16 páginasPDF - 9fd59eb3a9 - 0012231 POTENCIAIS APLICAÇÕES DA INTELIGÊNCIAcatia.santosAinda não há avaliações
- Trajetória de pesquisa sobre podcastsDocumento15 páginasTrajetória de pesquisa sobre podcastsGessiela SilvaAinda não há avaliações
- Metadados interoperáveis TCC UFESDocumento39 páginasMetadados interoperáveis TCC UFESisraelAinda não há avaliações
- Resumo Da Obra Dinamica Da Pesquisa em Ciencias Sociais Os Polos Da Pratica MetodologicaDocumento32 páginasResumo Da Obra Dinamica Da Pesquisa em Ciencias Sociais Os Polos Da Pratica Metodologicarronaldofpinho100% (1)
- 380 1286 1 PBDocumento18 páginas380 1286 1 PBJanice AbreuAinda não há avaliações
- Minicurso ENUCOMPI 2019Documento18 páginasMinicurso ENUCOMPI 2019RicoSuheteAinda não há avaliações
- Biblioteca, Eder Eugênio MunhãoDocumento17 páginasBiblioteca, Eder Eugênio MunhãommanooAinda não há avaliações
- Livro Dados Abertos Interligados 2021Documento128 páginasLivro Dados Abertos Interligados 2021Rita LaipeltAinda não há avaliações
- ArquivometriaDocumento16 páginasArquivometriataelmichaelAinda não há avaliações
- Comparação Modelos Organização Informação Dublin Core MIPDocumento3 páginasComparação Modelos Organização Informação Dublin Core MIPRodel LeitãoAinda não há avaliações
- Repositórios de informação para promover literaciaDocumento5 páginasRepositórios de informação para promover literaciaJuliana BragaAinda não há avaliações
- Febab, ArtigoDocumento16 páginasFebab, ArtigoNilson CortesAinda não há avaliações
- Atividade 3 BIBDDocumento2 páginasAtividade 3 BIBDTHYAGO JORGE MACHADOAinda não há avaliações
- Fundamentos de Biblioteconomia e Ciência Da InformaçãoDocumento178 páginasFundamentos de Biblioteconomia e Ciência Da InformaçãoTaís Silva100% (4)
- Informação e redes sociais: Interfaces de teorias, métodos e objetosNo EverandInformação e redes sociais: Interfaces de teorias, métodos e objetosAinda não há avaliações
- Comunicação, Tecnologias Interativas e Educação: (Re)Pensar o Ensinar-Aprender na Cultura DigitalNo EverandComunicação, Tecnologias Interativas e Educação: (Re)Pensar o Ensinar-Aprender na Cultura DigitalAinda não há avaliações
- Fontes de Informação na Área de Saúde: Conteúdo, Funcionalidade e Recuperação da InformaçãoNo EverandFontes de Informação na Área de Saúde: Conteúdo, Funcionalidade e Recuperação da InformaçãoAinda não há avaliações
- Gestão de documentos arquivísticos digitais para a Rede Federal de Educação Profissional, Científica e TecnológicaNo EverandGestão de documentos arquivísticos digitais para a Rede Federal de Educação Profissional, Científica e TecnológicaAinda não há avaliações
- O Rio de 1860 Pela Revista Semana IlustradaDocumento25 páginasO Rio de 1860 Pela Revista Semana IlustradaRenan Rivaben PereiraAinda não há avaliações
- Artigo - Abordagem Clínica Da InformacaoDocumento28 páginasArtigo - Abordagem Clínica Da InformacaoESTELA DE CARVALHO NUNESAinda não há avaliações
- Cronograma aulas EUSC 2022.2Documento1 páginaCronograma aulas EUSC 2022.2ESTELA DE CARVALHO NUNESAinda não há avaliações
- CDU Historico e DesenvolviimentoDocumento23 páginasCDU Historico e DesenvolviimentoESTELA DE CARVALHO NUNESAinda não há avaliações
- Slides Sobre Sri ConceitosDocumento29 páginasSlides Sobre Sri ConceitosESTELA DE CARVALHO NUNESAinda não há avaliações
- CAPITULO - Acesso Aberto - Costa e Leite 2013Documento18 páginasCAPITULO - Acesso Aberto - Costa e Leite 2013ESTELA DE CARVALHO NUNESAinda não há avaliações
- Marcia AbreuDocumento23 páginasMarcia AbreuLine FSilvaAinda não há avaliações
