
Você também pode gostar
- Nomes Dos ConsultoriosDocumento60 páginasNomes Dos ConsultoriosJackson MartinsAinda não há avaliações
- O Balanço De Carbono Na Produção De Cana-de-açucarNo EverandO Balanço De Carbono Na Produção De Cana-de-açucarAinda não há avaliações
- Triagem Neonatal PDFDocumento92 páginasTriagem Neonatal PDFGiovannaAinda não há avaliações
- Psicologia ForenseDocumento127 páginasPsicologia ForenseSandro Alex100% (1)
- Introdução À Programação Para Bioinformática Com PerlNo EverandIntrodução À Programação Para Bioinformática Com PerlAinda não há avaliações
- As sete ferramentas da qualidade para melhoria contínuaDocumento41 páginasAs sete ferramentas da qualidade para melhoria contínuaDavid Silva100% (1)
- Instrumentação e Controle PDFDocumento143 páginasInstrumentação e Controle PDFJorge VilaAinda não há avaliações
- Levantamento BotânicoDocumento106 páginasLevantamento Botânicogustavo PinheiroAinda não há avaliações
- Roteiro de aulas práticas de histologia da Universidade Federal da Grande DouradosDocumento66 páginasRoteiro de aulas práticas de histologia da Universidade Federal da Grande DouradosKenia GomezAinda não há avaliações
- Diagnóstico Da Cadeia Produtiva Da Pecuária de CorteDocumento161 páginasDiagnóstico Da Cadeia Produtiva Da Pecuária de CorteFórum de Desenvolvimento do Rio50% (2)
- Detetive Por Um Dia: Aprendendo A Investigar Por Meio Da Química ForenseNo EverandDetetive Por Um Dia: Aprendendo A Investigar Por Meio Da Química ForenseAinda não há avaliações
- Clínica Médica - TVP TEP FinalDocumento38 páginasClínica Médica - TVP TEP FinalTomazia Rakielle Estrela de OliveiraAinda não há avaliações
- Astro-Diagnose - Um Guia para A Cura Definitiva - Max Heindel e Augusta Foss HeindelDocumento425 páginasAstro-Diagnose - Um Guia para A Cura Definitiva - Max Heindel e Augusta Foss HeindelCARLOS GUITTIAinda não há avaliações
- Ee Dr. Eloy De Miranda Chaves 2023No EverandEe Dr. Eloy De Miranda Chaves 2023Ainda não há avaliações
- Seleção ClonalDocumento81 páginasSeleção ClonalSuellen CostaAinda não há avaliações
- Apostila+Final+ +Analista+de+ContasDocumento158 páginasApostila+Final+ +Analista+de+ContasEdilson SilvaAinda não há avaliações
- Assinaturas DigitaisDocumento103 páginasAssinaturas DigitaispaulinoAinda não há avaliações
- Patologia Veterinária Especial de Cães e GatosDocumento219 páginasPatologia Veterinária Especial de Cães e GatosAriadne Nascimento75% (4)
- Docência em Saúde: Hipertensão E Diabetes Mellitus em Cães E GatosDocumento165 páginasDocência em Saúde: Hipertensão E Diabetes Mellitus em Cães E GatosLouise Maciel FernandesAinda não há avaliações
- Estatísticas de Acidentes no TrabalhoDocumento45 páginasEstatísticas de Acidentes no TrabalhoMarcia Cristina OliveiraAinda não há avaliações
- Astro Diagnose Um Guia para A Cura Definitiva Max Heindel e Augusta Foss Heindel PDFDocumento425 páginasAstro Diagnose Um Guia para A Cura Definitiva Max Heindel e Augusta Foss Heindel PDFmarcia_tra100% (1)
- Manual Do Sih Sus Dez 2004Documento113 páginasManual Do Sih Sus Dez 2004Rock SanttanaAinda não há avaliações