- ARTIGO Estudo - Das - Similaridades - Entre - A - Teoria COMUNICACAO E RECUPERAÇÃO DA INFODocumento11 páginasARTIGO Estudo - Das - Similaridades - Entre - A - Teoria COMUNICACAO E RECUPERAÇÃO DA INFOESTELA DE CARVALHO NUNESAinda não há avaliações
- Dissertação Gestão Dos Metadados Contidos NosDocumento150 páginasDissertação Gestão Dos Metadados Contidos NosESTELA DE CARVALHO NUNESAinda não há avaliações
- 120 Termos Técnicos Dos SistemasDocumento1 página120 Termos Técnicos Dos SistemasESTELA DE CARVALHO NUNESAinda não há avaliações
- Slides Aula 2 - Conceito de UsuárioDocumento6 páginasSlides Aula 2 - Conceito de UsuárioESTELA DE CARVALHO NUNESAinda não há avaliações
- Plano de Aula - EuscDocumento4 páginasPlano de Aula - EuscESTELA DE CARVALHO NUNESAinda não há avaliações
- Artigo Usuários RochaDocumento18 páginasArtigo Usuários RochaESTELA DE CARVALHO NUNESAinda não há avaliações
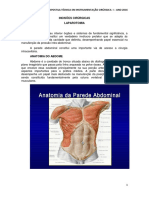
- Incisões cirúrgicas abdominaisDocumento8 páginasIncisões cirúrgicas abdominaisESTELA DE CARVALHO NUNESAinda não há avaliações
- SSD DetalhesDocumento1 páginaSSD DetalhesESTELA DE CARVALHO NUNESAinda não há avaliações
- Resumo FRIEDRICH HAYAEKDocumento2 páginasResumo FRIEDRICH HAYAEKESTELA DE CARVALHO NUNESAinda não há avaliações
- Resumo Supermarket3Documento2 páginasResumo Supermarket3ESTELA DE CARVALHO NUNESAinda não há avaliações
- Por Uma Biblioteconomia Mais Social: Interfaces E PerspectivasDocumento17 páginasPor Uma Biblioteconomia Mais Social: Interfaces E PerspectivasESTELA DE CARVALHO NUNESAinda não há avaliações
- Amor ImpossívelDocumento2 páginasAmor ImpossívelESTELA DE CARVALHO NUNESAinda não há avaliações
- Arte Paleolítica: Pinturas RupestresDocumento3 páginasArte Paleolítica: Pinturas RupestresESTELA DE CARVALHO NUNESAinda não há avaliações
- Roteiro Do Relatorio de LeituraDocumento2 páginasRoteiro Do Relatorio de LeituraESTELA DE CARVALHO NUNESAinda não há avaliações
- Termo de opção odontológica StefaniniDocumento2 páginasTermo de opção odontológica StefaniniESTELA DE CARVALHO NUNESAinda não há avaliações
- Programa Da DisciplinaDocumento3 páginasPrograma Da DisciplinaESTELA DE CARVALHO NUNESAinda não há avaliações
- ANOTAÇÕES DE Sentido e Forma Da Produção ArtísticaDocumento2 páginasANOTAÇÕES DE Sentido e Forma Da Produção ArtísticaESTELA DE CARVALHO NUNESAinda não há avaliações
- Programa Estudos UsuariosDocumento4 páginasPrograma Estudos UsuariosESTELA DE CARVALHO NUNESAinda não há avaliações
- E-Book Leitura Crítica Na ContemporaneidadeDocumento155 páginasE-Book Leitura Crítica Na ContemporaneidadeAndreina Alves de Sousa VirginioAinda não há avaliações
- Fontes Informação Bibliotecas UNIRIODocumento6 páginasFontes Informação Bibliotecas UNIRIOESTELA DE CARVALHO NUNESAinda não há avaliações
- ARTIGO Do Documento Impresso À Informação Nas Nuvens ReflexõesDocumento24 páginasARTIGO Do Documento Impresso À Informação Nas Nuvens ReflexõesESTELA DE CARVALHO NUNESAinda não há avaliações
- ARTIGO Periodicos Cientificos Eletronicos HistoricoDocumento10 páginasARTIGO Periodicos Cientificos Eletronicos HistoricoESTELA DE CARVALHO NUNESAinda não há avaliações
- ARTIGO Publicações Científicas Eletrônicas No Brasil Mudanças NaDocumento15 páginasARTIGO Publicações Científicas Eletrônicas No Brasil Mudanças NaESTELA DE CARVALHO NUNESAinda não há avaliações
- Estrategias de EnsingemDocumento21 páginasEstrategias de Ensingemdavidvieira2Ainda não há avaliações
- Comunicacao Empresarial 2018Documento192 páginasComunicacao Empresarial 2018Matheus MottaAinda não há avaliações
- Respostas de um Lama sobre temas esotéricosDocumento18 páginasRespostas de um Lama sobre temas esotéricosteddmAinda não há avaliações