- 6 PPRA UDESC CEFID Florian Polis 2019 Rev 02 16009719364972 13388Documento68 páginas6 PPRA UDESC CEFID Florian Polis 2019 Rev 02 16009719364972 13388Gilberto CamposAinda não há avaliações
- Sistema para Cálculos de TrefilaDocumento69 páginasSistema para Cálculos de TrefilaVinicius Prates SilvaAinda não há avaliações
- SESI-SP - Manual Saude Na GalvanoplastiaDocumento133 páginasSESI-SP - Manual Saude Na GalvanoplastiaXray UandAinda não há avaliações
- Banco de Dados RelacionalDocumento55 páginasBanco de Dados RelacionalRogério JamasAinda não há avaliações
- Banco de Dados para Tratamentos de EletroquimioterapiaDocumento29 páginasBanco de Dados para Tratamentos de EletroquimioterapiaSydAinda não há avaliações
- Curso Arduino CompletoDocumento90 páginasCurso Arduino CompletoGleison PilotAinda não há avaliações
- A Responsabilidade Civil Do Anestesiologista 2020Documento147 páginasA Responsabilidade Civil Do Anestesiologista 2020Igor MascarenhasAinda não há avaliações
- Livro Marketing EstratégicoDocumento48 páginasLivro Marketing EstratégicoSILDO PEDRO SOUSA CORDOVILAinda não há avaliações
- Projeto Barra de CerealDocumento70 páginasProjeto Barra de CerealLilian Dos AnjosAinda não há avaliações
- Ito 30 Atendimento A Tentativas de Suicídio CBMMG Separata 13 31 - 03 - 2021Documento67 páginasIto 30 Atendimento A Tentativas de Suicídio CBMMG Separata 13 31 - 03 - 2021Daniel MarquesAinda não há avaliações
- Resumo de pensadores das humanidadesDocumento288 páginasResumo de pensadores das humanidadesRafael Macedo Barcelos100% (2)
- Relatório de EstágioDocumento57 páginasRelatório de EstágioPamela AraiAinda não há avaliações
- Rede SeniorDocumento44 páginasRede SeniorDébora :-DAinda não há avaliações
- Estrutura Do ProjetoDocumento20 páginasEstrutura Do Projeto141.1415Ainda não há avaliações
- Introdução à programação e ADVPL básicoDocumento216 páginasIntrodução à programação e ADVPL básicoCaio ChimAinda não há avaliações
- QVT dos funcionários de escola: um estudo de casoDocumento80 páginasQVT dos funcionários de escola: um estudo de casoRaphael Fialho100% (1)
- Apostila de Eletronica AnologicaDocumento109 páginasApostila de Eletronica AnologicaOldemiro Danie LAinda não há avaliações
- Apostila - 01 - Introdução À Avaliação Da Aptidão FísicaDocumento92 páginasApostila - 01 - Introdução À Avaliação Da Aptidão FísicaLíss FlächAinda não há avaliações
- NR 23 - Brigada 912Documento110 páginasNR 23 - Brigada 912CPSSTAinda não há avaliações
- Manual Sisgado EsDocumento63 páginasManual Sisgado EsCésar Bonifaz100% (1)
- Drogasde AbusoDocumento128 páginasDrogasde AbusoJerry RodriguesAinda não há avaliações
- Apostila Excel 2Documento50 páginasApostila Excel 2Thais Fernanda GuimarãesAinda não há avaliações
- Manual do sistema de pregão eletrônico Licitações-e do BBDocumento48 páginasManual do sistema de pregão eletrônico Licitações-e do BBPaula Tavares AmorimAinda não há avaliações
- Apostila de PTSDocumento28 páginasApostila de PTSMatheus HeraclioAinda não há avaliações
- Tutorial de Testes em Avaliação Motora em Atividade Física e Treinamento DesportivoDocumento31 páginasTutorial de Testes em Avaliação Motora em Atividade Física e Treinamento DesportivoedueapxAinda não há avaliações
- Cap. PLANTÃO PSICOLÓGICO ON-LINE: EXPERIÊNCIA E PRÁTICA A PARTIR DA ABORDAGEM PSICANALÍTICADocumento21 páginasCap. PLANTÃO PSICOLÓGICO ON-LINE: EXPERIÊNCIA E PRÁTICA A PARTIR DA ABORDAGEM PSICANALÍTICAPamela StalianoAinda não há avaliações
- PLANO-DE-GERENCIAMENTO-DE-RESIDUOS-PGRS - Modelo PDFDocumento36 páginasPLANO-DE-GERENCIAMENTO-DE-RESIDUOS-PGRS - Modelo PDFLucas JoahayAinda não há avaliações
- O Guia Da Quimica No Enem - Professor Douglas Cazaroti PDFDocumento348 páginasO Guia Da Quimica No Enem - Professor Douglas Cazaroti PDFLetícia CurciAinda não há avaliações
- Diabetes DefinitivoDocumento60 páginasDiabetes DefinitivoJaime VungoAinda não há avaliações
- A Promédica promove a saúde e o atendimento médico de qualidadeDocumento188 páginasA Promédica promove a saúde e o atendimento médico de qualidadealexsandranascimentoAinda não há avaliações
- Graxeiras IMECEDocumento38 páginasGraxeiras IMECEDiaploxAinda não há avaliações
- Defeitos - Defeitos em Estruturas Cerà MicasDocumento88 páginasDefeitos - Defeitos em Estruturas Cerà MicasJoão Gabriel LacAinda não há avaliações
- BI em Dados AcadêmicosDocumento14 páginasBI em Dados AcadêmicosWashington PatyAinda não há avaliações
- Big Data - Analisando Os DadosDocumento13 páginasBig Data - Analisando Os DadosWashington PatyAinda não há avaliações
- Variação linguística e norma-padrãoDocumento31 páginasVariação linguística e norma-padrãoJanus JuniorAinda não há avaliações
- Couch DB Big DataDocumento13 páginasCouch DB Big DataWashington PatyAinda não há avaliações
- Trabalho Big Data 2Documento7 páginasTrabalho Big Data 2Washington PatyAinda não há avaliações
- Prêmio reconhece excelência profissionalDocumento150 páginasPrêmio reconhece excelência profissionalFrancisco Vincente da SilvaAinda não há avaliações
- Aph Coe - PmesDocumento54 páginasAph Coe - PmesLucas Lessa89% (9)
- TC RM EncéfaloDocumento6 páginasTC RM EncéfaloLuis Mateus Camelo França MartinsAinda não há avaliações
- Caso Clínico IV DEMENCIA FRONRO TEMPORALDocumento16 páginasCaso Clínico IV DEMENCIA FRONRO TEMPORALViviane CoelhoAinda não há avaliações
- Treinamento BenzenoDocumento19 páginasTreinamento BenzenoLuiz Carlos DiasAinda não há avaliações
- Protocolo de Regulação de Acesso para Tratamento de CâncerDocumento7 páginasProtocolo de Regulação de Acesso para Tratamento de CâncerbeatrizsdiasAinda não há avaliações
- Câncer de mama: ações educativas para o autoexameDocumento37 páginasCâncer de mama: ações educativas para o autoexameVanessa BorgesAinda não há avaliações
- Exame Dermatológico OSCEDocumento1 páginaExame Dermatológico OSCEPedro CabralAinda não há avaliações
- Lesões Celulares Reversiveis e IrreversíveisDocumento30 páginasLesões Celulares Reversiveis e IrreversíveisRoberto Oliveira0% (1)
- Sistema linfático e massagem redutoraDocumento50 páginasSistema linfático e massagem redutoraAline MoraesAinda não há avaliações