- LIVRO 8 O Ensino Mat Ed InclusivaDocumento130 páginasLIVRO 8 O Ensino Mat Ed InclusivaGustavo FrançaAinda não há avaliações
- Joao Paulo HergeselDocumento15 páginasJoao Paulo HergeselValeska MacedoAinda não há avaliações
- Internet influencia pensamento superficialmenteDocumento16 páginasInternet influencia pensamento superficialmenteDavi MendesAinda não há avaliações
- Fundamentos das Ciências da ReligiaoDocumento74 páginasFundamentos das Ciências da ReligiaoElias DamasioAinda não há avaliações
- AS POLÍTICAS PÚBLICAS EDUCACIONAIS DO PROGRAMADocumento11 páginasAS POLÍTICAS PÚBLICAS EDUCACIONAIS DO PROGRAMALuana SilveiraAinda não há avaliações
- 8564-Texto Do Artigo-25341-1-10-20170223Documento3 páginas8564-Texto Do Artigo-25341-1-10-20170223Carina TakeshitaAinda não há avaliações
- Martin: BuberDocumento125 páginasMartin: BuberDizendo da HenryAinda não há avaliações
- Os Sete Princípios Da ABA - Análise DiagnósticaDocumento31 páginasOs Sete Princípios Da ABA - Análise Diagnósticajulia.uriasAinda não há avaliações
- Relações Étnico-Raciais e Direitos HumanosDocumento87 páginasRelações Étnico-Raciais e Direitos HumanosCarlo FuentesAinda não há avaliações
- Caderno de Resumo 4-5 SemDocumento51 páginasCaderno de Resumo 4-5 SemManu LuizeAinda não há avaliações
- Relatório de ObraDocumento13 páginasRelatório de ObraSoldado Nutella100% (1)
- Livro Saúde Das Crianças Menores de 5 Anos em Cabo Verde - Minist Saúde e UNICEF - 1996Documento76 páginasLivro Saúde Das Crianças Menores de 5 Anos em Cabo Verde - Minist Saúde e UNICEF - 1996ABAmadoAinda não há avaliações
- Reestrutura UEPA com novos níveis de atuaçãoDocumento16 páginasReestrutura UEPA com novos níveis de atuaçãoAline CardosoAinda não há avaliações
- Avaliações de disciplina histórico-filosófica da educaçãoDocumento5 páginasAvaliações de disciplina histórico-filosófica da educaçãoKlayton Lima75% (28)
- Objetivos de pesquisa na metodologia científicaDocumento10 páginasObjetivos de pesquisa na metodologia científicaGabriel ErnstAinda não há avaliações
- APOSTILA DE MIC PDF (Incompleta) - 084906Documento38 páginasAPOSTILA DE MIC PDF (Incompleta) - 084906Joseph Van-DunemAinda não há avaliações
- TCC BimDocumento77 páginasTCC BimCesarrizzofiuzaAinda não há avaliações
- Clima Escolar em Escolas de Alto e Baixo PrestigioDocumento20 páginasClima Escolar em Escolas de Alto e Baixo PrestigioEric SantosAinda não há avaliações
- MJI - Exercicios - Saber Juridico - Guiao - Denisse DananeDocumento3 páginasMJI - Exercicios - Saber Juridico - Guiao - Denisse DananeShirley JanfarAinda não há avaliações
- Resumo - Mundo de SofiaDocumento36 páginasResumo - Mundo de SofiaGabriel LunaAinda não há avaliações
- EDUARDO JORGE TEODÓSIO GONÇALVES NEVES - DISSERTAÇÃO (PPGDesign) 2020Documento137 páginasEDUARDO JORGE TEODÓSIO GONÇALVES NEVES - DISSERTAÇÃO (PPGDesign) 2020gian piorskyAinda não há avaliações
- Estrutura e AçãoDocumento35 páginasEstrutura e Açãorodau100% (1)
- Administração de Recursos e Materiais LivroDocumento158 páginasAdministração de Recursos e Materiais LivroJéssica RodriguesAinda não há avaliações
- Comparações culturais e conceitos de poderDocumento13 páginasComparações culturais e conceitos de poderMichel AugustoAinda não há avaliações
- Entrevistas em profundidade na pesquisa qualitativa em AdministraçãoDocumento12 páginasEntrevistas em profundidade na pesquisa qualitativa em AdministraçãoSilvia CarvalhoAinda não há avaliações
- Metodologias ativas no ensino de CiênciasDocumento20 páginasMetodologias ativas no ensino de Ciênciasanon_883543840Ainda não há avaliações
- Sobre A Educação Estética Do HomemDocumento12 páginasSobre A Educação Estética Do HomemLeandro NascimentoAinda não há avaliações