- Ficha Avaliação NeurofuncionalDocumento8 páginasFicha Avaliação NeurofuncionalCaiani Dias Da SilvaAinda não há avaliações
- Metabolismo Do Ácido Úrico e Doença Renal Associada A Ácido ÚricoDocumento30 páginasMetabolismo Do Ácido Úrico e Doença Renal Associada A Ácido ÚricoDavid Muniz0% (1)
- Radiografia Tórax NormalDocumento16 páginasRadiografia Tórax NormaldecoswarAinda não há avaliações
- Tabela-De-Reconstituicao-E-Diluicao-De-Antimicrobianos-E-Posologia UPADocumento10 páginasTabela-De-Reconstituicao-E-Diluicao-De-Antimicrobianos-E-Posologia UPAnaguiar.prAinda não há avaliações
- Avaliação GeriátricaDocumento8 páginasAvaliação GeriátricaGabriela Oliveira100% (1)
- Citomegalovírus CongênitoDocumento2 páginasCitomegalovírus CongênitoGiovanna Maia CartaxoAinda não há avaliações
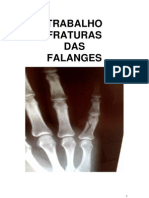
- PPAR - Fraturas de FalangesDocumento10 páginasPPAR - Fraturas de FalangesFábio FelixAinda não há avaliações
- Pro - Med-Obs.005 - V4 CardiotocografiaDocumento7 páginasPro - Med-Obs.005 - V4 CardiotocografiaqdabliuAinda não há avaliações
- Doenças infecto-contagiosas no BrasilDocumento59 páginasDoenças infecto-contagiosas no BrasilJonatan Montano Ruiz morenoAinda não há avaliações
- ImunopatologiaDocumento9 páginasImunopatologiaOsvaldo FariaAinda não há avaliações
- Para Além Da DMDocumento1 páginaPara Além Da DMAndré FernandesAinda não há avaliações
- Aula 25 - Perda Visual Aguda - Trauma OcularDocumento2 páginasAula 25 - Perda Visual Aguda - Trauma Ocularleticiabellin1108Ainda não há avaliações
- ECG Normal em ImagensDocumento61 páginasECG Normal em ImagensVigariooAinda não há avaliações
- Estudo Dirigido OdontogeriatriaDocumento18 páginasEstudo Dirigido Odontogeriatriajosias schaefferAinda não há avaliações
- Coleta de sangue: fundamentos e técnicaDocumento57 páginasColeta de sangue: fundamentos e técnicaJéssica TelesAinda não há avaliações
- E Book Disc 25 Acao Educativa Do A Acs Na Prevencao e Controle Das Doencas e Agravos Com Enfoque Nas Doencas Nao Transmissiveis 1684279938Documento53 páginasE Book Disc 25 Acao Educativa Do A Acs Na Prevencao e Controle Das Doencas e Agravos Com Enfoque Nas Doencas Nao Transmissiveis 1684279938LucivanioAinda não há avaliações
- Ultra-som obstétrico: avaliação fetal e gestacionalDocumento5 páginasUltra-som obstétrico: avaliação fetal e gestacionalKaline AlencarAinda não há avaliações
- Bula IVERMECTINADocumento9 páginasBula IVERMECTINAPatricia MeloAinda não há avaliações
- Aula EsquistossomoseDocumento51 páginasAula Esquistossomoseapi-3703629100% (3)
- Avaliação Doença Laboral e OcupacionalDocumento2 páginasAvaliação Doença Laboral e OcupacionalTereza Cristina Lima CostaAinda não há avaliações
- TDAH em Adultos - Como Reconhecer e Lidar Com Adultos Que Sofrem de TDAH Em 30 Passos SimplesNo EverandTDAH em Adultos - Como Reconhecer e Lidar Com Adultos Que Sofrem de TDAH Em 30 Passos SimplesNota: 4.5 de 5 estrelas4.5/5 (8)
- S.O.S. Autismo: Guia completo para entender o transtorno do espectro autistaNo EverandS.O.S. Autismo: Guia completo para entender o transtorno do espectro autistaNota: 4.5 de 5 estrelas4.5/5 (11)
- Manual Prático de Técnica Operatória e Cirurgia ExperimentalNo EverandManual Prático de Técnica Operatória e Cirurgia ExperimentalNota: 5 de 5 estrelas5/5 (2)
- Algoritmos em Java: Busca, ordenação e análiseNo EverandAlgoritmos em Java: Busca, ordenação e análiseNota: 5 de 5 estrelas5/5 (1)
- A Perda Auditva e a vida : Um guia para os pais sobre cansaço ,demencia ,tinido e vertigemNo EverandA Perda Auditva e a vida : Um guia para os pais sobre cansaço ,demencia ,tinido e vertigemAinda não há avaliações
- Atlas de urodinâmica: Práticas clínicas de consultório para urologistas e ginecologistasNo EverandAtlas de urodinâmica: Práticas clínicas de consultório para urologistas e ginecologistasNota: 2 de 5 estrelas2/5 (1)
- Transtornos Alimentares e NeurociênciaNo EverandTranstornos Alimentares e NeurociênciaAinda não há avaliações
- Dieta Cetogênica: Seu Guia Completo E Definitivo Para Perder Peso Para IniciantesNo EverandDieta Cetogênica: Seu Guia Completo E Definitivo Para Perder Peso Para IniciantesNota: 5 de 5 estrelas5/5 (1)
- Medicina integrativa: A cura pelo equilíbrioNo EverandMedicina integrativa: A cura pelo equilíbrioNota: 4.5 de 5 estrelas4.5/5 (7)
- Parasitologia 1: Helmintos de Interesse MédicoNo EverandParasitologia 1: Helmintos de Interesse MédicoAinda não há avaliações
- Microbiologia Médica I: Patógenos e Microbioma HumanoNo EverandMicrobiologia Médica I: Patógenos e Microbioma HumanoAinda não há avaliações
- Dietoterapia Ambulatorial: Nutrição no sobrepeso, na hipertensão e nas dislipidemiasNo EverandDietoterapia Ambulatorial: Nutrição no sobrepeso, na hipertensão e nas dislipidemiasAinda não há avaliações
- Equilíbrio hormonal _ Recupere equilíbrio hormonal, libido, sono e emagreça já!No EverandEquilíbrio hormonal _ Recupere equilíbrio hormonal, libido, sono e emagreça já!Nota: 5 de 5 estrelas5/5 (2)
- As Constelações Familiares na Medicina: O que as Histórias Revelam sobre Sintomas, Doenças e CuraNo EverandAs Constelações Familiares na Medicina: O que as Histórias Revelam sobre Sintomas, Doenças e CuraNota: 3 de 5 estrelas3/5 (5)
- 10 Induções hipnóticas para profissionaisNo Everand10 Induções hipnóticas para profissionaisNota: 4 de 5 estrelas4/5 (8)
- Formas lúdicas de investigação em psicologia:: Procedimento de Desenhos-Estórias e Procedimento de Desenhos de Família com EstóriasNo EverandFormas lúdicas de investigação em psicologia:: Procedimento de Desenhos-Estórias e Procedimento de Desenhos de Família com EstóriasNota: 5 de 5 estrelas5/5 (2)
- Fragmento de uma análise de histeria [O caso Dora]No EverandFragmento de uma análise de histeria [O caso Dora]Nota: 5 de 5 estrelas5/5 (4)
- Sem açúcar: Doces, bolos e tortas liberadosNo EverandSem açúcar: Doces, bolos e tortas liberadosNota: 5 de 5 estrelas5/5 (2)

























































































































![Fragmento de uma análise de histeria [O caso Dora]](https://imgv2-1-f.scribdassets.com/img/word_document/457949460/149x198/f0012e6e80/1708442340?v=1)
